 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Analysis of Thompson Sampling for Partially Observable Contextual Multi-Armed Bandits
Oct 23, 2021
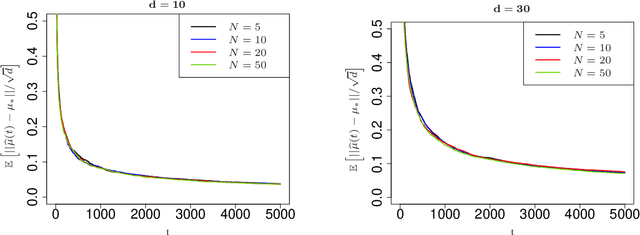
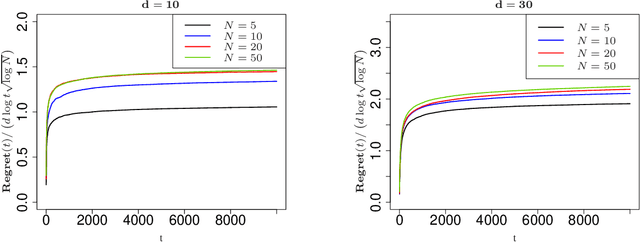
Contextual multi-armed bandits are classical models in reinforcement learning for sequential decision-making associated with individual information. A widely-used policy for bandits is Thompson Sampling, where samples from a data-driven probabilistic belief about unknown parameters are used to select the control actions. For this computationally fast algorithm, performance analyses are available under full context-observations. However, little is known for problems that contexts are not fully observed. We propose a Thompson Sampling algorithm for partially observable contextual multi-armed bandits, and establish theoretical performance guarantees. Technically, we show that the regret of the presented policy scales logarithmically with time and the number of arms, and linearly with the dimension. Further, we establish rates of learning unknown parameters, and provide illustrative numerical analyses.
Out-of-Zone Signal Leakage Sensing in Radio Dynamic Zones
Nov 18, 2021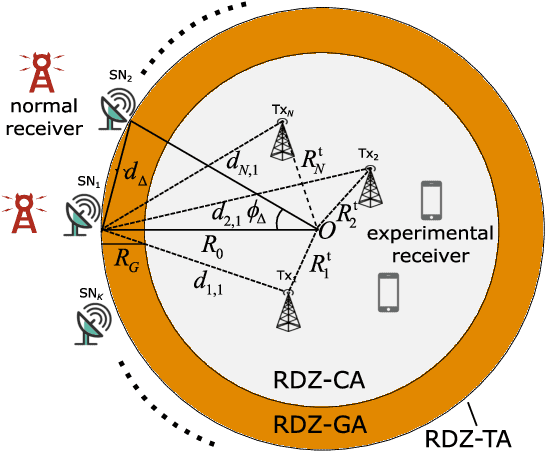
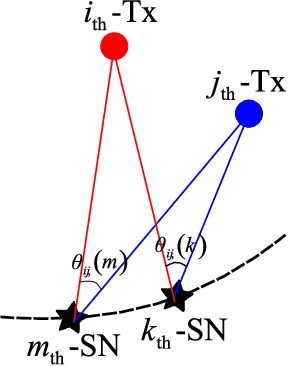
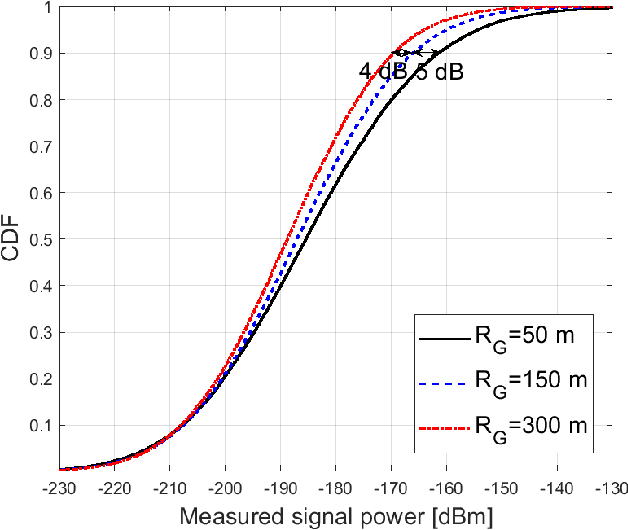
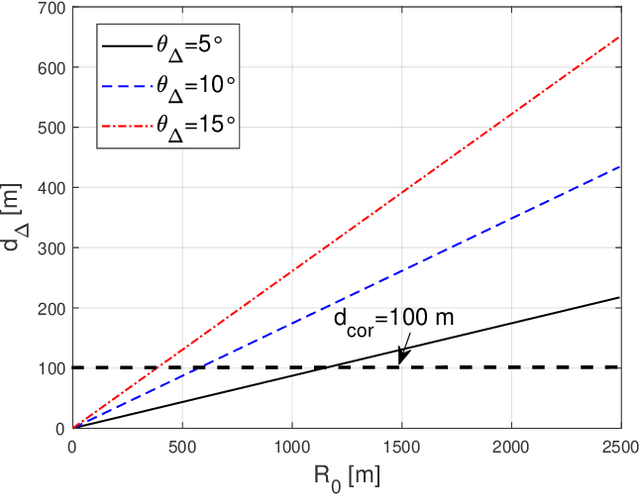
Radio dynamic zones (RDZs) are geographically bounded areas where novel advanced wireless technologies can be developed, tested, and improved, without the concern of interfering to other incumbent radio technologies nearby the RDZ. In order to operate an RDZ, use of a real-time spectrum monitoring system