 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RV-FuseNet: Range View based Fusion of Time-Series LiDAR Data for Joint 3D Object Detection and Motion Forecasting
May 21, 2020

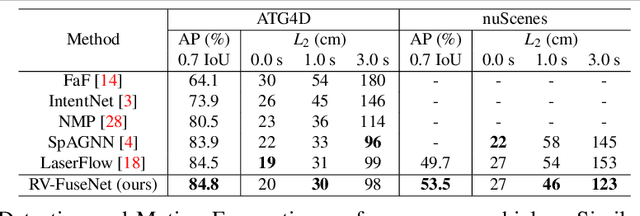
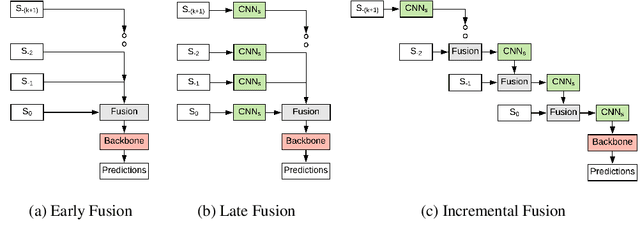

Autonomous vehicles rely on robust real-time detection and future motion prediction of traffic participants to safely navigate urban environments. We present a novel end-to-end approach that uses raw time-series LiDAR data to jointly solve both detection and prediction. We use the range view representation of LiDAR instead of voxelization since it does not discard information and is more efficient due to its compactness. However, for time-series fusion the data needs to be projected to a common viewpoint, and often this viewpoint is different from where it was captured leading to distortions. These distortions have an adverse impact on performance. Thus, we propose a novel architecture which reduces the impact of distortions by sequentially projecting each sweep into the viewpoint of the next sweep in time. We demonstrate that our sequential fusion approach is superior to methods that directly project all the data into the most recent viewpoint. Furthermore, we compare our approach to existing state-of-the art methods on multiple autonomous driving datasets and show competitive results.
Learning Generalized Gumbel-max Causal Mechanisms
Nov 11, 2021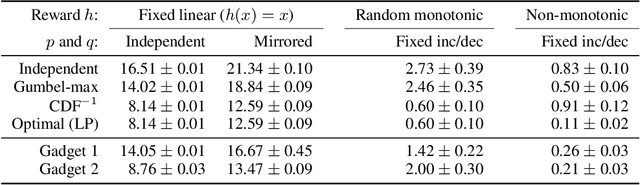
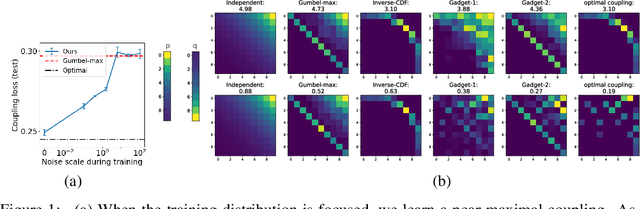

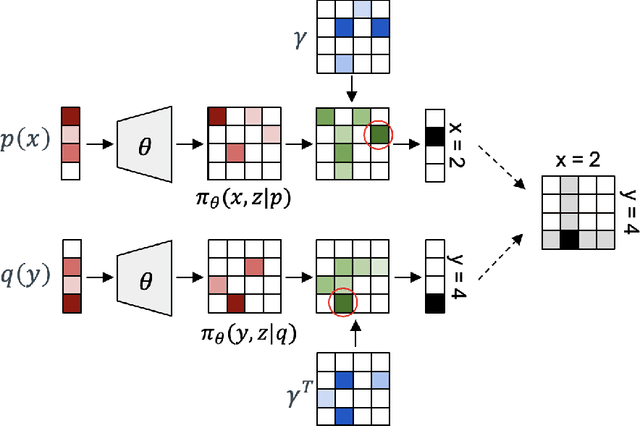
To perform counterfactual reasoning in Structural Causal Models (SCMs), one needs to know the causal mechanisms, which provide factorizations of conditional distributions into noise sources and deterministic functions mapping realizations of noise to samples. Unfortunately, the causal mechanism is not uniquely identified by data that can be gathered by observing and interacting with the world, so there remains the question of how to choose causal mechanisms. In recent work, Oberst & Sontag (2019) propose Gumbel-max SCMs, which use Gumbel-max reparameterizations as the causal mechanism due to an intuitively appealing counterfactual stability property. In this work, we instead argue for choosing a causal mechanism that is best under a quantitative criteria such as minimizing variance when estimating counterfactual treatment effects. We propose a parameterized family of causal mechanisms that generalize Gumbel-max. We show that they can be trained to minimize counterfactual effect variance and other losses on a distribution of queries of interest, yielding lower variance estimates of counterfactual treatment effect than fixed alternatives, also generalizing to queries not seen at training time.
