 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Enhancing Identification of Structure Function of Academic Articles Using Contextual Information
Dec 02, 2021
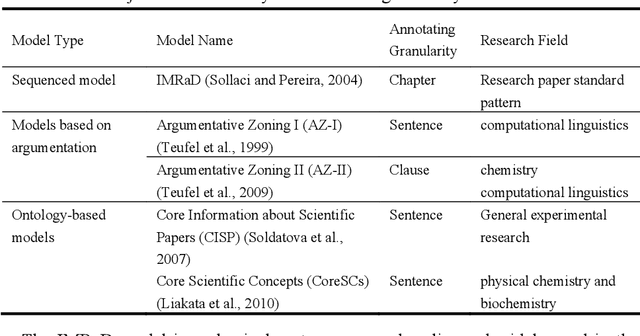
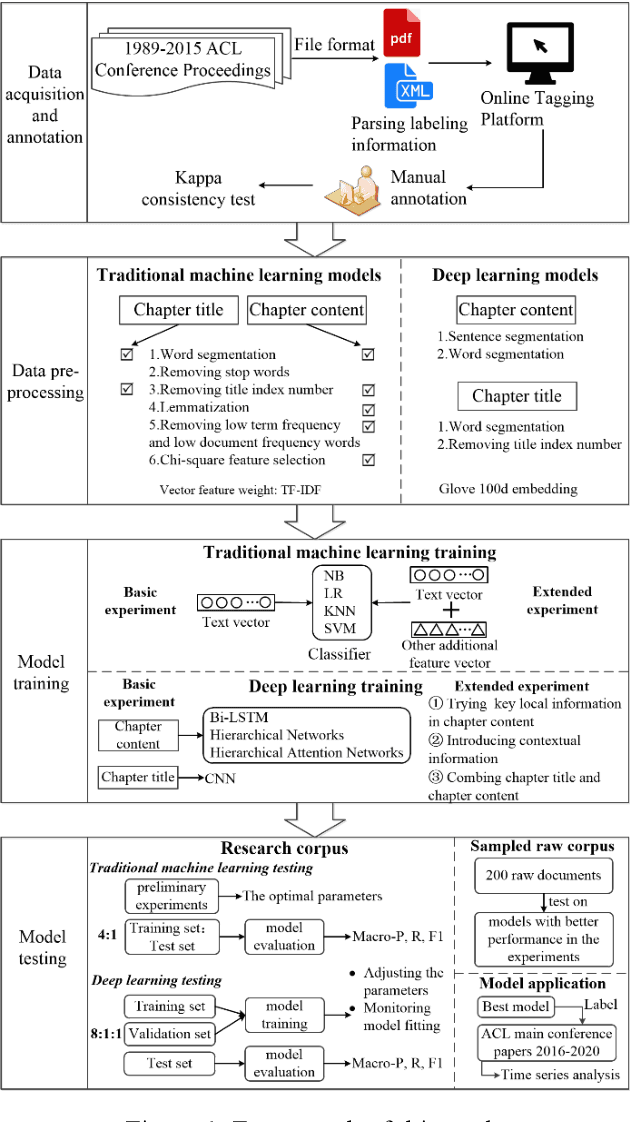
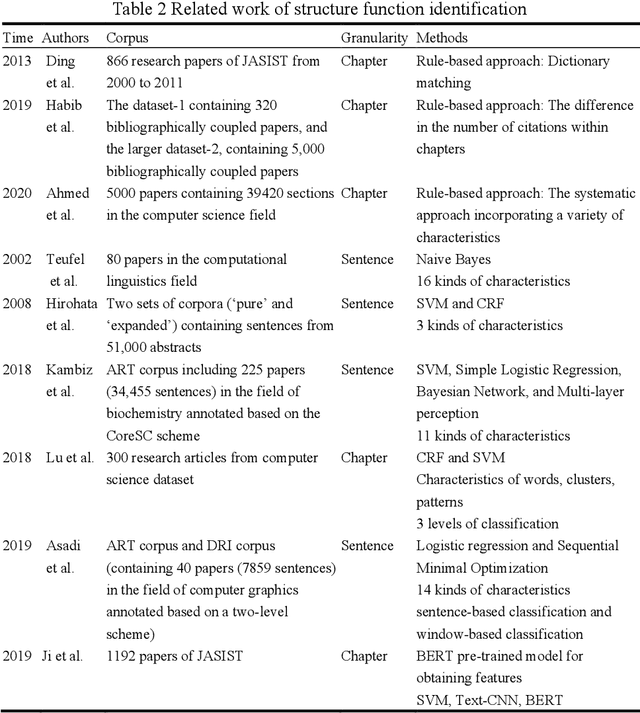
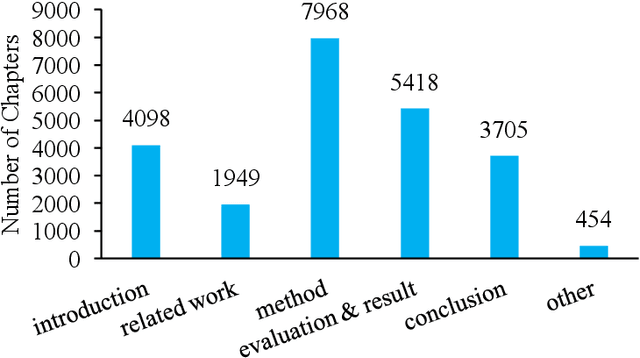
With the enrichment of literature resources, researchers are facing the growing problem of information explosion and knowledge overload. To help scholars retrieve literature and acquire knowledge successfully, clarifying the semantic structure of the content in academic literature has become the essential research question. In the research on identifying the structure function of chapters in academic articles, only a few studies used the deep learning model and explored the optimization for feature input. This limits the application, optimization potential of deep learning models for the research task. This paper took articles of the ACL conference as the corpus. We employ the traditional machine learning models and deep learning models to construct the classifiers based on various feature input. Experimental results show that (1) Compared with the chapter content, the chapter title is more conducive to identifying the structure function of academic articles. (2) Relative position is a valuable feature for building traditional models. (3) Inspired by (2), this paper further introduces contextual information into the deep learning models and achieved significant results. Meanwhile, our models show good migration ability