 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time-Resolved fMRI Shared Response Model using Gaussian Process Factor Analysis
Jun 10, 2020
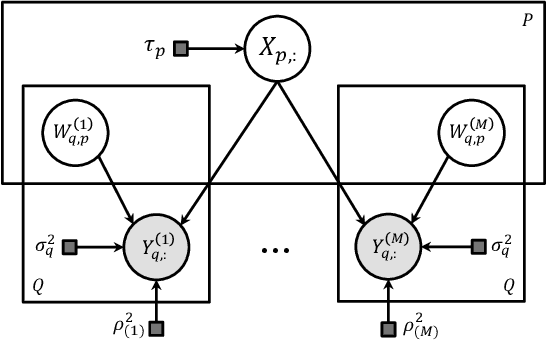
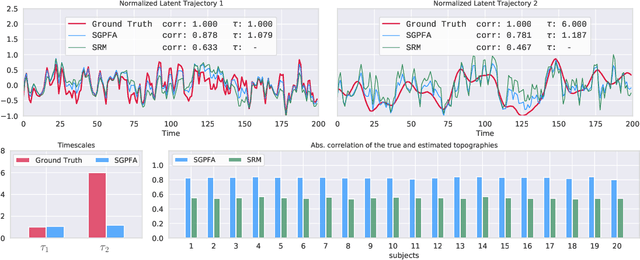
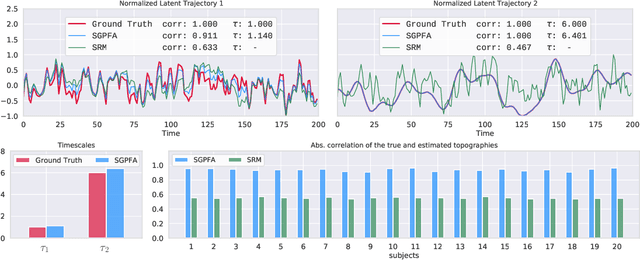
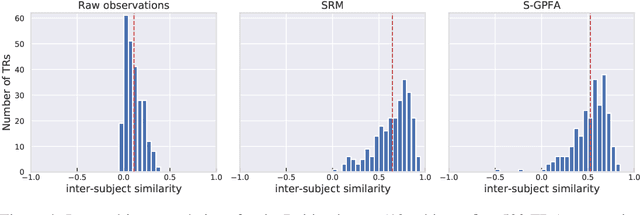
Multi-subject fMRI studies are challenging due to the high variability of both brain anatomy and functional brain topographies across participants. An effective way of aggregating multi-subject fMRI data is to extract a shared representation that filters out unwanted variability among subjects. Some recent work has implemented probabilistic models to extract a shared representation in task fMRI. In the present work, we improve upon these models by incorporating temporal information in the common latent structures. We introduce a new model, Shared Gaussian Process Factor Analysis (S-GPFA), that discovers shared latent trajectories and subject-specific functional topographies, while modelling temporal correlation in fMRI data. We demonstrate the efficacy of our model in revealing ground truth latent structures using simulated data, and replicate experimental performance of time-segment matching and inter-subject similarity on the publicly available Raider dataset. We further test the utility of our model by analyzing its learned model parameters in the large multi-site SPINS dataset, on a social cognition task from participants with and without schizophrenia.
