 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On-board Fault Diagnosis of a Laboratory Mini SR-30 Gas Turbine Engine
Oct 19, 2021
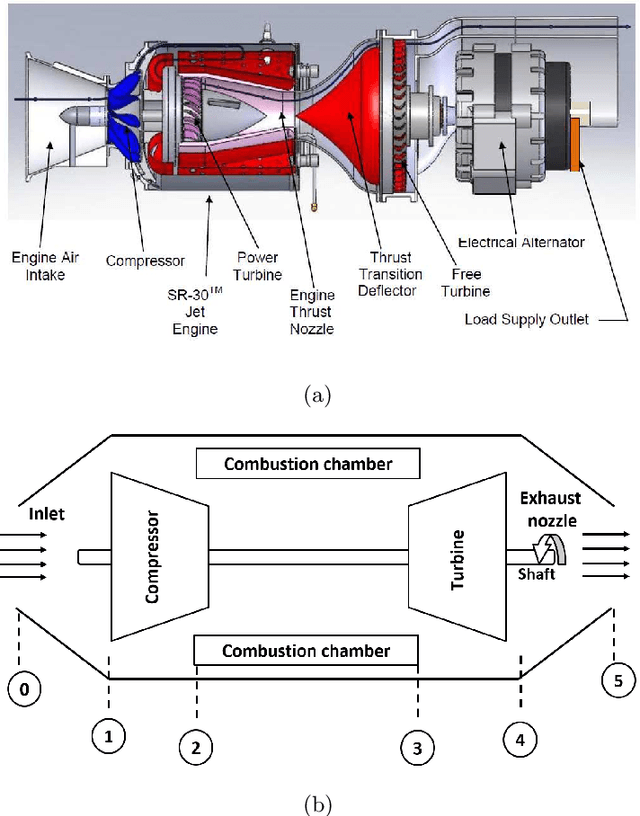
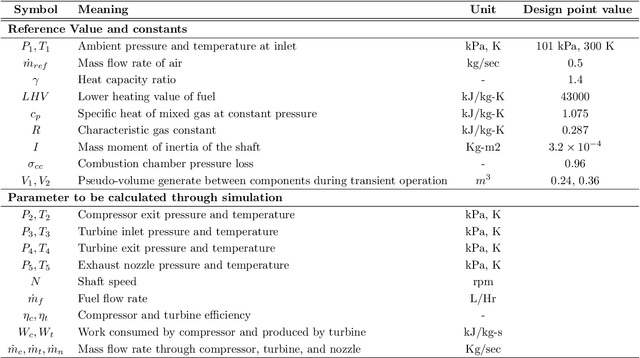
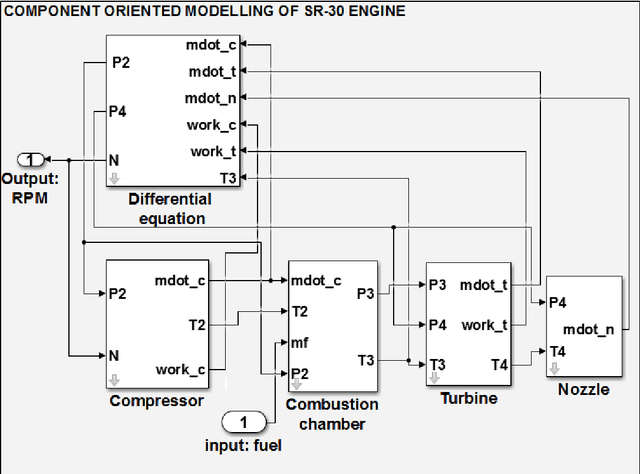
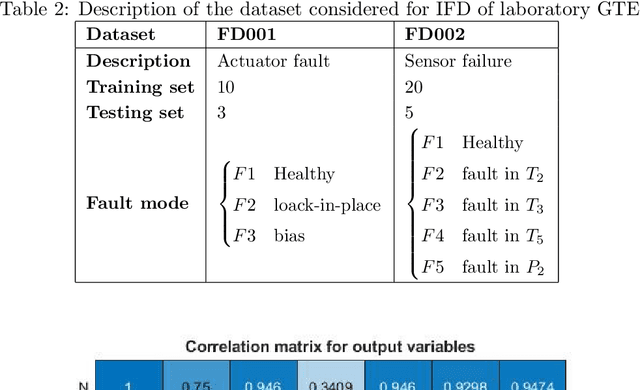
Inspired by recent progress in machine learning, a data-driven fault diagnosis and isolation (FDI) scheme is explicitly developed for failure in the fuel supply system and sensor measurements of the laboratory gas turbine system. A passive approach of fault diagnosis is implemented where a model is trained using machine learning classifiers to detect a given set of fault scenarios in real-time on which it is trained. Towards the end, a comparative study is presented for well-known classification techniques, namely Support vector classifier, linear discriminant analysis, K-neighbor, and decision trees. Several simulation studies were carried out to demonstrate and illustrate the proposed fault diagnosis scheme's advantages, capabilities, and performance.