in the open test containing 200 sampled non-training samples. We also annotated the ACL main conference papers in recent five years based on the best practice performing models and performed a time series analysis of the overall corpus. This work explores and summarizes the practical features and models for this task through multiple comparative experiments and provides a reference for related text classification tasks. Finally, we indicate the limitations and shortcomings of the current model and the direction of further optimization.
Robust and efficient change point detection using novel multivariate rank-energy GoF test
Oct 29, 2021

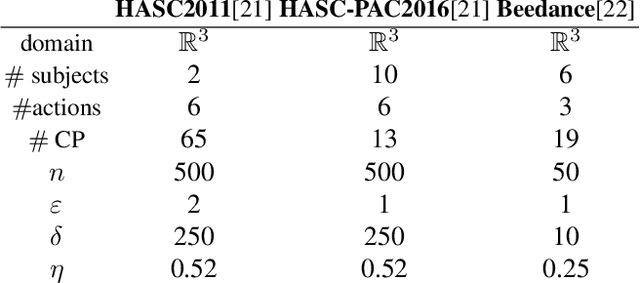
In this paper, we use and further develop upon a recently proposed multivariate, distribution-free Goodness-of-Fit (GoF) test based on the theory of Optimal Transport (OT) called the Rank Energy (RE) [1], for non-parametric and unsupervised Change Point Detection (CPD) in multivariate time series data. We show that directly using RE leads to high sensitivity to very small changes in distributions (causing high false alarms) and it requires large sample complexity and huge computational cost. To alleviate these drawbacks, we propose a new GoF test statistic called as soft-Rank Energy (sRE) that is based on entropy regularized OT and employ it towards CPD. We discuss the advantages of using sRE over RE and demonstrate that the proposed sRE based CPD outperforms all the existing methods in terms of Area Under the Curve (AUC) and F1-score on real and synthetic data sets.
