 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Object Manipulation to an Arbitrary Goal Pose: Learning-based Anytime Prioritized Planning
Sep 22, 2021

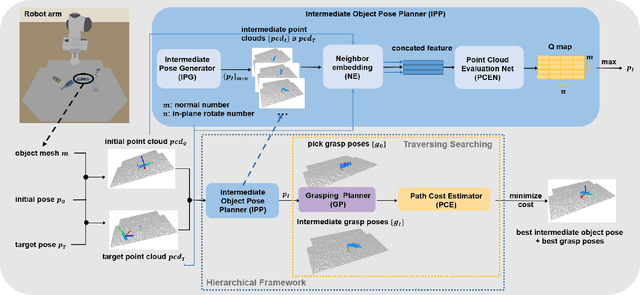
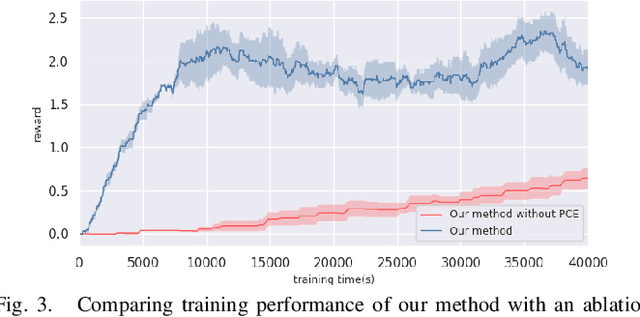
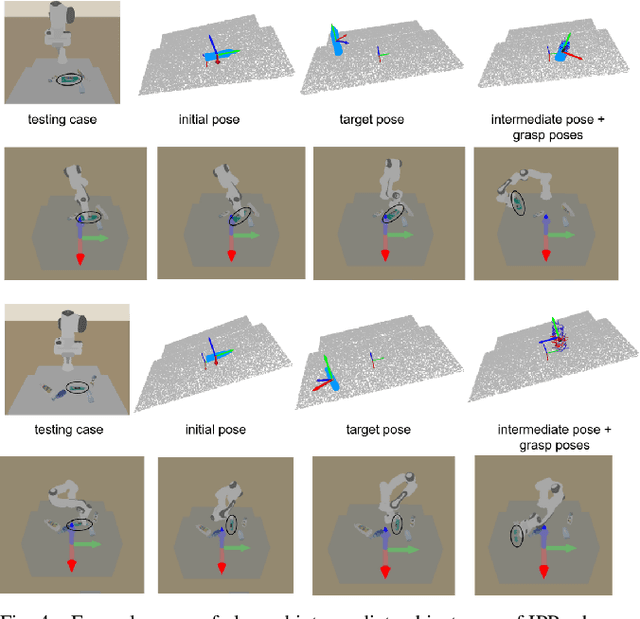
We focus on the task of object manipulation to an arbitrary goal pose, in which a robot is supposed to pick an assigned object to place at the goal position with a specific pose. However, limited by the execution space of the manipulator with gripper, one-step picking, moving and releasing might be failed, where an intermediate object pose is required as a transition. In this paper, we propose a learning-driven anytime prioritized search-based solver to find a feasible solution with low path cost in a short time. In our work, the problem is formulated as a hierarchical learning problem, with the high level aiming at finding an intermediate object pose, and the low-level manipulator path planning between adjacent grasps. We learn an off-line training path cost estimator to predict approximate path planning costs, which serve as pseudo rewards to allow for pre-training the high-level planner without interacting with the simulator. To deal with the problem of distribution mismatch of the cost net and the actual execution cost space, a refined training stage is conducted with simulation interaction. A series of experiments carried out in simulation and real world indicate that our system can achieve better performances in the object manipulation task with less time and less cost.
