 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Comparing seven methods for state-of-health time series prediction for the lithium-ion battery packs of forklifts
Jul 06, 2021

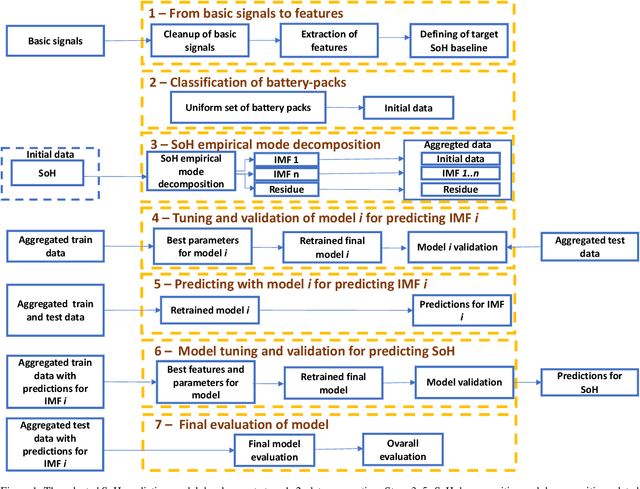
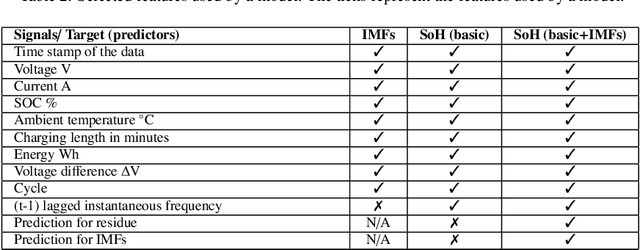
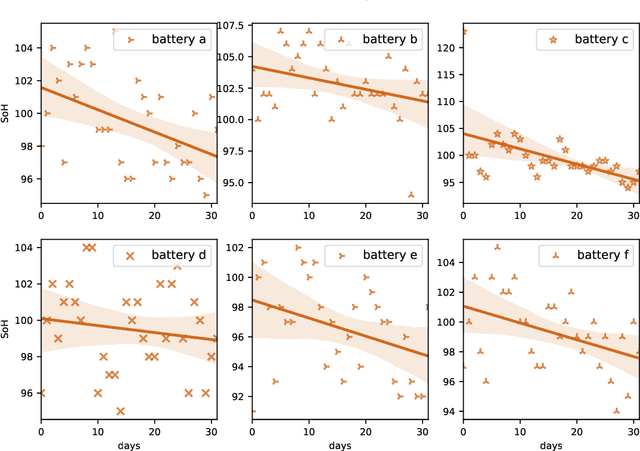
A key aspect for the forklifts is the state-of-health (SoH) assessment to ensure the safety and the reliability of uninterrupted power source. Forecasting the battery SoH well is imperative to enable preventive maintenance and hence to reduce the costs. This paper demonstrates the capabilities of gradient boosting regression for predicting the SoH timeseries under circumstances when there is little prior information available about the batteries. We compared the gradient boosting method with light gradient boosting, extra trees, extreme gradient boosting, random forests, long short-term memory networks and with combined convolutional neural network and long short-term memory networks methods. We used multiple predictors and lagged target signal decomposition results as additional predictors and compared the yielded prediction results with different sets of predictors for each method. For this work, we are in possession of a unique data set of 45 lithium-ion battery packs with large variation in the data. The best model that we derived was validated by a novel walk-forward algorithm that also calculates point-wise confidence intervals for the predictions; we yielded reasonable predictions and confidence intervals for the predictions. Furthermore, we verified this model against five other lithium-ion battery packs; the best model generalised to greater extent to this set of battery packs. The results about the final model suggest that we were able to enhance the results in respect to previously developed models. Moreover, we further validated the model for extracting cycle counts presented in our previous work with data from new forklifts; their battery packs completed around 3000 cycles in a 10-year service period, which corresponds to the cycle life for commercial Nickel-Cobalt-Manganese (NMC) cells.