Indexing Context-Sensitive Reachability
Sep 03, 2021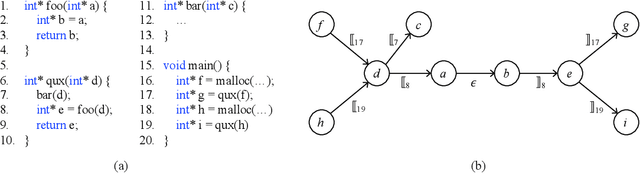
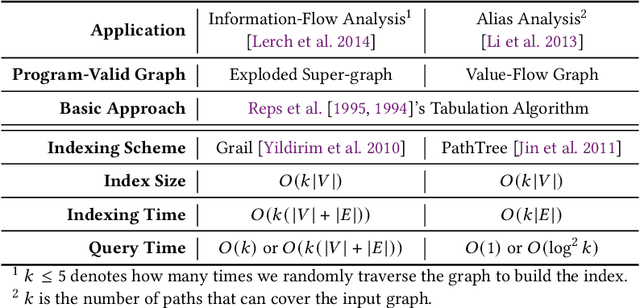
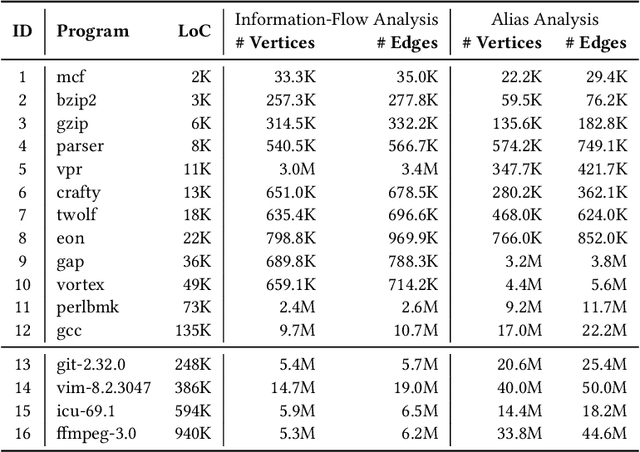
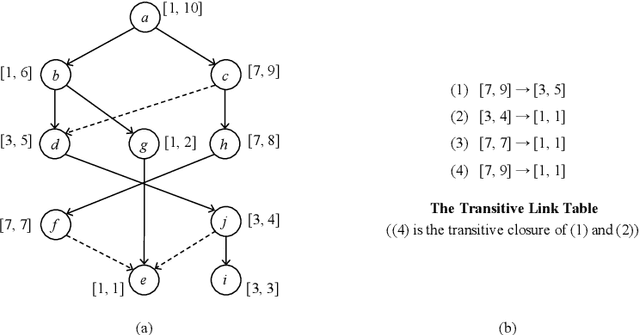
Many context-sensitive data flow analyses can be formulated as a variant of the all-pairs Dyck-CFL reachability problem, which, in general, is of sub-cubic time complexity and quadratic space complexity. Such high complexity significantly limits the scalability of context-sensitive data flow analysis and is not affordable for analyzing large-scale software. This paper presents \textsc{Flare}, a reduction from the CFL reachability problem to the conventional graph reachability problem for context-sensitive data flow analysis. This reduction allows us to benefit from recent advances in reachability indexing schemes, which often consume almost linear space for answering reachability queries in almost constant time. We have applied our reduction to a context-sensitive alias analysis and a context-sensitive information-flow analysis for C/C++ programs. Experimental results on standard benchmarks and open-source software demonstrate that we can achieve orders of magnitude speedup at the cost of only moderate space to store the indexes. The implementation of our approach is publicly available.
