 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Optimised Informed RRTs for Mobile Robot Path Planning
Aug 18, 2021
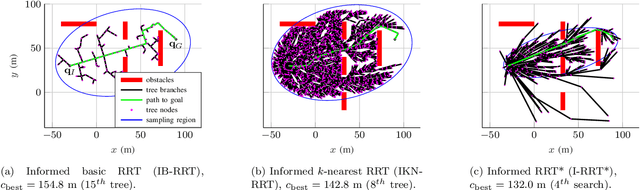
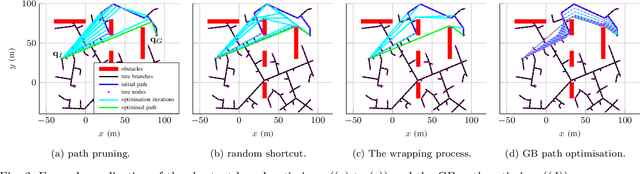
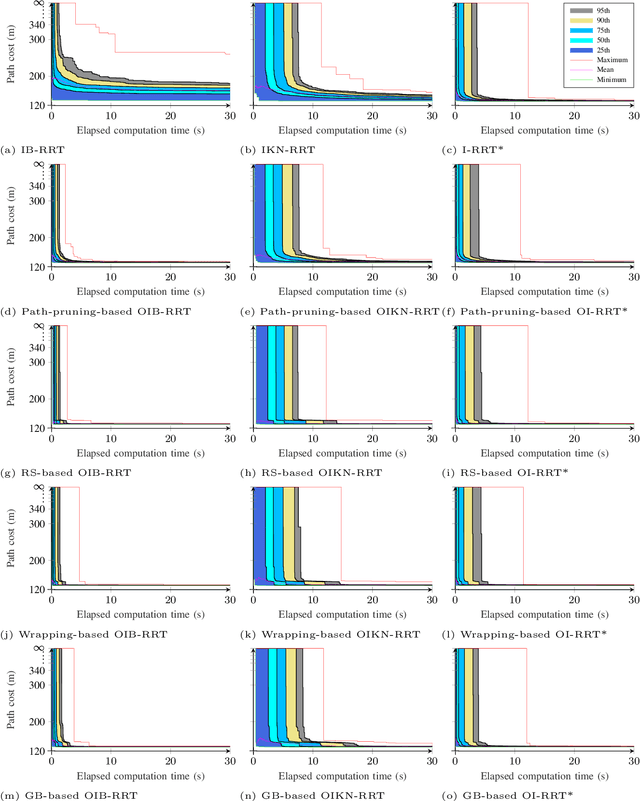
Path planners based on basic rapidly-exploring random trees (RRTs) are quick and efficient, and thus favourable for real-time robot path planning, but are almost-surely suboptimal. In contrast, the optimal RRT (RRT*) converges to the optimal solution, but may be expensive in practice. Recent work has focused on accelerating the RRT*'s convergence rate. The most successful strategies are informed sampling, path optimisation, and a combination thereof. However, these acceleration methods have not been applied to the basic RRT. Moreover, while a number of path optimisers can be used to accelerate the convergence rate, a comparison of their effectiveness is lacking. In this paper, we investigate the use of informed sampling and path optimisation to accelerate planners based on both the basic RRT and the RRT*, resulting in a family of algorithms known as optimised informed RRTs. We apply different path optimisers and compare their effectiveness. The goal is to ascertain if applying informed sampling and path optimisation can help the quick, though almost-surely suboptimal, path planners based on the basic RRT attain comparable or better performance than RRT*-based planners. Analyses show that RRT-based optimised informed RRTs do attain better performance than their RRT*-based counterparts, both when planning time is limited and when there is more planning time.