Designing Wireless Powered Networks assisted by Intelligent Reflecting Surfaces with Mechanical Tilt
Aug 25, 2021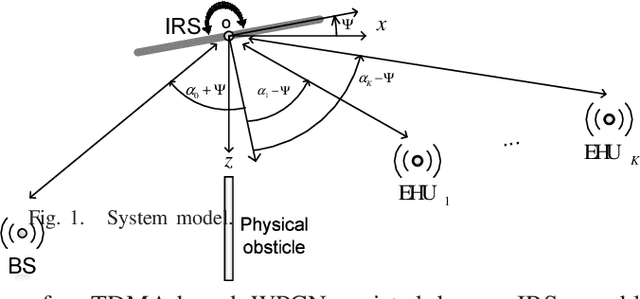
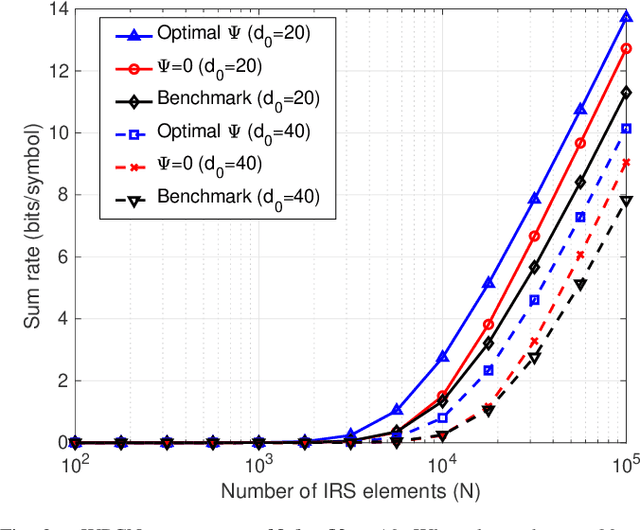
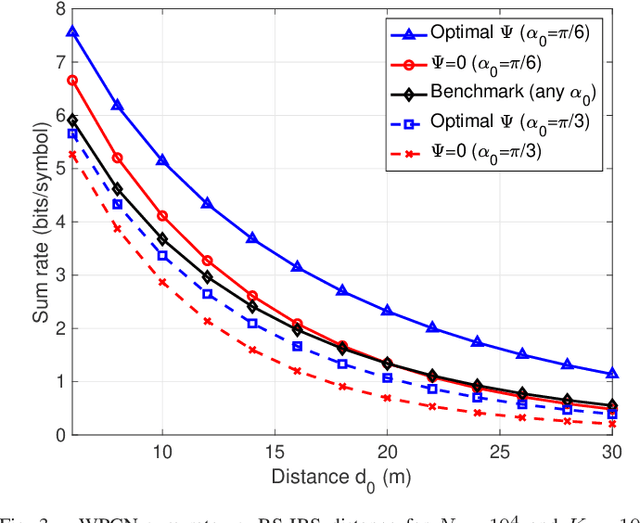
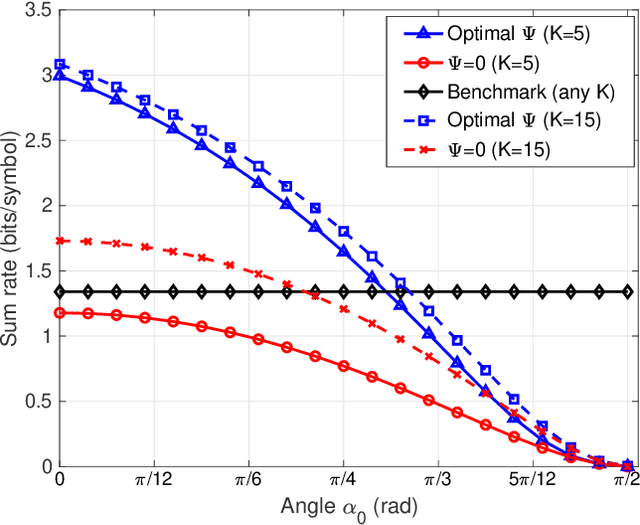
In this paper, we propose a fairness-aware rate maximization scheme for a wireless powered communications network (WPCN) assisted by an intelligent reflecting surface (IRS). The proposed scheme combines user scheduling based on time division multiple access (TDMA) and (mechanical) angular displacement of the IRS. Each energy harvesting user (EHU) has dedicated time slots with optimized durations for energy harvesting and information transmission whereas, the phase matrix of the IRS is adjusted to focus its beam to a particular EHU. The proposed scheme exploits the fundamental dependence of the IRS channel path-loss on the angle between the IRS and the node's line-of-sight, which is often overlooked in the literature. Additionally, the network design can be optimized for large number of IRS unit cells, which is not the case with the computationally intensive state-of-the-art schemes. In fact, the EHUs can achieve significant rates at practical distances of several tens of meters to the base station (BS) only if the number of IRS unit cells is at least a few thousand.
