 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
OVERT: An Algorithm for Safety Verification of Neural Network Control Policies for Nonlinear Systems
Aug 03, 2021
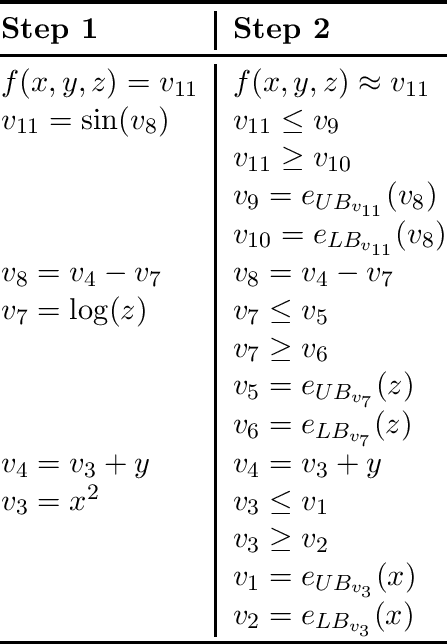
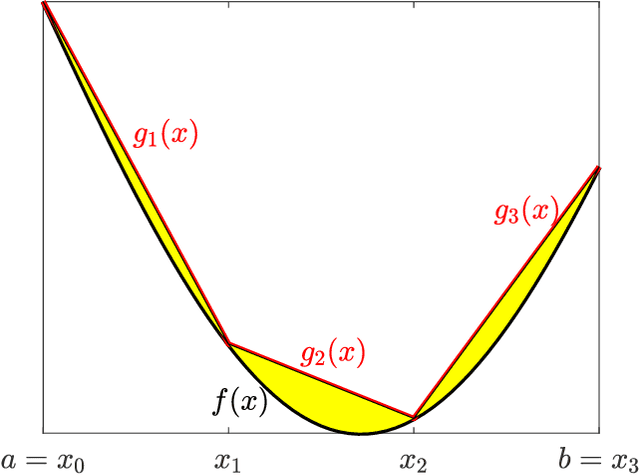
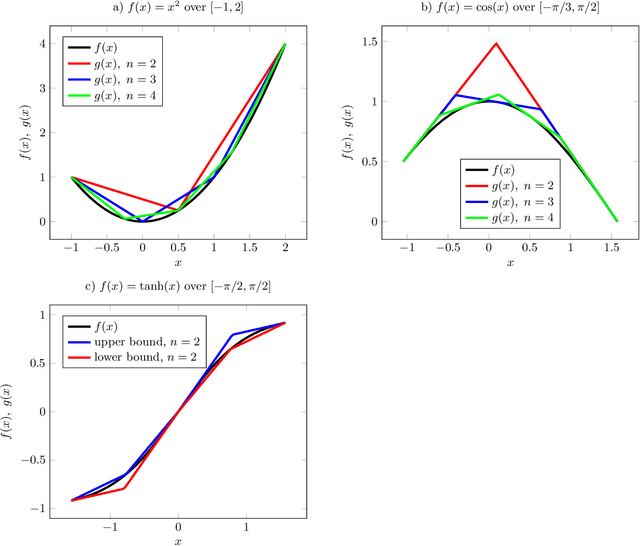

Deep learning methods can be used to produce control policies, but certifying their safety is challenging. The resulting networks are nonlinear and often very large. In response to this challenge, we present OVERT: a sound algorithm for safety verification of nonlinear discrete-time closed loop dynamical systems with neural network control policies. The novelty of OVERT lies in combining ideas from the classical formal methods literature with ideas from the newer neural network verification literature. The central concept of OVERT is to abstract nonlinear functions with a set of optimally tight piecewise linear bounds. Such piecewise linear bounds are designed for seamless integration into ReLU neural network verification tools. OVERT can be used to prove bounded-time safety properties by either computing reachable sets or solving feasibility queries directly. We demonstrate various examples of safety verification for several classical benchmark examples. OVERT compares favorably to existing methods both in computation time and in tightness of the reachable set.
