 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Recurrent Space-time Graphs for Video Understanding
Apr 11, 2019
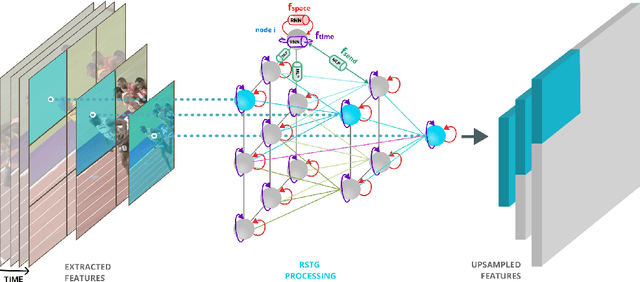
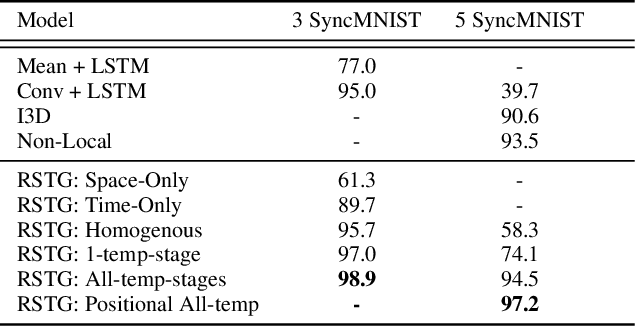
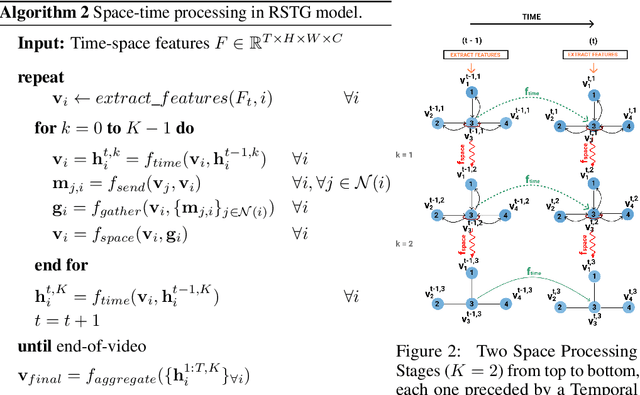
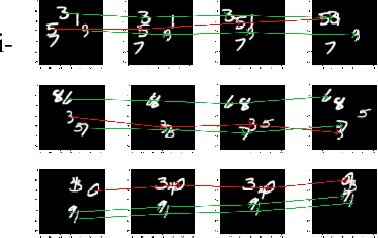
Visual learning in the space-time domain remains a very challenging problem in artificial intelligence. Current computational models for understanding video data are heavily rooted in the classical single-image based paradigm. It is not yet well understood how to integrate visual information from space and time into a single, general model. We propose a neural graph model, recurrent in space and time, suitable for capturing both the appearance and the complex interactions of different entities and objects within the changing world scene. Nodes and links in our graph have dedicated neural networks for processing information. Edges process messages between connected nodes at different locations and scales or between past and present time. Nodes compute over features extracted from local parts in space and time and over messages received from their neighbours and previous memory states. Messages are passed iteratively in order to transmit information globally and establish long range interactions. Our model is general and could learn to recognize a variety of high level spatio-temporal concepts and be applied to different learning tasks. We demonstrate, through extensive experiments, a competitive performance over strong baselines on the tasks of recognizing complex patterns of movement in video.
