 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Physics Informed Neural Networks for Control Oriented Thermal Modeling of Buildings
Nov 23, 2021
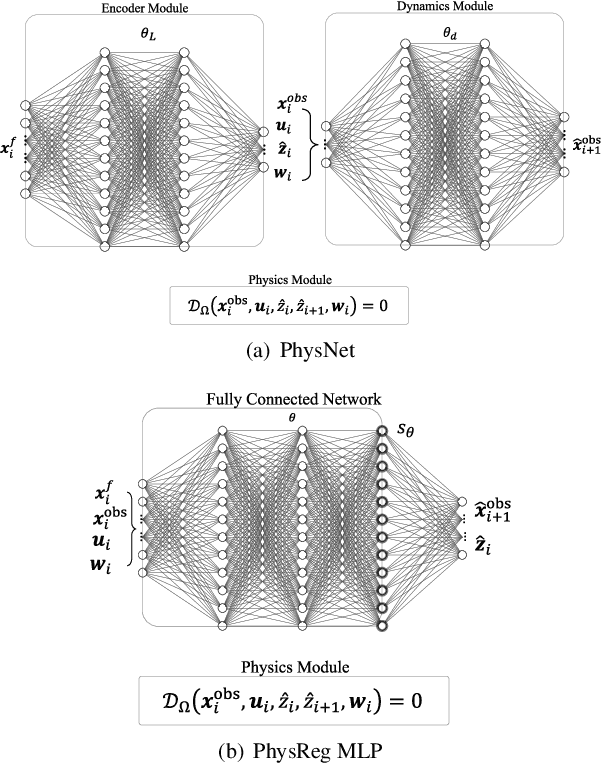
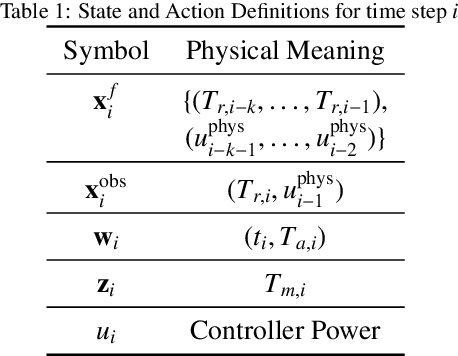
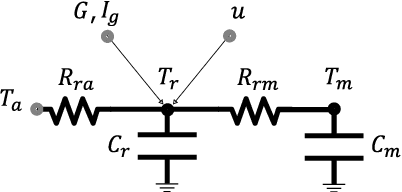
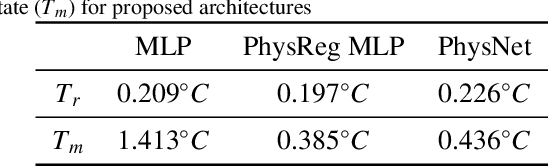
This paper presents a data-driven modeling approach for developing control-oriented thermal models of buildings. These models are developed with the objective of reducing energy consumption costs while controlling the indoor temperature of the building within required comfort limits. To combine the interpretability of white/gray box physics models and the expressive power of neural networks, we propose a physics informed neural network approach for this modeling task. Along with measured data and building parameters, we encode the neural networks with the underlying physics that governs the thermal behavior of these buildings. Thus, realizing a model that is guided by physics, aids in modeling the temporal evolution of room temperature and power consumption as well as the hidden state, i.e., the temperature of building thermal mass for subsequent time steps. The main research contributions of this work are: (1) we propose two variants of physics informed neural network architectures for the task of control-oriented thermal modeling of buildings, (2) we show that training these architectures is data-efficient, requiring less training data compared to conventional, non-physics informed neural networks, and (3) we show that these architectures achieve more accurate predictions than conventional neural networks for longer prediction horizons. We test the prediction performance of the proposed architectures using simulated and real-word data to demonstrate (2) and (3) and show that the proposed physics informed neural network architectures can be used for this control-oriented modeling problem.
