 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Optimized Deployment of Unmanned Aerial Vehicles for Wildfire Detection and Monitoring
Nov 21, 2021
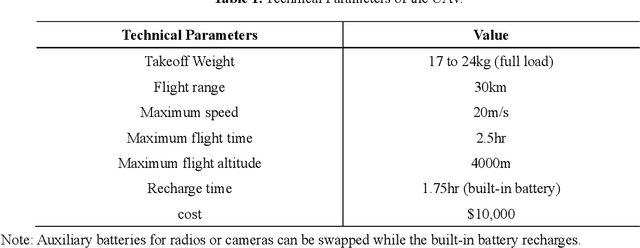

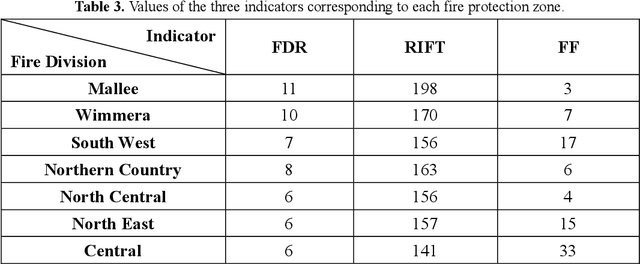
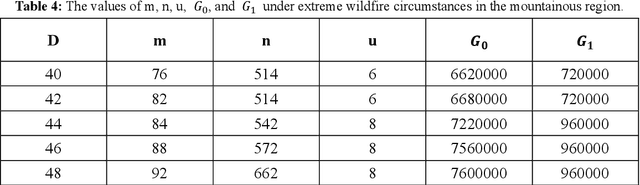
In recent years, increased wildfires have caused irreversible damage to forest resources worldwide, threatening wildlives and human living conditions. The lack of accurate frontline information in real-time can pose great risks to firefighters. Though a plethora of machine learning algorithms have been developed to detect wildfires using aerial images and videos captured by drones, there is a lack of methods corresponding to drone deployment. We propose a wildfire rapid response system that optimizes the number and relative positions of drones to achieve full coverage of the whole wildfire area. Trained on the data from historical wildfire events, our model evaluates the possibility of wildfires at different scales and accordingly allocates the resources. It adopts plane geometry to deploy drones while balancing the capability and safety with inequality constrained nonlinear programming. The method can flexibly adapt to different terrains and the dynamic extension of the wildfire area. Lastly, the operation cost under extreme wildfire circumstances can be assessed upon the completion of the deployment. We applied our model to the wildfire data collected from eastern Victoria, Australia, and demonstrated its great potential in the real world.