carries critical importance. Such a monitoring system should detect out-of-zone (OoZ) signal leakage outside of the RDZ, and if the interference to nearby receivers is intolerable, the monitoring system should be capable of mitigating such interference. This can e.g. be achieved by stopping operations inside the RDZ or switching to other bands for RDZ operation. In this paper, we introduce a spectrum monitoring concept for OoZ signal leakage detection at RDZs, where sensor nodes (SNs) are installed at the boundary of an RDZ and monitor the power leakage from multiple transmitters within the RDZ. We propose a prediction algorithm that estimates the received interference at OoZ geographical locations outside of the RDZ, using the measurements obtained at sparsely located SNs at the RDZ boundary. Using computer simulations, we evaluate the performance of the proposed algorithm and study its sensitivity to SN deployment density.
Comparing Prophet and Deep Learning to ARIMA in Forecasting Wholesale Food Prices
Aug 16, 2021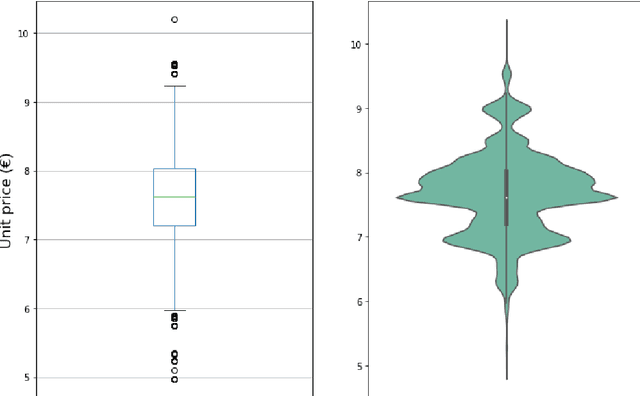
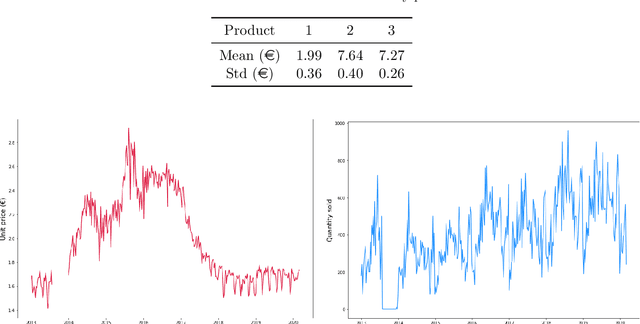
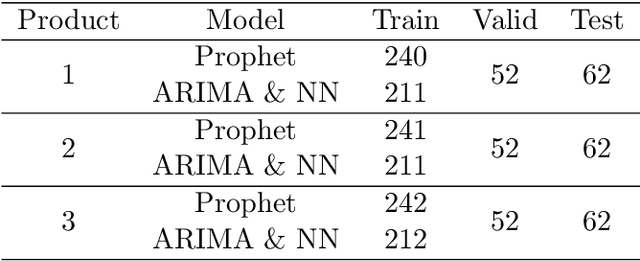
Setting sale prices correctly is of great importance for firms, and the study and forecast of prices time series is therefore a relevant topic not only from a data science perspective but also from an economic and applicative one. In this paper we examine different techniques to forecast sale prices applied by an Italian food wholesaler, as a step towards the automation of pricing tasks usually taken care by human workforce. We consider ARIMA models and compare them to Prophet, a scalable forecasting tool by Facebook based on