 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SHAQ: Single Headed Attention with Quasi-Recurrence
Aug 18, 2021
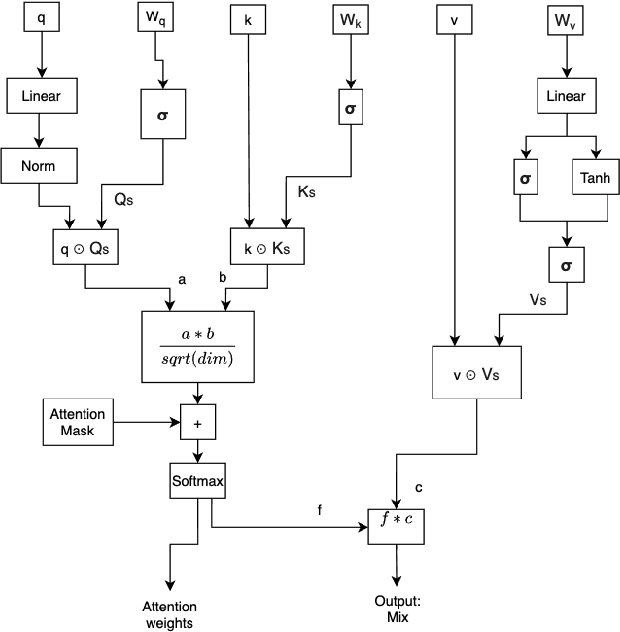
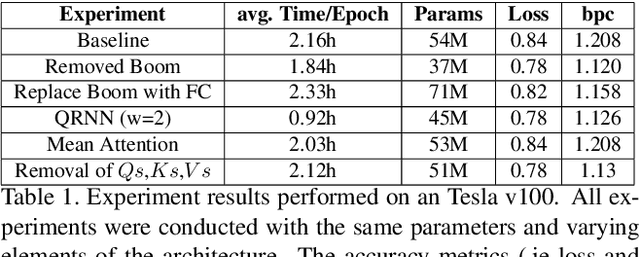
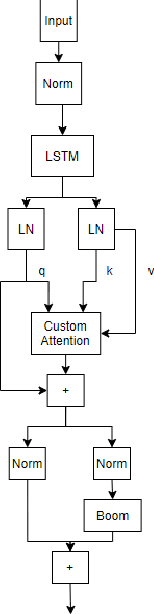
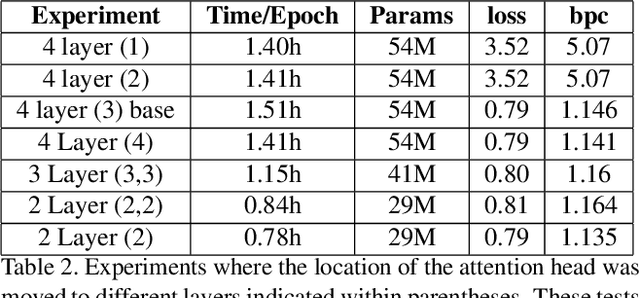
Natural Language Processing research has recently been dominated by large scale transformer models. Although they achieve state of the art on many important language tasks, transformers often require expensive compute resources, and days spanning to weeks to train. This is feasible for researchers at big tech companies and leading research universities, but not for scrappy start-up founders, students, and independent researchers. Stephen Merity's SHA-RNN, a compact, hybrid attention-RNN model, is designed for consumer-grade modeling as it requires significantly fewer parameters and less training time to reach near state of the art results. We analyze Merity's model here through an exploratory model analysis over several units of the architecture considering both training time and overall quality in our assessment. Ultimately, we combine these findings into a new architecture which we call SHAQ: Single Headed Attention Quasi-recurrent Neural Network. With our new architecture we achieved similar accuracy results as the SHA-RNN while accomplishing a 4x speed boost in training.
Human-in-the-Loop Disinformation Detection: Stance, Sentiment, or Something Else?
