 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-view Contrastive Self-Supervised Learning of Accounting Data Representations for Downstream Audit Tasks
Sep 23, 2021
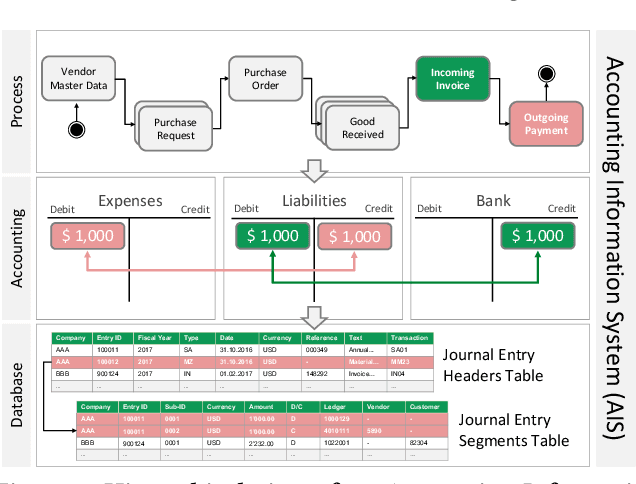
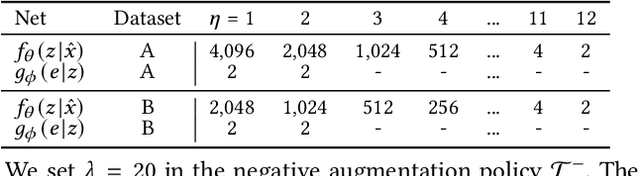
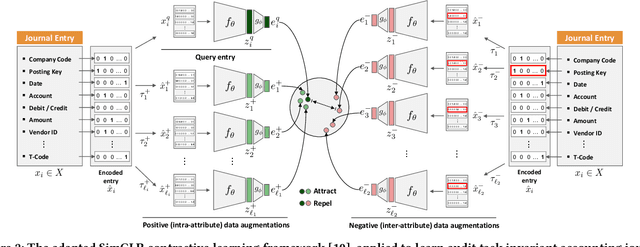
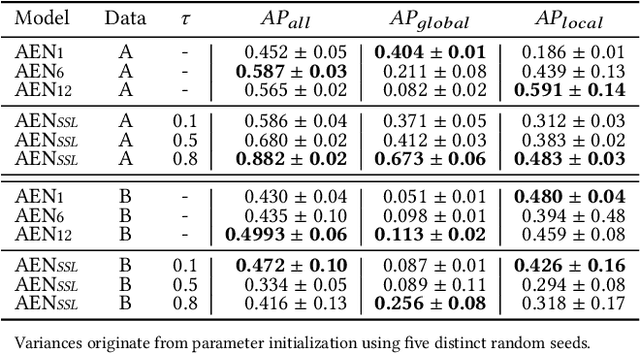
International audit standards require the direct assessment of a financial statement's underlying accounting transactions, referred to as journal entries. Recently, driven by the advances in artificial intelligence, deep learning inspired audit techniques have emerged in the field of auditing vast quantities of journal entry data. Nowadays, the majority of such methods rely on a set of specialized models, each trained for a particular audit task. At the same time, when conducting a financial statement audit, audit teams are confronted with (i) challenging time-budget constraints, (ii) extensive documentation obligations, and (iii) strict model interpretability requirements. As a result, auditors prefer to harness only a single preferably `multi-purpose' model throughout an audit engagement. We propose a contrastive self-supervised learning framework designed to learn audit task invariant accounting data representations to meet this requirement. The framework encompasses deliberate interacting data augmentation policies that utilize the attribute characteristics of journal entry data. We evaluate the framework on two real-world datasets of city payments and transfer the learned representations to three downstream audit tasks: anomaly detection, audit sampling, and audit documentation. Our experimental results provide empirical evidence that the proposed framework offers the ability to increase the efficiency of audits by learning rich and interpretable `multi-task' representations.