Multistage Pruning of CNN Based ECG Classifiers for Edge Devices
Aug 31, 2021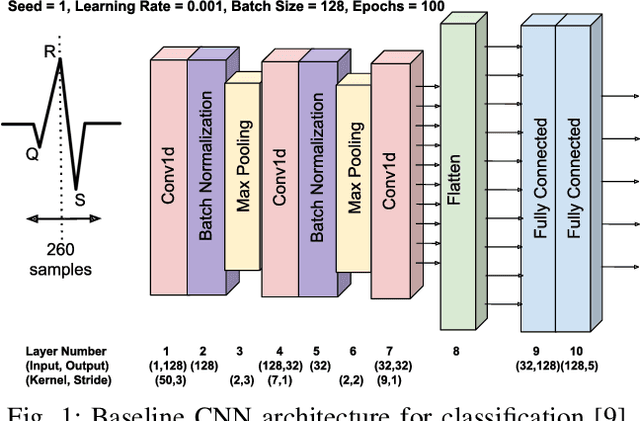

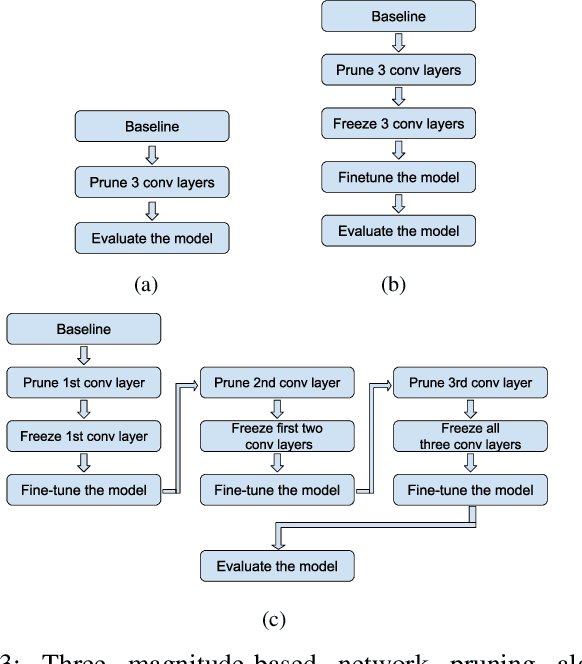
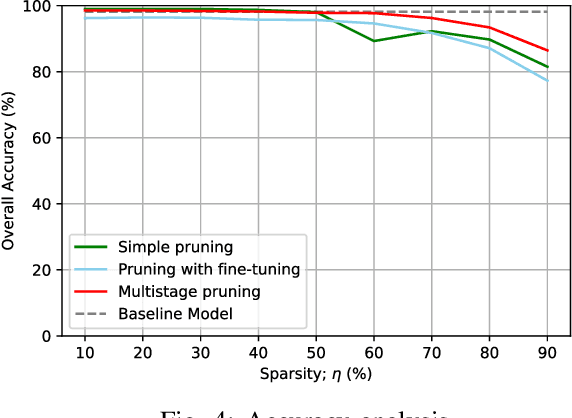
Using smart wearable devices to monitor patients electrocardiogram (ECG) for real-time detection of arrhythmias can significantly improve healthcare outcomes. Convolutional neural network (CNN) based deep learning has been used successfully to detect anomalous beats in ECG. However, the computational complexity of existing CNN models prohibits them from being implemented in low-powered edge devices. Usually, such models are complex with lots of model parameters which results in large number of computations, memory, and power usage in edge devices. Network pruning techniques can reduce model complexity at the expense of performance in CNN models. This paper presents a novel multistage pruning technique that reduces CNN model complexity with negligible loss in performance compared to existing pruning techniques. An existing CNN model for ECG classification is used as a baseline reference. At 60% sparsity, the proposed technique achieves 97.7% accuracy and an F1 score of 93.59% for ECG classification tasks. This is an improvement of 3.3% and 9% for accuracy and F1 Score respectively, compared to traditional pruning with fine-tuning approach. Compared to the baseline model, we also achieve a 60.4% decrease in run-time complexity.
Oil and Gas Pipeline Monitoring during COVID-19 Pandemic via Unmanned Aerial Vehicle
Nov 15, 2021
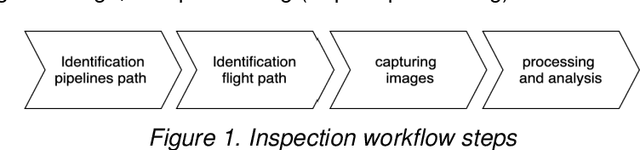
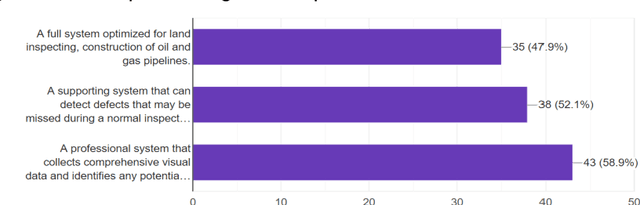
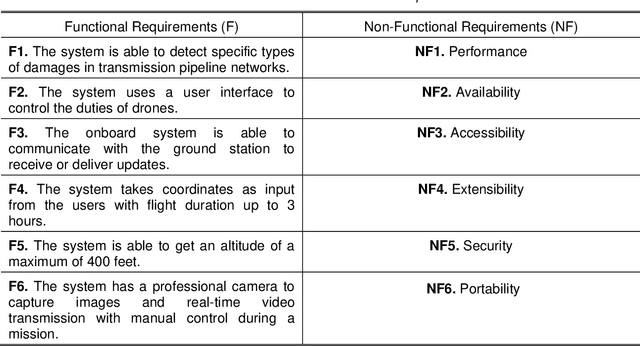
The vast network of oil and gas transmission pipelines requires periodic monitoring for maintenance and hazard inspection to avoid equipment failure and potential accidents. The severe COVID-19 pandemic situation forced the companies to shrink the size of their teams. One risk which is faced on-site is represented by the uncontrolled release of flammable oil and gas. Among many inspection methods, the unmanned aerial vehicle system contains flexibility and stability. Unmanned aerial vehicles can transfer data in real-time, while they are doing their monitoring tasks. The current article focuses on unmanned aerial vehicles equipped with optical sensing and artificial intelligence, especially image recognition with deep learning techniques for pipeline surveillance. Unmanned aerial vehicles can be used for regular patrolling duties to identify and capture images and videos of the area of interest. Places that are hard to reach will be accessed faster, cheaper and with less risk. The current paper is based on the idea of capturing video and images of drone-based inspections, which can discover several potential hazardous problems before they become dangerous. Damage can emerge as a weakening of the cladding on the external pipe insulation. There can also be the case when the thickness of piping through external corrosion can occur. The paper describes a survey completed by experts from the oil and gas industry done for finding the functional and non-functional requirements of the proposed system.