Three-dimensional Cooperative Localization of Commercial-Off-The-Shelf Sensors
Nov 03, 2021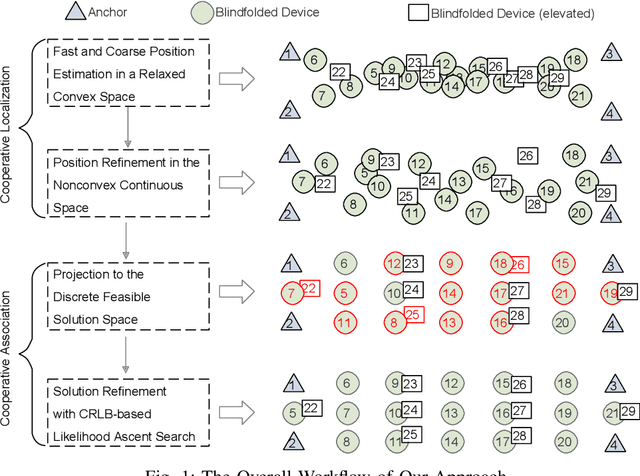
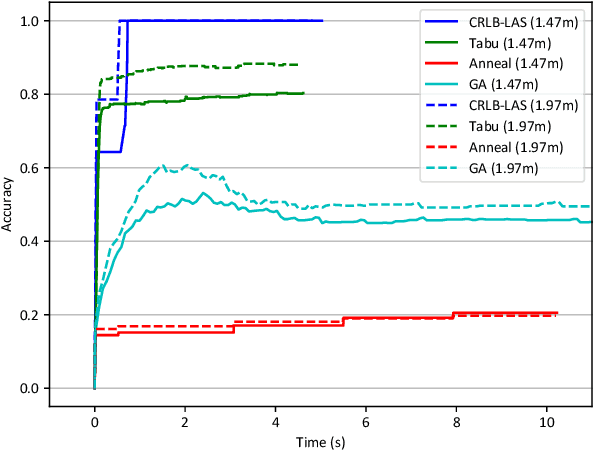
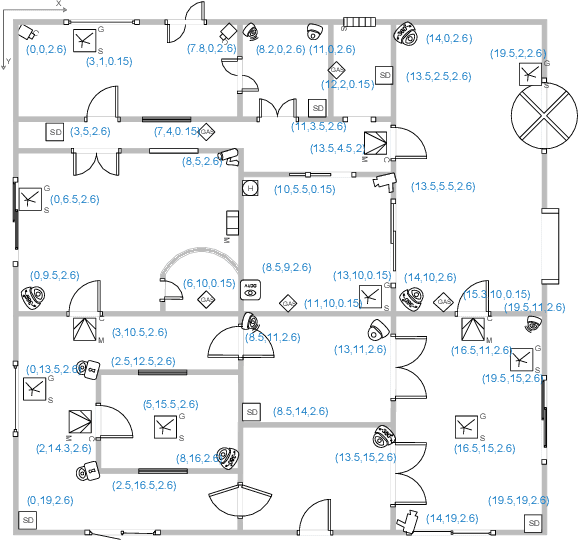
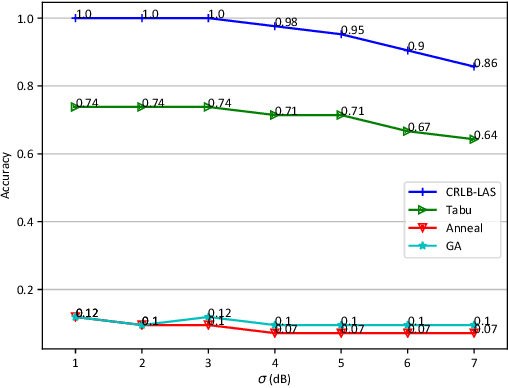
Many location-based services use Received Signal Strength (RSS) measurements due to their universal availability. In this paper, we study the association of a large number of low-cost Internet-of-Things (IoT) sensors and their possible installation locations, which can enable various sensing and automation-related applications. We propose an efficient approach to solve the corresponding permutation combinatorial optimization problem, which integrates continuous space cooperative localization and permutation space likelihood ascent search. A convex relaxation-based optimization is designed to estimate the coarse locations of blindfolded devices in continuous 3D spaces, which are then projected to the feasible permutation space. An efficient Cram\'er-Rao Lower Bound based likelihood ascent search algorithm is proposed to refine the solution. Extensive experiments were conducted to evaluate the performance of the proposed approach, which show that the proposed approach significantly outperforms state-of-the-art combinatorial optimization algorithms and achieves close-to-100% accuracy with affordable execution time.