CLIP-Forge: Towards Zero-Shot Text-to-Shape Generation
Oct 06, 2021
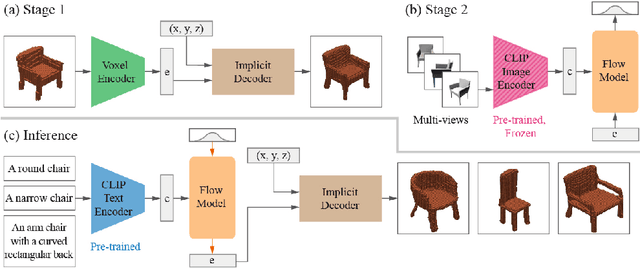


While recent progress has been made in text-to-image generation, text-to-shape generation remains a challenging problem due to the unavailability of paired text and shape data at a large scale. We present a simple yet effective method for zero-shot text-to-shape generation based on a two-stage training process, which only depends on an unlabelled shape dataset and a pre-trained image-text network such as CLIP. Our method not only demonstrates promising zero-shot generalization, but also avoids expensive inference time optimization and can generate multiple shapes for a given text.
A Novel Data Pre-processing Technique: Making Data Mining Robust to Different Units and Scales of Measurement
Nov 08, 2021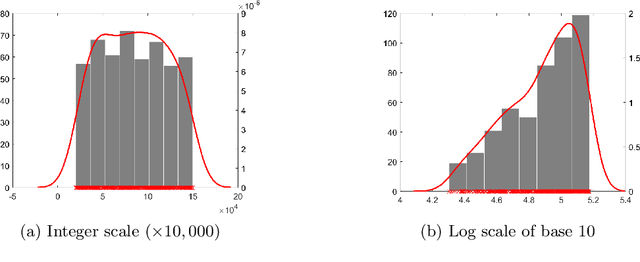
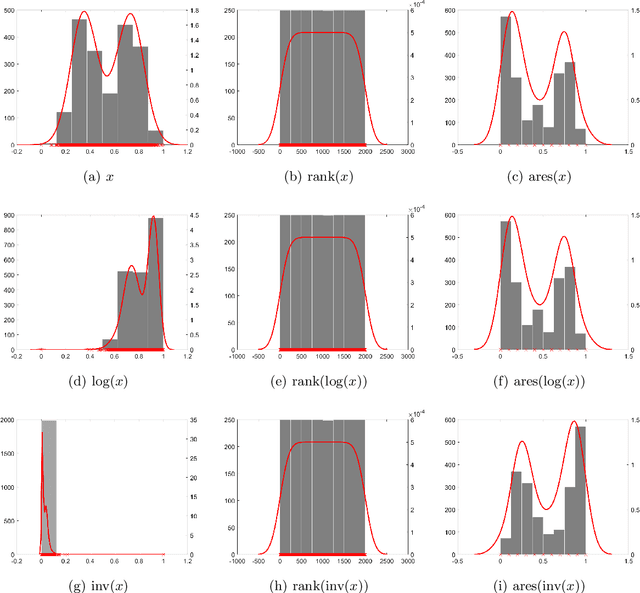
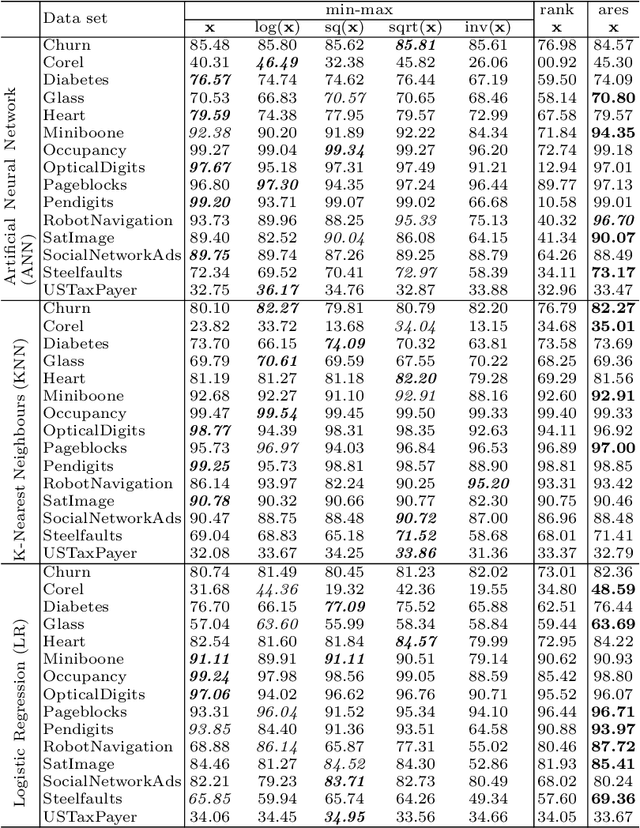
Many existing data mining algorithms use feature values directly in their model, making them sensitive to units/scales used to measure/represent data. Pre-processing of data based on rank transformation has been suggested as a potential solution to overcome this issue. However, the resulting data after pre-processing with rank transformation is uniformly distributed, which may not be very useful in many data mining applications. In this paper, we present a better and effective alternative based on ranks over multiple sub-samples of data. We call the proposed pre-processing technique as ARES | Average Rank over an Ensemble of Sub-samples. Our empirical results of widely used data mining algorithms for classification and anomaly detection in a wide range of data sets suggest that ARES results in more consistent task specific? outcome across various algorithms and data sets. In addition to this, it results in better or competitive outcome most of the time compared to the most widely used min-max normalisation and the traditional rank transformation.
