 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Distributed Adaptive Learning Under Communication Constraints
Dec 03, 2021

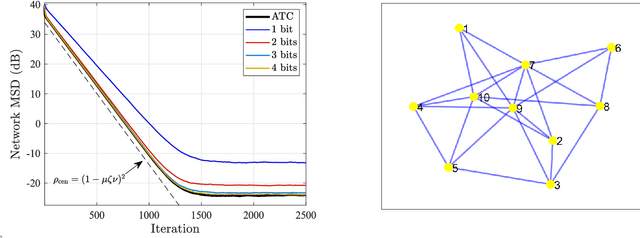
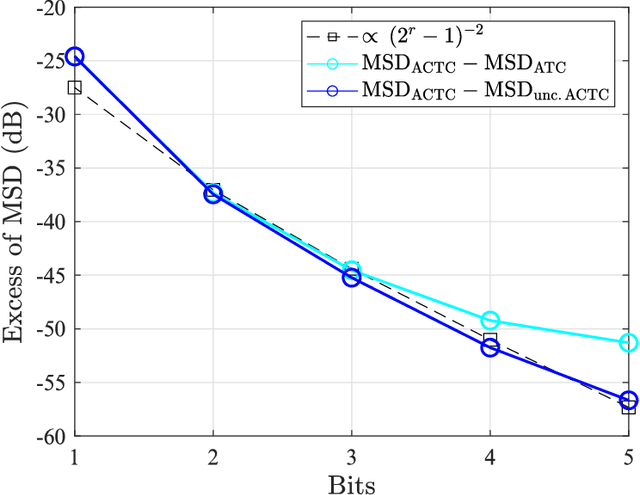
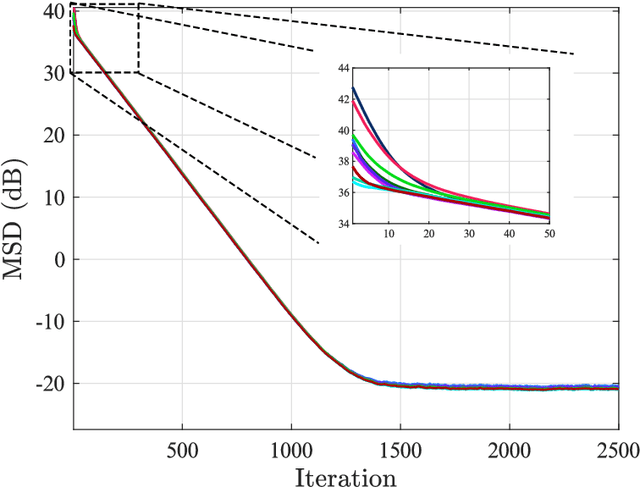
This work examines adaptive distributed learning strategies designed to operate under communication constraints. We consider a network of agents that must solve an online optimization problem from continual observation of streaming data. The agents implement a distributed cooperative strategy where each agent is allowed to perform local exchange of information with its neighbors. In order to cope with communication constraints, the exchanged information must be unavoidably compressed. We propose a diffusion strategy nicknamed as ACTC (Adapt-Compress-Then-Combine), which relies on the following steps: i) an adaptation step where each agent performs an individual stochastic-gradient update with constant step-size; ii) a compression step that leverages a recently introduced class of stochastic compression operators; and iii) a combination step where each agent combines the compressed updates received from its neighbors. The distinguishing elements of this work are as follows. First, we focus on adaptive strategies, where constant (as opposed to diminishing) step-sizes are critical to respond in real time to nonstationary variations. Second, we consider the general class of directed graphs and left-stochastic combination policies, which allow us to enhance the interplay between topology and learning. Third, in contrast with related works that assume strong convexity for all individual agents' cost functions, we require strong convexity only at a network level, a condition satisfied even if a single agent has a strongly-convex cost and the remaining agents have non-convex costs. Fourth, we focus on a diffusion (as opposed to consensus) strategy. Under the demanding setting of compressed information, we establish that the ACTC iterates fluctuate around the desired optimizer, achieving remarkable savings in terms of bits exchanged between neighboring agents.