Automatic Evaluation and Moderation of Open-domain Dialogue Systems
Nov 03, 2021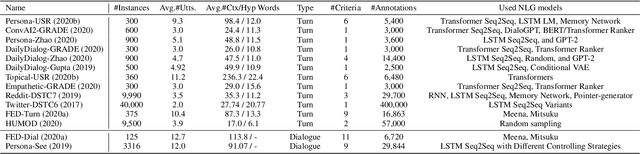


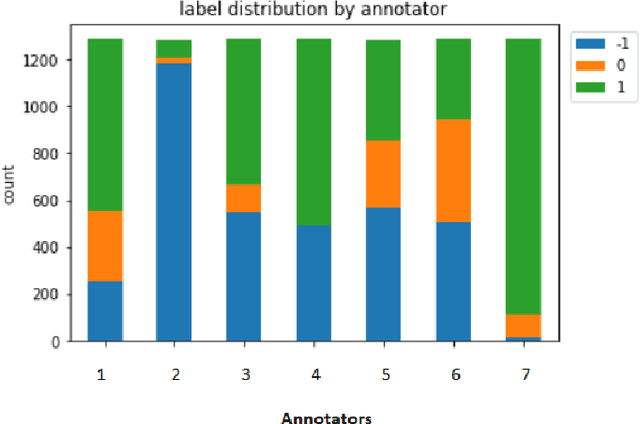
In recent years, dialogue systems have attracted significant interests in both academia and industry. Especially the discipline of open-domain dialogue systems, aka chatbots, has gained great momentum. Yet, a long standing challenge that bothers the researchers is the lack of effective automatic evaluation metrics, which results in significant impediment in the current research. Common practice in assessing the performance of open-domain dialogue models involves extensive human evaluation on the final deployed models, which is both time- and cost- intensive. Moreover, a recent trend in building open-domain chatbots involve pre-training dialogue models with a large amount of social media conversation data. However, the information contained in the social media conversations may be offensive and inappropriate. Indiscriminate usage of such data can result in insensitive and toxic generative models. This paper describes the data, baselines and results obtained for the Track 5 at the Dialogue System Technology Challenge 10 (DSTC10).
Deep Convolution Network Based Emotion Analysis for Automatic Detection of Mild Cognitive Impairment in the Elderly