Realtime Trajectory Smoothing with Neural Nets
Nov 03, 2021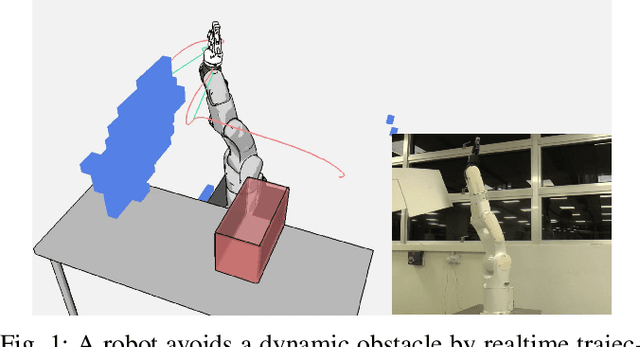
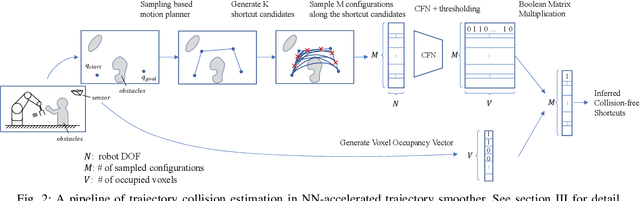
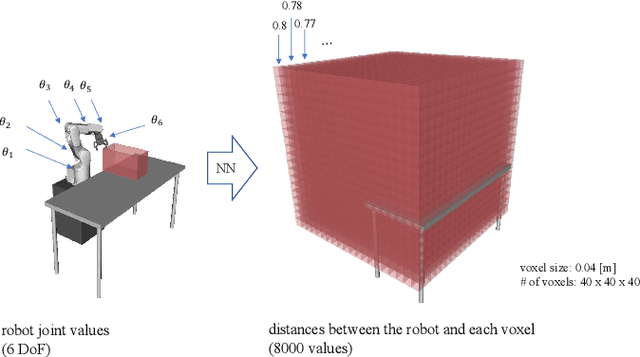
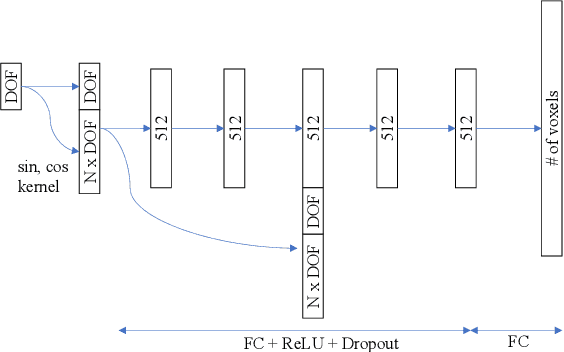
In order to safely and efficiently collaborate with humans, industrial robots need the ability to alter their motions quickly to react to sudden changes in the environment, such as an obstacle appearing across a planned trajectory. In Realtime Motion Planning, obstacles are detected in real time through a vision system, and new trajectories are planned with respect to the current positions of the obstacles, and immediately executed on the robot. Existing realtime motion planners, however, lack the smoothing post-processing step -- which are crucial in sampling-based motion planning -- resulting in the planned trajectories being jerky, and therefore inefficient and less human-friendly. Here we propose a Realtime Trajectory Smoother based on the shortcutting technique to address this issue. Leveraging fast clearance inference by a novel neural network, the proposed method is able to consistently smooth the trajectories of a 6-DOF industrial robot arm within 200 ms on a commercial GPU. We integrate the proposed smoother into a full Vision--Motion Planning--Execution loop and demonstrate a realtime, smooth, performance of an industrial robot subject to dynamic obstacles.