Nov 09, 2021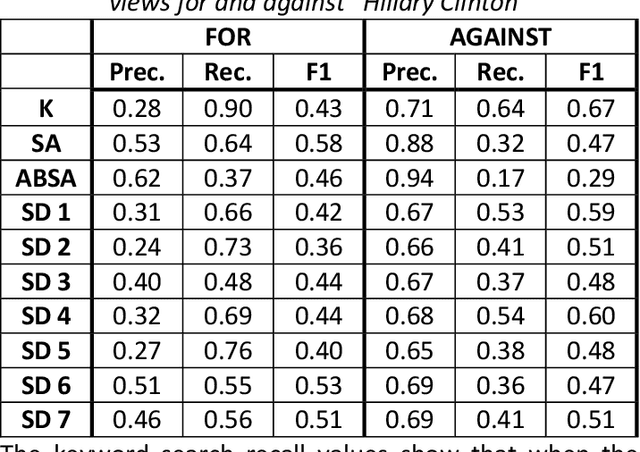
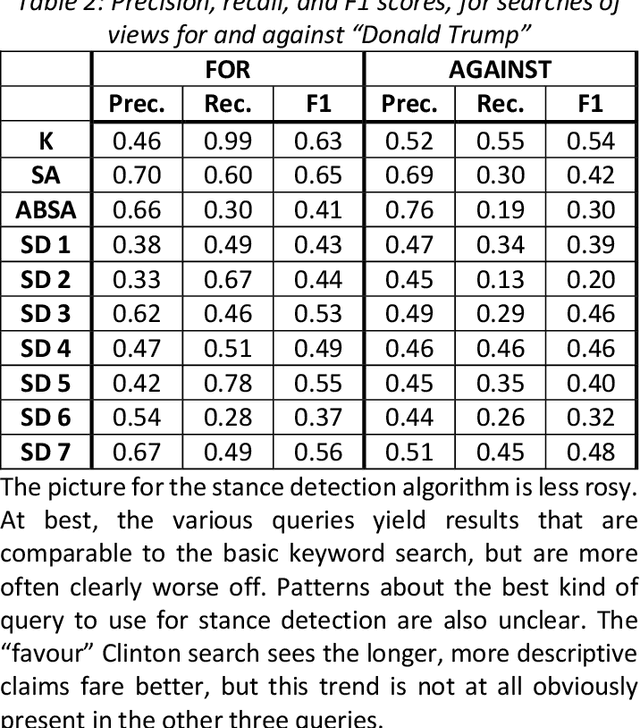
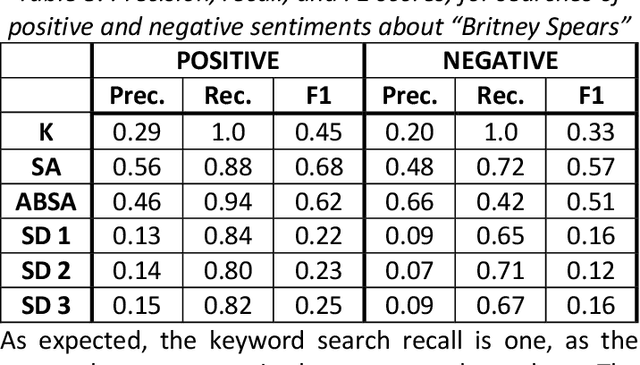
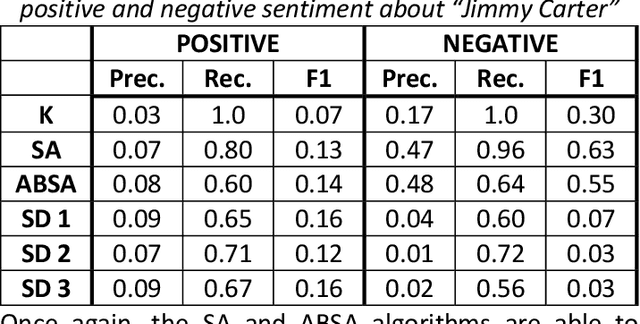
Both politics and pandemics have recently provided ample motivation for the development of machine learning-enabled disinformation (a.k.a. fake news) detection algorithms. Existing literature has focused primarily on the fully-automated case, but the resulting techniques cannot reliably detect disinformation on the varied topics, sources, and time scales required for military applications. By leveraging an already-available analyst as a human-in-the-loop, however, the canonical machine learning techniques of sentiment analysis, aspect-based sentiment analysis, and stance detection become plausible methods to use for a partially-automated disinformation detection system. This paper aims to determine which of these techniques is best suited for this purpose and how each technique might best be used towards this end. Training datasets of the same size and nearly identical neural architectures (a BERT transformer as a word embedder with a single feed-forward layer thereafter) are used for each approach, which are then tested on sentiment- and stance-specific datasets to establish a baseline of how well each method can be used to do the other tasks. Four different datasets relating to COVID-19 disinformation are used to test the ability of each technique to detect disinformation on a topic that did not appear in the training data set. Quantitative and qualitative results from these tests are then used to provide insight into how best to employ these techniques in practice.
