 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Identity Conversion for Emotional Speakers: A Study for Disentanglement of Emotion Style and Speaker Identity
Oct 20, 2021
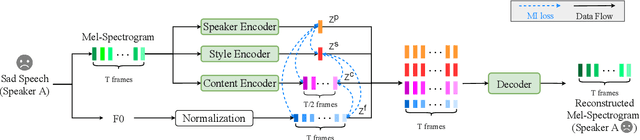
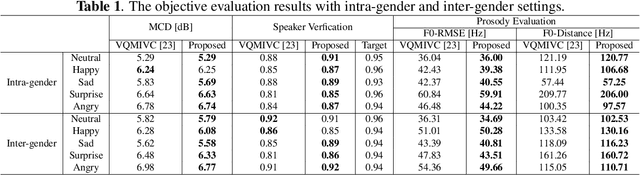

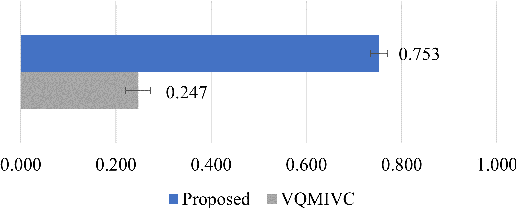
Expressive voice conversion performs identity conversion for emotional speakers by jointly converting speaker identity and speaker-dependent emotion style. Due to the hierarchical structure of speech emotion, it is challenging to disentangle the speaker-dependent emotional style for expressive voice conversion. Motivated by the recent success on speaker disentanglement with variational autoencoder (VAE), we propose an expressive voice conversion framework which can effectively disentangle linguistic content, speaker identity, pitch, and emotional style information. We study the use of emotion encoder to model emotional style explicitly, and introduce mutual information (MI) losses to reduce the irrelevant information from the disentangled emotion representations. At run-time, our proposed framework can convert both speaker identity and speaker-dependent emotional style without the need for parallel data. Experimental results validate the effectiveness of our proposed framework in both objective and subjective evaluations.
Roadside-assisted Cooperative Planning using Future Path Sharing for Autonomous Driving
Aug 10, 2021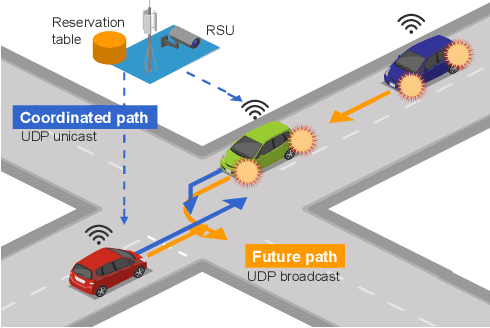
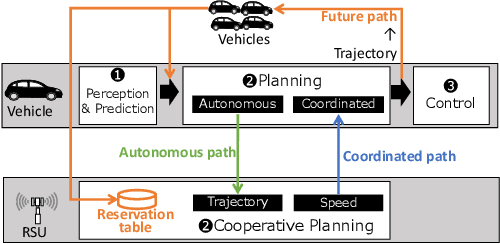
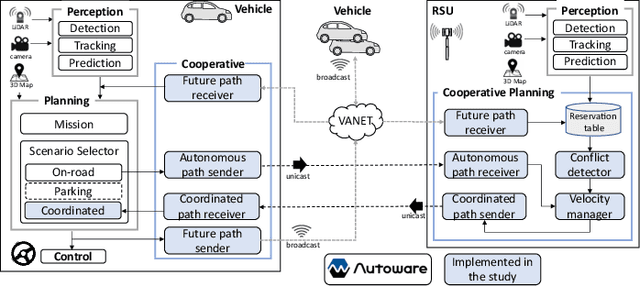
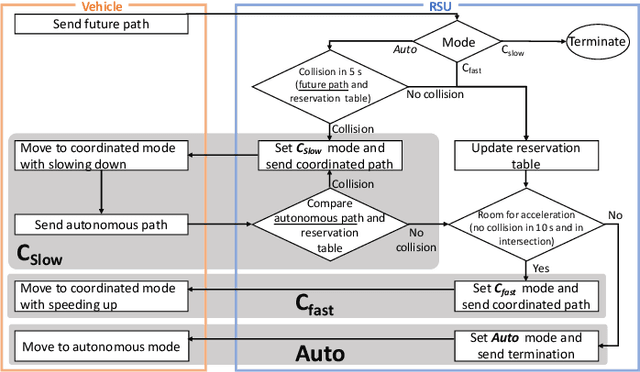
Cooperative intelligent transportation systems (ITS) are used by autonomous vehicles to communicate with surrounding autonomous vehicles and roadside units (RSU). Current C-ITS applications focus primarily on real-time information sharing, such as cooperative perception. In addition to real-time information sharing, self-driving cars need to coordinate their action plans to achieve higher safety and efficiency. For this reason, this study defines a vehicle's future action plan/path and designs a cooperative path-planning model at intersections using future path sharing based on the future path information of multiple vehicles. The notion is that when the RSU detects a potential conflict of vehicle paths or an acceleration opportunity according to the shared future paths, it will generate a coordinated path update that adjusts the speeds of the vehicles. We implemented the proposed method using the open-source Autoware autonomous driving software and evaluated it with the LGSVL autonomous vehicle simulator. We conducted simulation experiments with two vehicles at a blind intersection scenario, finding that each car can travel safely and more efficiently by planning a path that reflects the action plans of all vehicles involved. The time consumed by introducing the RSU is 23.0 % and 28.1 % shorter than that of the stand-alone autonomous driving case at the intersection.
