 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Parallel Logic Programming: A Sequel
Nov 22, 2021
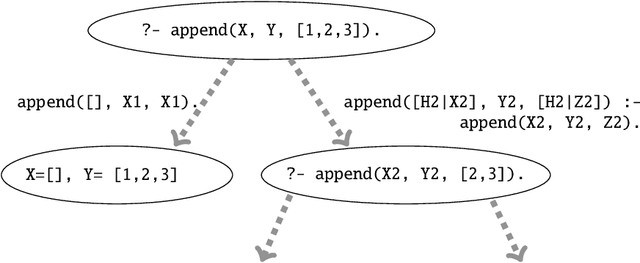
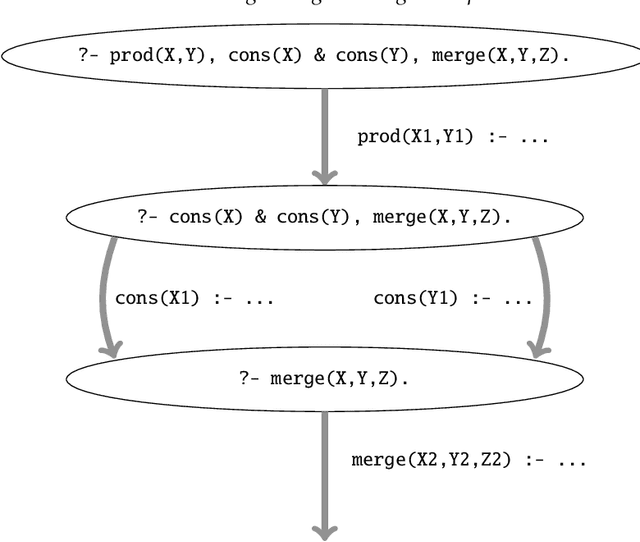
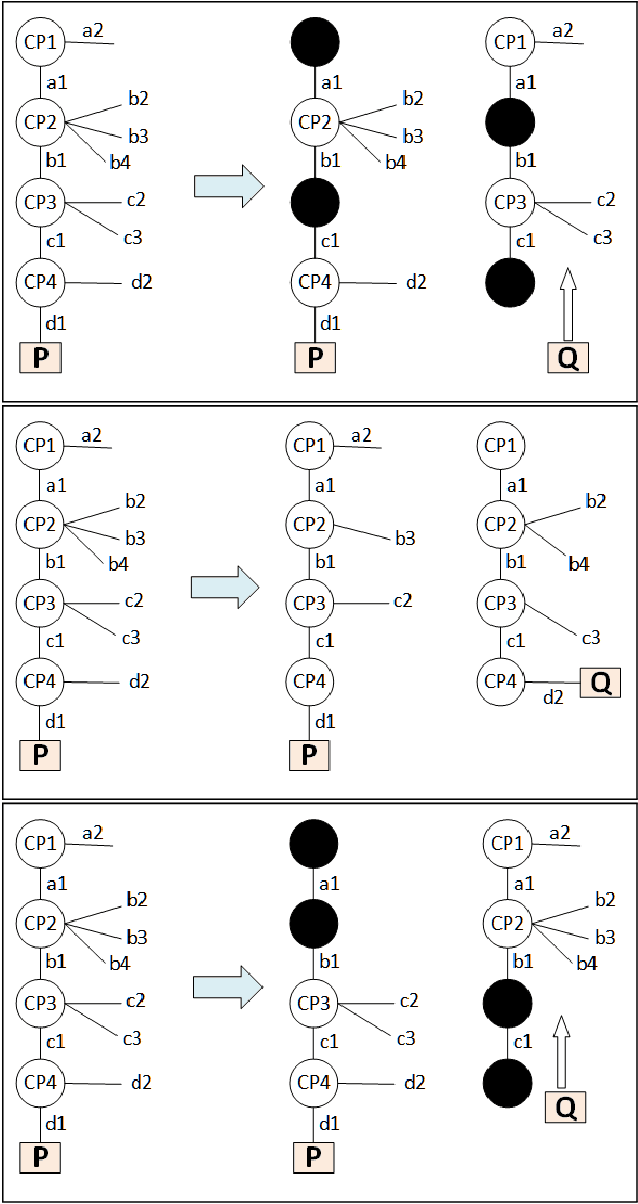
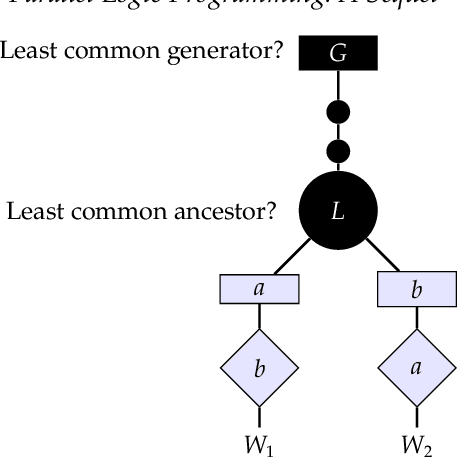
Multi-core and highly-connected architectures have become ubiquitous, and this has brought renewed interest in language-based approaches to the exploitation of parallelism. Since its inception, logic programming has been recognized as a programming paradigm with great potential for automated exploitation of parallelism. The comprehensive survey of the first twenty years of research in parallel logic programming, published in 2001, has served since as a fundamental reference to researchers and developers. The contents are quite valid today, but at the same time the field has continued evolving at a fast pace in the years that have followed. Many of these achievements and ongoing research have been driven by the rapid pace of technological innovation, that has led to advances such as very large clusters, the wide diffusion of multi-core processors, the game-changing role of general-purpose graphic processing units, and the ubiquitous adoption of cloud computing. This has been paralleled by significant advances within logic programming, such as tabling, more powerful static analysis and verification, the rapid growth of Answer Set Programming, and in general, more mature implementations and systems. This survey provides a review of the research in parallel logic programming covering the period since 2001, thus providing a natural continuation of the previous survey. The goal of the survey is to serve not only as a reference for researchers and developers of logic programming systems, but also as engaging reading for anyone interested in logic and as a useful source for researchers in parallel systems outside logic programming. Under consideration in Theory and Practice of Logic Programming (TPLP).