Nov 09, 2021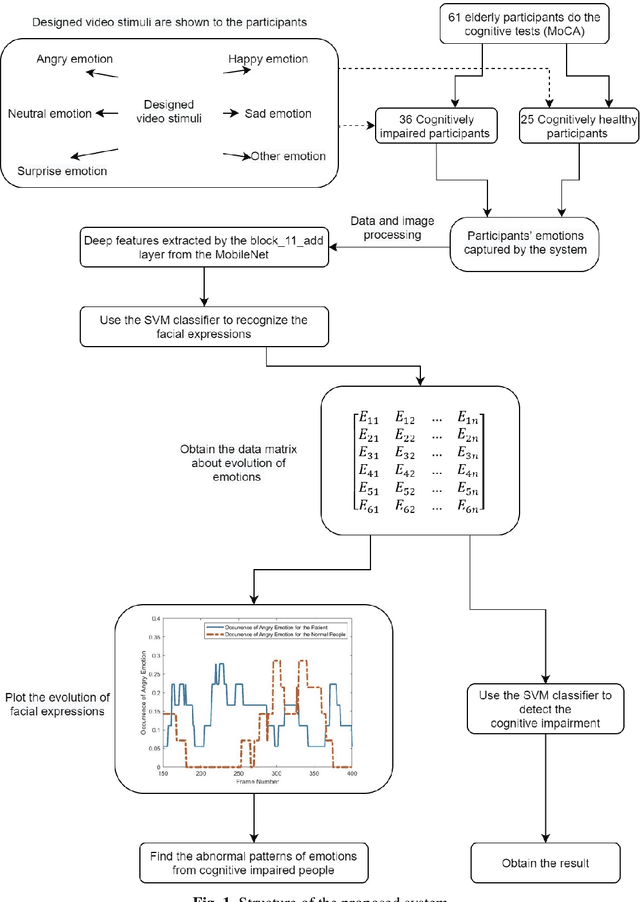
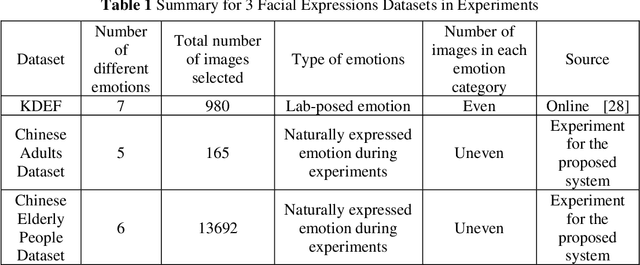
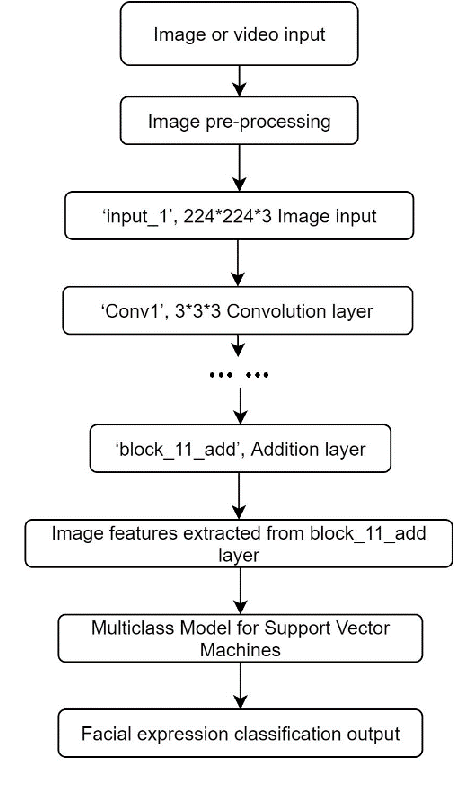
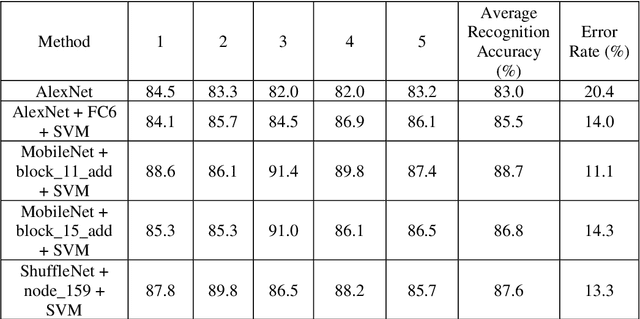
A significant number of people are suffering from cognitive impairment all over the world. Early detection of cognitive impairment is of great importance to both patients and caregivers. However, existing approaches have their shortages, such as time consumption and financial expenses involved in clinics and the neuroimaging stage. It has been found that patients with cognitive impairment show abnormal emotion patterns. In this paper, we present a novel deep convolution network-based system to detect the cognitive impairment through the analysis of the evolution of facial emotions while participants are watching designed video stimuli. In our proposed system, a novel facial expression recognition algorithm is developed using layers from MobileNet and Support Vector Machine (SVM), which showed satisfactory performance in 3 datasets. To verify the proposed system in detecting cognitive impairment, 61 elderly people including patients with cognitive impairment and healthy people as a control group have been invited to participate in the experiments and a dataset was built accordingly. With this dataset, the proposed system has successfully achieved the detection accuracy of 73.3%.