Simple Contrastive Representation Adversarial Learning for NLP Tasks
Dec 02, 2021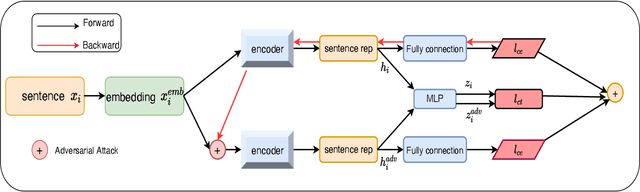

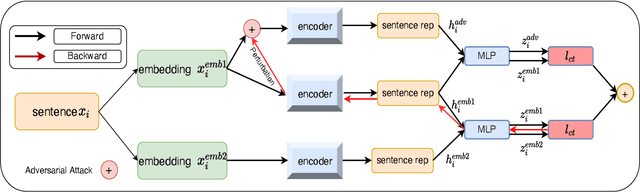

Self-supervised learning approach like contrastive learning is attached great attention in natural language processing. It uses pairs of training data augmentations to build a classification task for an encoder with well representation ability. However, the construction of learning pairs over contrastive learning is much harder in NLP tasks. Previous works generate word-level changes to form pairs, but small transforms may cause notable changes on the meaning of sentences as the discrete and sparse nature of natural language. In this paper, adversarial training is performed to generate challenging and harder learning adversarial examples over the embedding space of NLP as learning pairs. Using contrastive learning improves the generalization ability of adversarial training because contrastive loss can uniform the sample distribution. And at the same time, adversarial training also enhances the robustness of contrastive learning. Two novel frameworks, supervised contrastive adversarial learning (SCAL) and unsupervised SCAL (USCAL), are proposed, which yields learning pairs by utilizing the adversarial training for contrastive learning. The label-based loss of supervised tasks is exploited to generate adversarial examples while unsupervised tasks bring contrastive loss. To validate the effectiveness of the proposed framework, we employ it to Transformer-based models for natural language understanding, sentence semantic textual similarity and adversarial learning tasks. Experimental results on GLUE benchmark tasks show that our fine-tuned supervised method outperforms BERT$_{base}$ over 1.75\%. We also evaluate our unsupervised method on semantic textual similarity (STS) tasks, and our method gets 77.29\% with BERT$_{base}$. The robustness of our approach conducts state-of-the-art results under multiple adversarial datasets on NLI tasks.
User-Centric Federated Learning
Oct 19, 2021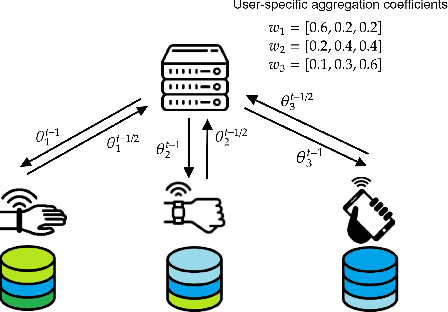
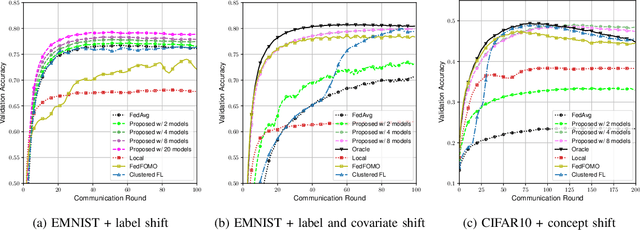
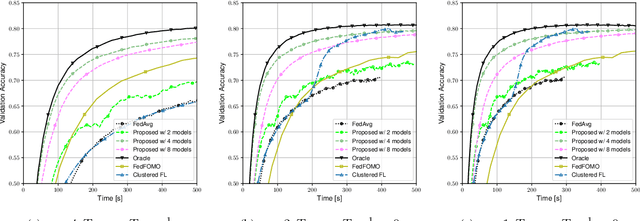

Data heterogeneity across participating devices poses one of the main challenges in federated learning as it has been shown to greatly hamper its convergence time and generalization capabilities. In this work, we address this limitation by enabling personalization using multiple user-centric aggregation rules at the parameter server. Our approach potentially produces a personalized model for each user at the cost of some extra downlink communication overhead. To strike a trade-off between personalization and communication efficiency, we propose a broadcast protocol that limits the number of personalized streams while retaining the essential advantages of our learning scheme. Through simulation results, our approach is shown to enjoy higher personalization capabilities, faster convergence, and better communication efficiency compared to other competing baseline solutions.