Towards an Efficient Semantic Segmentation Method of ID Cards for Verification Systems
Nov 24, 2021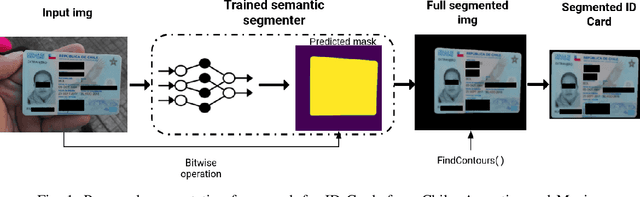

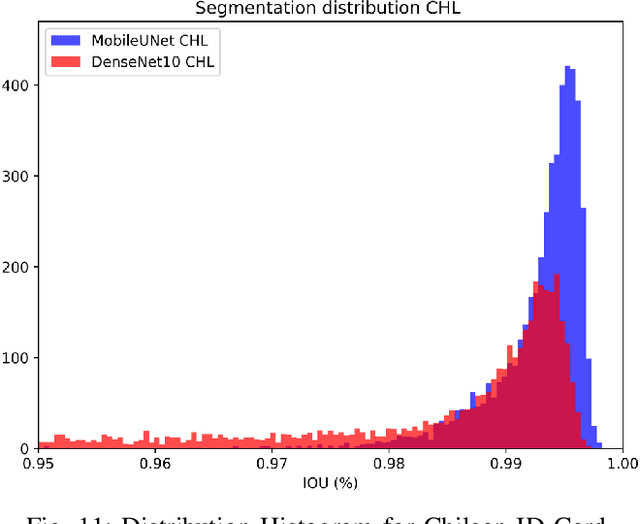
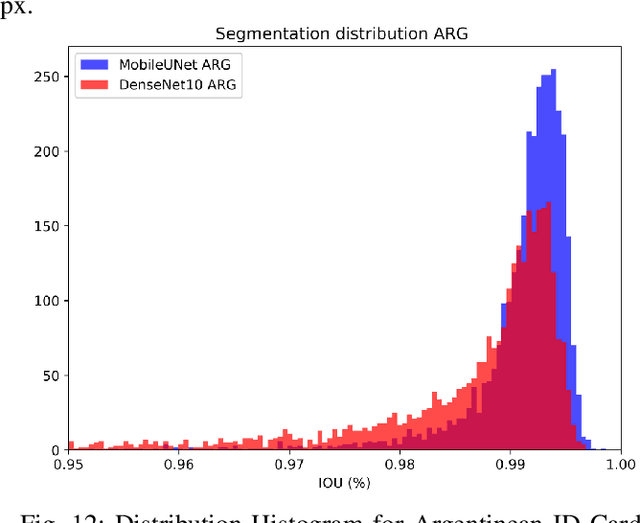
Removing the background in ID Card images is a real challenge for remote verification systems because many of the re-digitalised images present cluttered backgrounds, poor illumination conditions, distortion and occlusions. The background in ID Card images confuses the classifiers and the text extraction. Due to the lack of available images for research, this field represents an open problem in computer vision today. This work proposes a method for removing the background using semantic segmentation of ID Cards. In the end, images captured in the wild from the real operation, using a manually labelled dataset consisting of 45,007 images, with five types of ID Cards from three countries (Chile, Argentina and Mexico), including typical presentation attack scenarios, were used. This method can help to improve the following stages in a regular identity verification or document tampering detection system. Two Deep Learning approaches were explored, based on MobileUNet and DenseNet10. The best results were obtained using MobileUNet, with 6.5 million parameters. A Chilean ID Card's mean Intersection Over Union (IoU) was 0.9926 on a private test dataset of 4,988 images. The best results for the fused multi-country dataset of ID Card images from Chile, Argentina and Mexico reached an IoU of 0.9911. The proposed methods are lightweight enough to be used in real-time operation on mobile devices.
