 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
LLOL: Low-Latency Odometry for Spinning Lidars
Oct 04, 2021
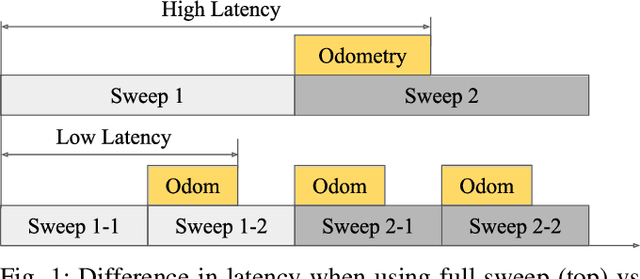


In this paper, we present a low-latency odometry system designed for spinning lidars. Many existing lidar odometry methods wait for an entire sweep from the lidar before processing the data. This introduces a large delay between the first laser firing and its pose estimate. To reduce this latency, we treat the spinning lidar as a streaming sensor and process packets as they arrive. This effectively distributes expensive operations across time, resulting in a very fast and lightweight system with much higher throughput and lower latency. Our open-source implementation is available at \url{https://github.com/versatran01/llol}.
TraSw: Tracklet-Switch Adversarial Attacks against Multi-Object Tracking
Nov 17, 2021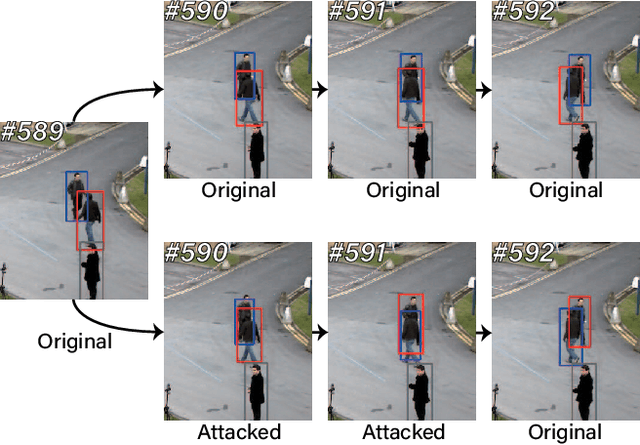
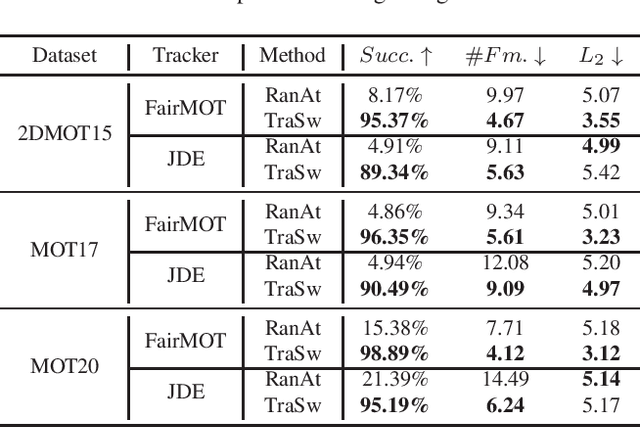
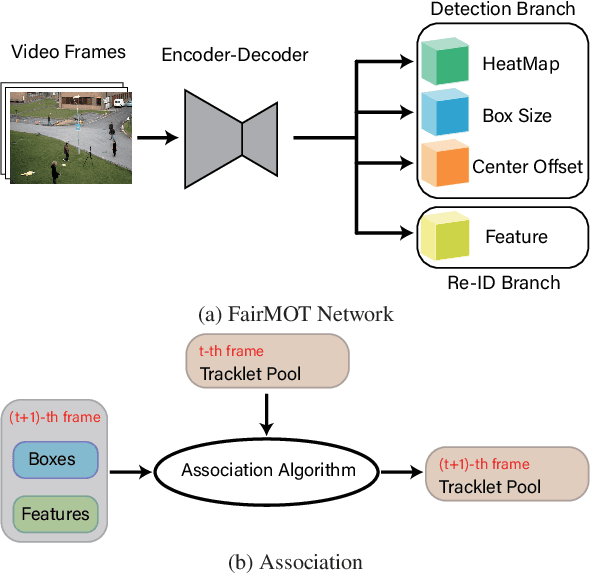
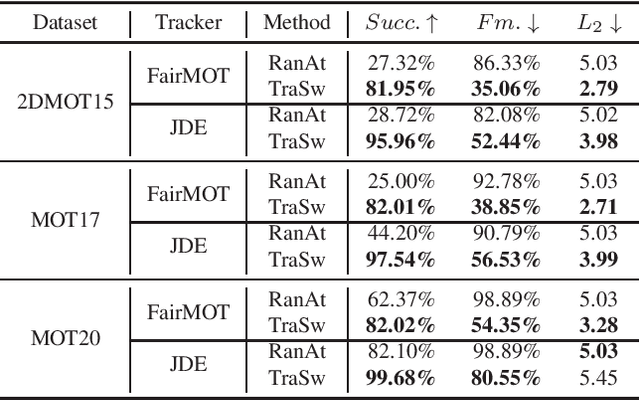
Benefiting from the development of Deep Neural Networks, Multi-Object Tracking (MOT) has achieved aggressive progress. Currently, the real-time Joint-Detection-Tracking (JDT) based MOT trackers gain increasing attention and derive many excellent models. However, the robustness of JDT trackers is rarely studied, and it is challenging to attack the MOT system since its mature association algorithms are designed to be robust against errors during tracking. In this work, we analyze the weakness of JDT trackers and propose a novel adversarial attack method, called Tracklet-Switch (TraSw), against