* This paper is published in a special issue of the Australian Journal of Intelligent Information Processing Systems as part of the proceedings of the International Conference on Neural Information Processing (ICONIP) 2019
Leaky Integrate-and-Fire Spiking Neuron with Learnable Membrane Time Parameter
Jul 11, 2020
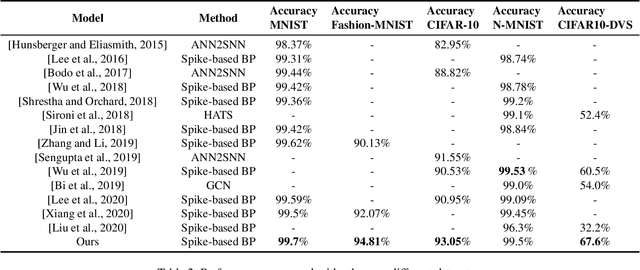
The Spiking Neural Networks (SNNs) have attracted research interest due to its temporal information processing capability, low power consumption, and high biological plausibility. The Leaky Integrate-and-Fire (LIF) neuron model is one of the most popular spiking neuron models used in SNNs for it achieves a balance between computing cost and biological plausibility. The most important parameter of a LIF neuron is the membrane time constant $\tau$, which determines the decay rate of membrane potential. The value of $\tau$ plays a crucial role in SNNs containing LIF neurons. However, $\tau$ is usually treated as a hyper-parameter, which is preset before training SNNs and adjusted manually. In this article, we propose a novel spiking neuron, namely parametric Leaky Integrate-and-Fire (PLIF) neuron, whose $\tau$ is a learnable parameter rather than an empirical hyper-parameter. We evaluate the performance of SNNs with PLIF neurons for image classification tasks on both traditional static MNIST, Fashion-MNIST, CIFAR-10 datasets, and neuromorphic N-MNIST, CIFAR10-DVS datasets. The experiment results show that SNNs augmented by PLIF neurons outperform those with conventional spiking neurons.