Loss Landscape Dependent Self-Adjusting Learning Rates in Decentralized Stochastic Gradient Descent
Dec 02, 2021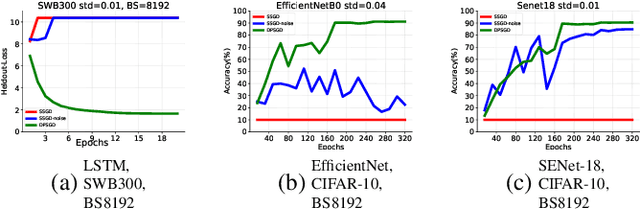
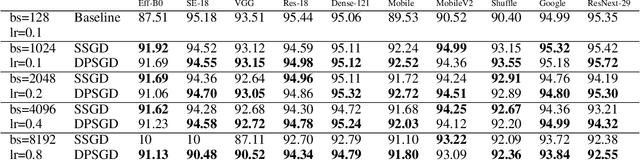
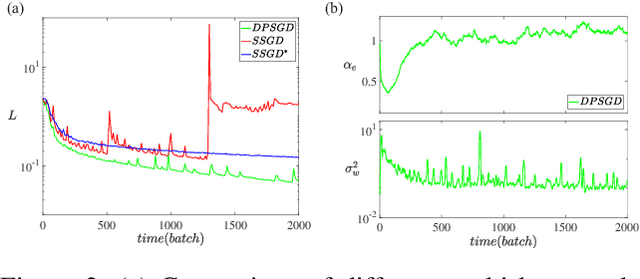
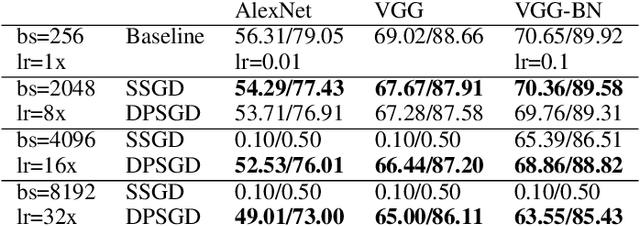
Distributed Deep Learning (DDL) is essential for large-scale Deep Learning (DL) training. Synchronous Stochastic Gradient Descent (SSGD) 1 is the de facto DDL optimization method. Using a sufficiently large batch size is critical to achieving DDL runtime speedup. In a large batch setting, the learning rate must be increased to compensate for the reduced number of parameter updates. However, a large learning rate may harm convergence in SSGD and training could easily diverge. Recently, Decentralized Parallel SGD (DPSGD) has been proposed to improve distributed training speed. In this paper, we find that DPSGD not only has a system-wise run-time benefit but also a significant convergence benefit over SSGD in the large batch setting. Based on a detailed analysis of the DPSGD learning dynamics, we find that DPSGD introduces additional landscape-dependent noise that automatically adjusts the effective learning rate to improve convergence. In addition, we theoretically show that this noise smoothes the loss landscape, hence allowing a larger learning rate. We conduct extensive studies over 18 state-of-the-art DL models/tasks and demonstrate that DPSGD often converges in cases where SSGD diverges for large learning rates in the large batch setting. Our findings are consistent across two different application domains: Computer Vision (CIFAR10 and ImageNet-1K) and Automatic Speech Recognition (SWB300 and SWB2000), and two different types of neural network models: Convolutional Neural Networks and Long Short-Term Memory Recurrent Neural Networks.