MT3: Multi-Task Multitrack Music Transcription
Nov 04, 2021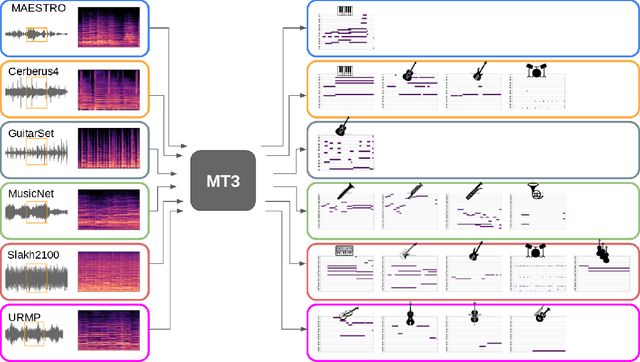

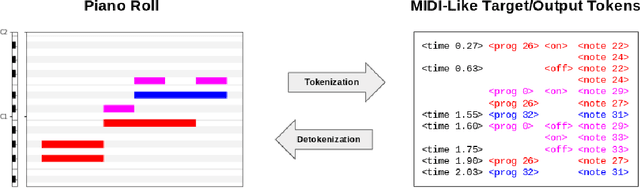
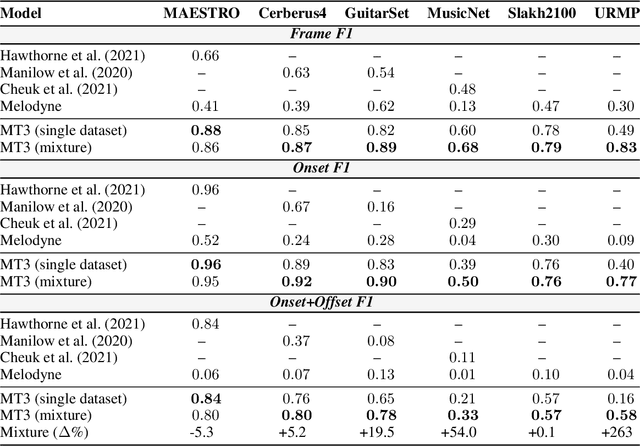
Automatic Music Transcription (AMT), inferring musical notes from raw audio, is a challenging task at the core of music understanding. Unlike Automatic Speech Recognition (ASR), which typically focuses on the words of a single speaker, AMT often requires transcribing multiple instruments simultaneously, all while preserving fine-scale pitch and timing information. Further, many AMT datasets are "low-resource", as even expert musicians find music transcription difficult and time-consuming. Thus, prior work has focused on task-specific architectures, tailored to the individual instruments of each task. In this work, motivated by the promising results of sequence-to-sequence transfer learning for low-resource Natural Language Processing (NLP), we demonstrate that a general-purpose Transformer model can perform multi-task AMT, jointly transcribing arbitrary combinations of musical instruments across several transcription datasets. We show this unified training framework achieves high-quality transcription results across a range of datasets, dramatically improving performance for low-resource instruments (such as guitar), while preserving strong performance for abundant instruments (such as piano). Finally, by expanding the scope of AMT, we expose the need for more consistent evaluation metrics and better dataset alignment, and provide a strong baseline for this new direction of multi-task AMT.