Highly Scalable and Provably Accurate Classification in Poincare Balls
Sep 15, 2021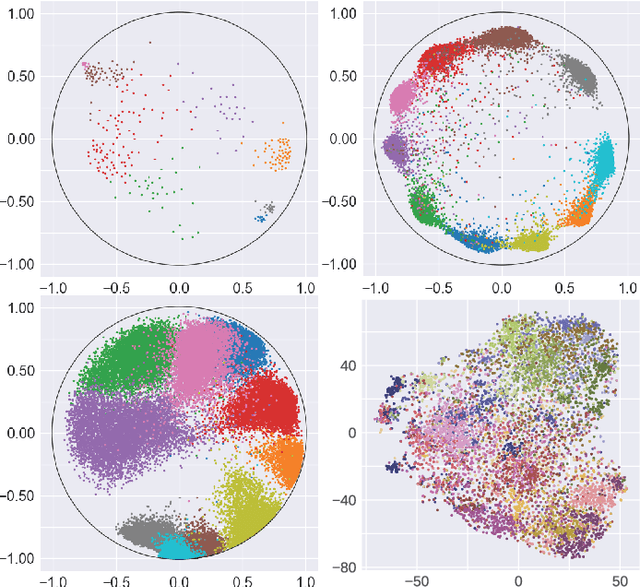
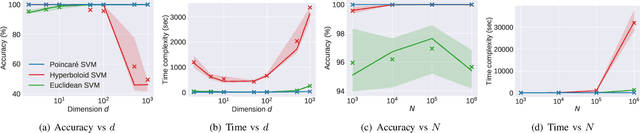
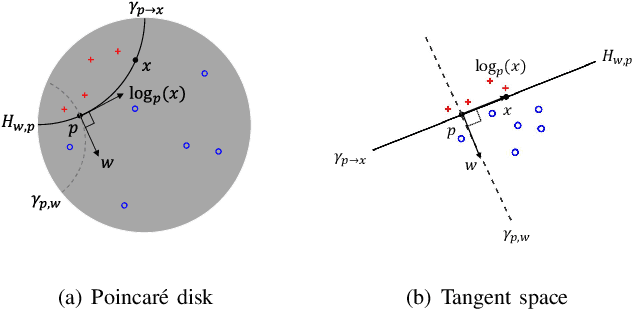
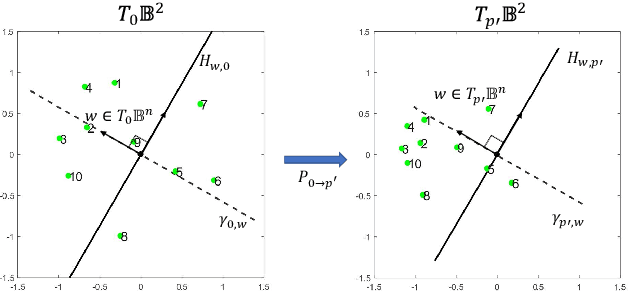
Many high-dimensional and large-volume data sets of practical relevance have hierarchical structures induced by trees, graphs or time series. Such data sets are hard to process in Euclidean spaces and one often seeks low-dimensional embeddings in other space forms to perform required learning tasks. For hierarchical data, the space of choice is a hyperbolic space since it guarantees low-distortion embeddings for tree-like structures. Unfortunately, the geometry of hyperbolic spaces has properties not encountered in Euclidean spaces that pose challenges when trying to rigorously analyze algorithmic solutions. Here, for the first time, we establish a unified framework for learning scalable and simple hyperbolic linear classifiers with provable performance guarantees. The gist of our approach is to focus on Poincar\'e ball models and formulate the classification problems using tangent space formalisms. Our results include a new hyperbolic and second-order perceptron algorithm as well as an efficient and highly accurate convex optimization setup for hyperbolic support vector machine classifiers. All algorithms provably converge and are highly scalable as they have complexities comparable to those of their Euclidean counterparts. Their performance accuracies on synthetic data sets comprising millions of points, as well as on complex real-world data sets such as single-cell RNA-seq expression measurements, CIFAR10, Fashion-MNIST and mini-ImageNet.
