 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Revisiting Methods for Finding Influential Examples
Nov 08, 2021
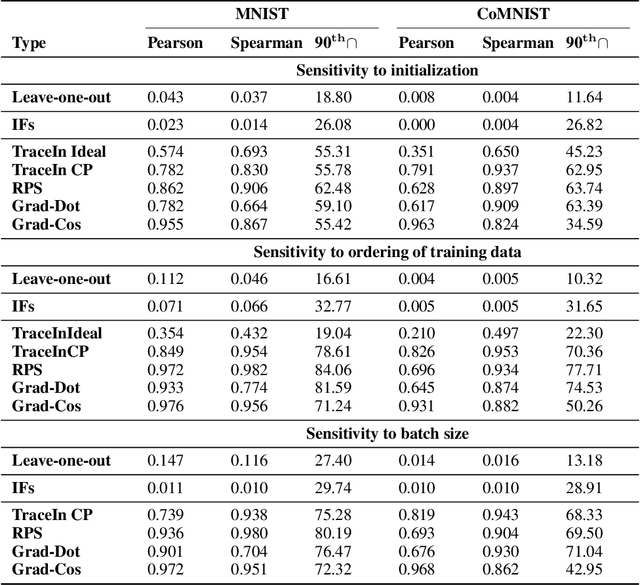
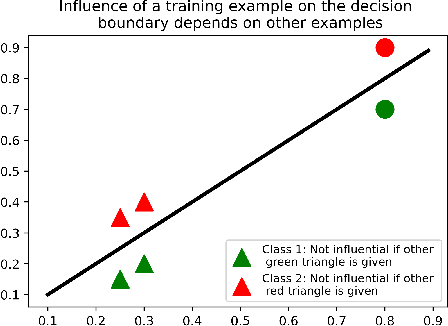
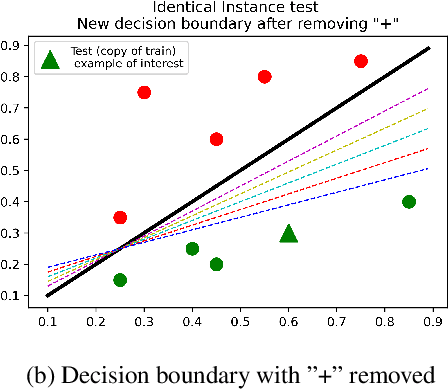
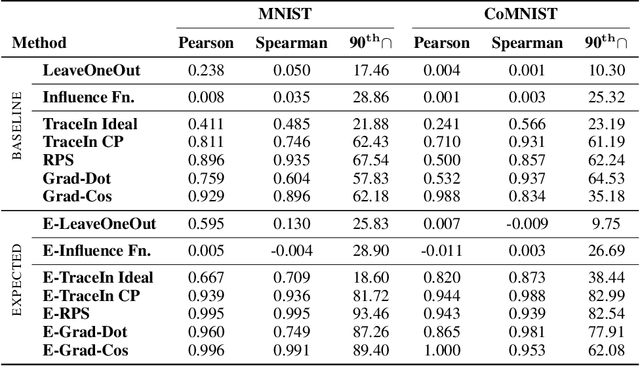
Several instance-based explainability methods for finding influential training examples for test-time decisions have been proposed recently, including Influence Functions, TraceIn, Representer Point Selection, Grad-Dot, and Grad-Cos. Typically these methods are evaluated using LOO influence (Cook's distance) as a gold standard, or using various heuristics. In this paper, we show that all of the above methods are unstable, i.e., extremely sensitive to initialization, ordering of the training data, and batch size. We suggest that this is a natural consequence of how in the literature, the influence of examples is assumed to be independent of model state and other examples -- and argue it is not. We show that LOO influence and heuristics are, as a result, poor metrics to measure the quality of instance-based explanations, and instead propose to evaluate such explanations by their ability to detect poisoning attacks. Further, we provide a simple, yet effective baseline to improve all of the above methods and show how it leads to very significant improvements on downstream tasks.