* 16 pages, 10 figures and 10 tables
Keypoint Message Passing for Video-based Person Re-Identification
Nov 16, 2021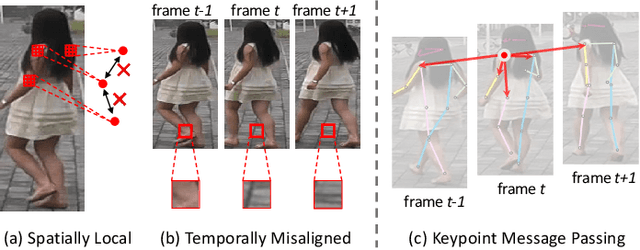
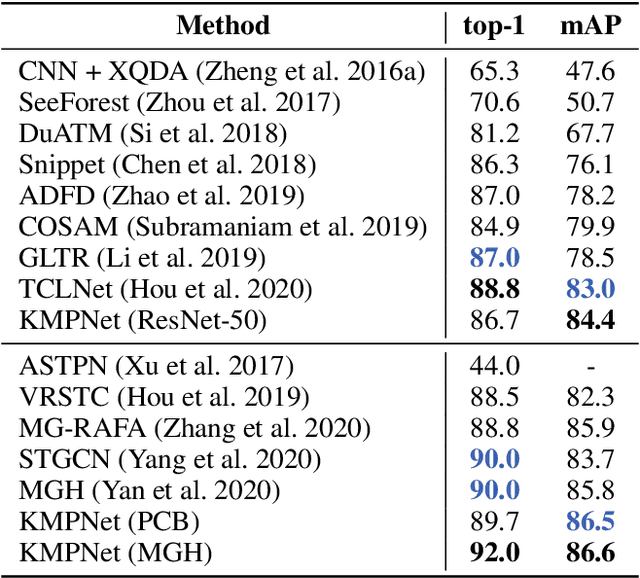
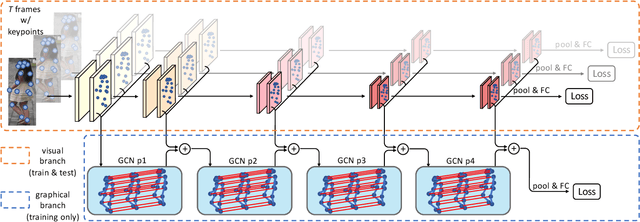
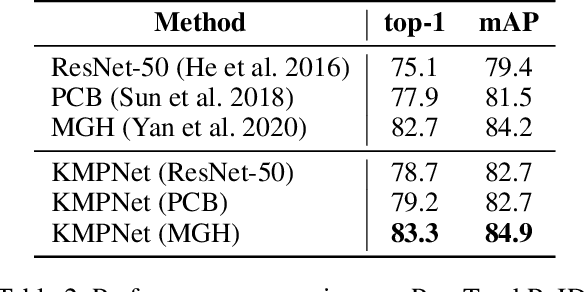
Video-based person re-identification (re-ID) is an important technique in visual surveillance systems which aims to match video snippets of people captured by different cameras. Existing methods are mostly based on convolutional neural networks (CNNs), whose building blocks either process local neighbor pixels at a time, or, when 3D convolutions are used to model temporal information, suffer from the misalignment problem caused by person movement. In this paper, we propose to overcome the limitations of normal convolutions with a human-oriented graph method. Specifically, features located at person joint keypoints are extracted and connected as a spatial-temporal graph. These keypoint features are then updated by message passing from their connected nodes with a graph convolutional network (GCN). During training, the GCN can be attached to any CNN-based person re-ID model to assist representation learning on feature maps, whilst it can be dropped after training for better inference speed. Our method brings significant improvements over the CNN-based baseline model on the MARS dataset with generated person keypoints and a newly annotated dataset: PoseTrackReID. It also defines a new state-of-the-art method in terms of top-1 accuracy and mean average precision in comparison to prior works.