a generalized additive model, and to deep learning models exploiting Long Short--Term Memory (LSTM) and Convolutional Neural Networks (CNNs). ARIMA models are frequently used in econometric analyses, providing a good benchmark for the problem under study. Our results indicate that ARIMA models and LSTM neural networks perform similarly for the forecasting task under consideration, while the combination of CNNs and LSTMs attains the best overall accuracy, but requires more time to be tuned. On the contrary, Prophet is quick and easy to use, but considerably less accurate.t overall accuracy, but requires more time to be tuned. On the contrary, Prophet is quick and easy to use, but considerably less accurate.
A Deep Learning Inference Scheme Based on Pipelined Matrix Multiplication Acceleration Design and Non-uniform Quantization
Oct 10, 2021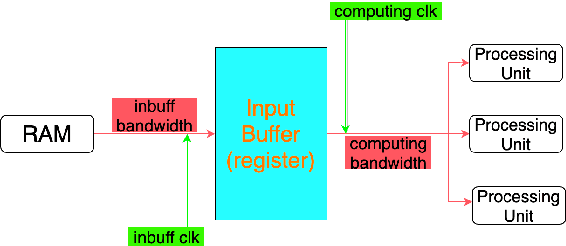
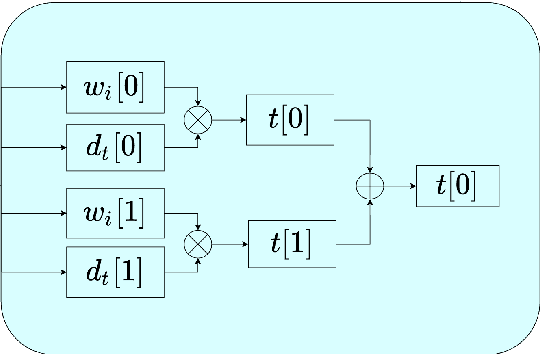
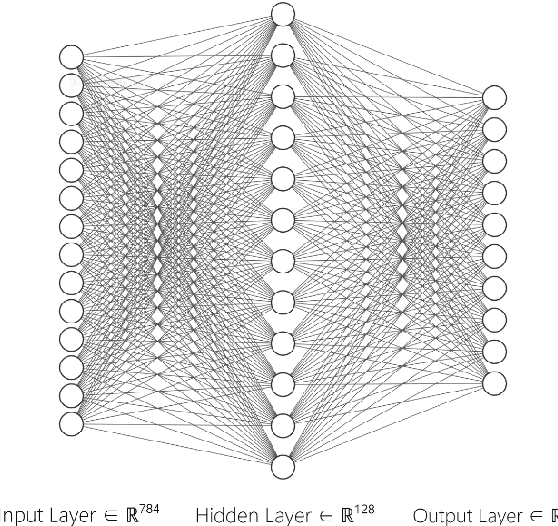
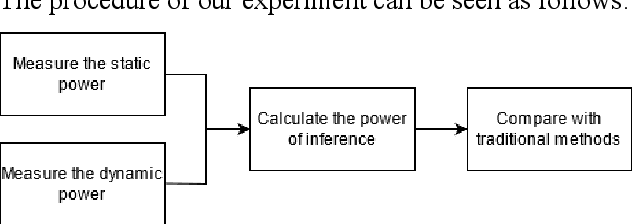
Matrix multiplication is the bedrock in Deep Learning inference application. When it comes to hardware acceleration on edge computing devices, matrix multiplication often takes up a great majority of the time. To achieve better performance in edge computing, we introduce a low-power Multi-layer Perceptron (MLP) accelerator based on a pipelined matrix multiplication scheme and a nonuniform quantization methodology. The implementation is running on Field-programmable Gate Array (FPGA) devices and tested its performance on handwritten digit classification and Q-learning tasks. Results show that our method can achieve better performance with fewer power consumption.