Learning Stable Koopman Embeddings
Oct 13, 2021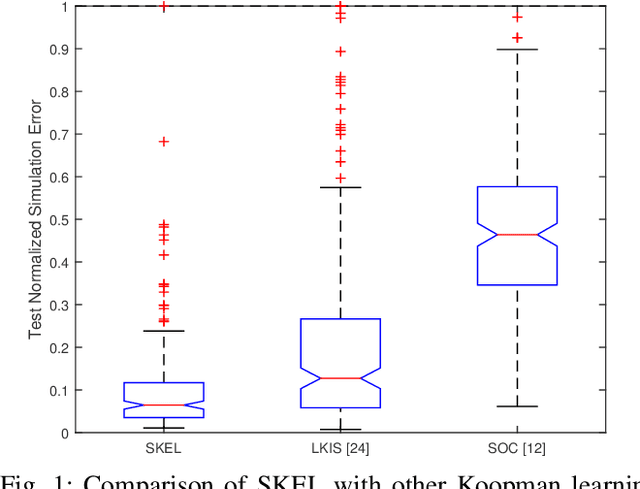
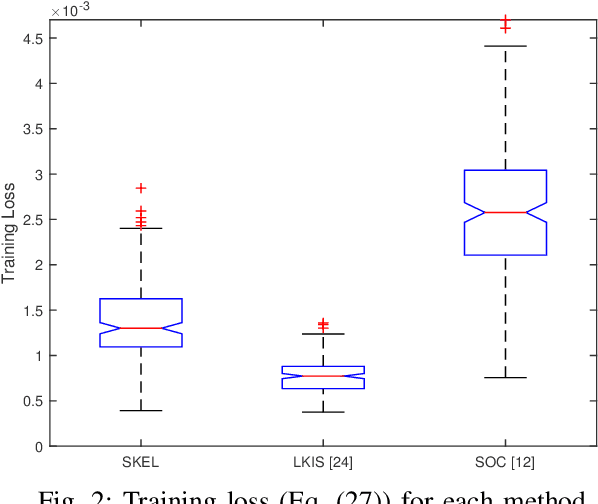
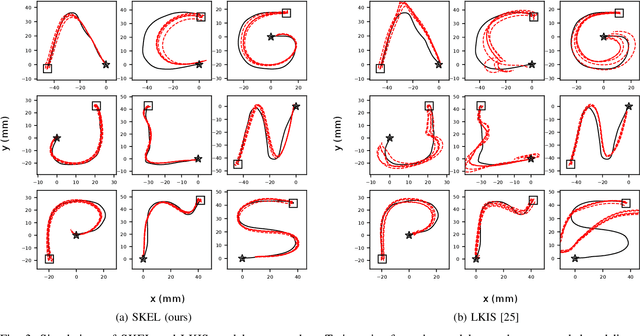
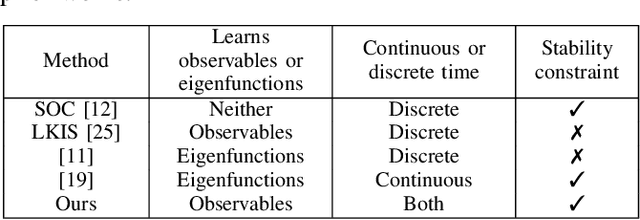
In this paper, we present a new data-driven method for learning stable models of nonlinear systems. Our model lifts the original state space to a higher-dimensional linear manifold using Koopman embeddings. Interestingly, we prove that every discrete-time nonlinear contracting model can be learnt in our framework. Another significant merit of the proposed approach is that it allows for unconstrained optimization over the Koopman embedding and operator jointly while enforcing stability of the model, via a direct parameterization of stable linear systems, greatly simplifying the computations involved. We validate our method on a simulated system and analyze the advantages of our parameterization compared to alternatives.
Enabling equivariance for arbitrary Lie groups
Nov 16, 2021
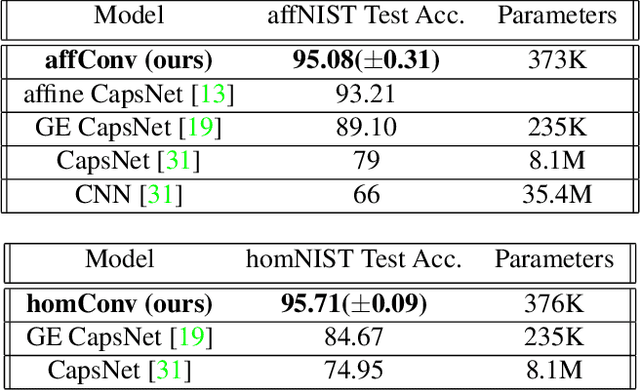
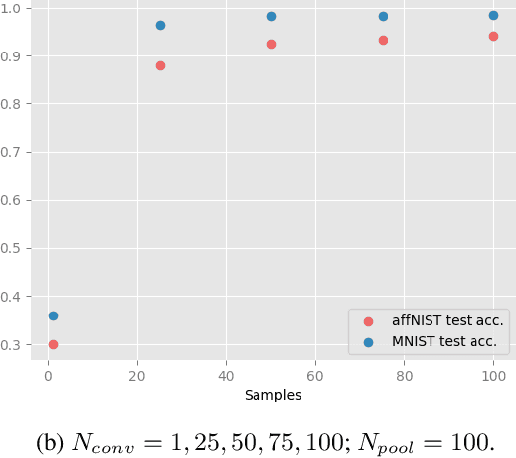
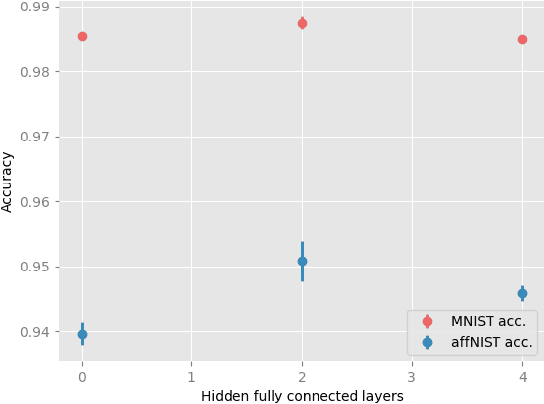
Although provably robust to translational perturbations, convolutional neural networks (CNNs) are known to suffer from extreme performance degradation when presented at test time with more general geometric transformations of inputs. Recently, this limitation has motivated a shift in focus from CNNs to Capsule Networks (CapsNets). However, CapsNets suffer from admitting relatively few theoretical guarantees of invariance. We introduce a rigourous mathematical framework to permit invariance to any Lie group of warps, exclusively using convolutions (over Lie groups), without the need for capsules. Previous work on group convolutions has been hampered by strong assumptions about the group, which precludes the application of such techniques to common warps in computer vision such as affine and homographic. Our framework enables the implementation of group convolutions over \emph{any} finite-dimensional Lie group. We empirically validate our approach on the benchmark affine-invariant classification task, where we achieve $\sim$30\% improvement in accuracy against conventional CNNs while outperforming the state-of-the-art CapsNet. As further illustration of the generality of our framework, we train a homography-convolutional model which achieves superior robustness on a homography-perturbed dataset, where CapsNet results degrade.