Sustainable AI: Environmental Implications, Challenges and Opportunities
Oct 30, 2021
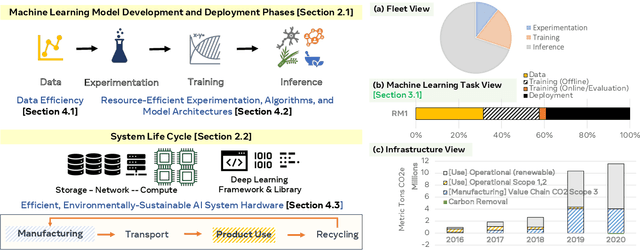
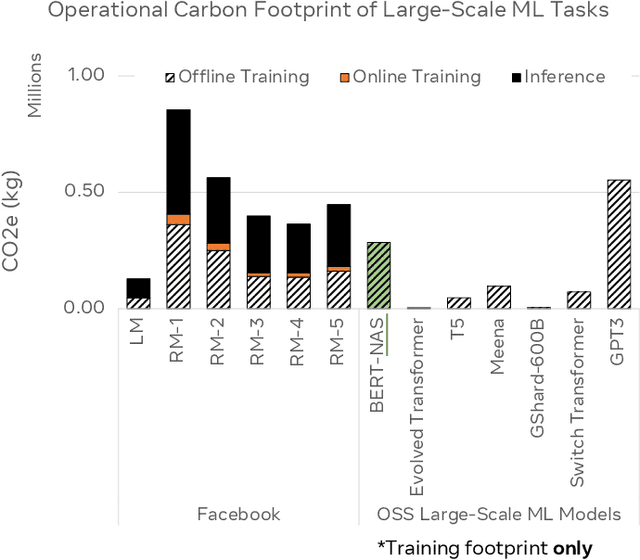
This paper explores the environmental impact of the super-linear growth trends for AI from a holistic perspective, spanning Data, Algorithms, and System Hardware. We characterize the carbon footprint of AI computing by examining the model development cycle across industry-scale machine learning use cases and, at the same time, considering the life cycle of system hardware. Taking a step further, we capture the operational and manufacturing carbon footprint of AI computing and present an end-to-end analysis for what and how hardware-software design and at-scale optimization can help reduce the overall carbon footprint of AI. Based on the industry experience and lessons learned, we share the key challenges and chart out important development directions across the many dimensions of AI. We hope the key messages and insights presented in this paper can inspire the community to advance the field of AI in an environmentally-responsible manner.
Compressing Sensor Data for Remote Assistance of Autonomous Vehicles using Deep Generative Models
Nov 09, 2021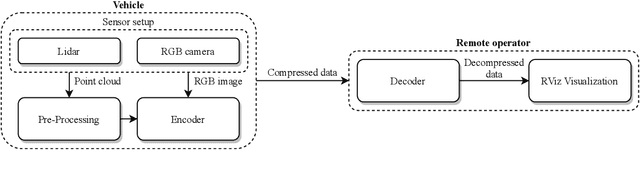
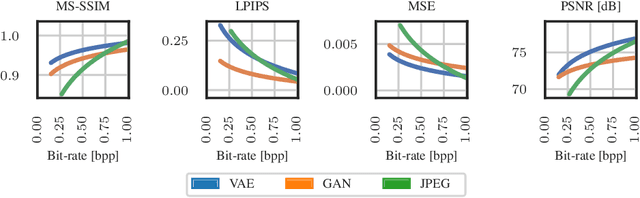

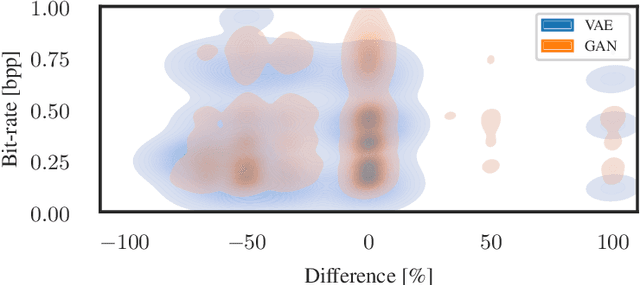
In the foreseeable future, autonomous vehicles will require human assistance in situations they can not resolve on their own. In such scenarios, remote assistance from a human can provide the required input for the vehicle to continue its operation. Typical sensors used in autonomous vehicles include camera and lidar sensors. Due to the massive volume of sensor data that must be sent in real-time, highly efficient data compression is elementary to prevent an overload of network infrastructure. Sensor data compression using deep generative neural networks has been shown to outperform traditional compression approaches for both image and lidar data, regarding compression rate as well as reconstruction quality. However, there is a lack of research about the performance of generative-neural-network-based compression algorithms for remote assistance. In order to gain insights into the feasibility of deep generative models for usage in remote assistance, we evaluate state-of-the-art algorithms regarding their applicability and identify potential weaknesses. Further, we implement an online pipeline for processing sensor data and demonstrate its performance for remote assistance using the CARLA simulator.