Context-Aware Online Client Selection for Hierarchical Federated Learning
Dec 02, 2021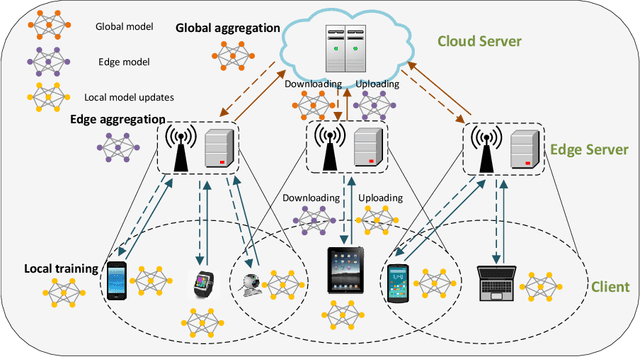
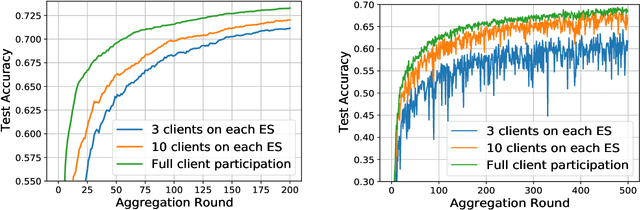
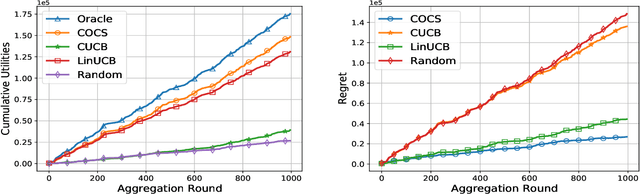
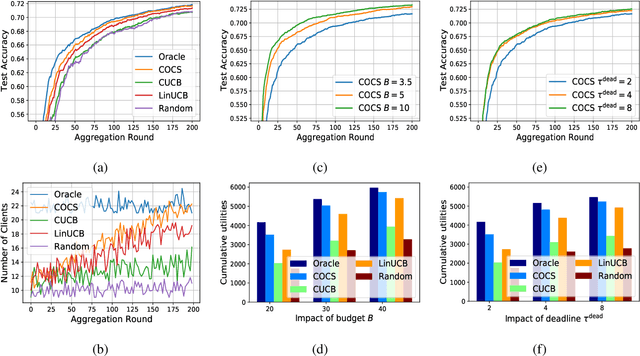
Federated Learning (FL) has been considered as an appealing framework to tackle data privacy issues of mobile devices compared to conventional Machine Learning (ML). Using Edge Servers (ESs) as intermediaries to perform model aggregation in proximity can reduce the transmission overhead, and it enables great potentials in low-latency FL, where the hierarchical architecture of FL (HFL) has been attracted more attention. Designing a proper client selection policy can significantly improve training performance, and it has been extensively used in FL studies. However, to the best of our knowledge, there are no studies focusing on HFL. In addition, client selection for HFL faces more challenges than conventional FL, e.g., the time-varying connection of client-ES pairs and the limited budget of the Network Operator (NO). In this paper, we investigate a client selection problem for HFL, where the NO learns the number of successful participating clients to improve the training performance (i.e., select as many clients in each round) as well as under the limited budget on each ES. An online policy, called Context-aware Online Client Selection (COCS), is developed based on Contextual Combinatorial Multi-Armed Bandit (CC-MAB). COCS observes the side-information (context) of local computing and transmission of client-ES pairs and makes client selection decisions to maximize NO's utility given a limited budget. Theoretically, COCS achieves a sublinear regret compared to an Oracle policy on both strongly convex and non-convex HFL. Simulation results also support the efficiency of the proposed COCS policy on real-world datasets.