Dynamic Prediction Model for NOx Emission of SCR System Based on Hybrid Data-driven Algorithms
Aug 03, 2021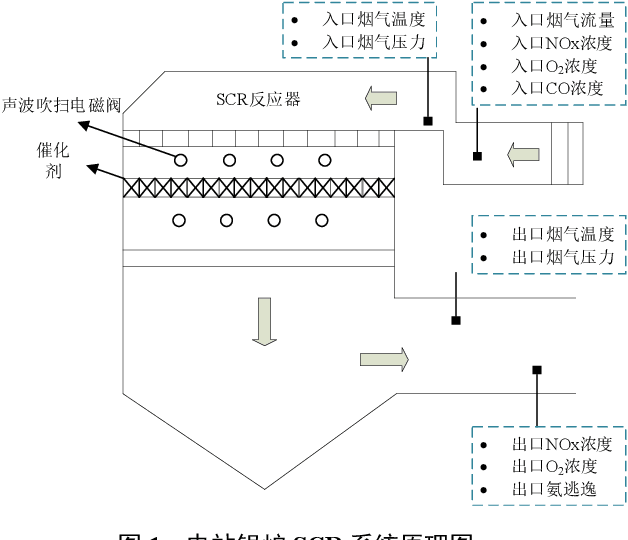
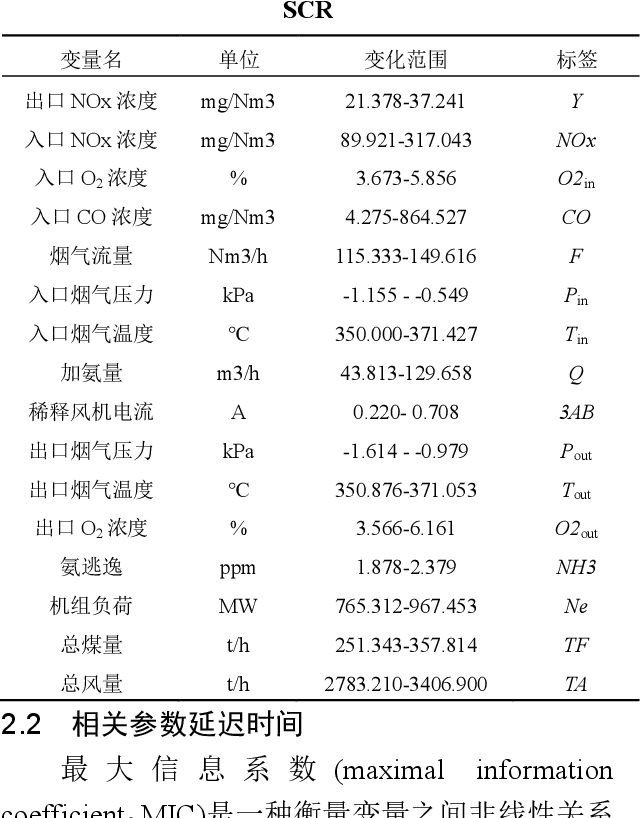
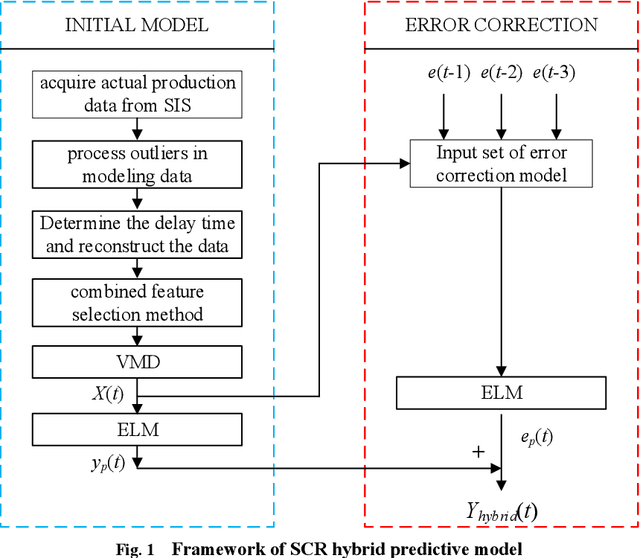
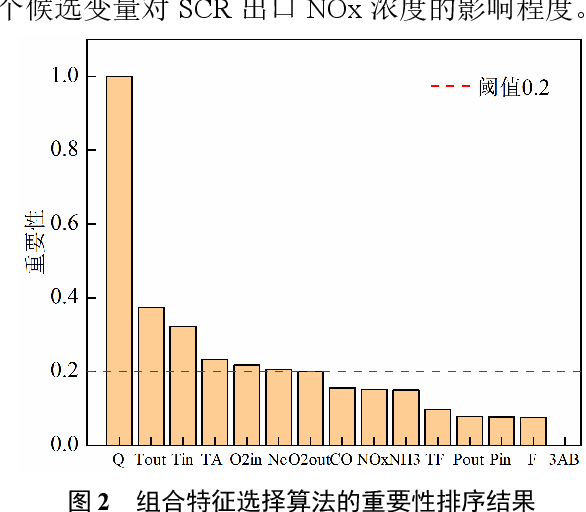
Aiming at the problem that delay time is difficult to determine and prediction accuracy is low in building prediction model of SCR system, a dynamic modeling scheme based on a hybrid of multiple data-driven algorithms was proposed. First, processed abnormal values and normalized the data. To improve the relevance of the input data, used MIC to estimate delay time and reconstructed production data. Then used combined feature selection method to determine input variables. To further mine data information, VMD was used to decompose input time series. Finally, established NOx emission prediction model combining ELM and EC model. Experimental results based on actual historical operating data show that the MAPE of predicted results is 2.61%. Model sensitivity analysis shows that besides the amount of ammonia injection, the inlet oxygen concentration and the flue gas temperature have a significant impact on NOx emission, which should be considered in SCR process control and optimization.