TinyDefectNet: Highly Compact Deep Neural Network Architecture for High-Throughput Manufacturing Visual Quality Inspection
Nov 29, 2021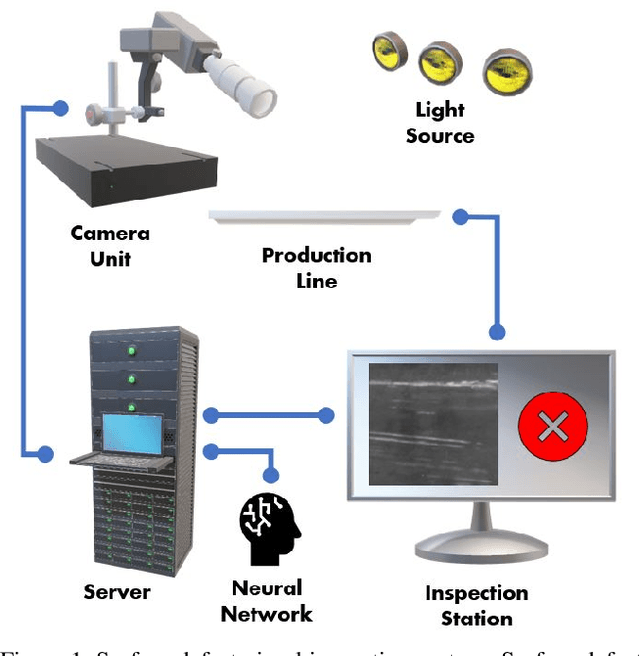
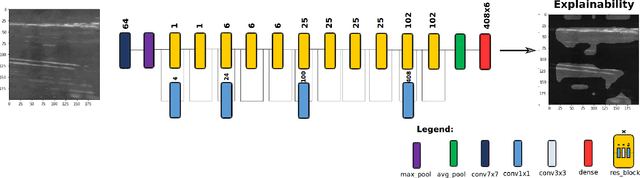

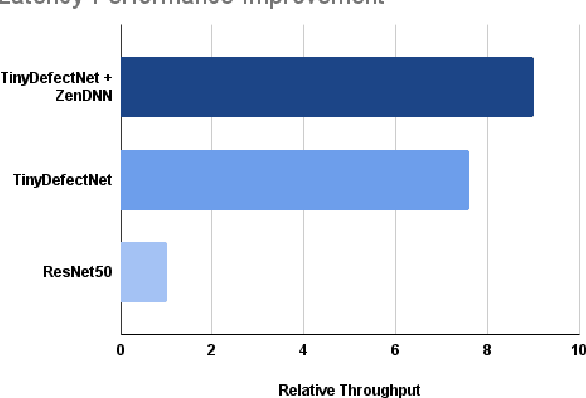
A critical aspect in the manufacturing process is the visual quality inspection of manufactured components for defects and flaws. Human-only visual inspection can be very time-consuming and laborious, and is a significant bottleneck especially for high-throughput manufacturing scenarios. Given significant advances in the field of deep learning, automated visual quality inspection can lead to highly efficient and reliable detection of defects and flaws during the manufacturing process. However, deep learning-driven visual inspection methods often necessitate significant computational resources, thus limiting throughput and act as a bottleneck to widespread adoption for enabling smart factories. In this study, we investigated the utilization of a machine-driven design exploration approach to create TinyDefectNet, a highly compact deep convolutional network architecture tailored for high-throughput manufacturing visual quality inspection. TinyDefectNet comprises of just ~427K parameters and has a computational complexity of ~97M FLOPs, yet achieving a detection accuracy of a state-of-the-art architecture for the task of surface defect detection on the NEU defect benchmark dataset. As such, TinyDefectNet can achieve the same level of detection performance at 52$\times$ lower architectural complexity and 11x lower computational complexity. Furthermore, TinyDefectNet was deployed on an AMD EPYC 7R32, and achieved 7.6x faster throughput using the native Tensorflow environment and 9x faster throughput using AMD ZenDNN accelerator library. Finally, explainability-driven performance validation strategy was conducted to ensure correct decision-making behaviour was exhibited by TinyDefectNet to improve trust in its usage by operators and inspectors.