A First-Occupancy Representation for Reinforcement Learning
Oct 06, 2021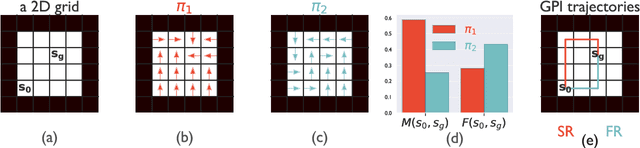
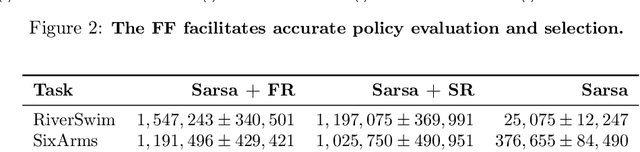
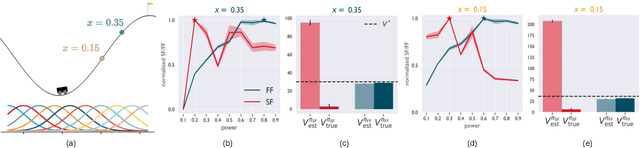
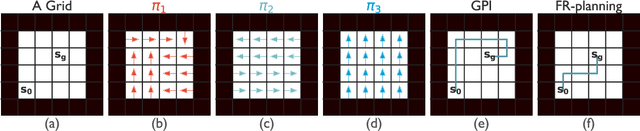
Both animals and artificial agents benefit from state representations that support rapid transfer of learning across tasks and which enable them to efficiently traverse their environments to reach rewarding states. The successor representation (SR), which measures the expected cumulative, discounted state occupancy under a fixed policy, enables efficient transfer to different reward structures in an otherwise constant Markovian environment and has been hypothesized to underlie aspects of biological behavior and neural activity. However, in the real world, rewards may move or only be available for consumption once, may shift location, or agents may simply aim to reach goal states as rapidly as possible without the constraint of artificially imposed task horizons. In such cases, the most behaviorally-relevant representation would carry information about when the agent was likely to first reach states of interest, rather than how often it should expect to visit them over a potentially infinite time span. To reflect such demands, we introduce the first-occupancy representation (FR), which measures the expected temporal discount to the first time a state is accessed. We demonstrate that the FR facilitates exploration, the selection of efficient paths to desired states, allows the agent, under certain conditions, to plan provably optimal trajectories defined by a sequence of subgoals, and induces similar behavior to animals avoiding threatening stimuli.
Three-Way Deep Neural Network for Radio Frequency Map Generation and Source Localization
Nov 23, 2021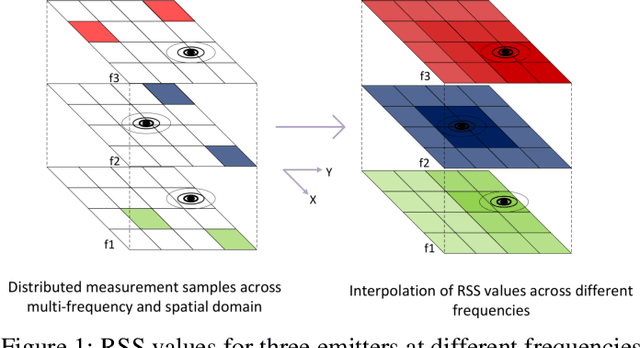
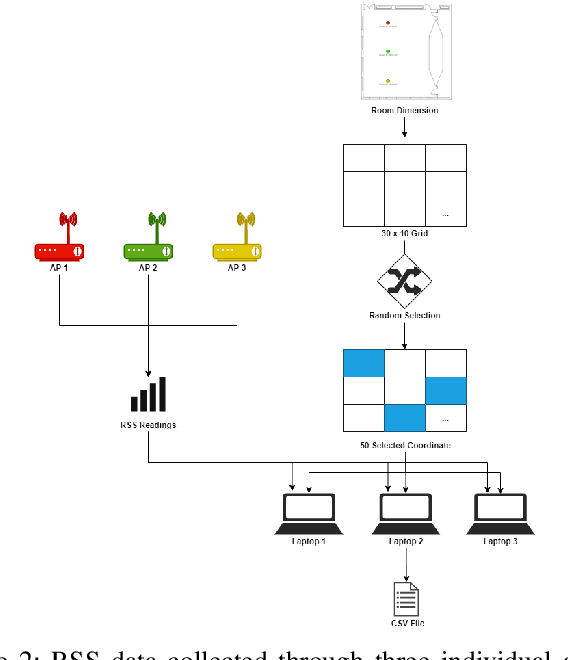
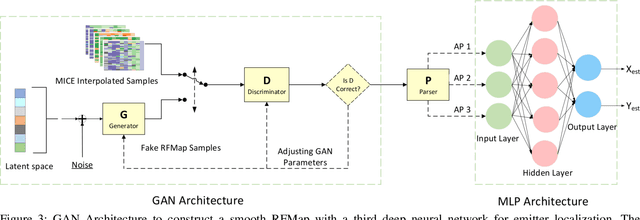
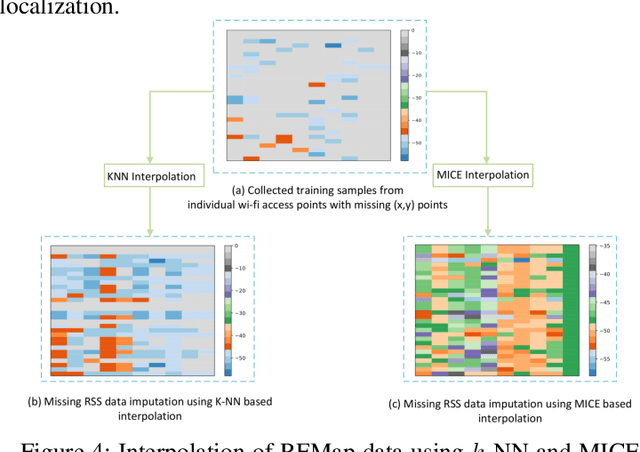
In this paper, we present a Generative Adversarial Network (GAN) machine learning model to interpolate irregularly distributed measurements across the spatial domain to construct a smooth radio frequency map (RFMap) and then perform localization using a deep neural network. Monitoring wireless spectrum over spatial, temporal, and frequency domains will become a critical feature in facilitating dynamic spectrum access (DSA) in beyond-5G and 6G communication technologies. Localization, wireless signal detection, and spectrum