 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Bad-Policy Density: A Measure of Reinforcement Learning Hardness
Oct 07, 2021
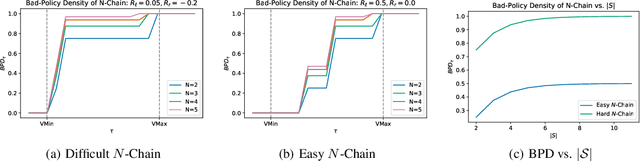
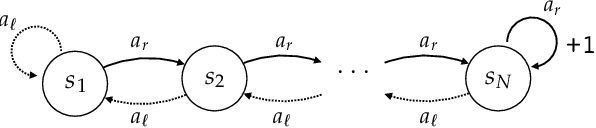
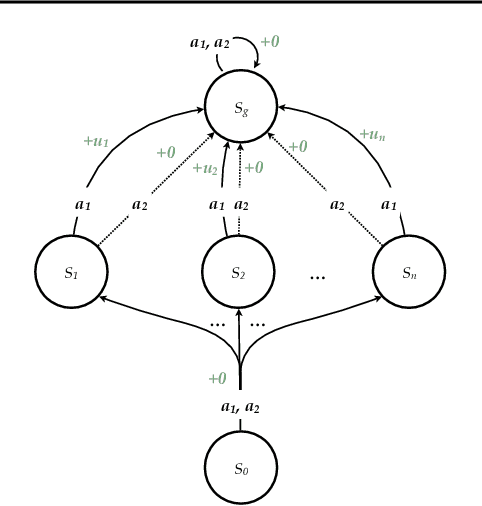
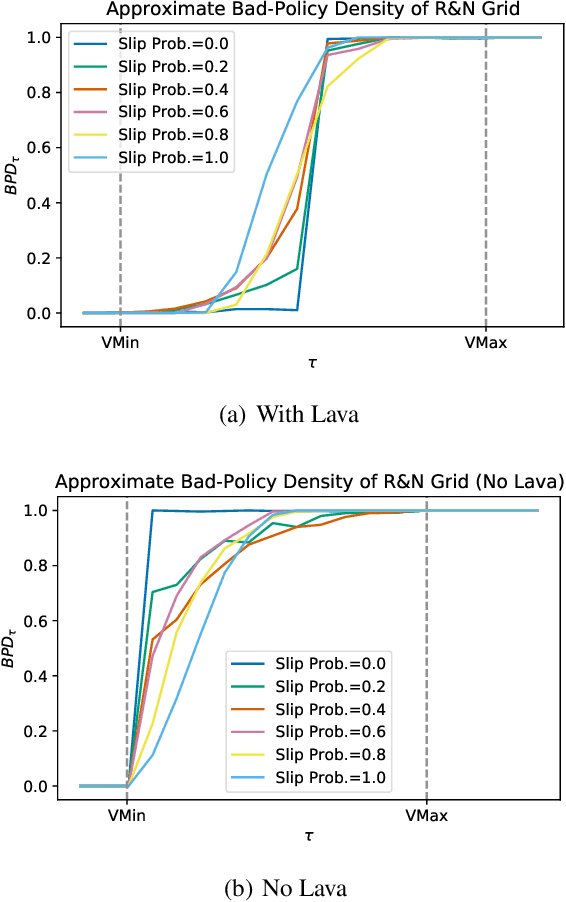
Reinforcement learning is hard in general. Yet, in many specific environments, learning is easy. What makes learning easy in one environment, but difficult in another? We address this question by proposing a simple measure of reinforcement-learning hardness called the bad-policy density. This quantity measures the fraction of the deterministic stationary policy space that is below a desired threshold in value. We prove that this simple quantity has many properties one would expect of a measure of learning hardness. Further, we prove it is NP-hard to compute the measure in general, but there are paths to polynomial-time approximation. We conclude by summarizing potential directions and uses for this measure.