TTM: Terrain Traversability Mapping for Autonomous Excavator Navigation in Unstructured Environments
Sep 13, 2021
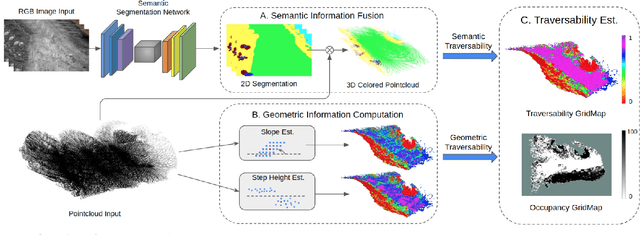

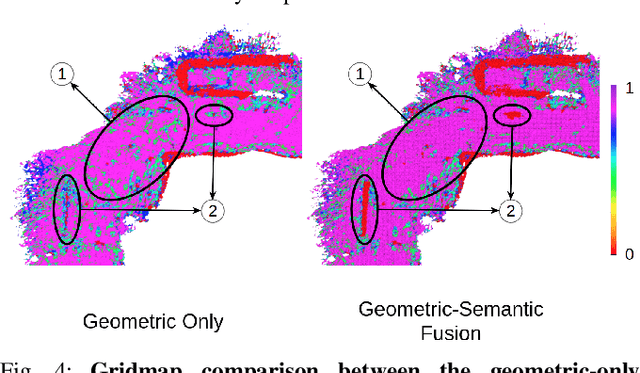
We present Terrain Traversability Mapping (TTM), a real-time mapping approach for terrain traversability estimation and path planning for autonomous excavators in an unstructured environment. We propose an efficient learning-based geometric method to extract terrain features from RGB images and 3D pointclouds and incorporate them into a global map for planning and navigation for autonomous excavation. Our method used the physical characteristics of the excavator, including maximum climbing degree and other machine specifications, to determine the traversable area. Our method can adapt to changing environments and update the terrain information in real-time. Moreover, we prepare a novel dataset, Autonomous Excavator Terrain (AET) dataset, consisting of RGB images from construction sites with seven categories according to navigability. We integrate our mapping approach with planning and control modules in an autonomous excavator navigation system, which outperforms previous method by 49.3% in terms of success rate based on existing planning schemes. With our mapping the excavator can navigate through unstructured environments consisting of deep pits, steep hills, rock piles, and other complex terrain features.