the complete tracking pipeline of MOT. Specifically, a push-pull loss and a center leaping optimization are designed to generate adversarial examples for both re-ID feature and object detection. TraSw can fool the tracker to fail to track the targets in the subsequent frames by attacking very few frames. We evaluate our method on the advanced deep trackers (i.e., FairMOT, JDE, ByteTrack) using the MOT-Challenge datasets (i.e., 2DMOT15, MOT17, and MOT20). Experiments show that TraSw can achieve a high success rate of over 95% by attacking only five frames on average for the single-target attack and a reasonably high success rate of over 80% for the multiple-target attack. The code is available at https://github.com/DerryHub/FairMOT-attack .
Productive Multitasking for Industrial Robots
Aug 25, 2021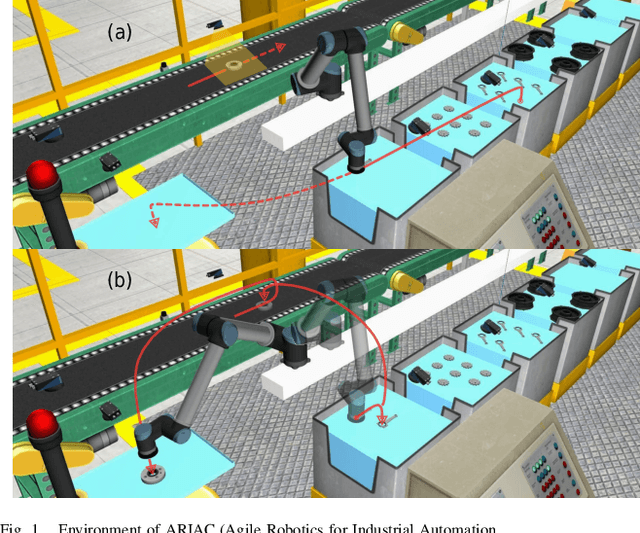
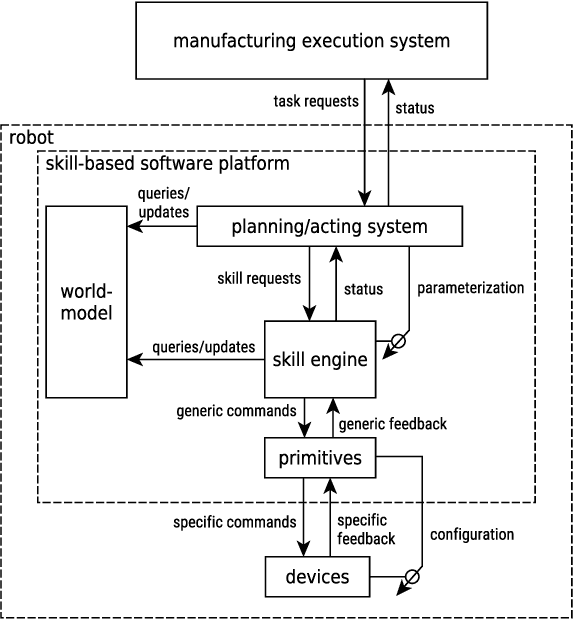

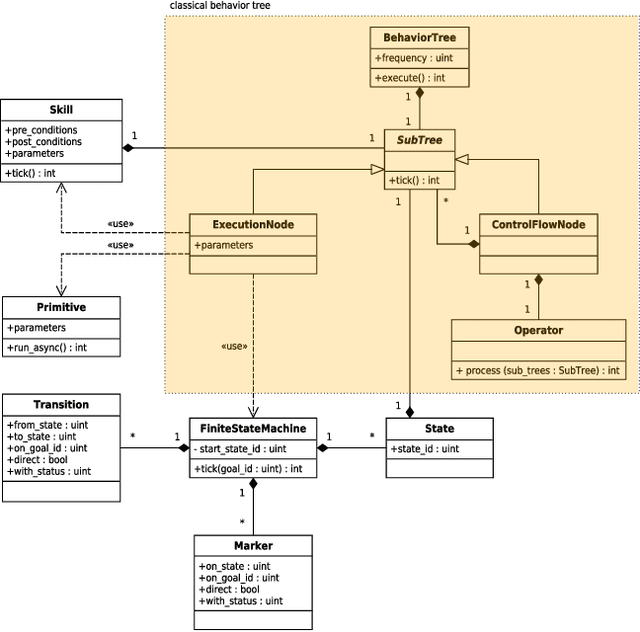
The application of robotic solutions to small-batch production is challenging: economical constraints tend to dramatically limit the time for setting up new batches. Organizing robot tasks into modular software components, called skills, and allowing the assignment of multiple concurrent tasks to a single robot is potentially game-changing. However, due to cycle time constraints, it may be necessary for a skill to take over without waiting on another to terminate, and the available literature lacks a systematic approach in this case. In the present article, we fill the gap by (a) establishing the specifications of skills that can be sequenced with partial executions, (b) proposing an implementation based on the combination of finite-state machines and behavior trees, and (c) demonstrating the benefits of such skills through extensive trials in the environment of ARIAC (Agile Robotics for Industrial Automation Competition).
