 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Network Traffic Shaping for Enhancing Privacy in IoT Systems
Nov 29, 2021
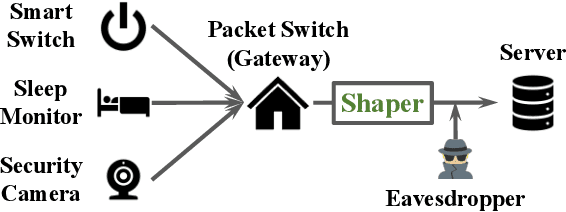
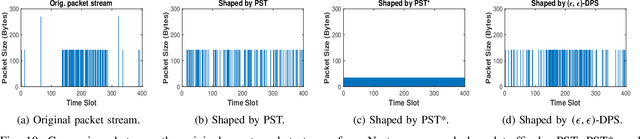
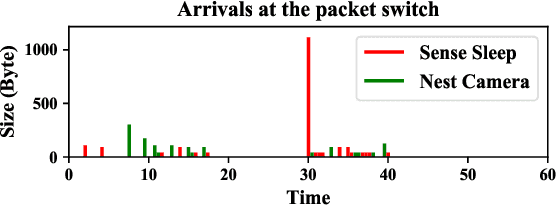
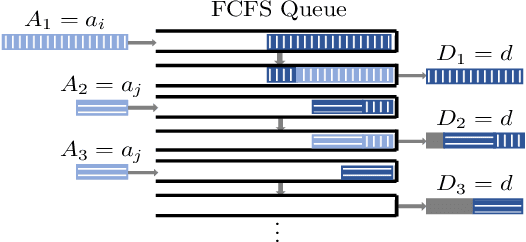
Motivated by privacy issues caused by inference attacks on user activities in the packet sizes and timing information of Internet of Things (IoT) network traffic, we establish a rigorous event-level differential privacy (DP) model on infinite packet streams. We propose a memoryless traffic shaping mechanism satisfying a first-come-first-served queuing discipline that outputs traffic dependent on the input using a DP mechanism. We show that in special cases the proposed mechanism recovers existing shapers which standardize the output independently from the input. To find the optimal shapers for given levels of privacy and transmission efficiency, we formulate the constrained problem of minimizing the expected delay per packet and propose using the expected queue size across time as a proxy. We further show that the constrained minimization is a convex program. We demonstrate the effect of shapers on both synthetic data and packet traces from actual IoT devices. The experimental results reveal inherent privacy-overhead tradeoffs: more shaping overhead provides better privacy protection. Under the same privacy level, there naturally exists a tradeoff between dummy traffic and delay. When dealing with heavier or less bursty input traffic, all shapers become more overhead-efficient. We also show that increased traffic from a larger number of IoT devices makes guaranteeing event-level privacy easier. The DP shaper offers tunable privacy that is invariant with the change in the input traffic distribution and has an advantage in handling burstiness over traffic-independent shapers. This approach well accommodates heterogeneous network conditions and enables users to adapt to their privacy/overhead demands.
Revisiting the Uniform Information Density Hypothesis
