 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Foreseeing Brain Graph Evolution Over Time Using Deep Adversarial Network Normalizer
Sep 23, 2020
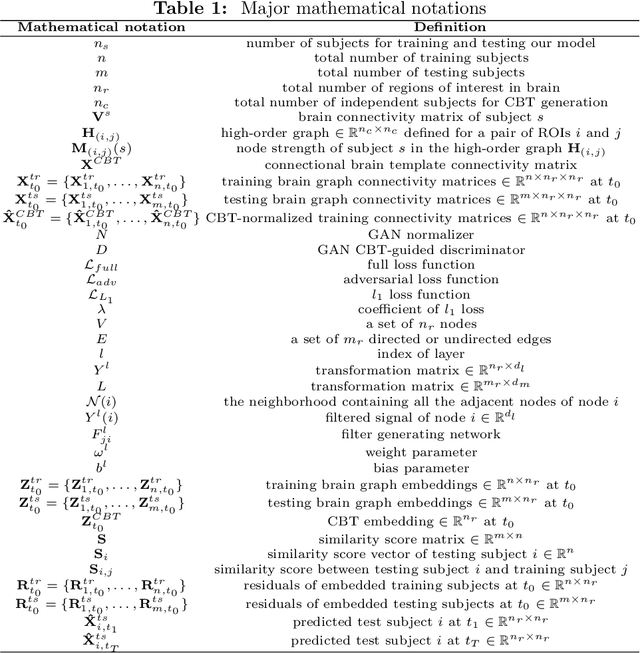
Foreseeing the brain evolution as a complex highly inter-connected system, widely modeled as a graph, is crucial for mapping dynamic interactions between different anatomical regions of interest (ROIs) in health and disease. Interestingly, brain graph evolution models remain almost absent in the literature. Here we design an adversarial brain network normalizer for representing each brain network as a transformation of a fixed centered population-driven connectional template. Such graph normalization with respect to a fixed reference paves the way for reliably identifying the most similar training samples (i.e., brain graphs) to the testing sample at baseline timepoint. The testing evolution trajectory will be then spanned by the selected training graphs and their corresponding evolution trajectories. We base our prediction framework on geometric deep learning which naturally operates on graphs and nicely preserves their topological properties. Specifically, we propose the first graph-based Generative Adversarial Network (gGAN) that not only learns how to normalize brain graphs with respect to a fixed connectional brain template (CBT) (i.e., a brain template that selectively captures the most common features across a brain population) but also learns a high-order representation of the brain graphs also called embeddings. We use these embeddings to compute the similarity between training and testing subjects which allows us to pick the closest training subjects at baseline timepoint to predict the evolution of the testing brain graph over time. A series of benchmarks against several comparison methods showed that our proposed method achieved the lowest brain disease evolution prediction error using a single baseline timepoint. Our gGAN code is available at http://github.com/basiralab/gGAN.
Towards Robust and Adaptive Motion Forecasting: A Causal Representation Perspective
Nov 29, 2021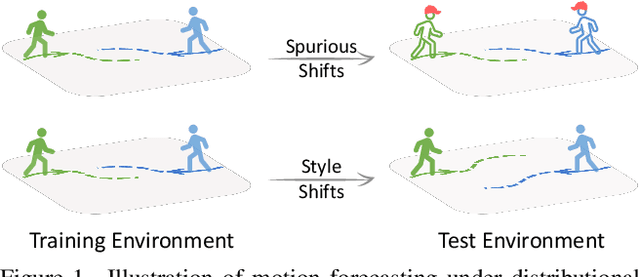
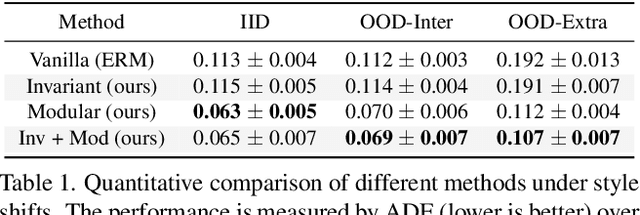
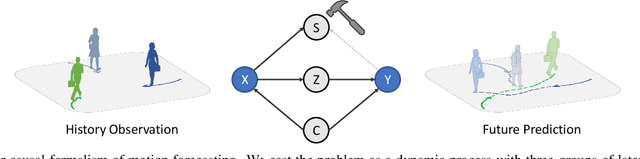
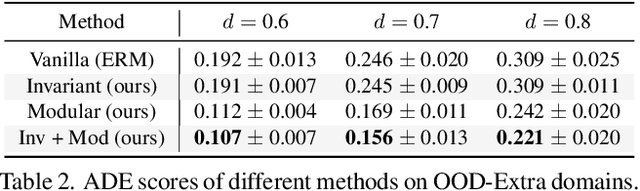
Learning behavioral patterns from observational data has been a de-facto approach to motion forecasting. Yet, the current paradigm suffers from two shortcomings: brittle under covariate shift and inefficient for knowledge transfer. In this work, we propose to address these challenges from a causal representation perspective. We first introduce a causal formalism of motion forecasting, which casts the problem as a dynamic process with three groups of latent