 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SALSA-Lite: A Fast and Effective Feature for Polyphonic Sound Event Localization and Detection with Microphone Arrays
Nov 16, 2021
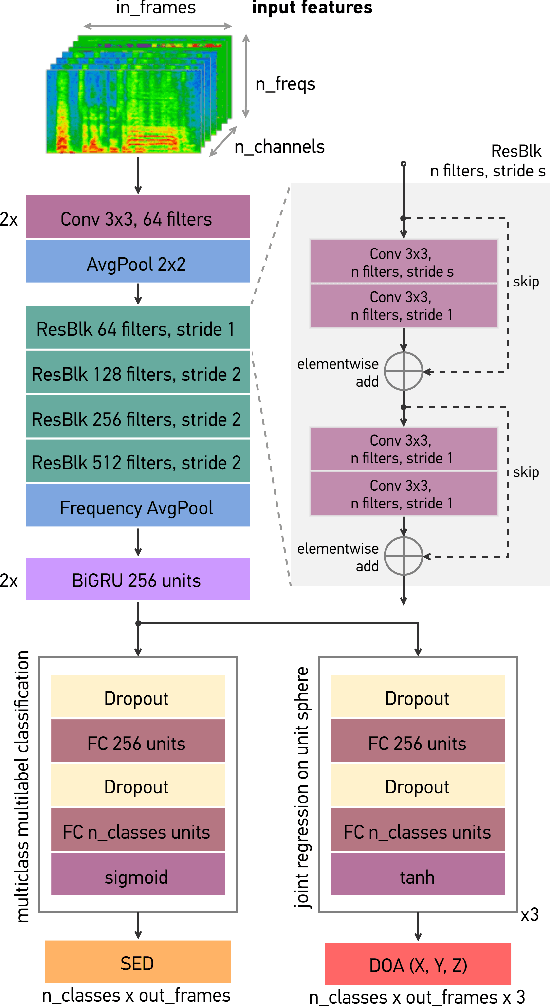
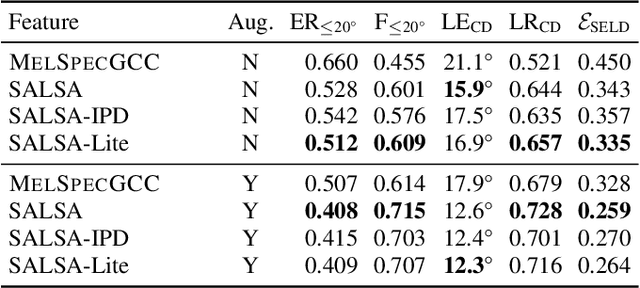
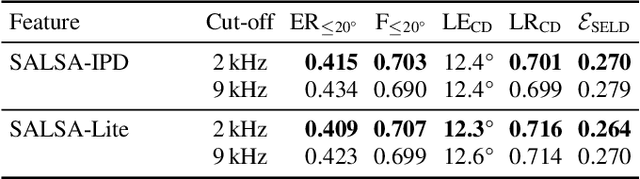
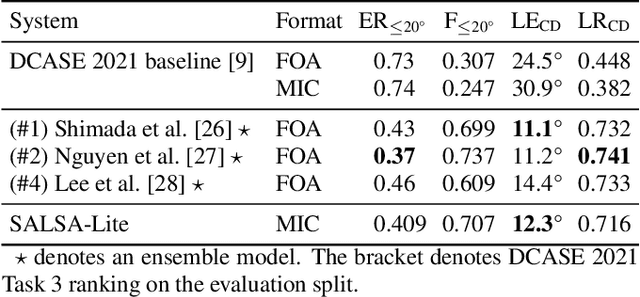
Polyphonic sound event localization and detection (SELD) has many practical applications in acoustic sensing and monitoring. However, the development of real-time SELD has been limited by the demanding computational requirement of most recent SELD systems. In this work, we introduce SALSA-Lite, a fast and effective feature for polyphonic SELD using microphone array inputs. SALSA-Lite is a lightweight variation of a previously proposed SALSA feature for polyphonic SELD. SALSA, which stands for Spatial Cue-Augmented Log-Spectrogram, consists of multichannel log-spectrograms stacked channelwise with the normalized principal eigenvectors of the spectrotemporally corresponding spatial covariance matrices. In contrast to SALSA, which uses eigenvector-based spatial features, SALSA-Lite uses normalized inter-channel phase differences as spatial features, allowing a 30-fold speedup compared to the original SALSA feature. Experimental results on the TAU-NIGENS Spatial Sound Events 2021 dataset showed that the SALSA-Lite feature achieved competitive performance compared to the full SALSA feature, and significantly outperformed the traditional feature set of multichannel log-mel spectrograms with generalized cross-correlation spectra. Specifically, using SALSA-Lite features increased localization-dependent F1 score and class-dependent localization recall by 15% and 5%, respectively, compared to using multichannel log-mel spectrograms with generalized cross-correlation spectra.