The Neural Correlates of Image Texture in the Human Vision Using Magnetoencephalography
Nov 16, 2021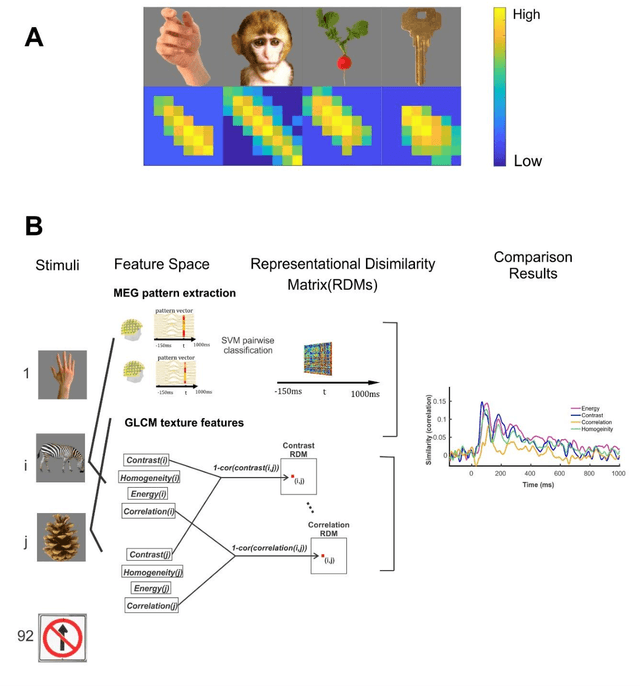
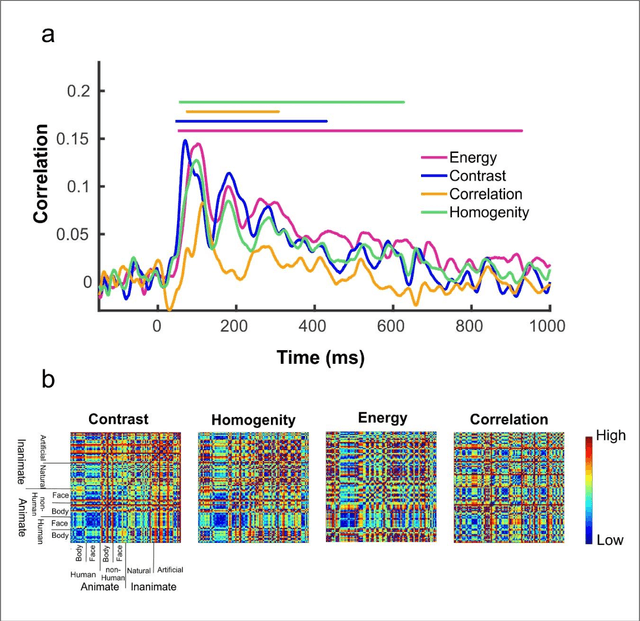
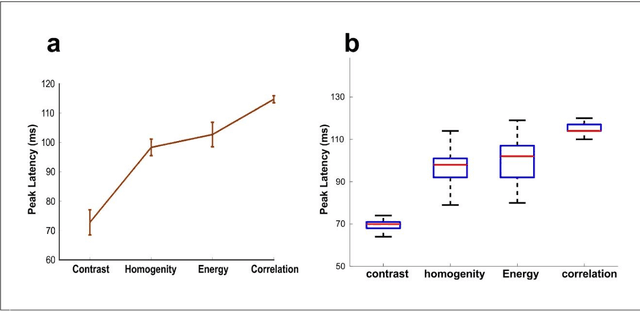
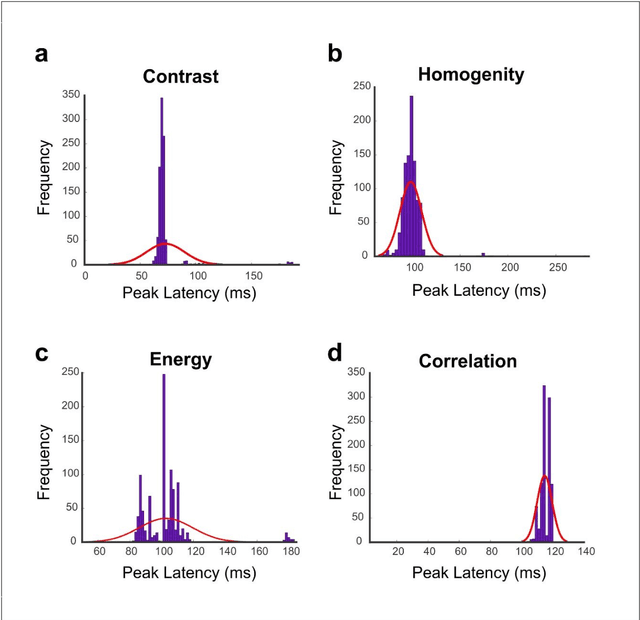
Undoubtedly, textural property of an image is one of the most important features in object recognition task in both human and computer vision applications. Here, we investigated the neural signatures of four well-known statistical texture features including contrast, homogeneity, energy, and correlation computed from the gray level co-occurrence matrix (GLCM) of the images viewed by the participants in the process of magnetoencephalography (MEG) data collection. To trace these features in the human visual system, we used multivariate pattern analysis (MVPA) and trained a linear support vector machine (SVM) classifier on every timepoint of MEG data representing the brain activity and compared it with the textural descriptors of images using the Spearman correlation. The result of this study demonstrates that hierarchical structure in the processing of these four texture descriptors in the human brain with the order of contrast, homogeneity, energy, and correlation. Additionally, we found that energy, which carries broad texture property of the images, shows a more sustained statistically meaningful correlation with the brain activity in the course of time.