An ASP-based Solution to the Chemotherapy Treatment Scheduling problem
Aug 25, 2021


The problem of scheduling chemotherapy treatments in oncology clinics is a complex problem, given that the solution has to satisfy (as much as possible) several requirements such as the cyclic nature of chemotherapy treatment plans, maintaining a constant number of patients, and the availability of resources, e.g., treatment time, nurses, and drugs. At the same time, realizing a satisfying schedule is of upmost importance for obtaining the best health outcomes. In this paper we first consider a specific instance of the problem which is employed in the San Martino Hospital in Genova, Italy, and present a solution to the problem based on Answer Set Programming (ASP). Then, we enrich the problem and the related ASP encoding considering further features often employed in other hospitals, desirable also in S. Martino, and/or considered in related papers. Results of an experimental analysis, conducted on the real data provided by the San Martino Hospital, show that ASP is an effective solving methodology also for this important scheduling problem. Under consideration for acceptance in TPLP.
Real-Time Monitoring and Driver Feedback to Promote Fuel Efficient Driving
Jul 03, 2020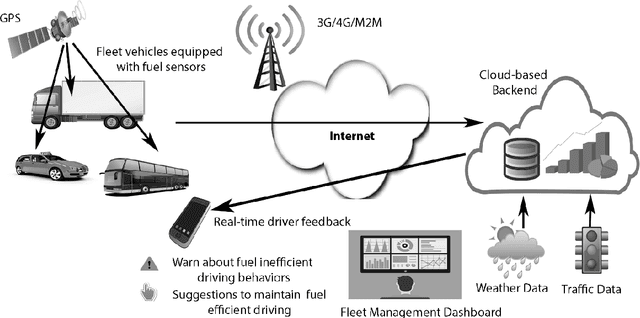
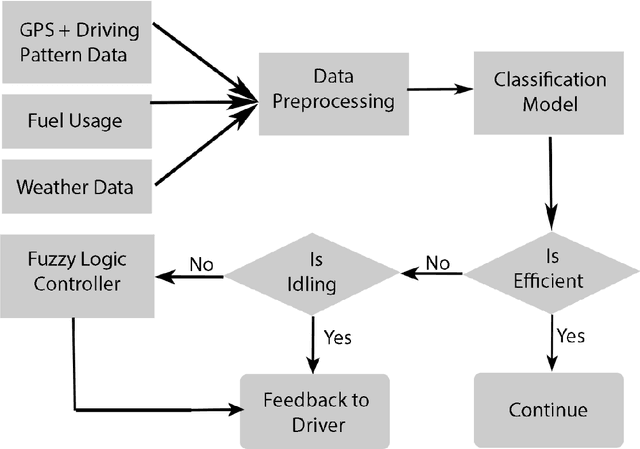
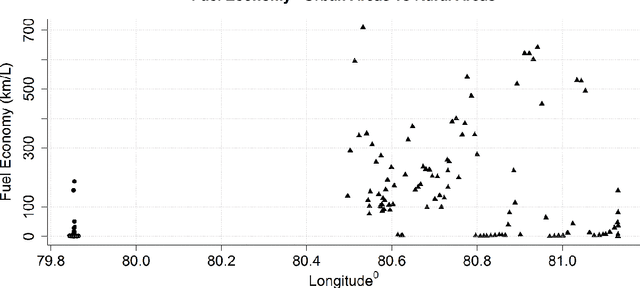
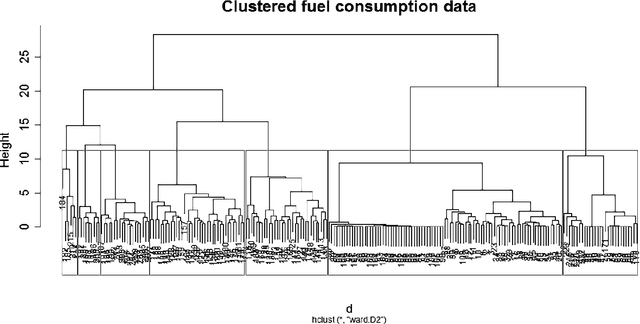
Improving the fuel efficiency of vehicles is imperative to reduce costs and protect the environment. While the efficient engine and vehicle designs, as well as intelligent route planning, are well-known solutions to enhance the fuel efficiency, research has also demonstrated that the adoption of fuel-efficient driving behaviors could lead to further savings. In this work, we propose a novel framework to promote fuel-efficient driving behaviors through real-time automatic monitoring and driver feedback. In this framework, a random-forest based classification model developed using historical data to identifies fuel-inefficient driving behaviors. The classifier considers driver-dependent parameters such as speed and acceleration/deceleration pattern, as well as environmental parameters such as traffic, road topography, and weather to evaluate the fuel efficiency of one-minute driving events. When an inefficient driving action is detected, a fuzzy logic inference system is used to determine what the driver should do to maintain fuel-efficient driving behavior. The decided action is then conveyed to the driver via a smartphone in a non-intrusive manner. Using a dataset from a long-distance bus, we demonstrate that the proposed classification model yields an accuracy of 85.2% while increasing the fuel efficiency up to 16.4%.