Continuous and Discrete-Time Analysis of Stochastic Gradient Descent for Convex and Non-Convex Functions
Apr 08, 2020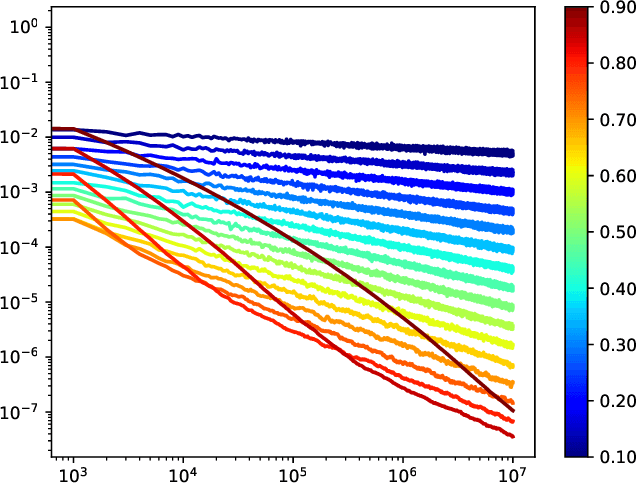

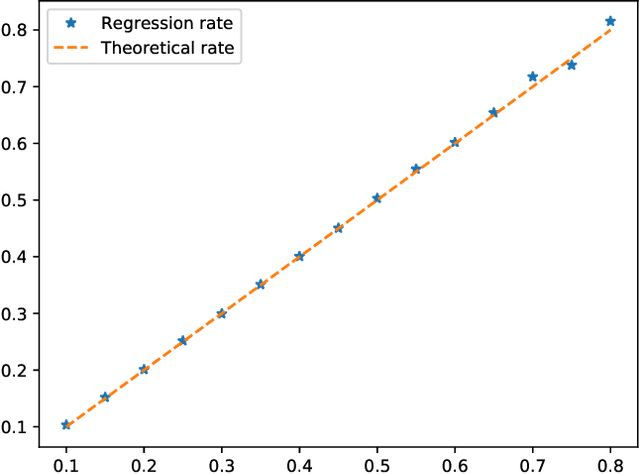

This paper proposes a thorough theoretical analysis of Stochastic Gradient Descent (SGD) with decreasing step sizes. First, we show that the recursion defining SGD can be provably approximated by solutions of a time inhomogeneous Stochastic Differential Equation (SDE) in a weak and strong sense. Then, motivated by recent analyses of deterministic and stochastic optimization methods by their continuous counterpart, we study the long-time convergence of the continuous processes at hand and establish non-asymptotic bounds. To that purpose, we develop new comparison techniques which we think are of independent interest. This continuous analysis allows us to develop an intuition on the convergence of SGD and, adapting the technique to the discrete setting, we show that the same results hold to the corresponding sequences. In our analysis, we notably obtain non-asymptotic bounds in the convex setting for SGD under weaker assumptions than the ones considered in previous works. Finally, we also establish finite time convergence results under various conditions, including relaxations of the famous {\L}ojasiewicz inequality, which can be applied to a class of non-convex functions.