Efficient deep learning models for land cover image classification
Nov 18, 2021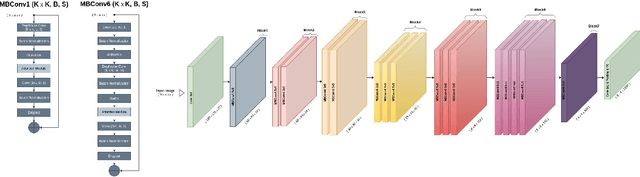
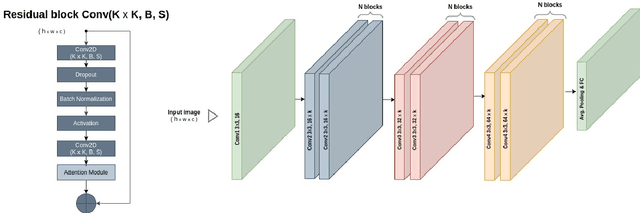
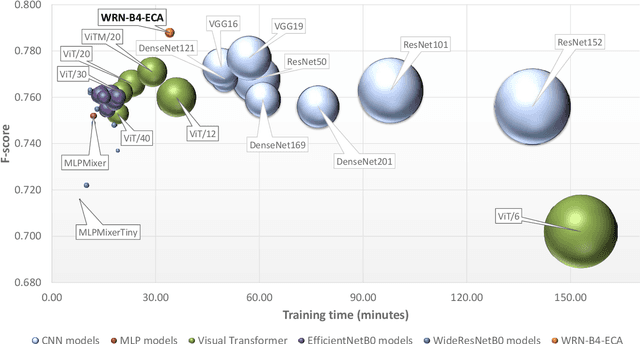

The availability of the sheer volume of Copernicus Sentinel imagery has created new opportunities for land use land cover (LULC) mapping at large scales using deep learning. Training on such large datasets though is a non-trivial task. In this work we experiment with the BigEarthNet dataset for LULC image classification and benchmark different state-of-the-art models, including Convolution Neural Networks, Multi-Layer Perceptrons, Visual Transformers, EfficientNets and Wide Residual Networks (WRN) architectures. Our aim is to leverage classification accuracy, training time and inference rate. We propose a framework based on EfficientNets for compound scaling of WRNs in terms of network depth, width and input data resolution, for efficiently training and testing different model setups. We design a novel scaled WRN architecture enhanced with an Efficient Channel Attention mechanism. Our proposed lightweight model has an order of magnitude less trainable parameters, achieves 4.5% higher averaged f-score classification accuracy for all 19 LULC classes and is trained two times faster with respect to a ResNet50 state-of-the-art model that we use as a baseline. We provide access to more than 50 trained models, along with our code for distributed training on multiple GPU nodes.
See Eye to Eye: A Lidar-Agnostic 3D Detection Framework for Unsupervised Multi-Target Domain Adaptation
Nov 17, 2021
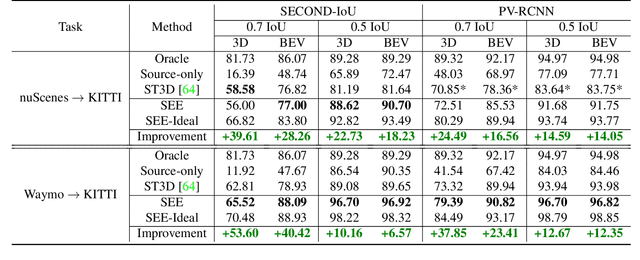
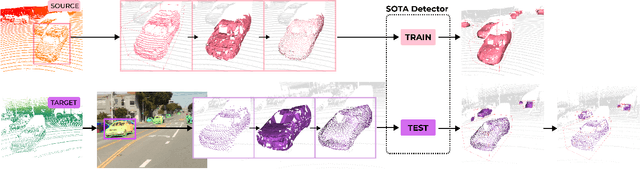
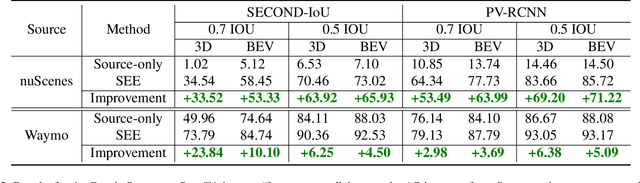
Sampling discrepancies between different manufacturers and models of lidar sensors result in inconsistent representations of objects. This leads to performance degradation when 3D detectors trained for one lidar are tested on other types of lidars. Remarkable progress in lidar manufacturing has brought about advances in mechanical, solid-state, and recently, adjustable scan pattern lidars. For the latter, existing works often require fine-tuning the model each time scan patterns are adjusted, which is infeasible. We explicitly deal with the sampling discrepancy by proposing a novel unsupervised multi-target domain adaptation framework, SEE, for transferring the performance of state-of-the-art 3D detectors across both fixed and flexible scan pattern lidars without requiring fine-tuning of models by end-users. Our approach interpolates the underlying geometry and normalizes the scan pattern of objects from different lidars before passing them to the detection network. We demonstrate the effectiveness of SEE on public datasets, achieving state-of-the-art results, and additionally provide quantitative results on a novel high-resolution lidar to prove the industry applications of our framework. This dataset and our code will be made publicly available.
