 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Follow the Gradient: Crossing the Reality Gap using Differentiable Physics (RealityGrad)
Sep 10, 2021
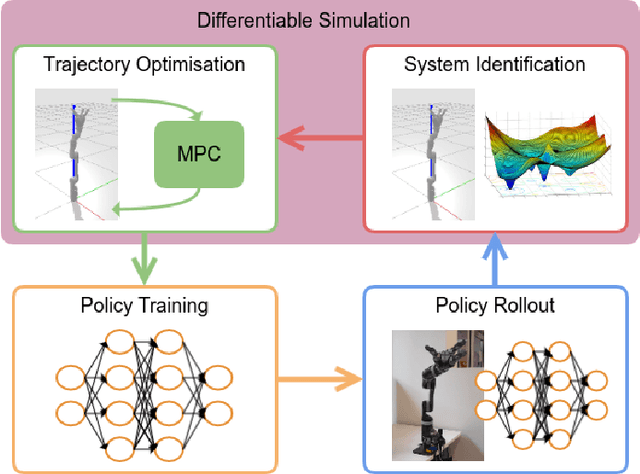

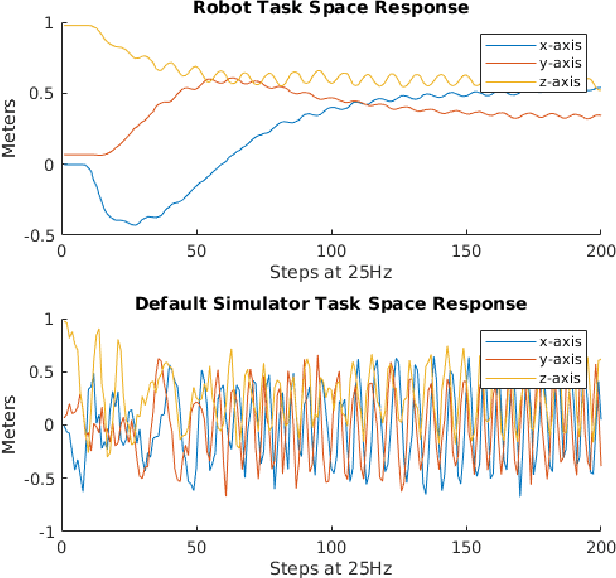
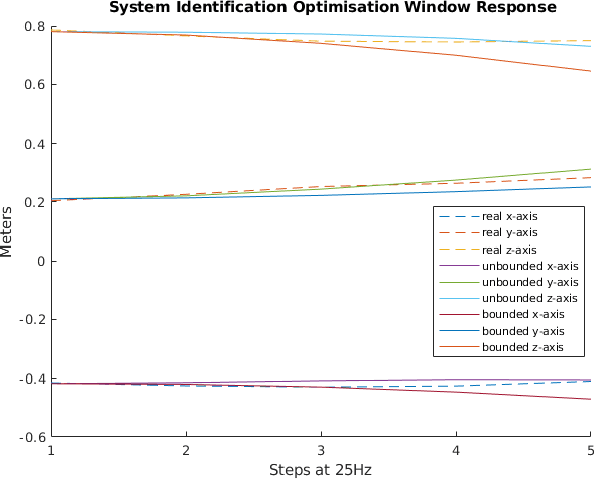
We propose a novel iterative approach for crossing the reality gap that utilises live robot rollouts and differentiable physics. Our method, RealityGrad, demonstrates for the first time, an efficient sim2real transfer in combination with a real2sim model optimisation for closing the reality gap. Differentiable physics has become an alluring alternative to classical rigid-body simulation due to the current culmination of automatic differentiation libraries, compute and non-linear optimisation libraries. Our method builds on this progress and employs differentiable physics for efficient trajectory optimisation. We demonstrate RealitGrad on a dynamic control task for a serial link robot manipulator and present results that show its efficiency and ability to quickly improve not just the robot's performance in real world tasks but also enhance the simulation model for future tasks. One iteration of RealityGrad takes less than 22 minutes on a desktop computer while reducing the error by 2/3, making it efficient compared to other sim2real methods in both compute and time. Our methodology and application of differentiable physics establishes a promising approach for crossing the reality gap and has great potential for scaling to complex environments.