policy-making are several of the applications where distributed spectrum sensing will play a significant role. Detection and positioning of wireless emitters is a very challenging task in a large spectral and spatial area. In order to construct a smooth RFMap database, a large number of measurements are required which can be very expensive and time consuming. One approach to help realize these systems is to collect finite localized measurements across a given area and then interpolate the measurement values to construct the database. Current methods in the literature employ channel modeling to construct the radio frequency map, which lacks the granularity for accurate localization whereas our proposed approach reconstructs a new generalized RFMap. Localization results are presented and compared with conventional channel models.
Multilingual training for Software Engineering
Dec 03, 2021
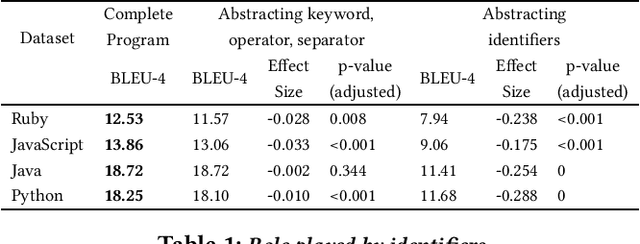
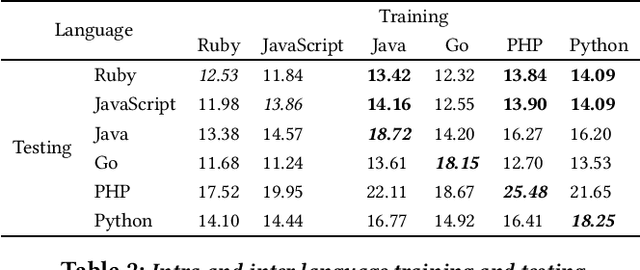

Well-trained machine-learning models, which leverage large amounts of open-source software data, have now become an interesting approach to automating many software engineering tasks. Several SE tasks have all been subject to this approach, with performance gradually improving over the past several years with better models and training methods. More, and more diverse, clean, labeled data is better for training; but constructing good-quality datasets is time-consuming and challenging. Ways of augmenting the volume and diversity of clean, labeled data generally have wide applicability. For some languages (e.g., Ruby) labeled data is less abundant; in others (e.g., JavaScript) the available data maybe more focused on some application domains, and thus less diverse. As a way around such data bottlenecks, we present evidence suggesting that human-written code in different languages (which performs the same function), is rather similar, and particularly preserving of identifier naming patterns; we further present evidence suggesting that identifiers are a very important element of training data for software engineering tasks. We leverage this rather fortuitous phenomenon to find evidence that available multilingual training data (across different languages) can be used to amplify performance. We study this for 3 different tasks: code summarization, code retrieval, and function naming. We note that this data-augmenting approach is broadly compatible with different tasks, languages, and machine-learning models.
