 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Learning-Based Power Control for Uplink Cell-Free Massive MIMO Systems
Oct 18, 2021
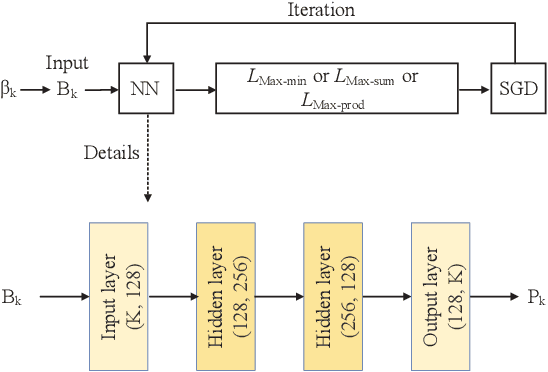
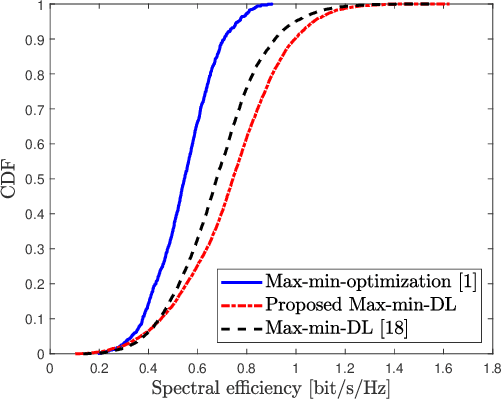
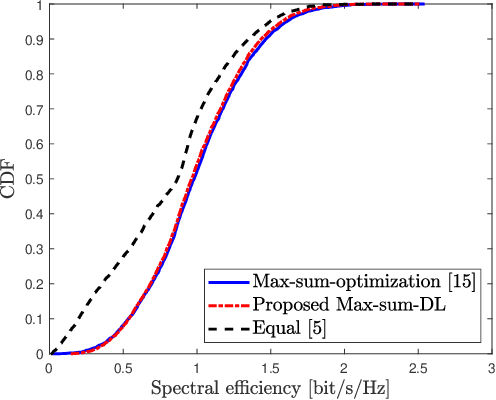
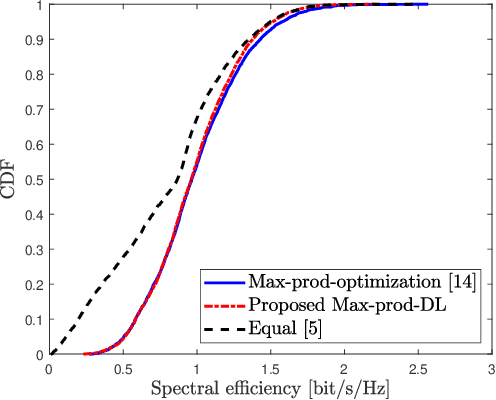
In this paper, a general framework for deep learning-based power control methods for max-min, max-product and max-sum-rate optimization in uplink cell-free massive multiple-input multiple-output (CF mMIMO) systems is proposed. Instead of using supervised learning, the proposed method relies on unsupervised learning, in which optimal power allocations are not required to be known, and thus has low training complexity. More specifically, a deep neural network (DNN) is trained to learn the map between fading coefficients and power coefficients within short time and with low computational complexity. It is interesting to note that the spectral efficiency of CF mMIMO systems with the proposed method outperforms previous optimization methods for max-min optimization and fits well for both max-sum-rate and max-product optimizations.