Quantum Semi-Supervised Learning with Quantum Supremacy
Oct 05, 2021Quantum machine learning promises to efficiently solve important problems. There are two persistent challenges in classical machine learning: the lack of labeled data, and the limit of computational power. We propose a novel framework that resolves both issues: quantum semi-supervised learning. Moreover, we provide a protocol in systematically designing quantum machine learning algorithms with quantum supremacy, which can be extended beyond quantum semi-supervised learning. We showcase two concrete quantum semi-supervised learning algorithms: a quantum self-training algorithm named the propagating nearest-neighbor classifier, and the quantum semi-supervised K-means clustering algorithm. By doing time complexity analysis, we conclude that they indeed possess quantum supremacy.
Online estimation and control with optimal pathlength regret
Oct 24, 2021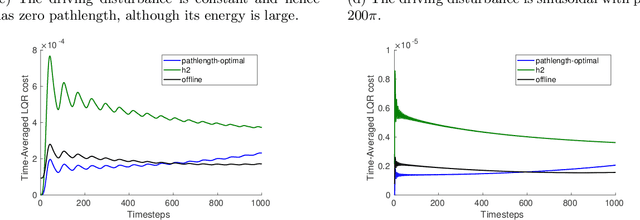
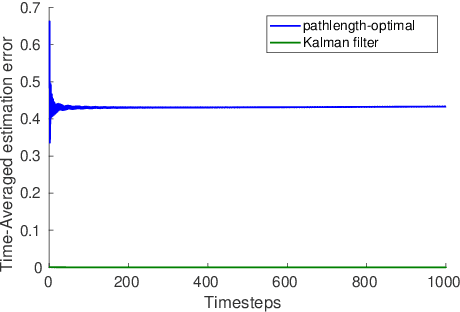
A natural goal when designing online learning algorithms for non-stationary environments is to bound the regret of the algorithm in terms of the temporal variation of the input sequence. Intuitively, when the variation is small, it should be easier for the algorithm to achieve low regret, since past observations are predictive of future inputs. Such data-dependent "pathlength" regret bounds have recently been obtained for a wide variety of online learning problems, including OCO and bandits. We obtain the first pathlength regret bounds for online control and estimation (e.g. Kalman filtering) in linear dynamical systems. The key idea in our derivation is to reduce pathlength-optimal filtering and control to certain variational problems in robust estimation and control; these reductions may be of independent interest. Numerical simulations confirm that our pathlength-optimal algorithms outperform traditional $H_2$ and $H_{\infty}$ algorithms when the environment varies over time.
GenReg: Deep Generative Method for Fast Point Cloud Registration
Nov 23, 2021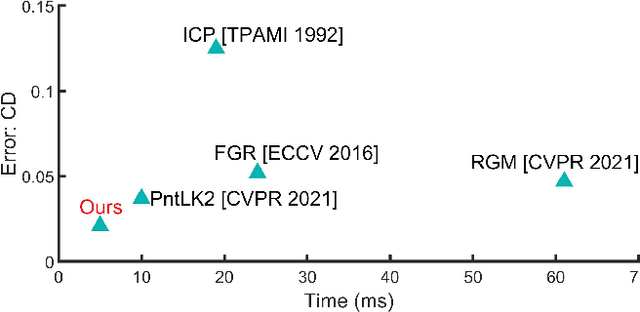


Accurate and efficient point cloud registration is a challenge because the noise and a large number of points impact the correspondence search. This challenge is still a remaining research problem since most of the existing methods rely on correspondence search. To solve this challenge, we propose a new data-driven registration algorithm by investigating deep generative neural networks to point cloud registration. Given two point clouds, the motivation is to generate the aligned point clouds directly, which is very useful in many applications like 3D matching and search. We design an end-to-end generative neural network for aligned point clouds generation to achieve this motivation, containing three novel components. Firstly, a point multi-perception layer (MLP) mixer (PointMixer) network is proposed to efficiently maintain both the global and local structure information at multiple levels from the self point clouds. Secondly, a feature interaction module is proposed to fuse information from cross point clouds. Thirdly, a parallel and differential sample consensus method is proposed to calculate the transformation matrix of the input point clouds based on the generated registration results. The proposed generative neural network is trained in a GAN framework by maintaining the data distribution and structure similarity. The experiments on both ModelNet40 and 7Scene datasets demonstrate that the proposed algorithm achieves state-of-the-art accuracy and efficiency. Notably, our method reduces $2\times$ in registration error (CD) and $12\times$ running time compared to the state-of-the-art correspondence-based algorithm.