Green CWS: Extreme Distillation and Efficient Decode Method Towards Industrial Application
Nov 17, 2021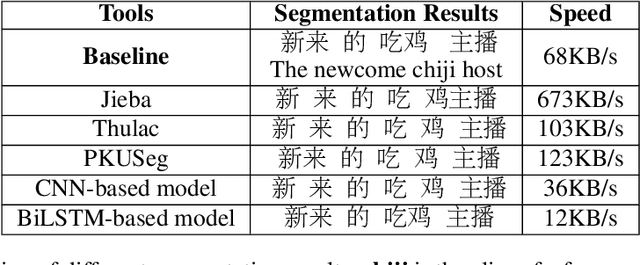
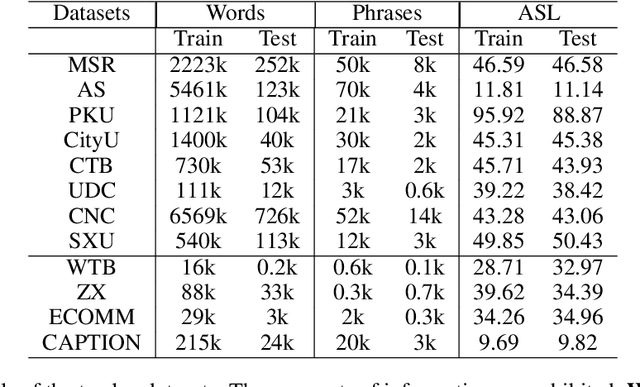
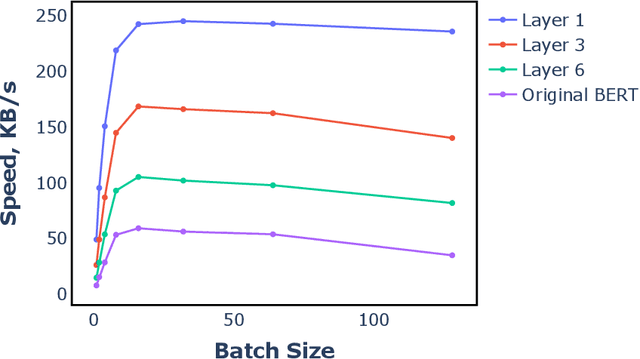
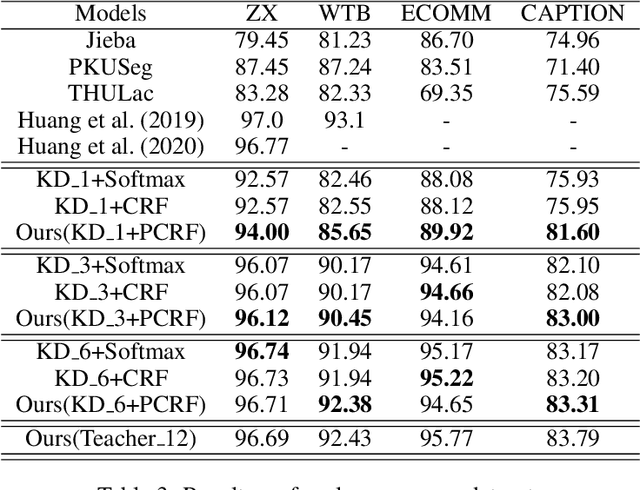
Benefiting from the strong ability of the pre-trained model, the research on Chinese Word Segmentation (CWS) has made great progress in recent years. However, due to massive computation, large and complex models are incapable of empowering their ability for industrial use. On the other hand, for low-resource scenarios, the prevalent decode method, such as Conditional Random Field (CRF), fails to exploit the full information of the training data. This work proposes a fast and accurate CWS framework that incorporates a light-weighted model and an upgraded decode method (PCRF) towards industrially low-resource CWS scenarios. First, we distill a Transformer-based student model as an encoder, which not only accelerates the inference speed but also combines open knowledge and domain-specific knowledge. Second, the perplexity score to evaluate the language model is fused into the CRF module to better identify the word boundaries. Experiments show that our work obtains relatively high performance on multiple datasets with as low as 14\% of time consumption compared with the original BERT-based model. Moreover, under the low-resource setting, we get superior results in comparison with the traditional decoding methods.