Design of a Smooth Landing Trajectory Tracking System for a Fixed-wing Aircraft
Jul 13, 2021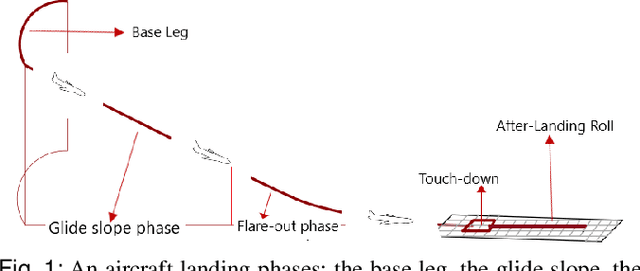
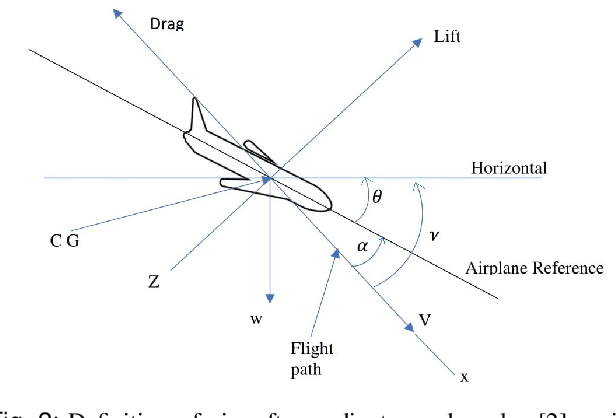
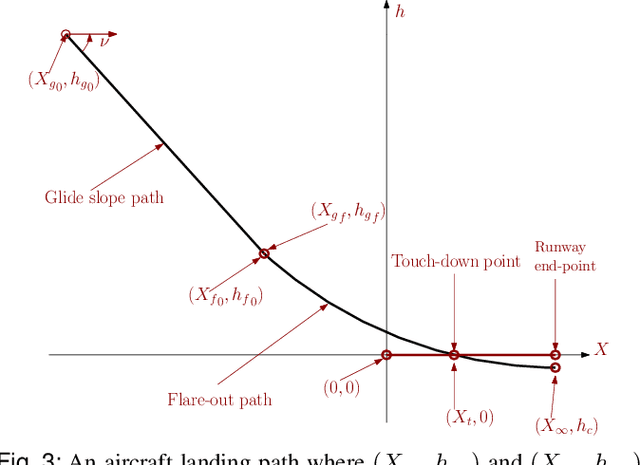
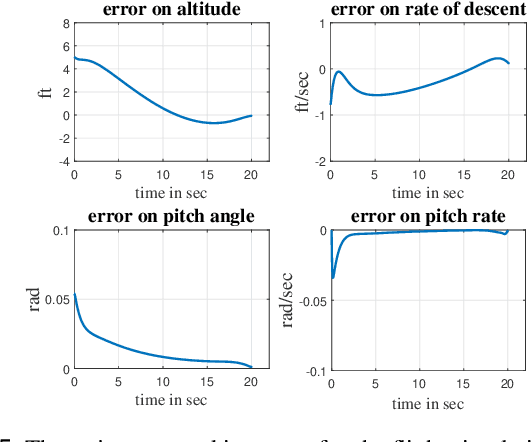
This paper presents a landing controller for a fixed-wing aircraft during the landing phase, ensuring the aircraft reaches the touchdown point smoothly. The landing problem is converted to a finite-time linear quadratic tracking (LQT) problem in which an aircraft needs to track the desired landing path in the longitudinal-vertical plane while satisfying performance requirements and flight constraints. First, we design a smooth trajectory that meets flight performance requirements and constraints. Then, an optimal controller is designed to minimize the tracking error, while landing the aircraft within the desired time frame. For this purpose, a linearized model of an aircraft developed under the assumption of a small flight path angle and a constant approach speed is used. The resulting Differential Riccati equation is solved backward in time using the Dormand Prince algorithm. Simulation results show a satisfactory tracking performance and the finite-time convergence of tracking errors for different initial conditions of the flare-out phase of landing.
Autonomous Blimp Control using Deep Reinforcement Learning
Sep 22, 2021

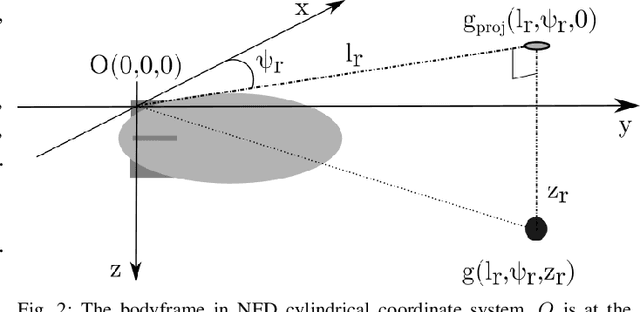

Aerial robot solutions are becoming ubiquitous for an increasing number of tasks. Among the various types of aerial robots, blimps are very well suited to perform long-duration tasks while being energy efficient, relatively silent and safe. To address the blimp navigation and control task, in our recent work, we have developed a software-in-the-loop simulation and a PID-based controller for large blimps in the presence of wind disturbance. However, blimps have a deformable structure and their dynamics are inherently non-linear and time-delayed, often resulting in large trajectory tracking errors. Moreover, the buoyancy of a blimp is constantly changing due to changes in the ambient temperature and pressure. In the present paper, we explore a deep reinforcement learning (DRL) approach to address these issues. We train only in simulation, while keeping conditions as close as possible to the real-world scenario. We derive a compact state representation to reduce the training time and a discrete action space to enforce control smoothness. Our initial results in simulation show a significant potential of DRL in solving the blimp control task and robustness against moderate wind and parameter uncertainty. Extensive experiments are presented to study the robustness of our approach. We also openly provide the source code of our approach.
