 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Reduction of Subjective Listening Effort for TV Broadcast Signals with Recurrent Neural Networks
Nov 02, 2021
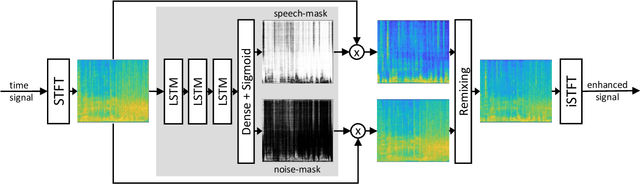
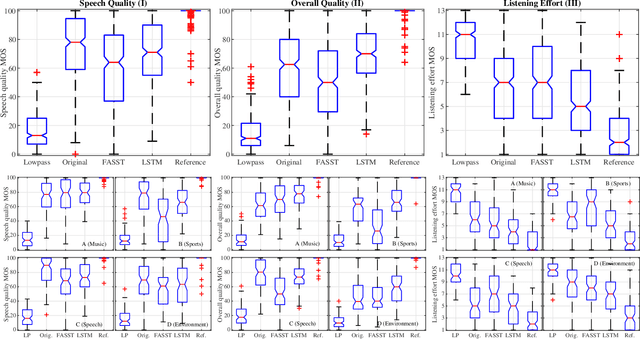


Listening to the audio of TV broadcast signals can be challenging for hearing-impaired as well as normal-hearing listeners, especially when background sounds are prominent or too loud compared to the speech signal. This can result in a reduced satisfaction and increased listening effort of the listeners. Since the broadcast sound is usually premixed, we perform a subjective evaluation for quantifying the potential of speech enhancement systems based on audio source separation and recurrent neural networks (RNN). Recently, RNNs have shown promising results in the context of sound source separation and real-time signal processing. In this paper, we separate the speech from the background signals and remix the separated sounds at a higher signal-to-noise ratio. This differs from classic speech enhancement, where usually only the extracted speech signal is exploited. The subjective evaluation with 20 normal-hearing subjects on real TV-broadcast material shows that our proposed enhancement system is able to reduce the listening effort by around 2 points on a 13-point listening effort rating scale and increases the perceived sound quality compared to the original mixture.
Swarm intelligence algorithms applied to Virtual Reference Feedback Tuning to increase controller robustness -- a one-shot technique
Nov 08, 2021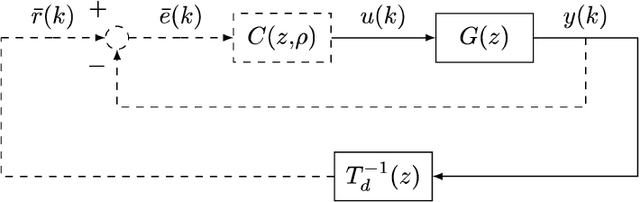

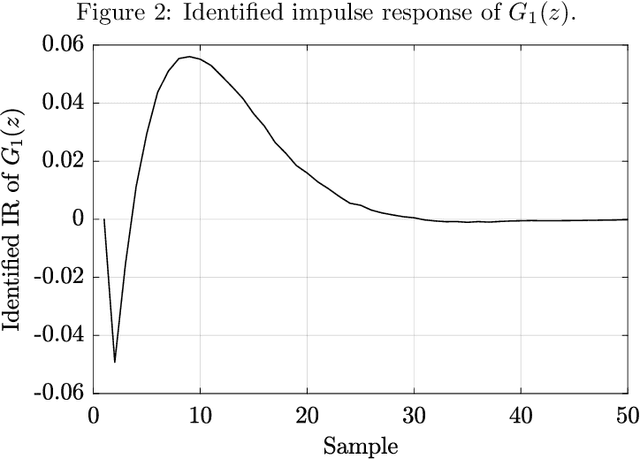

This work presents a data-driven one-shot method for increasing robustness of a discrete-time closed-loop system by changing the controller parameters using swarm intelligence algorithms. Four swarm intelligence algorithms - Particle Swarm Optimization (PSO), Artificial Bee Colony (ABC), Grey Wolf Optimization (GWO), and Improved Grey Wolf Optimization (I-GWO) - are described. Data-driven controller design is commented, focusing on the Virtual Reference Feedback Tuning (VRFT) algorithms. The estimation of the $\mathcal{H}_{\infty}$ norm of $S(z)$ via impulse response is presented. Two illustrative real-world based examples, regarding a Boost-like second order plant and a SEPIC-like fourth order plant, are tested for all commented swarm intelligence algorithms with the proposed method. Each algorithm at each case was run for 50 times, with 100 search agents, and maximum number of iterations limited to 100. For both examples, I-GWO presented the the best desired behavior, with the least number of outliers and no bad outlier in terms of fitness and $||S(z)||_{\infty}$ norm, as well as faster convergence, lowering the $||S(z)||_{\infty}$ norm of the plant from values greater than 2.0 to 1.8, still maintaining a low fitness value.