STFNets: Learning Sensing Signals from the Time-Frequency Perspective with Short-Time Fourier Neural Networks
Feb 21, 2019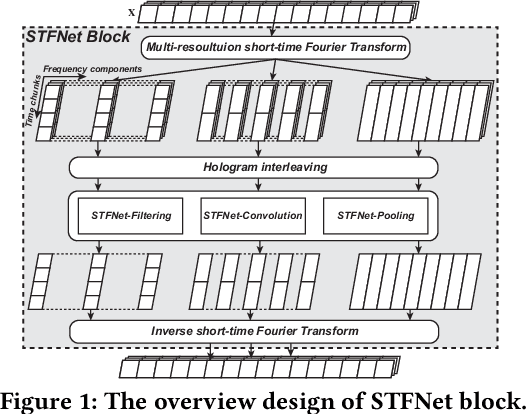
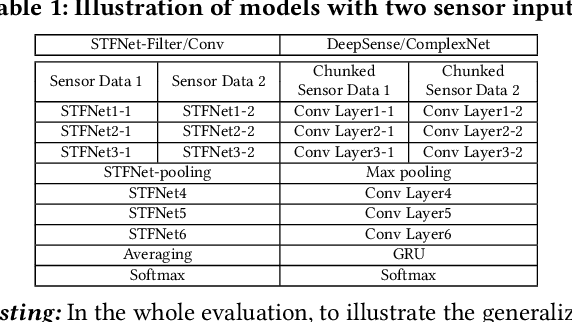
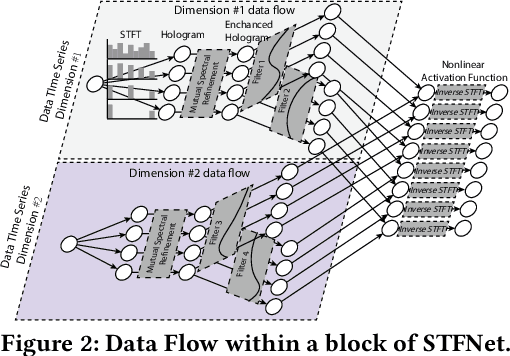
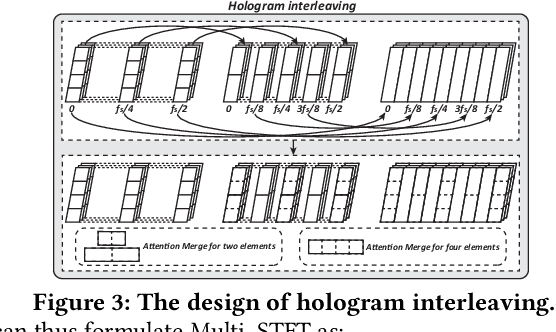
Recent advances in deep learning motivate the use of deep neural networks in Internet-of-Things (IoT) applications. These networks are modelled after signal processing in the human brain, thereby leading to significant advantages at perceptual tasks such as vision and speech recognition. IoT applications, however, often measure physical phenomena, where the underlying physics (such as inertia, wireless signal propagation, or the natural frequency of oscillation) are fundamentally a function of signal frequencies, offering better features in the frequency domain. This observation leads to a fundamental question: For IoT applications, can one develop a new brand of neural network structures that synthesize features inspired not only by the biology of human perception but also by the fundamental nature of physics? Hence, in this paper, instead of using conventional building blocks (e.g., convolutional and recurrent layers), we propose a new foundational neural network building block, the Short-Time Fourier Neural Network (STFNet). It integrates a widely-used time-frequency analysis method, the Short-Time Fourier Transform, into data processing to learn features directly in the frequency domain, where the physics of underlying phenomena leave better foot-prints. STFNets bring additional flexibility to time-frequency analysis by offering novel nonlinear learnable operations that are spectral-compatible. Moreover, STFNets show that transforming signals to a domain that is more connected to the underlying physics greatly simplifies the learning process. We demonstrate the effectiveness of STFNets with extensive experiments. STFNets significantly outperform the state-of-the-art deep learning models in all experiments. A STFNet, therefore, demonstrates superior capability as the fundamental building block of deep neural networks for IoT applications for various sensor inputs.