Smooth tensor estimation with unknown permutations
Nov 08, 2021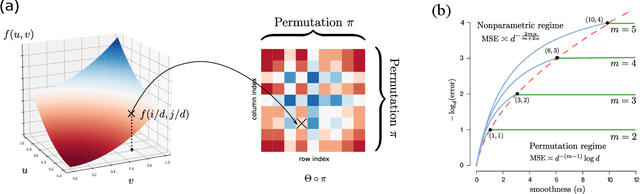

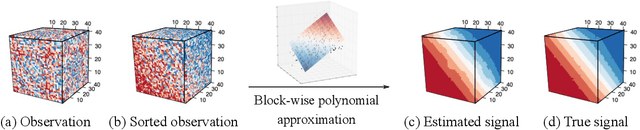
We consider the problem of structured tensor denoising in the presence of unknown permutations. Such data problems arise commonly in recommendation system, neuroimaging, community detection, and multiway comparison applications. Here, we develop a general family of smooth tensor models up to arbitrary index permutations; the model incorporates the popular tensor block models and Lipschitz hypergraphon models as special cases. We show that a constrained least-squares estimator in the block-wise polynomial family achieves the minimax error bound. A phase transition phenomenon is revealed with respect to the smoothness threshold needed for optimal recovery. In particular, we find that a polynomial of degree up to $(m-2)(m+1)/2$ is sufficient for accurate recovery of order-$m$ tensors, whereas higher degree exhibits no further benefits. This phenomenon reveals the intrinsic distinction for smooth tensor estimation problems with and without unknown permutations. Furthermore, we provide an efficient polynomial-time Borda count algorithm that provably achieves optimal rate under monotonicity assumptions. The efficacy of our procedure is demonstrated through both simulations and Chicago crime data analysis.
Indexing Context-Sensitive Reachability
Sep 03, 2021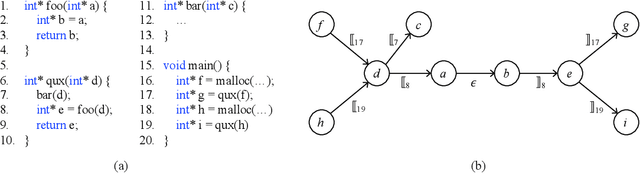
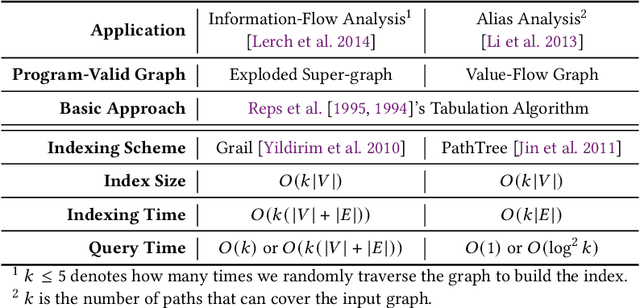
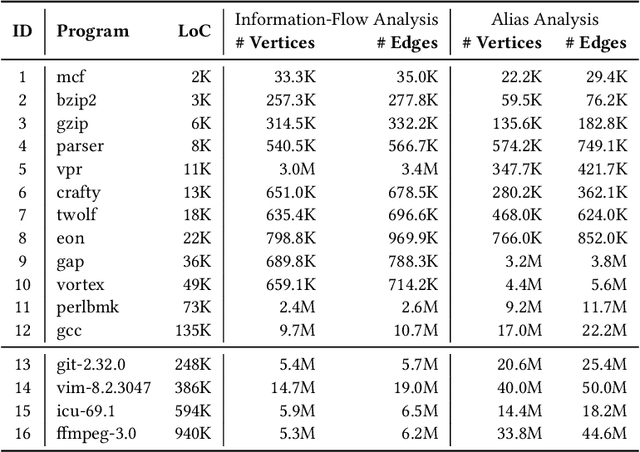
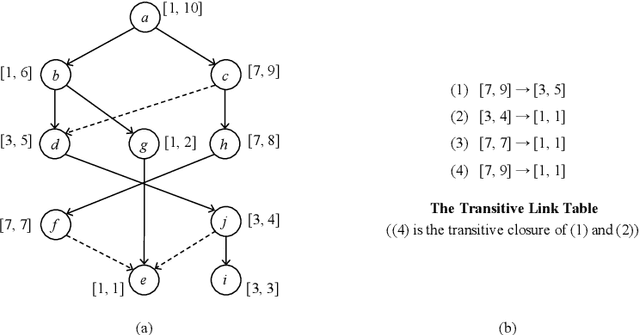
Many context-sensitive data flow analyses can be formulated as a variant of the all-pairs Dyck-CFL reachability problem, which, in general, is of sub-cubic time complexity and quadratic space complexity. Such high complexity significantly limits the scalability of context-sensitive data flow analysis and is not affordable for analyzing large-scale software. This paper presents \textsc{Flare}, a reduction from the CFL reachability problem to the conventional graph reachability problem for context-sensitive data flow analysis. This reduction allows us to benefit from recent advances in reachability indexing schemes, which often consume almost linear space for answering reachability queries in almost constant time. We have applied our reduction to a context-sensitive alias analysis and a context-sensitive information-flow analysis for C/C++ programs. Experimental results on standard benchmarks and open-source software demonstrate that we can achieve orders of magnitude speedup at the cost of only moderate space to store the indexes. The implementation of our approach is publicly available.