Sep 23, 2021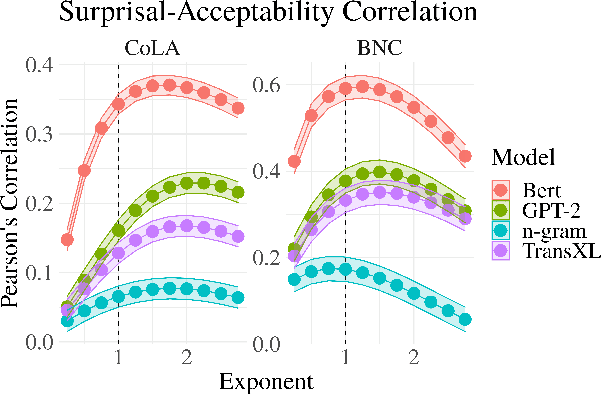
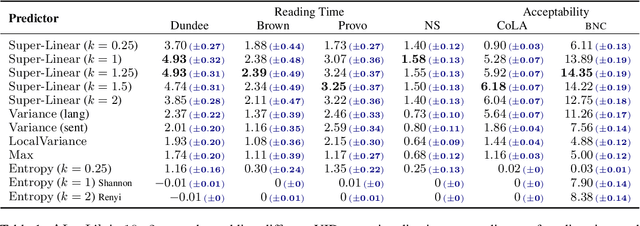
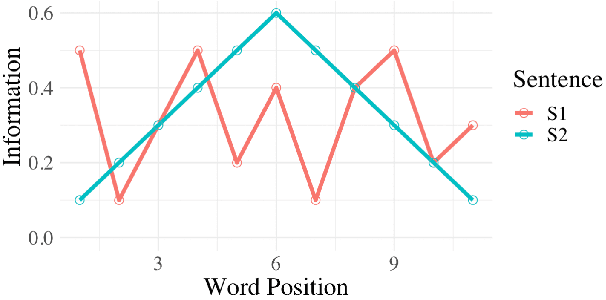
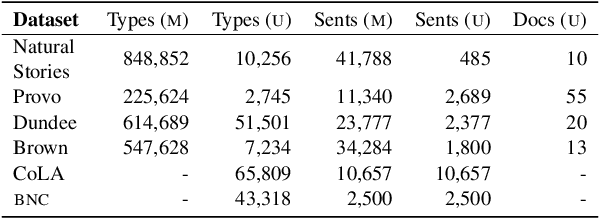
The uniform information density (UID) hypothesis posits a preference among language users for utterances structured such that information is distributed uniformly across a signal. While its implications on language production have been well explored, the hypothesis potentially makes predictions about language comprehension and linguistic acceptability as well. Further, it is unclear how uniformity in a linguistic signal -- or lack thereof -- should be measured, and over which linguistic unit, e.g., the sentence or language level, this uniformity should hold. Here we investigate these facets of the UID hypothesis using reading time and acceptability data. While our reading time results are generally consistent with previous work, they are also consistent with a weakly super-linear effect of surprisal, which would be compatible with UID's predictions. For acceptability judgments, we find clearer evidence that non-uniformity in information density is predictive of lower acceptability. We then explore multiple operationalizations of UID, motivated by different interpretations of the original hypothesis, and analyze the scope over which the pressure towards uniformity is exerted. The explanatory power of a subset of the proposed operationalizations suggests that the strongest trend may be a regression towards a mean surprisal across the language, rather than the phrase, sentence, or document -- a finding that supports a typical interpretation of UID, namely that it is the byproduct of language users maximizing the use of a (hypothetical) communication channel.
Throughput and Latency in the Distributed Q-Learning Random Access mMTC Networks
Oct 30, 2021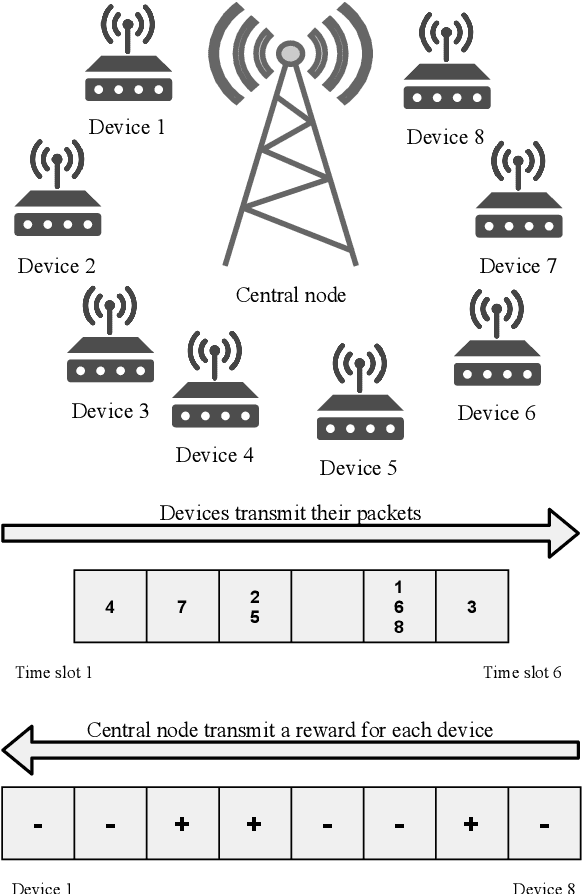
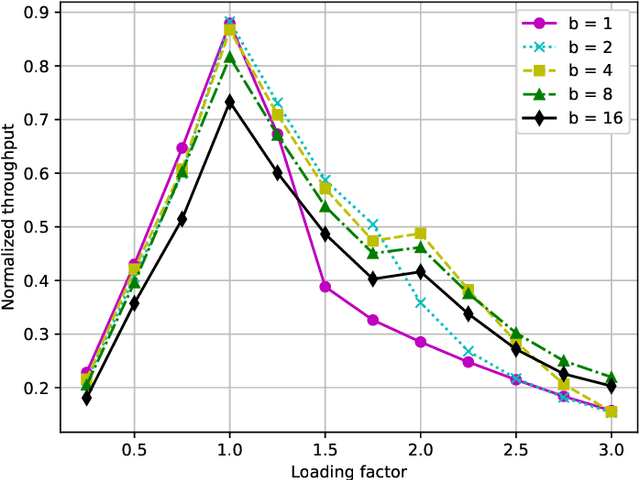
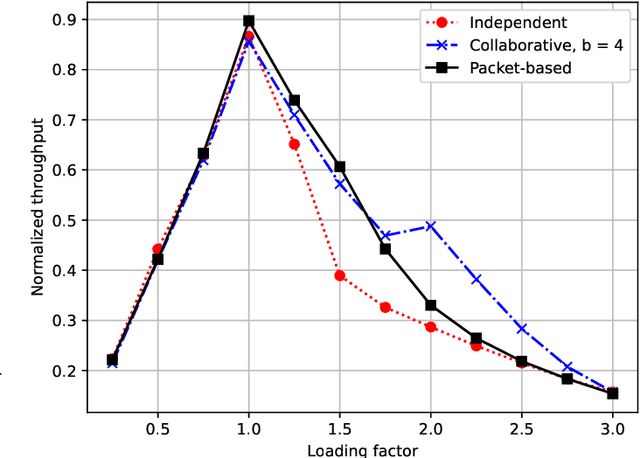
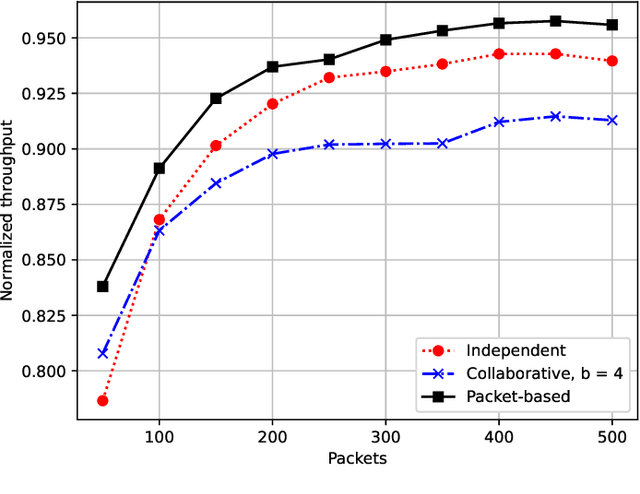