A New Unified Deep Learning Approach with Decomposition-Reconstruction-Ensemble Framework for Time Series Forecasting
Feb 22, 2020

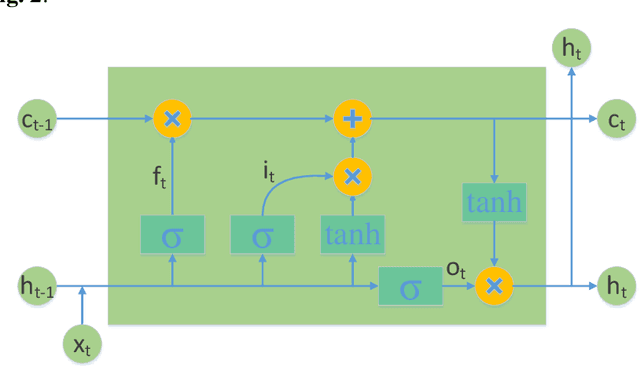
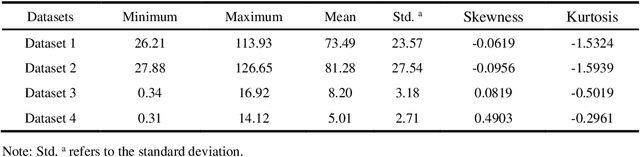
A new variational mode decomposition (VMD) based deep learning approach is proposed in this paper for time series forecasting problem. Firstly, VMD is adopted to decompose the original time series into several sub-signals. Then, a convolutional neural network (CNN) is applied to learn the reconstruction patterns on the decomposed sub-signals to obtain several reconstructed sub-signals. Finally, a long short term memory (LSTM) network is employed to forecast the time series with the decomposed sub-signals and the reconstructed sub-signals as inputs. The proposed VMD-CNN-LSTM approach is originated from the decomposition-reconstruction-ensemble framework, and innovated by embedding the reconstruction, single forecasting, and ensemble steps in a unified deep learning approach. To verify the forecasting performance of the proposed approach, four typical time series datasets are introduced for empirical analysis. The empirical results demonstrate that the proposed approach outperforms consistently the benchmark approaches in terms of forecasting accuracy, and also indicate that the reconstructed sub-signals obtained by CNN is of importance for further improving the forecasting performance.
MedRDF: A Robust and Retrain-Less Diagnostic Framework for Medical Pretrained Models Against Adversarial Attack
Nov 29, 2021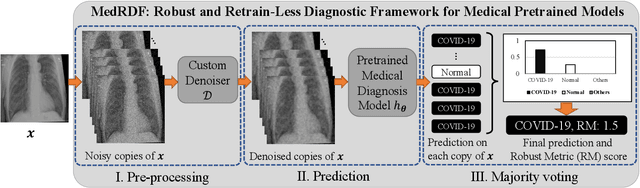
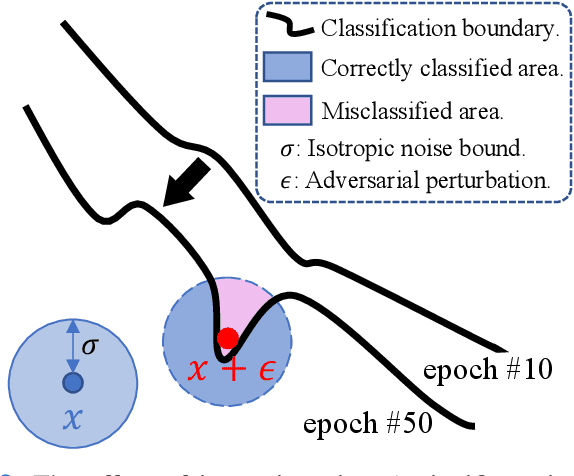
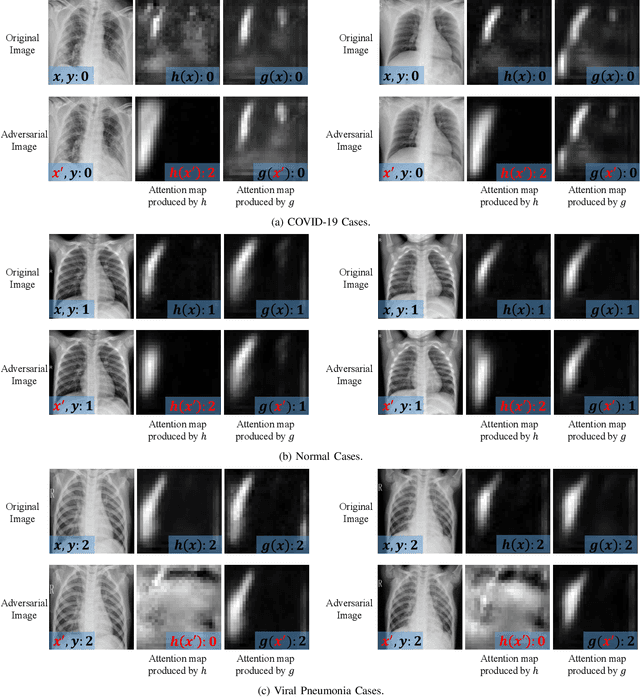