High-Order Signed Distance Transform of Sampled Signals
Oct 26, 2021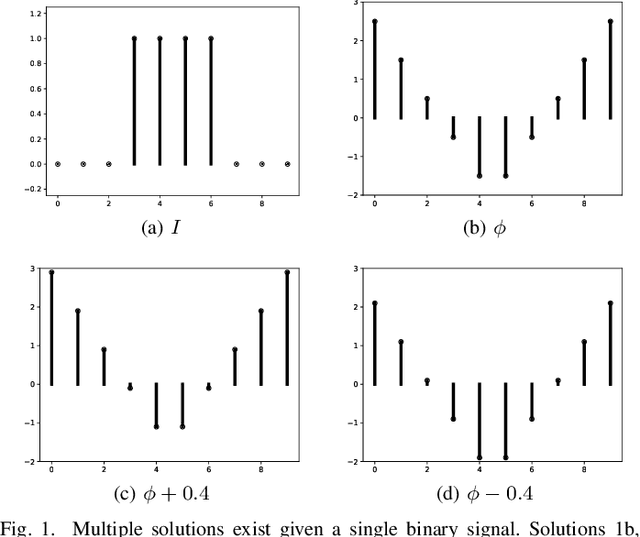

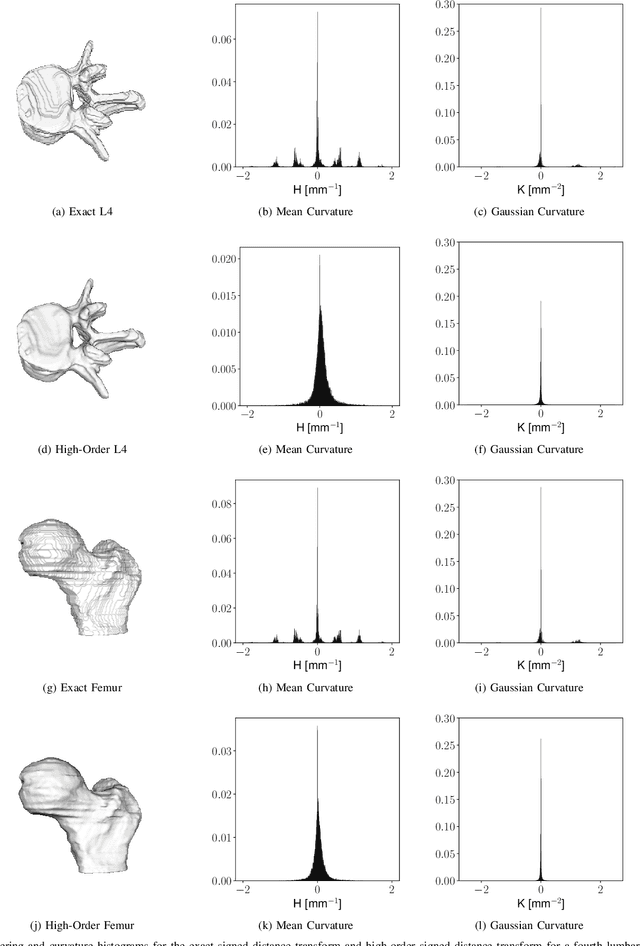
Signed distance transforms of sampled signals can be constructed better than the traditional exact signed distance transform. Such a transform is termed the high-order signed distance transform and is defined as satisfying three conditions: the Eikonal equation, recovery by a Heaviside function, and has an order of accuracy greater than unity away from the medial axis. Such a transform is an improvement to the classic notion of an exact signed distance transform because it does not exhibit artifacts of quantization. A large constant, linear time complexity high-order signed distance transform for arbitrary dimensionality sampled signals is developed based on the high order fast sweeping method. The transform is initialized with an exact signed distance transform and quantization corrected through an upwind solver for the boundary value Eikonal equation. The proposed method cannot attain arbitrary order of accuracy and is limited by the initialization method and non-uniqueness of the problem. However, meshed surfaces are visually smoother and do not exhibit artifacts of quantization in local mean and Gaussian curvature.