AI-Powered Semantic Segmentation and Fluid Volume Calculation of Lung CT images in Covid-19 Patients
Oct 29, 2021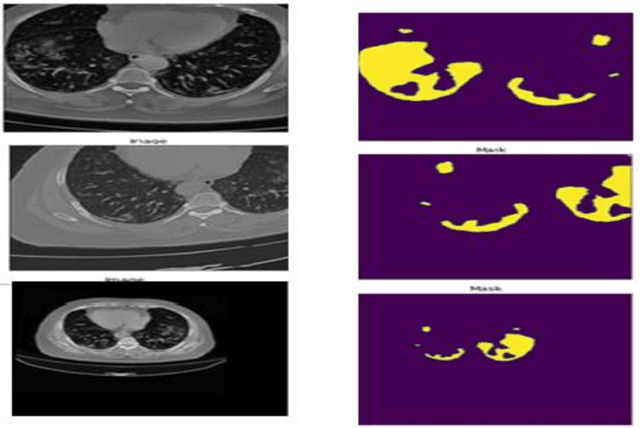
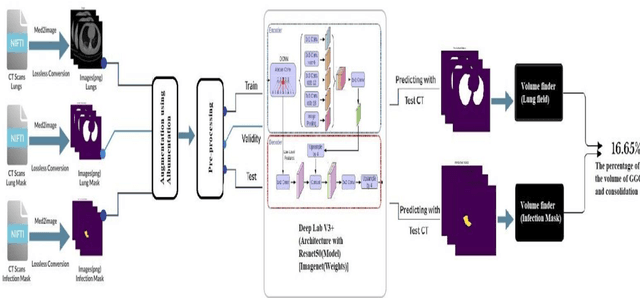
COVID-19 pandemic is a deadly disease spreading very fast. People with the confronted immune system are susceptible to many health conditions. A highly significant condition is pneumonia, which is found to be the cause of death in the majority of patients. The main purpose of this study is to find the volume of GGO and consolidation of a covid-19 patient so that the physicians can prioritize the patients. Here we used transfer learning techniques for segmentation of lung CTs with the latest libraries and techniques which reduces training time and increases the accuracy of the AI Model. This system is trained with DeepLabV3+ network architecture and model Resnet50 with Imagenet weights. We used different augmentation techniques like Gaussian Noise, Horizontal shift, color variation, etc to get to the result. Intersection over Union(IoU) is used as the performance metrics. The IoU of lung masks is predicted as 99.78% and that of infected masks is as 89.01%. Our work effectively measures the volume of infected region by calculating the volume of infected and lung mask region of the patients.