An Energy-Efficient Edge Computing Paradigm for Convolution-based Image Upsampling
Jul 15, 2021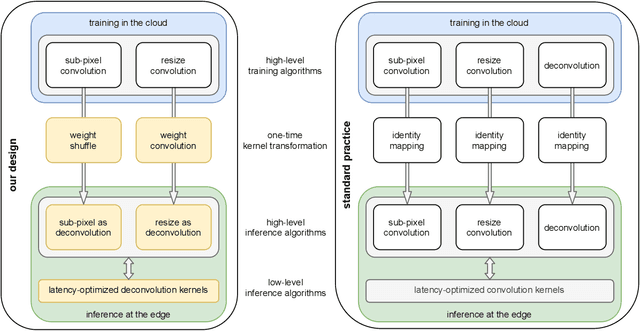

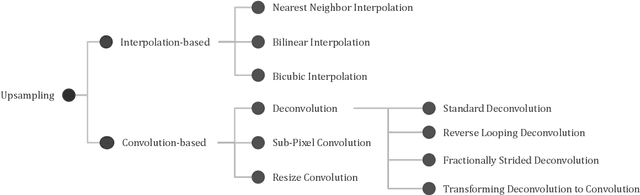

A novel energy-efficient edge computing paradigm is proposed for real-time deep learning-based image upsampling applications. State-of-the-art deep learning solutions for image upsampling are currently trained using either resize or sub-pixel convolution to learn kernels that generate high fidelity images with minimal artifacts. However, performing inference with these learned convolution kernels requires memory-intensive feature map transformations that dominate time and energy costs in real-time applications. To alleviate this pressure on memory bandwidth, we confine the use of resize or sub-pixel convolution to training in the cloud by transforming learned convolution kernels to deconvolution kernels before deploying them for inference as a functionally equivalent deconvolution. These kernel transformations, intended as a one-time cost when shifting from training to inference, enable a systems designer to use each algorithm in their optimal context by preserving the image fidelity learned when training in the cloud while minimizing data transfer penalties during inference at the edge. We also explore existing variants of deconvolution inference algorithms and introduce a novel variant for consideration. We analyze and compare the inference properties of convolution-based upsampling algorithms using a quantitative model of incurred time and energy costs and show that using deconvolution for inference at the edge improves both system latency and energy efficiency when compared to their sub-pixel or resize convolution counterparts.
A Machine-learning Based Initialization for Joint Statistical Iterative Dual-energy CT with Application to Proton Therapy
Jul 30, 2021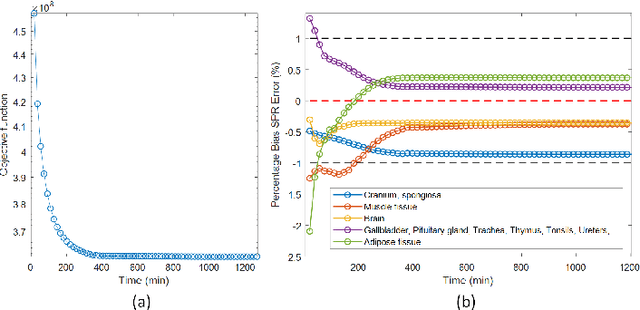
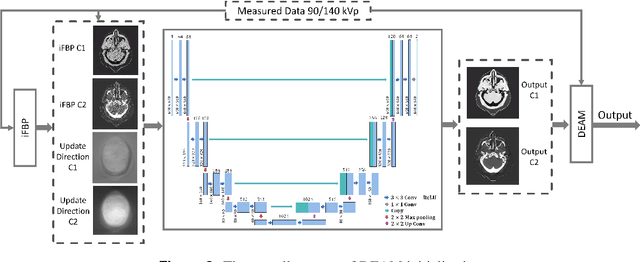