In mMTC mode, with thousands of devices trying to access network resources sporadically, the problem of random access (RA) and collisions between devices that select the same resources becomes crucial. A promising approach to solve such an RA problem is to use learning mechanisms, especially the Q-learning algorithm, where the devices learn about the best time-slot periods to transmit through rewards sent by the central node. In this work, we propose a distributed packet-based learning method by varying the reward from the central node that favors devices having a larger number of remaining packets to transmit. Our numerical results indicated that the proposed distributed packet-based Q-learning method attains a much better throughput-latency trade-off than the alternative independent and collaborative techniques in practical scenarios of interest. In contrast, the number of payload bits of the packet-based technique is reduced regarding the collaborative Q-learning RA technique for achieving the same normalized throughput.
Unified Style Transfer
Oct 20, 2021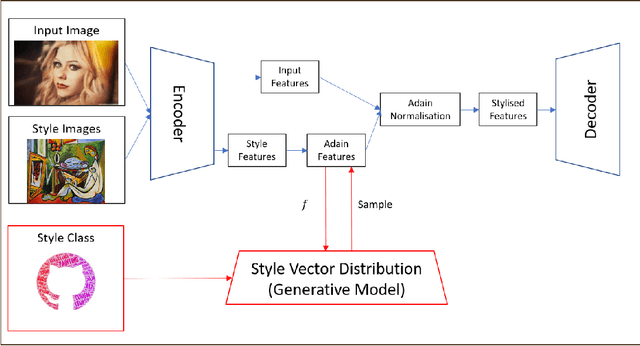
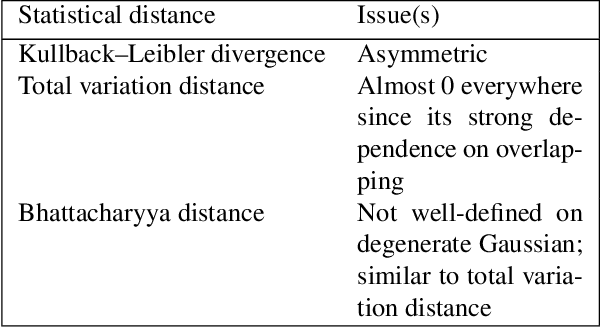
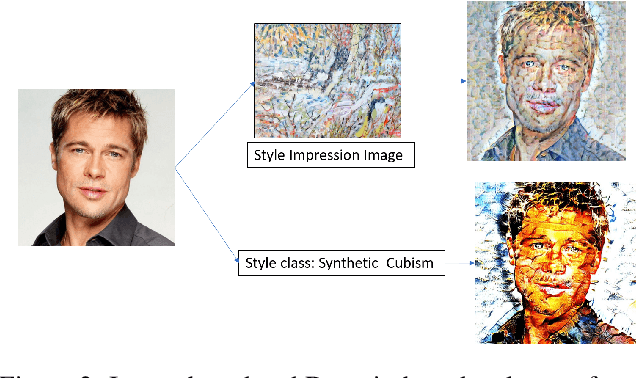

Currently, it is hard to compare and evaluate different style transfer algorithms due to chaotic definitions of style and the absence of agreed objective validation methods in the study of style transfer. In this paper, a novel approach, the Unified Style Transfer (UST) model, is proposed. With the introduction of a generative model for internal style representation, UST can transfer images in two approaches, i.e., Domain-based and Image-based, simultaneously. At the same time, a new philosophy based on the human sense of art and style distributions for evaluating the transfer model is presented and demonstrated, called Statistical Style Analysis. It provides a new path to validate style transfer models' feasibility by validating the general consistency between internal style representation and art facts. Besides, the translation-invariance of AdaIN features is also discussed.