End-to-end training of time domain audio separation and recognition
Dec 25, 2019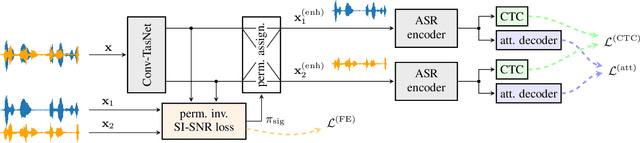


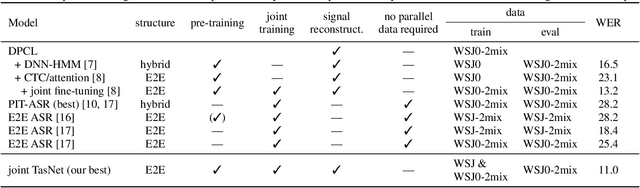
The rising interest in single-channel multi-speaker speech separation sparked development of End-to-End (E2E) approaches to multi-speaker speech recognition. However, up until now, state-of-the-art neural network-based time domain source separation has not yet been combined with E2E speech recognition. We here demonstrate how to combine a separation module based on a Convolutional Time domain Audio Separation Network (Conv-TasNet) with an E2E speech recognizer and how to train such a model jointly by distributing it over multiple GPUs or by approximating truncated back-propagation for the convolutional front-end. To put this work into perspective and illustrate the complexity of the design space, we provide a compact overview of single-channel multi-speaker recognition systems. Our experiments show a word error rate of 11.0% on WSJ0-2mix and indicate that our joint time domain model can yield substantial improvements over cascade DNN-HMM and monolithic E2E frequency domain systems proposed so far.
Active Bayesian Multi-class Mapping from Range and Semantic Segmentation Observations
Dec 08, 2021
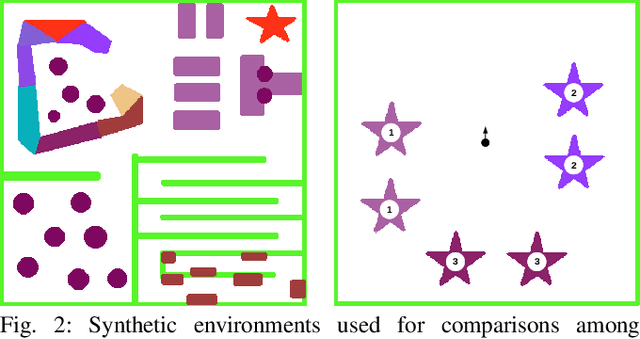
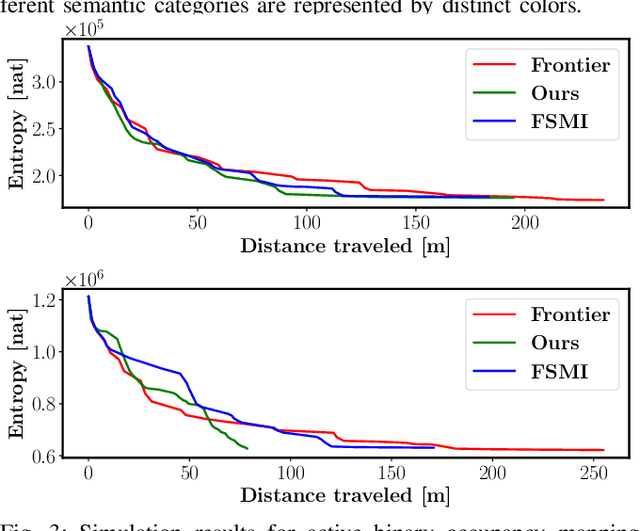
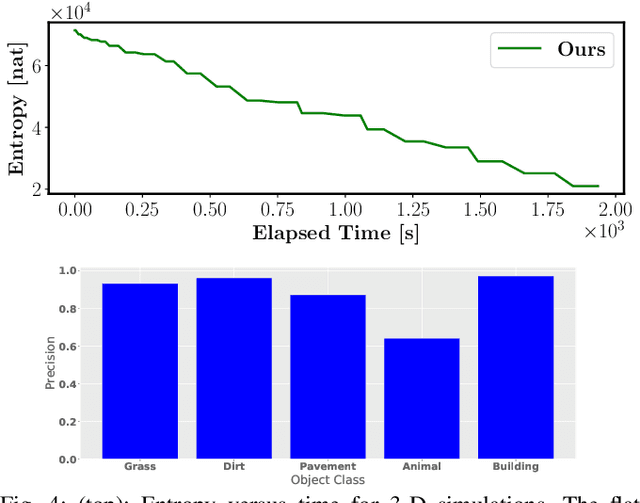
The demand for robot exploration in unstructured and unknown environments has recently grown substantially thanks to the host of inexpensive sensing and edge-computing solutions. In order to come closer to full autonomy, robots need to process the measurement stream in real-time, which calls for efficient exploration strategies. Information-based exploration techniques, such as Cauchy-Schwarz quadratic mutual information (CSQMI) and fast Shannon mutual information (FSMI), have successfully achieved active binary occupancy mapping with range measurements. However, as we envision robots performing complex tasks specified with semantically meaningful objects, it is necessary to capture semantic categories in the measurements, map representation, and exploration