Coupled Oscillatory Recurrent Neural Network (coRNN): An accurate and (gradient) stable architecture for learning long time dependencies
Oct 02, 2020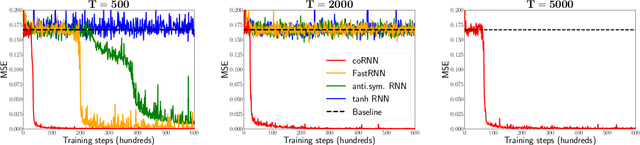
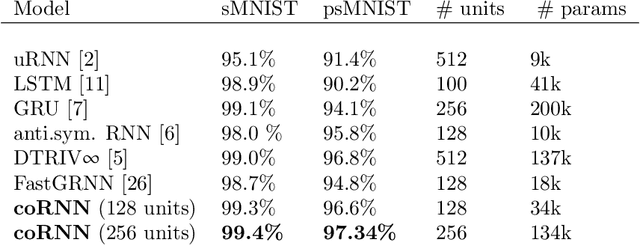
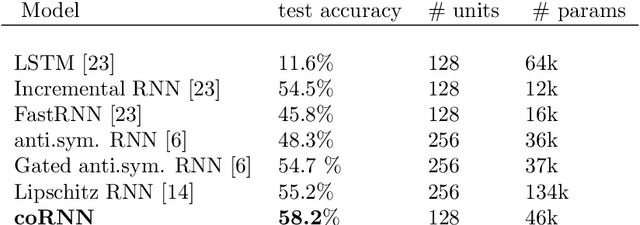
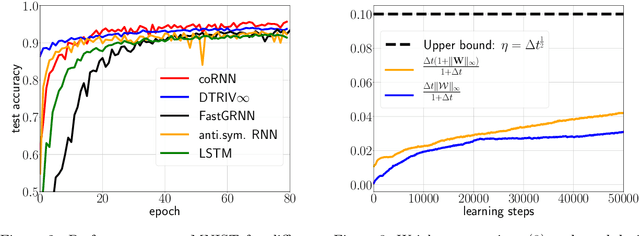
Circuits of biological neurons, such as in the functional parts of the brain can be modeled as networks of coupled oscillators. Inspired by the ability of these systems to express a rich set of outputs while keeping (gradients of) state variables bounded, we propose a novel architecture for recurrent neural networks. Our proposed RNN is based on a time-discretization of a system of second-order ordinary differential equations, modeling networks of controlled nonlinear oscillators. We prove precise bounds on the gradients of the hidden states, leading to the mitigation of the exploding and vanishing gradient problem for this RNN. Experiments show that the proposed RNN is comparable in performance to the state of the art on a variety of benchmarks, demonstrating the potential of this architecture to provide stable and accurate RNNs for processing complex sequential data.
Spatial-Separated Curve Rendering Network for Efficient and High-Resolution Image Harmonization
Sep 20, 2021
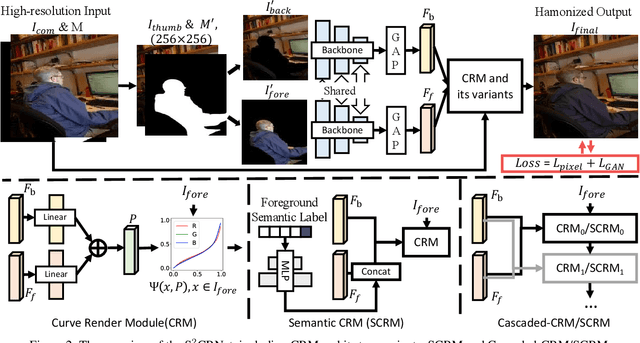

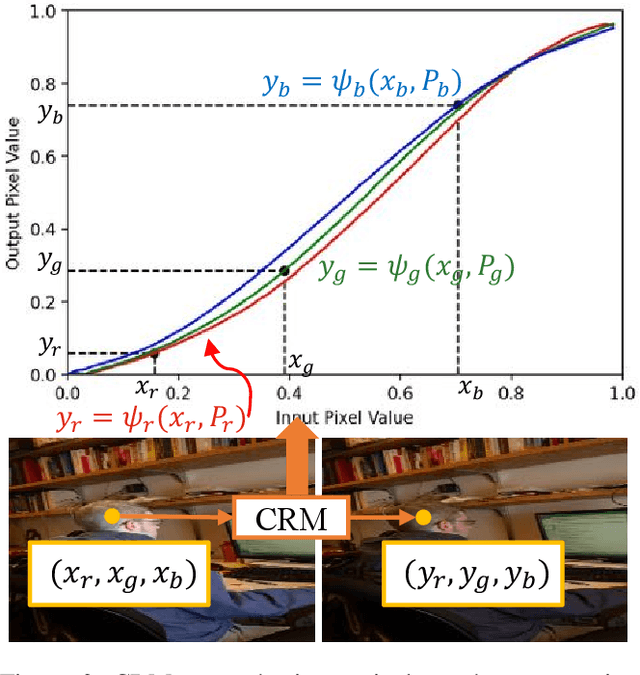
Image harmonization aims to modify the color of the composited region with respect to the specific background. Previous works model this task as a pixel-wise image-to-image translation using UNet family structures. However, the model size and computational cost limit the performability of their models on edge devices and higher-resolution images. To this end, we propose a novel spatial-separated curve rendering network (S$^2$CRNet) for efficient and high-resolution image harmonization for the first time. In S$^2$CRNet, we firstly extract the spatial-separated embeddings from the thumbnails of the masked foreground and background individually. Then, we design a curve rendering module (CRM), which learns and combines the spatial-specific knowledge using linear layers to generate the parameters of the pixel-wise curve mapping in the foreground region. Finally, we directly render the original high-resolution images using the learned color curve. Besides, we also make two extensions of the proposed framework via the Cascaded-CRM and Semantic-CRM for cascaded refinement and semantic guidance, respectively. Experiments show that the proposed method reduces more than 90% parameters compared with previous methods but still achieves the state-of-the-art performance on both synthesized iHarmony4 and real-world DIH test set. Moreover, our method can work smoothly on higher resolution images in real-time which is more than 10$\times$ faster than the existing methods. The code and pre-trained models will be made available and released at https://github.com/stefanLeong/S2CRNet.