Sequential Community Mode Estimation
Nov 16, 2021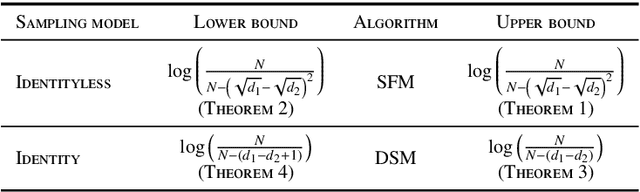
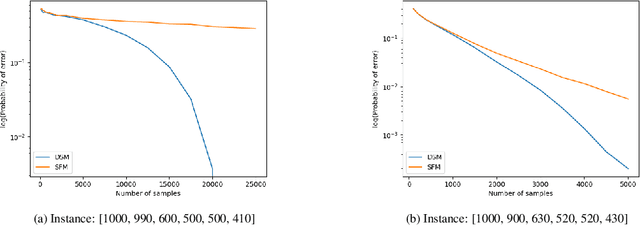

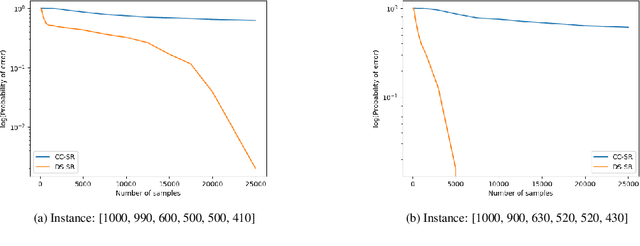
We consider a population, partitioned into a set of communities, and study the problem of identifying the largest community within the population via sequential, random sampling of individuals. There are multiple sampling domains, referred to as \emph{boxes}, which also partition the population. Each box may consist of individuals of different communities, and each community may in turn be spread across multiple boxes. The learning agent can, at any time, sample (with replacement) a random individual from any chosen box; when this is done, the agent learns the community the sampled individual belongs to, and also whether or not this individual has been sampled before. The goal of the agent is to minimize the probability of mis-identifying the largest community in a \emph{fixed budget} setting, by optimizing both the sampling strategy as well as the decision rule. We propose and analyse novel algorithms for this problem, and also establish information theoretic lower bounds on the probability of error under any algorithm. In several cases of interest, the exponential decay rates of the probability of error under our algorithms are shown to be optimal up to constant factors. The proposed algorithms are further validated via simulations on real-world datasets.