Transformer Based Bengali Chatbot Using General Knowledge Dataset
Nov 09, 2021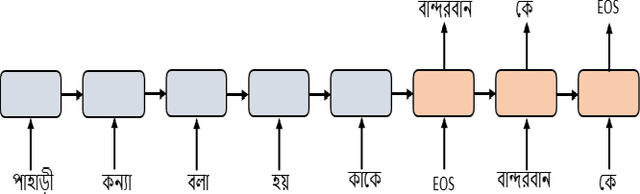
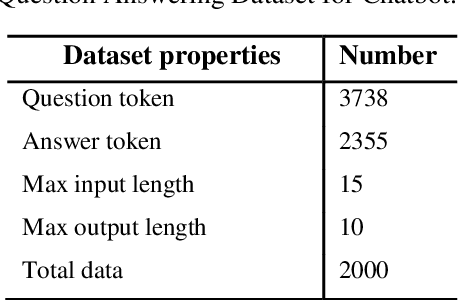
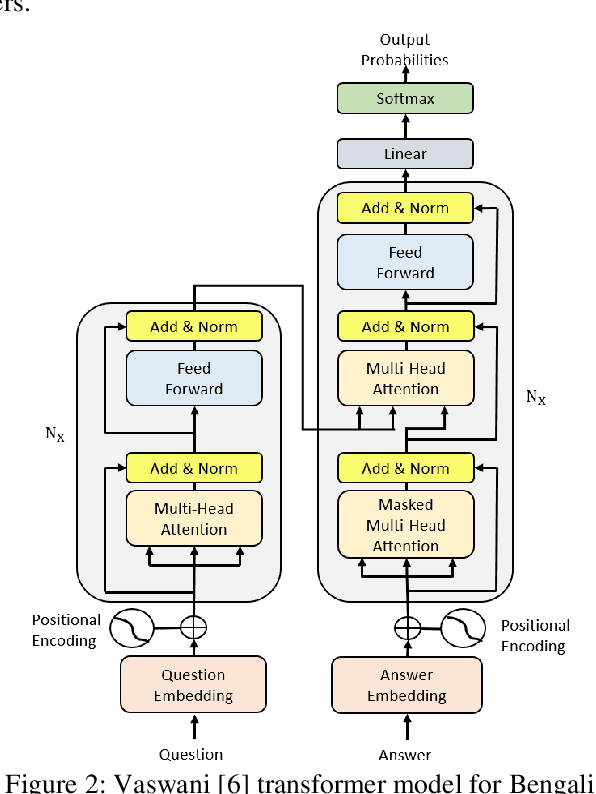
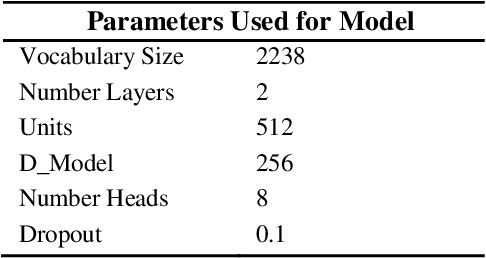
An AI chatbot provides an impressive response after learning from the trained dataset. In this decade, most of the research work demonstrates that deep neural models superior to any other model. RNN model regularly used for determining the sequence-related problem like a question and it answers. This approach acquainted with everyone as seq2seq learning. In a seq2seq model mechanism, it has encoder and decoder. The encoder embedded any input sequence, and the decoder embedded output sequence. For reinforcing the seq2seq model performance, attention mechanism added into the encoder and decoder. After that, the transformer model has introduced itself as a high-performance model with multiple attention mechanism for solving the sequence-related dilemma. This model reduces training time compared with RNN based model and also achieved state-of-the-art performance for sequence transduction. In this research, we applied the transformer model for Bengali general knowledge chatbot based on the Bengali general knowledge Question Answer (QA) dataset. It scores 85.0 BLEU on the applied QA data. To check the comparison of the transformer model performance, we trained the seq2seq model with attention on our dataset that scores 23.5 BLEU.