ASL Trigger Recognition in Mixed Activity/Signing Sequences for RF Sensor-Based User Interfaces
Nov 18, 2021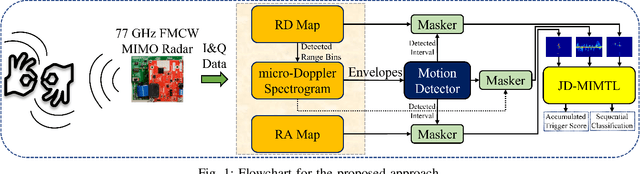

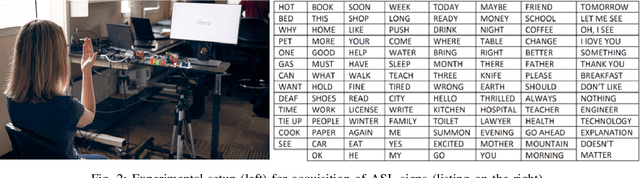
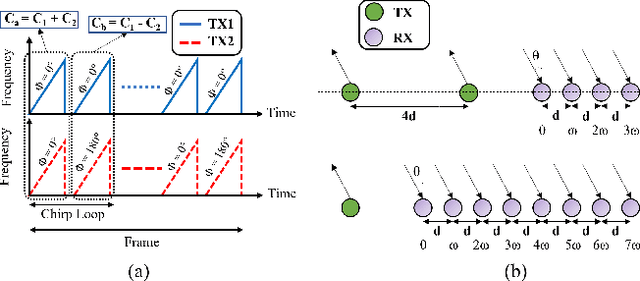
The past decade has seen great advancements in speech recognition for control of interactive devices, personal assistants, and computer interfaces. However, Deaf and hard-ofhearing (HoH) individuals, whose primary mode of communication is sign language, cannot use voice-controlled interfaces. Although there has been significant work in video-based sign language recognition, video is not effective in the dark and has raised privacy concerns in the Deaf community when used in the context of human ambient intelligence. RF sensors have been recently proposed as a new modality that can be effective under the circumstances where video is not. This paper considers the problem of recognizing a trigger sign (wake word) in the context of daily living, where gross motor activities are interwoven with signing sequences. The proposed approach exploits multiple RF data domain representations (time-frequency, range-Doppler, and range-angle) for sequential classification of mixed motion data streams. The recognition accuracy of signs with varying kinematic properties is compared and used to make recommendations on appropriate trigger sign selection for RFsensor based user interfaces. The proposed approach achieves a trigger sign detection rate of 98.9% and a classification accuracy of 92% for 15 ASL words and 3 gross motor activities.
Delay-aware Robust Control for Safe Autonomous Driving
Sep 15, 2021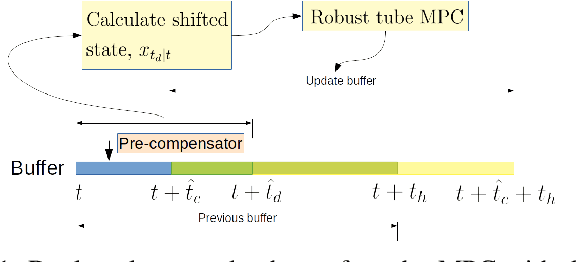
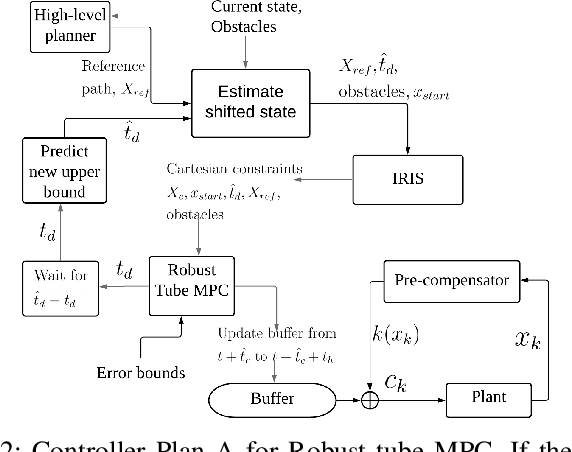
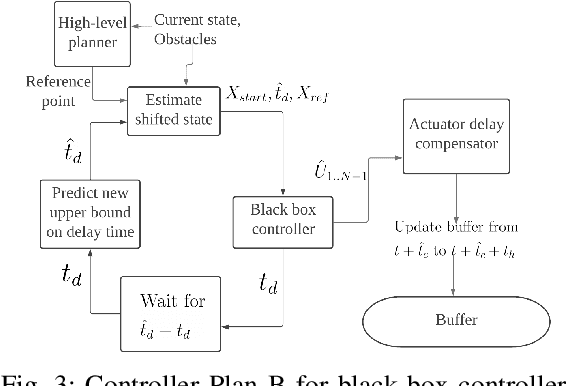
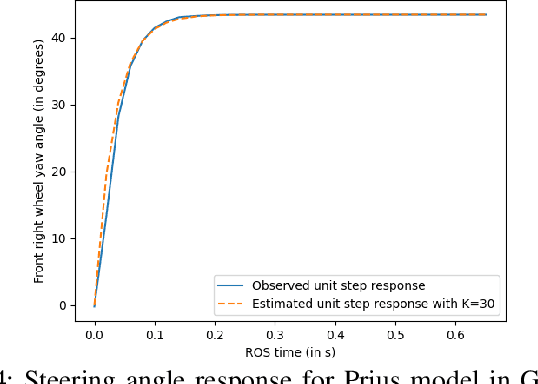