Continuous and Discrete-Time Analysis of Stochastic Gradient Descent for Convex and Non-Convex Functions
Apr 08, 2020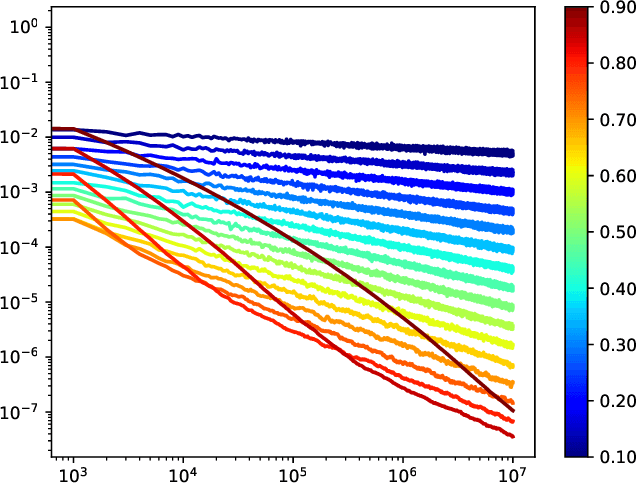

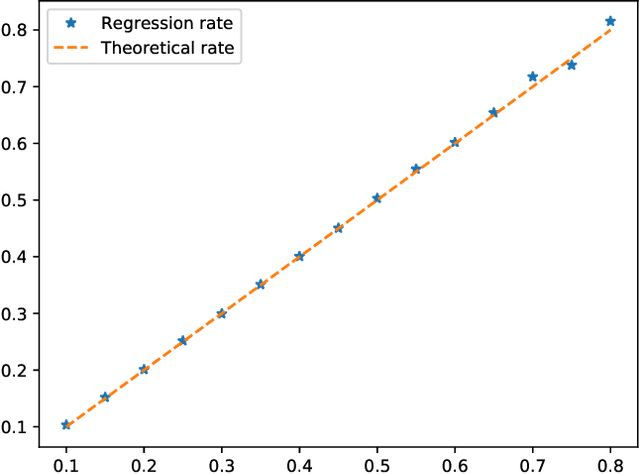

This paper proposes a thorough theoretical analysis of Stochastic Gradient Descent (SGD) with decreasing step sizes. First, we show that the recursion defining SGD can be provably approximated by solutions of a time inhomogeneous Stochastic Differential Equation (SDE) in a weak and strong sense. Then, motivated by recent analyses of deterministic and stochastic optimization methods by their continuous counterpart, we study the long-time convergence of the continuous processes at hand and establish non-asymptotic bounds. To that purpose, we develop new comparison techniques which we think are of independent interest. This continuous analysis allows us to develop an intuition on the convergence of SGD and, adapting the technique to the discrete setting, we show that the same results hold to the corresponding sequences. In our analysis, we notably obtain non-asymptotic bounds in the convex setting for SGD under weaker assumptions than the ones considered in previous works. Finally, we also establish finite time convergence results under various conditions, including relaxations of the famous {\L}ojasiewicz inequality, which can be applied to a class of non-convex functions.