From One to Many: A Deep Learning Coincident Gravitational-Wave Search
Aug 24, 2021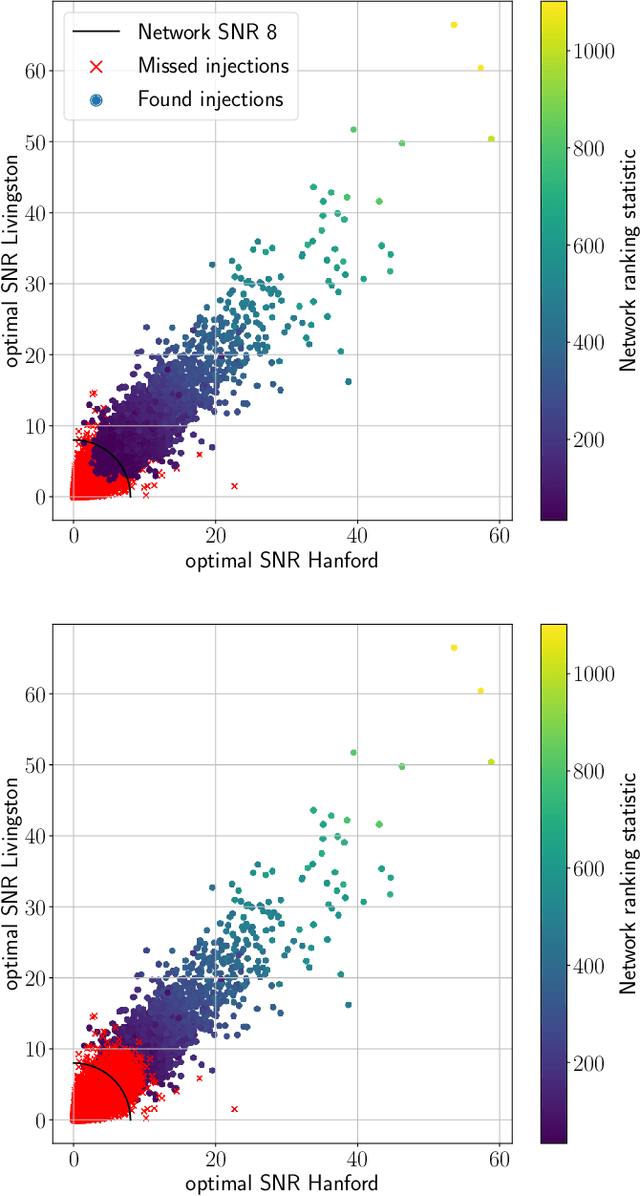
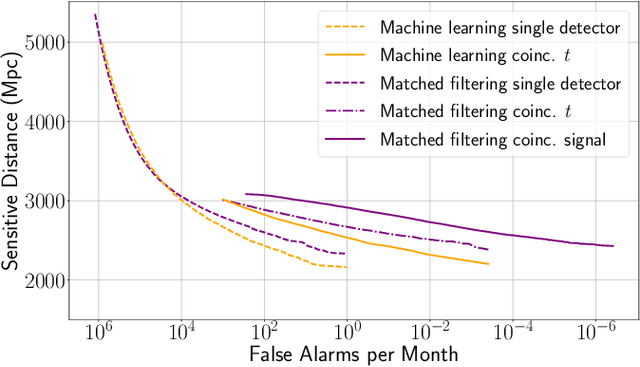
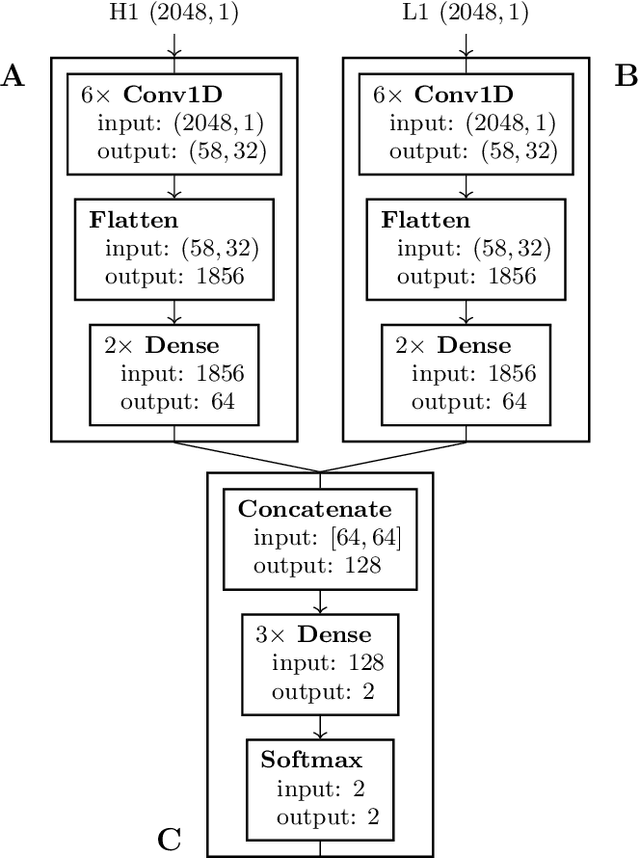
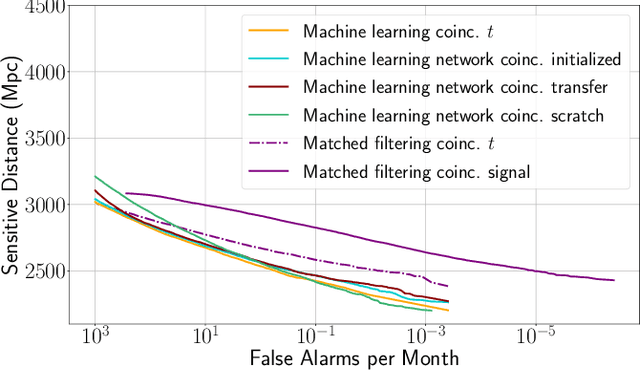
Gravitational waves from the coalescence of compact-binary sources are now routinely observed by Earth bound detectors. The most sensitive search algorithms convolve many different pre-calculated gravitational waveforms with the detector data and look for coincident matches between different detectors. Machine learning is being explored as an alternative approach to building a search algorithm that has the prospect to reduce computational costs and target more complex signals. In this work we construct a two-detector search for gravitational waves from binary black hole mergers using neural networks trained on non-spinning binary black hole data from a single detector. The network is applied to the data from both observatories independently and we check for events coincident in time between the two. This enables the efficient analysis of large quantities of background data by time-shifting the independent detector data. We find that while for a single detector the network retains $91.5\%$ of the sensitivity matched filtering can achieve, this number drops to $83.9\%$ for two observatories. To enable the network to check for signal consistency in the detectors, we then construct a set of simple networks that operate directly on data from both detectors. We find that none of these simple two-detector networks are capable of improving the sensitivity over applying networks individually to the data from the detectors and searching for time coincidences.