WEST operation with real time feed back control based on wall component temperature toward machine protection in a steady state tungsten environment
Jan 06, 2021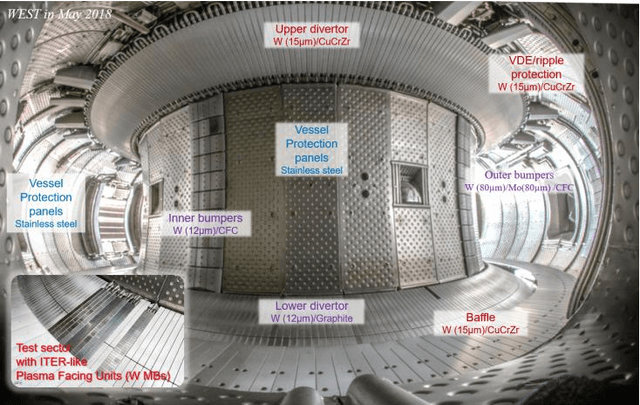
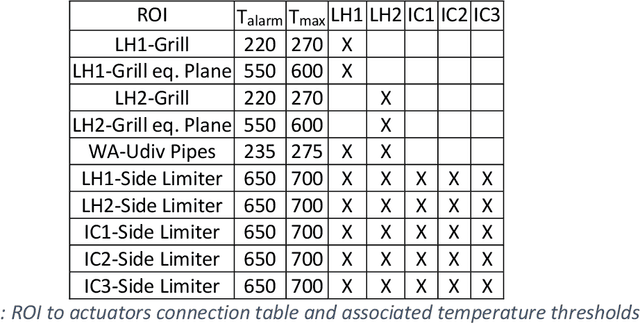
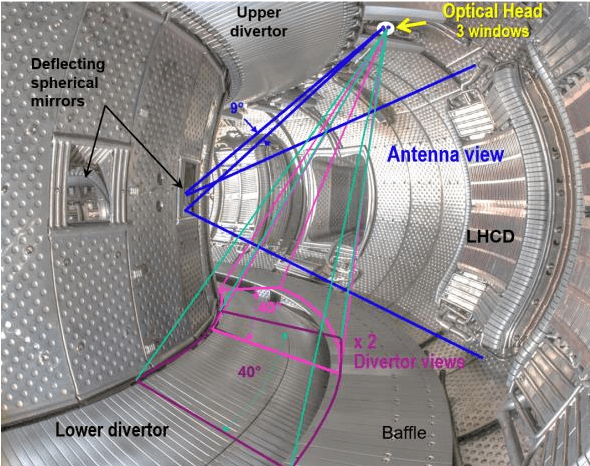

A real time Wall Monitoring System (WMS) is used on the WEST tokamak during the C4 experimental campaign. The WMS uses the wall surface temperatures from 6 fields of view of the Infrared viewing system. It extracts the raw digital data from selected areas, converts it to temperatures using the calibration and write it on the shared memory network being used by the Plasma Control System (PCS). The PCS feeds back to actuators, namely the injected power from 5 antennae's of the lower hybrid and ion cyclotron resonance radiofrequency (RF) heating systems. WMS activates feed back control 63 times during C4, which is 14% of the plasma discharges. It activates mainly as the result of a direct RF loss to the upper divertor pipes. The feedback control maintains the wall temperature within the operation envelope during 97% of the occurrences, while enabling plasma discharge continuation. The false positive rate establishes at 0.2%. WMS significantly facilitated the operation path to high power operation during C4, by managing the technical risks to critical wall components.