Robustness via Uncertainty-aware Cycle Consistency
Oct 24, 2021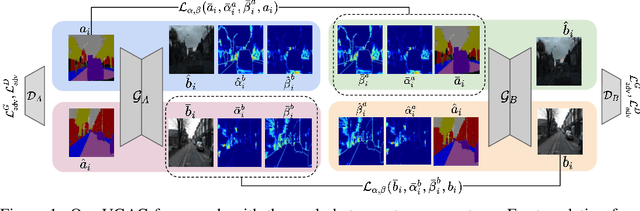
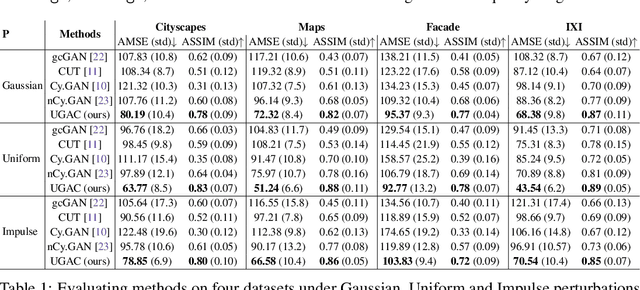
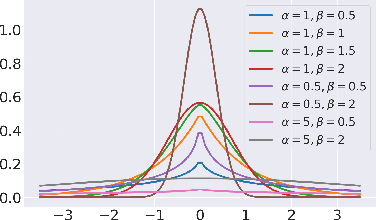
Unpaired image-to-image translation refers to learning inter-image-domain mapping without corresponding image pairs. Existing methods learn deterministic mappings without explicitly modelling the robustness to outliers or predictive uncertainty, leading to performance degradation when encountering unseen perturbations at test time. To address this, we propose a novel probabilistic method based on Uncertainty-aware Generalized Adaptive Cycle Consistency (UGAC), which models the per-pixel residual by generalized Gaussian distribution, capable of modelling heavy-tailed distributions. We compare our model with a wide variety of state-of-the-art methods on various challenging tasks including unpaired image translation of natural images, using standard datasets, spanning autonomous driving, maps, facades, and also in medical imaging domain consisting of MRI. Experimental results demonstrate that our method exhibits stronger robustness towards unseen perturbations in test data. Code is released here: https://github.com/ExplainableML/UncertaintyAwareCycleConsistency.
De Novo Molecular Generation with Stacked Adversarial Model
Oct 24, 2021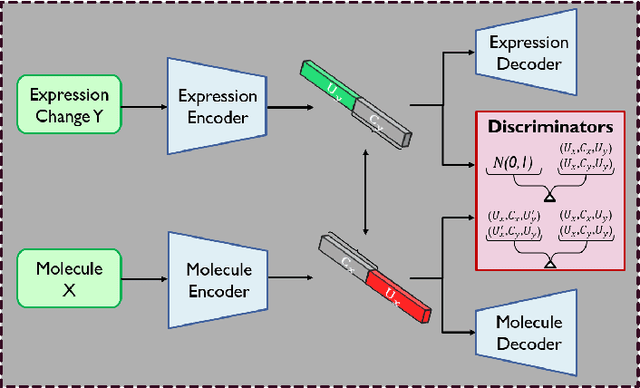

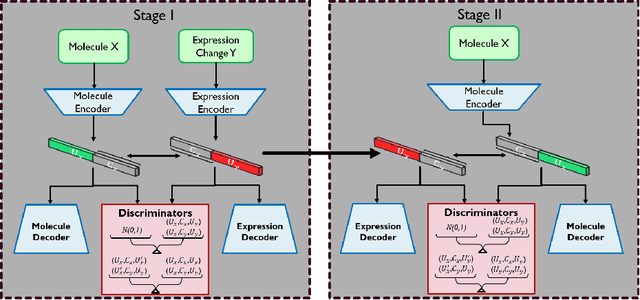

Generating novel drug molecules with desired biological properties is a time consuming and complex task. Conditional generative adversarial models have recently been proposed as promising approaches for de novo drug design. In this paper, we propose a new generative model which extends an existing adversarial autoencoder (AAE) based model by stacking two models together. Our stacked approach generates more valid molecules, as well as molecules that are more similar to known drugs. We break down this challenging task into two sub-problems. A first stage model to learn primitive features from the molecules and gene expression data. A second stage model then takes these features to learn properties of the molecules and refine more valid molecules. Experiments and comparison to baseline methods on the LINCS L1000 dataset demonstrate that our proposed model has promising performance for molecular generation.