Roadside-assisted Cooperative Planning using Future Path Sharing for Autonomous Driving
Aug 10, 2021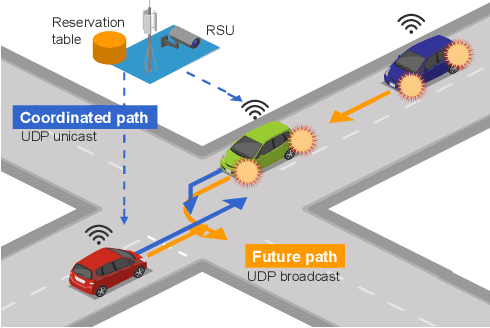
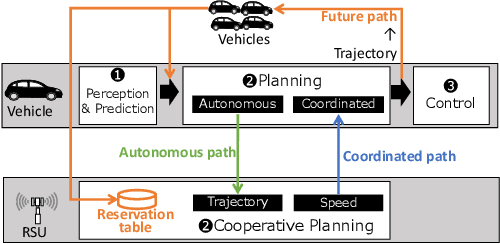
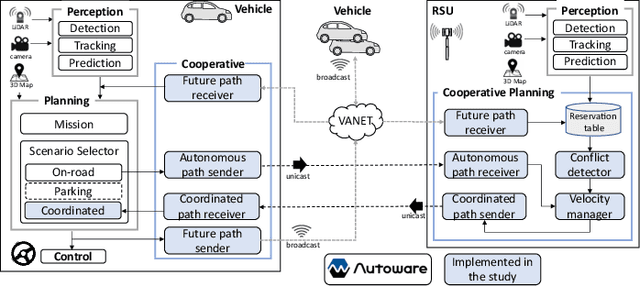
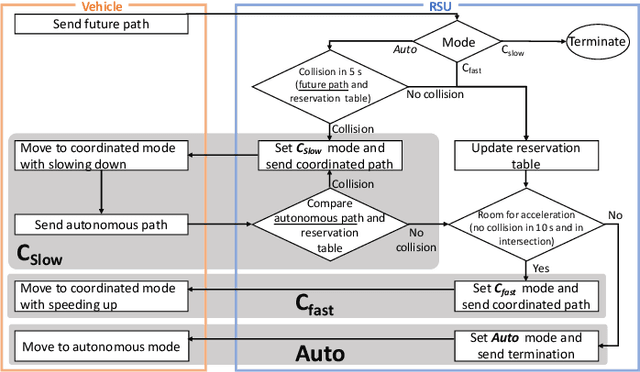
Cooperative intelligent transportation systems (ITS) are used by autonomous vehicles to communicate with surrounding autonomous vehicles and roadside units (RSU). Current C-ITS applications focus primarily on real-time information sharing, such as cooperative perception. In addition to real-time information sharing, self-driving cars need to coordinate their action plans to achieve higher safety and efficiency. For this reason, this study defines a vehicle's future action plan/path and designs a cooperative path-planning model at intersections using future path sharing based on the future path information of multiple vehicles. The notion is that when the RSU detects a potential conflict of vehicle paths or an acceleration opportunity according to the shared future paths, it will generate a coordinated path update that adjusts the speeds of the vehicles. We implemented the proposed method using the open-source Autoware autonomous driving software and evaluated it with the LGSVL autonomous vehicle simulator. We conducted simulation experiments with two vehicles at a blind intersection scenario, finding that each car can travel safely and more efficiently by planning a path that reflects the action plans of all vehicles involved. The time consumed by introducing the RSU is 23.0 % and 28.1 % shorter than that of the stand-alone autonomous driving case at the intersection.