Real-Time Prediction of BITCOIN Price using Machine Learning Techniques and Public Sentiment Analysis
Jun 18, 2020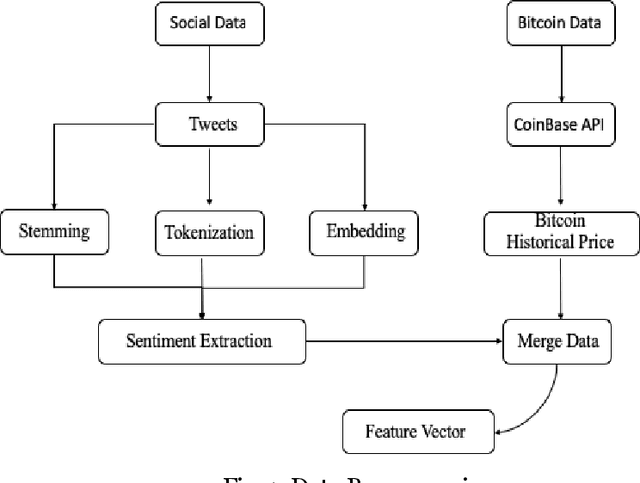
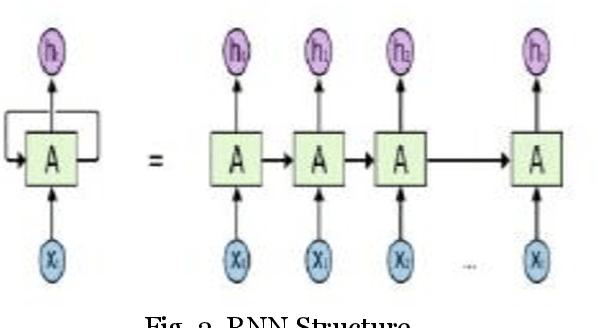
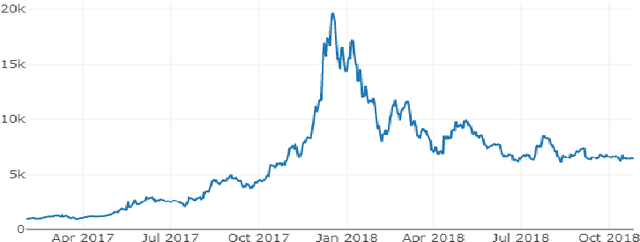
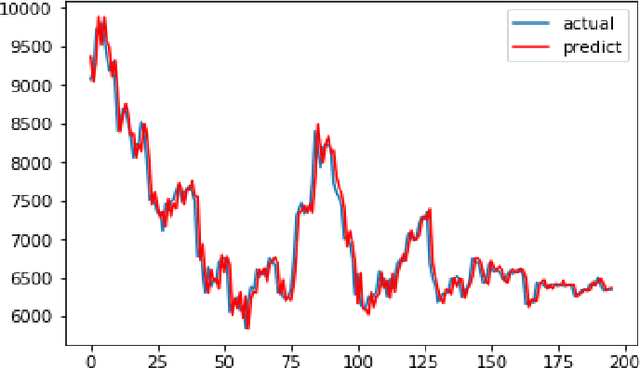
Bitcoin is the first digital decentralized cryptocurrency that has shown a significant increase in market capitalization in recent years. The objective of this paper is to determine the predictable price direction of Bitcoin in USD by machine learning techniques and sentiment analysis. Twitter and Reddit have attracted a great deal of attention from researchers to study public sentiment. We have applied sentiment analysis and supervised machine learning principles to the extracted tweets from Twitter and Reddit posts, and we analyze the correlation between bitcoin price movements and sentiments in tweets. We explored several algorithms of machine learning using supervised learning to develop a prediction model and provide informative analysis of future market prices. Due to the difficulty of evaluating the exact nature of a Time Series(ARIMA) model, it is often very difficult to produce appropriate forecasts. Then we continue to implement Recurrent Neural Networks (RNN) with long short-term memory cells (LSTM). Thus, we analyzed the time series model prediction of bitcoin prices with greater efficiency using long short-term memory (LSTM) techniques and compared the predictability of bitcoin price and sentiment analysis of bitcoin tweets to the standard method (ARIMA). The RMSE (Root-mean-square error) of LSTM are 198.448 (single feature) and 197.515 (multi-feature) whereas the ARIMA model RMSE is 209.263 which shows that LSTM with multi feature shows the more accurate result.