Characterizing and Taming Resolution in Convolutional Neural Networks
Oct 28, 2021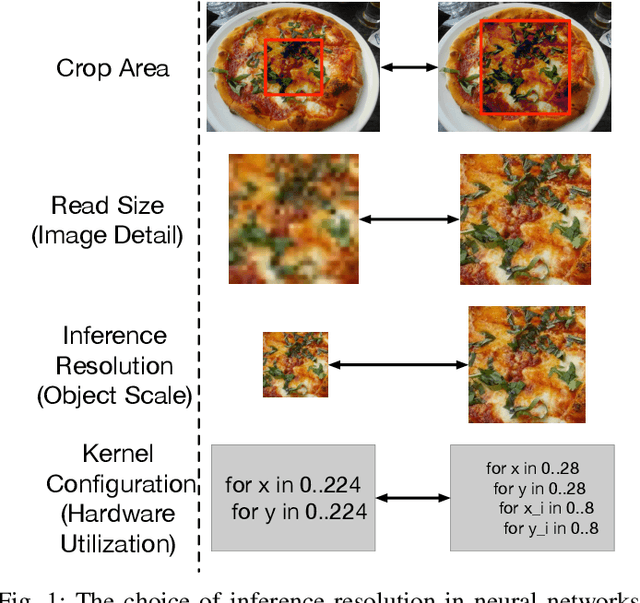

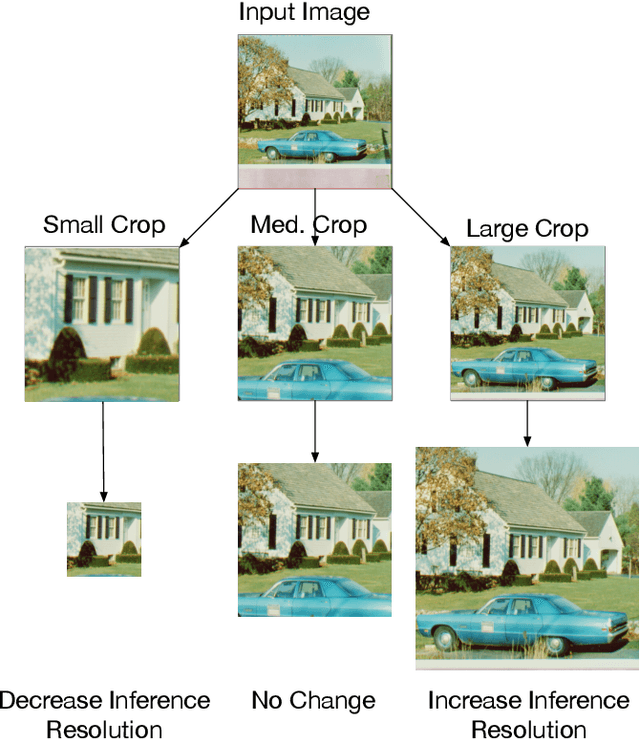
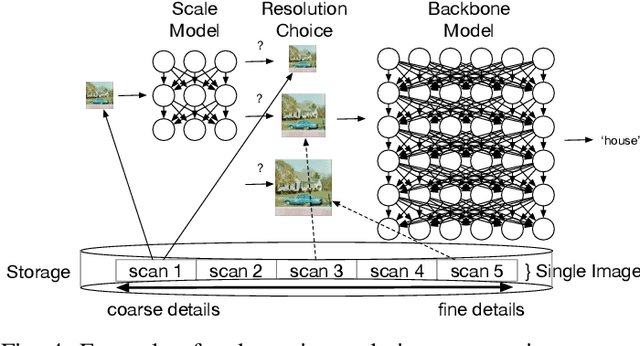
Image resolution has a significant effect on the accuracy and computational, storage, and bandwidth costs of computer vision model inference. These costs are exacerbated when scaling out models to large inference serving systems and make image resolution an attractive target for optimization. However, the choice of resolution inherently introduces additional tightly coupled choices, such as image crop size, image detail, and compute kernel implementation that impact computational, storage, and bandwidth costs. Further complicating this setting, the optimal choices from the perspective of these metrics are highly dependent on the dataset and problem scenario. We characterize this tradeoff space, quantitatively studying the accuracy and efficiency tradeoff via systematic and automated tuning of image resolution, image quality and convolutional neural network operators. With the insights from this study, we propose a dynamic resolution mechanism that removes the need to statically choose a resolution ahead of time.