Enabling a Social Robot to Process Social Cues to Detect when to Help a User
Oct 18, 2021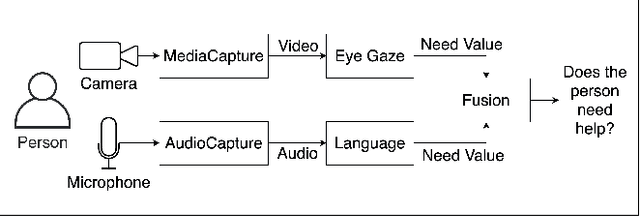
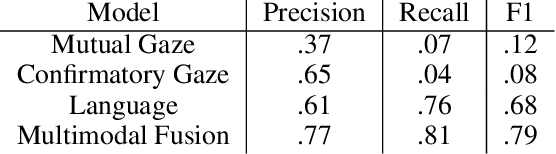

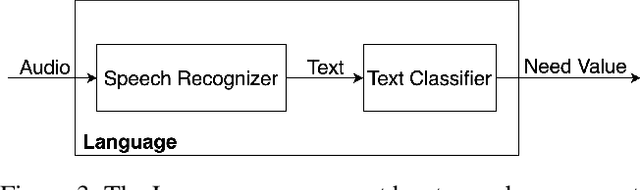
It is important for socially assistive robots to be able to recognize when a user needs and wants help. Such robots need to be able to recognize human needs in a real-time manner so that they can provide timely assistance. We propose an architecture that uses social cues to determine when a robot should provide assistance. Based on a multimodal fusion approach upon eye gaze and language modalities, our architecture is trained and evaluated on data collected in a robot-assisted Lego building task. By focusing on social cues, our architecture has minimal dependencies on the specifics of a given task, enabling it to be applied in many different contexts. Enabling a social robot to recognize a user's needs through social cues can help it to adapt to user behaviors and preferences, which in turn will lead to improved user experiences.
Multi-label Classification of Aircraft Heading Changes Using Neural Network to Resolve Conflicts
Sep 18, 2021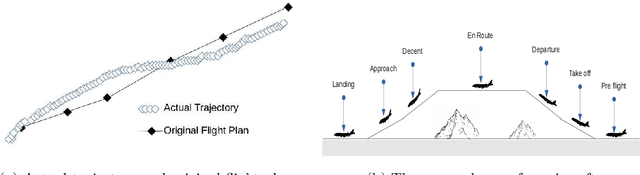

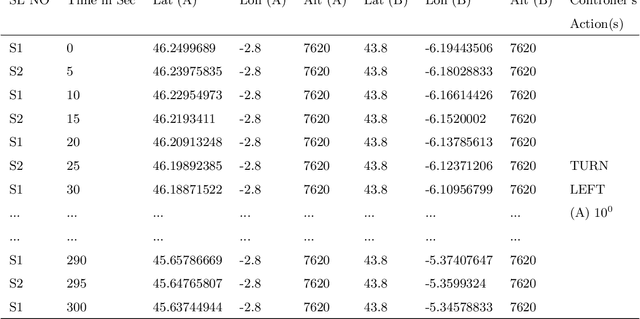
An aircraft conflict occurs when two or more aircraft cross at a certain distance at the same time. Specific air traffic controllers are assigned to solve such conflicts. A controller needs to consider various types of information in order to solve a conflict. The most common and preliminary information is the coordinate position of the involved aircraft. Additionally, a controller has to take into account more information such as flight planning, weather, restricted territory, etc. The most important challenges a controller has to face are: to think about the issues involved and make a decision in a very short time. Due to the increased number of aircraft, it is crucial to reduce the workload of the controllers and help them make quick decisions. A conflict can be solved in many ways, therefore, we consider this problem as a multi-label classification problem. In doing so, we are proposing a multi-label classification model which provides multiple heading advisories for a given conflict. This model we named CRMLnet is based on a novel application of a multi-layer neural network and helps the controllers in their decisions. When compared to other machine learning models, our CRMLnet has achieved the best results with an accuracy of 98.72% and ROC of 0.999. The simulated data set that we have developed and used in our experiments will be delivered to the research community.