Finite-Time Analysis of Asynchronous Stochastic Approximation and $Q$-Learning
Feb 01, 2020We consider a general asynchronous Stochastic Approximation (SA) scheme featuring a weighted infinity-norm contractive operator, and prove a bound on its finite-time convergence rate on a single trajectory. Additionally, we specialize the result to asynchronous $Q$-learning. The resulting bound matches the sharpest available bound for synchronous $Q$-learning, and improves over previous known bounds for asynchronous $Q$-learning.
Nested Multiple Instance Learning with Attention Mechanisms
Nov 02, 2021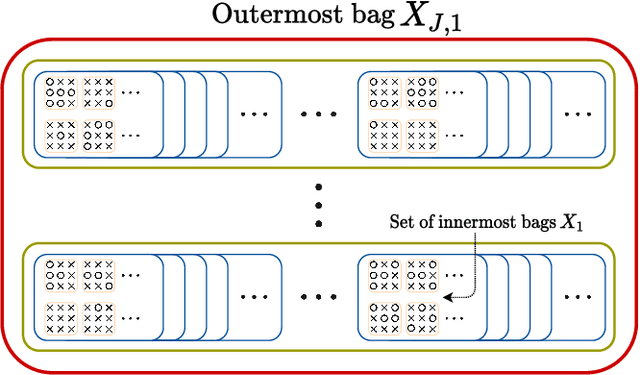
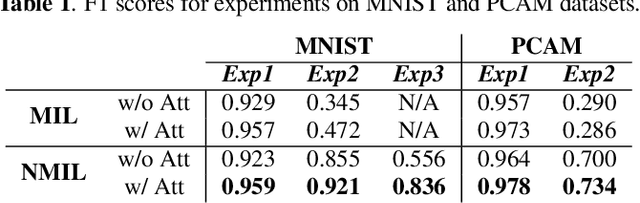
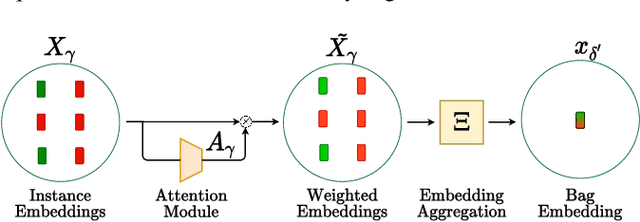
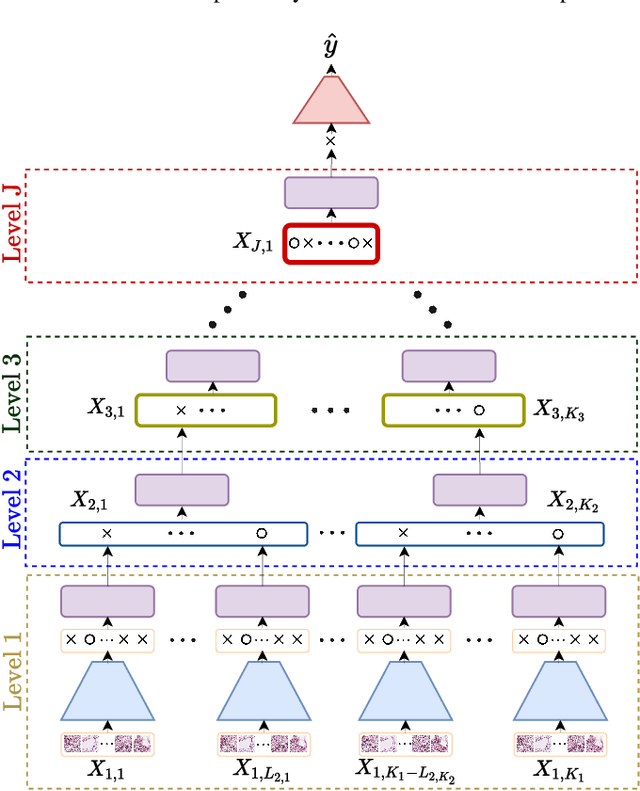
Multiple instance learning (MIL) is a type of weakly supervised learning where multiple instances of data with unknown labels are sorted into bags. Since knowledge about the individual instances is incomplete, labels are assigned to the bags containing the instances. While this method fits diverse applications were labelled data is scarce, it lacks depth for solving more complex scenarios where associations between sets of instances have to be made, like finding relevant regions of interest in an image or detecting events in a set of time-series signals. Nested MIL considers labelled bags within bags, where only the outermost bag is labelled and inner-bags and instances are represented as latent labels. In addition, we propose using an attention mechanism to add interpretability, providing awareness into the impact of each instance to the weak bag label. Experiments in classical image datasets show that our proposed model provides high accuracy performance as well as spotting relevant instances on image regions.