FastBERT: a Self-distilling BERT with Adaptive Inference Time
Apr 05, 2020
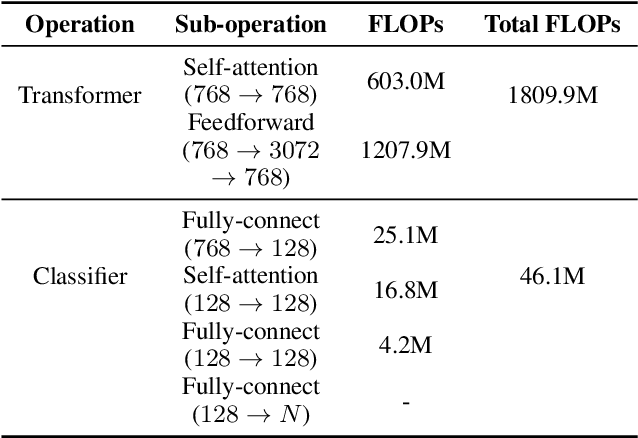
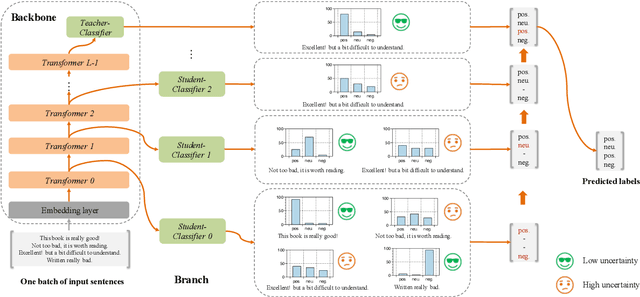
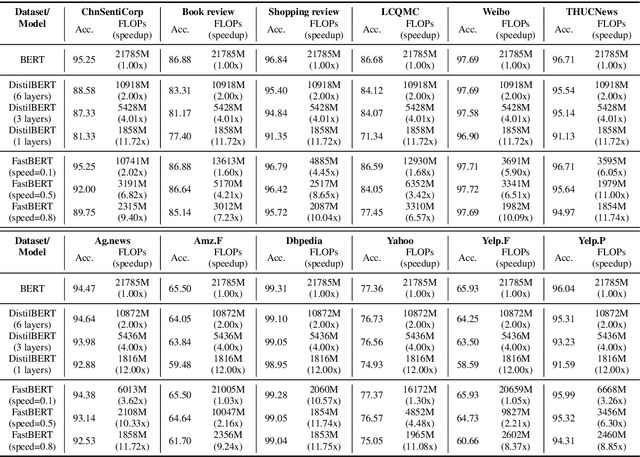
Pre-trained language models like BERT have proven to be highly performant. However, they are often computationally expensive in many practical scenarios, for such heavy models can hardly be readily implemented with limited resources. To improve their efficiency with an assured model performance, we propose a novel speed-tunable FastBERT with adaptive inference time. The speed at inference can be flexibly adjusted under varying demands, while redundant calculation of samples is avoided. Moreover, this model adopts a unique self-distillation mechanism at fine-tuning, further enabling a greater computational efficacy with minimal loss in performance. Our model achieves promising results in twelve English and Chinese datasets. It is able to speed up by a wide range from 1 to 12 times than BERT if given different speedup thresholds to make a speed-performance tradeoff.