Self-Regulated Learning for Egocentric Video Activity Anticipation
Nov 23, 2021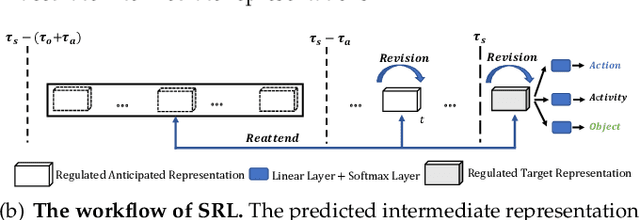
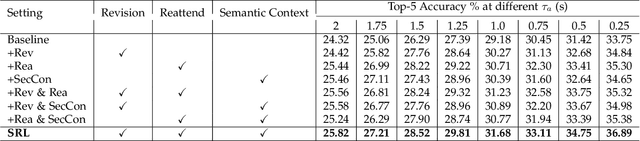
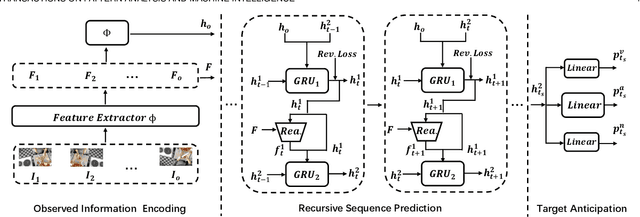
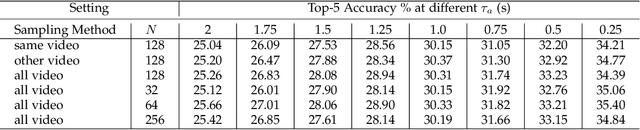
Future activity anticipation is a challenging problem in egocentric vision. As a standard future activity anticipation paradigm, recursive sequence prediction suffers from the accumulation of errors. To address this problem, we propose a simple and effective Self-Regulated Learning framework, which aims to regulate the intermediate representation consecutively to produce representation that (a) emphasizes the novel information in the frame of the current time-stamp in contrast to previously observed content, and (b) reflects its correlation with previously observed frames. The former is achieved by minimizing a contrastive loss, and the latter can be achieved by a dynamic reweighing mechanism to attend to informative frames in the observed content with a similarity comparison between feature of the current frame and observed frames. The learned final video representation can be further enhanced by multi-task learning which performs joint feature learning on the target activity labels and the automatically detected action and object class tokens. SRL sharply outperforms existing state-of-the-art in most cases on two egocentric video datasets and two third-person video datasets. Its effectiveness is also verified by the experimental fact that the action and object concepts that support the activity semantics can be accurately identified.