Map Enhanced Route Travel Time Prediction using Deep Neural Networks
Nov 06, 2019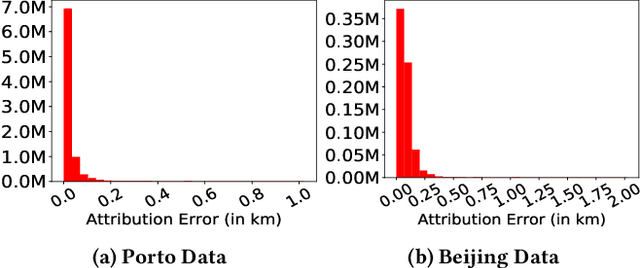
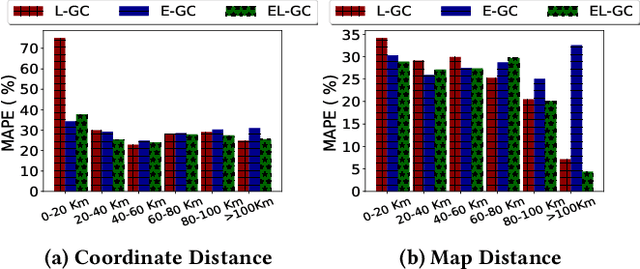
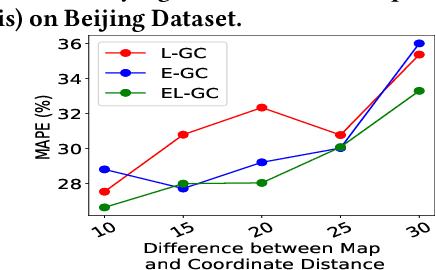
Travel time estimation is a fundamental problem in transportation science with extensive literature. The study of these techniques has intensified due to availability of many publicly available large trip datasets. Recently developed deep learning based models have improved the generality and performance and have focused on estimating times for individual sub-trajectories and aggregating them to predict the travel time of the entire trajectory. However, these techniques ignore the road network information. In this work, we propose and study techniques for incorporating road networks along with historical trips' data into travel time prediction. We incorporate both node embeddings as well as road distance into the existing model. Experiments on large real-world benchmark datasets suggest improved performance, especially when the train data is small. As expected, the proposed method performs better than the baseline when there is a larger difference between road distance and Vincenty distance between start and end points.
An AO-ADMM approach to constraining PARAFAC2 on all modes
Oct 04, 2021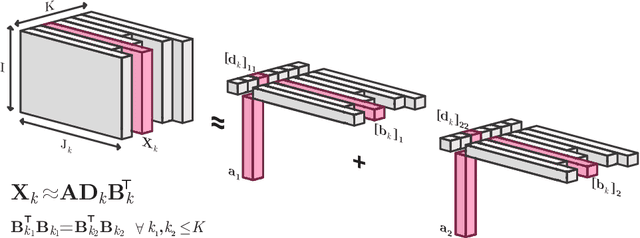
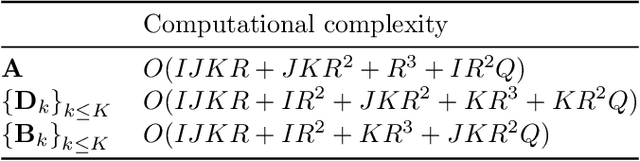

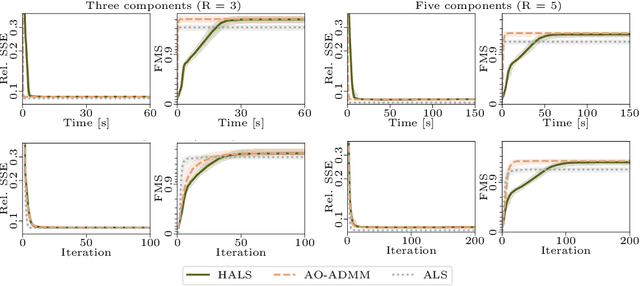
Analyzing multi-way measurements with variations across one mode of the dataset is a challenge in various fields including data mining, neuroscience and chemometrics. For example, measurements may evolve over time or have unaligned time profiles. The PARAFAC2 model has been successfully used to analyze such data by allowing the underlying factor matrices in one mode (i.e., the evolving mode) to change across slices. The traditional approach to fit a PARAFAC2 model is to use an alternating least squares-based algorithm, which handles the constant cross-product constraint of the PARAFAC2 model by implicitly estimating the evolving factor matrices. This approach makes imposing regularization on these factor matrices challenging. There is currently no algorithm to flexibly impose such regularization with general penalty functions and hard constraints. In order to address this challenge and to avoid the implicit estimation, in this paper, we propose an algorithm for fitting PARAFAC2 based on alternating optimization with the alternating direction method of multipliers (AO-ADMM). With numerical experiments on simulated data, we show that the proposed PARAFAC2 AO-ADMM approach allows for flexible constraints, recovers the underlying patterns accurately, and is computationally efficient compared to the state-of-the-art. We also apply our model to a real-world chromatography dataset, and show that constraining the evolving mode improves the interpretability of the extracted patterns.