Learning and Dynamical Models for Sub-seasonal Climate Forecasting: Comparison and Collaboration
Sep 29, 2021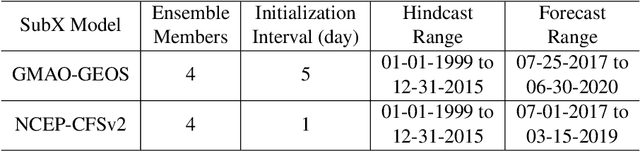
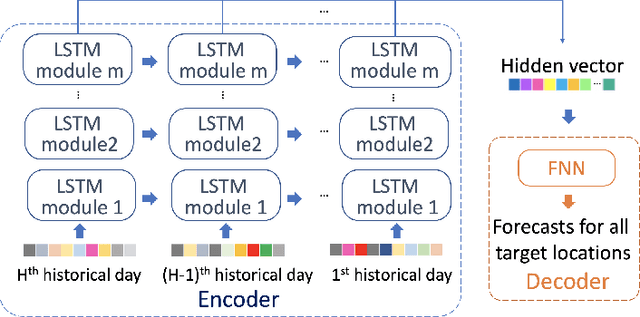
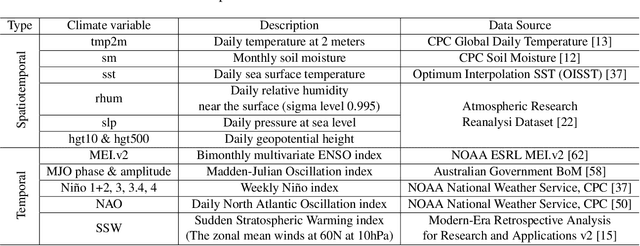
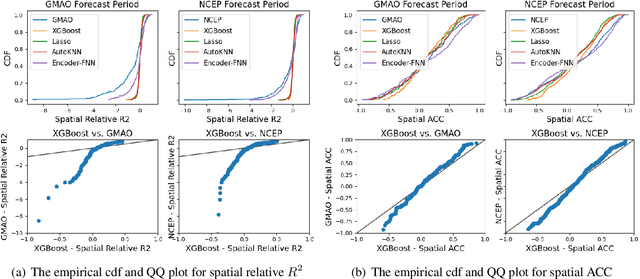
Sub-seasonal climate forecasting (SSF) is the prediction of key climate variables such as temperature and precipitation on the 2-week to 2-month time horizon. Skillful SSF would have substantial societal value in areas such as agricultural productivity, hydrology and water resource management, and emergency planning for extreme events such as droughts and wildfires. Despite its societal importance, SSF has stayed a challenging problem compared to both short-term weather forecasting and long-term seasonal forecasting. Recent studies have shown the potential of machine learning (ML) models to advance SSF. In this paper, for the first time, we perform a fine-grained comparison of a suite of modern ML models with start-of-the-art physics-based dynamical models from the Subseasonal Experiment (SubX) project for SSF in the western contiguous United States. Additionally, we explore mechanisms to enhance the ML models by using forecasts from dynamical models. Empirical results illustrate that, on average, ML models outperform dynamical models while the ML models tend to be conservatives in their forecasts compared to the SubX models. Further, we illustrate that ML models make forecasting errors under extreme weather conditions, e.g., cold waves due to the polar vortex, highlighting the need for separate models for extreme events. Finally, we show that suitably incorporating dynamical model forecasts as inputs to ML models can substantially improve the forecasting performance of the ML models. The SSF dataset constructed for the work, dynamical model predictions, and code for the ML models are released along with the paper for the benefit of the broader machine learning community.
Can machines learn to see without visual databases?