Real-Time Style Transfer With Strength Control
Apr 18, 2019

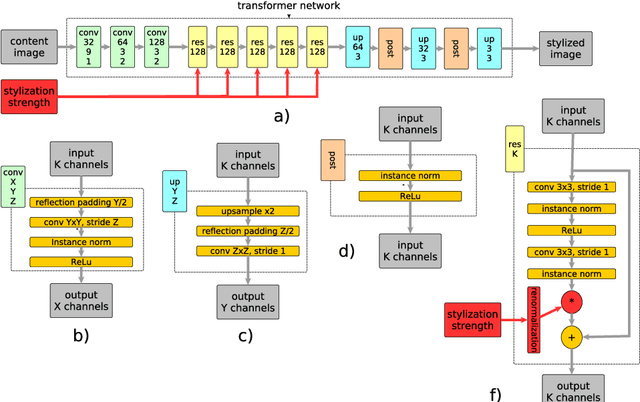

Style transfer is a problem of rendering a content image in the style of another style image. A natural and common practical task in applications of style transfer is to adjust the strength of stylization. Algorithm of Gatys et al. (2016) provides this ability by changing the weighting factors of content and style losses but is computationally inefficient. Real-time style transfer introduced by Johnson et al. (2016) enables fast stylization of any image by passing it through a pre-trained transformer network. Although fast, this architecture is not able to continuously adjust style strength. We propose an extension to real-time style transfer that allows direct control of style strength at inference, still requiring only a single transformer network. We conduct qualitative and quantitative experiments that demonstrate that the proposed method is capable of smooth stylization strength control and removes certain stylization artifacts appearing in the original real-time style transfer method. Comparisons with alternative real-time style transfer algorithms, capable of adjusting stylization strength, show that our method reproduces style with more details.