A Scalable Inference Method For Large Dynamic Economic Systems
Oct 27, 2021
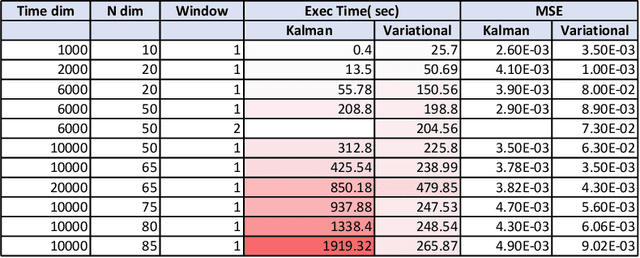
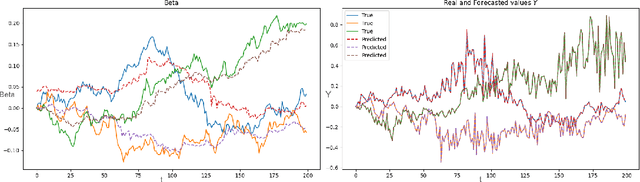
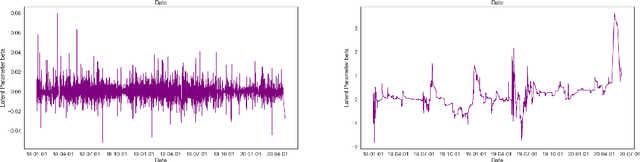
The nature of available economic data has changed fundamentally in the last decade due to the economy's digitisation. With the prevalence of often black box data-driven machine learning methods, there is a necessity to develop interpretable machine learning methods that can conduct econometric inference, helping policymakers leverage the new nature of economic data. We therefore present a novel Variational Bayesian Inference approach to incorporate a time-varying parameter auto-regressive model which is scalable for big data. Our model is applied to a large blockchain dataset containing prices, transactions of individual actors, analyzing transactional flows and price movements on a very granular level. The model is extendable to any dataset which can be modelled as a dynamical system. We further improve the simple state-space modelling by introducing non-linearities in the forward model with the help of machine learning architectures.
American Hate Crime Trends Prediction with Event Extraction
Nov 09, 2021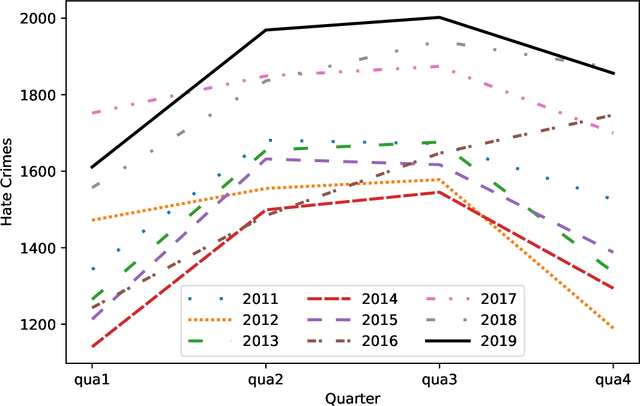
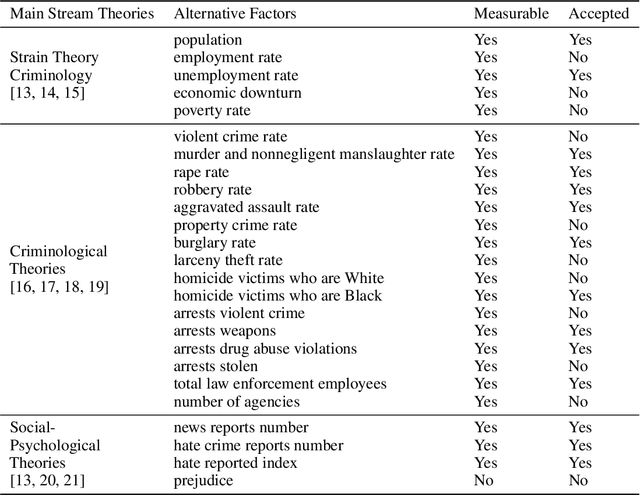
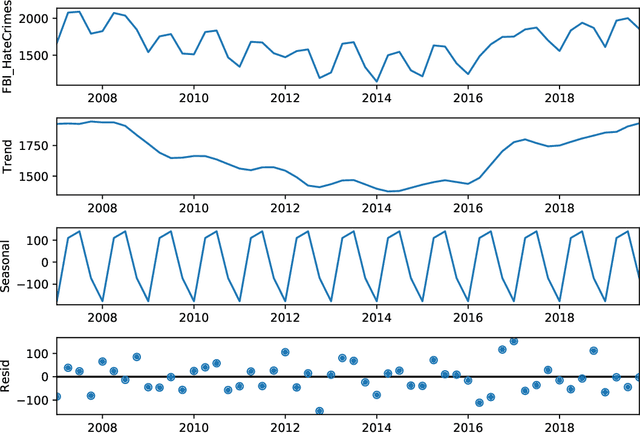

Social media platforms may provide potential space for discourses that contain hate speech, and even worse, can act as a propagation mechanism for hate crimes. The FBI's Uniform Crime Reporting (UCR) Program collects hate crime data and releases statistic report yearly. These statistics provide information in determining national hate crime trends. The statistics can also provide valuable holistic and