Follow the Gradient: Crossing the Reality Gap using Differentiable Physics (RealityGrad)
Sep 10, 2021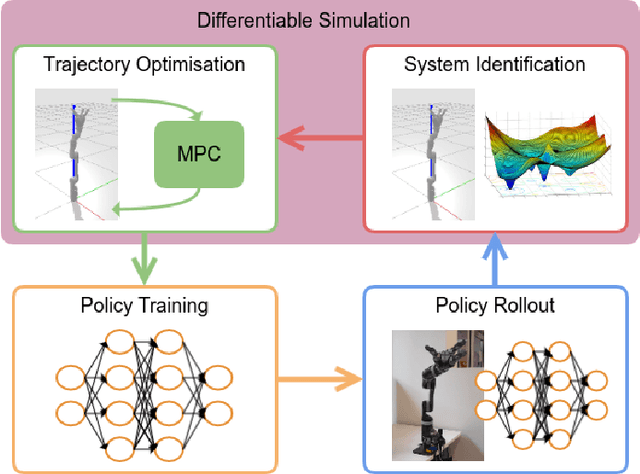

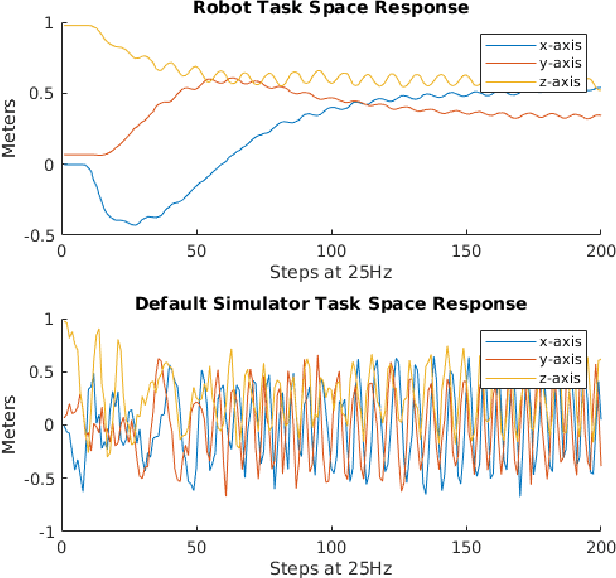
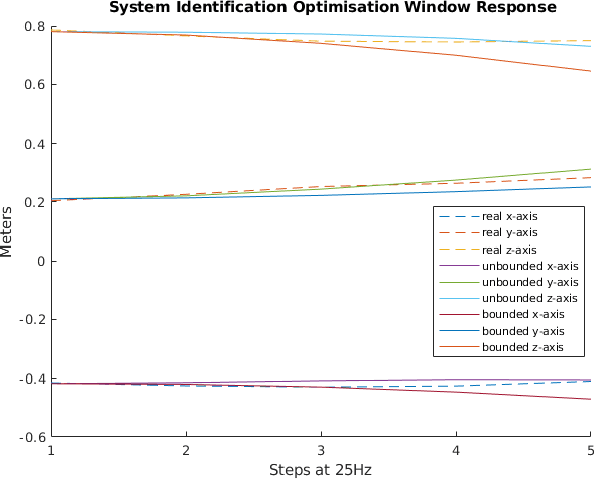
We propose a novel iterative approach for crossing the reality gap that utilises live robot rollouts and differentiable physics. Our method, RealityGrad, demonstrates for the first time, an efficient sim2real transfer in combination with a real2sim model optimisation for closing the reality gap. Differentiable physics has become an alluring alternative to classical rigid-body simulation due to the current culmination of automatic differentiation libraries, compute and non-linear optimisation libraries. Our method builds on this progress and employs differentiable physics for efficient trajectory optimisation. We demonstrate RealitGrad on a dynamic control task for a serial link robot manipulator and present results that show its efficiency and ability to quickly improve not just the robot's performance in real world tasks but also enhance the simulation model for future tasks. One iteration of RealityGrad takes less than 22 minutes on a desktop computer while reducing the error by 2/3, making it efficient compared to other sim2real methods in both compute and time. Our methodology and application of differentiable physics establishes a promising approach for crossing the reality gap and has great potential for scaling to complex environments.