CNN-Based Real-Time Parameter Tuning for Optimizing Denoising Filter Performance
Jan 20, 2020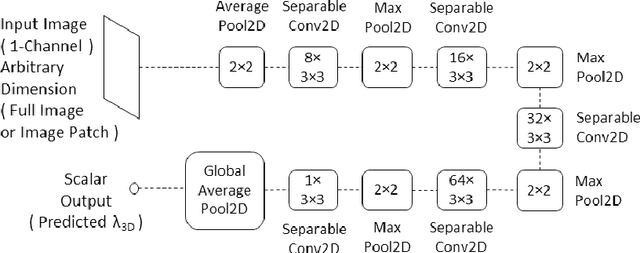
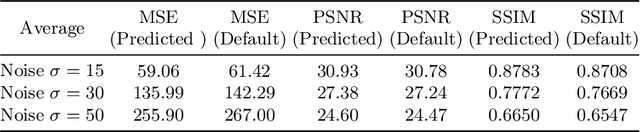
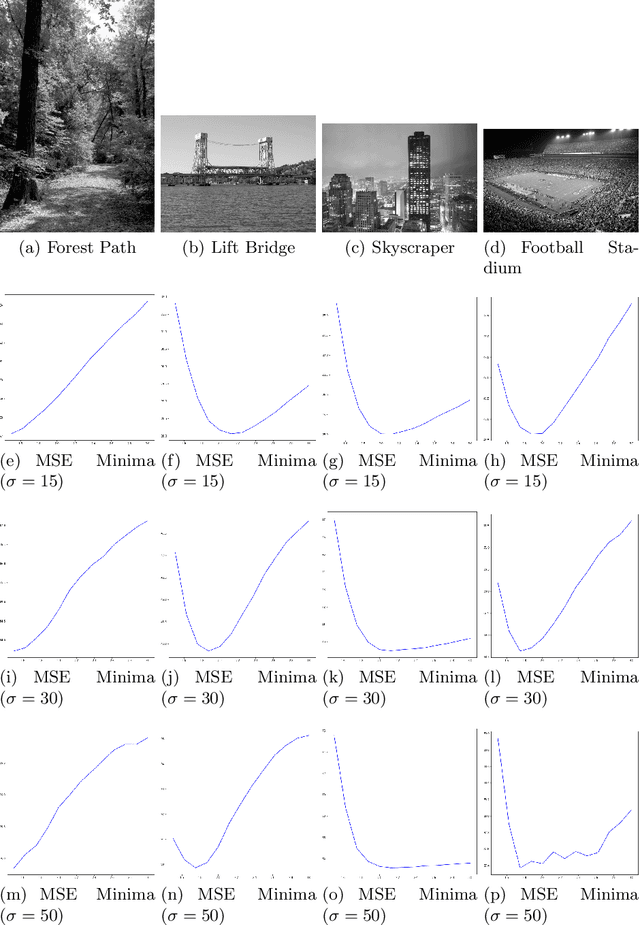

We propose a novel direction to improve the denoising quality of filtering-based denoising algorithms in real time by predicting the best filter parameter value using a Convolutional Neural Network (CNN). We take the use case of BM3D, the state-of-the-art filtering-based denoising algorithm, to demonstrate and validate our approach. We propose and train a simple, shallow CNN to predict in real time, the optimum filter parameter value, given the input noisy image. Each training example consists of a noisy input image (training data) and the filter parameter value that produces the best output (training label). Both qualitative and quantitative results using the widely used PSNR and SSIM metrics on the popular BSD68 dataset show that the CNN-guided BM3D outperforms the original, unguided BM3D across different noise levels. Thus, our proposed method is a CNN-based improvement on the original BM3D which uses a fixed, default parameter value for all images.