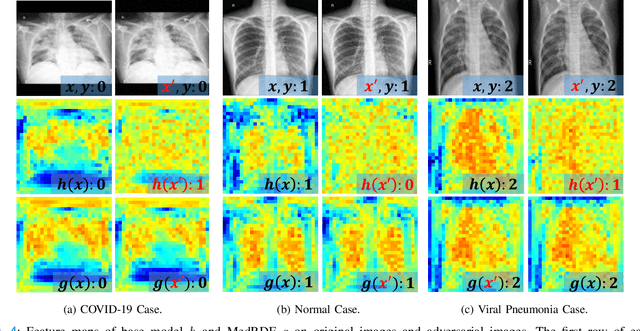
Deep neural networks are discovered to be non-robust when attacked by imperceptible adversarial examples, which is dangerous for it applied into medical diagnostic system that requires high reliability. However, the defense methods that have good effect in natural images may not be suitable for medical diagnostic tasks. The preprocessing methods (e.g., random resizing, compression) may lead to the loss of the small lesions feature in the medical image. Retraining the network on the augmented data set is also not practical for medical models that have already been deployed online. Accordingly, it is necessary to design an easy-to-deploy and effective defense framework for medical diagnostic tasks. In this paper, we propose a Robust and Retrain-Less Diagnostic Framework for Medical pretrained models against adversarial attack (i.e., MedRDF). It acts on the inference time of the pertained medical model. Specifically, for each test image, MedRDF firstly creates a large number of noisy copies of it, and obtains the output labels of these copies from the pretrained medical diagnostic model. Then, based on the labels of these copies, MedRDF outputs the final robust diagnostic result by majority voting. In addition to the diagnostic result, MedRDF produces the Robust Metric (RM) as the confidence of the result. Therefore, it is convenient and reliable to utilize MedRDF to convert pre-trained non-robust diagnostic models into robust ones. The experimental results on COVID-19 and DermaMNIST datasets verify the effectiveness of our MedRDF in improving the robustness of medical diagnostic models.