objective. In this work we propose a Bayesian multi-class mapping algorithm utilizing range-category measurements, as well as a closed-form efficiently computable lower bound for the Shannon mutual information between the multi-class map and the measurements. The bound allows rapid evaluation of many potential robot trajectories for autonomous exploration and mapping. Furthermore, we develop a compressed representation of 3-D environments with semantic labels based on OcTree data structure, where each voxel maintains a categorical distribution over object classes. The proposed 3-D representation facilitates fast computation of Shannon mutual information between the semantic Octomap and the measurements using Run-Length Encoding (RLE) of range-category observation rays. We compare our method against frontier-based and FSMI exploration and apply it in a variety of simulated and real-world experiments.
Echocardiography Segmentation with Enforced Temporal Consistency
Dec 03, 2021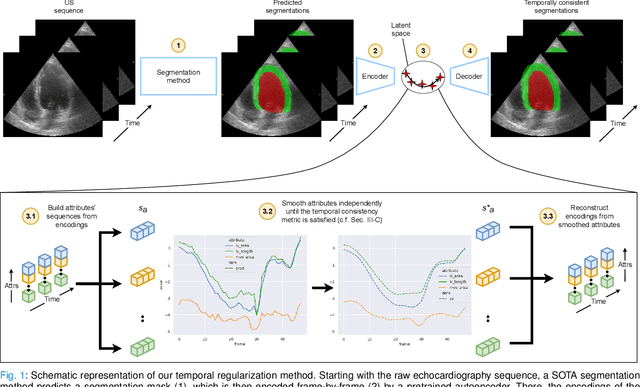
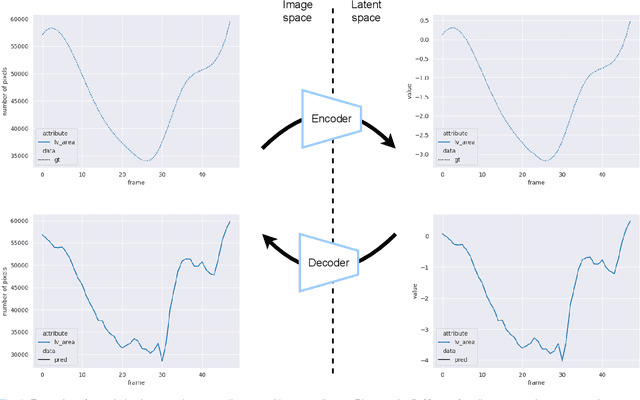

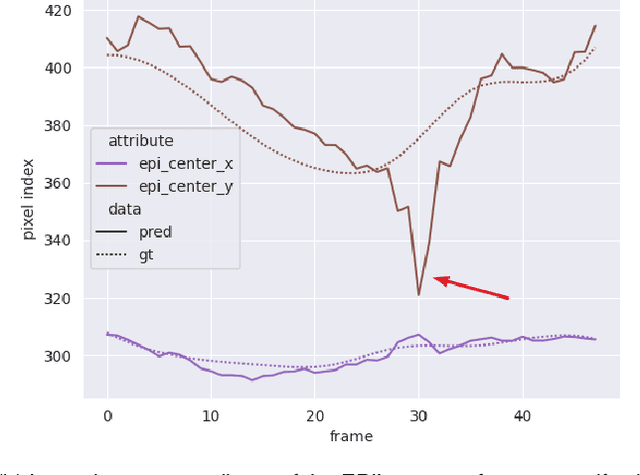
Convolutional neural networks (CNN) have demonstrated their ability to segment 2D cardiac ultrasound images. However, despite recent successes according to which the intra-observer variability on end-diastole and end-systole images has been reached, CNNs still struggle to leverage temporal information to provide accurate and temporally consistent segmentation maps across the whole cycle. Such consistency is required to accurately describe the cardiac function, a necessary step in diagnosing many cardiovascular diseases. In this paper, we propose a framework to learn the 2D+time long-axis cardiac shape such that the segmented sequences can benefit from temporal and anatomical consistency constraints. Our method is a post-processing that takes as input segmented echocardiographic sequences produced by any state-of-the-art method and processes it in two steps to (i) identify spatio-temporal inconsistencies according to the overall dynamics of the cardiac sequence and (ii) correct the inconsistencies. The identification and correction of cardiac