Offline Reinforcement Learning: Fundamental Barriers for Value Function Approximation
Nov 21, 2021
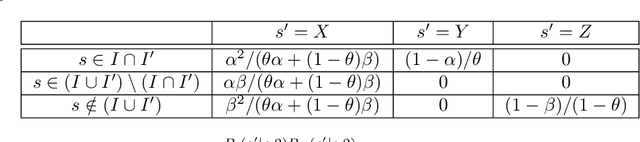
We consider the offline reinforcement learning problem, where the aim is to learn a decision making policy from logged data. Offline RL -- particularly when coupled with (value) function approximation to allow for generalization in large or continuous state spaces -- is becoming increasingly relevant in practice, because it avoids costly and time-consuming online data collection and is well suited to safety-critical domains. Existing sample complexity guarantees for offline value function approximation methods typically require both (1) distributional assumptions (i.e., good coverage) and (2) representational assumptions (i.e., ability to represent some or all $Q$-value functions) stronger than what is required for supervised learning. However, the necessity of these conditions and the fundamental limits of offline RL are not well understood in spite of decades of research. This led Chen and Jiang (2019) to conjecture that concentrability (the most standard notion of coverage) and realizability (the weakest representation condition) alone are not sufficient for sample-efficient offline RL. We resolve this conjecture in the positive by proving that in general, even if both concentrability and realizability are satisfied, any algorithm requires sample complexity polynomial in the size of the state space to learn a non-trivial policy. Our results show that sample-efficient offline reinforcement learning requires either restrictive coverage conditions or representation conditions that go beyond supervised learning, and highlight a phenomenon called over-coverage which serves as a fundamental barrier for offline value function approximation methods. A consequence of our results for reinforcement learning with linear function approximation is that the separation between online and offline RL can be arbitrarily large, even in constant dimension.
DirectQuote: A Dataset for Direct Quotation Extraction and Attribution in News Articles
Oct 15, 2021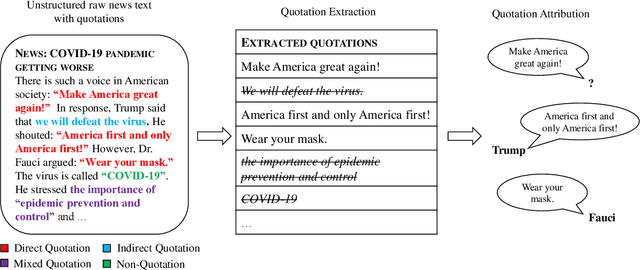
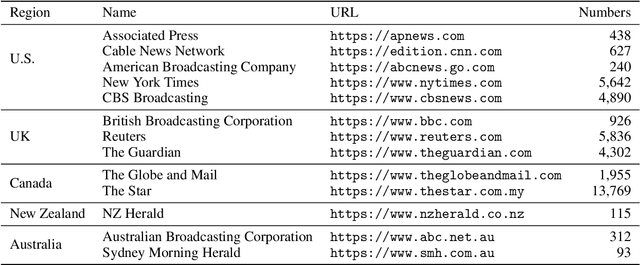


Quotation extraction and attribution are challenging tasks, aiming at determining the spans containing quotations and attributing each quotation to the original speaker. Applying this task to news data is highly related to fact-checking, media monitoring and news tracking. Direct quotations are more traceable and informative, and therefore of great significance among different types of quotations. Therefore, this paper introduces DirectQuote, a corpus containing 19,760 paragraphs and 10,279 direct quotations manually annotated from online news media. To the best of our knowledge, this is the largest and most complete corpus that focuses on direct quotations in news texts. We ensure that each speaker in the annotation can be linked to a specific named entity on Wikidata, benefiting various downstream tasks. In addition, for the first time, we propose several sequence labeling models as baseline methods to extract and attribute quotations simultaneously in an end-to-end manner.