Neural Human Performer: Learning Generalizable Radiance Fields for Human Performance Rendering
Sep 15, 2021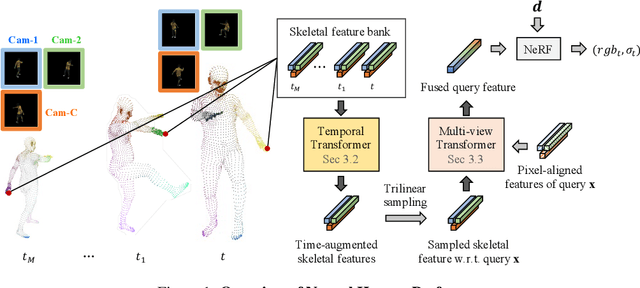
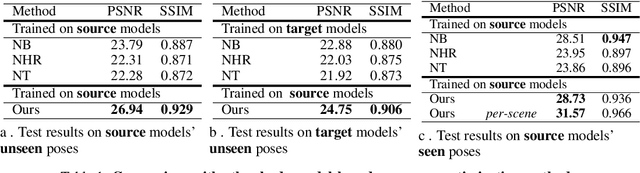


In this paper, we aim at synthesizing a free-viewpoint video of an arbitrary human performance using sparse multi-view cameras. Recently, several works have addressed this problem by learning person-specific neural radiance fields (NeRF) to capture the appearance of a particular human. In parallel, some work proposed to use pixel-aligned features to generalize radiance fields to arbitrary new scenes and objects. Adopting such generalization approaches to humans, however, is highly challenging due to the heavy occlusions and dynamic articulations of body parts. To tackle this, we propose Neural Human Performer, a novel approach that learns generalizable neural radiance fields based on a parametric human body model for robust performance capture. Specifically, we first introduce a temporal transformer that aggregates tracked visual features based on the skeletal body motion over time. Moreover, a multi-view transformer is proposed to perform cross-attention between the temporally-fused features and the pixel-aligned features at each time step to integrate observations on the fly from multiple views. Experiments on the ZJU-MoCap and AIST datasets show that our method significantly outperforms recent generalizable NeRF methods on unseen identities and poses. The video results and code are available at https://youngjoongunc.github.io/nhp.