Online estimation and control with optimal pathlength regret
Oct 24, 2021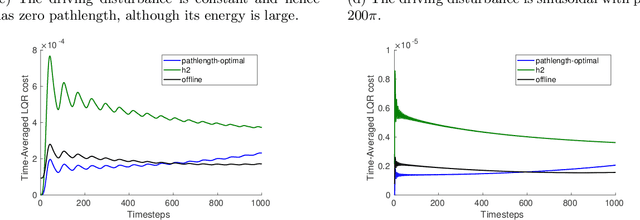
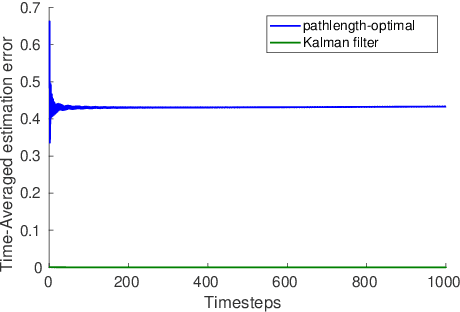
A natural goal when designing online learning algorithms for non-stationary environments is to bound the regret of the algorithm in terms of the temporal variation of the input sequence. Intuitively, when the variation is small, it should be easier for the algorithm to achieve low regret, since past observations are predictive of future inputs. Such data-dependent "pathlength" regret bounds have recently been obtained for a wide variety of online learning problems, including OCO and bandits. We obtain the first pathlength regret bounds for online control and estimation (e.g. Kalman filtering) in linear dynamical systems. The key idea in our derivation is to reduce pathlength-optimal filtering and control to certain variational problems in robust estimation and control; these reductions may be of independent interest. Numerical simulations confirm that our pathlength-optimal algorithms outperform traditional $H_2$ and $H_{\infty}$ algorithms when the environment varies over time.
Unified Sample-Optimal Property Estimation in Near-Linear Time
Nov 08, 2019
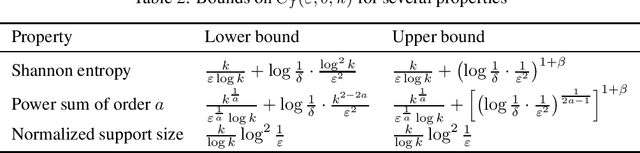
We consider the fundamental learning problem of estimating properties of distributions over large domains. Using a novel piecewise-polynomial approximation technique, we derive the first unified methodology for constructing sample- and time-efficient estimators for all sufficiently smooth, symmetric and non-symmetric, additive properties. This technique yields near-linear-time computable estimators whose approximation values are asymptotically optimal and highly-concentrated, resulting in the first: 1) estimators achieving the $\mathcal{O}(k/(\varepsilon^2\log k))$ min-max $\varepsilon$-error sample complexity for all $k$-symbol Lipschitz properties; 2) unified near-optimal differentially private estimators for a variety of properties; 3) unified estimator achieving optimal bias and near-optimal variance for five important properties; 4) near-optimal sample-complexity estimators for several important symmetric properties over both domain sizes and confidence levels. In addition, we establish a McDiarmid's inequality under Poisson sampling, which is of independent interest.