On the relationship between disentanglement and multi-task learning
Oct 07, 2021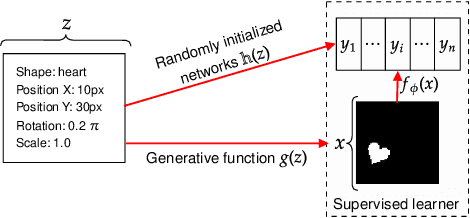
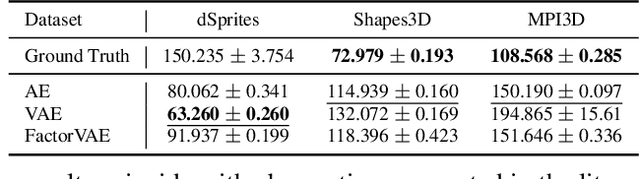
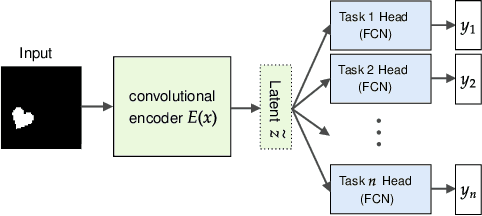
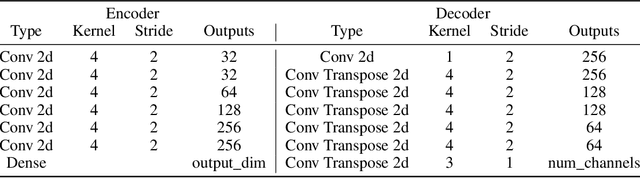
One of the main arguments behind studying disentangled representations is the assumption that they can be easily reused in different tasks. At the same time finding a joint, adaptable representation of data is one of the key challenges in the multi-task learning setting. In this paper, we take a closer look at the relationship between disentanglement and multi-task learning based on hard parameter sharing. We perform a thorough empirical study of the representations obtained by neural networks trained on automatically generated supervised tasks. Using a set of standard metrics we show that disentanglement appears naturally during the process of multi-task neural network training.
Scheduling in Parallel Finite Buffer Systems: Optimal Decisions under Delayed Feedback
Sep 17, 2021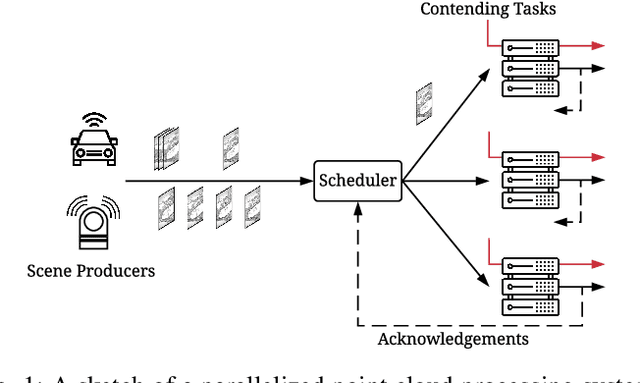
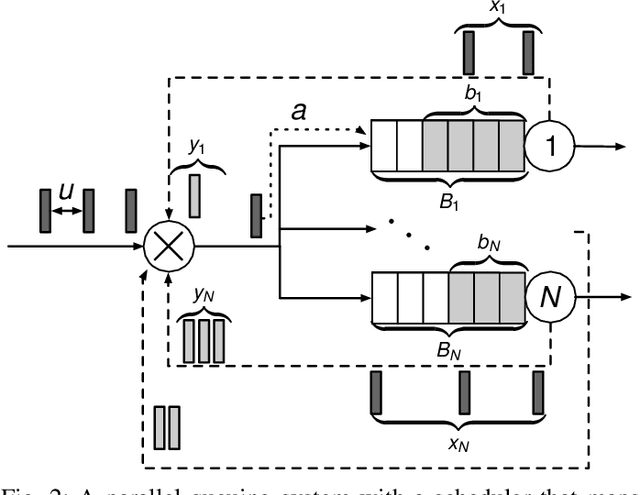
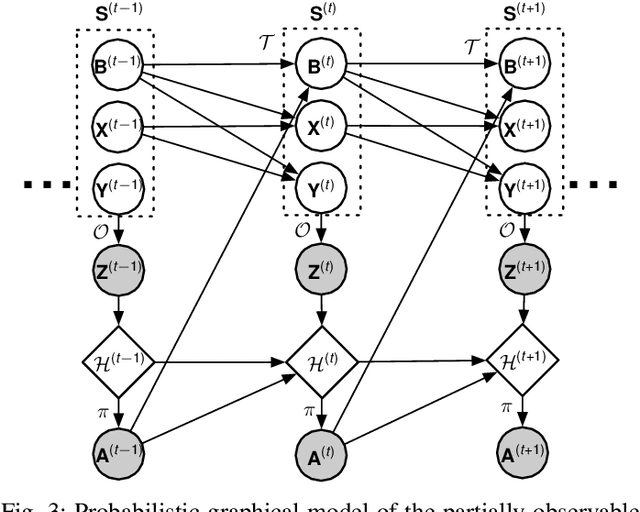

Scheduling decisions in parallel queuing systems arise as a fundamental problem, underlying the dimensioning and operation of many computing and communication systems, such as job routing in data center clusters, multipath communication, and Big Data systems. In essence, the scheduler maps each arriving job to one of the possibly heterogeneous servers while aiming at an optimization goal such as load balancing, low average delay or low loss rate. One main difficulty in finding optimal scheduling decisions here is that the scheduler only partially observes the impact of its decisions, e.g., through the delayed acknowledgements of the served jobs. In this paper, we provide a partially observable (PO) model that captures the scheduling decisions in parallel queuing systems under limited information of delayed acknowledgements. We present