 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
UAV-based Crowd Surveillance in Post COVID-19 Era
Nov 28, 2021
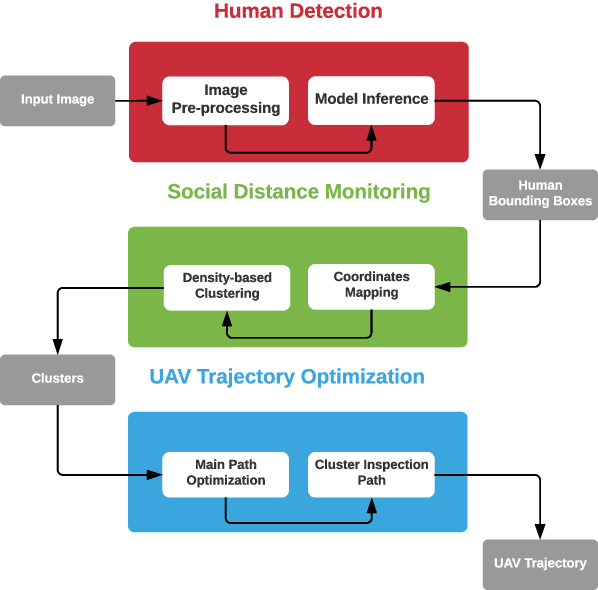
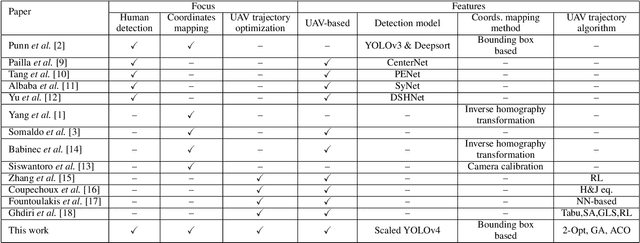


To cope with the current pandemic situation and reinstate pseudo-normal daily life, several measures have been deployed and maintained, such as mask wearing, social distancing, hands sanitizing, etc. Since outdoor cultural events, concerts, and picnics, are gradually allowed, a close monitoring of the crowd activity is needed to avoid undesired contact and disease transmission. In this context, intelligent unmanned aerial vehicles (UAVs) can be occasionally deployed to ensure the surveillance of these activities, that health restriction measures are applied, and to trigger alerts when the latter are not respected. Consequently, we propose in this paper a complete UAV framework for intelligent monitoring of post COVID-19 outdoor activities. Specifically, we propose a three steps approach. In the first step, captured images by a UAV are analyzed using machine learning to detect and locate individuals. The second step consists of a novel coordinates mapping approach to evaluate distances among individuals, then cluster them, while the third step provides an energy-efficient and/or reliable UAV trajectory to inspect clusters for restrictions violation such as mask wearing. Obtained results provide the following insights: 1) Efficient detection of individuals depends on the angle from which the image was captured, 2) coordinates mapping is very sensitive to the estimation error in individuals' bounding boxes, and 3) UAV trajectory design algorithm 2-Opt is recommended for practical real-time deployments due to its low-complexity and near-optimal performance.