CodeNeRF: Disentangled Neural Radiance Fields for Object Categories
Sep 03, 2021
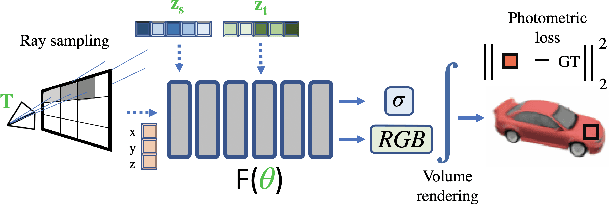
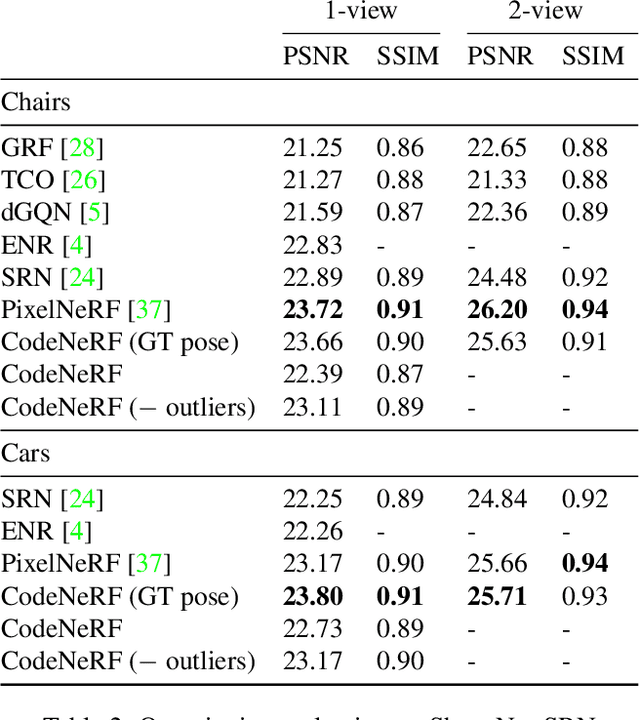
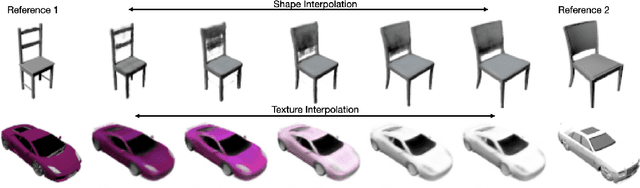
CodeNeRF is an implicit 3D neural representation that learns the variation of object shapes and textures across a category and can be trained, from a set of posed images, to synthesize novel views of unseen objects. Unlike the original NeRF, which is scene specific, CodeNeRF learns to disentangle shape and texture by learning separate embeddings. At test time, given a single unposed image of an unseen object, CodeNeRF jointly estimates camera viewpoint, and shape and appearance codes via optimization. Unseen objects can be reconstructed from a single image, and then rendered from new viewpoints or their shape and texture edited by varying the latent codes. We conduct experiments on the SRN benchmark, which show that CodeNeRF generalises well to unseen objects and achieves on-par performance with methods that require known camera pose at test time. Our results on real-world images demonstrate that CodeNeRF can bridge the sim-to-real gap. Project page: \url{https://github.com/wayne1123/code-nerf}
Robust and Information-theoretically Safe Bias Classifier against Adversarial Attacks
Nov 08, 2021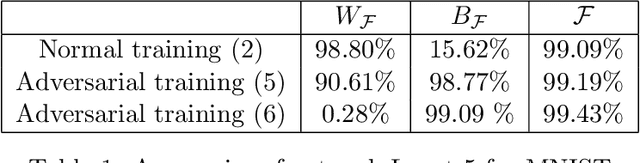
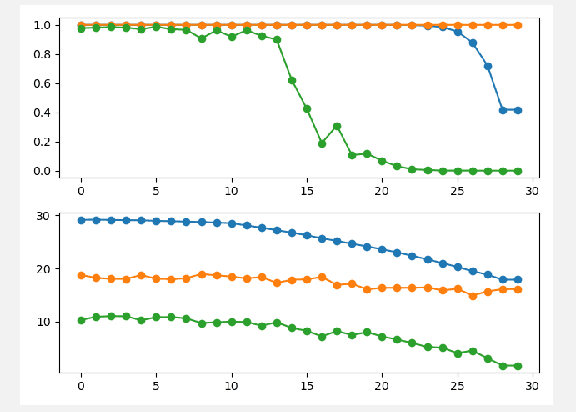

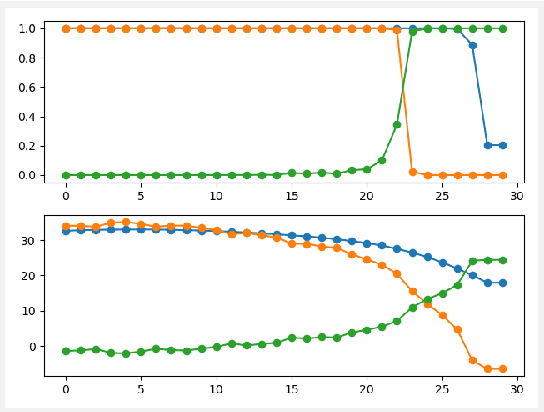
In this paper, the bias classifier is introduced, that is, the bias part of a DNN with Relu as the activation function is used as a classifier. The work is motivated by the fact that the bias part is a piecewise constant function with zero gradient and hence cannot be directly attacked by gradient-based methods to generate adversaries such as FGSM. The existence of the bias classifier is proved an effective training method for the bias classifier