Continuous-discrete multiple target tracking with out-of-sequence measurements
Jun 09, 2021
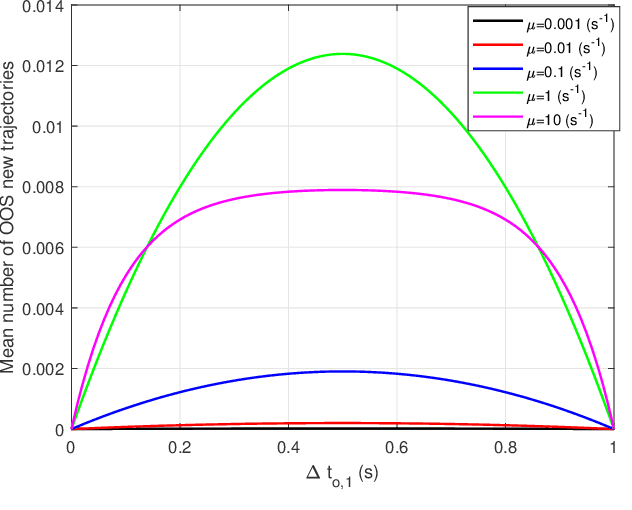
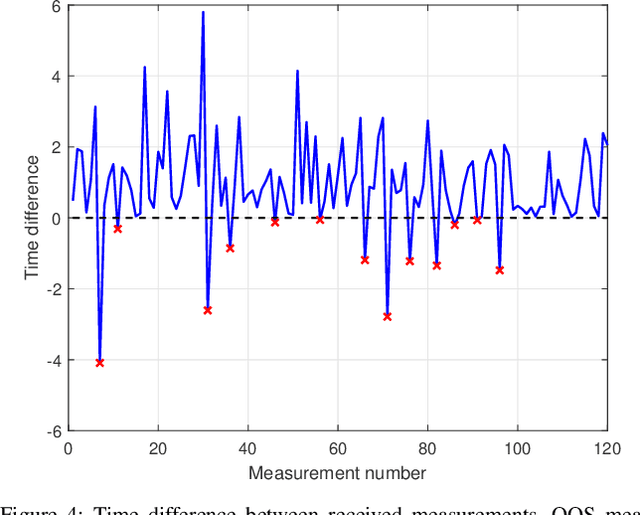
This paper derives the optimal Bayesian processing of an out-of-sequence (OOS) set of measurements in continuous-time for multiple target tracking. We consider a multi-target system modelled in continuous time that is discretised at the time steps when we receive the measurements, which are distributed according to the standard point target model. All information about this system at the sampled time steps is provided by the posterior density on the set of all trajectories. This density can be computed via the continuous-discrete trajectory Poisson multi-Bernoulli mixture (TPMBM) filter. When we receive an OOS measurement, the optimal Bayesian processing performs a retrodiction step that adds trajectory information at the OOS measurement time stamp followed by an update step. After the OOS measurement update, the posterior remains in TPMBM form. We also provide a computationally lighter alternative based on a trajectory Poisson multi-Bernoulli filter. The effectiveness of the two approaches to handle OOS measurements is evaluated via simulations.