Federated Expectation Maximization with heterogeneity mitigation and variance reduction
Nov 03, 2021
The Expectation Maximization (EM) algorithm is the default algorithm for inference in latent variable models. As in any other field of machine learning, applications of latent variable models to very large datasets make the use of advanced parallel and distributed architectures mandatory. This paper introduces FedEM, which is the first extension of the EM algorithm to the federated learning context. FedEM is a new communication efficient method, which handles partial participation of local devices, and is robust to heterogeneous distributions of the datasets. To alleviate the communication bottleneck, FedEM compresses appropriately defined complete data sufficient statistics. We also develop and analyze an extension of FedEM to further incorporate a variance reduction scheme. In all cases, we derive finite-time complexity bounds for smooth non-convex problems. Numerical results are presented to support our theoretical findings, as well as an application to federated missing values imputation for biodiversity monitoring.
Time series and machine learning to forecast the water quality from satellite data
Mar 16, 2020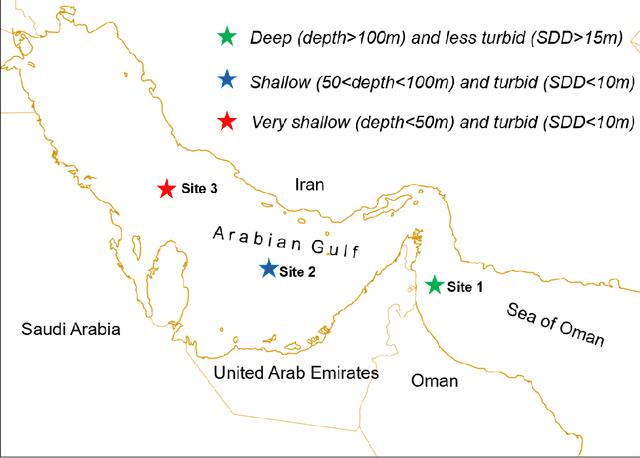
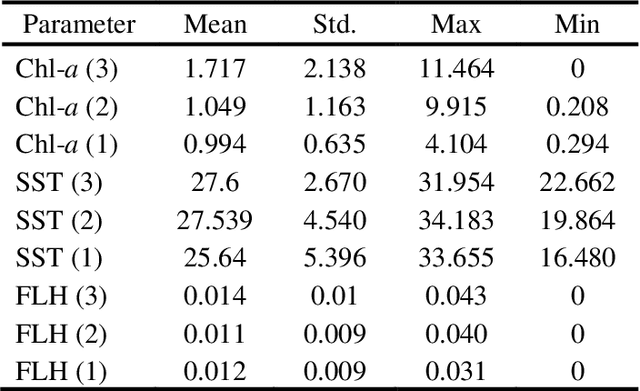
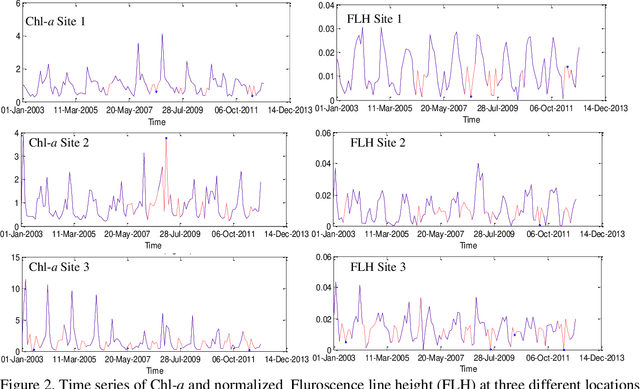
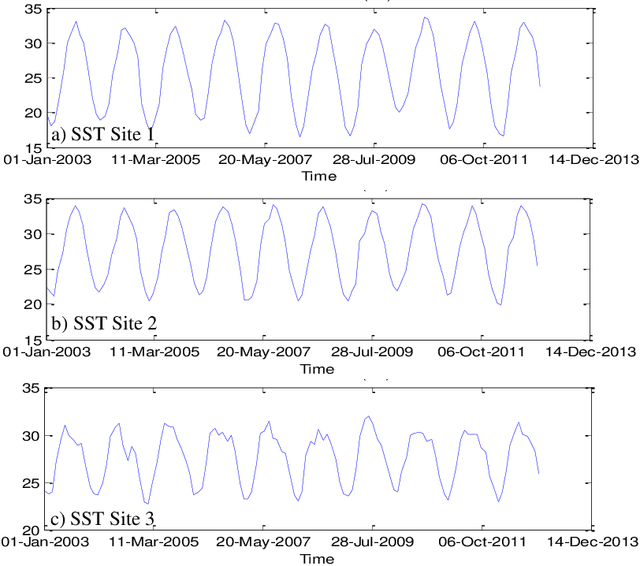
Managing the quality of water for present and future generations of coastal regions should be a central concern of both citizens and public officials. Remote sensing can contribute to the management and monitoring of coastal water and pollutants. Algal blooms are a coastal pollutant that is a cause of concern. Many satellite data, such as MODIS, have been used to generate water-quality products to detect the blooms such as chlorophyll a (Chl-a), a photosynthesis index called fluorescence line height (FLH), and sea surface temperature (SST). It is important to characterize the spatial and temporal