a simulation model for this PO system to find a near-optimal scheduling policy in real-time using a scalable Monte Carlo tree search algorithm. We numerically show that the resulting policy outperforms other limited information scheduling strategies such as variants of Join-the-Most-Observations and has comparable performance to full information strategies like: Join-the-Shortest-Queue, Join-the- Shortest-Queue(d) and Shortest-Expected-Delay. Finally, we show how our approach can optimise the real-time parallel processing by using network data provided by Kaggle.
Neural Network Based Epileptic EEG Detection and Classification
Nov 05, 2021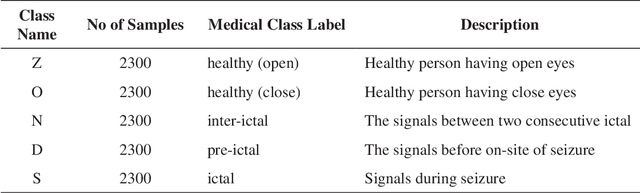
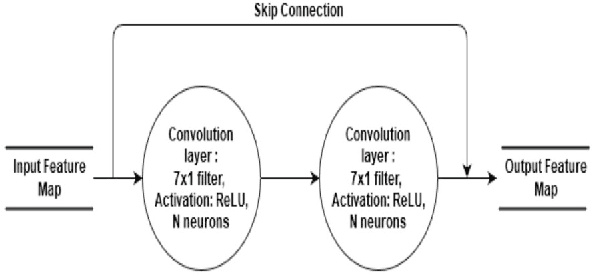
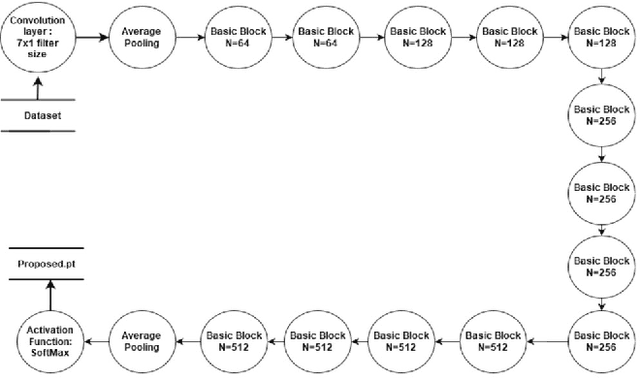
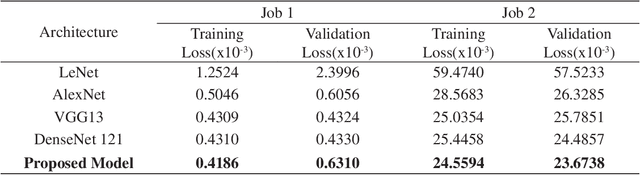
Timely diagnosis is important for saving the life of epileptic patients. In past few years, a lot of treatments are available for epilepsy. These treatments require use of anti-seizure drugs but are not effective in controlling frequency of seizure. There is need of removal of an affected region using surgery. Electroencephalogram (EEG) is a widely used technique for monitoring the brain activity and widely popular for seizure region detection. It is used before surgery for locating affected region. This manual process, using EEG graphs, is time consuming and requires deep expertise. In the present paper, a model has been proposed that preserves the true nature of an EEG signal in form of textual one-dimensional vector. The proposed model achieves a state of art performance for Bonn University dataset giving an average sensitivity, specificity of 81% and 81.4% respectively for classification of EEG data among all five classes. Also for binary classification achieving 99.9%, 99.5% score value for specificity and sensitivity instead of 2D models used by other researchers. Thus, developed system will significantly help neurosurgeons in the increase of their performance.