Oct 12, 2021This paper sustains the position that the time has come for thinking of learning machines that conquer visual skills in a truly human-like context, where a few human-like object supervisions are given by vocal interactions and pointing aids only. This likely requires new foundations on computational processes of vision with the final purpose of involving machines in tasks of visual description by living in their own visual environment under simple man-machine linguistic interactions. The challenge consists of developing machines that learn to see without needing to handle visual databases. This might open the doors to a truly orthogonal competitive track concerning deep learning technologies for vision which does not rely on the accumulation of huge visual databases.
Space-time deep neural network approximations for high-dimensional partial differential equations
Jun 03, 2020It is one of the most challenging issues in applied mathematics to approximately solve high-dimensional partial differential equations (PDEs) and most of the numerical approximation methods for PDEs in the scientific literature suffer from the so-called curse of dimensionality in the sense that the number of computational operations employed in the corresponding approximation scheme to obtain an approximation precision $\varepsilon>0$ grows exponentially in the PDE dimension and/or the reciprocal of $\varepsilon$. Recently, certain deep learning based approximation methods for PDEs have been proposed and various numerical simulations for such methods suggest that deep neural network (DNN) approximations might have the capacity to indeed overcome the curse of dimensionality in the sense that the number of real parameters used to describe the approximating DNNs grows at most polynomially in both the PDE dimension $d\in\mathbb{N}$ and the reciprocal of the prescribed accuracy $\varepsilon>0$. There are now also a few rigorous results in the scientific literature which substantiate this conjecture by proving that DNNs overcome the curse of dimensionality in approximating solutions of PDEs. Each of these results establishes that DNNs overcome the curse of dimensionality in approximating suitable PDE solutions at a fixed time point $T>0$ and on a compact cube $[a,b]^d$ in space but none of these results provides an answer to the question whether the entire PDE solution on $[0,T]\times [a,b]^d$ can be approximated by DNNs without the curse of dimensionality. It is precisely the subject of this article to overcome this issue. More specifically, the main result of this work in particular proves for every $a\in\mathbb{R}$, $ b\in (a,\infty)$ that solutions of certain Kolmogorov PDEs can be approximated by DNNs on the space-time region $[0,T]\times [a,b]^d$ without the curse of dimensionality.