AR-Net: A simple Auto-Regressive Neural Network for time-series
Nov 27, 2019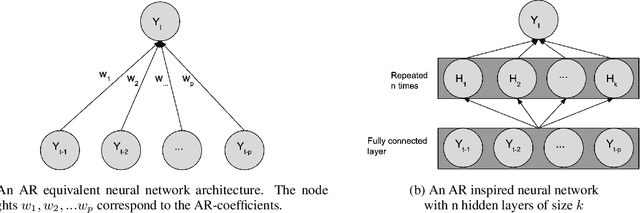
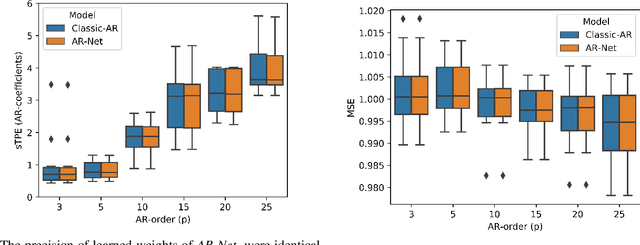
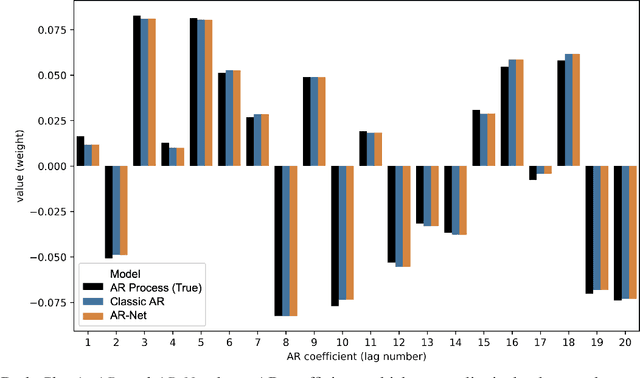
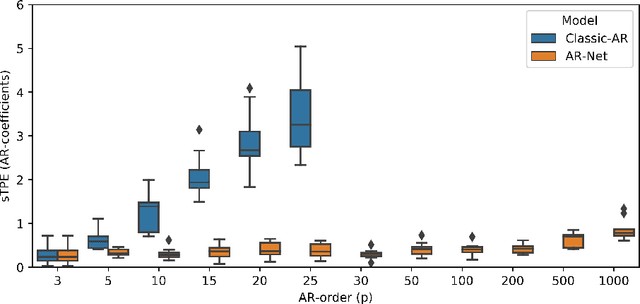
In this paper we present a new framework for time-series modeling that combines the best of traditional statistical models and neural networks. We focus on time-series with long-range dependencies, needed for monitoring fine granularity data (e.g. minutes, seconds, milliseconds), prevalent in operational use-cases. Traditional models, such as auto-regression fitted with least squares (Classic-AR) can model time-series with a concise and interpretable model. When dealing with long-range dependencies, Classic-AR models can become intractably slow to fit for large data. Recently, sequence-to-sequence models, such as Recurrent Neural Networks, which were originally intended for natural language processing, have become popular for time-series. However, they can be overly complex for typical time-series data and lack interpretability. A scalable and interpretable model is needed to bridge the statistical and deep learning-based approaches. As a first step towards this goal, we propose modelling AR-process dynamics using a feed-forward neural network approach, termed AR-Net. We show that AR-Net is as interpretable as Classic-AR but also scales to long-range dependencies. Our results lead to three major conclusions: First, AR-Net learns identical AR-coefficients as Classic-AR, thus being equally interpretable. Second, the computational complexity with respect to the order of the AR process, is linear for AR-Net as compared to a quadratic for Classic-AR. This makes it possible to model long-range dependencies within fine granularity data. Third, by introducing regularization, AR-Net automatically selects and learns sparse AR-coefficients. This eliminates the need to know the exact order of the AR-process and allows to learn sparse weights for a model with long-range dependencies.