variations of these water quality products by using the mathematical models of these products. However, for monitoring, pollution control boards will need nowcasts and forecasts of any pollution. Therefore, we aim to predict the future values of the MODIS Chl-a, FLH, and SST of the water. This will not be limited to one type of water but, rather, will cover different types of water varying in depth and turbidity. This is very significant because the temporal trend of Chl-a, FLH, and SST is dependent on the geospatial and water properties. For this purpose, we will decompose the time series of each pixel into several components: trend, intra-annual variations, seasonal cycle, and stochastic stationary. We explore three such time series machine learning models that can characterize the non-stationary time series data and predict future values, including the Seasonal ARIMA (Auto Regressive Integrated Moving Average) (SARIMA), regression, and neural network. The results indicate that all these methods are effective at modelling Chl-a, FLH, and SST time series and predicting the values reasonably well. However, regression and neural network are found to be the best at predicting Chl-a in all types of water (turbid and shallow). Meanwhile, the SARIMA model provides the best prediction of FLH and SST.
End-to-End Optimized Arrhythmia Detection Pipeline using Machine Learning for Ultra-Edge Devices
Nov 23, 2021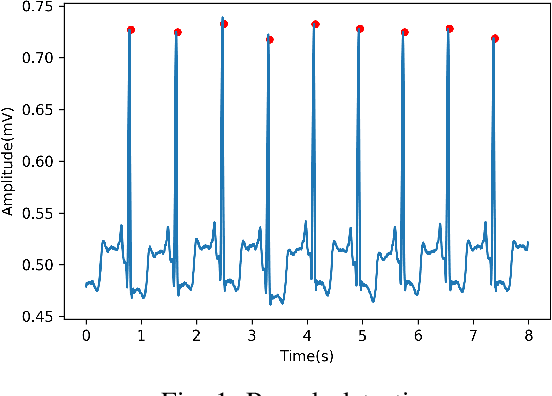
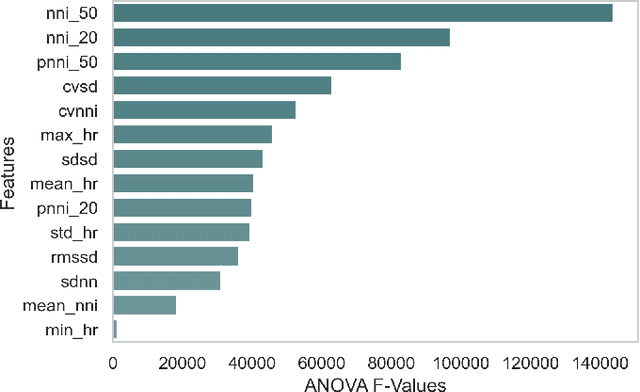
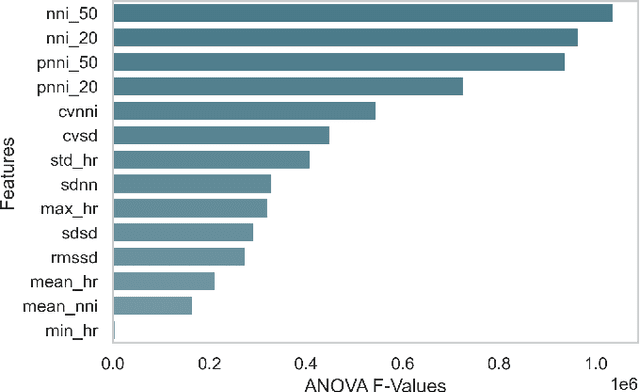
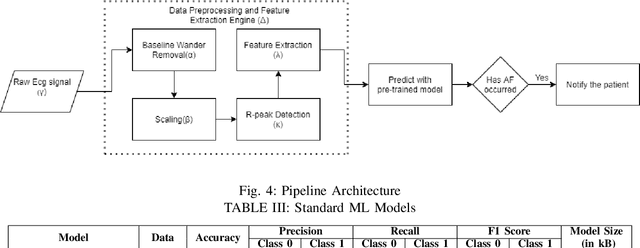
Atrial fibrillation (AF) is the most prevalent cardiac arrhythmia worldwide, with 2% of the population affected. It is associated with an increased risk of strokes, heart failure and other heart-related complications. Monitoring at-risk individuals and detecting asymptomatic AF could result in considerable public health benefits, as individuals with asymptomatic AF could take preventive measures with lifestyle