Two steps to risk sensitivity
Nov 12, 2021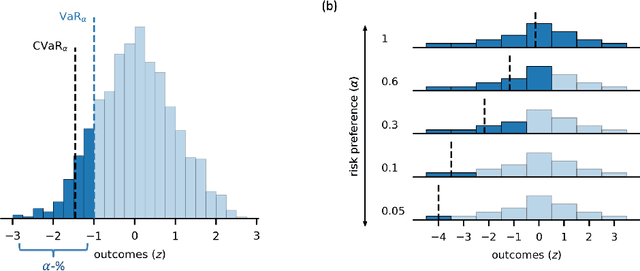
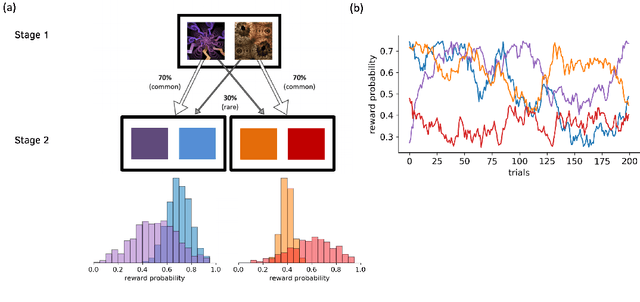
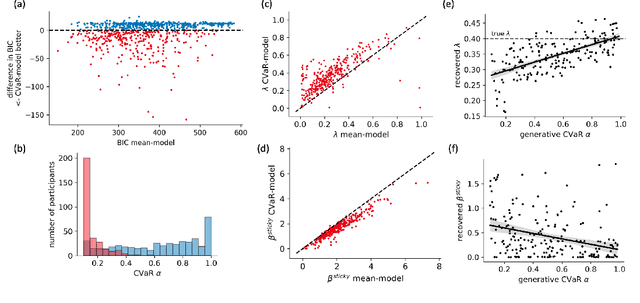
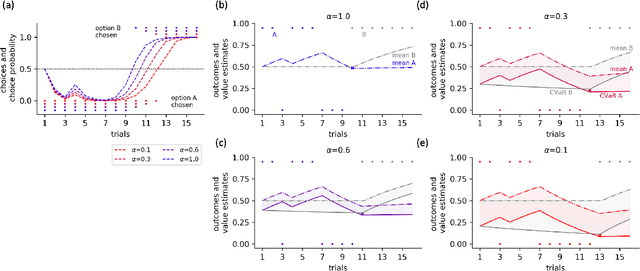
Distributional reinforcement learning (RL) -- in which agents learn about all the possible long-term consequences of their actions, and not just the expected value -- is of great recent interest. One of the most important affordances of a distributional view is facilitating a modern, measured, approach to risk when outcomes are not completely certain. By contrast, psychological and neuroscientific investigations into decision making under risk have utilized a variety of more venerable theoretical models such as prospect theory that lack axiomatically desirable properties such as coherence. Here, we consider a particularly relevant risk measure for modeling human and animal planning, called conditional value-at-risk (CVaR), which quantifies worst-case outcomes (e.g., vehicle accidents or predation). We first adopt a conventional distributional approach to CVaR in a sequential setting and reanalyze the choices of human decision-makers in the well-known two-step task, revealing substantial risk aversion that had been lurking under stickiness and perseveration. We then consider a further critical property of risk sensitivity, namely time consistency, showing alternatives to this form of CVaR that enjoy this desirable characteristic. We use simulations to examine settings in which the various forms differ in ways that have implications for human and animal planning and behavior.