Decision Support Models for Predicting and Explaining Airport Passenger Connectivity from Data
Nov 02, 2021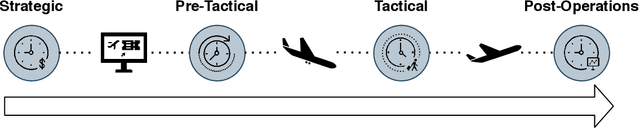
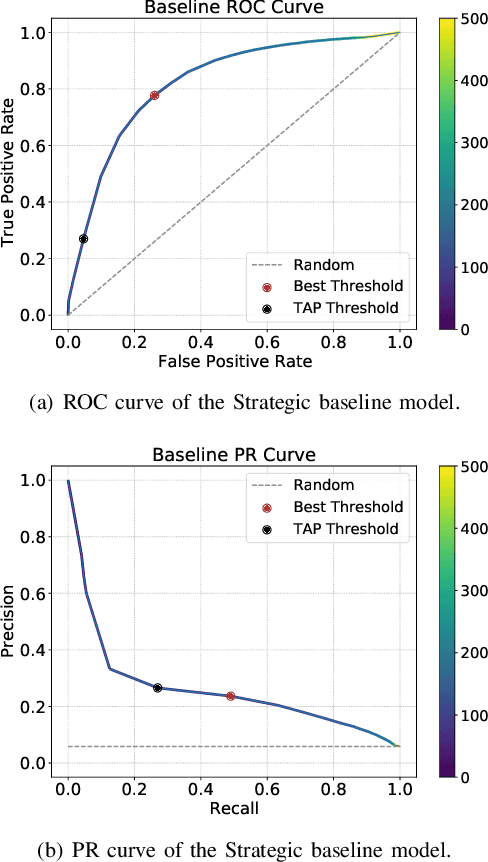
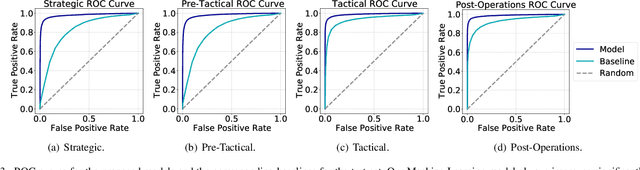
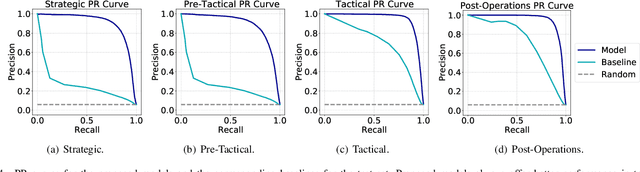
Predicting if passengers in a connecting flight will lose their connection is paramount for airline profitability. We present novel machine learning-based decision support models for the different stages of connection flight management, namely for strategic, pre-tactical, tactical and post-operations. We predict missed flight connections in an airline's hub airport using historical data on flights and passengers, and analyse the factors that contribute additively to the predicted outcome for each decision horizon. Our data is high-dimensional, heterogeneous, imbalanced and noisy, and does not inform about passenger arrival/departure transit time. We employ probabilistic encoding of categorical classes, data balancing with Gaussian Mixture Models, and boosting. For all planning horizons, our models attain an AUC of the ROC higher than 0.93. SHAP value explanations of our models indicate that scheduled/perceived connection times contribute the most to the prediction, followed by passenger age and whether border controls are required.
Improved Safe Real-time Heuristic Search
May 15, 2019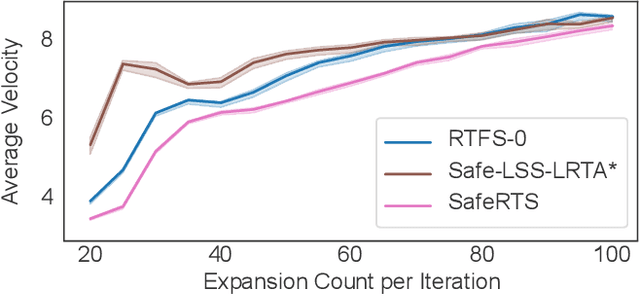
A fundamental concern in real-time planning is the presence of dead-ends in the state space, from which no goal is reachable. Recently, the SafeRTS algorithm was proposed for searching in such spaces. SafeRTS exploits a user-provided predicate to identify safe states, from which a goal is likely reachable, and attempts to maintain a backup plan for reaching a safe state at all times. In this paper, we study the SafeRTS approach, identify certain properties of its behavior, and design an improved framework for safe real-time search. We prove that the new approach performs at least as well as SafeRTS and present experimental results showing that its promise is fulfilled in practice.