changes. With increasing affordability to wearables, personalized health care is becoming more accessible. These personalized healthcare solutions require accurate classification of bio-signals while being computationally inexpensive. By making inferences on-device, we avoid issues inherent to cloud-based systems such as latency and network connection dependency. We propose an efficient pipeline for real-time Atrial Fibrillation Detection with high accuracy that can be deployed in ultra-edge devices. The feature engineering employed in this research catered to optimizing the resource-efficient classifier used in the proposed pipeline, which was able to outperform the best performing standard ML model by $10^5\times$ in terms of memory footprint with a mere trade-off of 2% classification accuracy. We also obtain higher accuracy of approximately 6% while consuming 403$\times$ lesser memory and being 5.2$\times$ faster compared to the previous state-of-the-art (SoA) embedded implementation.
Prototypical Model with Novel Information-theoretic Loss Function for Generalized Zero Shot Learning
Dec 06, 2021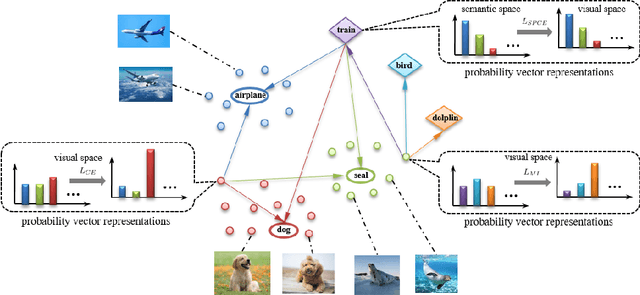
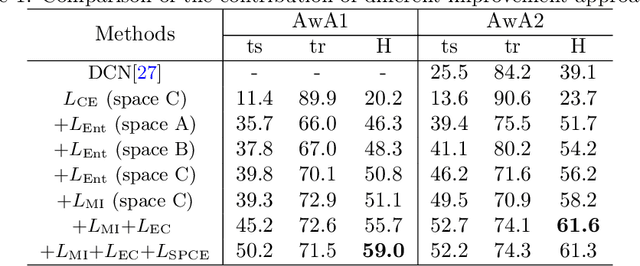
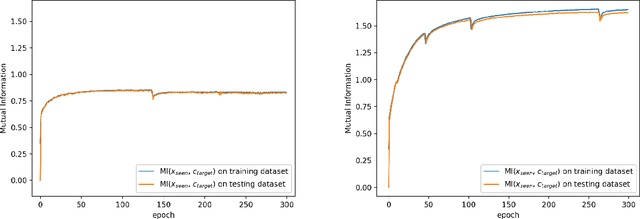
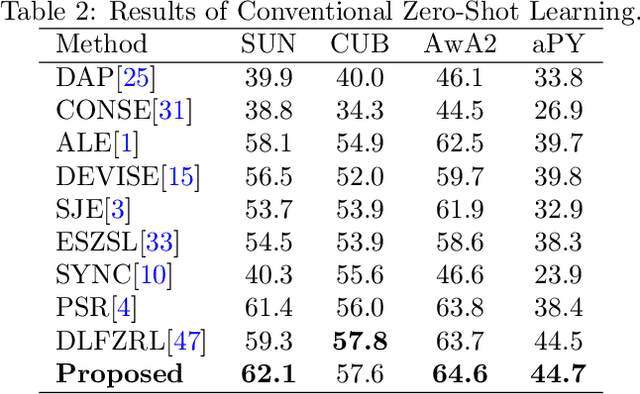
Generalized zero shot learning (GZSL) is still a technical challenge of deep learning as it has to recognize both source and target classes without data from target classes. To preserve the semantic relation between source and target classes when only trained with data from source classes, we address the quantification of the knowledge transfer and semantic relation from an information-theoretic viewpoint. To this end, we follow the prototypical model and format the variables of concern as a probability vector. Leveraging on the proposed probability vector representation, the information measurement such as mutual information and entropy, can be effectively evaluated with simple closed forms. We discuss