Unsupervised Spiking Instance Segmentation on Event Data using STDP
Nov 12, 2021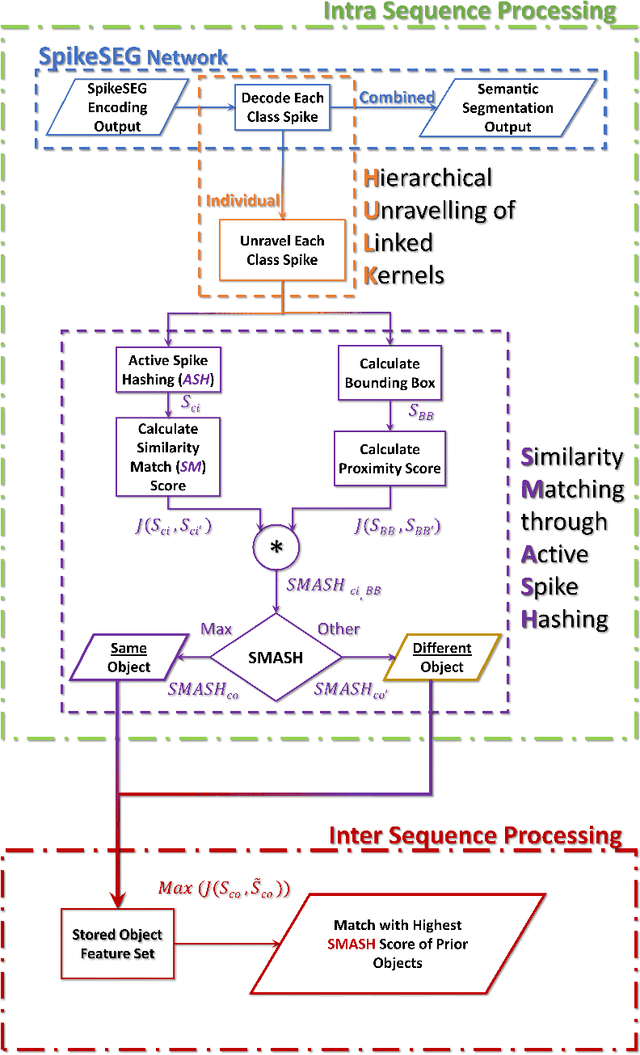
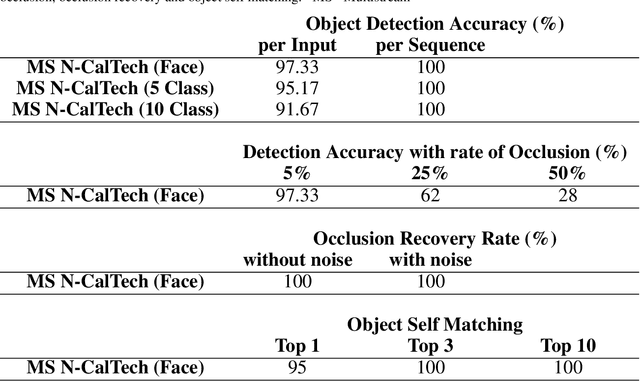
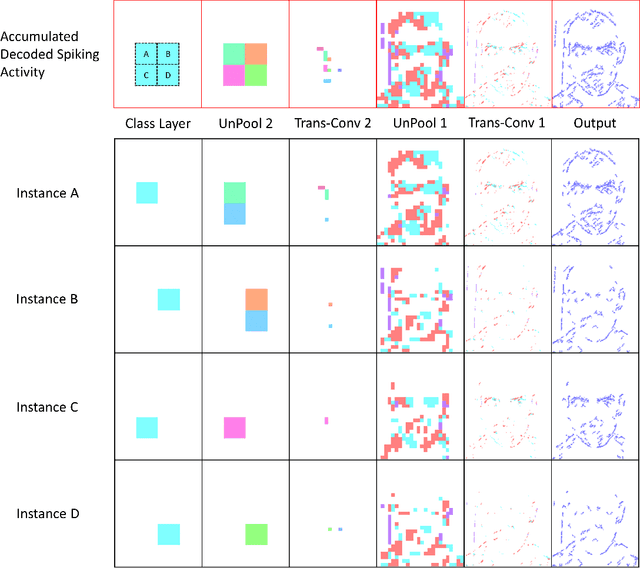
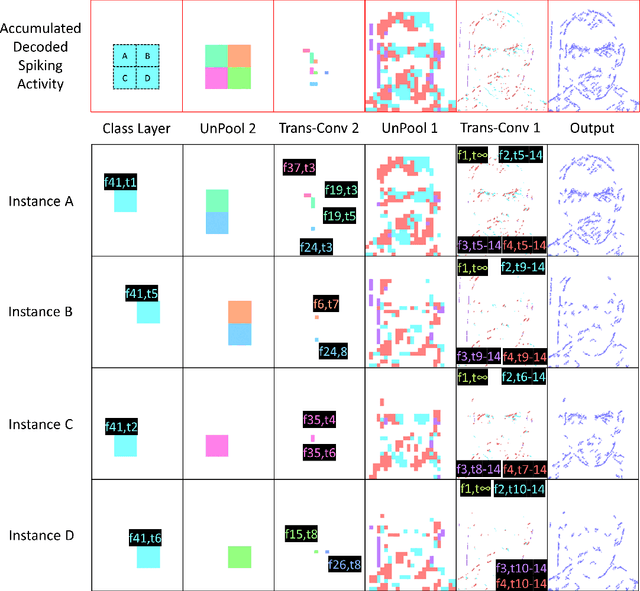
Spiking Neural Networks (SNN) and the field of Neuromorphic Engineering has brought about a paradigm shift in how to approach Machine Learning (ML) and Computer Vision (CV) problem. This paradigm shift comes from the adaption of event-based sensing and processing. An event-based vision sensor allows for sparse and asynchronous events to be produced that are dynamically related to the scene. Allowing not only the spatial information but a high-fidelity of temporal information to be captured. Meanwhile avoiding the extra overhead and redundancy of conventional high frame rate approaches. However, with this change in paradigm, many techniques from traditional CV and ML are not applicable to these event-based spatial-temporal visual streams. As such a limited number of recognition, detection and segmentation approaches exist. In this paper, we present a novel approach that can perform instance segmentation using just the weights of a Spike Time Dependent Plasticity trained Spiking Convolutional Neural Network that was trained for object recognition. This exploits the spatial and temporal aspects of the network's internal feature representations adding this