is proposed. It is proved that by adding a proper random first-degree part to the bias classifier, an information-theoretically safe classifier against the original-model gradient-based attack is obtained in the sense that the attack generates a totally random direction for generating adversaries. This seems to be the first time that the concept of information-theoretically safe classifier is proposed. Several attack methods for the bias classifier are proposed and numerical experiments are used to show that the bias classifier is more robust than DNNs against these attacks in most cases.
Meta-Voice: Fast few-shot style transfer for expressive voice cloning using meta learning
Nov 14, 2021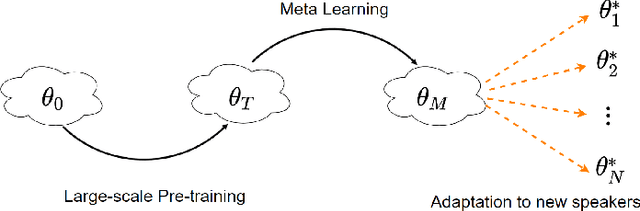
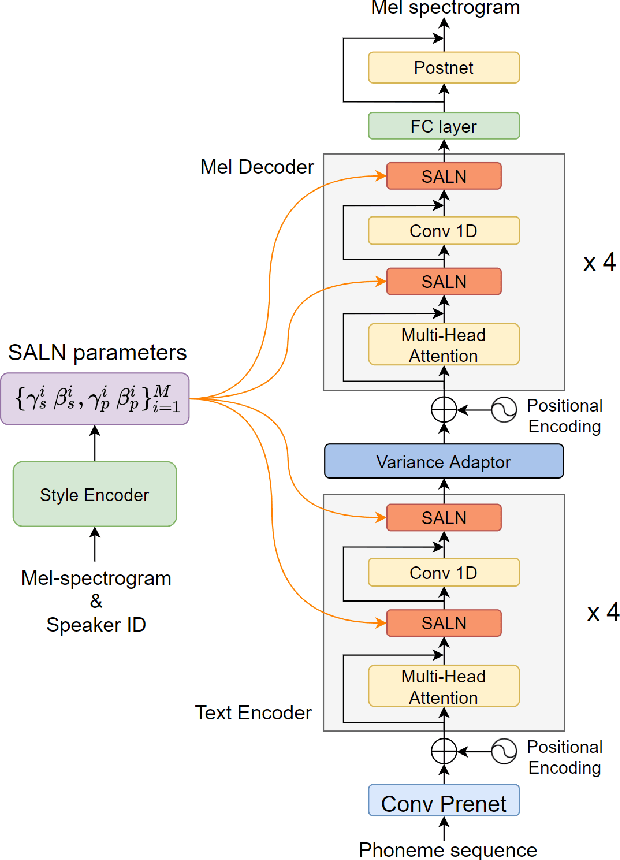
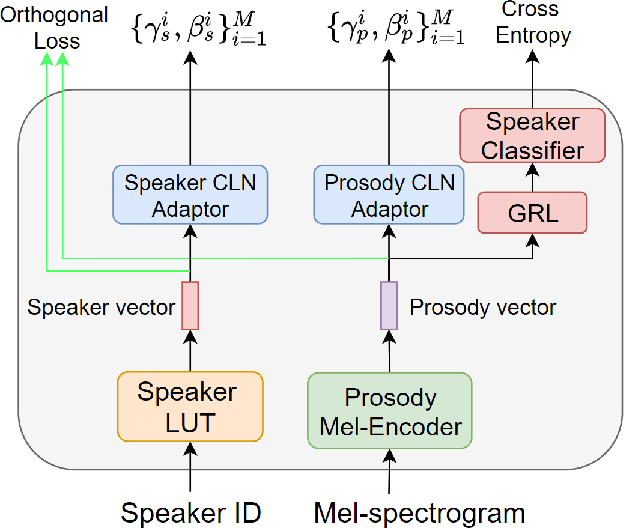
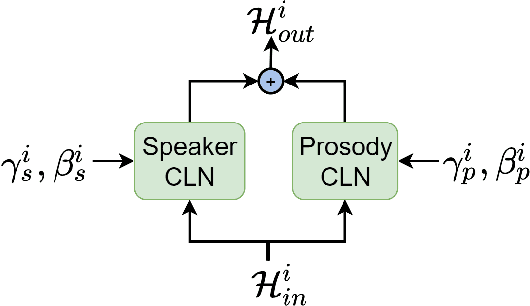
The task of few-shot style transfer for voice cloning in text-to-speech (TTS) synthesis aims at transferring speaking styles of an arbitrary source speaker to a target speaker's voice using very limited amount of neutral data. This is a very challenging task since the learning algorithm needs to deal with few-shot voice cloning and speaker-prosody disentanglement at the same time. Accelerating the adaptation process for a new target speaker is of importance in real-world applications, but even more challenging. In this paper, we approach to the hard fast few-shot style transfer for voice cloning task using meta learning. We investigate the model-agnostic meta-learning (MAML) algorithm and meta-transfer a pre-trained multi-speaker and multi-prosody base TTS model to be highly sensitive for adaptation with few samples. Domain adversarial training mechanism and orthogonal constraint are adopted to disentangle speaker and prosody representations for effective cross-speaker style transfer. Experimental results show that the proposed approach is able to conduct fast voice cloning using only 5 samples (around 12 second speech data) from a target speaker, with only 100 adaptation steps. Audio samples are available online.