the choice of common embedding space and distance function when using the prototypical model. Then We propose three information-theoretic loss functions for deterministic GZSL model: a mutual information loss to bridge seen data and target classes; an uncertainty-aware entropy constraint loss to prevent overfitting when using seen data to learn the embedding of target classes; a semantic preserving cross entropy loss to preserve the semantic relation when mapping the semantic representations to the common space. Simulation shows that, as a deterministic model, our proposed method obtains state of the art results on GZSL benchmark datasets. We achieve 21%-64% improvements over the baseline model -- deep calibration network (DCN) and for the first time demonstrate a deterministic model can perform as well as generative ones. Moreover, our proposed model is compatible with generative models. Simulation studies show that by incorporating with f-CLSWGAN, we obtain comparable results compared with advanced generative models.
Random Feature Approximation for Online Nonlinear Graph Topology Identification
Oct 19, 2021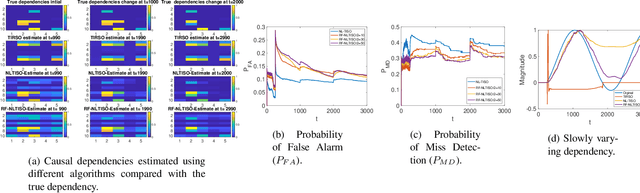
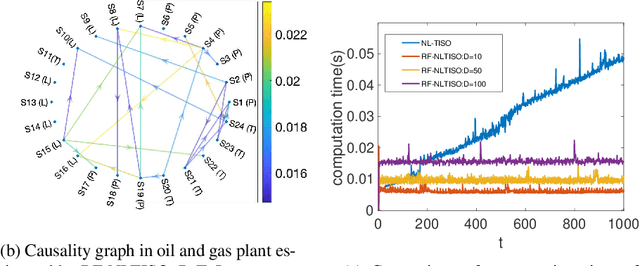
Online topology estimation of graph-connected time series is challenging, especially since the causal dependencies in many real-world networks are nonlinear. In this paper, we propose a kernel-based algorithm for graph topology estimation. The algorithm uses a Fourier-based Random feature approximation to tackle the curse of dimensionality associated with the kernel representations. Exploiting the fact that the real-world networks often exhibit sparse topologies, we propose a group lasso based optimization framework, which is solve using an iterative composite objective mirror descent method, yielding an online algorithm with fixed computational complexity per iteration. The experiments conducted on real and synthetic data show that the proposed method outperforms its competitors.