new discriminative capability. We highlight the new capability by successfully transforming a single class unsupervised network for face detection into a multi-person face recognition and instance segmentation network.
Pyramidal Blur Aware X-Corner Chessboard Detector
Oct 26, 2021
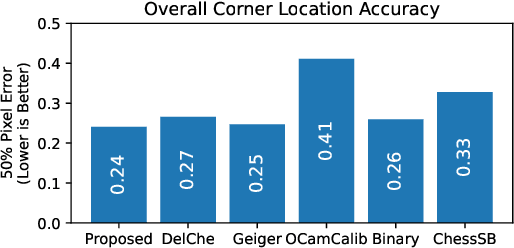
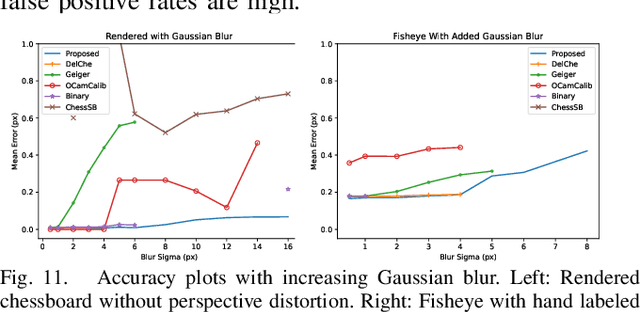
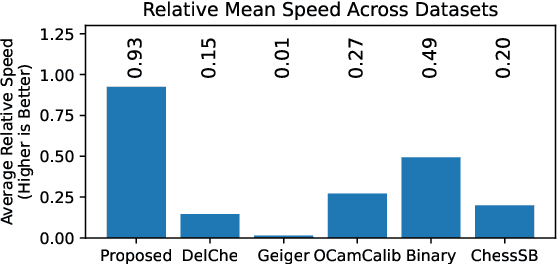
With camera resolution ever increasing and the need to rapidly recalibrate robotic platforms in less than ideal environments, there is a need for faster and more robust chessboard fiducial marker detectors. A new chessboard detector is proposed that is specifically designed for: high resolution images, focus/motion blur, harsh lighting conditions, and background clutter. This is accomplished using a new x-corner detector, where for the first time blur is estimated and used in a novel way to enhance corner localization, edge validation, and connectivity. Performance is measured and compared against other libraries using a diverse set of images created by combining multiple third party datasets and including new specially crafted scenarios designed to stress the state-of-the-art. The proposed detector has the best F1- Score of 0.97, runs 1.9x faster than next fastest, and is a top performer for corner accuracy, while being the only detector to have consistent good performance in all scenarios.