Blaschke Product Neural Networks (BPNN): A Physics-Infused Neural Network for Phase Retrieval of Meromorphic Functions
Nov 26, 2021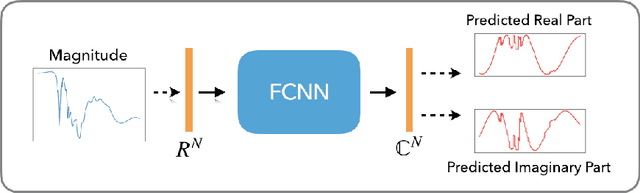
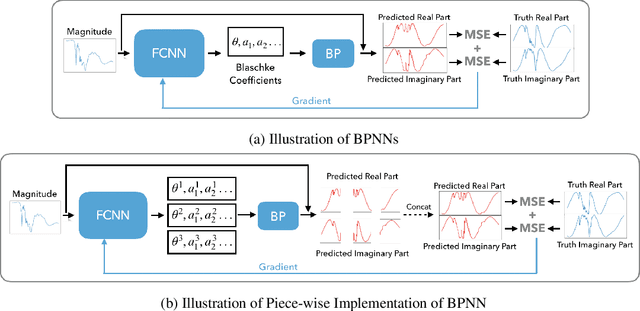
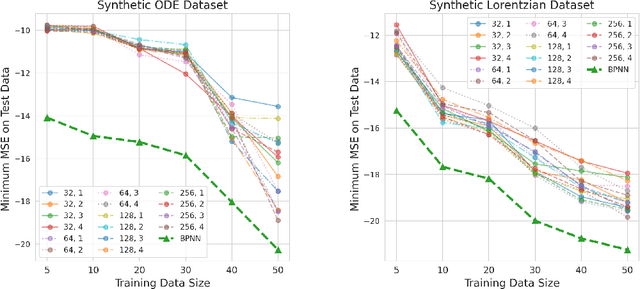
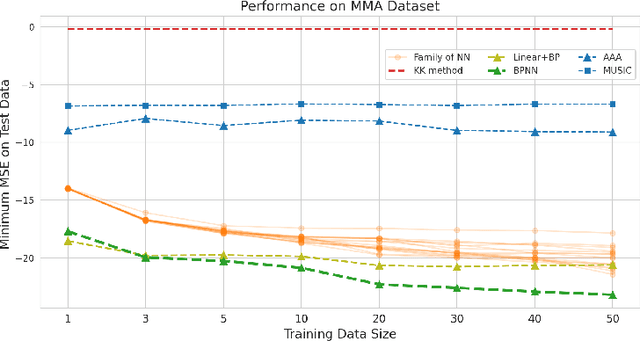
Numerous physical systems are described by ordinary or partial differential equations whose solutions are given by holomorphic or meromorphic functions in the complex domain. In many cases, only the magnitude of these functions are observed on various points on the purely imaginary jw-axis since coherent measurement of their phases is often expensive. However, it is desirable to retrieve the lost phases from the magnitudes when possible. To this end, we propose a physics-infused deep neural network based on the Blaschke products for phase retrieval. Inspired by the Helson and Sarason Theorem, we recover coefficients of a rational function of Blaschke products using a Blaschke Product Neural Network (BPNN), based upon the magnitude observations as input. The resulting rational function is then used for phase retrieval. We compare the BPNN to conventional deep neural networks (NNs) on several phase retrieval problems, comprising both synthetic and contemporary real-world problems (e.g., metamaterials for which data collection requires substantial expertise and is time consuming). On each phase retrieval problem, we compare against a population of conventional NNs of varying size and hyperparameter settings. Even without any hyper-parameter search, we find that BPNNs consistently outperform the population of optimized NNs in scarce data scenarios, and do so despite being much smaller models. The results can in turn be applied to calculate the refractive index of metamaterials, which is an important problem in emerging areas of material science.