Neural Tangent Kernel of Matrix Product States: Convergence and Applications
Nov 28, 2021
In this work, we study the Neural Tangent Kernel (NTK) of Matrix Product States (MPS) and the convergence of its NTK in the infinite bond dimensional limit. We prove that the NTK of MPS asymptotically converges to a constant matrix during the gradient descent (training) process (and also the initialization phase) as the bond dimensions of MPS go to infinity by the observation that the variation of the tensors in MPS asymptotically goes to zero during training in the infinite limit. By showing the positive-definiteness of the NTK of MPS, the convergence of MPS during the training in the function space (space of functions represented by MPS) is guaranteed without any extra assumptions of the data set. We then consider the settings of (supervised) Regression with Mean Square Error (RMSE) and (unsupervised) Born Machines (BM) and analyze their dynamics in the infinite bond dimensional limit. The ordinary differential equations (ODEs) which describe the dynamics of the responses of MPS in the RMSE and BM are derived and solved in the closed-form. For the Regression, we consider Mercer Kernels (Gaussian Kernels) and find that the evolution of the mean of the responses of MPS follows the largest eigenvalue of the NTK. Due to the orthogonality of the kernel functions in BM, the evolution of different modes (samples) decouples and the "characteristic time" of convergence in training is obtained.
Variable-Length Music Score Infilling via XLNet and Musically Specialized Positional Encoding
Aug 11, 2021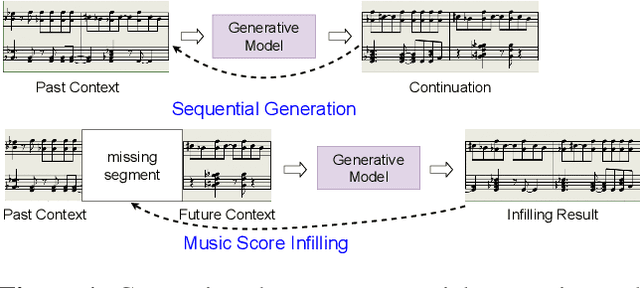
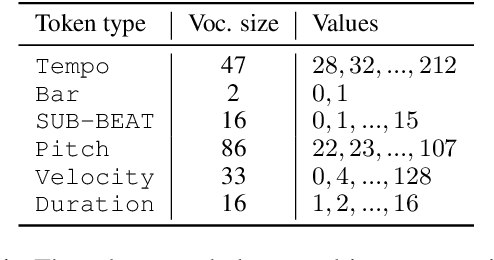
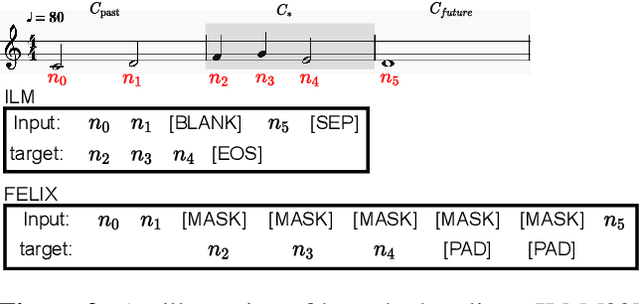

This paper proposes a new self-attention based model for music score infilling, i.e., to generate a polyphonic music sequence that fills in the gap between given past and future contexts. While existing approaches can only fill in a short segment with a fixed number of notes, or a fixed time span between the past and future contexts, our model can infill a variable number of notes (up to 128) for different time spans. We achieve so with three major technical contributions. First, we adapt XLNet, an autoregressive model originally proposed for unsupervised model pre-training, to music score infilling. Second, we propose a new, musically specialized positional encoding called relative bar encoding that better informs the model of notes' position within the past and future context. Third, to capitalize relative bar encoding, we perform look-ahead onset prediction to predict the onset of a note one time step before predicting the other attributes of the note. We compare our proposed model with two strong baselines and show that our model is superior in both objective and subjective analyses.