GenNI: Human-AI Collaboration for Data-Backed Text Generation
Oct 19, 2021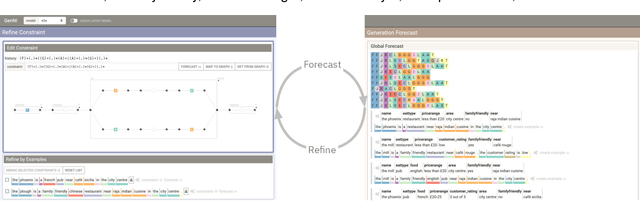
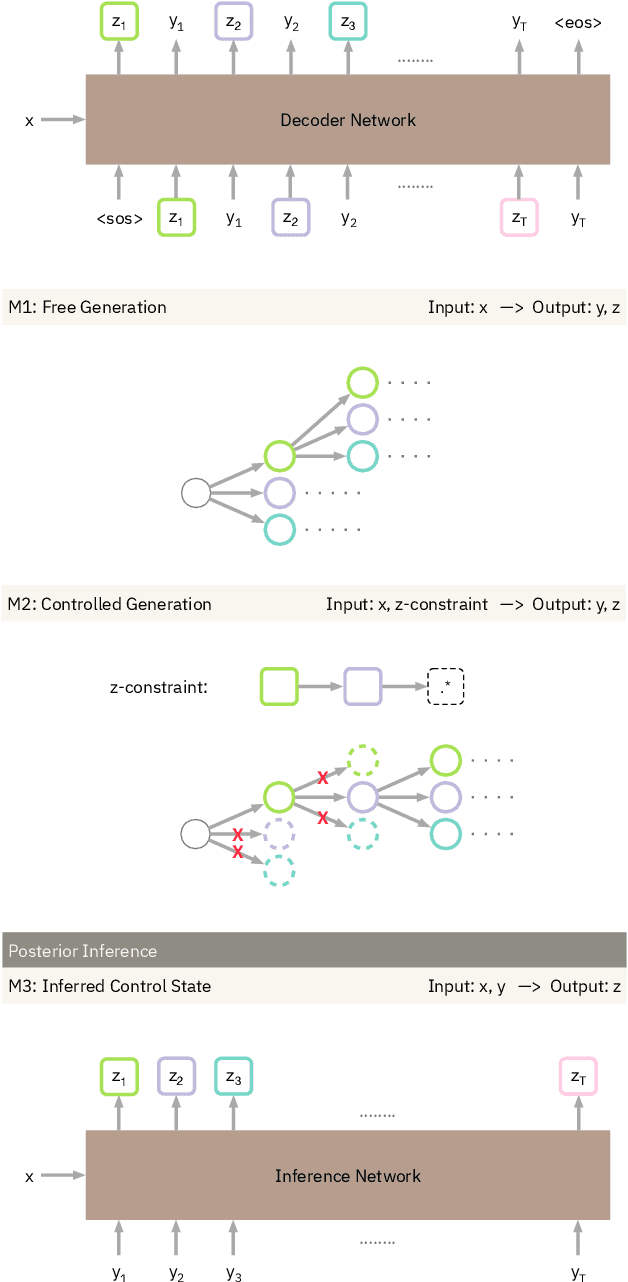
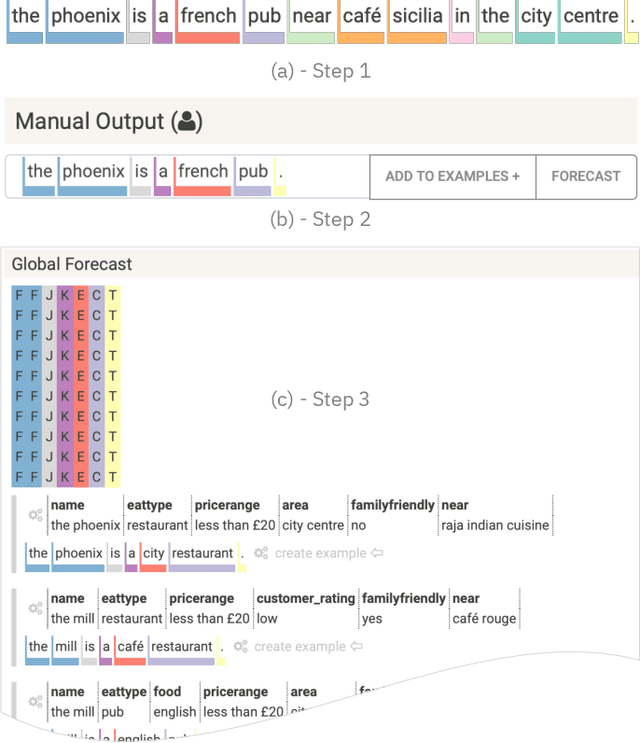
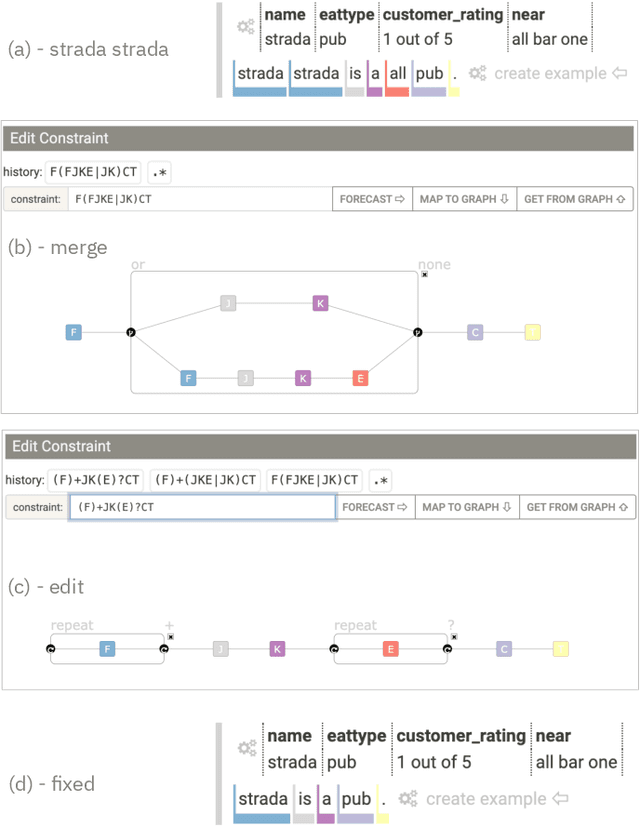
Table2Text systems generate textual output based on structured data utilizing machine learning. These systems are essential for fluent natural language interfaces in tools such as virtual assistants; however, left to generate freely these ML systems often produce misleading or unexpected outputs. GenNI (Generation Negotiation Interface) is an interactive visual system for high-level human-AI collaboration in producing descriptive text. The tool utilizes a deep learning model designed with explicit control states. These controls allow users to globally constrain model generations, without sacrificing the representation power of the deep learning models. The visual interface makes it possible for users to interact with AI systems following a Refine-Forecast paradigm to ensure that the generation system acts in a manner human users find suitable. We report multiple use cases on two experiments that improve over uncontrolled generation approaches, while at the same time providing fine-grained control. A demo and source code are available at https://genni.vizhub.ai .