A New Unified Deep Learning Approach with Decomposition-Reconstruction-Ensemble Framework for Time Series Forecasting
Feb 22, 2020

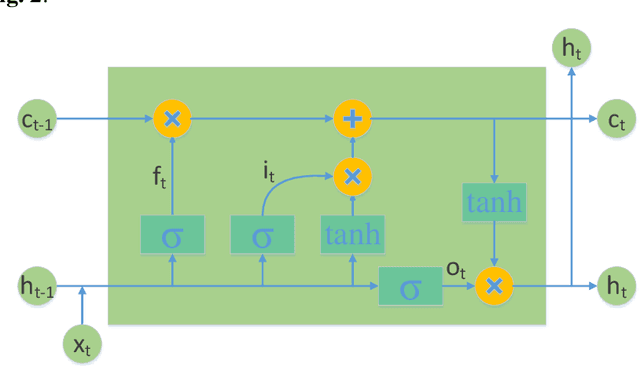
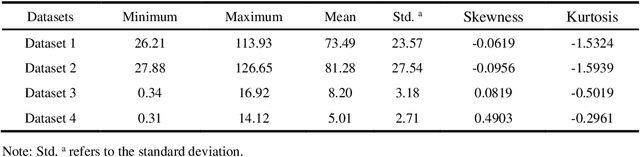
A new variational mode decomposition (VMD) based deep learning approach is proposed in this paper for time series forecasting problem. Firstly, VMD is adopted to decompose the original time series into several sub-signals. Then, a convolutional neural network (CNN) is applied to learn the reconstruction patterns on the decomposed sub-signals to obtain several reconstructed sub-signals. Finally, a long short term memory (LSTM) network is employed to forecast the time series with the decomposed sub-signals and the reconstructed sub-signals as inputs. The proposed VMD-CNN-LSTM approach is originated from the decomposition-reconstruction-ensemble framework, and innovated by embedding the reconstruction, single forecasting, and ensemble steps in a unified deep learning approach. To verify the forecasting performance of the proposed approach, four typical time series datasets are introduced for empirical analysis. The empirical results demonstrate that the proposed approach outperforms consistently the benchmark approaches in terms of forecasting accuracy, and also indicate that the reconstructed sub-signals obtained by CNN is of importance for further improving the forecasting performance.