Cross-Batch Negative Sampling for Training Two-Tower Recommenders
Oct 28, 2021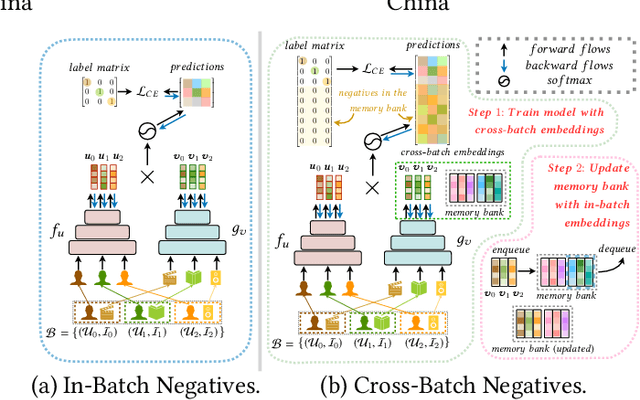
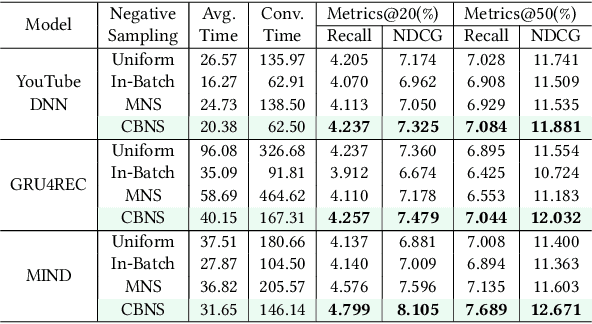
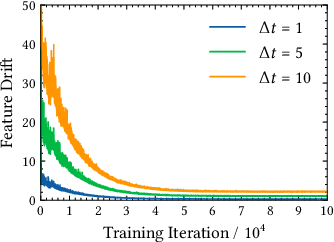
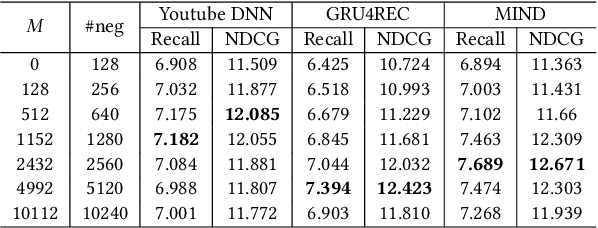
The two-tower architecture has been widely applied for learning item and user representations, which is important for large-scale recommender systems. Many two-tower models are trained using various in-batch negative sampling strategies, where the effects of such strategies inherently rely on the size of mini-batches. However, training two-tower models with a large batch size is inefficient, as it demands a large volume of memory for item and user contents and consumes a lot of time for feature encoding. Interestingly, we find that neural encoders can output relatively stable features for the same input after warming up in the training process. Based on such facts, we propose a simple yet effective sampling strategy called Cross-Batch Negative Sampling (CBNS), which takes advantage of the encoded item embeddings from recent mini-batches to boost the model training. Both theoretical analysis and empirical evaluations demonstrate the effectiveness and the efficiency of CBNS.
Low-Complexity Algorithm for Outage Optimal Resource Allocation in Energy Harvesting-Based UAV Identification Networks
Aug 18, 2021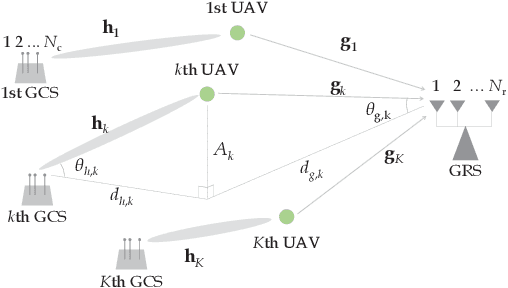
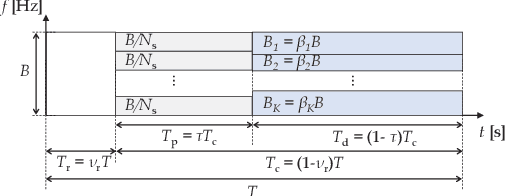
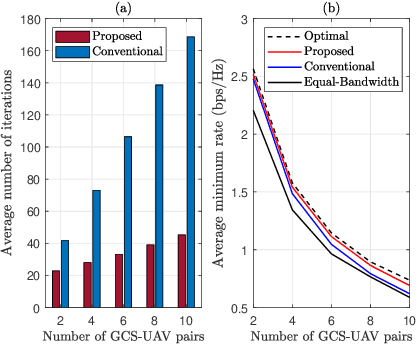
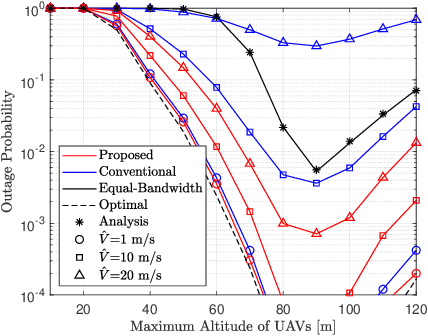
We study an unmanned aerial vehicle (UAV) identification network equipped with an energy harvesting (EH) technique. In the network, the UAVs harvest energy through radio frequency (RF) signals transmitted from ground control stations (GCSs) and then transmit their identification information to the ground receiver station (GRS). Specifically, we first derive a closed-form expression of the outage probability to evaluate the network performance. Then we obtain the closed-form expression of the optimal time allocation when the bandwidth is equally allocated to the UAVs. We also propose a fast-converging algorithm for time and the bandwidth allocation, which is necessary for the UAV environment with high mobility, to optimize the outage performance of EH-based UAV identification network. Simulation results show that the proposed algorithm outperforms the conventional bisection algorithm and achieves near-optimal performance.