* 10 Pages, 3 Tables and 6 Figures
A Benchmark Comparison of Visual Place Recognition Techniques for Resource-Constrained Embedded Platforms
Sep 22, 2021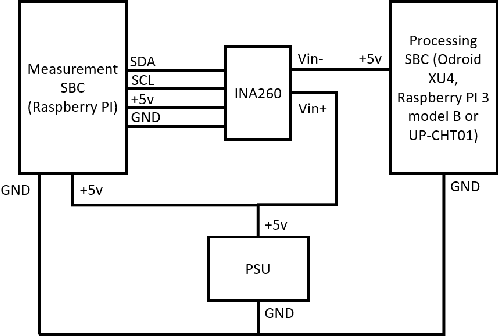
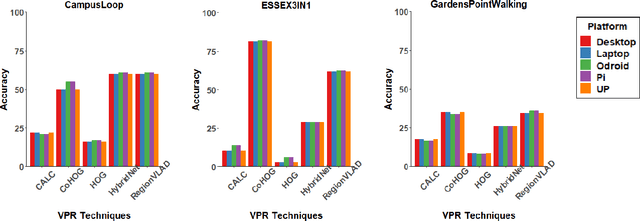
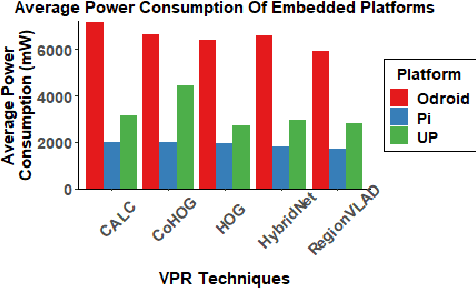
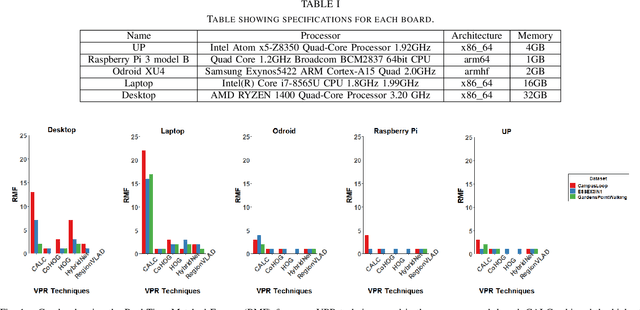
Visual Place Recognition (VPR) has been a subject of significant research over the last 15 to 20 years. VPR is a fundamental task for autonomous navigation as it enables self-localization within an environment. Although robots are often equipped with resource-constrained hardware, the computational requirements of and effects on VPR techniques have received little attention. In this work, we present a hardware-focused benchmark evaluation of a number of state-of-the-art VPR techniques on public datasets. We consider popular single board computers, including ODroid, UP and Raspberry Pi 3, in addition to a commodity desktop and laptop for reference. We present our analysis based on several key metrics, including place-matching accuracy, image encoding time, descriptor matching time and memory needs. Key questions addressed include: (1) How does the performance accuracy of a VPR technique change with processor architecture? (2) How does power consumption vary for different VPR techniques and embedded platforms? (3) How much does descriptor size matter in comparison to today's embedded platforms' storage? (4) How does the performance of a high-end platform relate to an on-board low-end embedded platform for VPR? The extensive analysis and results in this work serve not only as a benchmark for the VPR community, but also provide useful insights for real-world adoption of VPR applications.