Data-driven estimation of system norms via impulse response
Nov 08, 2021
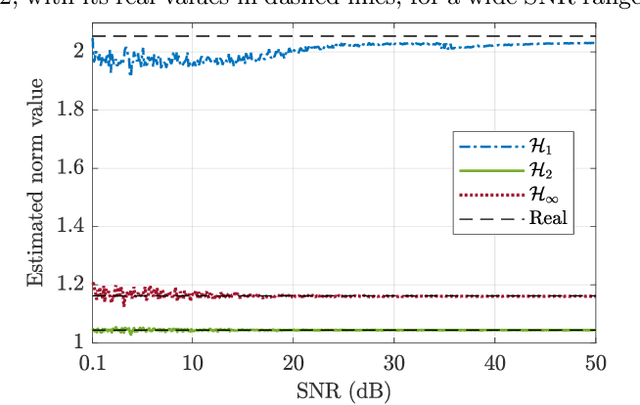
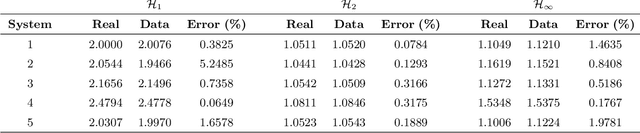
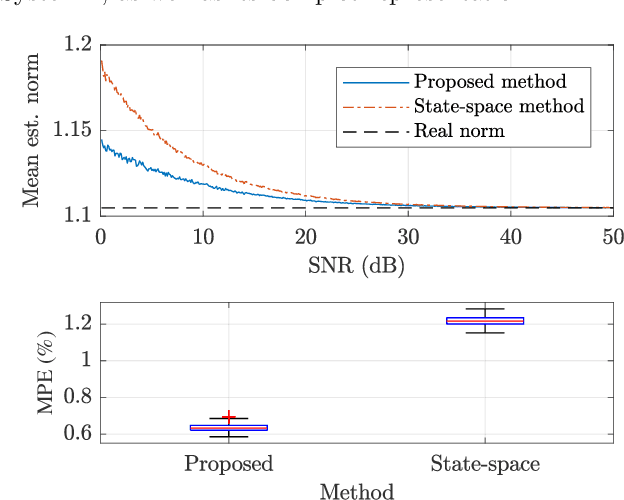
This paper proposes a method for estimating the norms of a system in a pure data-driven fashion based on their identified Impulse Response (IR) coefficients. The calculation of norms is briefly reviewed and the main expressions for the IR-based estimations are presented. As a case study, the $\mathcal{H}_{1}$, $\mathcal{H}_2$, and $\mathcal{H}_{\infty}$ norms of the sensitivity transfer function of five different discrete-time closed-loop systems are estimated for a Signal-to-Noise-Ratio (SNR) of 10 dB, achieving low percent error values if compared to the real value. To verify the influence of the noise amplitude, norms are estimated considering a wide range of SNR values, for a specific system, presenting low Mean Percent Error (MPE) if compared to the real norms. The proposed technique is also compared to an existing state-space-based method in terms of $\mathcal{H}_{\infty}$, through Monte Carlo, showing a reduction of approximately 48 % in the MPE for a wide range of SNR values.
Untangling Braids with Multi-agent Q-Learning
Sep 29, 2021
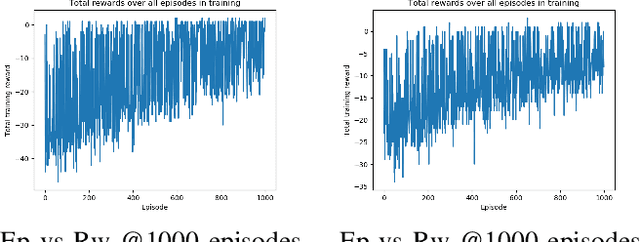
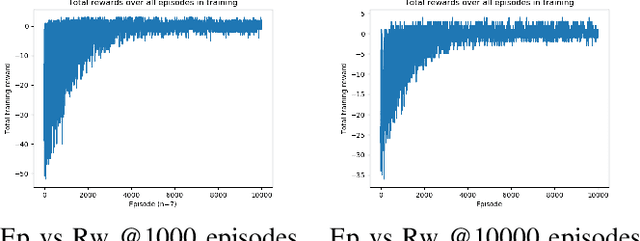
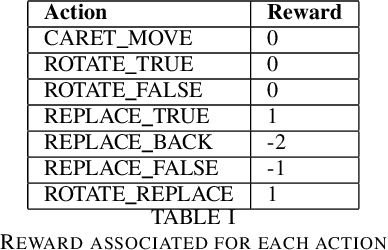
We use reinforcement learning to tackle the problem of untangling braids. We experiment with braids with 2 and 3 strands. Two competing players learn to tangle and untangle a braid. We interface the braid untangling problem with the OpenAI Gym environment, a widely used way of connecting agents to reinforcement learning problems. The results provide evidence that the more we train the system, the better the untangling player gets at untangling braids. At the same time, our tangling player produces good examples of tangled braids.