OVERT: An Algorithm for Safety Verification of Neural Network Control Policies for Nonlinear Systems
Aug 03, 2021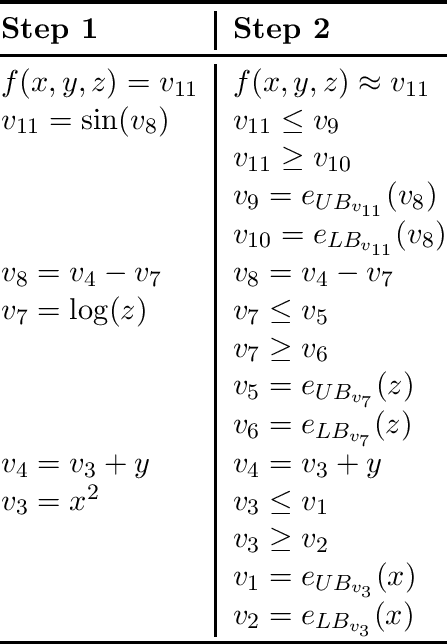
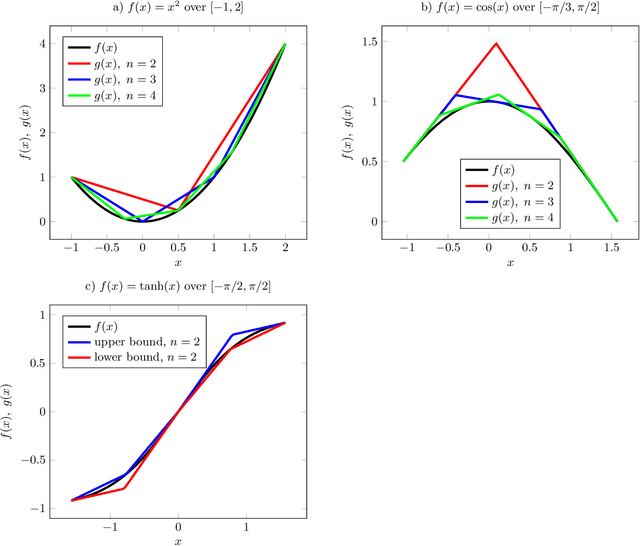

Deep learning methods can be used to produce control policies, but certifying their safety is challenging. The resulting networks are nonlinear and often very large. In response to this challenge, we present OVERT: a sound algorithm for safety verification of nonlinear discrete-time closed loop dynamical systems with neural network control policies. The novelty of OVERT lies in combining ideas from the classical formal methods literature with ideas from the newer neural network verification literature. The central concept of OVERT is to abstract nonlinear functions with a set of optimally tight piecewise linear bounds. Such piecewise linear bounds are designed for seamless integration into ReLU neural network verification tools. OVERT can be used to prove bounded-time safety properties by either computing reachable sets or solving feasibility queries directly. We demonstrate various examples of safety verification for several classical benchmark examples. OVERT compares favorably to existing methods both in computation time and in tightness of the reachable set.