Path Planning for Cellular-Connected UAV: A DRL Solution with Quantum-Inspired Experience Replay
Aug 30, 2021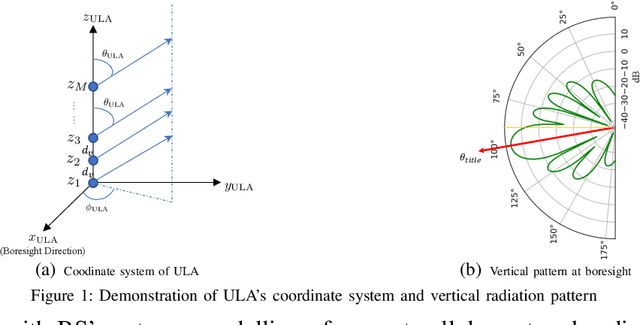
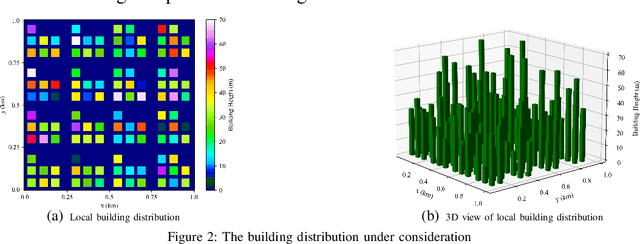

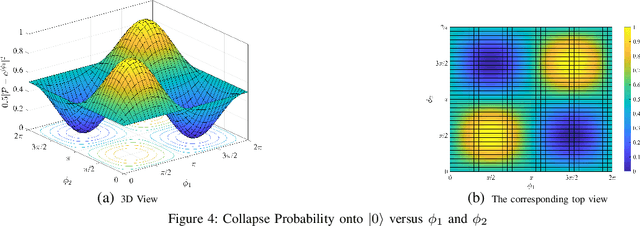
In cellular-connected unmanned aerial vehicle (UAV) network, a minimization problem on the weighted sum of time cost and expected outage duration is considered. Taking advantage of UAV's adjustable mobility, an intelligent UAV navigation approach is formulated to achieve the aforementioned optimization goal. Specifically, after mapping the navigation task into a Markov decision process (MDP), a deep reinforcement learning (DRL) solution with novel quantum-inspired experience replay (QiER) framework is proposed to help the UAV find the optimal flying direction within each time slot, and thus the designed trajectory towards the destination can be generated. Via relating experienced transition's importance to its associated quantum bit (qubit) and applying Grover iteration based amplitude amplification technique, the proposed DRL-QiER solution can commit a better trade-off between sampling priority and diversity. Compared to several representative baselines, the effectiveness and supremacy of the proposed DRL-QiER solution are demonstrated and validated in numerical results.
Recursively Summarizing Books with Human Feedback
Sep 22, 2021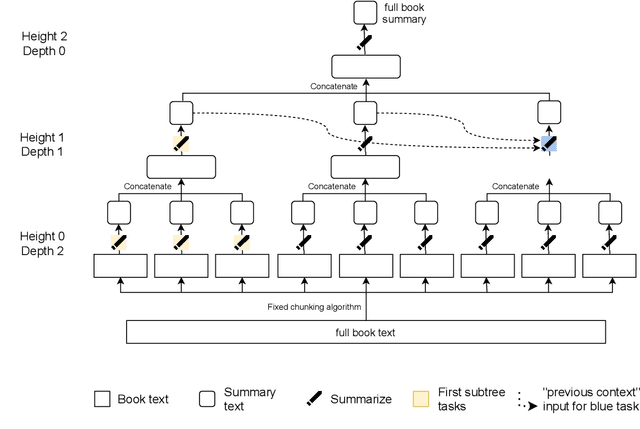
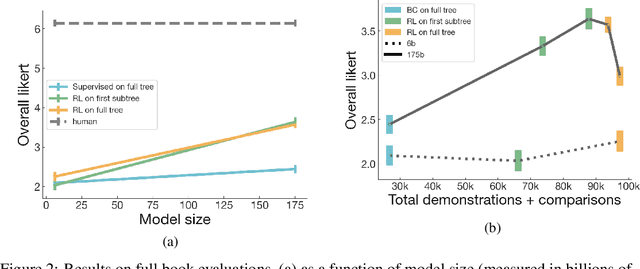
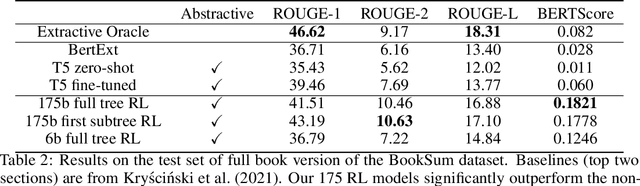
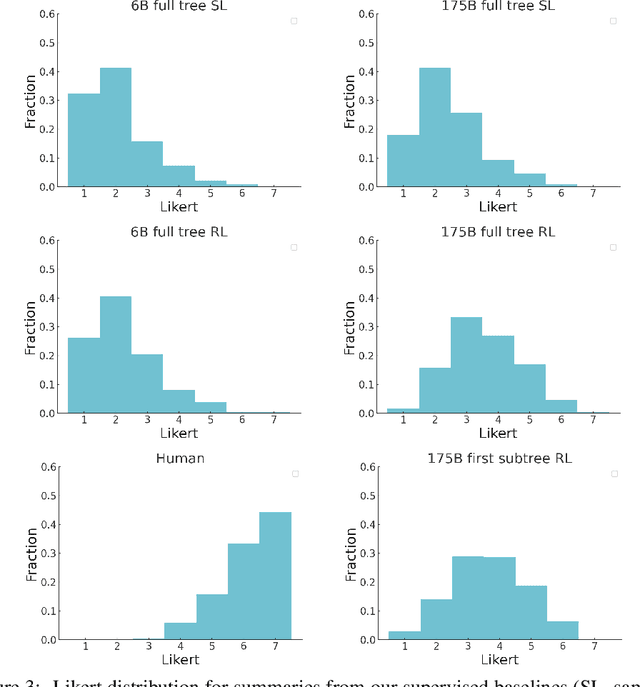
A major challenge for scaling machine learning is training models to perform tasks that are very difficult or time-consuming for humans to evaluate. We present progress on this problem on the task of abstractive summarization of entire fiction novels. Our method combines learning from human feedback with recursive task decomposition: we use models trained on smaller parts of the task to assist humans in giving feedback on the broader task. We collect a large volume of demonstrations and comparisons from human labelers, and fine-tune GPT-3 