Long-term series forecasting with Query Selector -- efficient model of sparse attention
Aug 17, 2021
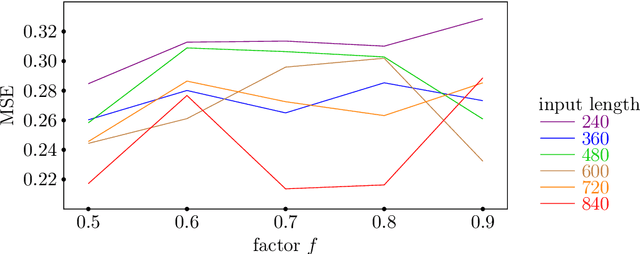
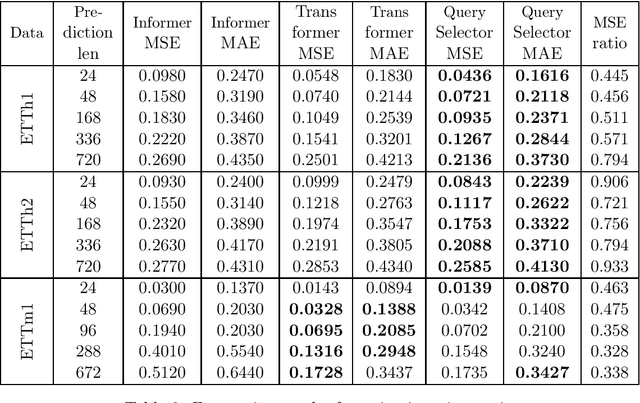
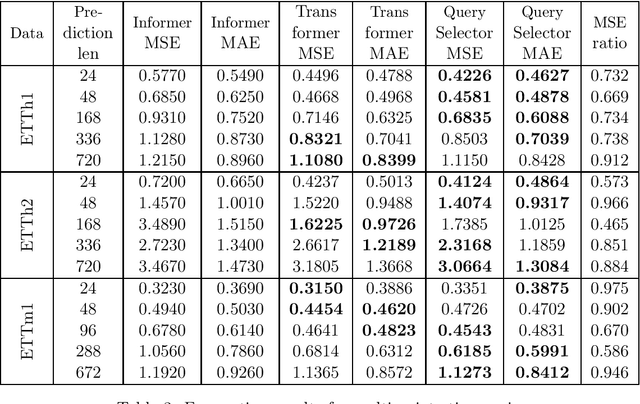
Various modifications of TRANSFORMER were recently used to solve time-series forecasting problem. We propose Query Selector - an efficient, deterministic algorithm for sparse attention matrix. Experiments show it achieves state-of-the art results on ETT, Helpdesk and BPI'12 datasets.