Fine-grained style control in Transformer-based Text-to-speech Synthesis
Oct 12, 2021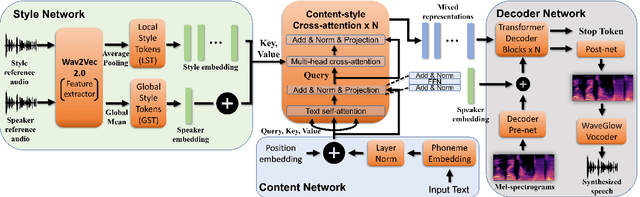

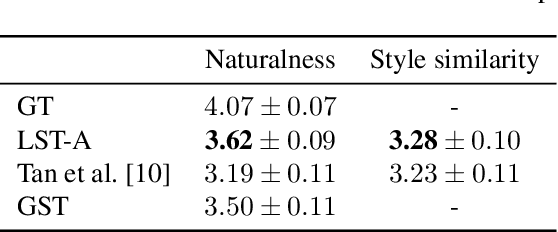
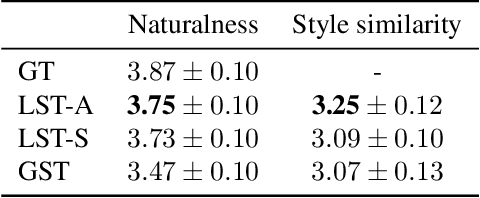
In this paper, we present a novel architecture to realize fine-grained style control on the transformer-based text-to-speech synthesis (TransformerTTS). Specifically, we model the speaking style by extracting a time sequence of local style tokens (LST) from the reference speech. The existing content encoder in TransformerTTS is then replaced by our designed cross-attention blocks for fusion and alignment between content and style. As the fusion is performed along with the skip connection, our cross-attention block provides a good inductive bias to gradually infuse the phoneme representation with a given style. Additionally, we prevent the style embedding from encoding linguistic content by randomly truncating LST during training and using wav2vec 2.0 features. Experiments show that with fine-grained style control, our system performs better in terms of naturalness, intelligibility, and style transferability. Our code and samples are publicly available.