variables, namely invariant mechanisms, style confounders, and spurious features. We then introduce a learning framework that treats each group separately: (i) unlike the common practice of merging datasets collected from different locations, we exploit their subtle distinctions by means of an invariance loss encouraging the model to suppress spurious correlations; (ii) we devise a modular architecture that factorizes the representations of invariant mechanisms and style confounders to approximate a causal graph; (iii) we introduce a style consistency loss that not only enforces the structure of style representations but also serves as a self-supervisory signal for test-time refinement on the fly. Experiment results on synthetic and real datasets show that our three proposed components significantly improve the robustness and reusability of the learned motion representations, outperforming prior state-of-the-art motion forecasting models for out-of-distribution generalization and low-shot transfer.
An Energy-Efficient Edge Computing Paradigm for Convolution-based Image Upsampling
Jul 26, 2021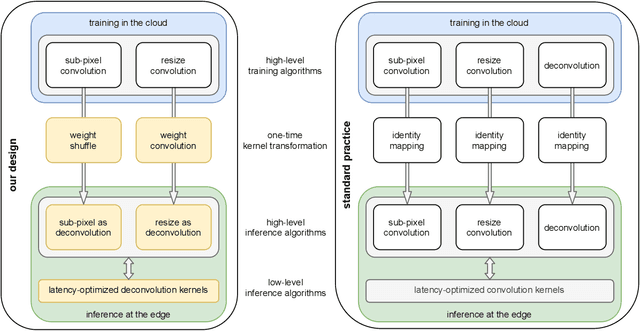

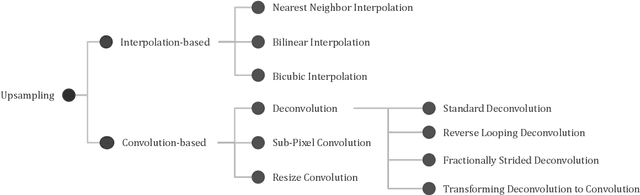

A novel energy-efficient edge computing paradigm is proposed for real-time deep learning-based image upsampling applications. State-of-the-art deep learning solutions for image upsampling are currently trained using either resize or sub-pixel convolution to learn kernels that generate high fidelity images with minimal artifacts. However, performing inference with these learned convolution kernels requires memory-intensive feature map transformations that dominate time and energy costs in real-time applications. To alleviate this pressure on memory bandwidth, we confine the use of resize or sub-pixel convolution to training in the cloud by transforming learned convolution kernels to deconvolution kernels before deploying them for inference as a functionally equivalent deconvolution. These kernel transformations, intended as a one-time cost when shifting from training to inference, enable a systems designer to use each algorithm in their optimal context by preserving the image fidelity learned when training in the cloud while minimizing data transfer penalties during inference at the edge. We also explore existing variants of deconvolution inference algorithms and introduce a novel variant for consideration. We analyze and compare the inference properties of convolution-based upsampling algorithms using a quantitative model of incurred time and energy costs and show that using deconvolution for inference at the edge improves both system latency and energy efficiency when compared to their sub-pixel or resize convolution counterparts.