Big Data Testing Techniques: Taxonomy, Challenges and Future Trends
Nov 04, 2021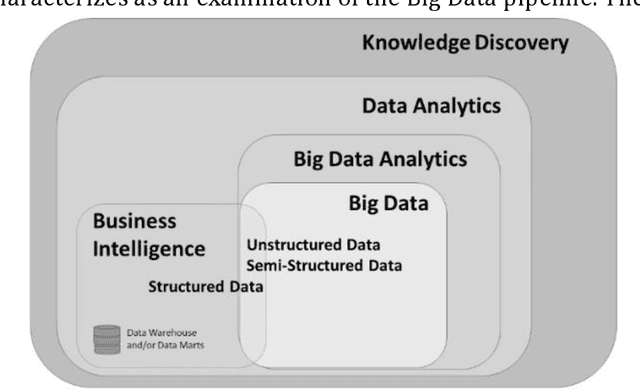
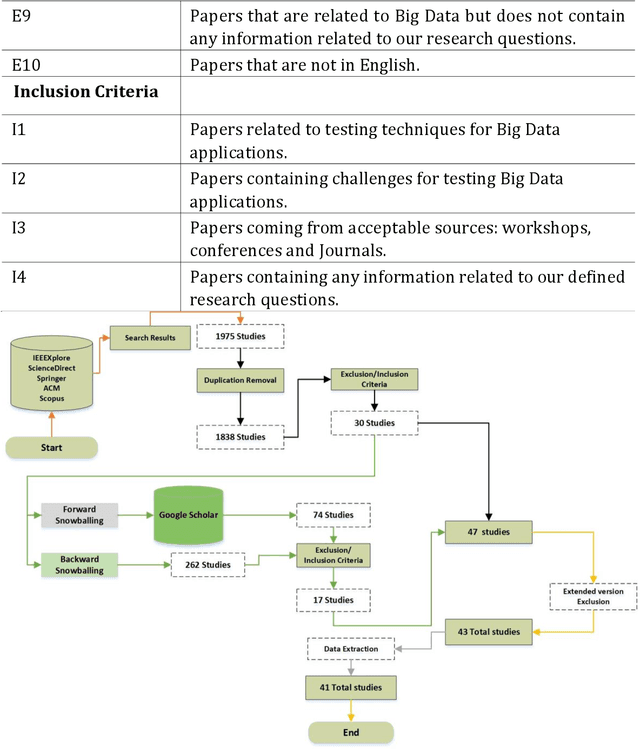
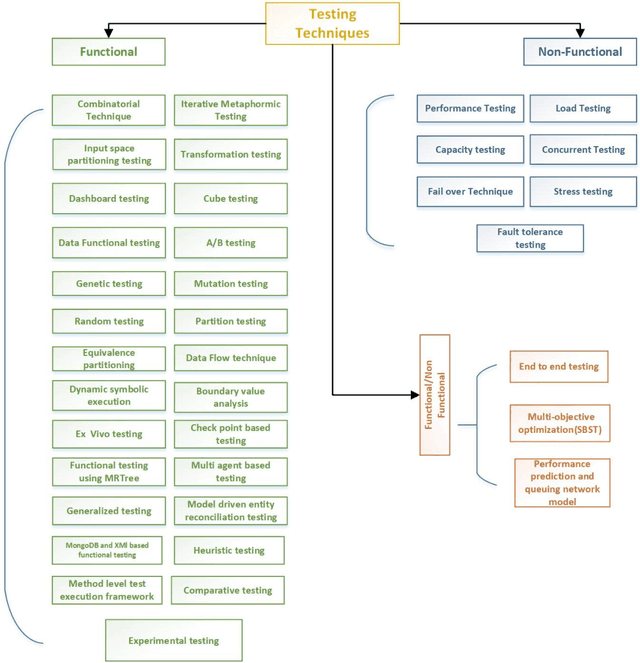

Big Data is reforming many industrial domains by providing decision support through analyzing large volumes of data. Big Data testing aims to ensure that Big Data systems run smoothly and error-free while maintaining the performance and quality of data. However, because of the diversity and complexity of data, testing Big Data is challenging. Though numerous researches deal with Big Data testing, a comprehensive review to address testing techniques and challenges is not conflate yet. Therefore, we have conducted a systematic review of the Big Data testing techniques period (2010 - 2021). This paper discusses the processing of testing data by highlighting the techniques used in every processing phase. Furthermore, we discuss the challenges and future directions. Our finding shows that diverse functional, non-functional and combined (functional and non-functional) testing techniques have been used to solve specific problems related to Big Data. At the same time, most of the testing challenges have been faced during the MapReduce validation phase. In addition, the combinatorial testing technique is one of the most applied techniques in combination with other techniques (i.e., random testing, mutation testing, input space partitioning and equivalence testing) to solve various functional faults challenges faced during Big Data testing.