Can neural networks predict dynamics they have never seen?
Nov 12, 2021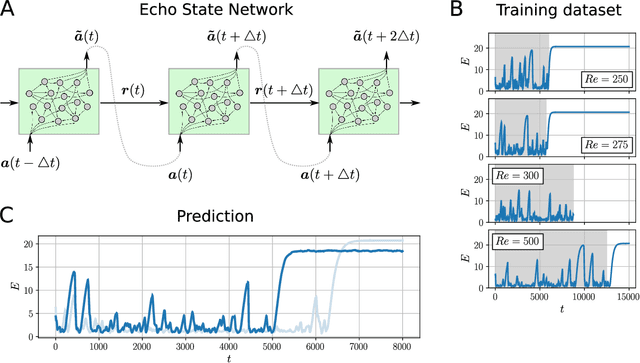
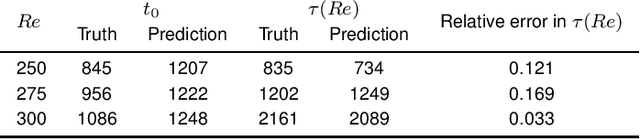
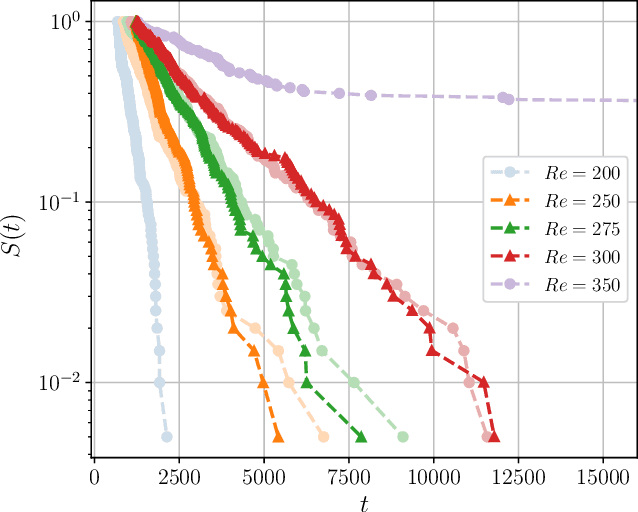
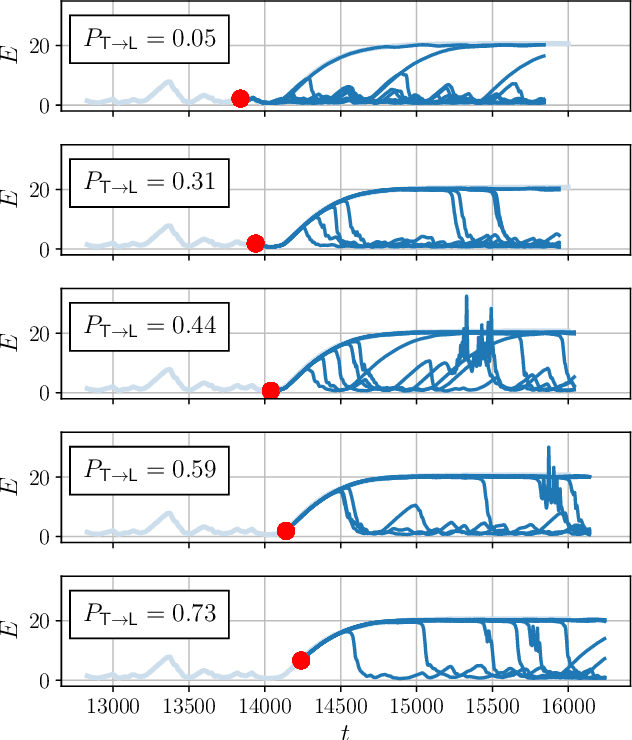
Neural networks have proven to be remarkably successful for a wide range of complicated tasks, from image recognition and object detection to speech recognition and machine translation. One of their successes is the skill in prediction of future dynamics given a suitable training set of data. Previous studies have shown how Echo State Networks (ESNs), a subset of Recurrent Neural Networks, can successfully predict even chaotic systems for times longer than the Lyapunov time. This study shows that, remarkably, ESNs can successfully predict dynamical behavior that is qualitatively different from any behavior contained in the training set. Evidence is provided for a fluid dynamics problem where the flow can transition between laminar (ordered) and turbulent (disordered) regimes. Despite being trained on the turbulent regime only, ESNs are found to predict laminar behavior. Moreover, the statistics of turbulent-to-laminar and laminar-to-turbulent transitions are also predicted successfully, and the utility of ESNs in acting as an early-warning system for transition is discussed. These results are expected to be widely applicable to data-driven modelling of temporal behaviour in a range of physical, climate, biological, ecological and finance models characterized by the presence of tipping points and sudden transitions between several competing states.