using behavioral cloning and reward modeling to do summarization recursively. At inference time, the model first summarizes small sections of the book and then recursively summarizes these summaries to produce a summary of the entire book. Our human labelers are able to supervise and evaluate the models quickly, despite not having read the entire books themselves. Our resulting model generates sensible summaries of entire books, even matching the quality of human-written summaries in a few cases ($\sim5\%$ of books). We achieve state-of-the-art results on the recent BookSum dataset for book-length summarization. A zero-shot question-answering model using these summaries achieves state-of-the-art results on the challenging NarrativeQA benchmark for answering questions about books and movie scripts. We release datasets of samples from our model.
MaIL: A Unified Mask-Image-Language Trimodal Network for Referring Image Segmentation
Nov 25, 2021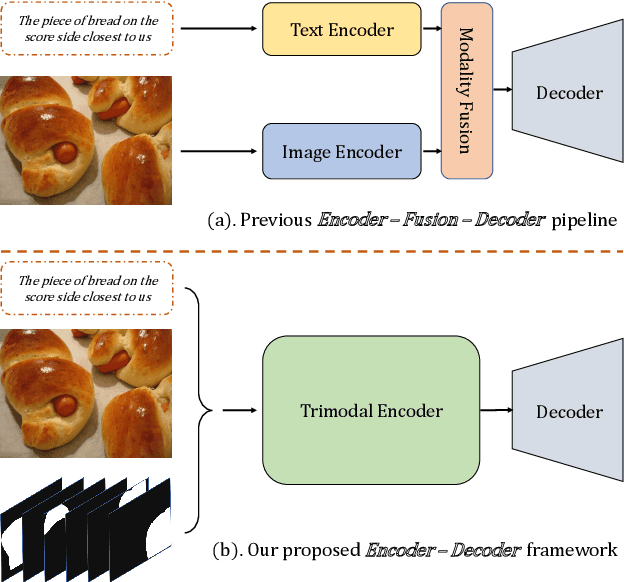
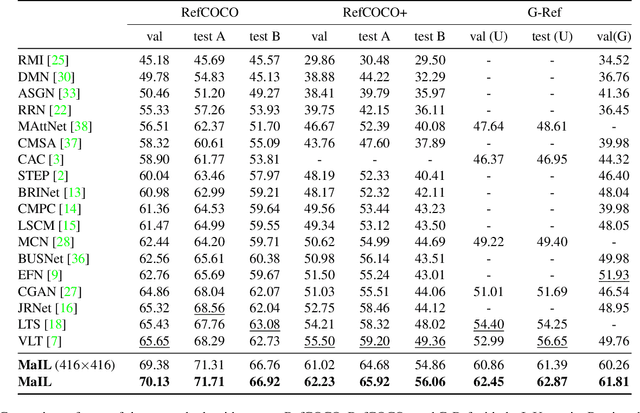
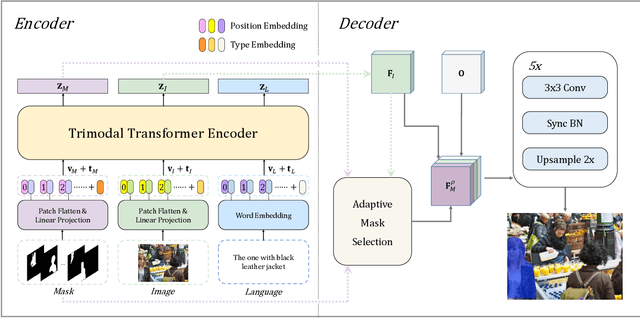
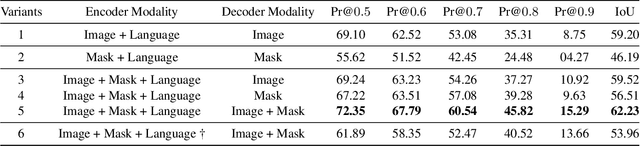
Referring image segmentation is a typical multi-modal task, which aims at generating a binary mask for referent described in given language expressions. Prior arts adopt a bimodal solution, taking images and languages as two modalities within an encoder-fusion-decoder pipeline. However, this pipeline is sub-optimal for the target task for two reasons. First, they only fuse high-level features produced by uni-modal encoders separately, which hinders sufficient cross-modal learning. Second, the uni-modal encoders are pre-trained independently, which brings inconsistency between pre-trained uni-modal tasks and the target multi-modal task. Besides, this pipeline often ignores or makes little use of intuitively beneficial instance-level features. To relieve these problems, we propose MaIL, which is a more concise encoder-decoder pipeline with a Mask-Image-Language trimodal encoder. Specifically, MaIL unifies uni-modal feature extractors and their fusion model into