The Curious Layperson: Fine-Grained Image Recognition without Expert Labels
Nov 05, 2021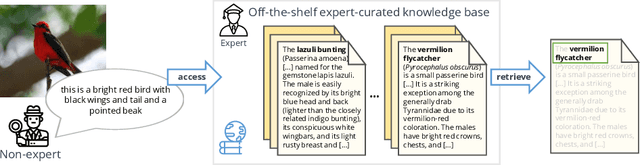
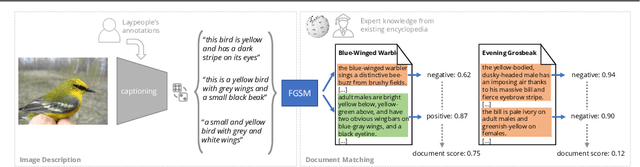
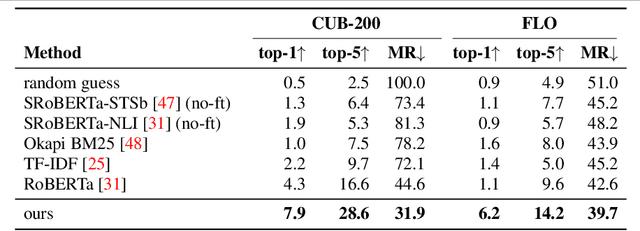
Most of us are not experts in specific fields, such as ornithology. Nonetheless, we do have general image and language understanding capabilities that we use to match what we see to expert resources. This allows us to expand our knowledge and perform novel tasks without ad-hoc external supervision. On the contrary, machines have a much harder time consulting expert-curated knowledge bases unless trained specifically with that knowledge in mind. Thus, in this paper we consider a new problem: fine-grained image recognition without expert annotations, which we address by leveraging the vast knowledge available in web encyclopedias. First, we learn a model to describe the visual appearance of objects using non-expert image descriptions. We then train a fine-grained textual similarity model that matches image descriptions with documents on a sentence-level basis. We evaluate the method on two datasets and compare with several strong baselines and the state of the art in cross-modal retrieval. Code is available at: https://github.com/subhc/clever
Enabling Cell-Free Massive MIMO Systems with Wireless Millimeter Wave Fronthaul
Oct 18, 2021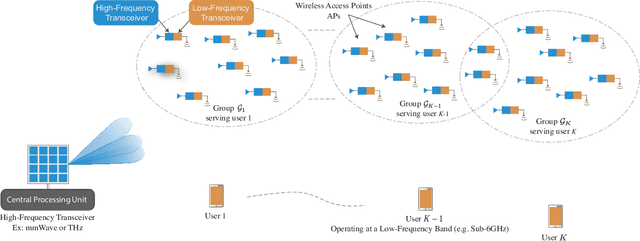
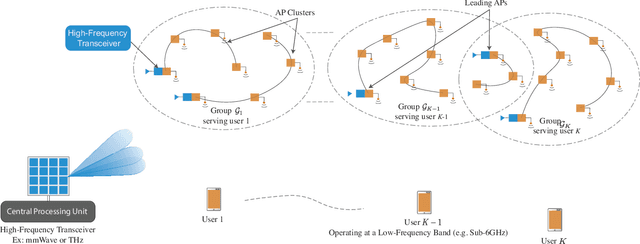
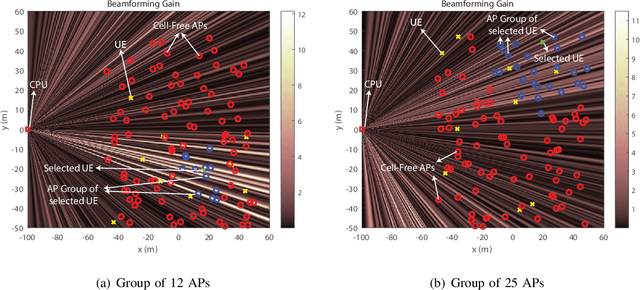
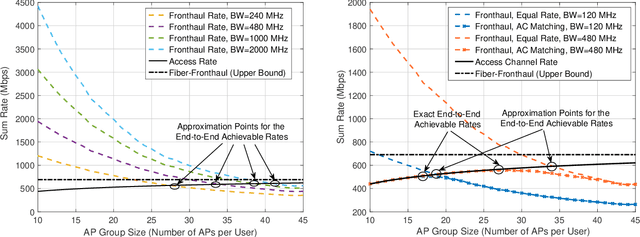
Cell-free massive MIMO systems have promising data rate and uniform coverage gains. These systems, however, typically rely on optical fiber based fronthaul for the communication between the central processing unit (CPU) and the distributed access points (APs), which increases the infrastructure cost, leads to high installation time, and limits the deployment flexibility and adaptability. To address these challenges, this paper proposes two architectures for cell-free massive MIMO systems based on wireless fronthaul that is operating at a \textit{higher-band} compared to the access links: (i) A wireless-only fronthaul architecture where the CPU has a wireless fronthaul link to each AP, and (ii) a mixed-fronthaul architecture where the CPU has a wireless link to each cluster of APs that are connected together via optical fibers. These dual-band architectures ensure high-data rate fronthaul and provide high capability to synchronize the distributed APs. Further, the wireless fronthaul reduces the infrastructure cost and installation time, and enhances the flexibility, adaptability, and scalability of the network deployment. To investigate the achievable data rates with the proposed architectures, we formulate the end-to-end data rate optimization problem accounting for the various practical aspects of the fronthaul and access links. Then, we develop a low-complexity yet efficient joint beamforming and resource allocation solution for the proposed architectures based on user-centric AP grouping. With this solution, we show that the proposed architectures can achieve comparable data rates to those obtained with optical fiber-based fronthaul under realistic assumptions on the fronthaul bandwidth, hardware constraints, and deployment scenarios. This highlights a promising path for realizing the cell-free massive MIMO gains in practice while reducing the infrastructure and deployment overhead.