Contextual Combinatorial Volatile Bandits with Satisfying via Gaussian Processes
Nov 29, 2021
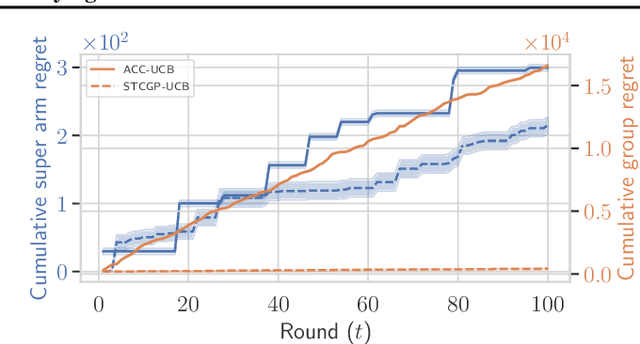
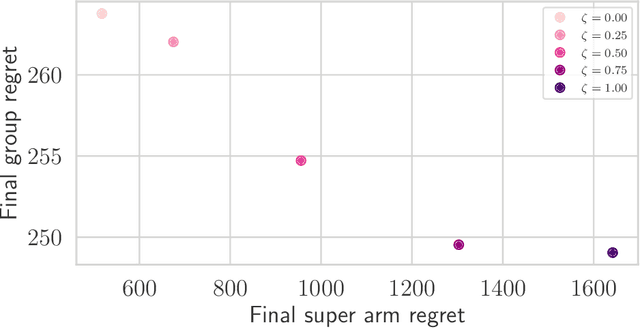
In many real-world applications of combinatorial bandits such as content caching, rewards must be maximized while satisfying minimum service requirements. In addition, base arm availabilities vary over time, and actions need to be adapted to the situation to maximize the rewards. We propose a new bandit model called Contextual Combinatorial Volatile Bandits with Group Thresholds to address these challenges. Our model subsumes combinatorial bandits by considering super arms to be subsets of groups of base arms. We seek to maximize super arm rewards while satisfying thresholds of all base arm groups that constitute a super arm. To this end, we define a new notion of regret that merges super arm reward maximization with group reward satisfaction. To facilitate learning, we assume that the mean outcomes of base arms are samples from a Gaussian Process indexed by the context set ${\cal X}$, and the expected reward is Lipschitz continuous in expected base arm outcomes. We propose an algorithm, called Thresholded Combinatorial Gaussian Process Upper Confidence Bounds (TCGP-UCB), that balances between maximizing cumulative reward and satisfying group reward thresholds and prove that it incurs $\tilde{O}(K\sqrt{T\overline{\gamma}_{T}} )$ regret with high probability, where $\overline{\gamma}_{T}$ is the maximum information gain associated with the set of base arm contexts that appeared in the first $T$ rounds and $K$ is the maximum super arm cardinality of any feasible action over all rounds. We show in experiments that our algorithm accumulates a reward comparable with that of the state-of-the-art combinatorial bandit algorithm while picking actions whose groups satisfy their thresholds.