a deep modality interaction encoder, facilitating sufficient feature interaction across different modalities. Meanwhile, MaIL directly avoids the second limitation since no uni-modal encoders are needed anymore. Moreover, for the first time, we propose to introduce instance masks as an additional modality, which explicitly intensifies instance-level features and promotes finer segmentation results. The proposed MaIL set a new state-of-the-art on all frequently-used referring image segmentation datasets, including RefCOCO, RefCOCO+, and G-Ref, with significant gains, 3%-10% against previous best methods. Code will be released soon.
Compressing Sensor Data for Remote Assistance of Autonomous Vehicles using Deep Generative Models
Nov 05, 2021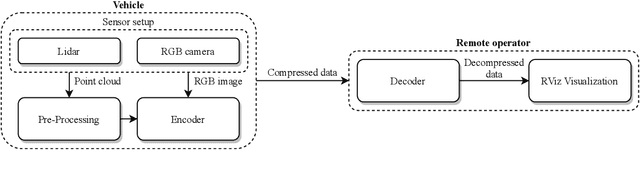
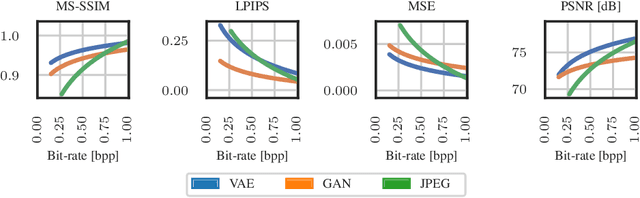

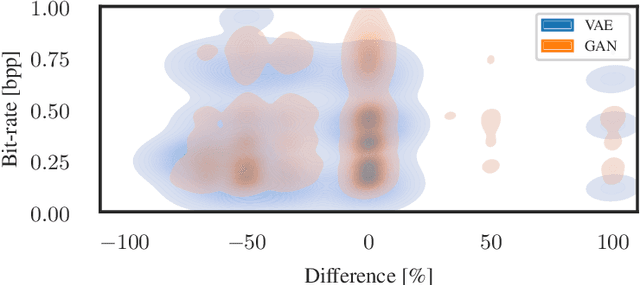
In the foreseeable future, autonomous vehicles will require human assistance in situations they can not resolve on their own. In such scenarios, remote assistance from a human can provide the required input for the vehicle to continue its operation. Typical sensors used in autonomous vehicles include camera and lidar sensors. Due to the massive volume of sensor data that must be sent in real-time, highly efficient data compression is elementary to prevent an overload of network infrastructure. Sensor data compression using deep generative neural networks has been shown to outperform traditional compression approaches for both image and lidar data, regarding compression rate as well as reconstruction quality. However, there is a lack of research about the performance of generative-neural-network-based compression algorithms for remote assistance. In order to gain insights into the feasibility of deep generative models for usage in remote assistance, we evaluate state-of-the-art algorithms regarding their applicability and identify potential weaknesses. Further, we implement an online pipeline for processing sensor data and demonstrate its performance for remote assistance using the CARLA simulator.