DEEPAGÉ: Answering Questions in Portuguese about the Brazilian Environment
Oct 19, 2021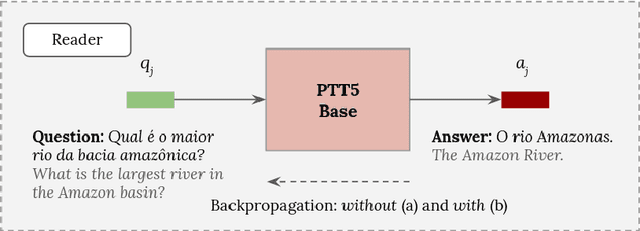
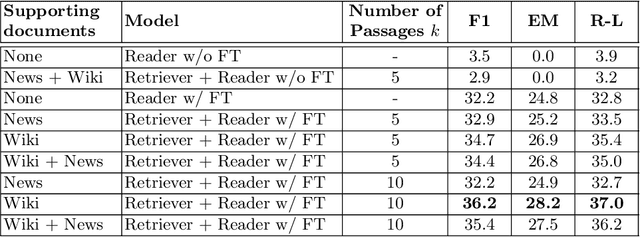
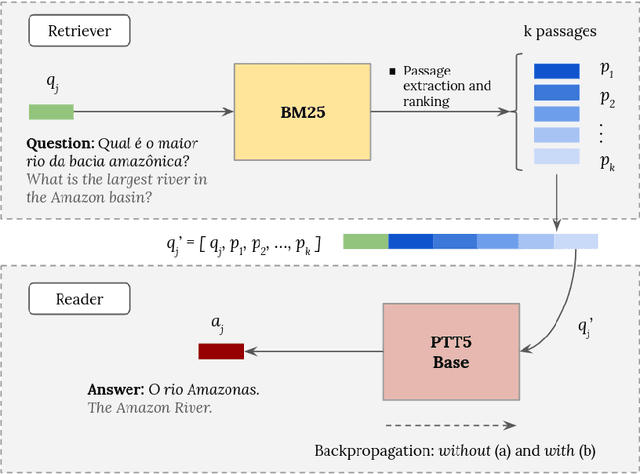
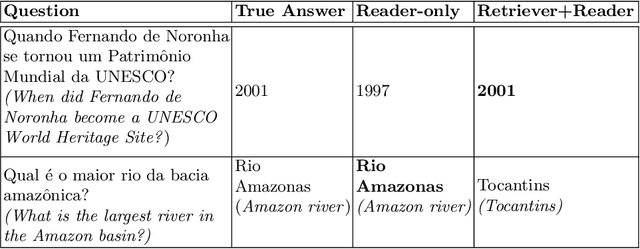
The challenge of climate change and biome conservation is one of the most pressing issues of our time - particularly in Brazil, where key environmental reserves are located. Given the availability of large textual databases on ecological themes, it is natural to resort to question answering (QA) systems to increase social awareness and understanding about these topics. In this work, we introduce multiple QA systems that combine in novel ways the BM25 algorithm, a sparse retrieval technique, with PTT5, a pre-trained state-of-the-art language model. Our QA systems focus on the Portuguese language, thus offering resources not found elsewhere in the literature. As training data, we collected questions from open-domain datasets, as well as content from the Portuguese Wikipedia and news from the press. We thus contribute with innovative architectures and novel applications, attaining an F1-score of 36.2 with our best model.
Optimal Signal Selection for Sensors
Jul 04, 2021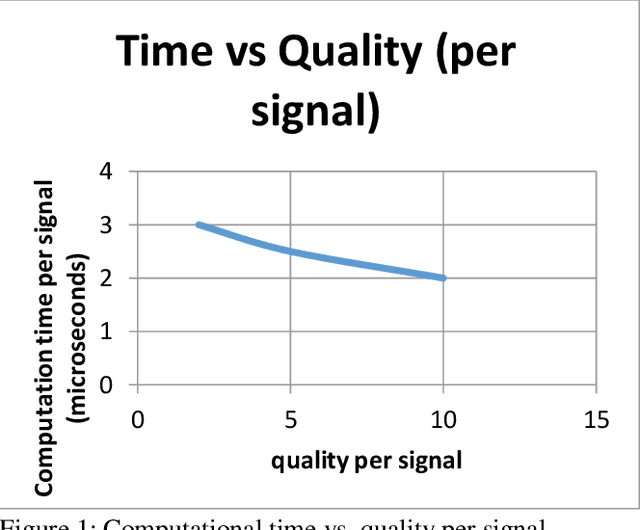
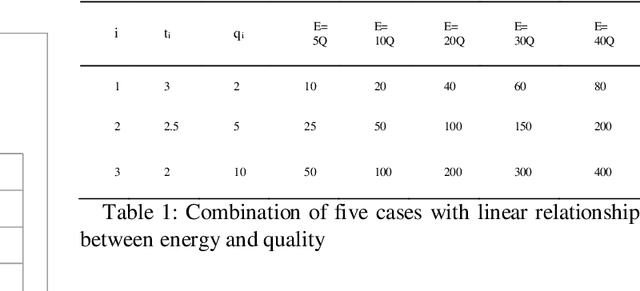
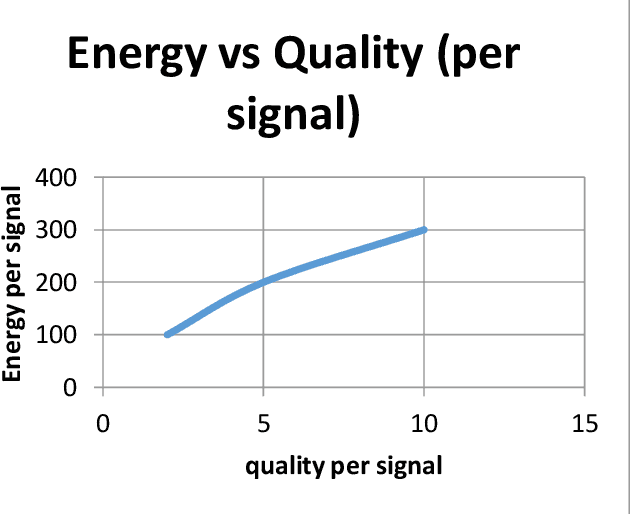
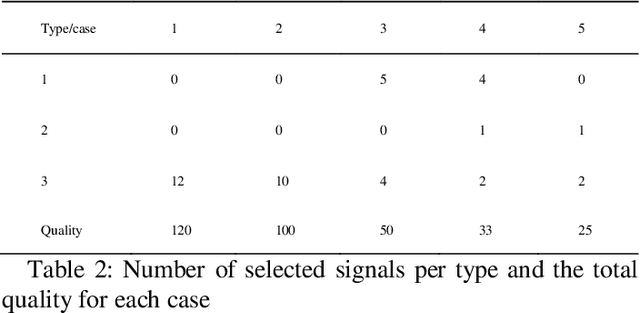
The focus of this research is sensor applications including radar and sonar. Optimal sensing means achieving the best signal quality with the least time and energy cost, which allows processing more data. This paper presents novel work by using an integer linear programming "algorithm" to achieve