Improving Novelty Detection using the Reconstructions of Nearest Neighbours
Nov 11, 2021
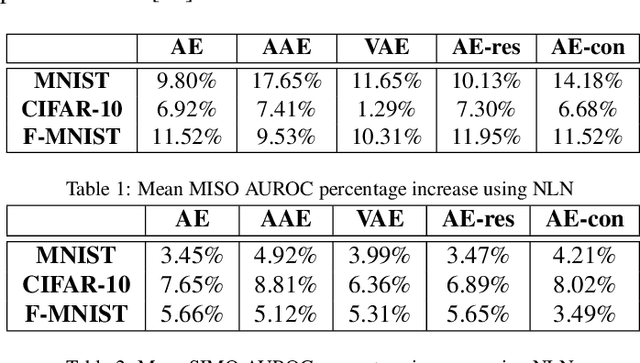
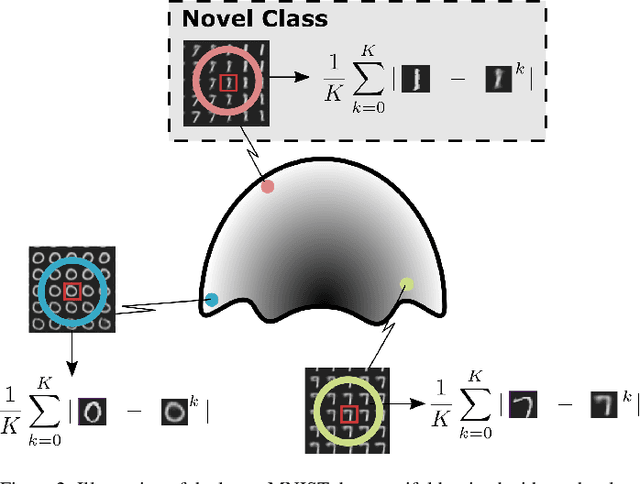
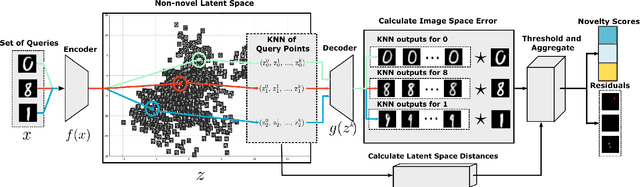
We show that using nearest neighbours in the latent space of autoencoders (AE) significantly improves performance of semi-supervised novelty detection in both single and multi-class contexts. Autoencoding methods detect novelty by learning to differentiate between the non-novel training class(es) and all other unseen classes. Our method harnesses a combination of the reconstructions of the nearest neighbours and the latent-neighbour distances of a given input's latent representation. We demonstrate that our nearest-latent-neighbours (NLN) algorithm is memory and time efficient, does not require significant data augmentation, nor is reliant on pre-trained networks. Furthermore, we show that the NLN-algorithm is easily applicable to multiple datasets without modification. Additionally, the proposed algorithm is agnostic to autoencoder architecture and reconstruction error method. We validate our method across several standard datasets for a variety of different autoencoding architectures such as vanilla, adversarial and variational autoencoders using either reconstruction, residual or feature consistent losses. The results show that the NLN algorithm grants up to a 17% increase in Area Under the Receiver Operating Characteristics (AUROC) curve performance for the multi-class case and 8% for single-class novelty detection.
LayerPipe: Accelerating Deep Neural Network Training by Intra-Layer and Inter-Layer Gradient Pipelining and Multiprocessor Scheduling
Aug 14, 2021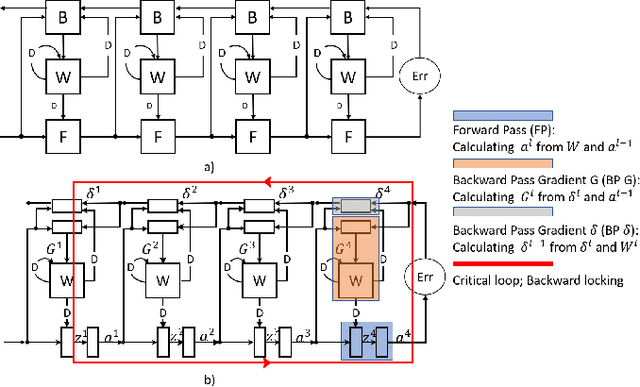
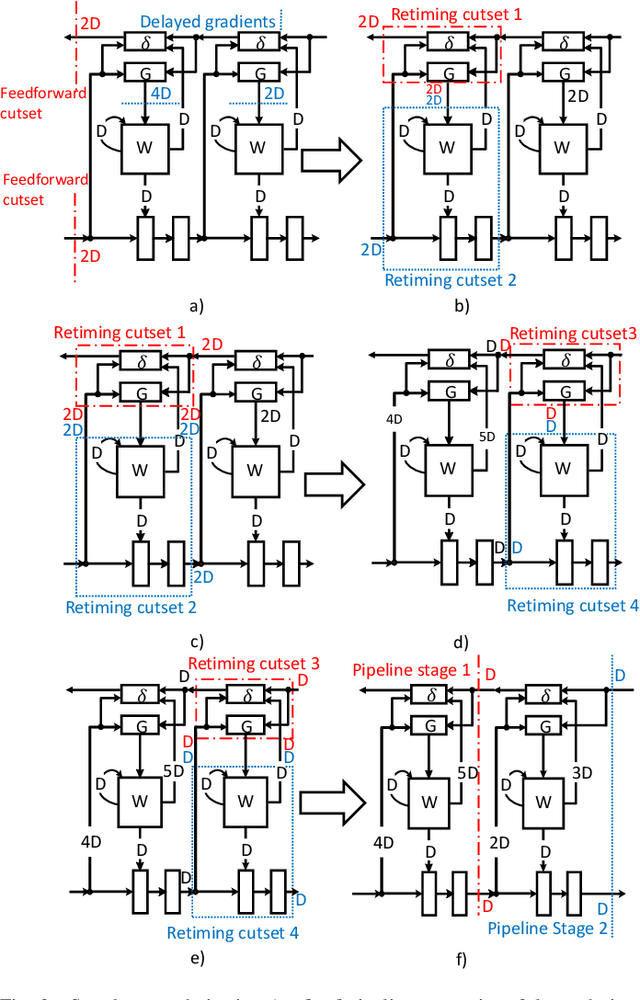
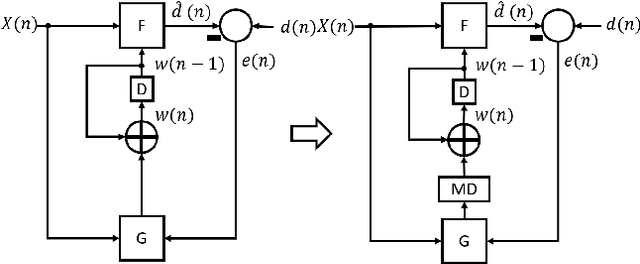
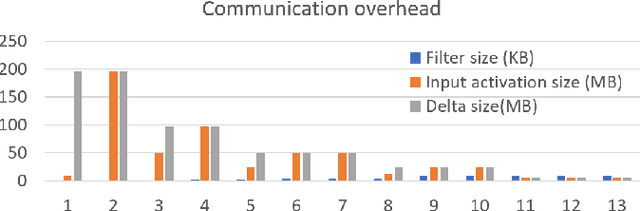
The time required for training the neural networks increases with size, complexity, and depth. Training model parameters by backpropagation inherently creates feedback loops. These loops hinder efficient pipelining and scheduling of the tasks within the layer and between consecutive layers. Prior approaches, such as PipeDream, have exploited the use of delayed gradient to achieve inter-layer pipelining. However, these approaches