SaLinA: Sequential Learning of Agents
Oct 15, 2021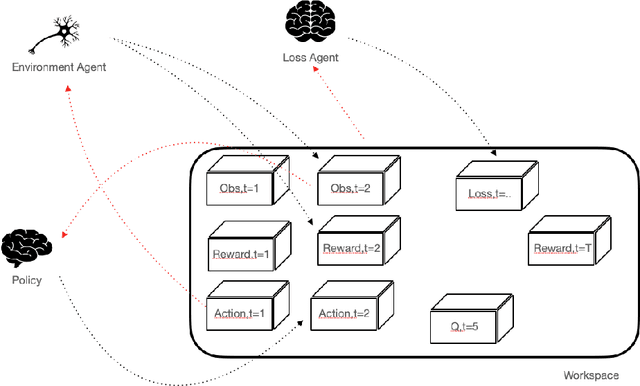


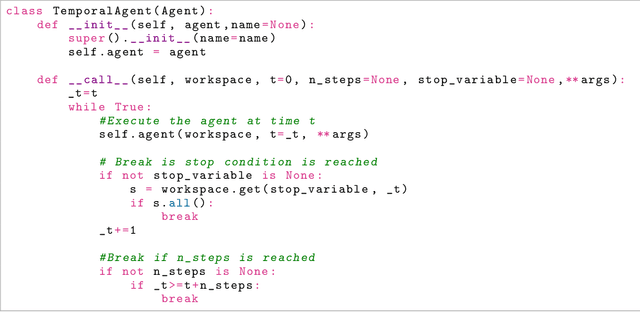
SaLinA is a simple library that makes implementing complex sequential learning models easy, including reinforcement learning algorithms. It is built as an extension of PyTorch: algorithms coded with \SALINA{} can be understood in few minutes by PyTorch users and modified easily. Moreover, SaLinA naturally works with multiple CPUs and GPUs at train and test time, thus being a good fit for the large-scale training use cases. In comparison to existing RL libraries, SaLinA has a very low adoption cost and capture a large variety of settings (model-based RL, batch RL, hierarchical RL, multi-agent RL, etc.). But SaLinA does not only target RL practitioners, it aims at providing sequential learning capabilities to any deep learning programmer.
Online Search With Best-Price and Query-Based Predictions
Dec 02, 2021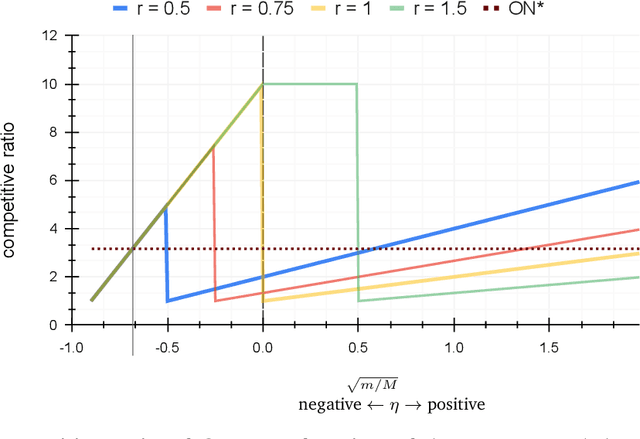
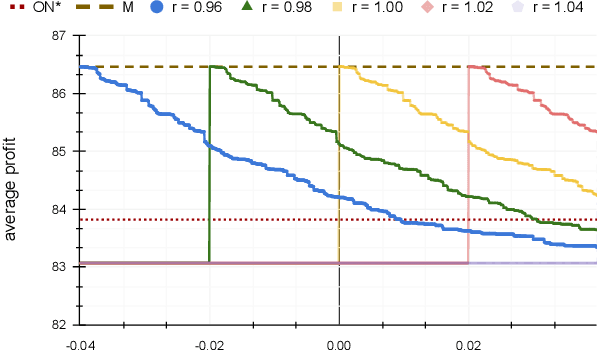
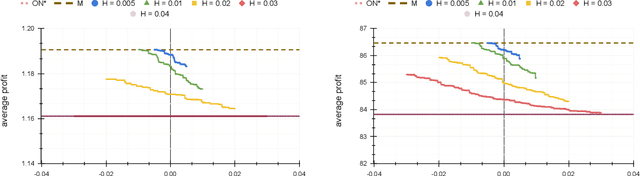
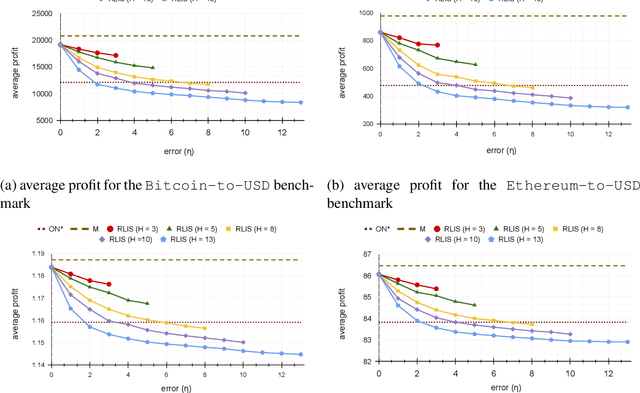
In the online (time-series) search problem, a player is presented with a sequence of prices which are revealed in an online manner. In the standard definition of the problem, for each revealed price, the player must decide irrevocably whether to accept or reject it, without knowledge of future prices (other than an upper and a lower bound on their extreme values), and the objective is to minimize the competitive ratio, namely the worst-case ratio between the maximum price in the sequence and the one selected by the player. The problem formulates several applications of decision-making in the face of uncertainty on the revealed samples. Previous work on this problem has largely assumed extreme scenarios in which either the player has almost no information about the input, or the player is provided with some powerful, and