Using neural networks to solve the 2D Poisson equation for electric field computation in plasma fluid simulations
Oct 04, 2021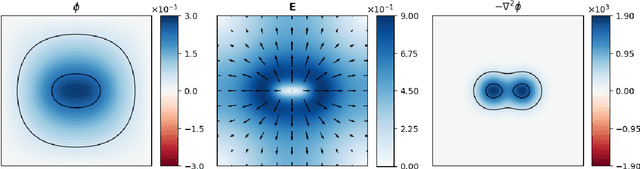
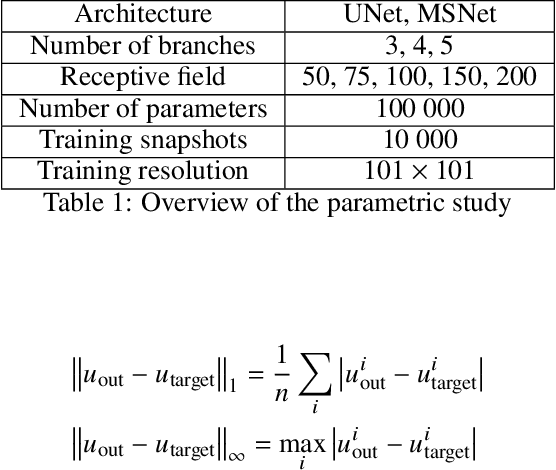
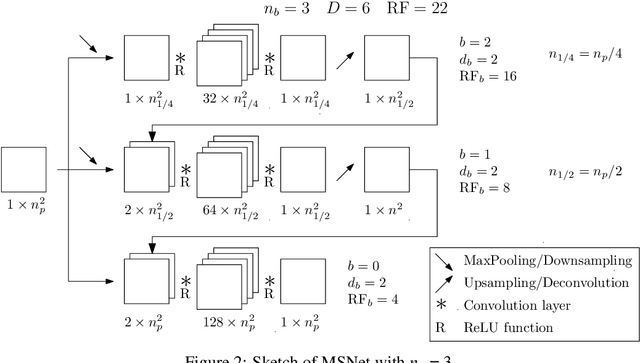
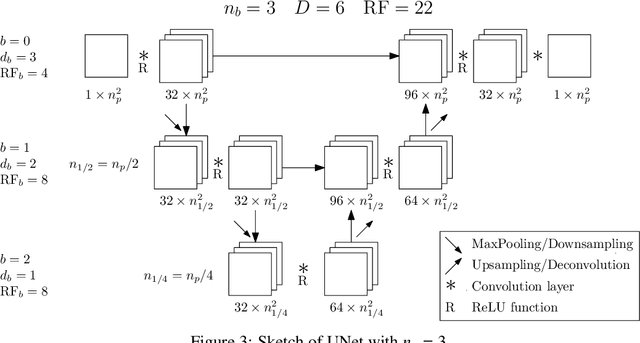
The Poisson equation is critical to get a self-consistent solution in plasma fluid simulations used for Hall effect thrusters and streamers discharges. Solving the 2D Poisson equation with zero Dirichlet boundary conditions using a deep neural network is investigated using multiple-scale architectures, defined in terms of number of branches, depth and receptive field. The latter is found critical to correctly capture large topological structures of the field. The investigation of multiple architectures, losses, and hyperparameters provides an optimum network to solve accurately the steady Poisson problem. Generalization to new resolutions and domain sizes is then proposed using a proper scaling of the network. Finally, found neural network solver, called PlasmaNet, is coupled with an unsteady Euler plasma fluid equations solver. The test case corresponds to electron plasma oscillations which is used to assess the accuracy of the neural network solution in a time-dependent simulation. In this time-evolving problem, a physical loss is necessary to produce a stable simulation. PlasmaNet is then benchmarked on meshes with increasing number of nodes, and compared with an existing solver based on a standard linear system algorithm for the Poisson equation. It outperforms the classical plasma solver, up to speedups 700 times faster on large meshes. PlasmaNet is finally tested on a more complex case of discharge propagation involving chemistry and advection. The guidelines established in previous sections are applied to build the CNN to solve the same Poisson equation but in cylindrical coordinates. Results reveal good CNN predictions with significant speedup. These results pave the way to new computational strategies to predict unsteady problems involving a Poisson equation, including configurations with coupled multiphysics interactions such as in plasma flows.