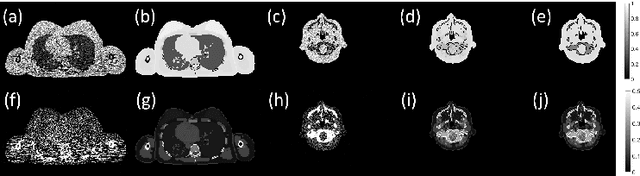
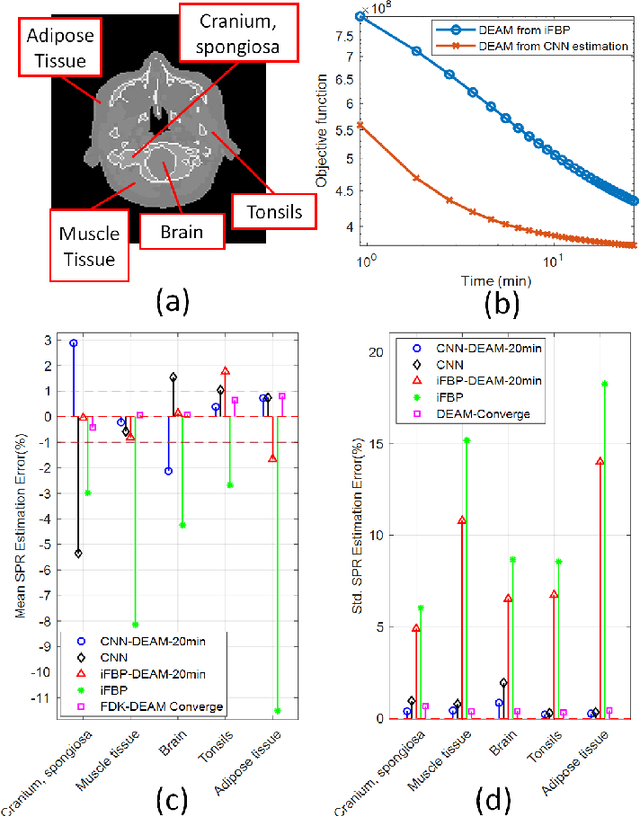
Dual-energy CT (DECT) has been widely investigated to generate more informative and more accurate images in the past decades. For example, Dual-Energy Alternating Minimization (DEAM) algorithm achieves sub-percentage uncertainty in estimating proton stopping-power mappings from experimental 3-mm collimated phantom data. However, elapsed time of iterative DECT algorithms is not clinically acceptable, due to their low convergence rate and the tremendous geometry of modern helical CT scanners. A CNN-based initialization method is introduced to reduce the computational time of iterative DECT algorithms. DEAM is used as an example of iterative DECT algorithms in this work. The simulation results show that our method generates denoised images with greatly improved estimation accuracy for adipose, tonsils, and muscle tissue. Also, it reduces elapsed time by approximately 5-fold for DEAM to reach the same objective function value for both simulated and real data.
Towards an Efficient Semantic Segmentation Method of ID Cards for Verification Systems
Nov 24, 2021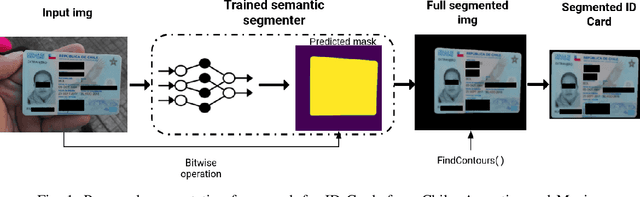

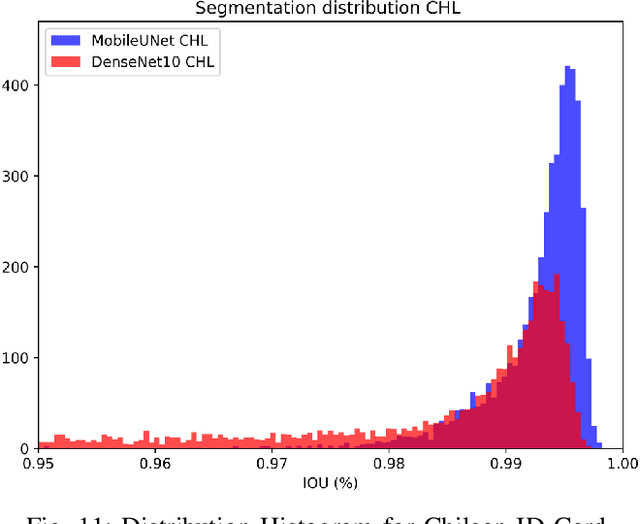
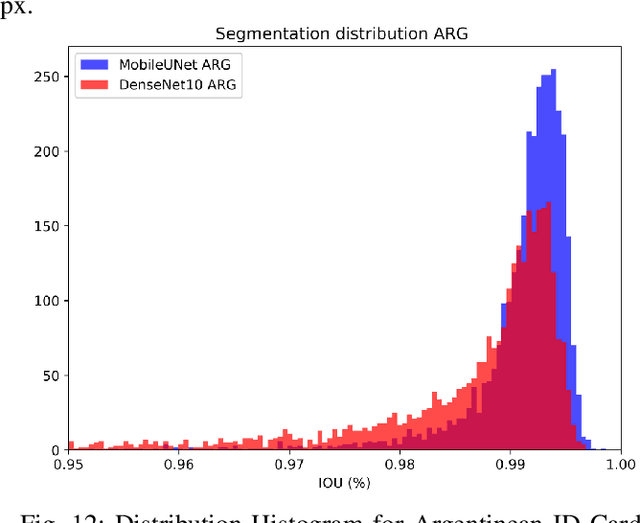
Removing the background in ID Card images is a real challenge for remote verification systems because many of the re-digitalised images present cluttered backgrounds, poor illumination conditions, distortion and occlusions. The background in ID Card images confuses the classifiers and the text extraction. Due to the lack of available images for research, this field represents an open problem in computer vision today. This work proposes a method for removing the background using semantic segmentation of ID Cards. In the end, images captured in the wild from the real operation, using a manually labelled dataset consisting of 45,007 