SAR Image Classification Based on Spiking Neural Network through Spike-Time Dependent Plasticity and Gradient Descent
Jun 15, 2021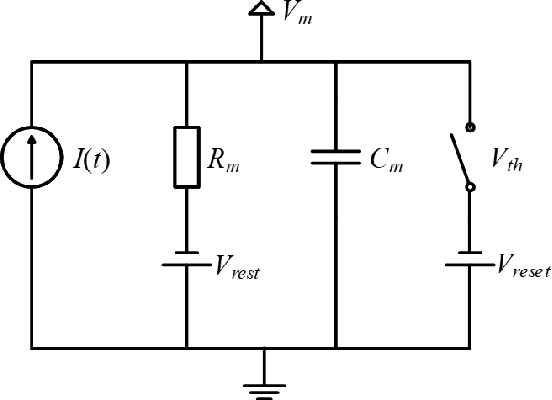
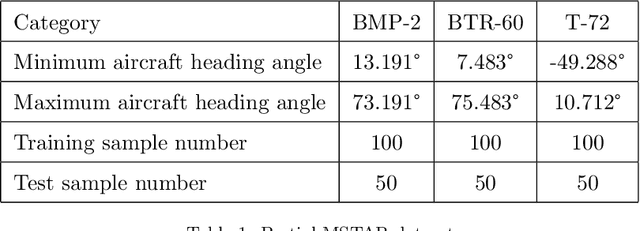
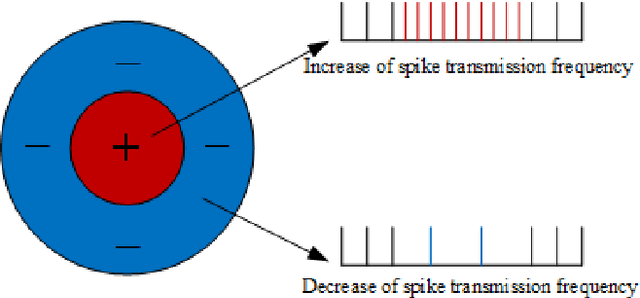
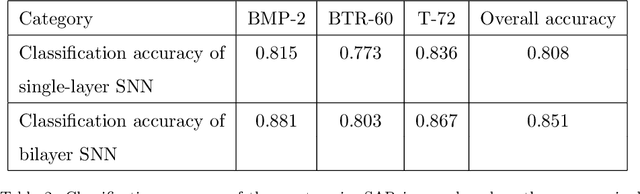
At present, the Synthetic Aperture Radar (SAR) image classification method based on convolution neural network (CNN) has faced some problems such as poor noise resistance and generalization ability. Spiking neural network (SNN) is one of the core components of brain-like intelligence and has good application prospects. This article constructs a complete SAR image classifier based on unsupervised and supervised learning of SNN by using spike sequences with complex spatio-temporal information. We firstly expound the spiking neuron model, the receptive field of SNN, and the construction of spike sequence. Then we put forward an unsupervised learning algorithm based on STDP and a supervised learning algorithm based on gradient descent. The average classification accuracy of single layer and bilayer unsupervised learning SNN in three categories images on MSTAR dataset is 80.8\% and 85.1\%, respectively. Furthermore, the convergent output spike sequences of unsupervised learning can be