FAST: Searching for a Faster Arbitrarily-Shaped Text Detector with Minimalist Kernel Representation
Nov 03, 2021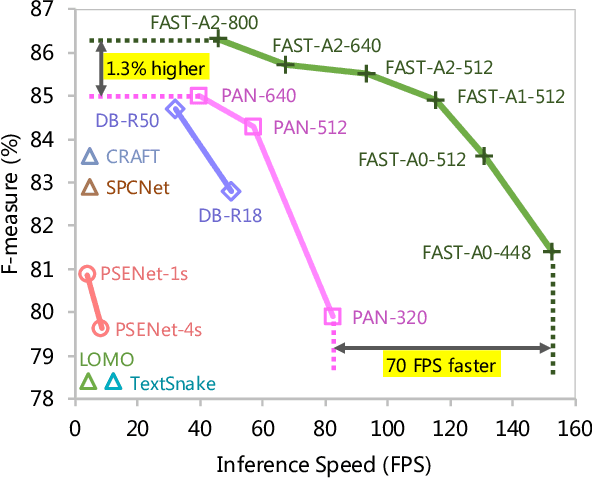
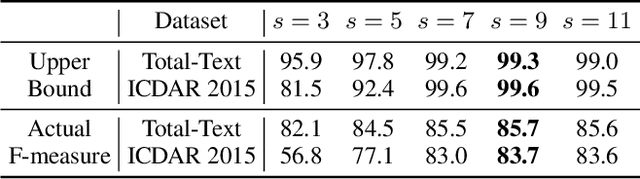
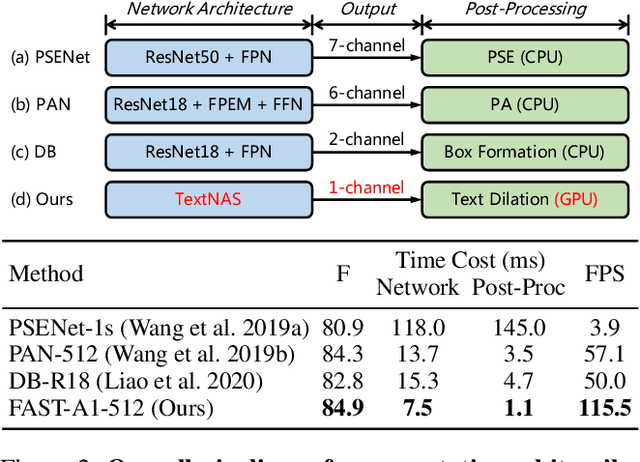
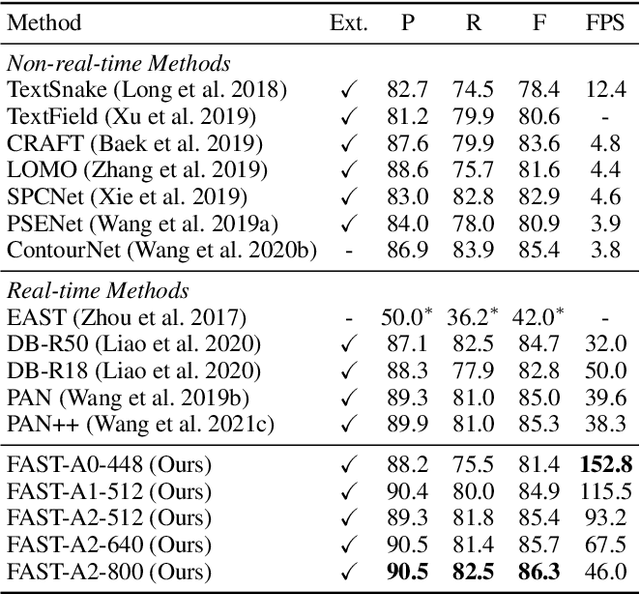
We propose an accurate and efficient scene text detection framework, termed FAST (i.e., faster arbitrarily-shaped text detector). Different from recent advanced text detectors that used hand-crafted network architectures and complicated post-processing, resulting in low inference speed, FAST has two new designs. (1) We search the network architecture by designing a network search space and reward function carefully tailored for text detection, leading to more powerful features than most networks that are searched for image classification. (2) We design a minimalist representation (only has 1-channel output) to model text with arbitrary shape, as well as a GPU-parallel post-processing to efficiently assemble text lines with negligible time overhead. Benefiting from these two designs, FAST achieves an excellent trade-off between accuracy and efficiency on several challenging datasets. For example, FAST-A0 yields 81.4% F-measure