A Machine-learning Based Initialization for Joint Statistical Iterative Dual-energy CT with Application to Proton Therapy
Jul 30, 2021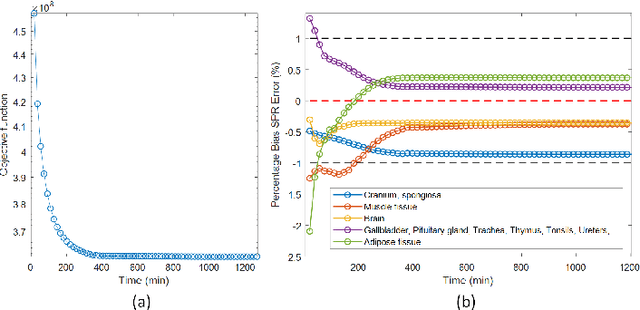
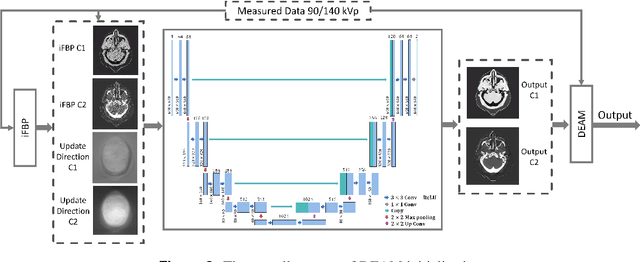
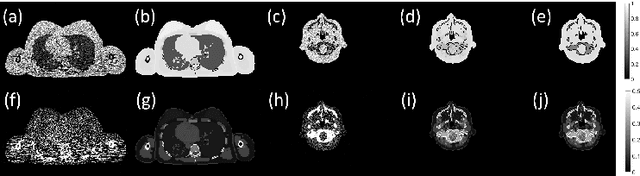
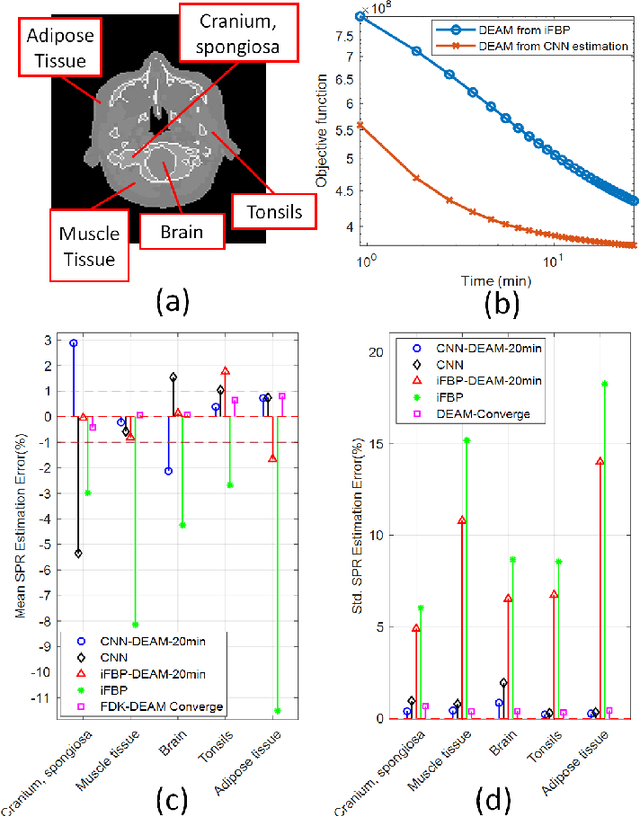
Dual-energy CT (DECT) has been widely investigated to generate more informative and more accurate images in the past decades. For example, Dual-Energy Alternating Minimization (DEAM) algorithm achieves sub-percentage uncertainty in estimating proton stopping-power mappings from experimental 3-mm collimated phantom data. However, elapsed time of iterative DECT algorithms is not clinically acceptable, due to their low convergence rate and the tremendous geometry of modern helical CT scanners. A CNN-based initialization method is introduced to reduce the computational time of iterative DECT algorithms. DEAM is used as an example of iterative DECT algorithms in this work. The simulation results show that our method generates denoised images with greatly improved estimation accuracy for adipose, tonsils, and muscle tissue. Also, it reduces elapsed time by approximately 5-fold for DEAM to reach the same objective function value for both simulated and real data.
Fighting Game Commentator with Pitch and Loudness Adjustment Utilizing Highlight Cues
Aug 18, 2021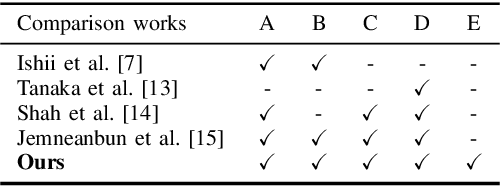
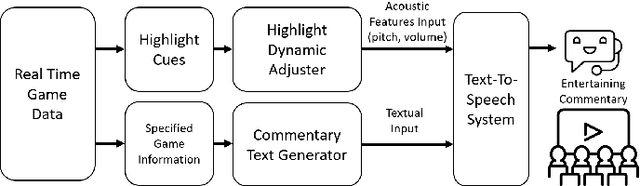


This paper presents a commentator for providing real-time game commentary in a fighting game. The commentary takes into account highlight cues, obtained by analyzing scenes during gameplay, as input to adjust the pitch and loudness of commentary to be spoken by using a Text-to-Speech (TTS) technology. We investigate different designs for pitch and loudness adjustment. The proposed AI consists of two parts: a dynamic adjuster for controlling pitch and loudness of the TTS and a real-time game commentary generator. We conduct a pilot study on a fighting game, and our result shows that by adjusting the loudness significantly according to the level of game highlight, the entertainment of the gameplay can be enhanced.