PatchFormer: A Versatile 3D Transformer Based on Patch Attention
Oct 30, 2021
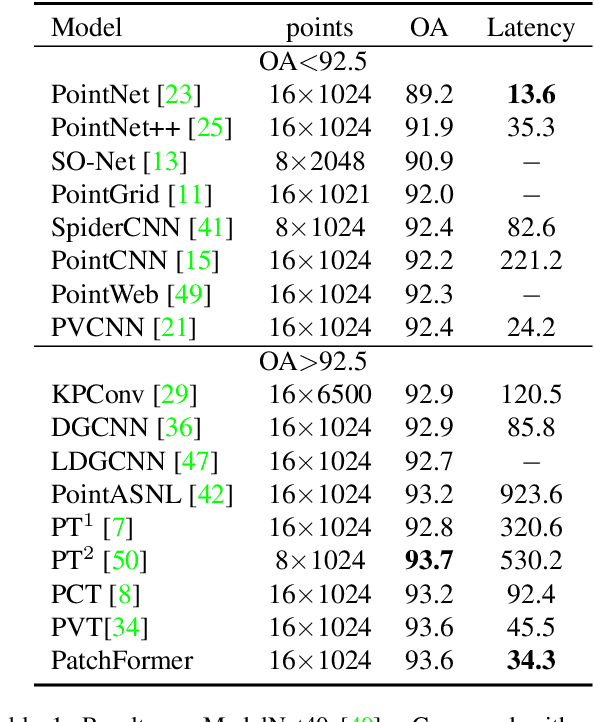
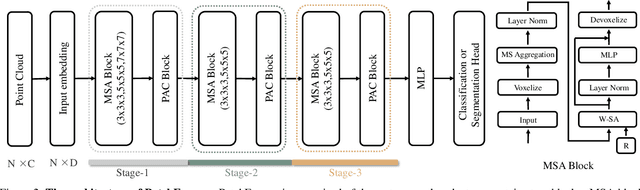
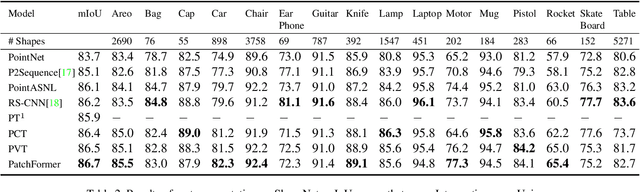
The 3D vision community is witnesses a modeling shift from CNNs to Transformers, where pure Transformer architectures have attained top accuracy on the major 3D learning benchmarks. However, existing 3D Transformers need to generate a large attention map, which has quadratic complexity (both in space and time) with respect to input size. To solve this shortcoming, we introduce patch-attention to adaptively learn a much smaller set of bases upon which the attention maps are computed. By a weighted summation upon these bases, patch-attention not only captures the global shape context but also achieves linear complexity to input size. In addition, we propose a lightweight Multi-scale Attention (MSA) block to build attentions among features of different scales, providing the model with multi-scale features. Based on these proposed modules, we construct our neural architecture called PatchFormer. Extensive experiments demonstrate that our network achieves strong accuracy on general 3D recognition tasks with 7.3x speed-up than previous 3D Transformers.
Finite-Time Analysis of Asynchronous Stochastic Approximation and $Q$-Learning
Feb 01, 2020We consider a general asynchronous Stochastic Approximation (SA) scheme featuring a weighted infinity-norm contractive operator, and prove a bound on its finite-time convergence rate on a single trajectory. Additionally, we specialize the result to asynchronous $Q$-learning. The resulting bound matches the sharpest available bound for synchronous $Q$-learning, and improves over previous known bounds for asynchronous $Q$-learning.
Manas: Mining Software Repositories to Assist AutoML
Dec 06, 2021
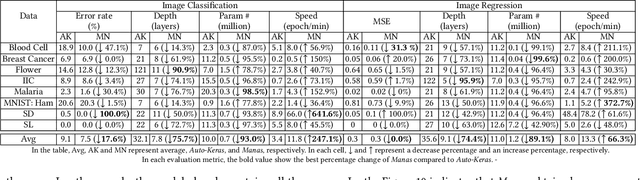
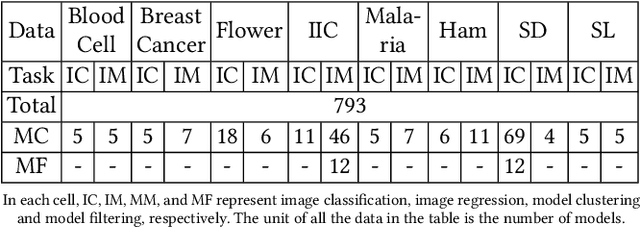
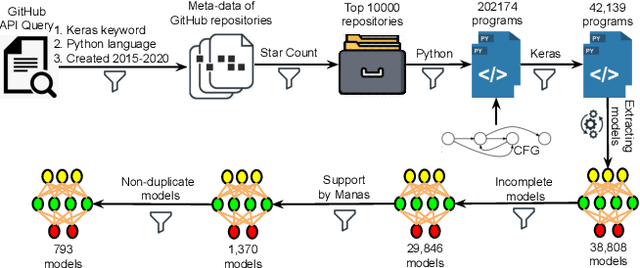
Today deep learning is widely used for building software. A software engineering problem with deep learning is that finding an appropriate convolutional neural network (CNN) model for the task can be a challenge for developers. Recent work on AutoML, more precisely neural architecture search (NAS), embodied by tools like Auto-Keras aims to solve this problem by essentially viewing it as a search problem where the starting point is a default CNN model, and mutation of this