at 152 FPS on Total-Text, outperforming the previous fastest method by 1.5 points and 70 FPS in terms of accuracy and speed. With TensorRT optimization, the inference speed can be further accelerated to over 600 FPS.
Turn-to-Diarize: Online Speaker Diarization Constrained by Transformer Transducer Speaker Turn Detection
Oct 05, 2021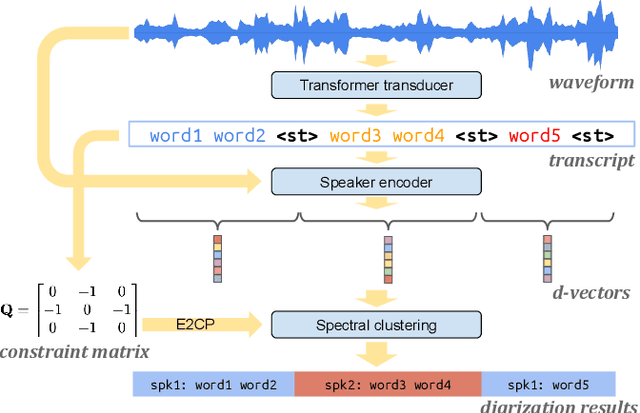

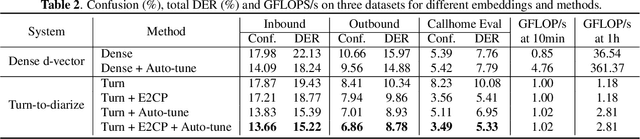
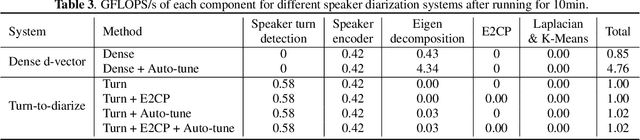
In this paper, we present a novel speaker diarization system for streaming on-device applications. In this system, we use a transformer transducer to detect the speaker turns, represent each speaker turn by a speaker embedding, then cluster these embeddings with constraints from the detected speaker turns. Compared with conventional clustering-based diarization systems, our system largely reduces the computational cost of clustering due to the sparsity of speaker turns. Unlike other supervised speaker diarization systems which require annotations of time-stamped speaker labels for training, our system only requires including speaker turn tokens during the transcribing process, which largely reduces the human efforts involved in data collection.