Learning Physical Concepts in Cyber-Physical Systems: A Case Study
Nov 28, 2021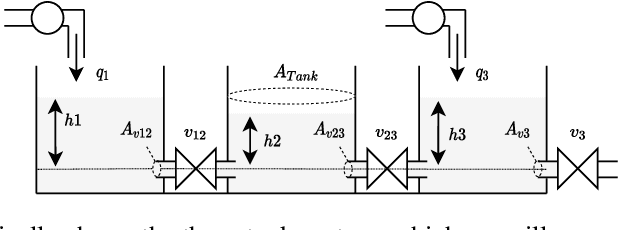
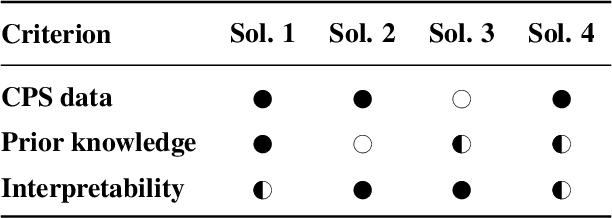
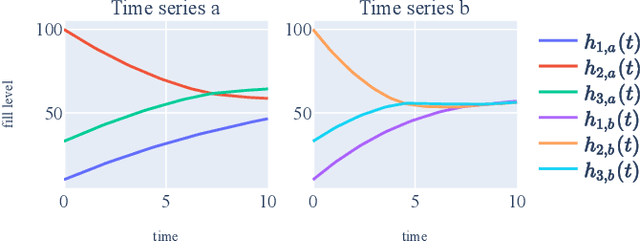
Machine Learning (ML) has achieved great successes in recent decades, both in research and in practice. In Cyber-Physical Systems (CPS), ML can for example be used to optimize systems, to detect anomalies or to identify root causes of system failures. However, existing algorithms suffer from two major drawbacks: (i) They are hard to interpret by human experts. (ii) Transferring results from one systems to another (similar) system is often a challenge. Concept learning, or Representation Learning (RepL), is a solution to both of these drawbacks; mimicking the human solution approach to explain-ability and transfer-ability: By learning general concepts such as physical quantities or system states, the model becomes interpretable by humans. Furthermore concepts on this abstract level can normally be applied to a wide range of different systems. Modern ML methods are already widely used in CPS, but concept learning and transfer learning are hardly used so far. In this paper, we provide an overview of the current state of research regarding methods