YOLOP: You Only Look Once for Panoptic Driving Perception
Aug 26, 2021
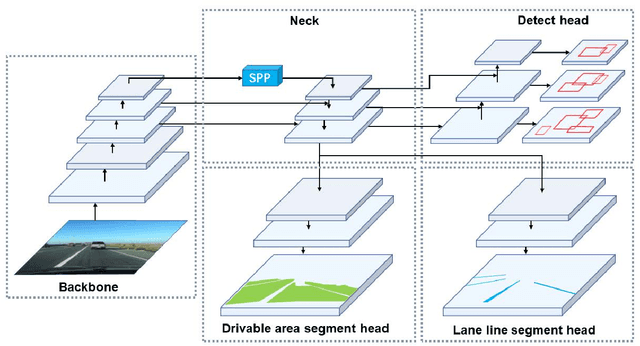


A panoptic driving perception system is an essential part of autonomous driving. A high-precision and real-time perception system can assist the vehicle in making the reasonable decision while driving. We present a panoptic driving perception network (YOLOP) to perform traffic object detection, drivable area segmentation and lane detection simultaneously. It is composed of one encoder for feature extraction and three decoders to handle the specific tasks. Our model performs extremely well on the challenging BDD100K dataset, achieving state-of-the-art on all three tasks in terms of accuracy and speed. Besides, we verify the effectiveness of our multi-task learning model for joint training via ablative studies. To our best knowledge, this is the first work that can process these three visual perception tasks simultaneously in real-time on an embedded device Jetson TX2(23 FPS) and maintain excellent accuracy. To facilitate further research, the source codes and pre-trained models will be released at https://github.com/hustvl/YOLOP.
Robust and Scalable SDE Learning: A Functional Perspective
Oct 11, 2021
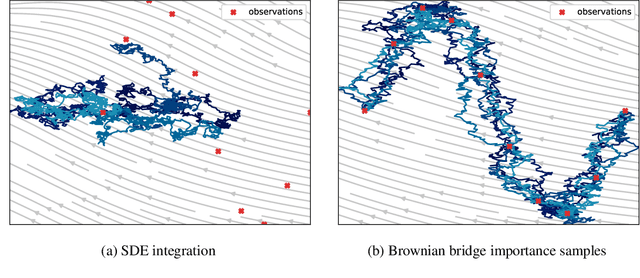
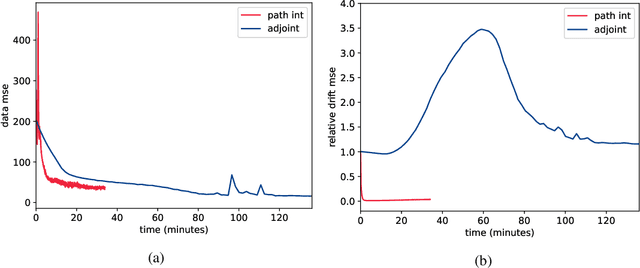
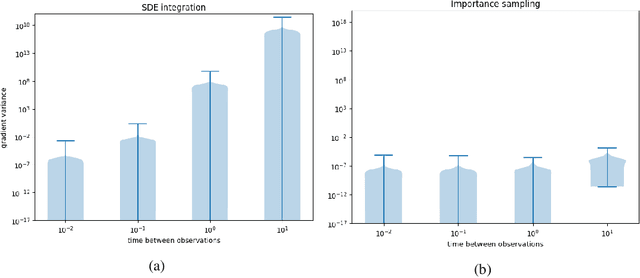
Stochastic differential equations provide a rich class of flexible generative models, capable of describing a wide range of spatio-temporal processes. A host of recent work looks to learn data-representing SDEs, using neural networks and other flexible function approximators. Despite these advances, learning remains computationally expensive due to the sequential nature of SDE integrators. In this work, we propose an importance-sampling estimator for probabilities of observations of SDEs for the purposes of learning. Crucially, the approach we suggest does not rely on such integrators. The proposed method produces lower-variance gradient estimates compared to algorithms based on SDE integrators and has the added advantage of being embarrassingly parallelizable. This facilitates the effective use of large-scale parallel hardware for massive decreases in computation time.