Adversarial Neuron Pruning Purifies Backdoored Deep Models
Oct 27, 2021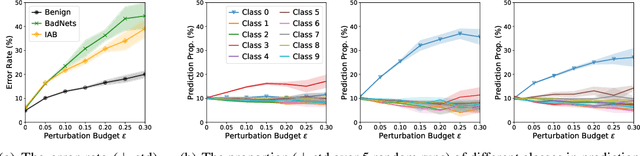
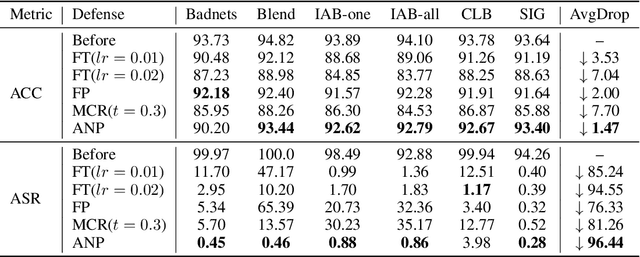

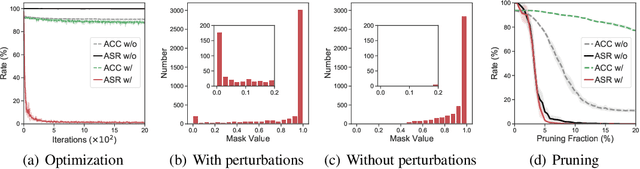
As deep neural networks (DNNs) are growing larger, their requirements for computational resources become huge, which makes outsourcing training more popular. Training in a third-party platform, however, may introduce potential risks that a malicious trainer will return backdoored DNNs, which behave normally on clean samples but output targeted misclassifications whenever a trigger appears at the test time. Without any knowledge of the trigger, it is difficult to distinguish or recover benign DNNs from backdoored ones. In this paper, we first identify an unexpected sensitivity of backdoored DNNs, that is, they are much easier to collapse and tend to predict the target label on clean samples when their neurons are adversarially perturbed. Based on these observations, we propose a novel model repairing method, termed Adversarial Neuron Pruning (ANP), which prunes some sensitive neurons to purify the injected backdoor. Experiments show, even with only an extremely small amount of clean data (e.g., 1%), ANP effectively removes the injected backdoor without causing obvious performance degradation.
Acceleration in Distributed Optimization Under Similarity
Oct 24, 2021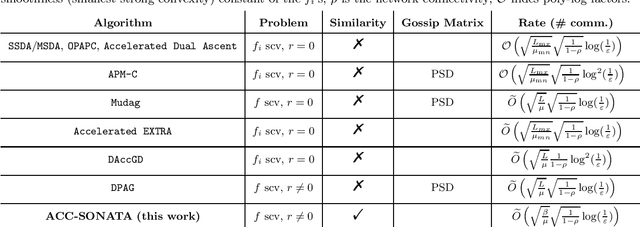
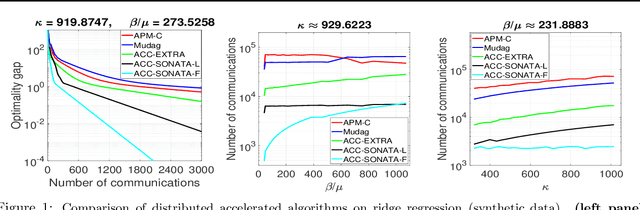
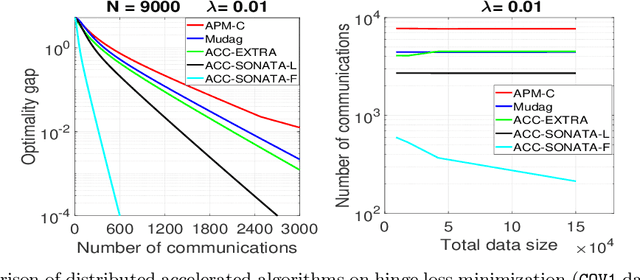
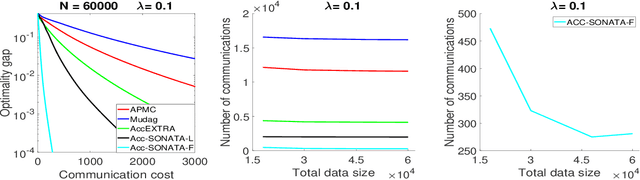
We study distributed (strongly convex) optimization problems over a network of agents, with no centralized nodes. The loss functions of the agents are assumed to be similar, due to statistical data similarity or otherwise. In order to reduce the number of communications to reach a solution accuracy, we proposed a preconditioned, accelerated distributed method. An $\varepsilon$-solution is achieved in $\tilde{\mathcal{O}}\big(\sqrt{\frac{\beta/\mu}{(1-\rho)}}\log1/\varepsilon\big)$ number of communications steps, where $\beta/\mu$ is the relative condition number between the global and local loss functions, and $\rho$ characterizes the connectivity of the network. This rate matches (up to poly-log factors) for the first time lower complexity communication bounds of distributed gossip-algorithms applied to the class of problems of interest. Numerical results show significant communication savings with respect to existing accelerated distributed schemes, especially when solving ill-conditioned problems.