optimal sensing by selecting the best possible number of signals of a type or a combination of multiple types of signals to ensure the best sensing quality considering all given constraints. A solution based on a heuristic algorithm is implemented to improve the computing time performance. What is novel in this solution is synthesis of an optimized signal mix using information such as but not limited to signal quality, energy and computing time.
Deep Neural Networks for Approximating Stream Reasoning with C-SPARQL
Jun 15, 2021
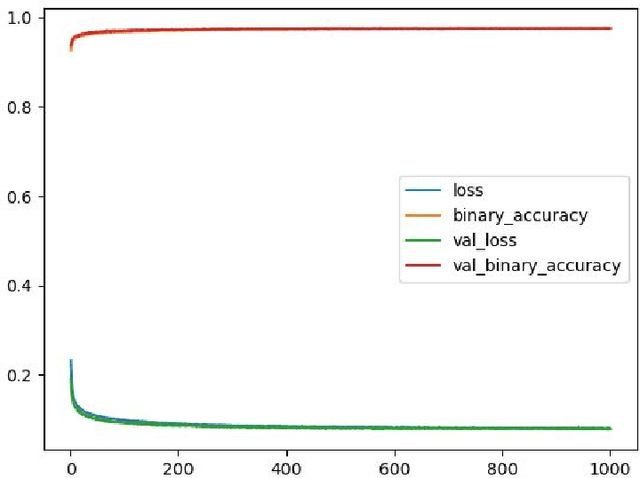
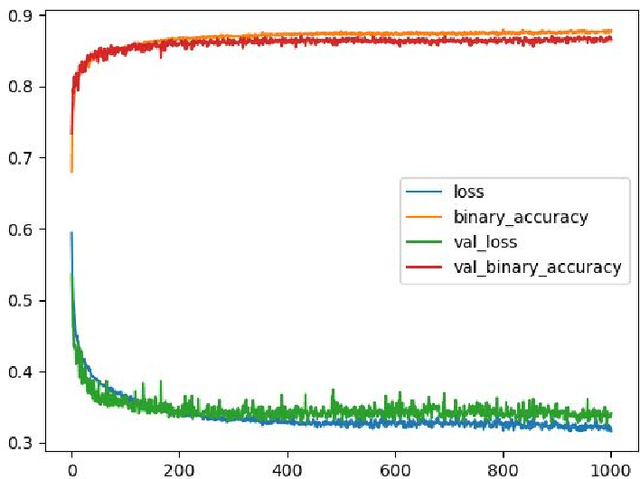
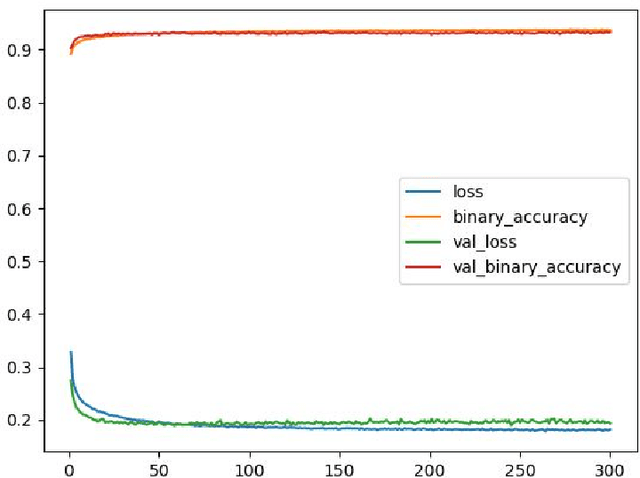
The amount of information produced, whether by newspapers, blogs and social networks, or by monitoring systems, is increasing rapidly. Processing all this data in real-time, while taking into consideration advanced knowledge about the problem domain, is challenging, but required in scenarios where assessing potential risks in a timely fashion is critical. C-SPARQL, a language for continuous queries over streams of RDF data, is one of the more prominent approaches in stream reasoning that provides such continuous inference capabilities over dynamic data that go beyond mere stream processing. However, it has been shown that, in the presence of huge amounts of data, C-SPARQL may not be able to answer queries in time, in particular when the frequency of incoming data is higher than the time required for reasoning with that data. In this paper, we investigate whether reasoning with C-SPARQL can be approximated using Recurrent Neural Networks and Convolutional Neural Networks, two neural network architectures that have