High-dimensional regression with potential prior information on variable importance
Sep 23, 2021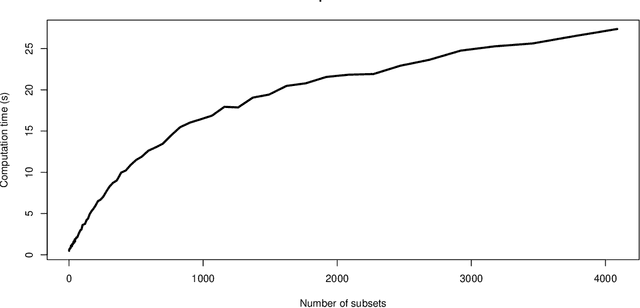
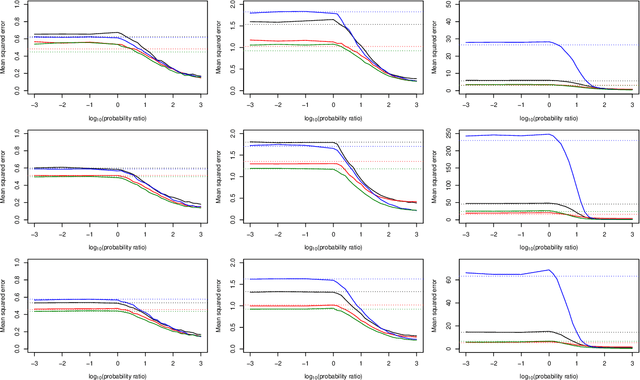
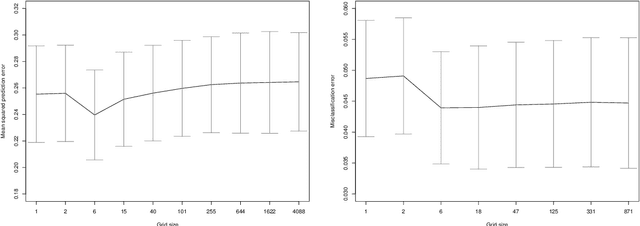
There are a variety of settings where vague prior information may be available on the importance of predictors in high-dimensional regression settings. Examples include ordering on the variables offered by their empirical variances (which is typically discarded through standardisation), the lag of predictors when fitting autoregressive models in time series settings, or the level of missingness of the variables. Whilst such orderings may not match the true importance of variables, we argue that there is little to be lost, and potentially much to be gained, by using them. We propose a simple scheme involving fitting a sequence of models indicated by the ordering. We show that the computational cost for fitting all models when ridge regression is used is no more than for a single fit of ridge regression, and describe a strategy for Lasso regression that makes use of previous fits to greatly speed up fitting the entire sequence of models. We propose to select a final estimator by cross-validation and provide a general result on the quality of the best performing estimator on a test set selected from among a number $M$ of competing estimators in a high-dimensional linear regression setting. Our result requires no sparsity assumptions and shows that only a $\log M$ price is incurred compared to the unknown best estimator. We demonstrate the effectiveness of our approach when applied to missing or corrupted data, and time series settings. An R package is available on github.