Training Verifiers to Solve Math Word Problems
Oct 27, 2021
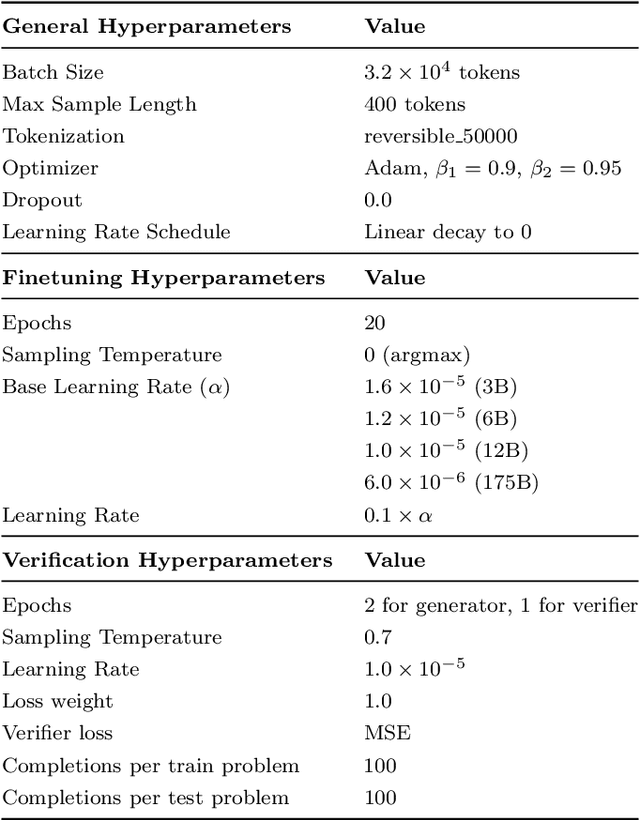
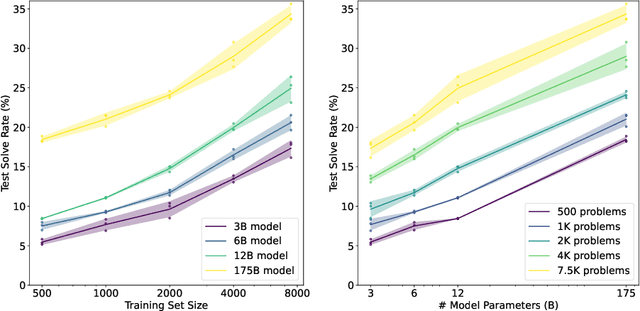
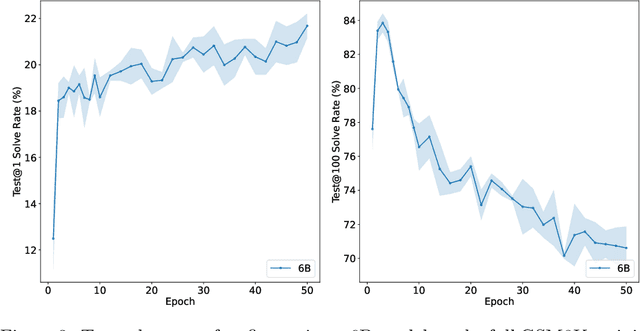
State-of-the-art language models can match human performance on many tasks, but they still struggle to robustly perform multi-step mathematical reasoning. To diagnose the failures of current models and support research, we introduce GSM8K, a dataset of 8.5K high quality linguistically diverse grade school math word problems. We find that even the largest transformer models fail to achieve high test performance, despite the conceptual simplicity of this problem distribution. To increase performance, we propose training verifiers to judge the correctness of model completions. At test time, we generate many candidate solutions and select the one ranked highest by the verifier. We demonstrate that verification significantly improves performance on GSM8K, and we provide strong empirical evidence that verification scales more effectively with increased data than a finetuning baseline.