Mimicking Playstyle by Adapting Parameterized Behavior Trees in RTS Games
Nov 23, 2021
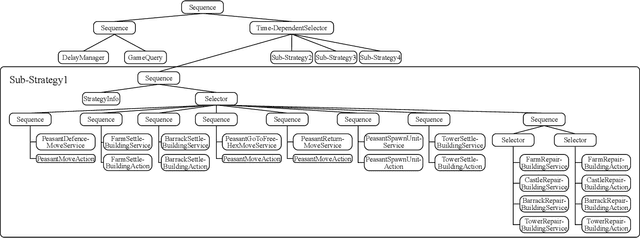
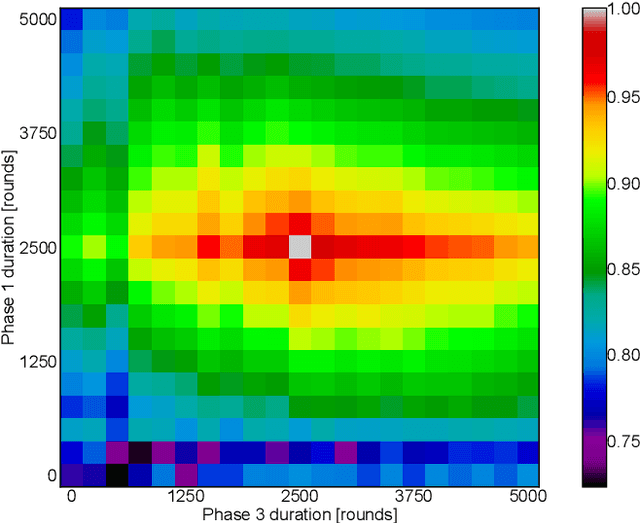
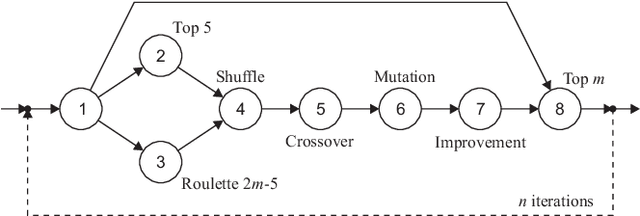
The discovery of Behavior Trees (BTs) impacted the field of Artificial Intelligence (AI) in games, by providing flexible and natural representation of non-player characters (NPCs) logic, manageable by game-designers. Nevertheless, increased pressure on ever better NPCs AI-agents forced complexity of handcrafted BTs to became barely-tractable and error-prone. On the other hand, while many just-launched on-line games suffer from player-shortage, the existence of AI with a broad-range of capabilities could increase players retention. Therefore, to handle above challenges, recent trends in the field focused on automatic creation of AI-agents: from deep- and reinforcementlearning techniques to combinatorial (constrained) optimization and evolution of BTs. In this paper, we present a novel approach to semi-automatic construction of AI-agents, that mimic and generalize given human gameplays by adapting and tuning of expert-created BT under a developed similarity metric between source and BT gameplays. To this end, we formulated mixed discrete-continuous optimization problem, in which topological and functional changes of the BT are reflected in numerical variables, and constructed a dedicated hybrid-metaheuristic. The performance of presented approach was verified experimentally in a prototype real-time strategy game. Carried out experiments confirmed efficiency and perspectives of presented approach, which is going to be applied in a commercial game.