inconsistencies relies on a constrained autoencoder trained to learn a physiologically interpretable embedding of cardiac shapes, where we can both detect and fix anomalies. We tested our framework on 98 full-cycle sequences from the CAMUS dataset, which will be rendered public alongside this paper. Our temporal regularization method not only improves the accuracy of the segmentation across the whole sequences, but also enforces temporal and anatomical consistency.
Survey on English Entity Linking on Wikidata
Dec 03, 2021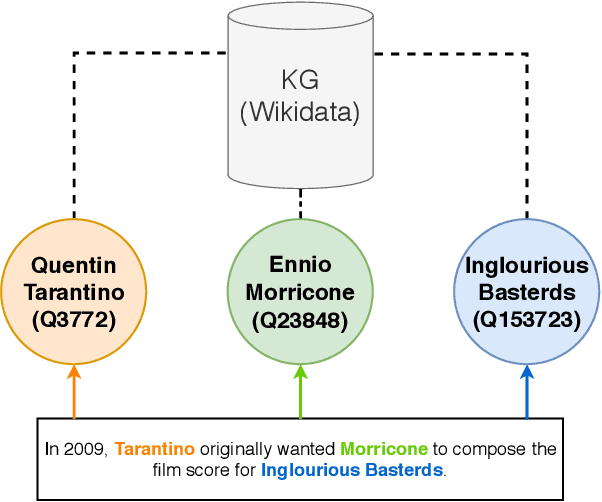

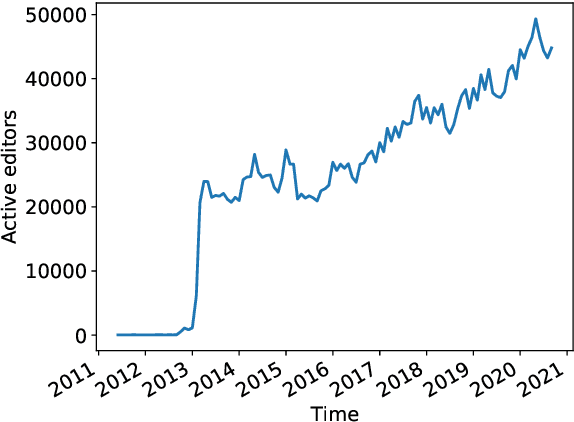
Wikidata is a frequently updated, community-driven, and multilingual knowledge graph. Hence, Wikidata is an attractive basis for Entity Linking, which is evident by the recent increase in published papers. This survey focuses on four subjects: (1) Which Wikidata Entity Linking datasets exist, how widely used are they and how are they constructed? (2) Do the characteristics of Wikidata matter for the design of Entity Linking datasets and if so, how? (3) How do current Entity Linking approaches exploit the specific characteristics of Wikidata? (4) Which Wikidata characteristics are unexploited by existing Entity Linking approaches? This survey reveals that current Wikidata-specific Entity Linking datasets do not differ in their annotation scheme from schemes for other knowledge graphs like DBpedia. Thus, the potential for multilingual and time-dependent datasets, naturally suited for Wikidata, is not lifted. Furthermore, we show that most Entity Linking approaches use Wikidata in the same way as any other knowledge graph missing the chance to leverage Wikidata-specific characteristics to increase quality. Almost all approaches employ specific properties like labels and sometimes descriptions but ignore characteristics such as the hyper-relational structure. Hence, there is still room for improvement, for example, by including hyper-relational graph embeddings or type information. Many approaches also include information from Wikipedia, which is easily combinable with Wikidata and provides valuable textual information, which Wikidata lacks.