GEOSCAN: Global Earth Observation using Swarm of Coordinated Autonomous Nanosats
Nov 27, 2021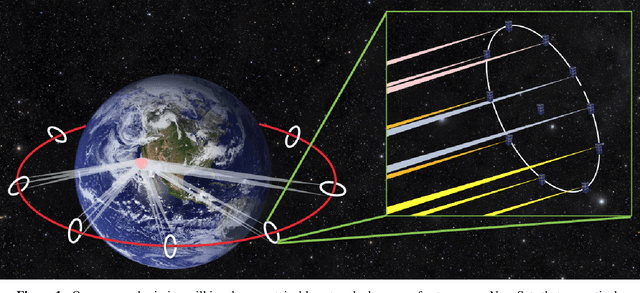
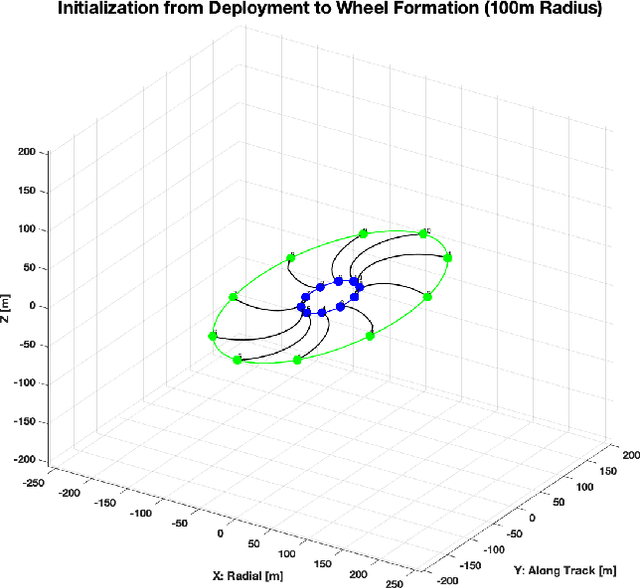
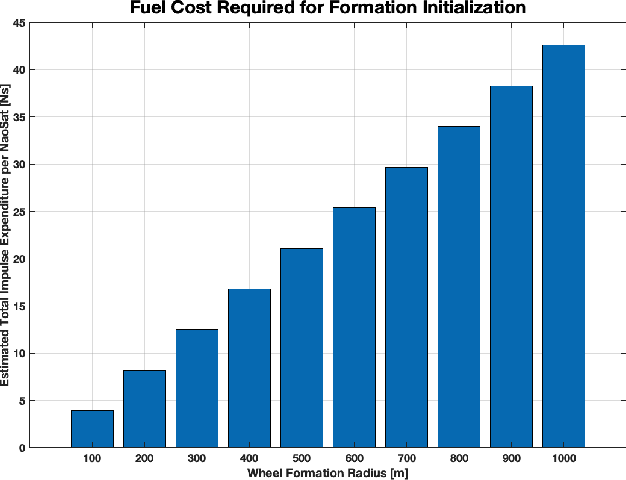
The climate crisis we are facing calls for significant improvements in our understanding of natural phenomena, with clouds being identified as a dominant source of uncertainty. To this end, the emerging field of 3D computed cloud tomography (CCT) aims to more precisely characterize clouds by utilizing multi-dimensional imaging to reconstruct their outer and inner structure. In this paper, we propose a future Earth observation mission concept, driven by the needs of CCT, that operates constellation of NanoSats to provide multi-angular, spectrally-resolved, spatial and temporal scientific measurements of natural atmospheric phenomena. Our proposed mission, GEOSCAN, will on-board active steering capability to rapidly reconfigure networked swarm of autonomous Nanosats to track evolving phenomena of interest, on-demand, in real-time. We present the structure of the GEOSCAN constellation and discuss details of the mission concept from both science and engineering perspectives. On the science side, we outline the types of remote Earth observation measurements that GEOSCAN enables beyond the state-of-the-art, and how such measurements translate to improvements in CCT that can lead to reduction in uncertainty of the global climate models (GCMs). From the engineering side, we investigate feasibility of the concept starting from hardware components of the NanoSat that form the basis of the constellation. In particular, we focus on the active steering capability of the GEOSCAN with algorithmic approaches that enable coordination from new software. We identify technology gaps that need to be bridged and discuss other aspects of the mission that require in-depth analysis to further mature the concept.