for learning physical concepts in time series data, which is the primary form of sensor data of CPS. We also analyze the most important methods from the current state of the art using the example of a three-tank system. Based on these concrete implementations1, we discuss the advantages and disadvantages of the methods and show for which purpose and under which conditions they can be used.
Clustering Discrete Valued Time Series
Jan 26, 2019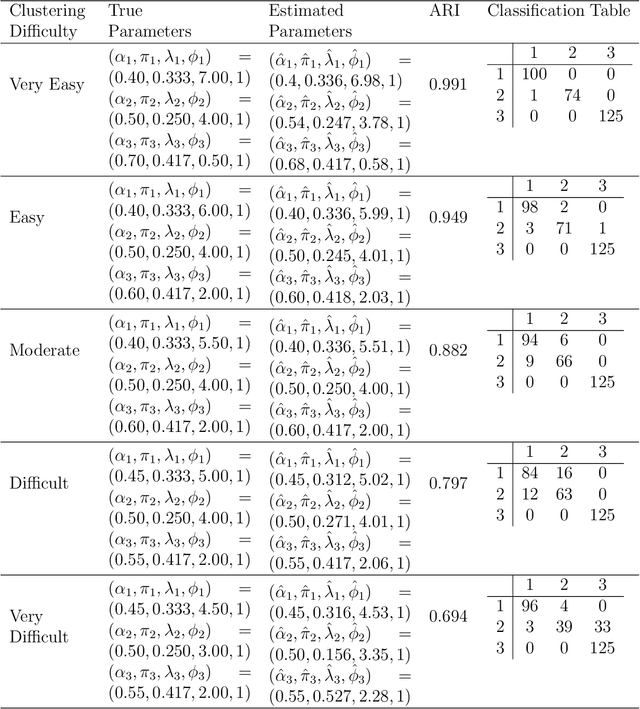
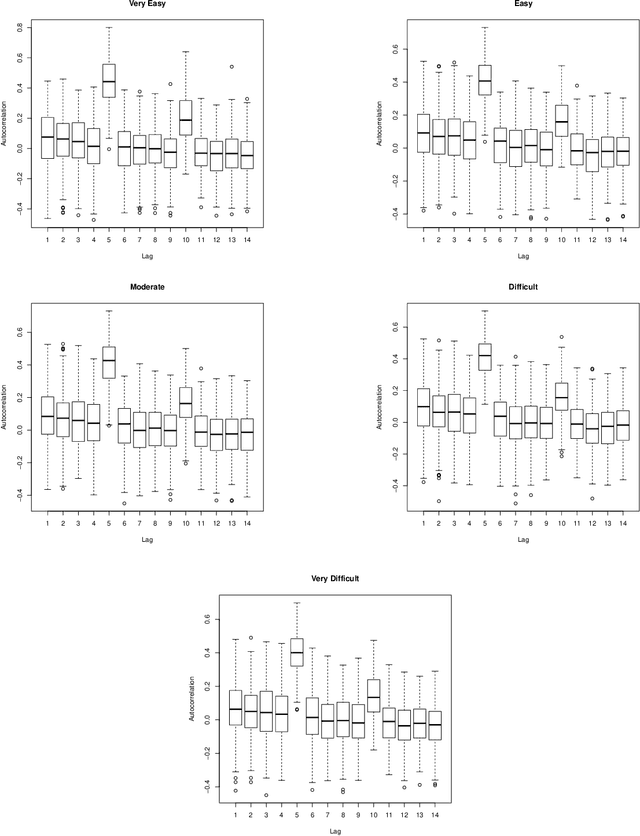
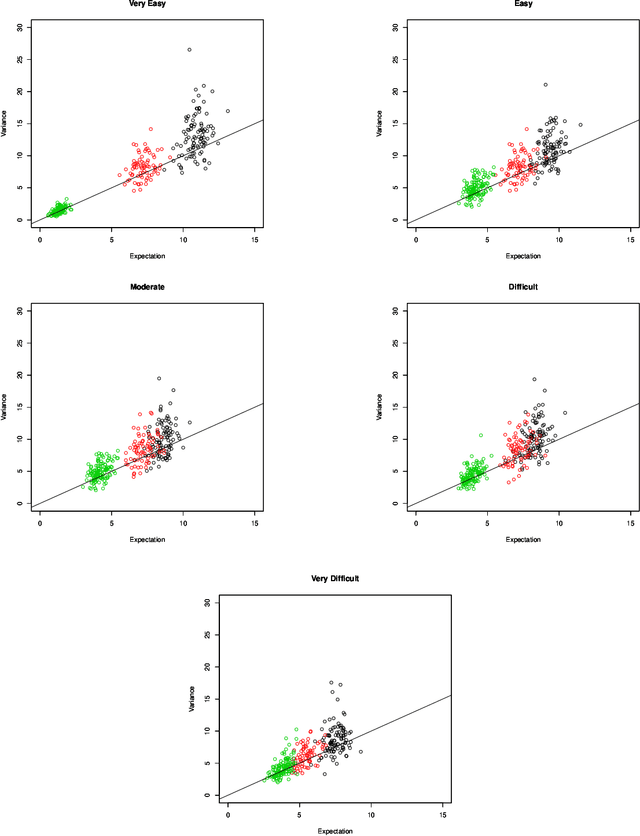
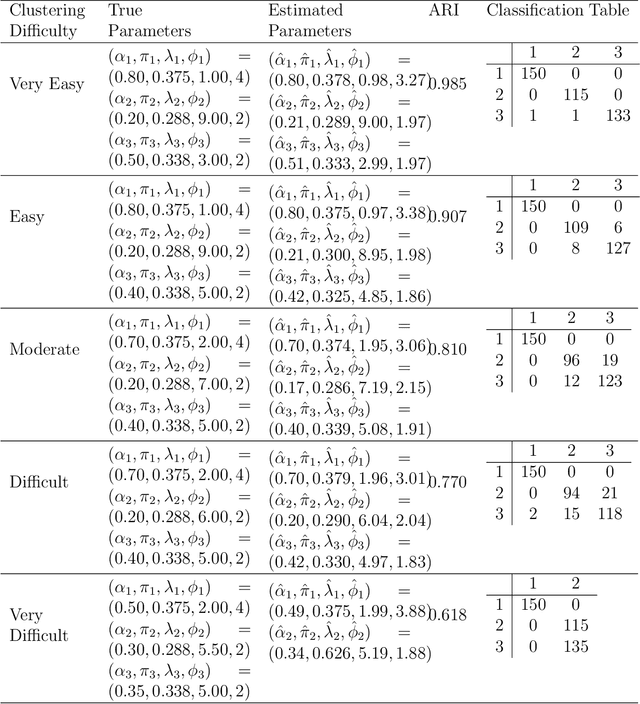
There is a need for the development of models that are able to account for discreteness in data, along with its time series properties and correlation. Our focus falls on INteger-valued AutoRegressive (INAR) type models. The INAR type models can be used in conjunction with existing model-based clustering techniques to cluster discrete valued time series data. With the use of a finite mixture model, several existing techniques such as the selection of the number of clusters, estimation using expectation-maximization and model selection are applicable. The proposed model is then demonstrated on real data to illustrate its clustering applications.