Runtime Interchange for Adaptive Re-use of Intelligent Cyber-Physical System Controllers
Sep 24, 2021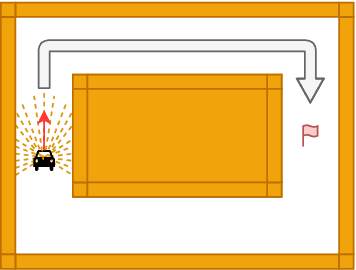
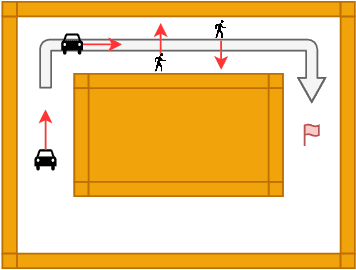
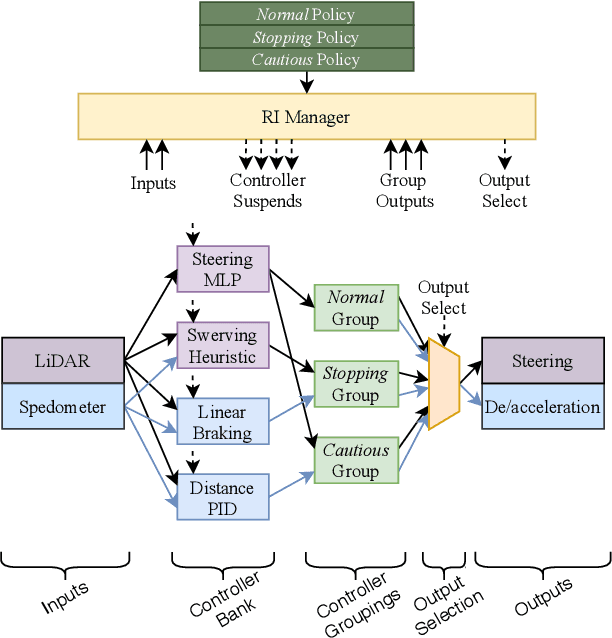
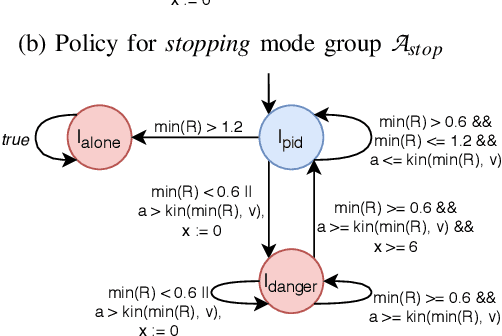
Cyber-Physical Systems (CPSs) such as those found within autonomous vehicles are increasingly adopting Artificial Neural Network (ANN)-based controllers. To ensure the safety of these controllers, there is a spate of recent activity to formally verify the ANN-based designs. There are two challenges with these approaches: (1) The verification of such systems is difficult and time consuming. (2) These verified controllers are not able to adapt to frequent requirements changes, which are typical in situations like autonomous driving. This raises the question: how can trained and verified controllers, which have gone through expensive training and verification processes, be re-used to deal with requirement changes? This paper addresses this challenge for the first time by proposing a new framework that is capable of dealing with requirement changes at runtime through a mechanism we term runtime interchange. Our approach functions via a continual exchange and selection process of multiple pre-verified controllers. It represents a key step on the way to component-oriented engineering for intelligent designs, as it preserves the behaviours of the original controllers while introducing additional functionality. To demonstrate the efficacy of our approach we utilise an existing autonomous driving case study as well as a set of smaller benchmarks. These show that introduced overheads are extremely minimal and that the approach is very scalable.
Efficient Neuromorphic Signal Processing with Loihi 2
Nov 05, 2021
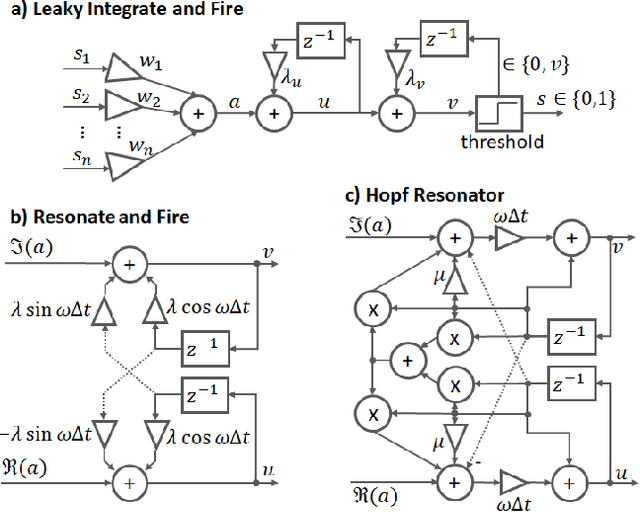
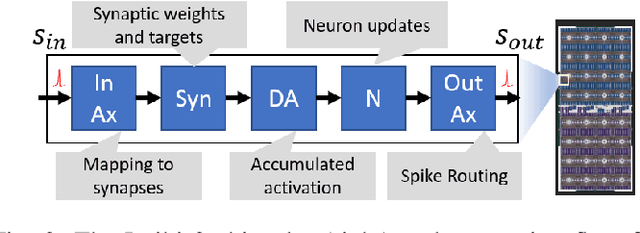

The biologically inspired spiking neurons used in neuromorphic computing are nonlinear filters with dynamic state variables -- very different from the stateless neuron models used in deep learning. The next version of Intel's neuromorphic research processor, Loihi 2, supports a wide range of stateful spiking neuron models with fully programmable dynamics. Here we showcase advanced spiking neuron models that can be used to efficiently process streaming data in simulation experiments on emulated Loihi 2 hardware. In one example, Resonate-and-Fire (RF) neurons are used to compute the Short Time Fourier Transform (STFT) with similar computational complexity but 47x less output bandwidth than the conventional STFT. In another example, we describe an algorithm for optical flow estimation using spatiotemporal RF neurons that requires over 90x fewer operations than a conventional DNN-based solution. We also demonstrate promising preliminary results using backpropagation to train RF neurons for audio classification tasks. Finally, we show that a cascade of Hopf resonators - a variant of the RF neuron - replicates novel properties of the cochlea and motivates an efficient spike-based spectrogram encoder.