CNN-based Omnidirectional Object Detection for HermesBot Autonomous Delivery Robot with Preliminary Frame Classification
Oct 22, 2021
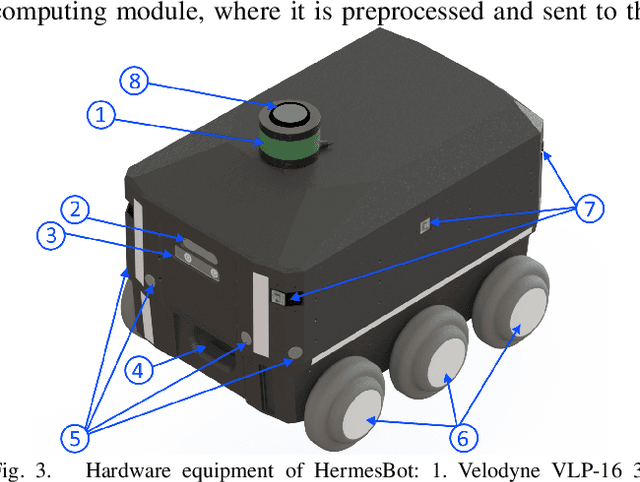
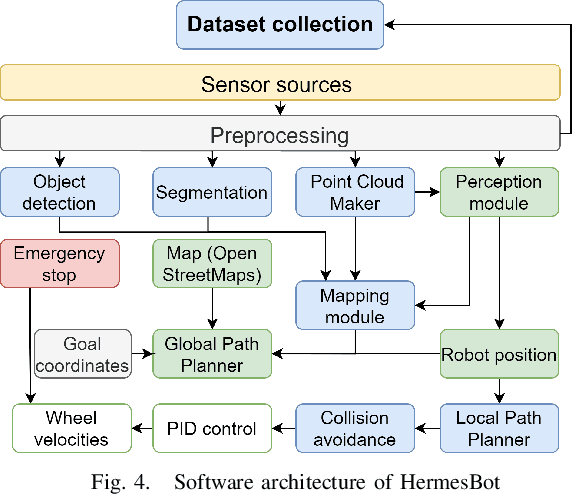
Mobile autonomous robots include numerous sensors for environment perception. Cameras are an essential tool for robot's localization, navigation, and obstacle avoidance. To process a large flow of data from the sensors, it is necessary to optimize algorithms, or to utilize substantial computational power. In our work, we propose an algorithm for optimizing a neural network for object detection using preliminary binary frame classification. An autonomous outdoor mobile robot with 6 rolling-shutter cameras on the perimeter providing a 360-degree field of view was used as the experimental setup. The obtained experimental results revealed that the proposed optimization accelerates the inference time of the neural network in the cases with up to 5 out of 6 cameras containing target objects.