Finite-time Identification of Stable Linear Systems: Optimality of the Least-Squares Estimator
Mar 17, 2020We provide a new finite-time analysis of the estimation error of stable linear time-invariant systems under the Ordinary Least Squares (OLS) estimator. Specifically, we characterize the sufficient number of observed samples (the length of the observed trajectory) so that the OLS is $(\varepsilon,\delta)$-PAC, i.e. yields an estimation error less than $\varepsilon$ with probability at least $1-\delta$. We show that this number matches existing sample complexity lower bound [1,2] up to universal multiplicative factors (independent of ($\varepsilon,\delta)$, of the system and of the dimension). This paper hence establishes the optimality of the OLS estimator for stable systems, a result conjectured in [1]. Our analysis of the performance of the OLS estimator is simpler, sharper, and easier to interpret than existing analyses, but is restricted to stable systems. It relies on new concentration results for the covariates matrix.
Joint AEC AND Beamforming with Double-Talk Detection using RNN-Transformer
Nov 09, 2021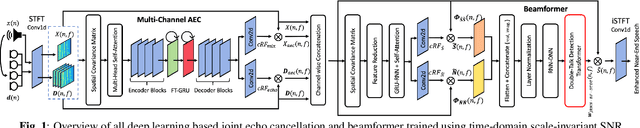
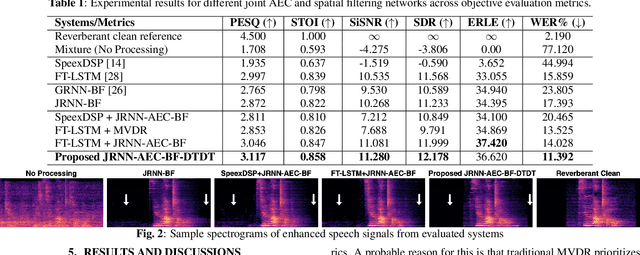
Acoustic echo cancellation (AEC) is a technique used in full-duplex communication systems to eliminate acoustic feedback of far-end speech. However, their performance degrades in naturalistic environments due to nonlinear distortions introduced by the speaker, as well as background noise, reverberation, and double-talk scenarios. To address nonlinear distortions and co-existing background noise, several deep neural network (DNN)-based joint AEC and denoising systems were developed. These systems are based on either purely "black-box" neural networks or "hybrid" systems that combine traditional AEC algorithms with neural networks. We propose an all-deep-learning framework that combines multi-channel AEC and our recently proposed self-attentive recurrent neural network (RNN) beamformer. We propose an all-deep-learning framework that combines multi-channel AEC and our recently proposed self-attentive recurrent neural network (RNN) beamformer. Furthermore, we propose a double-talk detection transformer (DTDT) module based on the multi-head attention transformer structure that computes attention over time by leveraging frame-wise double-talk predictions. Experiments show that our proposed method outperforms other approaches in terms of improving speech quality and speech recognition rate of an ASR system.