Learning Pruned Structure and Weights Simultaneously from Scratch: an Attention based Approach
Nov 01, 2021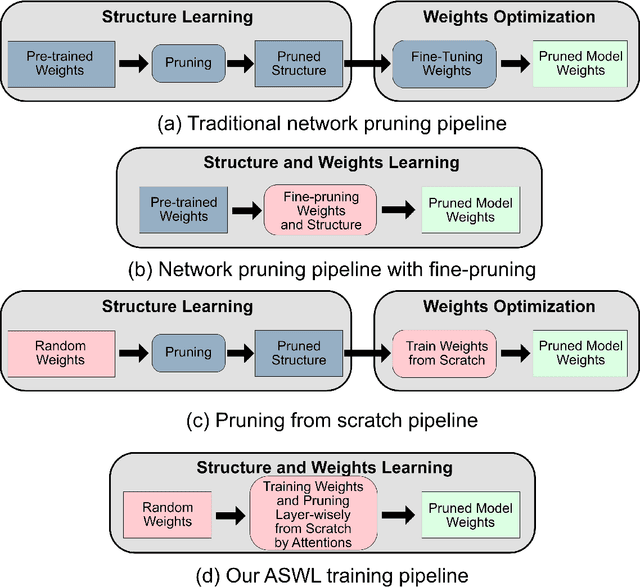
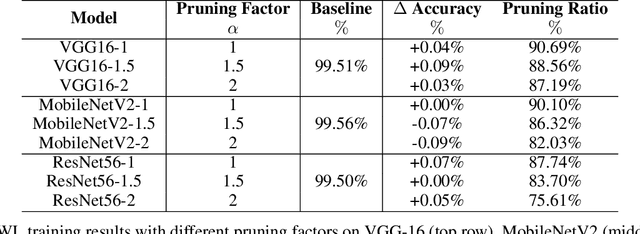
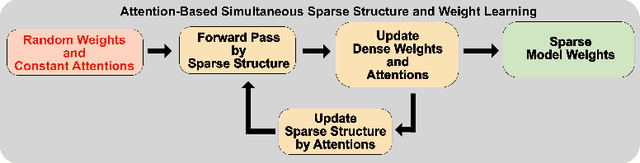
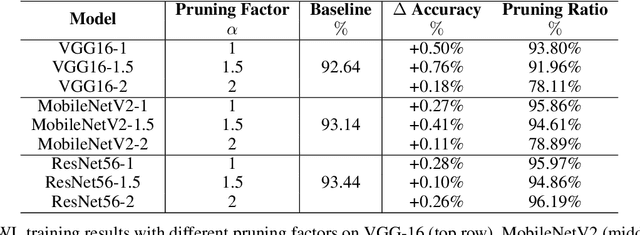
As a deep learning model typically contains millions of trainable weights, there has been a growing demand for a more efficient network structure with reduced storage space and improved run-time efficiency. Pruning is one of the most popular network compression techniques. In this paper, we propose a novel unstructured pruning pipeline, Attention-based Simultaneous sparse structure and Weight Learning (ASWL). Unlike traditional channel-wise or weight-wise attention mechanism, ASWL proposed an efficient algorithm to calculate the pruning ratio through layer-wise attention for each layer, and both weights for the dense network and the sparse network are tracked so that the pruned structure is simultaneously learned from randomly initialized weights. Our experiments on MNIST, Cifar10, and ImageNet show that ASWL achieves superior pruning results in terms of accuracy, pruning ratio and operating efficiency when compared with state-of-the-art network pruning methods.