SaLinA: Sequential Learning of Agents
Oct 15, 2021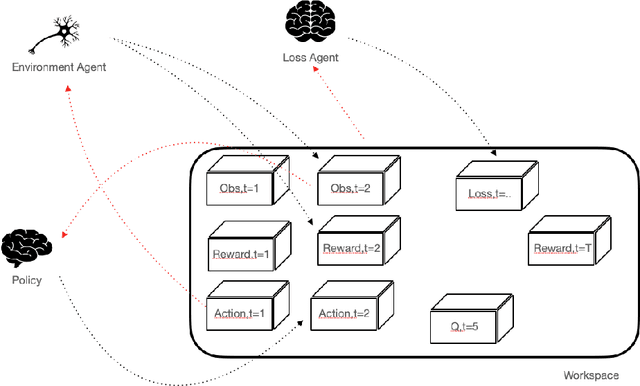


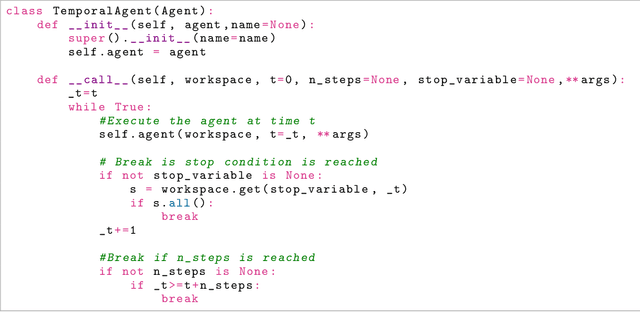
SaLinA is a simple library that makes implementing complex sequential learning models easy, including reinforcement learning algorithms. It is built as an extension of PyTorch: algorithms coded with \SALINA{} can be understood in few minutes by PyTorch users and modified easily. Moreover, SaLinA naturally works with multiple CPUs and GPUs at train and test time, thus being a good fit for the large-scale training use cases. In comparison to existing RL libraries, SaLinA has a very low adoption cost and capture a large variety of settings (model-based RL, batch RL, hierarchical RL, multi-agent RL, etc.). But SaLinA does not only target RL practitioners, it aims at providing sequential learning capabilities to any deep learning programmer.