Learning Disentangled Representations of Satellite Image Time Series
Mar 21, 2019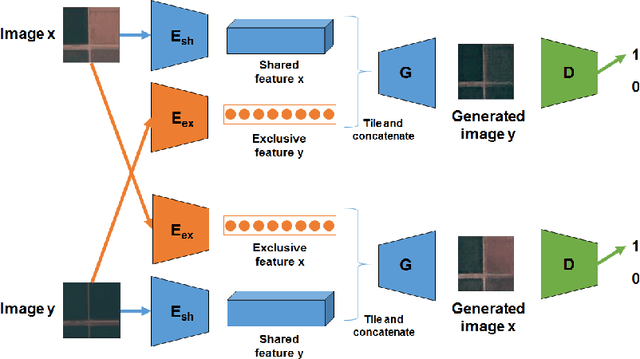
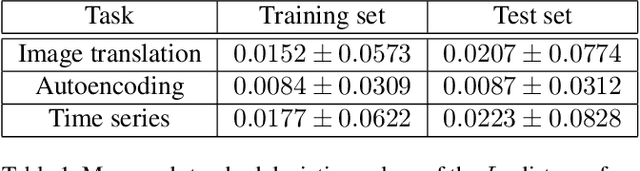
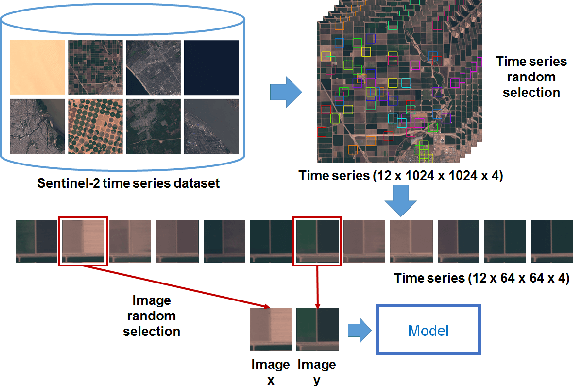
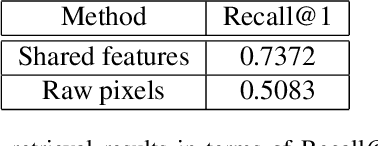
In this paper, we investigate how to learn a suitable representation of satellite image time series in an unsupervised manner by leveraging large amounts of unlabeled data. Additionally , we aim to disentangle the representation of time series into two representations: a shared representation that captures the common information between the images of a time series and an exclusive representation that contains the specific information of each image of the time series. To address these issues, we propose a model that combines a novel component called cross-domain autoencoders with the variational autoencoder (VAE) and generative ad-versarial network (GAN) methods. In order to learn disentangled representations of time series, our model learns the multimodal image-to-image translation task. We train our model using satellite image time series from the Sentinel-2 mission. Several experiments are carried out to evaluate the obtained representations. We show that these disentangled representations can be very useful to perform multiple tasks such as image classification, image retrieval, image segmentation and change detection.
Learning Correspondence from the Cycle-Consistency of Time
Apr 02, 2019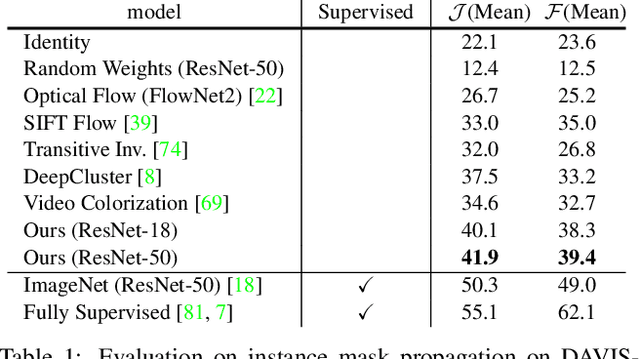
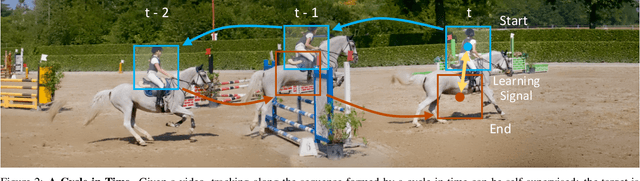
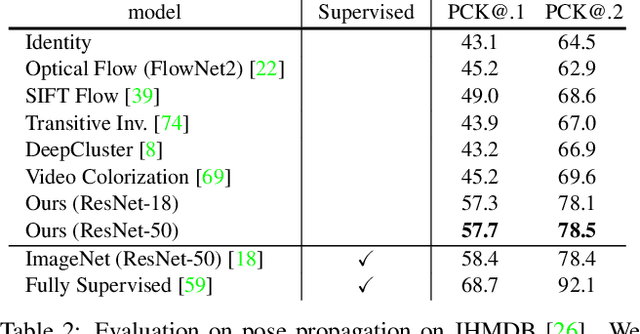
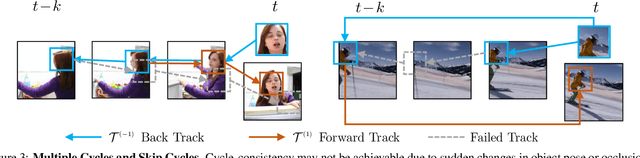