Using Multilevel Circulant Matrix Approximate to Speed Up Kernel Logistic Regression
Aug 19, 2021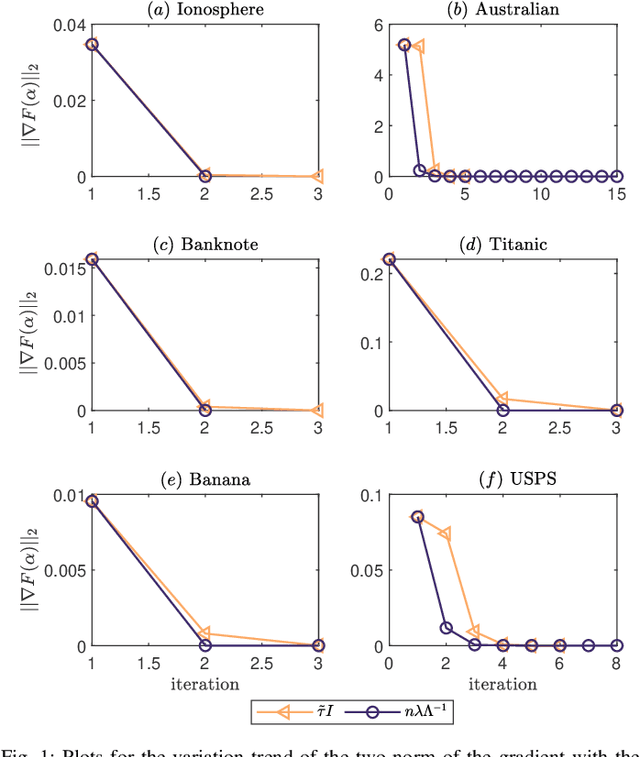
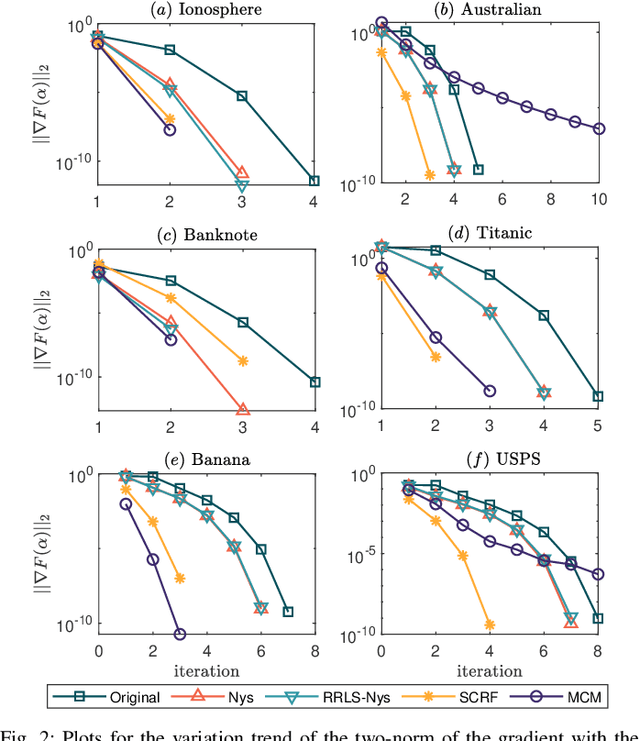
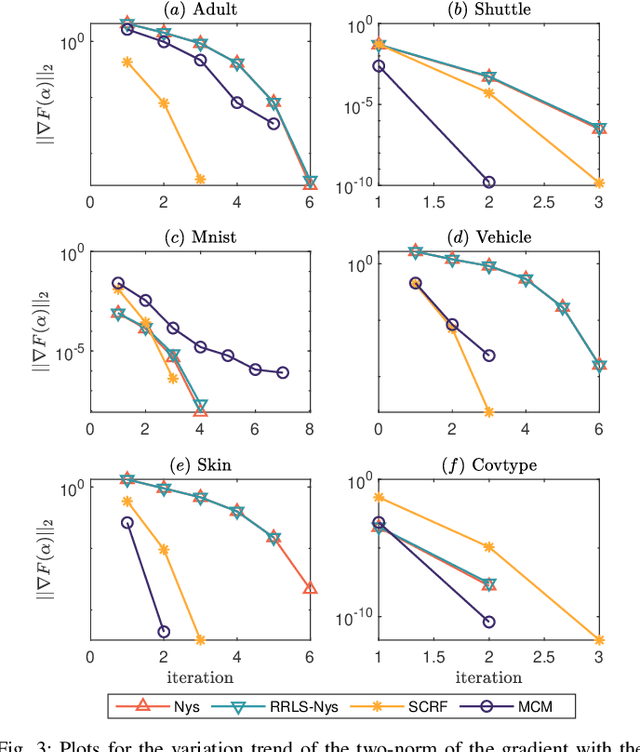
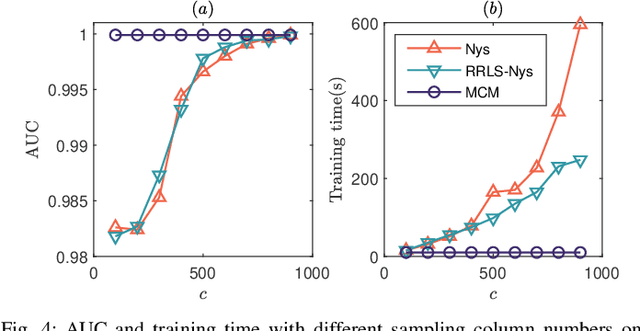
Kernel logistic regression (KLR) is a classical nonlinear classifier in statistical machine learning. Newton method with quadratic convergence rate can solve KLR problem more effectively than the gradient method. However, an obvious limitation of Newton method for training large-scale problems is the $O(n^{3})$ time complexity and $O(n^{2})$ space complexity, where $n$ is the number of training instances. In this paper, we employ the multilevel circulant matrix (MCM) approximate kernel matrix to save in storage space and accelerate the solution of the KLR. Combined with the characteristics of MCM and our ingenious design, we propose an MCM approximate Newton iterative method. We first simplify the Newton direction according to the semi-positivity of the kernel matrix and then perform a two-step approximation of the Newton direction by using MCM. Our method reduces the time complexity of each iteration to $O(n \log n)$ by using the multidimensional fast Fourier transform (mFFT). In addition, the space complexity can be reduced to $O(n)$ due to the built-in periodicity of MCM. Experimental results on some large-scale binary and multi-classification problems show that our method makes KLR scalable for large-scale problems, with less memory consumption, and converges to test accuracy without sacrifice in a shorter time.