treat the entire backpropagation as a single task; this leads to an increase in computation time and processor underutilization. This paper presents novel optimization approaches where the gradient computations with respect to the weights and the activation functions are considered independently; therefore, these can be computed in parallel. This is referred to as intra-layer optimization. Additionally, the gradient computation with respect to the activation function is further divided into two parts and distributed to two consecutive layers. This leads to balanced scheduling where the computation time of each layer is the same. This is referred to as inter-layer optimization. The proposed system, referred to as LayerPipe, reduces the number of clock cycles required for training while maximizing processor utilization with minimal inter-processor communication overhead. LayerPipe achieves an average speedup of 25% and upwards of 80% with 7 to 9 processors with less communication overhead when compared to PipeDream.
Comparing seven methods for state-of-health time series prediction for the lithium-ion battery packs of forklifts
Jul 06, 2021
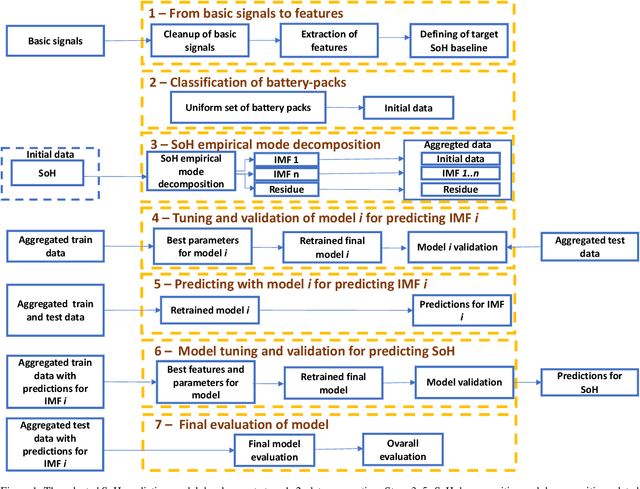
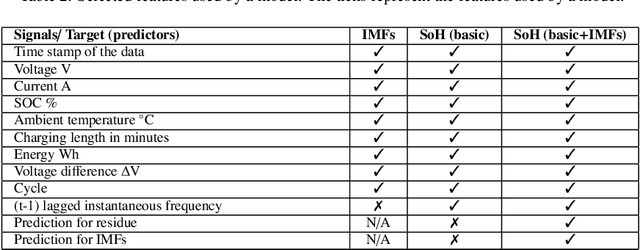
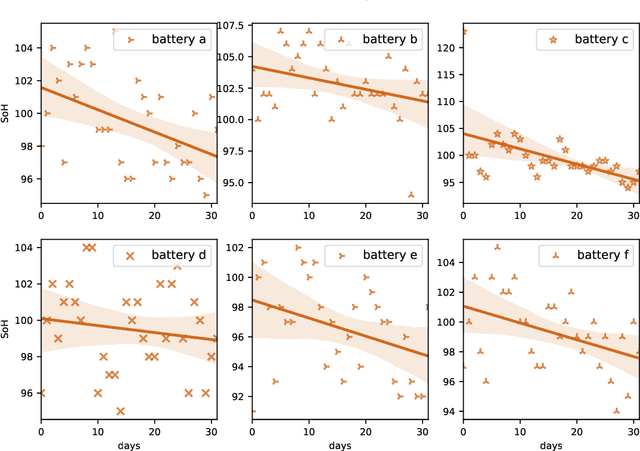
A key aspect for the forklifts is the state-of-health (SoH) assessment to ensure the safety and the reliability of uninterrupted power source. Forecasting the battery SoH well is imperative to enable preventive maintenance and hence to reduce the costs. This paper demonstrates the capabilities of gradient boosting regression for predicting the SoH timeseries under circumstances when there is little prior information available about the batteries. We compared the gradient boosting method with light gradient boosting, extra trees, extreme gradient boosting, random forests, long short-term memory networks and with combined convolutional neural network and long short-term memory networks methods. We used multiple predictors and lagged target signal decomposition results as additional predictors and compared the yielded prediction results with different sets of predictors for each method. For this work, we are in possession of a unique data set of 45 lithium-ion battery packs with large variation in the data. The