A Review of Dialogue Systems: From Trained Monkeys to Stochastic Parrots
Nov 02, 2021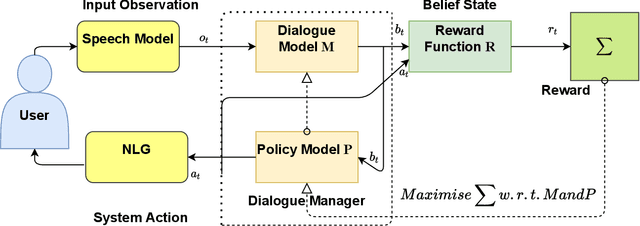
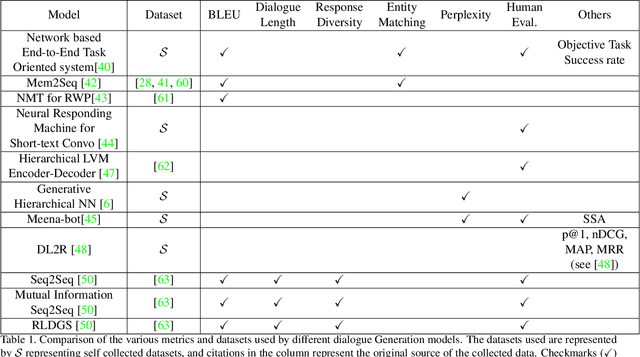
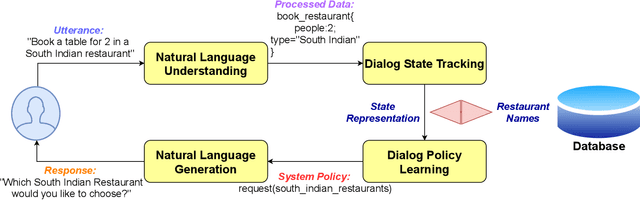

In spoken dialogue systems, we aim to deploy artificial intelligence to build automated dialogue agents that can converse with humans. Dialogue systems are increasingly being designed to move beyond just imitating conversation and also improve from such interactions over time. In this survey, we present a broad overview of methods developed to build dialogue systems over the years. Different use cases for dialogue systems ranging from task-based systems to open domain chatbots motivate and necessitate specific systems. Starting from simple rule-based systems, research has progressed towards increasingly complex architectures trained on a massive corpus of datasets, like deep learning systems. Motivated with the intuition of resembling human dialogues, progress has been made towards incorporating emotions into the natural language generator, using reinforcement learning. While we see a trend of highly marginal improvement on some metrics, we find that limited justification exists for the metrics, and evaluation practices are not uniform. To conclude, we flag these concerns and highlight possible research directions.