We introduce a self-supervised method for learning visual correspondence from unlabeled video. The main idea is to use cycle-consistency in time as free supervisory signal for learning visual representations from scratch. At training time, our model learns a feature map representation to be useful for performing cycle-consistent tracking. At test time, we use the acquired representation to find nearest neighbors across space and time. We demonstrate the generalizability of the representation -- without finetuning -- across a range of visual correspondence tasks, including video object segmentation, keypoint tracking, and optical flow. Our approach outperforms previous self-supervised methods and performs competitively with strongly supervised methods.
Low-Complexity Algorithm for Outage Optimal Resource Allocation in Energy Harvesting-Based UAV Identification Networks
Aug 18, 2021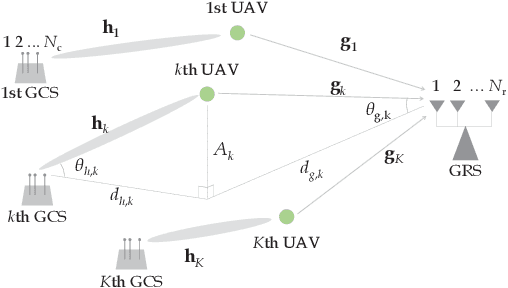
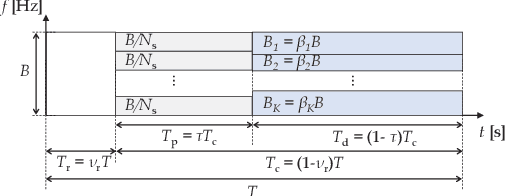
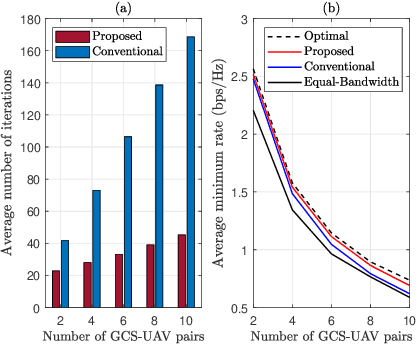
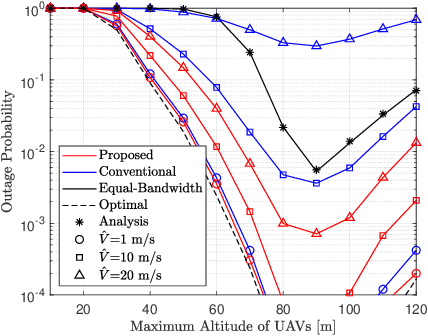
We study an unmanned aerial vehicle (UAV) identification network equipped with an energy harvesting (EH) technique. In the network, the UAVs harvest energy through radio frequency (RF) signals transmitted from ground control stations (GCSs) and then transmit their identification information to the ground receiver station (GRS). Specifically, we first derive a closed-form expression of the outage probability to evaluate the network performance. Then we obtain the closed-form expression of the optimal time allocation when the bandwidth is equally allocated to the UAVs. We also propose a fast-converging algorithm for time and the bandwidth allocation, which is necessary for the UAV environment with high mobility, to optimize the outage performance of EH-based UAV identification network. Simulation results show that the proposed algorithm outperforms the conventional bisection algorithm and achieves near-optimal performance.