Robust and Information-theoretically Safe Bias Classifier against Adversarial Attacks
Nov 08, 2021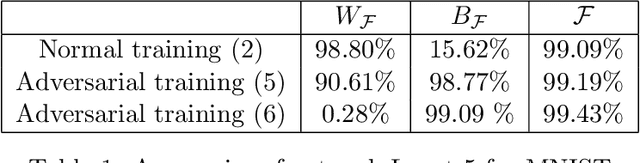
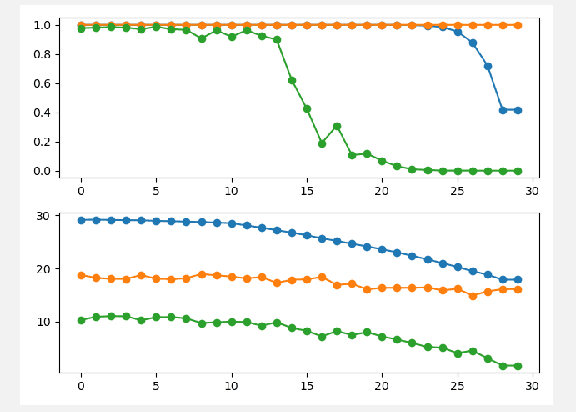

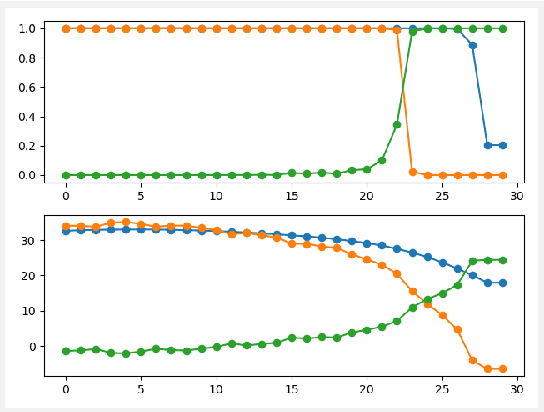
In this paper, the bias classifier is introduced, that is, the bias part of a DNN with Relu as the activation function is used as a classifier. The work is motivated by the fact that the bias part is a piecewise constant function with zero gradient and hence cannot be directly attacked by gradient-based methods to generate adversaries such as FGSM. The existence of the bias classifier is proved an effective training method for the bias classifier is proposed. It is proved that by adding a proper random first-degree part to the bias classifier, an information-theoretically safe classifier against the original-model gradient-based attack is obtained in the sense that the attack generates a totally random direction for generating adversaries. This seems to be the first time that the concept of information-theoretically safe classifier is proposed. Several attack methods for the bias classifier are proposed and numerical experiments are used to show that the bias classifier is more robust than DNNs against these attacks in most cases.
Single-shot fast 3D imaging through scattering media using structured illumination
Oct 23, 2021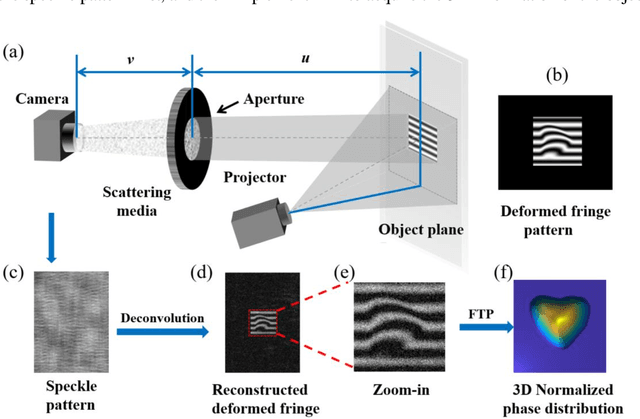
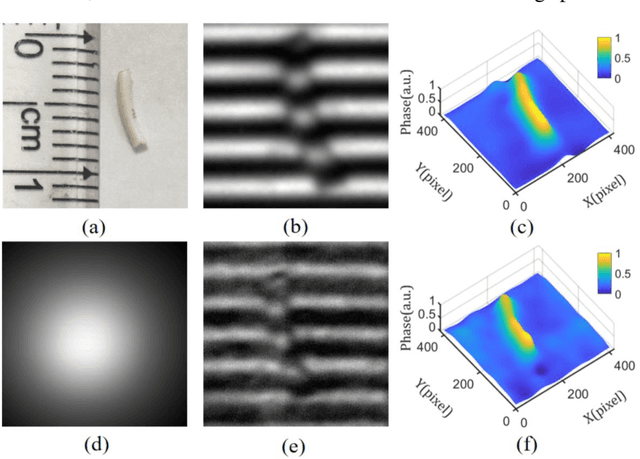

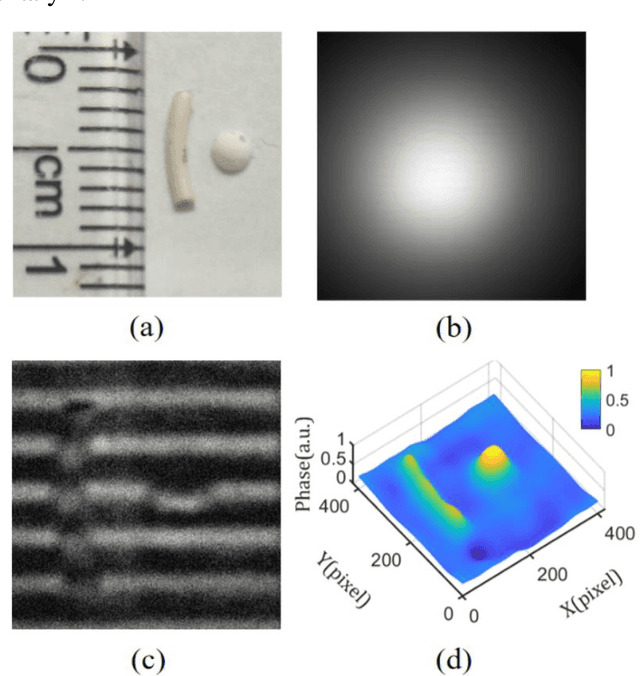
Conventional approaches for 3D imaging in or through scattering media are usually limited to 2D reconstruction of objects at some discontinuous locations, although the time-consuming iteration, guide-star, or complex system are implemented. How to quickly visualize dynamic 3D objects behind scattering media is still an open issue. Here, by using structured light illumination, we propose a single-shot technique that can quickly acquire continuous 3D surfaces of objects hidden behind