Expert Human-Level Driving in Gran Turismo Sport Using Deep Reinforcement Learning with Image-based Representation
Nov 11, 2021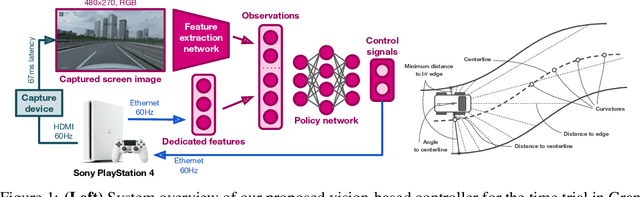

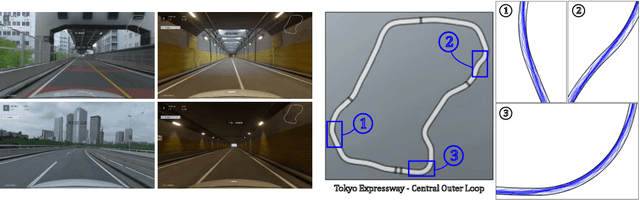
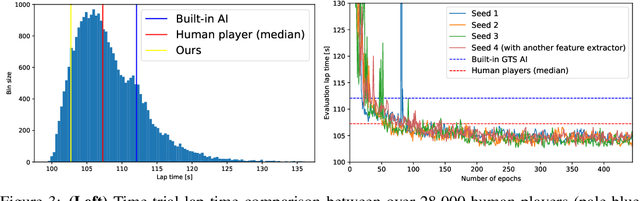
When humans play virtual racing games, they use visual environmental information on the game screen to understand the rules within the environments. In contrast, a state-of-the-art realistic racing game AI agent that outperforms human players does not use image-based environmental information but the compact and precise measurements provided by the environment. In this paper, a vision-based control algorithm is proposed and compared with human player performances under the same conditions in realistic racing scenarios using Gran Turismo Sport (GTS), which is known as a high-fidelity realistic racing simulator. In the proposed method, the environmental information that constitutes part of the observations in conventional state-of-the-art methods is replaced with feature representations extracted from game screen images. We demonstrate that the proposed method performs expert human-level vehicle control under high-speed driving scenarios even with game screen images as high-dimensional inputs. Additionally, it outperforms the built-in AI in GTS in a time trial task, and its score places it among the top 10% approximately 28,000 human players.
Predicting Antimicrobial Resistance in the Intensive Care Unit
Nov 05, 2021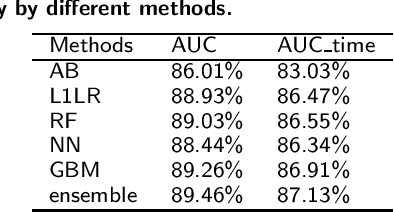
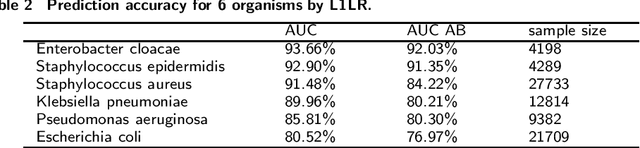

Antimicrobial resistance (AMR) is a risk for patients and a burden for the healthcare system. However, AMR assays typically take several days. This study develops predictive models for AMR based on easily available clinical and microbiological predictors, including patient demographics, hospital stay data, diagnoses, clinical features, and microbiological/antimicrobial characteristics and compares those models to a naive antibiogram based model using only microbiological/antimicrobial characteristics. The ability to predict the resistance accurately prior to culturing could inform clinical decision-making and shorten time to action. The machine learning algorithms employed here show improved classification performance (area under the receiver operating characteristic curve 0.88-0.89) versus the naive model (area under the receiver operating characteristic curve 0.86) for 6 organisms and 10 antibiotics using the Philips eICU Research Institute (eRI) database. This method can help guide antimicrobial treatment, with the objective of improving patient outcomes and reducing the usage of unnecessary or ineffective antibiotics.