threaTrace: Detecting and Tracing Host-based Threats in Node Level Through Provenance Graph Learning
Nov 08, 2021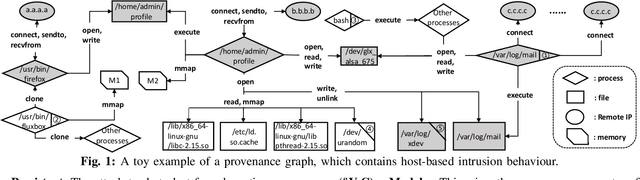
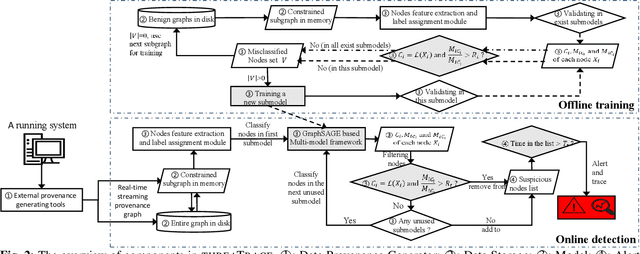
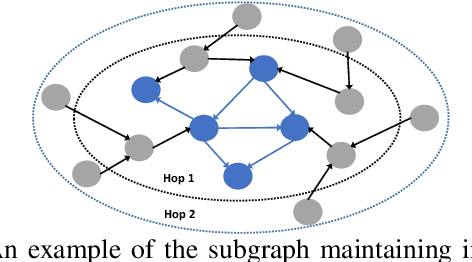
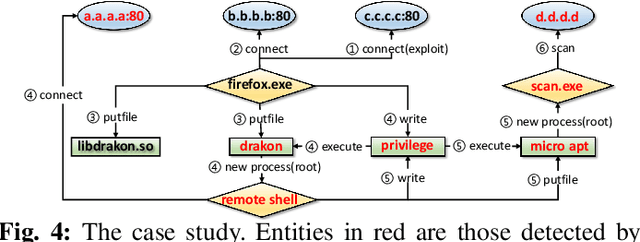
Host-based threats such as Program Attack, Malware Implantation, and Advanced Persistent Threats (APT), are commonly adopted by modern attackers. Recent studies propose leveraging the rich contextual information in data provenance to detect threats in a host. Data provenance is a directed acyclic graph constructed from system audit data. Nodes in a provenance graph represent system entities (e.g., $processes$ and $files$) and edges represent system calls in the direction of information flow. However, previous studies, which extract features of the whole provenance graph, are not sensitive to the small number of threat-related entities and thus result in low performance when hunting stealthy threats. We present threaTrace, an anomaly-based detector that detects host-based threats at system entity level without prior knowledge of attack patterns. We tailor GraphSAGE, an inductive graph neural network, to learn every benign entity's role in a provenance graph. threaTrace is a real-time system, which is scalable of monitoring a long-term running host and capable of detecting host-based intrusion in their early phase. We evaluate threaTrace on three public datasets. The results show that threaTrace outperforms three state-of-the-art host intrusion detection systems.