images, with five types of ID Cards from three countries (Chile, Argentina and Mexico), including typical presentation attack scenarios, were used. This method can help to improve the following stages in a regular identity verification or document tampering detection system. Two Deep Learning approaches were explored, based on MobileUNet and DenseNet10. The best results were obtained using MobileUNet, with 6.5 million parameters. A Chilean ID Card's mean Intersection Over Union (IoU) was 0.9926 on a private test dataset of 4,988 images. The best results for the fused multi-country dataset of ID Card images from Chile, Argentina and Mexico reached an IoU of 0.9911. The proposed methods are lightweight enough to be used in real-time operation on mobile devices.
TinyDefectNet: Highly Compact Deep Neural Network Architecture for High-Throughput Manufacturing Visual Quality Inspection
Nov 29, 2021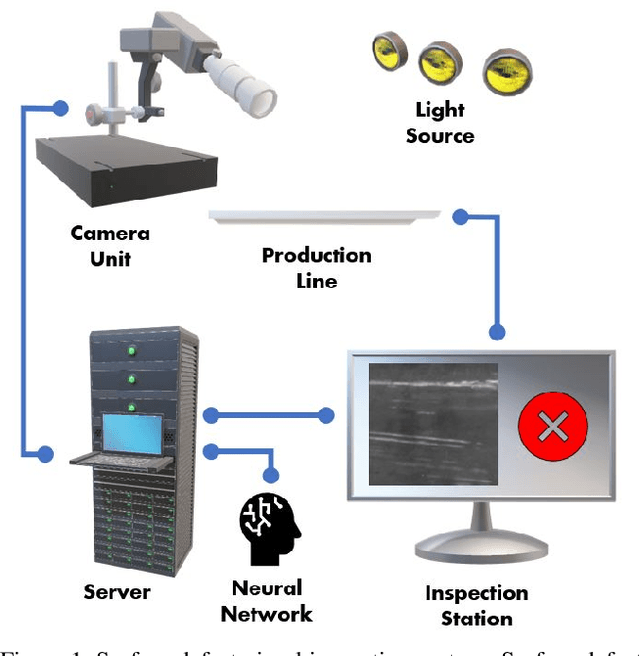
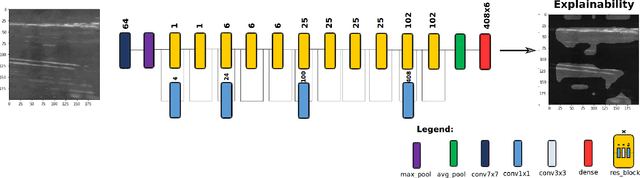

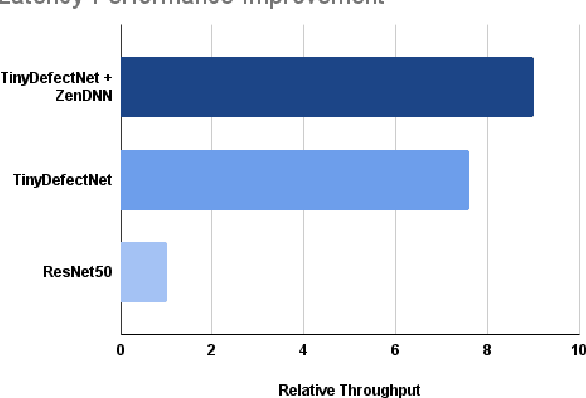
A critical aspect in the manufacturing process is the visual quality inspection of manufactured components for defects and flaws. Human-only visual inspection can be very time-consuming and laborious, and is a significant bottleneck especially for high-throughput manufacturing scenarios. Given significant advances in the field of deep learning, automated visual quality inspection can lead to highly efficient and reliable detection of defects and flaws during the manufacturing process. However, deep learning-driven visual inspection methods often necessitate significant computational resources, thus limiting throughput and act as a bottleneck to widespread adoption for enabling smart factories. In this study, we investigated the utilization of a machine-driven design exploration approach to create TinyDefectNet, a highly compact deep convolutional network architecture tailored for high-throughput