CNN model allows exploration of the space of CNN models to find a CNN model that will work best for the problem. These works have had significant success in producing high-accuracy CNN models. There are two problems, however. First, NAS can be very costly, often taking several hours to complete. Second, CNN models produced by NAS can be very complex that makes it harder to understand them and costlier to train them. We propose a novel approach for NAS, where instead of starting from a default CNN model, the initial model is selected from a repository of models extracted from GitHub. The intuition being that developers solving a similar problem may have developed a better starting point compared to the default model. We also analyze common layer patterns of CNN models in the wild to understand changes that the developers make to improve their models. Our approach uses commonly occurring changes as mutation operators in NAS. We have extended Auto-Keras to implement our approach. Our evaluation using 8 top voted problems from Kaggle for tasks including image classification and image regression shows that given the same search time, without loss of accuracy, Manas produces models with 42.9% to 99.6% fewer number of parameters than Auto-Keras' models. Benchmarked on GPU, Manas' models train 30.3% to 641.6% faster than Auto-Keras' models.
Foster Strengths and Circumvent Weaknesses: a Speech Enhancement Framework with Two-branch Collaborative Learning
Oct 12, 2021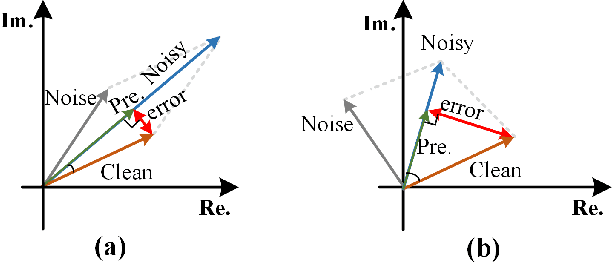
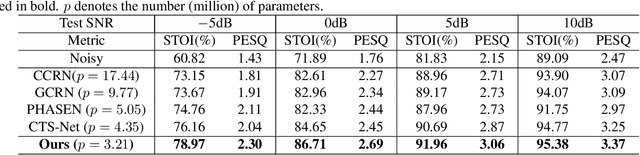
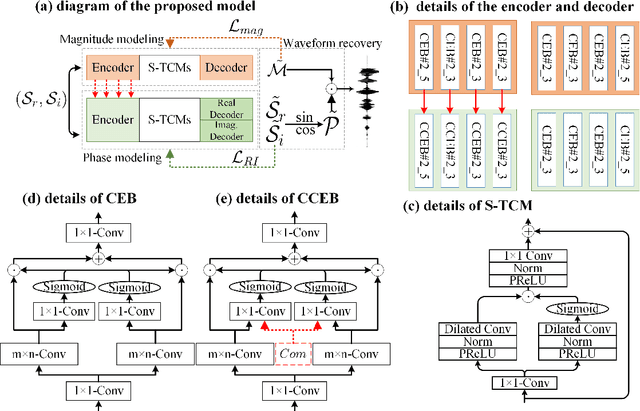
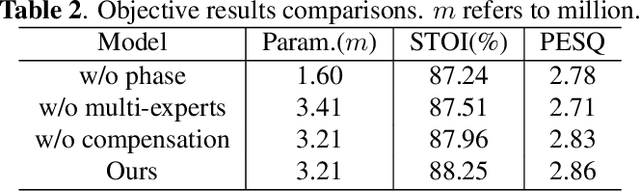
Recent single-channel speech enhancement methods usually convert waveform to the time-frequency domain and use magnitude/complex spectrum as the optimizing target. However, both magnitude-spectrum-based methods and complex-spectrum-based methods have their respective pros and cons. In this paper, we propose a unified two-branch framework to foster strengths and circumvent weaknesses of different paradigms. The proposed framework could take full advantage of the apparent spectral regularity in magnitude spectrogram and break the bottleneck that magnitude-based methods have suffered. Within each branch, we use collaborative expert block and its variants as substitutes for regular convolution layers. Experiments on TIMIT benchmark demonstrate that our method is superior to existing state-of-the-art ones.