Diffusion Schrödinger Bridge with Applications to Score-Based Generative Modeling
Jun 16, 2021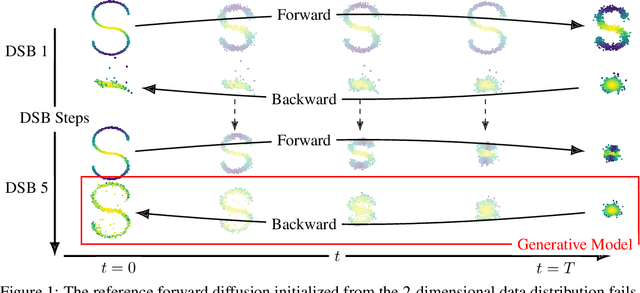
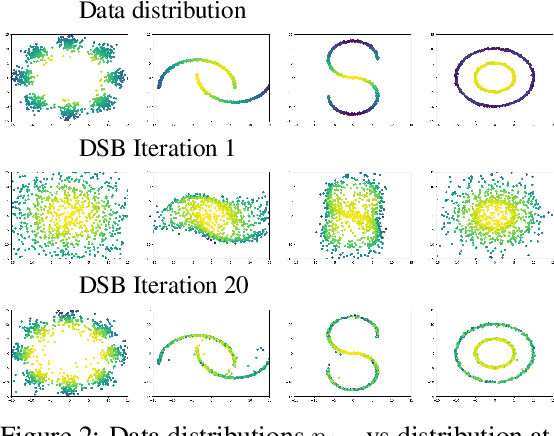
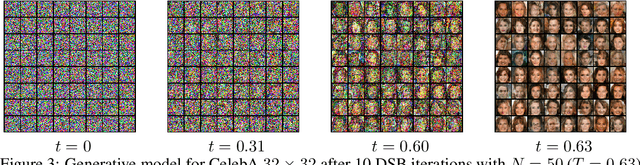
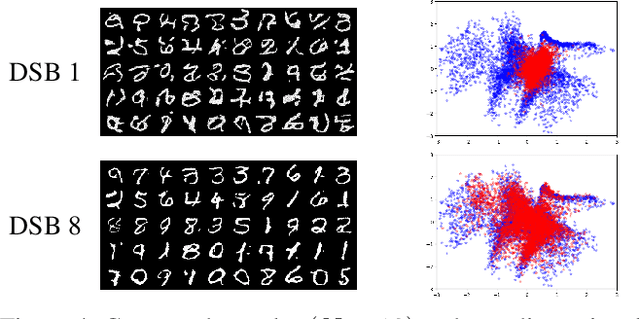
Progressively applying Gaussian noise transforms complex data distributions to approximately Gaussian. Reversing this dynamic defines a generative model. When the forward noising process is given by a Stochastic Differential Equation (SDE), Song et al. (2021) demonstrate how the time inhomogeneous drift of the associated reverse-time SDE may be estimated using score-matching. A limitation of this approach is that the forward-time SDE must be run for a sufficiently long time for the final distribution to be approximately Gaussian. In contrast, solving the Schr\"odinger Bridge problem (SB), i.e. an entropy-regularized optimal transport problem on path spaces, yields diffusions which generate samples from the data distribution in finite time. We present Diffusion SB (DSB), an original approximation of the Iterative Proportional Fitting (IPF) procedure to solve the SB problem, and provide theoretical analysis along with generative modeling experiments. The first DSB iteration recovers the methodology proposed by Song et al. (2021), with the flexibility of using shorter time intervals, as subsequent DSB iterations reduce the discrepancy between the final-time marginal of the forward (resp. backward) SDE with respect to the prior (resp. data) distribution. Beyond generative modeling, DSB offers a widely applicable computational optimal transport tool as the continuous state-space analogue of the popular Sinkhorn algorithm (Cuturi, 2013).