Effectiveness of Detection-based and Regression-based Approaches for Estimating Mask-Wearing Ratio
Dec 01, 2021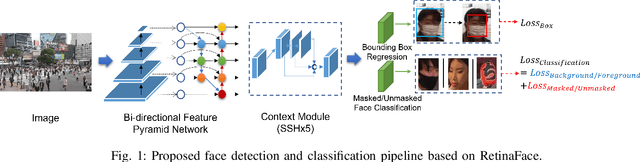
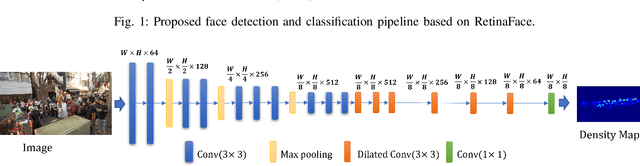

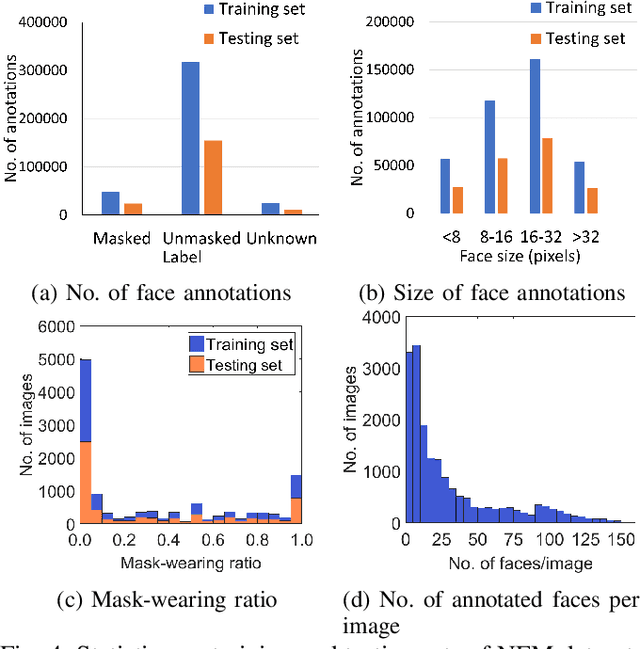
Estimating the mask-wearing ratio in public places is important as it enables health authorities to promptly analyze and implement policies. Methods for estimating the mask-wearing ratio on the basis of image analysis have been reported. However, there is still a lack of comprehensive research on both methodologies and datasets. Most recent reports straightforwardly propose estimating the ratio by applying conventional object detection and classification methods. It is feasible to use regression-based approaches to estimate the number of people wearing masks, especially for congested scenes with tiny and occluded faces, but this has not been well studied. A large-scale and well-annotated dataset is still in demand. In this paper, we present two methods for ratio estimation that leverage either a detection-based or regression-based approach. For the detection-based approach, we improved the state-of-the-art face detector, RetinaFace, used to estimate the ratio. For the regression-based approach, we fine-tuned the baseline network, CSRNet, used to estimate the density maps for masked and unmasked faces. We also present the first large-scale dataset, the ``NFM dataset,'' which contains 581,108 face annotations extracted from 18,088 video frames in 17 street-view videos. Experiments demonstrated that the RetinaFace-based method has higher accuracy under various situations and that the CSRNet-based method has a shorter operation time thanks to its compactness.