been shown to be well-suited for time series forecasting and time series classification, to leverage on their higher processing speed once the network has been trained. We consider a variety of different kinds of queries and obtain overall positive results with high accuracies while improving processing time often by several orders of magnitude.
Span Fine-tuning for Pre-trained Language Models
Aug 29, 2021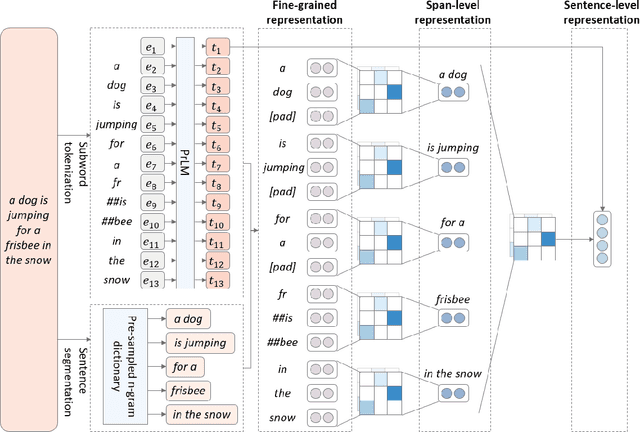
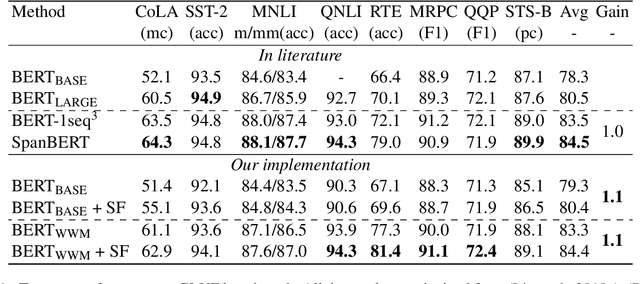

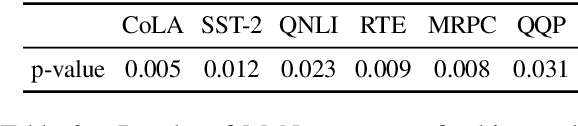
Pre-trained language models (PrLM) have to carefully manage input units when training on a very large text with a vocabulary consisting of millions of words. Previous works have shown that incorporating span-level information over consecutive words in pre-training could further improve the performance of PrLMs. However, given that span-level clues are introduced and fixed in pre-training, previous methods are time-consuming and lack of flexibility. To alleviate the inconvenience, this paper presents a novel span fine-tuning method for PrLMs, which facilitates the span setting to be adaptively determined by specific downstream tasks during the fine-tuning phase. In detail, any sentences processed by the PrLM will be segmented into multiple spans according to a pre-sampled dictionary. Then the segmentation information will be sent through a hierarchical CNN module together with the representation outputs of the PrLM and ultimately generate a span-enhanced representation. Experiments on GLUE benchmark show that the proposed span fine-tuning method significantly enhances the PrLM, and at the same time, offer more flexibility in an efficient way.