manufacturing visual quality inspection. TinyDefectNet comprises of just ~427K parameters and has a computational complexity of ~97M FLOPs, yet achieving a detection accuracy of a state-of-the-art architecture for the task of surface defect detection on the NEU defect benchmark dataset. As such, TinyDefectNet can achieve the same level of detection performance at 52$\times$ lower architectural complexity and 11x lower computational complexity. Furthermore, TinyDefectNet was deployed on an AMD EPYC 7R32, and achieved 7.6x faster throughput using the native Tensorflow environment and 9x faster throughput using AMD ZenDNN accelerator library. Finally, explainability-driven performance validation strategy was conducted to ensure correct decision-making behaviour was exhibited by TinyDefectNet to improve trust in its usage by operators and inspectors.
Improving Spectral Clustering Using Spectrum-Preserving Node Reduction
Oct 24, 2021

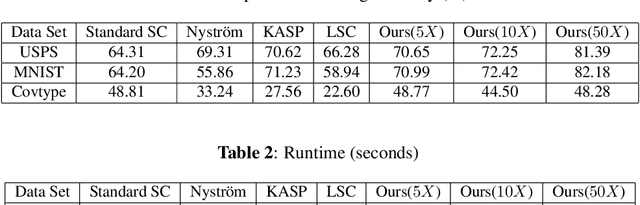
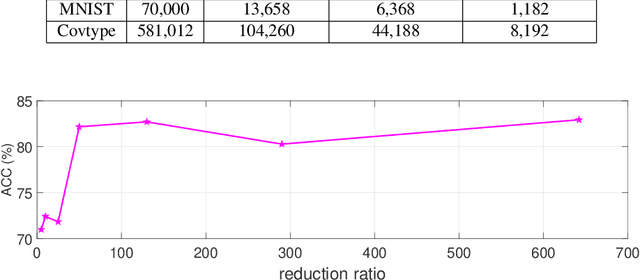
Spectral clustering is one of the most popular clustering methods. However, the high computational cost due to the involved eigen-decomposition procedure can immediately hinder its applications in large-scale tasks. In this paper we use spectrum-preserving node reduction to accelerate eigen-decomposition and generate concise representations of data sets. Specifically, we create a small number of pseudonodes based on spectral similarity. Then, standard spectral clustering algorithm is performed on the smaller node set. Finally, each data point in the original data set is assigned to the cluster as its representative pseudo-node. The proposed framework run in nearly-linear time. Meanwhile, the clustering accuracy can be significantly improved by mining concise representations. The experimental results show dramatically improved clustering performance when compared with state-of-the-art methods.