Deep Learning and Statistical Models for Time-Critical Pedestrian Behaviour Prediction
Feb 26, 2020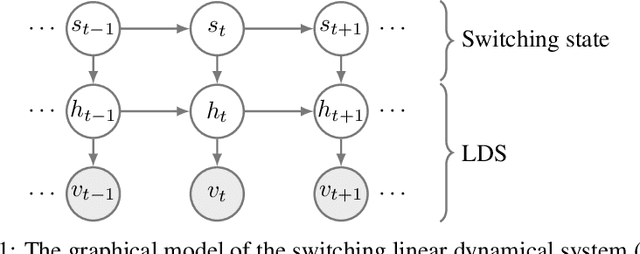
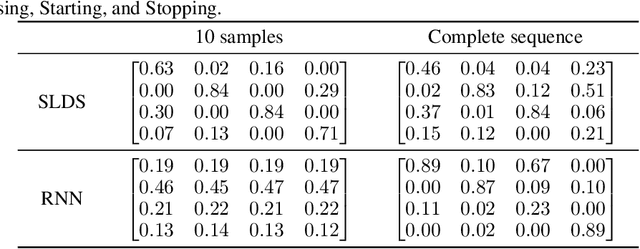
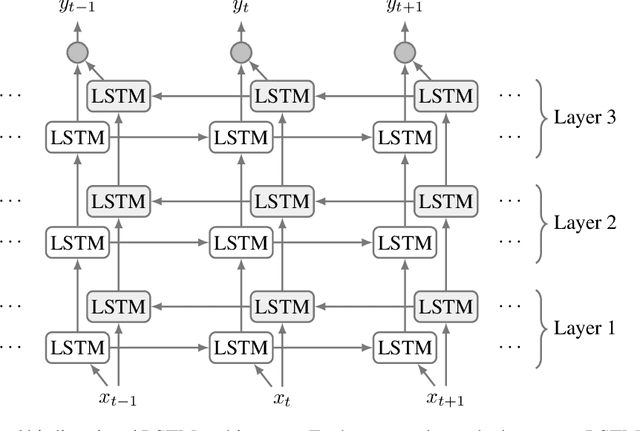
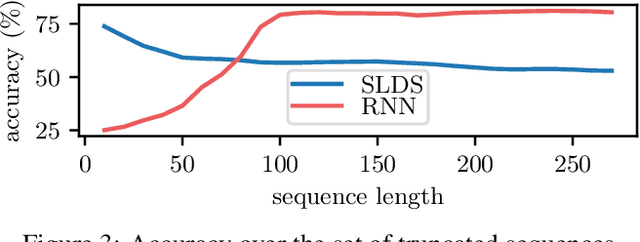
The time it takes for a classifier to make an accurate prediction can be crucial in many behaviour recognition problems. For example, an autonomous vehicle should detect hazardous pedestrian behaviour early enough for it to take appropriate measures. In this context, we compare the switching linear dynamical system (SLDS) and a three-layered bi-directional long short-term memory (LSTM) neural network, which are applied to infer pedestrian behaviour from motion tracks. We show that, though the neural network model achieves an accuracy of 80%, it requires long sequences to achieve this (100 samples or more). The SLDS, has a lower accuracy of 74%, but it achieves this result with short sequences (10 samples). To our knowledge, such a comparison on sequence length has not been considered in the literature before. The results provide a key intuition of the suitability of the models in time-critical problems.
A Quantum Generative Adversarial Network for distributions
Oct 04, 2021Generative Adversarial Networks are becoming a fundamental tool in Machine Learning, in particular in the context of improving the stability of deep neural networks. At the same time, recent advances in Quantum Computing have shown that, despite the absence of a fault-tolerant quantum computer so far, quantum techniques are providing exponential advantage over their classical counterparts. We develop a fully connected Quantum Generative Adversarial network and show how it can be applied in Mathematical Finance, with a particular focus on volatility modelling.
A Framework for Automatic Monitoring of Norms that regulate Time Constrained Actions
May 01, 2021This paper addresses the problem of proposing a model of norms and a framework for automatically computing their violation or fulfilment. The proposed T-NORM model can be used to express abstract norms able to regulate classes of actions that should or should not be performed in a temporal interval. We show how the model can be used to formalize obligations and prohibitions and for inhibiting them by introducing permissions and exemptions. The basic building blocks for norm specification consists of rules with suitably nested components. The activation condition, the regulated actions, and the temporal constrains of norms are specified using the W3C Web Ontology Language (OWL 2). Thanks to this choice, it is possible to use OWL reasoning for computing the effects that the logical implication between actions has on norms fulfilment or violation. The operational semantics of the T-NORM model is specified by providing an unambiguous procedure for translating every norm and every exception into production rules.
Independent SE(3)-Equivariant Models for End-to-End Rigid Protein Docking
Nov 15, 2021



Protein complex formation is a central problem in biology, being involved in most of the cell's processes, and essential for applications, e.g. drug design or protein engineering. We tackle rigid body protein-protein docking, i.e., computationally predicting the 3D structure of a protein-protein complex from the individual unbound structures, assuming no conformational change within the proteins happens during binding. We design a novel pairwise-independent SE(3)-equivariant graph matching network to predict the rotation and translation to place one of the proteins at the right docked position relative to the second protein. We mathematically guarantee a basic principle: the predicted complex is always identical regardless of the initial locations and orientations of the two structures. Our model, named EquiDock, approximates the binding pockets and predicts the docking poses using keypoint matching and alignment, achieved through optimal transport and a differentiable Kabsch algorithm. Empirically, we achieve significant running time improvements and often outperform existing docking software despite not relying on heavy candidate sampling, structure refinement, or templates.