Network Traffic Shaping for Enhancing Privacy in IoT Systems
Nov 29, 2021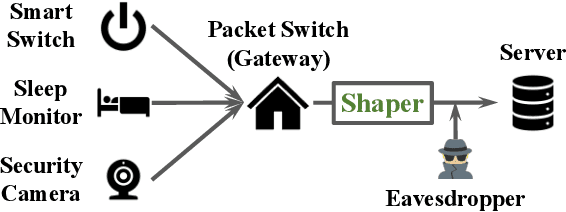
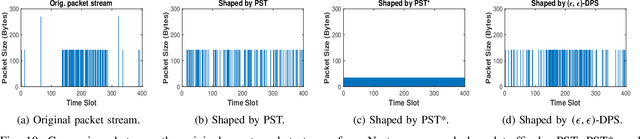
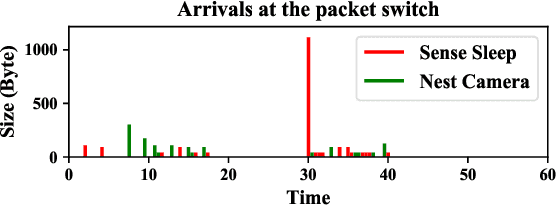
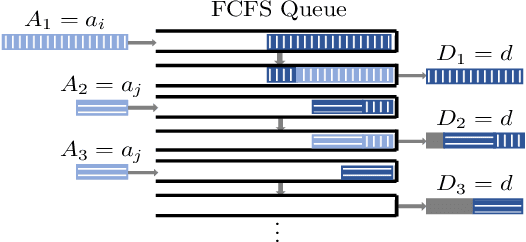
Motivated by privacy issues caused by inference attacks on user activities in the packet sizes and timing information of Internet of Things (IoT) network traffic, we establish a rigorous event-level differential privacy (DP) model on infinite packet streams. We propose a memoryless traffic shaping mechanism satisfying a first-come-first-served queuing discipline that outputs traffic dependent on the input using a DP mechanism. We show that in special cases the proposed mechanism recovers existing shapers which standardize the output independently from the input. To find the optimal shapers for given levels of privacy and transmission efficiency, we formulate the constrained problem of minimizing the expected delay per packet and propose using the expected queue size across time as a proxy. We further show that the constrained minimization is a convex program. We demonstrate the effect of shapers on both synthetic data and packet traces from actual IoT devices. The experimental results reveal inherent privacy-overhead tradeoffs: more shaping overhead provides better privacy protection. Under the same privacy level, there naturally exists a tradeoff between dummy traffic and delay. When dealing with heavier or less bursty input traffic, all shapers become more overhead-efficient. We also show that increased traffic from a larger number of IoT devices makes guaranteeing event-level privacy easier. The DP shaper offers tunable privacy that is invariant with the change in the input traffic distribution and has an advantage in handling burstiness over traffic-independent shapers. This approach well accommodates heterogeneous network conditions and enables users to adapt to their privacy/overhead demands.