Root Cause Detection Among Anomalous Time Series Using Temporal State Alignment
Jan 04, 2020
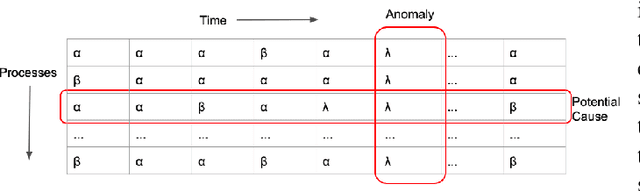
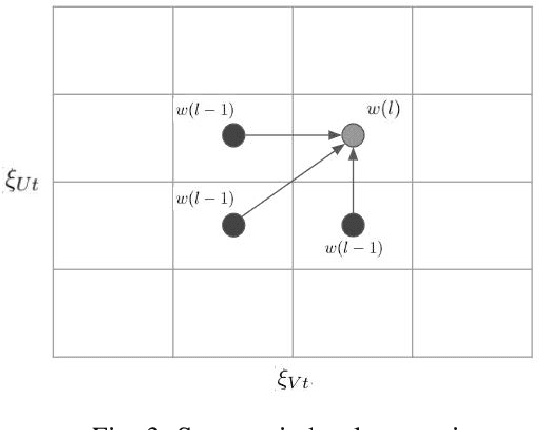
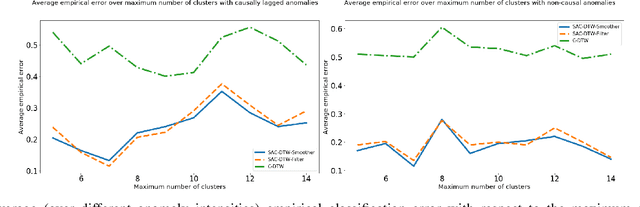
The recent increase in the scale and complexity of software systems has introduced new challenges to the time series monitoring and anomaly detection process. A major drawback of existing anomaly detection methods is that they lack contextual information to help stakeholders identify the cause of anomalies. This problem, known as root cause detection, is particularly challenging to undertake in today's complex distributed software systems since the metrics under consideration generally have multiple internal and external dependencies. Significant manual analysis and strong domain expertise is required to isolate the correct cause of the problem. In this paper, we propose a method that isolates the root cause of an anomaly by analyzing the patterns in time series fluctuations. Our method considers the time series as observations from an underlying process passing through a sequence of discretized hidden states. The idea is to track the propagation of the effect when a given problem causes unaligned but homogeneous shifts of the underlying states. We evaluate our approach by finding the root cause of anomalies in Zillows clickstream data by identifying causal patterns among a set of observed fluctuations.
SaLinA: Sequential Learning of Agents
Oct 15, 2021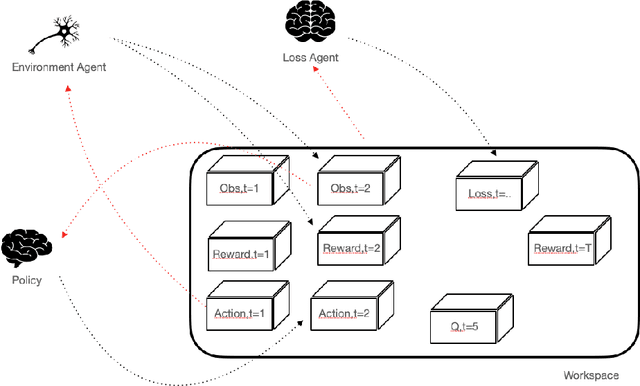


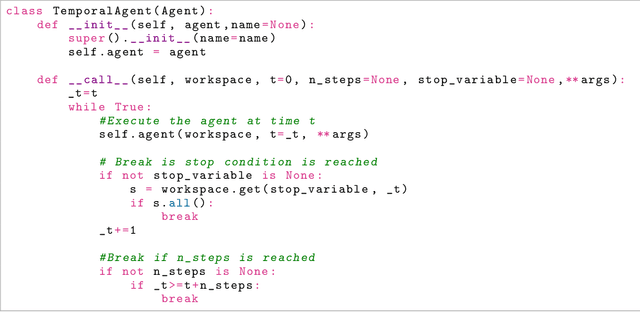
SaLinA is a simple library that makes implementing complex sequential learning models easy, including reinforcement learning algorithms. It is built as an extension of PyTorch: algorithms coded with \SALINA{} can be understood in few minutes by PyTorch users and modified easily. Moreover, SaLinA naturally works with multiple CPUs and GPUs at train and test time, thus being a good fit for the large-scale training use cases. In comparison to existing RL libraries, SaLinA has a very low adoption cost and capture a large variety of settings (model-based RL, batch RL, hierarchical RL, multi-agent RL, etc.). But SaLinA does not only target RL practitioners, it aims at providing sequential learning capabilities to any deep learning programmer.