Community detection in sparse time-evolving graphs with a dynamical Bethe-Hessian
Jun 03, 2020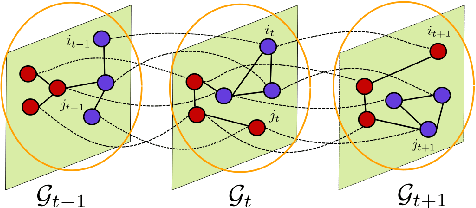

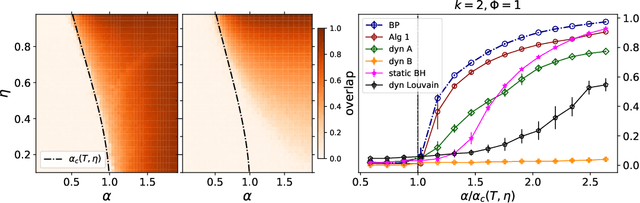
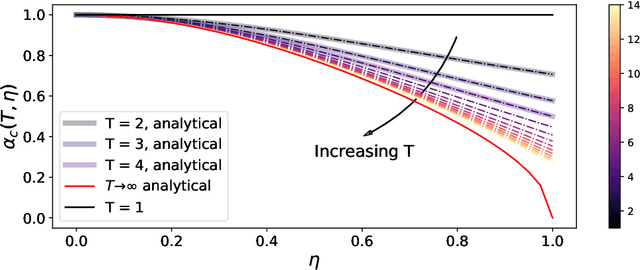
This article considers the problem of community detection in sparse dynamical graphs in which the community structure evolves over time. A fast spectral algorithm based on an extension of the Bethe-Hessian matrix is proposed, which benefits from the positive correlation in the class labels and in their temporal evolution and is designed to be applicable to any dynamical graph with a community structure. Under the dynamical degree-corrected stochastic block model, in the case of two classes of equal size, we demonstrate and support with extensive simulations that our proposed algorithm is capable of making non-trivial community reconstruction as soon as theoretically possible, thereby reaching the optimal detectability thresholdand provably outperforming competing spectral methods.
Neural Human Performer: Learning Generalizable Radiance Fields for Human Performance Rendering
Sep 15, 2021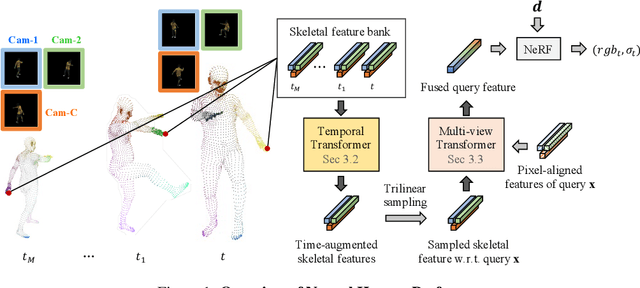
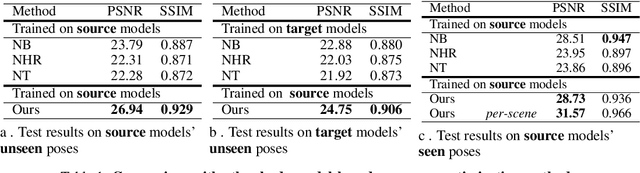


In this paper, we aim at synthesizing a free-viewpoint video of an arbitrary human performance using sparse multi-view cameras. Recently, several works have addressed this problem by learning person-specific neural radiance fields (NeRF) to capture the appearance of a particular human. In parallel, some work proposed to use pixel-aligned features to generalize radiance fields to arbitrary new scenes and objects. Adopting such generalization approaches to humans, however, is highly challenging due to the heavy occlusions and dynamic articulations of body parts. To tackle this, we propose Neural Human Performer, a novel approach that learns generalizable neural radiance fields based on a parametric human body model for robust performance capture. Specifically, we first introduce a temporal transformer that aggregates tracked visual features based on the skeletal body motion over time. Moreover, a multi-view transformer is proposed to perform cross-attention between the temporally-fused features and the pixel-aligned features at each time step to integrate observations on the fly from multiple views. Experiments on the ZJU-MoCap and AIST datasets show that our method significantly outperforms recent generalizable NeRF methods on unseen identities and poses. The video results and code are available at https://youngjoongunc.github.io/nhp.