Adversarial Online Learning with Variable Plays in the Pursuit-Evasion Game: Theoretical Foundations and Application in Connected and Automated Vehicle Cybersecurity
Oct 26, 2021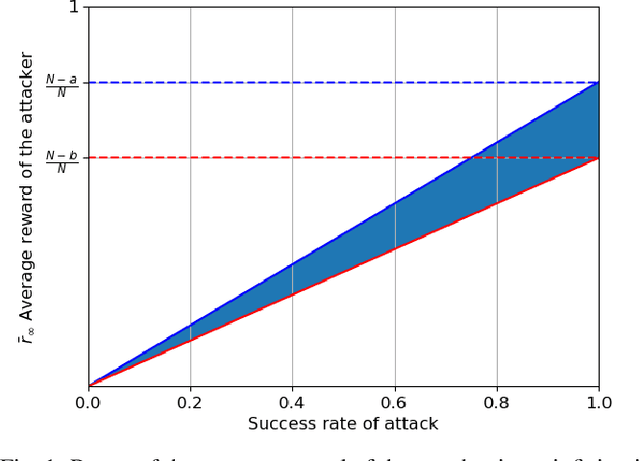
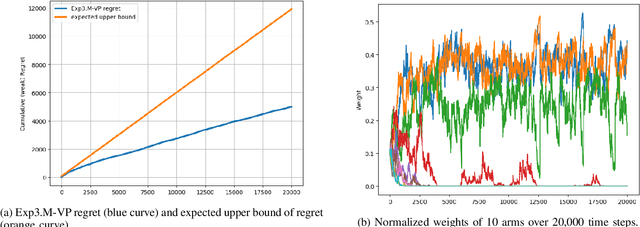
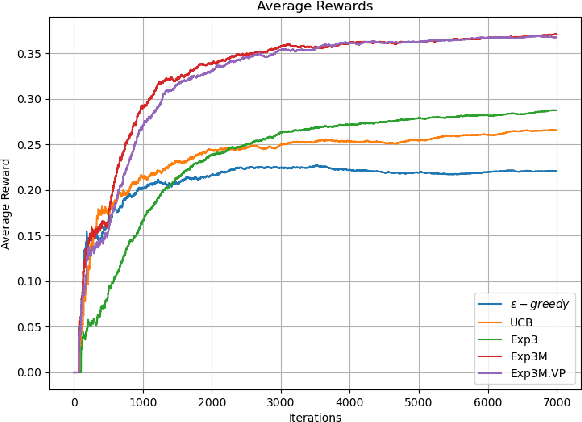
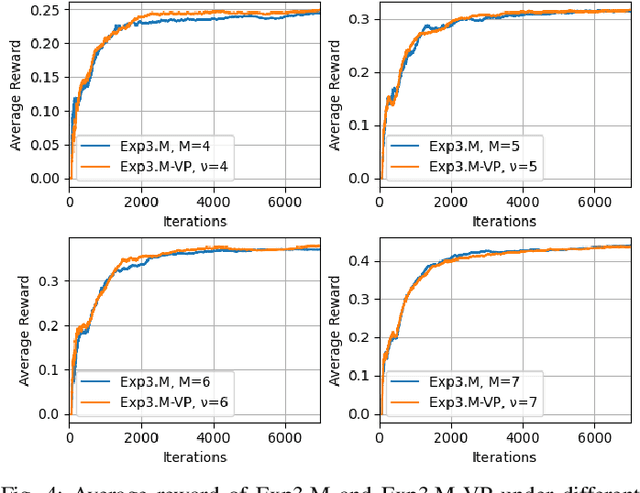
We extend the adversarial/non-stochastic multi-play multi-armed bandit (MPMAB) to the case where the number of arms to play is variable. The work is motivated by the fact that the resources allocated to scan different critical locations in an interconnected transportation system change dynamically over time and depending on the environment. By modeling the malicious hacker and the intrusion monitoring system as the attacker and the defender, respectively, we formulate the problem for the two players as a sequential pursuit-evasion game. We derive the condition under which a Nash equilibrium of the strategic game exists. For the defender side, we provide an exponential-weighted based algorithm with sublinear pseudo-regret. We further extend our model to heterogeneous rewards for both players, and obtain lower and upper bounds on the average reward for the attacker. We provide numerical experiments to demonstrate the effectiveness of a variable-arm play.