GRATIS: GeneRAting TIme Series with diverse and controllable characteristics
Mar 07, 2019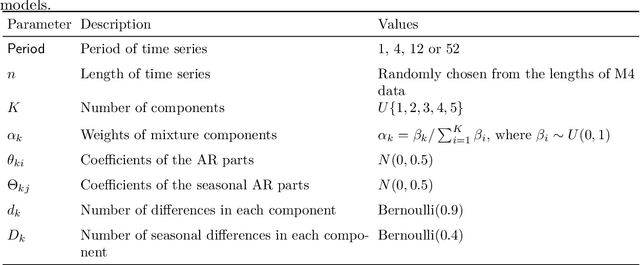
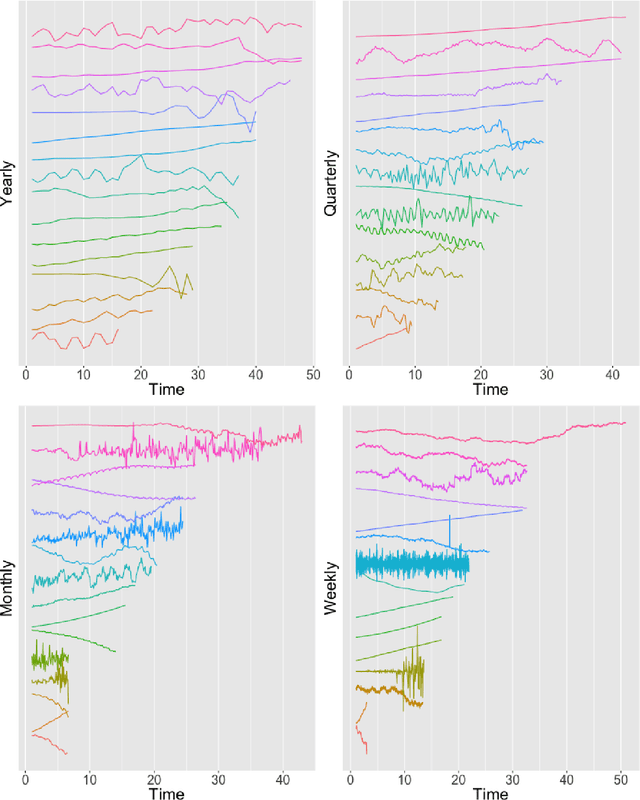

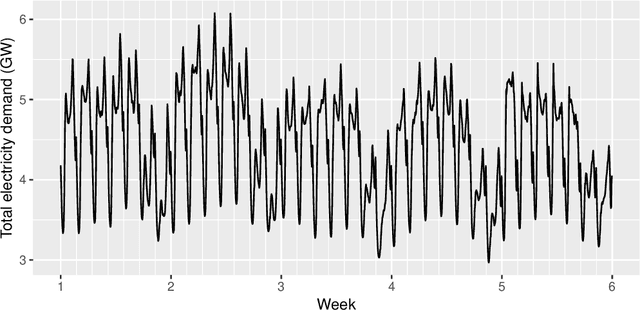
The explosion of time series data in recent years has brought a flourish of new time series analysis methods, for forecasting, clustering, classification and other tasks. The evaluation of these new methods requires a diverse collection of time series benchmarking data to enable reliable comparisons against alternative approaches. We propose GeneRAting TIme Series with diverse and controllable characteristics, named GRATIS, with the use of mixture autoregressive (MAR) models. We generate sets of time series using MAR models and investigate the diversity and coverage of the generated time series in a time series feature space. By tuning the parameters of the MAR models, GRATIS is also able to efficiently generate new time series with controllable features. In general, as a costless surrogate to the traditional data collection approach, GRATIS can be used as an evaluation tool for tasks such as time series forecasting and classification. We illustrate the usefulness of our time series generation process through a time series forecasting application.