Common Information based Approximate State Representations in Multi-Agent Reinforcement Learning
Oct 25, 2021Due to information asymmetry, finding optimal policies for Decentralized Partially Observable Markov Decision Processes (Dec-POMDPs) is hard with the complexity growing doubly exponentially in the horizon length. The challenge increases greatly in the multi-agent reinforcement learning (MARL) setting where the transition probabilities, observation kernel, and reward function are unknown. Here, we develop a general compression framework with approximate common and private state representations, based on which decentralized policies can be constructed. We derive the optimality gap of executing dynamic programming (DP) with the approximate states in terms of the approximation error parameters and the remaining time steps. When the compression is exact (no error), the resulting DP is equivalent to the one in existing work. Our general framework generalizes a number of methods proposed in the literature. The results shed light on designing practically useful deep-MARL network structures under the "centralized learning distributed execution" scheme.
Analysis of Sectoral Profitability of the Indian Stock Market Using an LSTM Regression Model
Nov 09, 2021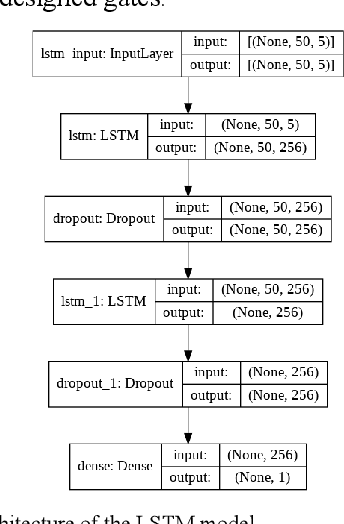
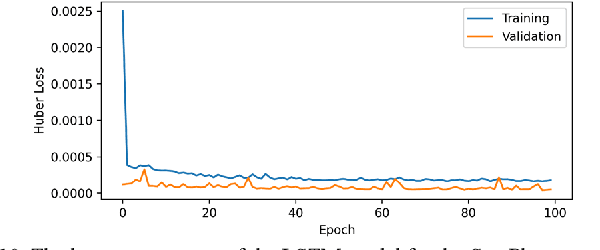
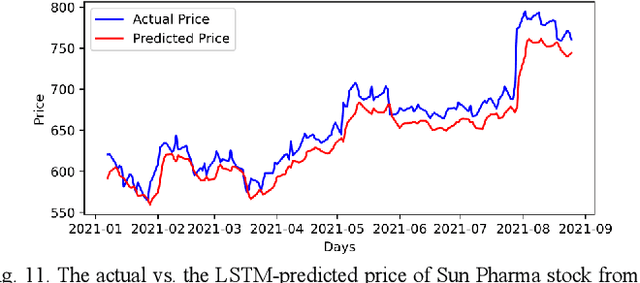
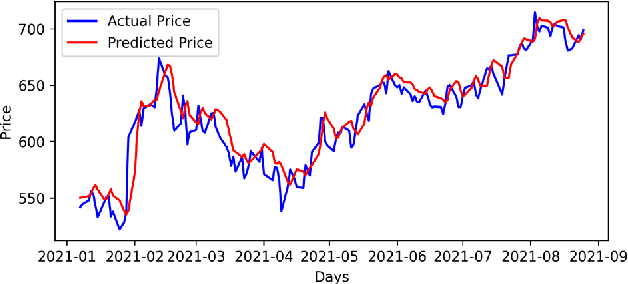
Predictive model design for accurately predicting future stock prices has always been considered an interesting and challenging research problem. The task becomes complex due to the volatile and stochastic nature of the stock prices in the real world which is affected by numerous controllable and uncontrollable variables. This paper presents an optimized predictive model built on long-and-short-term memory (LSTM) architecture for automatically extracting past stock prices from the web over a specified time interval and predicting their future prices for a specified forecast horizon, and forecasts the future stock prices. The model is deployed for making buy and sell transactions based on its predicted results for 70 important stocks from seven different sectors listed in the National Stock Exchange (NSE) of India. The profitability of each sector is derived based on the total profit yielded by the stocks in that sector over a period from Jan 1, 2010 to Aug 26, 2021. The sectors are compared based on their profitability values. The prediction accuracy of the model is also evaluated for each sector. The results indicate that the model is highly accurate in predicting future stock prices.