On-line Optimal Ranging Sensor Deployment for Robotic Exploration
Oct 17, 2021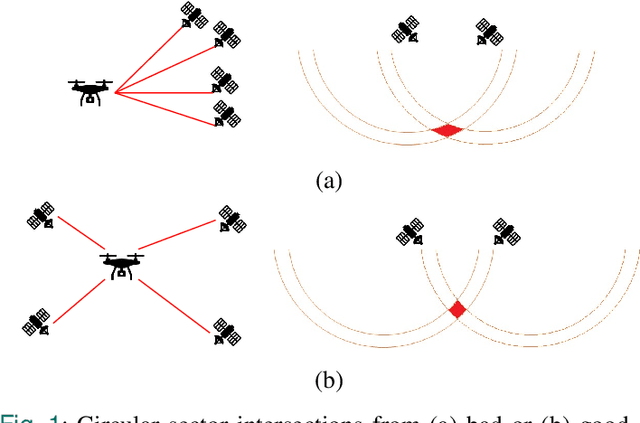
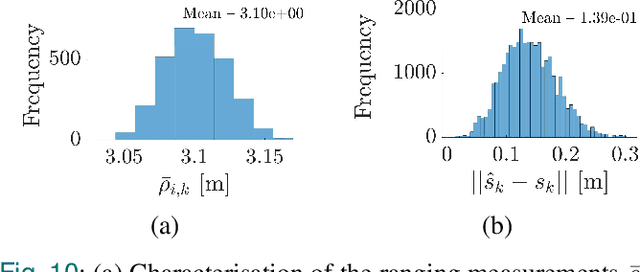
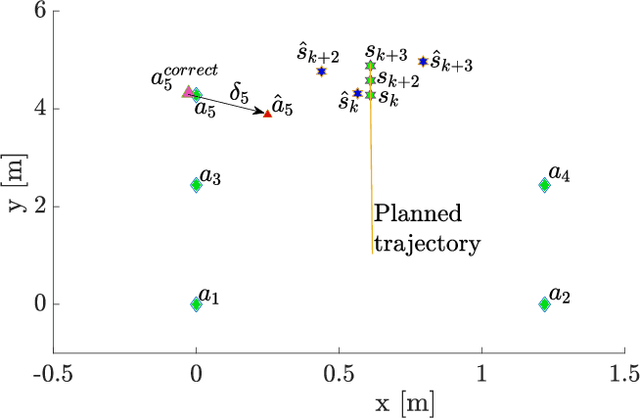
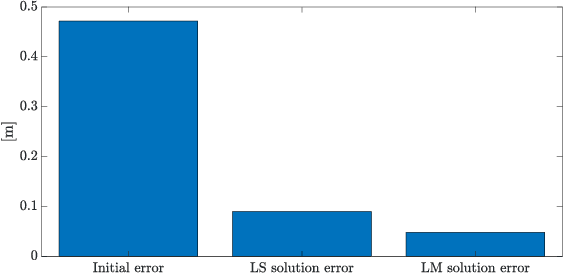
Navigation in an unknown environment without any preexisting positioning infrastructure has always been hard for mobile robots. This paper presents a self-deployable ultra wideband UWB infrastructure by mobile agents, that permits a dynamic placement and runtime extension of UWB anchors infrastructure while the robot explores the new environment. We provide a detailed analysis of the uncertainty of the positioning system while the UWB infrastructure grows. Moreover, we developed a genetic algorithm that minimizes the deployment of new anchors, saving energy and resources on the mobile robot and maximizing the time of the mission. Although the presented approach is general for any class of mobile system, we run simulations and experiments with indoor drones. Results demonstrate that maximum positioning uncertainty is always controlled under the user's threshold, using the Geometric Dilution of Precision (GDoP).
AEGIS: A real-time multimodal augmented reality computer vision based system to assist facial expression recognition for individuals with autism spectrum disorder
Oct 22, 2020The ability to interpret social cues comes naturally for most people, but for those living with Autism Spectrum Disorder (ASD), some experience a deficiency in this area. This paper presents the development of a multimodal augmented reality (AR) system which combines the use of computer vision and deep convolutional neural networks (CNN) in order to assist individuals with the detection and interpretation of facial expressions in social settings. The proposed system, which we call AEGIS (Augmented-reality Expression Guided Interpretation System), is an assistive technology deployable on a variety of user devices including tablets, smartphones, video conference systems, or smartglasses, showcasing its extreme flexibility and wide range of use cases, to allow integration into daily life with ease. Given a streaming video camera source, each real-world frame is passed into AEGIS, processed for facial bounding boxes, and then fed into our novel deep convolutional time windowed neural network (TimeConvNet). We leverage both spatial and temporal information in order to provide an accurate expression prediction, which is then converted into its corresponding visualization and drawn on top of the original video frame. The system runs in real-time, requires minimal set up and is simple to use. With the use of AEGIS, we can assist individuals living with ASD to learn to better identify expressions and thus improve their social experiences.