Confounder Identification-free Causal Visual Feature Learning
Nov 26, 2021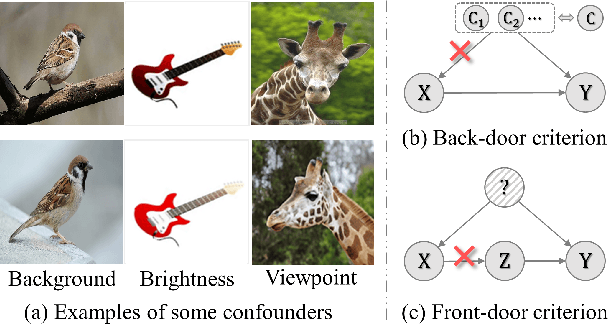
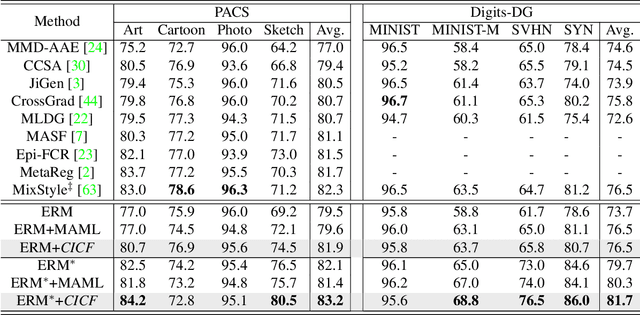
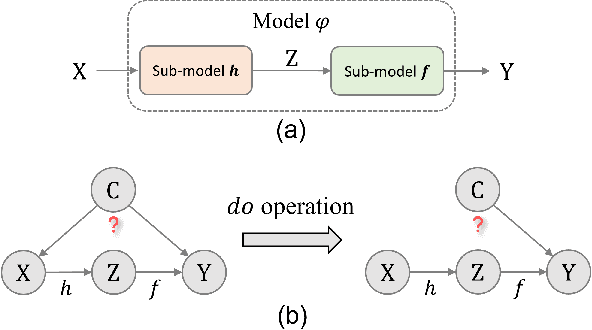
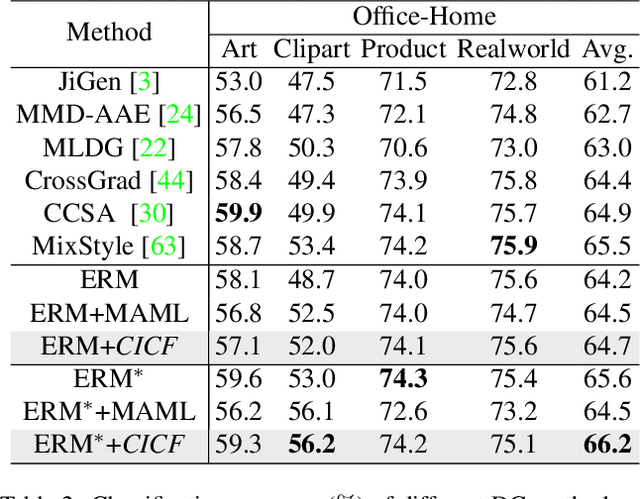
Confounders in deep learning are in general detrimental to model's generalization where they infiltrate feature representations. Therefore, learning causal features that are free of interference from confounders is important. Most previous causal learning based approaches employ back-door criterion to mitigate the adverse effect of certain specific confounder, which require the explicit identification of confounder. However, in real scenarios, confounders are typically diverse and difficult to be identified. In this paper, we propose a novel Confounder Identification-free Causal Visual Feature Learning (CICF) method, which obviates the need for identifying confounders. CICF models the interventions among different samples based on front-door criterion, and then approximates the global-scope intervening effect upon the instance-level interventions from the perspective of optimization. In this way, we aim to find a reliable optimization direction, which avoids the intervening effects of confounders, to learn causal features. Furthermore, we uncover the relation between CICF and the popular meta-learning strategy MAML, and provide an interpretation of why MAML works from the theoretical perspective of causal learning for the first time. Thanks to the effective learning of causal features, our CICF enables models to have superior generalization capability. Extensive experiments on domain generalization benchmark datasets demonstrate the effectiveness of our CICF, which achieves the state-of-the-art performance.