Logic Shrinkage: Learned FPGA Netlist Sparsity for Efficient Neural Network Inference
Dec 04, 2021
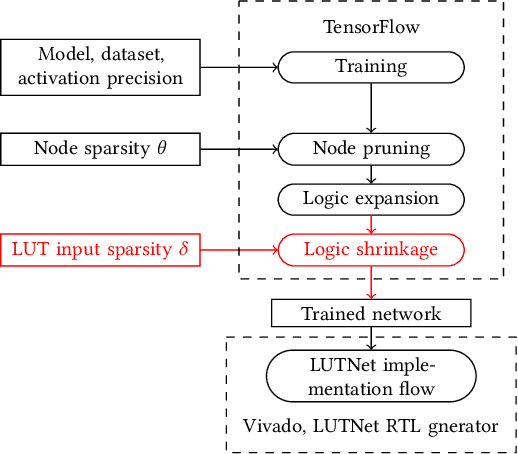

FPGA-specific DNN architectures using the native LUTs as independently trainable inference operators have been shown to achieve favorable area-accuracy and energy-accuracy tradeoffs. The first work in this area, LUTNet, exhibited state-of-the-art performance for standard DNN benchmarks. In this paper, we propose the learned optimization of such LUT-based topologies, resulting in higher-efficiency designs than via the direct use of off-the-shelf, hand-designed networks. Existing implementations of this class of architecture require the manual specification of the number of inputs per LUT, K. Choosing appropriate K a priori is challenging, and doing so at even high granularity, e.g. per layer, is a time-consuming and error-prone process that leaves FPGAs' spatial flexibility underexploited. Furthermore, prior works see LUT inputs connected randomly, which does not guarantee a good choice of network topology. To address these issues, we propose logic shrinkage, a fine-grained netlist pruning methodology enabling K to be automatically learned for every LUT in a neural network targeted for FPGA inference. By removing LUT inputs determined to be of low importance, our method increases the efficiency of the resultant accelerators. Our GPU-friendly solution to LUT input removal is capable of processing large topologies during their training with negligible slowdown. With logic shrinkage, we better the area and energy efficiency of the best-performing LUTNet implementation of the CNV network classifying CIFAR-10 by 1.54x and 1.31x, respectively, while matching its accuracy. This implementation also reaches 2.71x the area efficiency of an equally accurate, heavily pruned BNN. On ImageNet with the Bi-Real Net architecture, employment of logic shrinkage results in a post-synthesis area reduction of 2.67x vs LUTNet, allowing for implementation that was previously impossible on today's largest FPGAs.
High-Sensitivity Electric Potential Sensors for Non-Contact Monitoring of Physiological Signals
Oct 23, 2021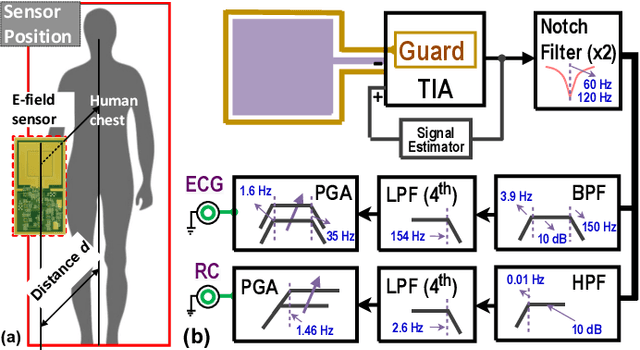
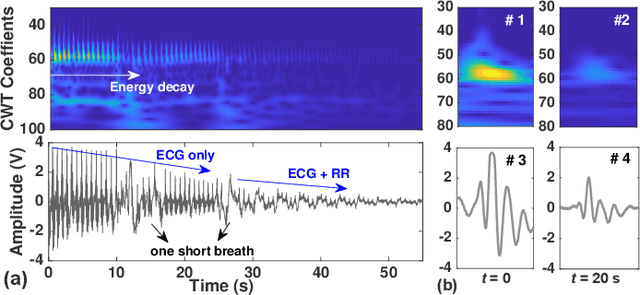
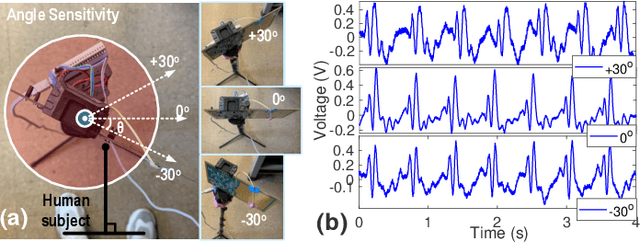
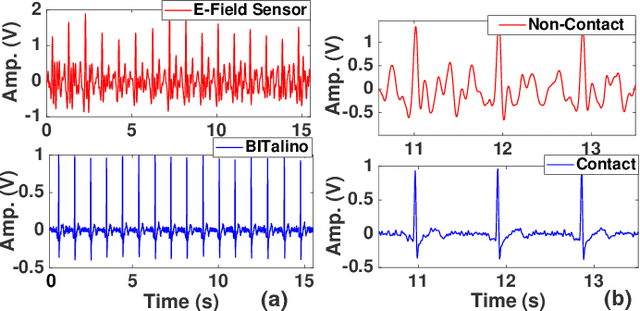