Early Lane Change Prediction for Automated Driving Systems Using Multi-Task Attention-based Convolutional Neural Networks
Sep 22, 2021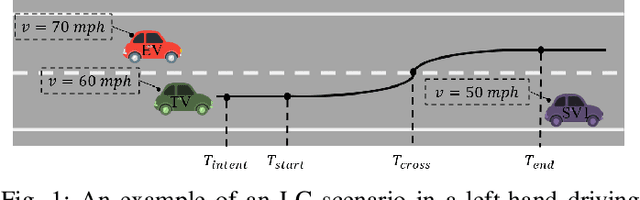
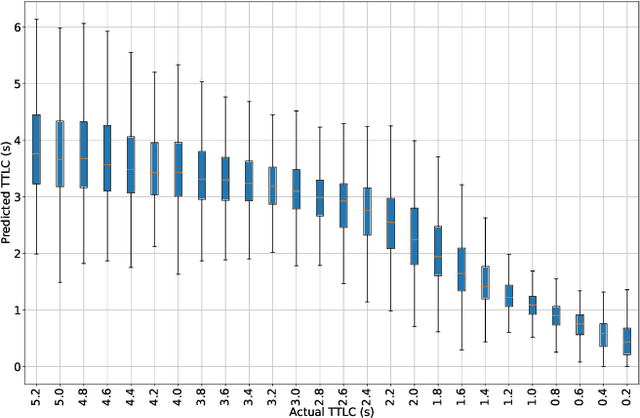
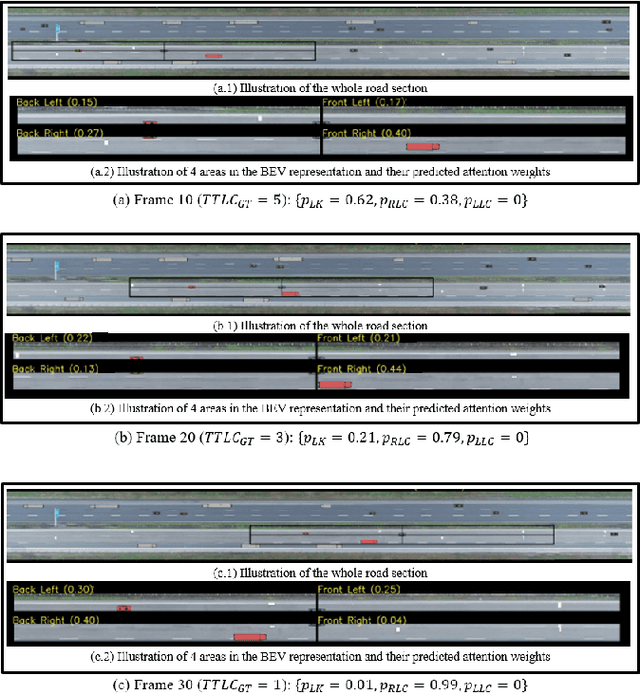

Lane change (LC) is one of the safety-critical manoeuvres in highway driving according to various road accident records. Thus, reliably predicting such manoeuvre in advance is critical for the safe and comfortable operation of automated driving systems. The majority of previous studies rely on detecting a manoeuvre that has been already started, rather than predicting the manoeuvre in advance. Furthermore, most of the previous works do not estimate the key timings of the manoeuvre (e.g., crossing time), which can actually yield more useful information for the decision making in the ego vehicle. To address these shortcomings, this paper proposes a novel multi-task model to simultaneously estimate the likelihood of LC manoeuvres and the time-to-lane-change (TTLC). In both tasks, an attention-based convolutional neural network (CNN) is used as a shared feature extractor from a bird's eye view representation of the driving environment. The spatial attention used in the CNN model improves the feature extraction process by focusing on the most relevant areas of the surrounding environment. In addition, two novel curriculum learning schemes are employed to train the proposed approach. The extensive evaluation and comparative analysis of the proposed method in existing benchmark datasets show that the proposed method outperforms state-of-the-art LC prediction models, particularly considering long-term prediction performance.