* Published in IEEE Access. DOI: 10.1109/ACCESS.2021.3120700
Traffic4cast -- Large-scale Traffic Prediction using 3DResNet and Sparse-UNet
Nov 10, 2021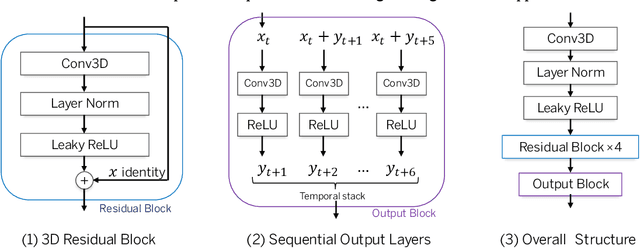
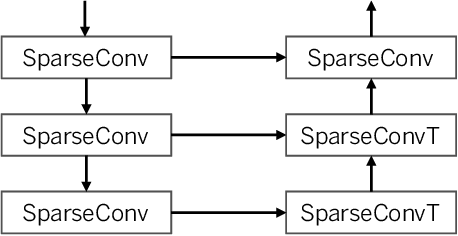
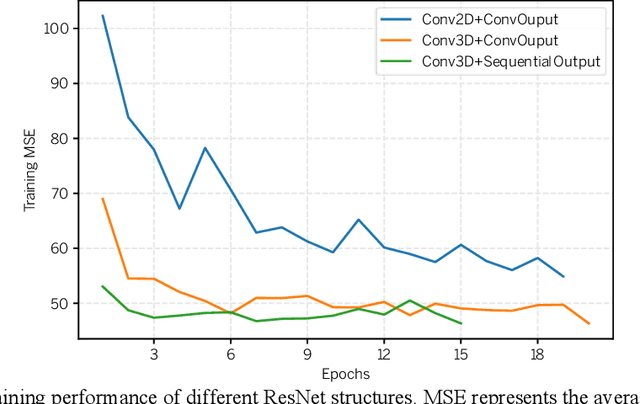

The IARAI competition Traffic4cast 2021 aims to predict short-term city-wide high-resolution traffic states given the static and dynamic traffic information obtained previously. The aim is to build a machine learning model for predicting the normalized average traffic speed and flow of the subregions of multiple large-scale cities using historical data points. The model is supposed to be generic, in a way that it can be applied to new cities. By considering spatiotemporal feature learning and modeling efficiency, we explore 3DResNet and Sparse-UNet approaches for the tasks in this competition. The 3DResNet based models use 3D convolution to learn the spatiotemporal features and apply sequential convolutional layers to enhance the temporal relationship of the outputs. The Sparse-UNet model uses sparse convolutions as the backbone for spatiotemporal feature learning. Since the latter algorithm mainly focuses on non-zero data points of the inputs, it dramatically reduces the computation time, while maintaining a competitive accuracy. Our results show that both of the proposed models achieve much better performance than the baseline algorithms. The codes and pretrained models are available at https://github.com/resuly/Traffic4Cast-2021.