The paper describes highly-sensitive passive electric potential sensors (EPS) for non-contact detection of multiple biophysical signals, including electrocardiogram (ECG), respiration cycle (RC), and electroencephalogram (EEG). The proposed EPS uses an optimized transimpedance amplifier (TIA), a single guarded sensing electrode, and an adaptive cancellation loop (ACL) to maximize sensitivity (DC transimpedance $=150$~G$\Omega$) in the presence of power line interference (PLI) and motion artifacts. Tests were performed on healthy adult volunteers in noisy and unshielded indoor environments. Useful sensing ranges for ECG, RC, and EEG measurements, as validated against reference contact sensors, were observed to be approximately 50~cm, 100~cm, and 5~cm, respectively. ECG and RC signals were also successfully measured through wooden tables for subjects in sleep-like postures. The EPS were integrated with a wireless microcontroller to realize wireless sensor nodes capable of streaming acquired data to a remote base station in real-time.
Robust Person Re-identification with Multi-Modal Joint Defence
Nov 18, 2021
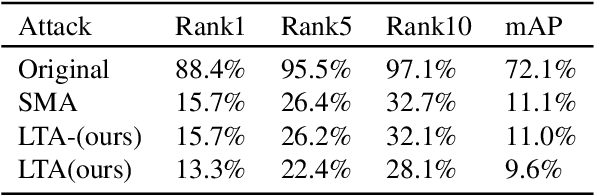
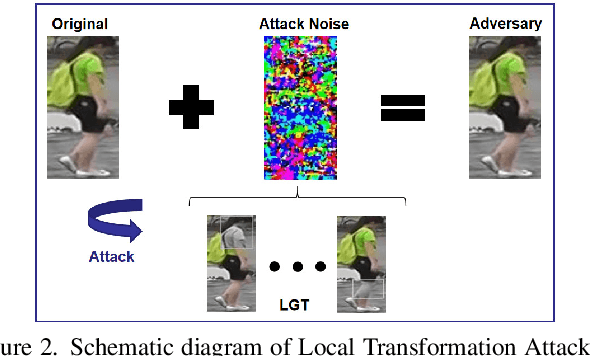
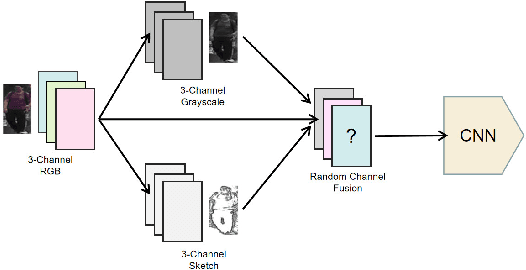
The Person Re-identification (ReID) system based on metric learning has been proved to inherit the vulnerability of deep neural networks (DNNs), which are easy to be fooled by adversarail metric attacks. Existing work mainly relies on adversarial training for metric defense, and more methods have not been fully studied. By exploring the impact of attacks on the underlying features, we propose targeted methods for metric attacks and defence methods. In terms of metric attack, we use the local color deviation to construct the intra-class variation of the input to attack color features. In terms of metric defenses, we propose a joint defense method which includes two parts of proactive defense and passive defense. Proactive defense helps to enhance the robustness of the model to color variations and the learning of structure relations across multiple modalities by constructing different inputs from multimodal images, and passive defense exploits the invariance of structural features in a changing pixel space by circuitous scaling to preserve structural features while eliminating some of the adversarial noise. Extensive experiments demonstrate that the proposed joint defense compared with the existing adversarial metric defense methods which not only against multiple attacks at the same time but also has not significantly reduced the generalization capacity of the model. The code is available at https://github.com/finger-monkey/multi-modal_joint_defence.