error-free advice. In this work, we study learning-augmented algorithms, in which there is a potentially erroneous prediction concerning the input. Specifically, we consider two different settings: the setting in which the prediction is related to the maximum price in the sequence, as well as the setting in which the prediction is obtained as a response to a number of binary queries. For both settings, we provide tight, or near-tight upper and lower bounds on the worst-case performance of search algorithms as a function of the prediction error. We also provide experimental results on data obtained from stock exchange markets that confirm the theoretical analysis, and explain how our techniques can be applicable to other learning-augmented applications.
Data-driven estimation of system norms via impulse response
Nov 08, 2021
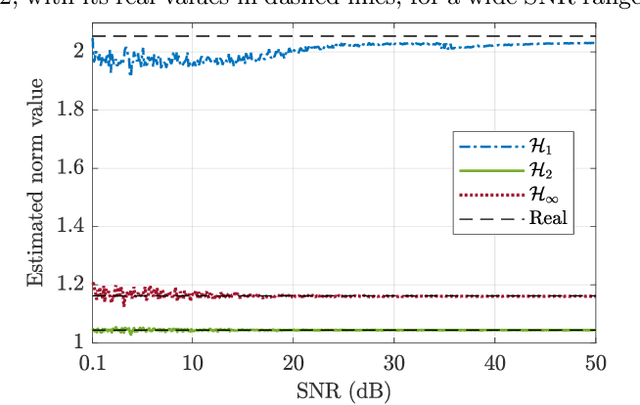
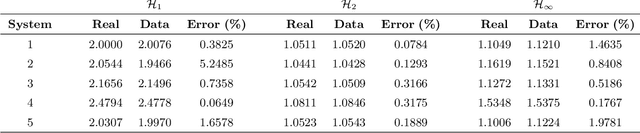
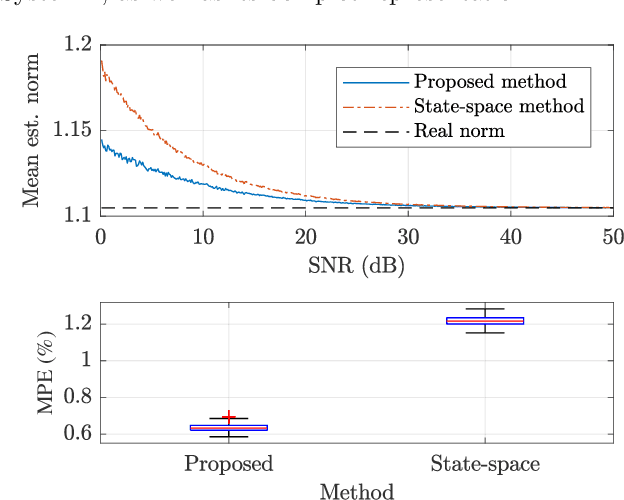
This paper proposes a method for estimating the norms of a system in a pure data-driven fashion based on their identified Impulse Response (IR) coefficients. The calculation of norms is briefly reviewed and the main expressions for the IR-based estimations are presented. As a case study, the $\mathcal{H}_{1}$, $\mathcal{H}_2$, and $\mathcal{H}_{\infty}$ norms of the sensitivity transfer function of five different discrete-time closed-loop systems are estimated for a Signal-to-Noise-Ratio (SNR) of 10 dB, achieving low percent error values if compared to the real value. To verify the influence of the noise amplitude, norms are estimated considering a wide range of SNR values, for a specific system, presenting low Mean Percent Error (MPE) if compared to the real norms. The proposed technique is also compared to an existing state-space-based method in terms of $\mathcal{H}_{\infty}$, through Monte Carlo, showing a reduction of approximately 48 % in the MPE for a wide range of SNR values.