best model that we derived was validated by a novel walk-forward algorithm that also calculates point-wise confidence intervals for the predictions; we yielded reasonable predictions and confidence intervals for the predictions. Furthermore, we verified this model against five other lithium-ion battery packs; the best model generalised to greater extent to this set of battery packs. The results about the final model suggest that we were able to enhance the results in respect to previously developed models. Moreover, we further validated the model for extracting cycle counts presented in our previous work with data from new forklifts; their battery packs completed around 3000 cycles in a 10-year service period, which corresponds to the cycle life for commercial Nickel-Cobalt-Manganese (NMC) cells.
* 16 pages, 10 figures and 10 tables
Global Interaction Modelling in Vision Transformer via Super Tokens
Nov 25, 2021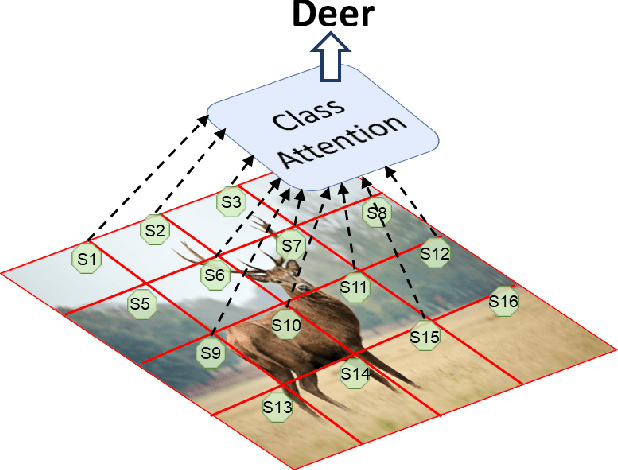
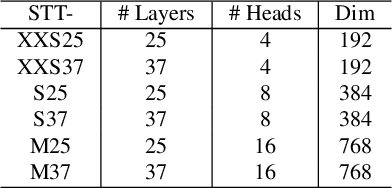
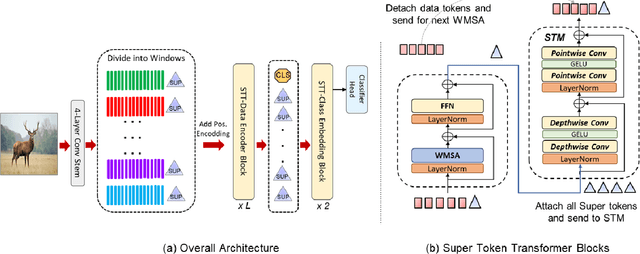
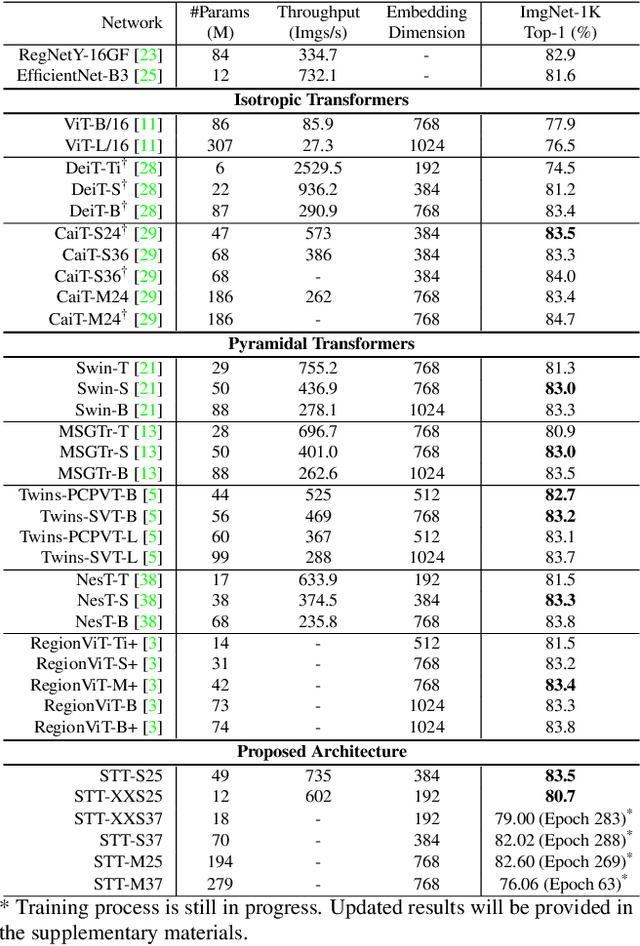
With the popularity of Transformer architectures in computer vision, the research focus has shifted towards developing computationally efficient designs. Window-based local attention is one of the major techniques being adopted in recent works. These methods begin with very small patch size and small embedding dimensions and then perform strided convolution (patch merging) in order to reduce the feature map size and increase embedding dimensions, hence, forming a pyramidal Convolutional Neural Network (CNN) like design. In this work, we investigate local and global information modelling in transformers by presenting a novel isotropic architecture that adopts local windows and special tokens, called Super tokens, for self-attention. Specifically, a single Super token is assigned to each image window which captures the rich local details for that window. These tokens are then employed for cross-window communication and global representation learning. Hence, most of the learning is independent of the image patches $(N)$ in the higher layers, and the class embedding is learned solely based on the Super tokens $(N/M^2)$ where $M^2$ is the window size. In standard image classification on Imagenet-1K, the proposed Super tokens based transformer (STT-S25) achieves 83.5\% accuracy which is equivalent to Swin transformer (Swin-B) with circa half the number of parameters (49M) and double the inference time throughput. The proposed Super token transformer offers a lightweight and promising backbone for visual recognition tasks.