Amortized Causal Discovery: Learning to Infer Causal Graphs from Time-Series Data
Jun 18, 2020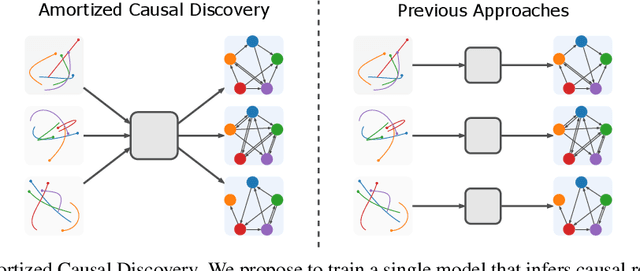
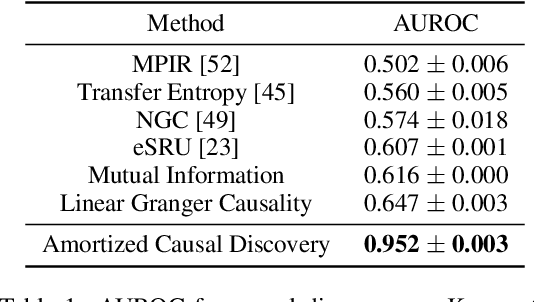
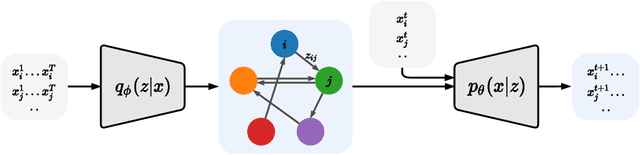
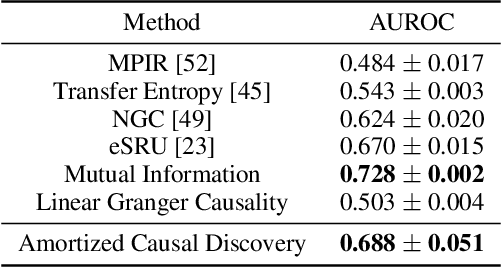
Standard causal discovery methods must fit a new model whenever they encounter samples from a new underlying causal graph. However, these samples often share relevant information - for instance, the dynamics describing the effects of causal relations - which is lost when following this approach. We propose Amortized Causal Discovery, a novel framework that leverages such shared dynamics to learn to infer causal relations from time-series data. This enables us to train a single, amortized model that infers causal relations across samples with different underlying causal graphs, and thus makes use of the information that is shared. We demonstrate experimentally that this approach, implemented as a variational model, leads to significant improvements in causal discovery performance, and show how it can be extended to perform well under hidden confounding.
Applications and Techniques for Fast Machine Learning in Science
Oct 25, 2021
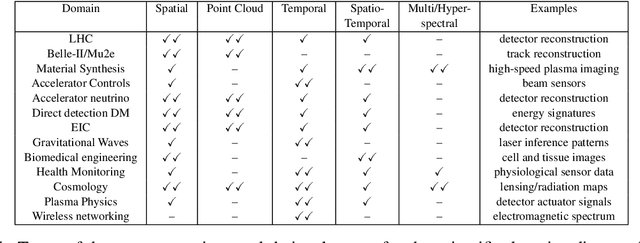
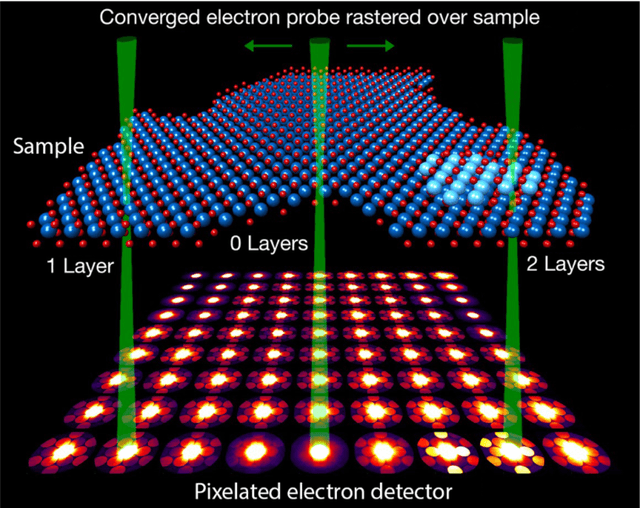
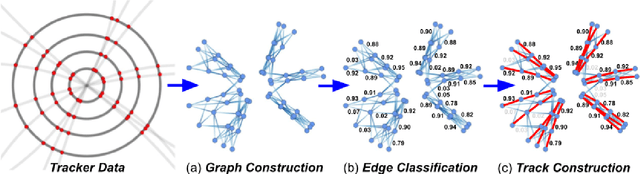