3DP3: 3D Scene Perception via Probabilistic Programming
Oct 30, 2021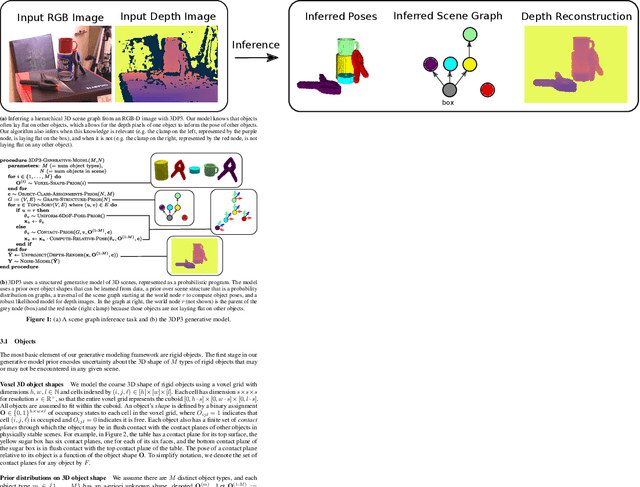
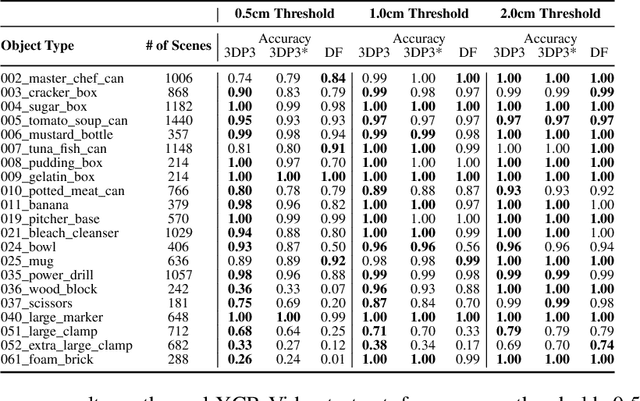
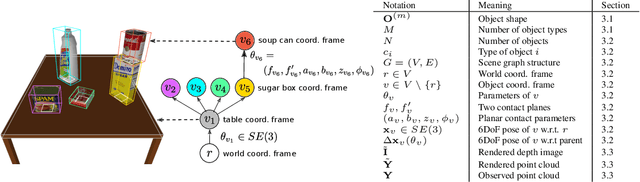
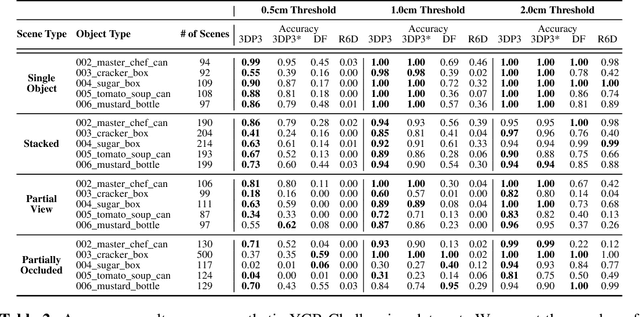
We present 3DP3, a framework for inverse graphics that uses inference in a structured generative model of objects, scenes, and images. 3DP3 uses (i) voxel models to represent the 3D shape of objects, (ii) hierarchical scene graphs to decompose scenes into objects and the contacts between them, and (iii) depth image likelihoods based on real-time graphics. Given an observed RGB-D image, 3DP3's inference algorithm infers the underlying latent 3D scene, including the object poses and a parsimonious joint parametrization of these poses, using fast bottom-up pose proposals, novel involutive MCMC updates of the scene graph structure, and, optionally, neural object detectors and pose estimators. We show that 3DP3 enables scene understanding that is aware of 3D shape, occlusion, and contact structure. Our results demonstrate that 3DP3 is more accurate at 6DoF object pose estimation from real images than deep learning baselines and shows better generalization to challenging scenes with novel viewpoints, contact, and partial observability.