strategic insight for law enforcement agencies or justify lawmakers for specific legislation. However, the reports are mostly released next year and lag behind many immediate needs. Recent research mainly focuses on hate speech detection in social media text or empirical studies on the impact of a confirmed crime. This paper proposes a framework that first utilizes text mining techniques to extract hate crime events from New York Times news, then uses the results to facilitate predicting American national-level and state-level hate crime trends. Experimental results show that our method can significantly enhance the prediction performance compared with time series or regression methods without event-related factors. Our framework broadens the methods of national-level and state-level hate crime trends prediction.
Moment evolution equations and moment matching for stochastic image EPDiff
Oct 07, 2021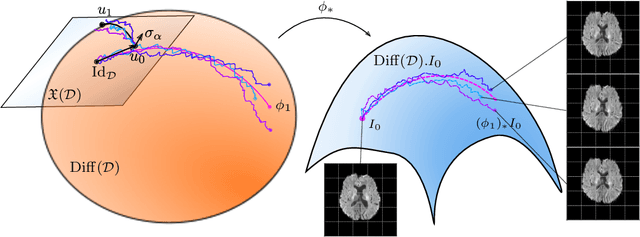
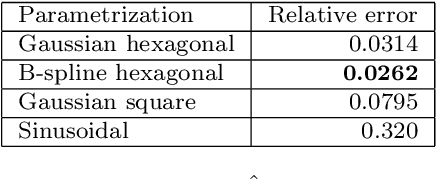
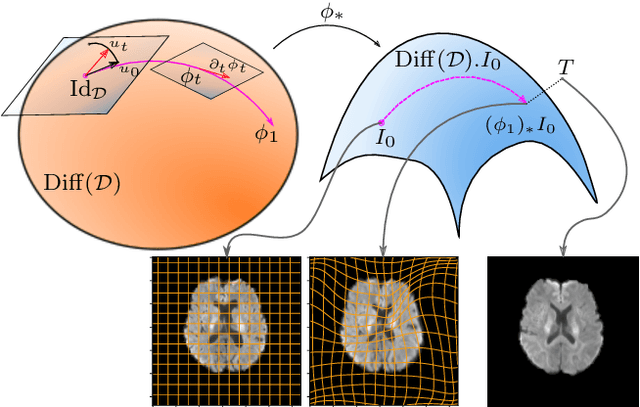

Models of stochastic image deformation allow study of time-continuous stochastic effects transforming images by deforming the image domain. Applications include longitudinal medical image analysis with both population trends and random subject specific variation. Focusing on a stochastic extension of the LDDMM models with evolutions governed by a stochastic EPDiff equation, we use moment approximations of the corresponding Ito diffusion to construct estimators for statistical inference in the full stochastic model. We show that this approach, when efficiently implemented with automatic differentiation tools, can successfully estimate parameters encoding the spatial correlation of the noise fields on the image