In this community review report, we discuss applications and techniques for fast machine learning (ML) in science -- the concept of integrating power ML methods into the real-time experimental data processing loop to accelerate scientific discovery. The material for the report builds on two workshops held by the Fast ML for Science community and covers three main areas: applications for fast ML across a number of scientific domains; techniques for training and implementing performant and resource-efficient ML algorithms; and computing architectures, platforms, and technologies for deploying these algorithms. We also present overlapping challenges across the multiple scientific domains where common solutions can be found. This community report is intended to give plenty of examples and inspiration for scientific discovery through integrated and accelerated ML solutions. This is followed by a high-level overview and organization of technical advances, including an abundance of pointers to source material, which can enable these breakthroughs.
The Center of Attention: Center-Keypoint Grouping via Attention for Multi-Person Pose Estimation
Oct 11, 2021



We introduce CenterGroup, an attention-based framework to estimate human poses from a set of identity-agnostic keypoints and person center predictions in an image. Our approach uses a transformer to obtain context-aware embeddings for all detected keypoints and centers and then applies multi-head attention to directly group joints into their corresponding person centers. While most bottom-up methods rely on non-learnable clustering at inference, CenterGroup uses a fully differentiable attention mechanism that we train end-to-end together with our keypoint detector. As a result, our method obtains state-of-the-art performance with up to 2.5x faster inference time than competing bottom-up methods. Our code is available at https://github.com/dvl-tum/center-group .
Data-based design of stabilizing switching signals for discrete-time switched linear systems
Mar 11, 2020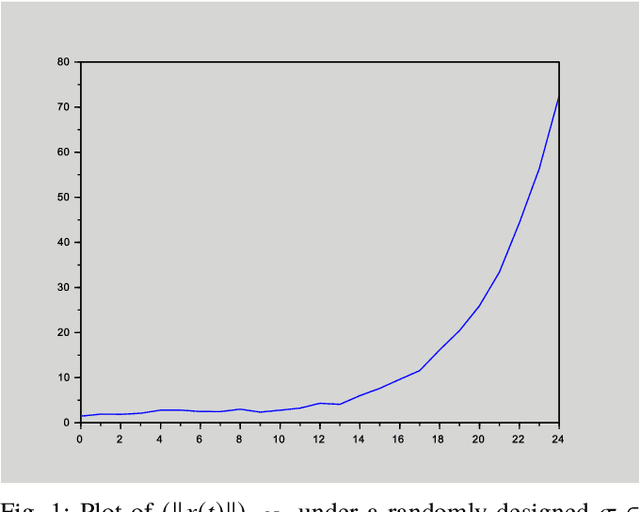
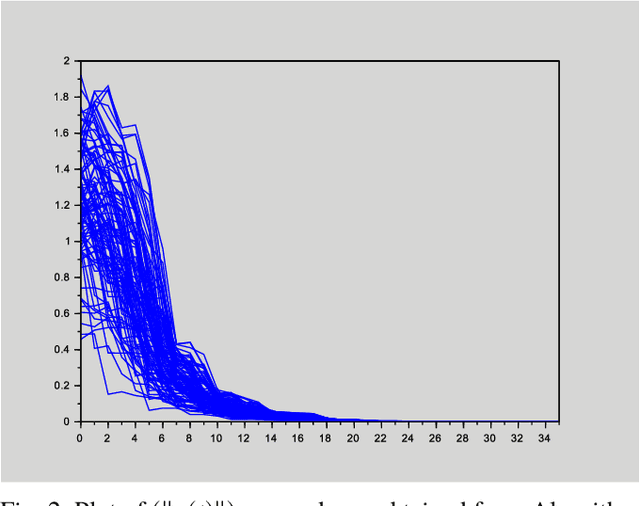
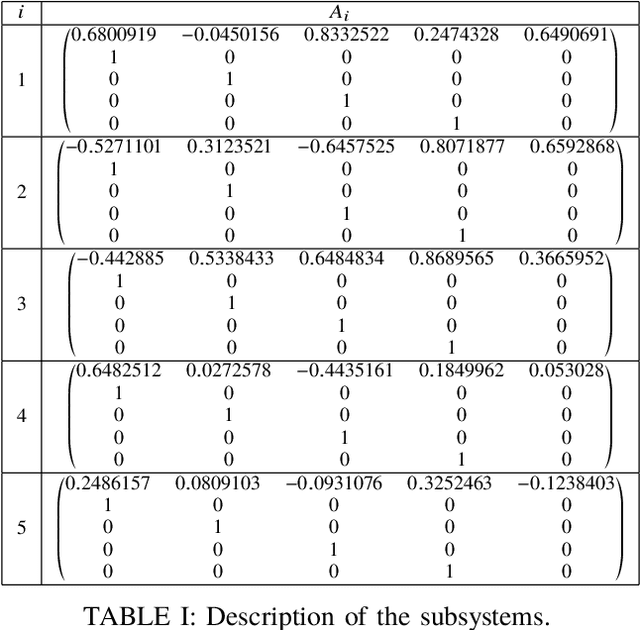
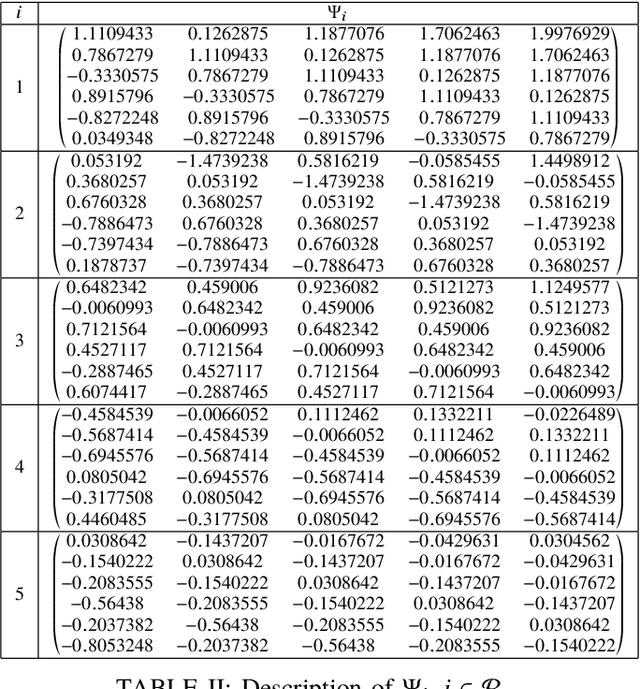
This paper deals with stabilization of discrete-time switched linear systems when explicit knowledge of the state-space models of their subsystems are not available. Given the sets of indices of the stable and unstable subsystems, the set of admissible switches between the subsystems, the admissible dwell times on the subsystems and a simulation model from which finite traces of state trajectories of the switched system can be collected, we devise an algorithm that designs periodic switching signals which preserve stability of the resulting switched system. We combine two ingredients: (a) data-based stability analysis of discrete-time linear systems and (b) multiple Lyapunov-like functions and graph walks based design of stabilizing switching signals, for this purpose. A numerical example is presented to demonstrate the proposed algorithm.