Sequential Community Mode Estimation
Nov 16, 2021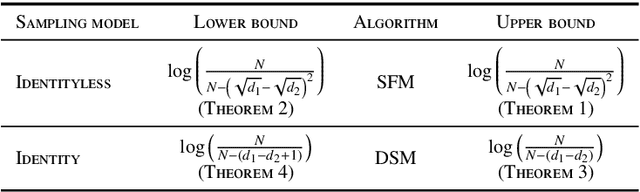
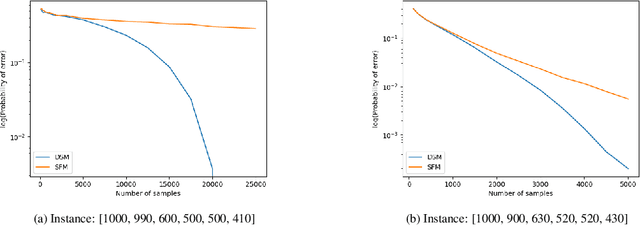

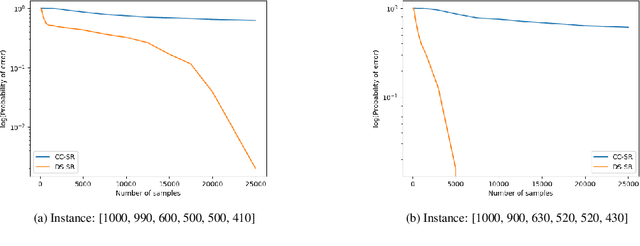
We consider a population, partitioned into a set of communities, and study the problem of identifying the largest community within the population via sequential, random sampling of individuals. There are multiple sampling domains, referred to as \emph{boxes}, which also partition the population. Each box may consist of individuals of different communities, and each community may in turn be spread across multiple boxes. The learning agent can, at any time, sample (with replacement) a random individual from any chosen box; when this is done, the agent learns the community the sampled individual belongs to, and also whether or not this individual has been sampled before. The goal of the agent is to minimize the probability of mis-identifying the largest community in a \emph{fixed budget} setting, by optimizing both the sampling strategy as well as the decision rule. We propose and analyse novel algorithms for this problem, and also establish information theoretic lower bounds on the probability of error under any algorithm. In several cases of interest, the exponential decay rates of the probability of error under our algorithms are shown to be optimal up to constant factors. The proposed algorithms are further validated via simulations on real-world datasets.
Improving Novelty Detection using the Reconstructions of Nearest Neighbours
Nov 11, 2021
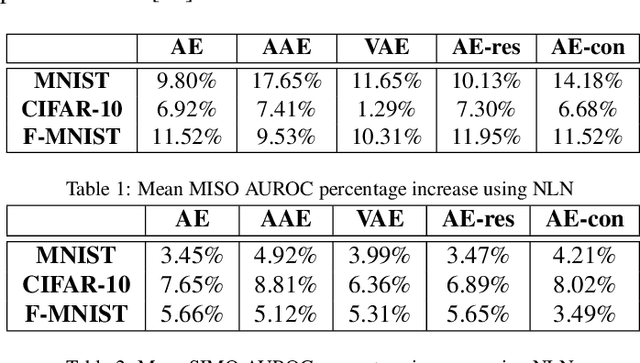
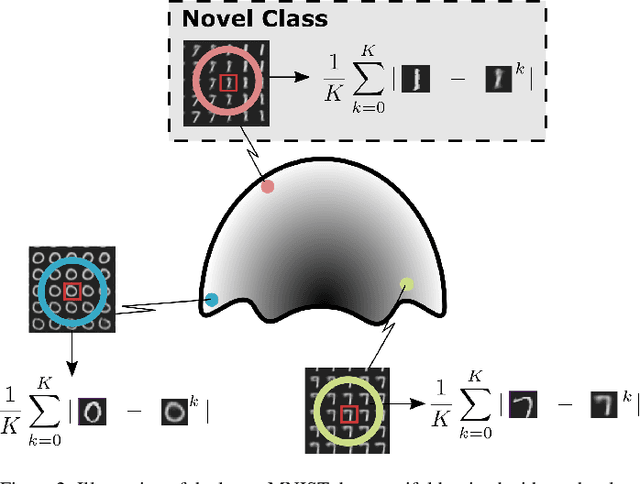
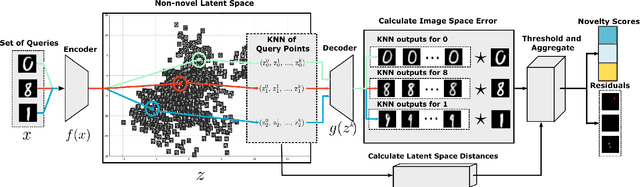
We show that using nearest neighbours in the latent space of autoencoders (AE) significantly improves performance of semi-supervised novelty detection in both single and multi-class contexts. Autoencoding methods detect novelty by learning to differentiate between the non-novel training class(es) and all other unseen classes. Our method harnesses a combination of the reconstructions of the nearest neighbours and the latent-neighbour distances of a given input's latent representation. We demonstrate that our nearest-latent-neighbours (NLN) algorithm is memory and time efficient, does not require significant data augmentation, nor is reliant on pre-trained networks. Furthermore, we show that the NLN-algorithm is easily applicable to multiple datasets without modification. Additionally, the proposed algorithm is agnostic to autoencoder architecture and reconstruction error method. We validate our method across several standard datasets for a variety of different autoencoding architectures such as vanilla, adversarial and variational autoencoders using either reconstruction, residual or feature consistent losses. The results show that the NLN algorithm grants up to a 17% increase in Area Under the Receiver Operating Characteristics (AUROC) curve performance for the multi-class case and 8% for single-class novelty detection.