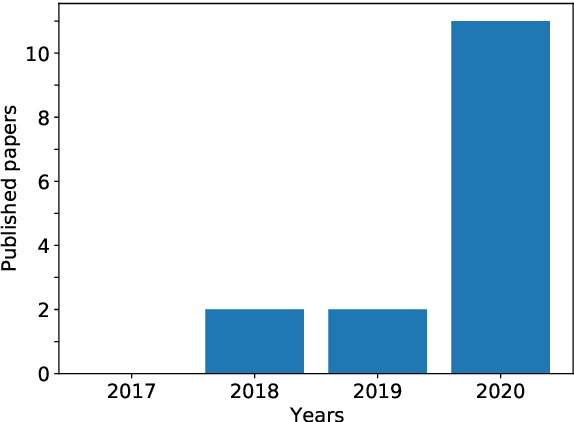
Single-Modal Entropy based Active Learning for Visual Question Answering
Nov 18, 2021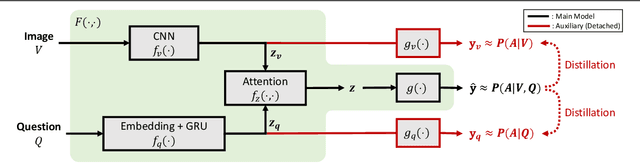
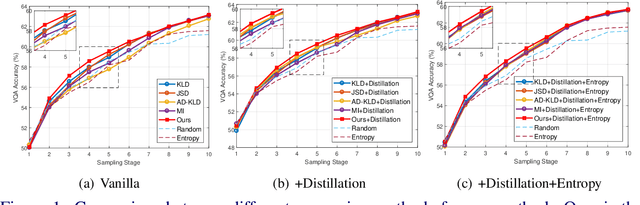
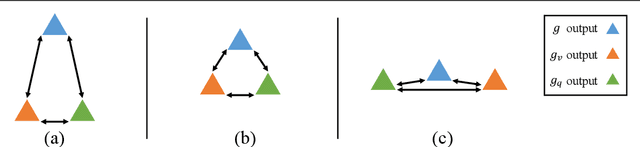
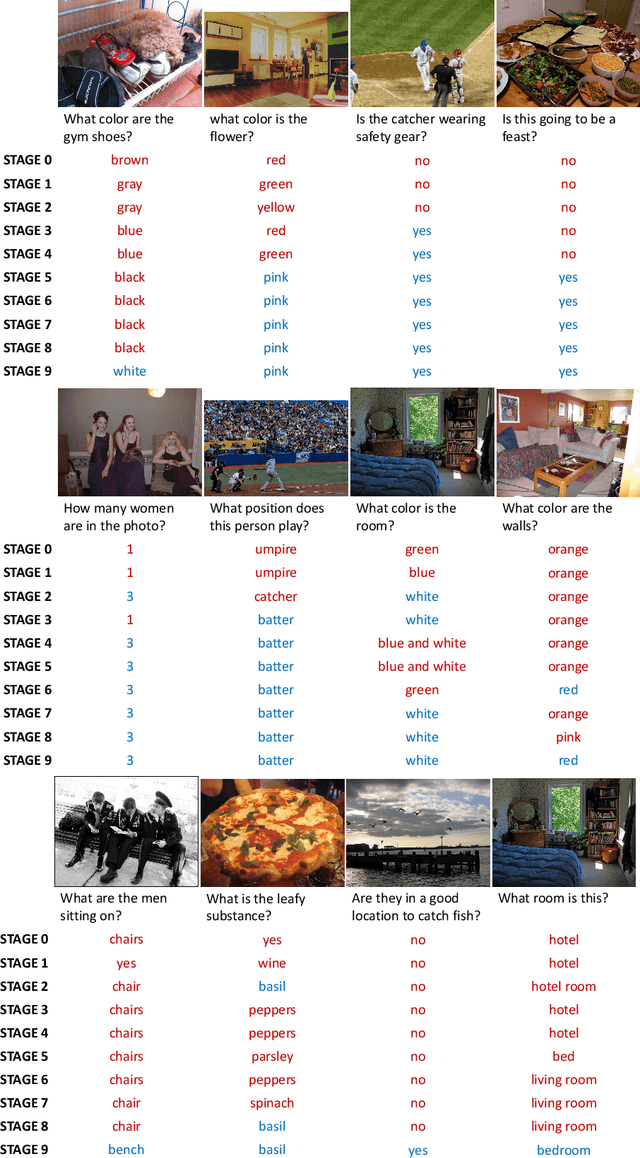
Constructing a large-scale labeled dataset in the real world, especially for high-level tasks (eg, Visual Question Answering), can be expensive and time-consuming. In addition, with the ever-growing amounts of data and architecture complexity, Active Learning has become an important aspect of computer vision research. In this work, we address Active Learning in the multi-modal setting of Visual Question Answering (VQA). In light of the multi-modal inputs, image and question, we propose a novel method for effective sample acquisition through the use of ad hoc single-modal branches for each input to leverage its information. Our mutual information based sample acquisition strategy Single-Modal Entropic Measure (SMEM) in addition to our self-distillation technique enables the sample acquisitor to exploit all present modalities and find the most informative samples. Our novel idea is simple to implement, cost-efficient, and readily adaptable to other multi-modal tasks. We confirm our findings on various VQA datasets through state-of-the-art performance by comparing to existing Active Learning baselines.
RODEO: Robust DE-aliasing autoencOder for Real-time Medical Image Reconstruction