used as teaching signals. Based on the TensorFlow framework, a single layer supervised learning SNN is built from the bottom, and the classification accuracy reaches 90.05\%. By comparing noise resistance and model parameters between SNNs and CNNs, the effectiveness and outstanding advantages of SNN are verified. Code to reproduce our experiments is available at \url{https://github.com/Jiankun-chen/Supervised-SNN-with-GD}.
Clustering Discrete Valued Time Series
Jan 26, 2019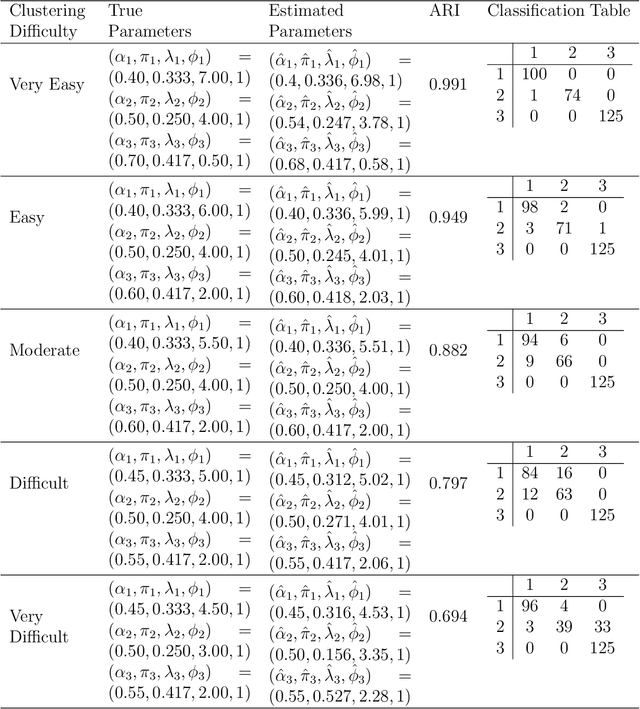
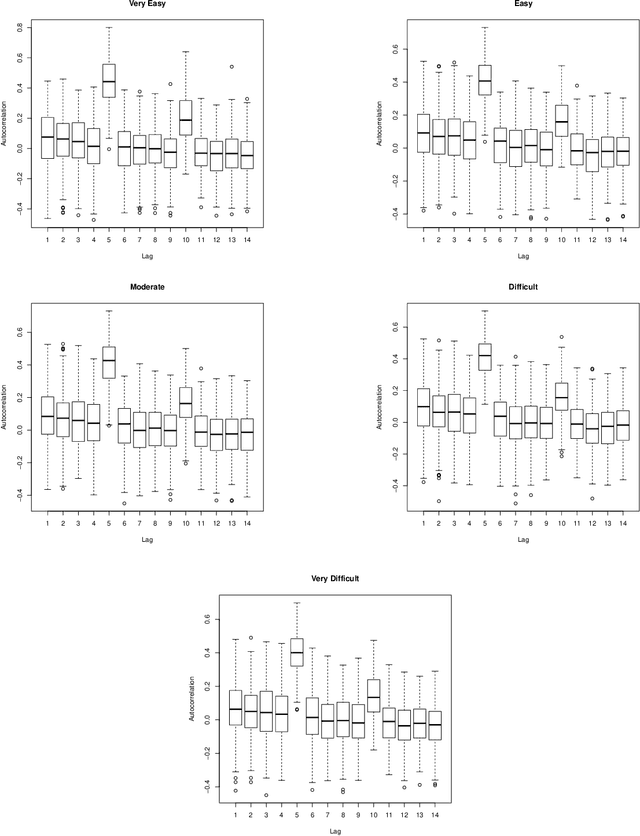
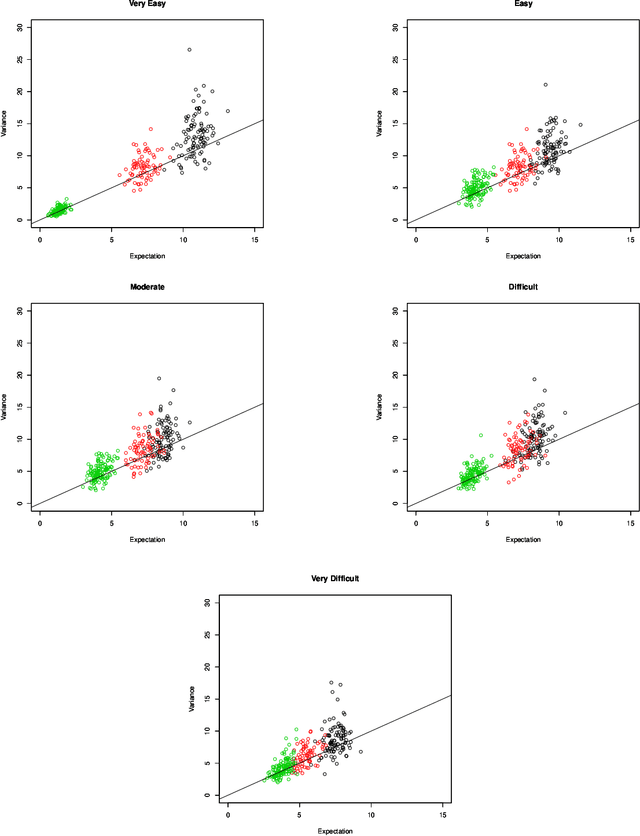
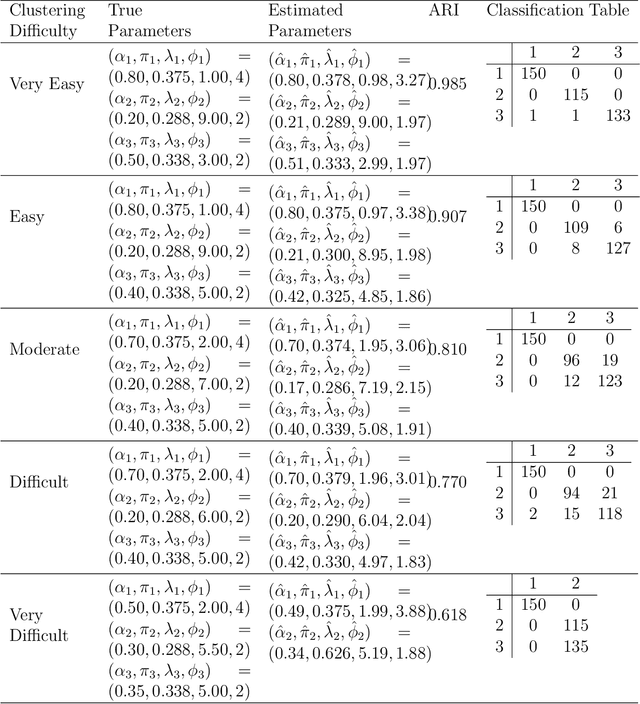
There is a need for the development of models that are able to account for discreteness in data, along with its time series properties and correlation. Our focus falls on INteger-valued AutoRegressive (INAR) type models. The INAR type models can be used in conjunction with existing model-based clustering techniques to cluster discrete valued time series data. With the use of a finite mixture model, several existing techniques such as the selection of the number of clusters, estimation using expectation-maximization and model selection are applicable. The proposed model is then demonstrated on real data to illustrate its clustering applications.