Parallel Detection for Efficient Video Analytics at the Edge
Jul 27, 2021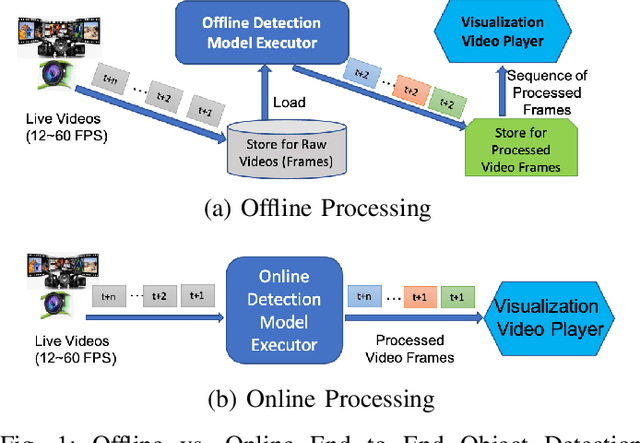


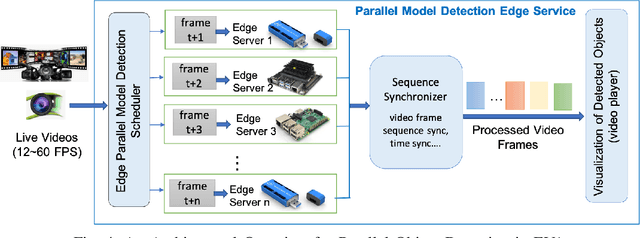
Deep Neural Network (DNN) trained object detectors are widely deployed in many mission-critical systems for real time video analytics at the edge, such as autonomous driving and video surveillance. A common performance requirement in these mission-critical edge services is the near real-time latency of online object detection on edge devices. However, even with well-trained DNN object detectors, the online detection quality at edge may deteriorate for a number of reasons, such as limited capacity to run DNN object detection models on heterogeneous edge devices, and detection quality degradation due to random frame dropping when the detection processing rate is significantly slower than the incoming video frame rate. This paper addresses these problems by exploiting multi-model multi-device detection parallelism for fast object detection in edge systems with heterogeneous edge devices. First, we analyze the performance bottleneck of running a well-trained DNN model at edge for real time online object detection. We use the offline detection as a reference model, and examine the root cause by analyzing the mismatch among the incoming video streaming rate, video processing rate for object detection, and output rate for real time detection visualization of video streaming. Second, we study performance optimizations by exploiting multi-model detection parallelism. We show that the model-parallel detection approach can effectively speed up the FPS detection processing rate, minimizing the FPS disparity with the incoming video frame rate on heterogeneous edge devices. We evaluate the proposed approach using SSD300 and YOLOv3 on benchmark videos of different video stream rates. The results show that exploiting multi-model detection parallelism can speed up the online object detection processing rate and deliver near real-time object detection performance for efficient video analytics at edge.