Dec 11, 2019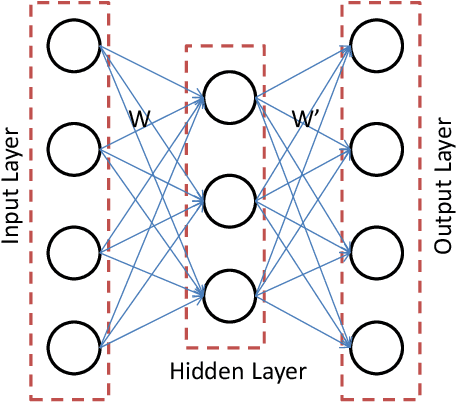
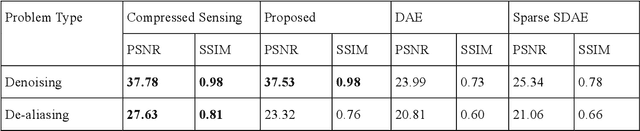
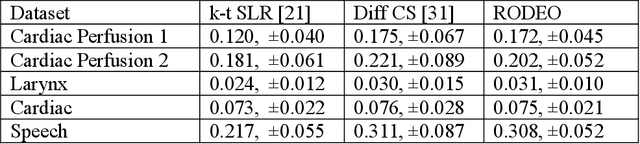
In this work we address the problem of real-time dynamic medical MRI and X Ray CT image reconstruction from parsimonious samples Fourier frequency space for MRI and sinogram tomographic projections for CT. Today the de facto standard for such reconstruction is compressed sensing. CS produces high quality images (with minimal perceptual loss, but such reconstructions are time consuming, requiring solving a complex optimization problem. In this work we propose to learn the reconstruction from training samples using an autoencoder. Our work is based on the universal function approximation capacity of neural networks. The training time for the autoencoder is large, but is offline and hence does not affect performance during operation. During testing or operation, our method requires only a few matrix vector products and hence is significantly faster than CS based methods. In fact, it is fast enough for real-time reconstruction the images are reconstructed as fast as they are acquired with only slight degradation of image quality. However, in order to make the autoencoder suitable for our problem, we depart from the standard Euclidean norm cost function of autoencoders and use a robust l1-norm instead. The ensuing problem is solved using the Split Bregman method.