the diffuser. The proposed method can realize the 3D imaging of single, multiple, and dynamic targets from the speckled structured light patterns under broad or narrow band light illumination, in which only once calibration of the imaging setup is needed before conducting the imaging. Our approach paves the way to quickly visualize dynamic objects behind scattering media in 3D and multispectral.
Flexible Pattern Discovery and Analysis
Nov 24, 2021
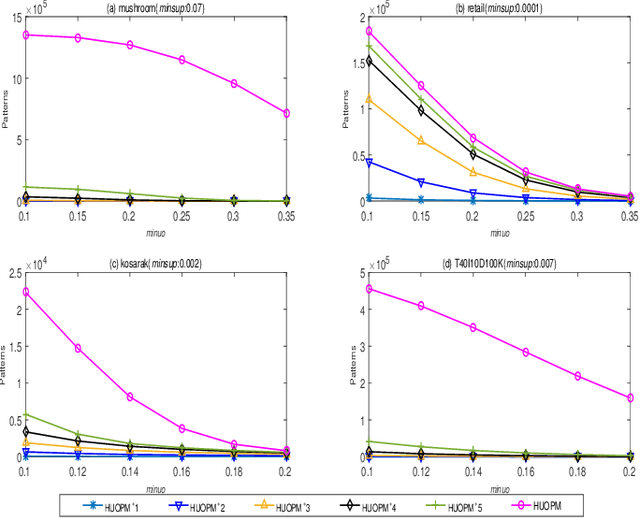
Based on the analysis of the proportion of utility in the supporting transactions used in the field of data mining, high utility-occupancy pattern mining (HUOPM) has recently attracted widespread attention. Unlike high-utility pattern mining (HUPM), which involves the enumeration of high-utility (e.g., profitable) patterns, HUOPM aims to find patterns representing a collection of existing transactions. In practical applications, however, not all patterns are used or valuable. For example, a pattern might contain too many items, that is, the pattern might be too specific and therefore lack value for users in real life. To achieve qualified patterns with a flexible length, we constrain the minimum and maximum lengths during the mining process and introduce a novel algorithm for the mining of flexible high utility-occupancy patterns. Our algorithm is referred to as HUOPM+. To ensure the flexibility of the patterns and tighten the upper bound of the utility-occupancy, a strategy called the length upper-bound (LUB) is presented to prune the search space. In addition, a utility-occupancy nested list (UO-nlist) and a frequency-utility-occupancy table (FUO-table) are employed to avoid multiple scans of the database. Evaluation results of the subsequent experiments confirm that the proposed algorithm can effectively control the length of the derived patterns, for both real-world and synthetic datasets. Moreover, it can decrease the execution time and memory consumption.