With the advancement of affordable self-driving vehicles using complicated nonlinear optimization but limited computation resources, computation time becomes a matter of concern. Other factors such as actuator dynamics and actuator command processing cost also unavoidably cause delays. In high-speed scenarios, these delays are critical to the safety of a vehicle. Recent works consider these delays individually, but none unifies them all in the context of autonomous driving. Moreover, recent works inappropriately consider computation time as a constant or a large upper bound, which makes the control either less responsive or over-conservative. To deal with all these delays, we present a unified framework by 1) modeling actuation dynamics, 2) using robust tube model predictive control, 3) using a novel adaptive Kalman filter without assuminga known process model and noise covariance, which makes the controller safe while minimizing conservativeness. On onehand, our approach can serve as a standalone controller; on theother hand, our approach provides a safety guard for a high-level controller, which assumes no delay. This can be used for compensating the sim-to-real gap when deploying a black-box learning-enabled controller trained in a simplistic environment without considering delays for practical vehicle systems.
Learning to Learn End-to-End Goal-Oriented Dialog From Related Dialog Tasks
Oct 10, 2021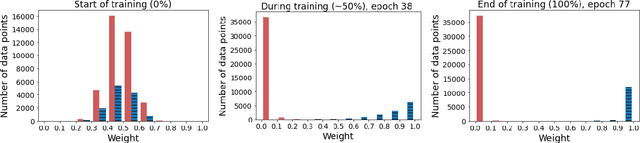
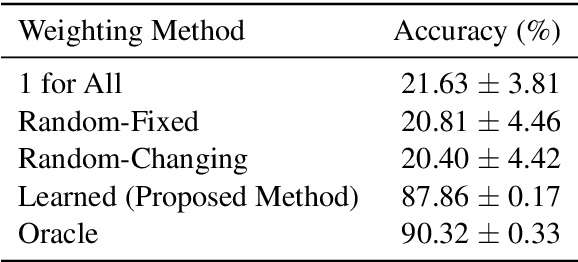
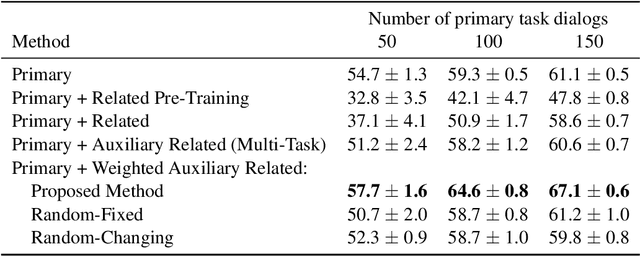
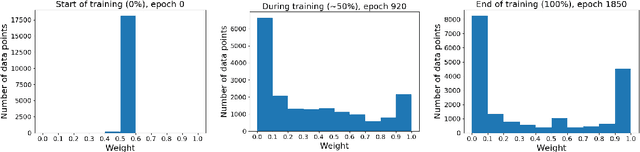
For each goal-oriented dialog task of interest, large amounts of data need to be collected for end-to-end learning of a neural dialog system. Collecting that data is a costly and time-consuming process. Instead, we show that we can use only a small amount of data, supplemented with data from a related dialog task. Naively learning from related data fails to improve performance as the related data can be inconsistent with the target task. We describe a meta-learning based method that selectively learns from the related dialog task data. Our approach leads to significant accuracy improvements in an example dialog task.