Evaluating Generalization and Transfer Capacity of Multi-Agent Reinforcement Learning Across Variable Number of Agents
Nov 28, 2021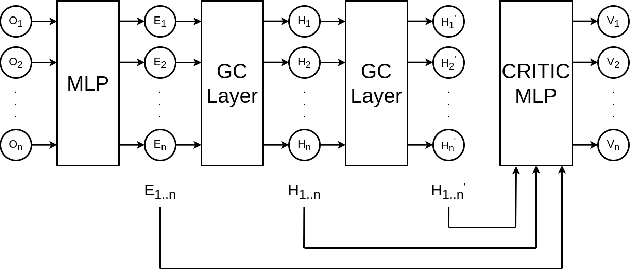

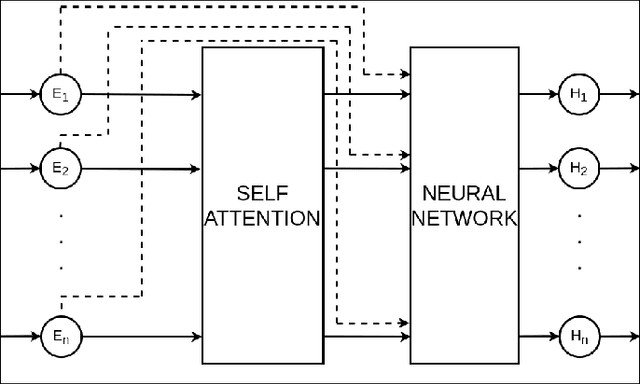
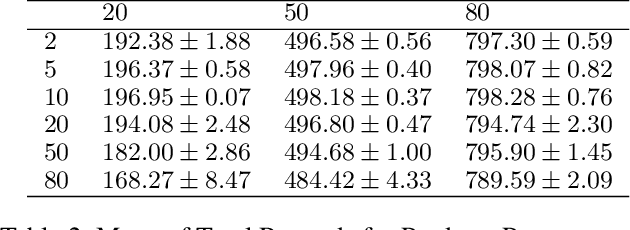
Multi-agent Reinforcement Learning (MARL) problems often require cooperation among agents in order to solve a task. Centralization and decentralization are two approaches used for cooperation in MARL. While fully decentralized methods are prone to converge to suboptimal solutions due to partial observability and nonstationarity, the methods involving centralization suffer from scalability limitations and lazy agent problem. Centralized training decentralized execution paradigm brings out the best of these two approaches; however, centralized training still has an upper limit of scalability not only for acquired coordination performance but also for model size and training time. In this work, we adopt the centralized training with decentralized execution paradigm and investigate the generalization and transfer capacity of the trained models across variable number of agents. This capacity is assessed by training variable number of agents in a specific MARL problem and then performing greedy evaluations with variable number of agents for each training configuration. Thus, we analyze the evaluation performance for each combination of agent count for training versus evaluation. We perform experimental evaluations on predator prey and traffic junction environments and demonstrate that it is possible to obtain similar or higher evaluation performance by training with less agents. We conclude that optimal number of agents to perform training may differ from the target number of agents and argue that transfer across large number of agents can be a more efficient solution to scaling up than directly increasing number of agents during training.