GPU-accelerated Optimal Path Planning in Stochastic Dynamic Environments
Sep 02, 2021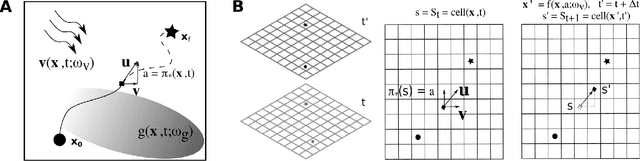
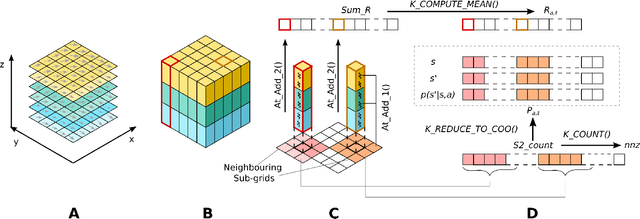
Autonomous marine vehicles play an essential role in many ocean science and engineering applications. Planning time and energy optimal paths for these vehicles to navigate in stochastic dynamic ocean environments is essential to reduce operational costs. In some missions, they must also harvest solar, wind, or wave energy (modeled as a stochastic scalar field) and move in optimal paths that minimize net energy consumption. Markov Decision Processes (MDPs) provide a natural framework for sequential decision-making for robotic agents in such environments. However, building a realistic model and solving the modeled MDP becomes computationally expensive in large-scale real-time applications, warranting the need for parallel algorithms and efficient implementation. In the present work, we introduce an efficient end-to-end GPU-accelerated algorithm that (i) builds the MDP model (computing transition probabilities and expected one-step rewards); and (ii) solves the MDP to compute an optimal policy. We develop methodical and algorithmic solutions to overcome the limited global memory of GPUs by (i) using a dynamic reduced-order representation of the ocean flows, (ii) leveraging the sparse nature of the state transition probability matrix, (iii) introducing a neighbouring sub-grid concept and (iv) proving that it is sufficient to use only the stochastic scalar field's mean to compute the expected one-step rewards for missions involving energy harvesting from the environment; thereby saving memory and reducing the computational effort. We demonstrate the algorithm on a simulated stochastic dynamic environment and highlight that it builds the MDP model and computes the optimal policy 600-1000x faster than conventional CPU implementations, making it suitable for real-time use.