RAVE: A variational autoencoder for fast and high-quality neural audio synthesis
Nov 09, 2021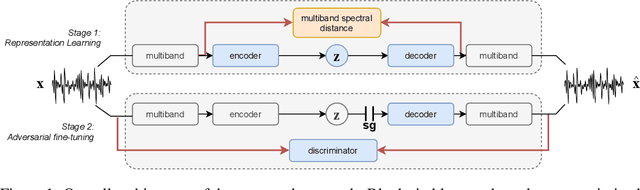
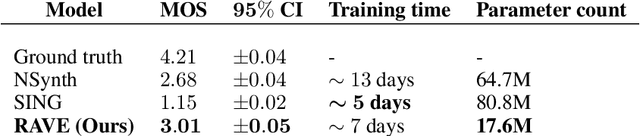
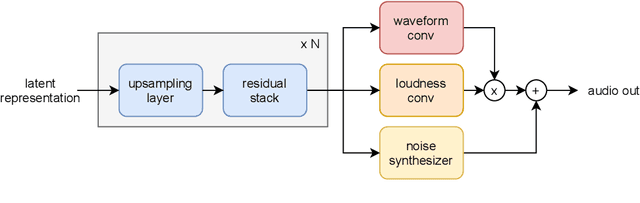

Deep generative models applied to audio have improved by a large margin the state-of-the-art in many speech and music related tasks. However, as raw waveform modelling remains an inherently difficult task, audio generative models are either computationally intensive, rely on low sampling rates, are complicated to control or restrict the nature of possible signals. Among those models, Variational AutoEncoders (VAE) give control over the generation by exposing latent variables, although they usually suffer from low synthesis quality. In this paper, we introduce a Realtime Audio Variational autoEncoder (RAVE) allowing both fast and high-quality audio waveform synthesis. We introduce a novel two-stage training procedure, namely representation learning and adversarial fine-tuning. We show that using a post-training analysis of the latent space allows a direct control between the reconstruction fidelity and the representation compactness. By leveraging a multi-band decomposition of the raw waveform, we show that our model is the first able to generate 48kHz audio signals, while simultaneously running 20 times faster than real-time on a standard laptop CPU. We evaluate synthesis quality using both quantitative and qualitative subjective experiments and show the superiority of our approach compared to existing models. Finally, we present applications of our model for timbre transfer and signal compression. All of our source code and audio examples are publicly available.
Leveraging SE(3) Equivariance for Self-Supervised Category-Level Object Pose Estimation
Oct 30, 2021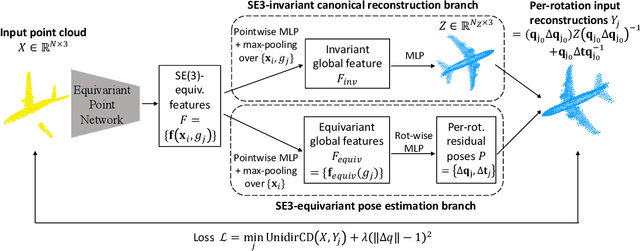

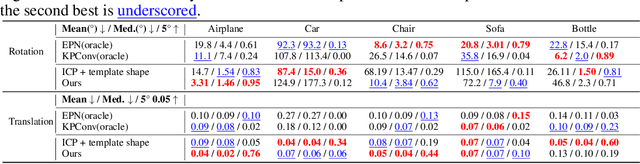

Category-level object pose estimation aims to find 6D object poses of previously unseen object instances from known categories without access to object CAD models. To reduce the huge amount of pose annotations needed for category-level learning, we propose for the first time a self-supervised learning framework to estimate category-level 6D object pose from single 3D point clouds.During training, our method assumes no ground-truth pose annotations, no CAD models, and no multi-view supervision. The key to our method is to disentangle shape and pose through an invariant shape reconstruction module and an equivariant pose estimation module, empowered by SE(3) equivariant point cloud networks.The invariant shape reconstruction module learns to perform aligned reconstructions, yielding a category-level reference frame without using any annotations. In addition, the equivariant pose estimation module achieves category-level pose estimation accuracy that is comparable to some fully supervised methods. Extensive experiments demonstrate the effectiveness of our approach on both complete and partial depth point clouds from the ModelNet40 benchmark, and on real depth point clouds from the NOCS-REAL 275 dataset. The project page with code and visualizations can be found at: https://dragonlong.github.io/equi-pose.