Differentiable Generalised Predictive Coding
Dec 08, 2021This paper deals with differentiable dynamical models congruent with neural process theories that cast brain function as the hierarchical refinement of an internal generative model explaining observations. Our work extends existing implementations of gradient-based predictive coding with automatic differentiation and allows to integrate deep neural networks for non-linear state parameterization. Gradient-based predictive coding optimises inferred states and weights locally in for each layer by optimising precision-weighted prediction errors that propagate from stimuli towards latent states. Predictions flow backwards, from latent states towards lower layers. The model suggested here optimises hierarchical and dynamical predictions of latent states. Hierarchical predictions encode expected content and hierarchical structure. Dynamical predictions capture changes in the encoded content along with higher order derivatives. Hierarchical and dynamical predictions interact and address different aspects of the same latent states. We apply the model to various perception and planning tasks on sequential data and show their mutual dependence. In particular, we demonstrate how learning sampling distances in parallel address meaningful locations data sampled at discrete time steps. We discuss possibilities to relax the assumption of linear hierarchies in favor of more flexible graph structure with emergent properties. We compare the granular structure of the model with canonical microcircuits describing predictive coding in biological networks and review the connection to Markov Blankets as a tool to characterize modularity. A final section sketches out ideas for efficient perception and planning in nested spatio-temporal hierarchies.
Self-Supervised Audio-Visual Representation Learning with Relaxed Cross-Modal Temporal Synchronicity
Nov 09, 2021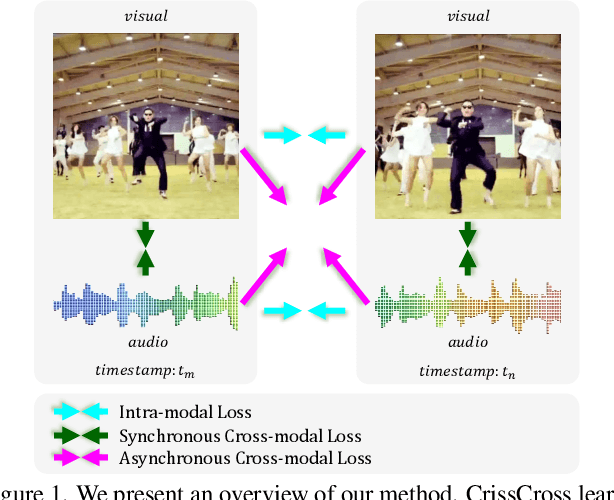
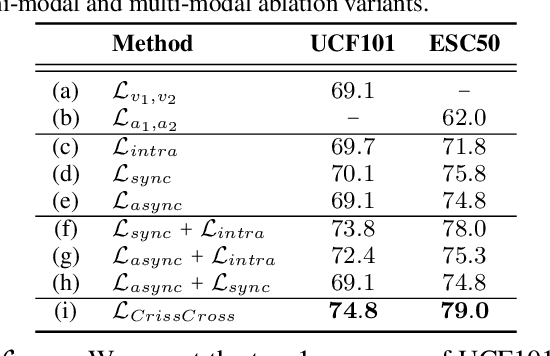
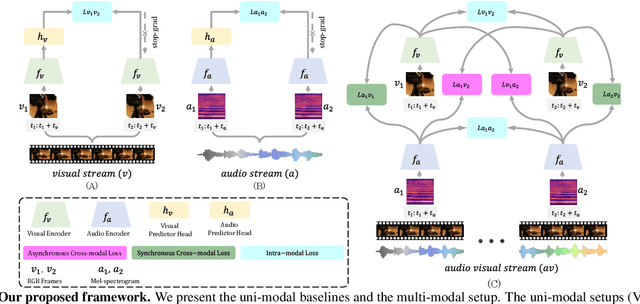
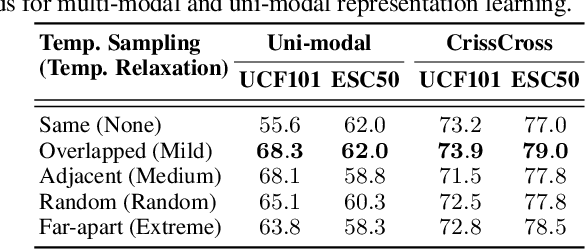
We present CrissCross, a self-supervised framework for learning audio-visual representations. A novel notion is introduced in our framework whereby in addition to learning the intra-modal and standard 'synchronous' cross-modal relations, CrissCross also learns 'asynchronous' cross-modal relationships. We show that by relaxing the temporal synchronicity between the audio and visual modalities, the network learns strong time-invariant representations. Our experiments show that strong augmentations for both audio and visual modalities with relaxation of cross-modal temporal synchronicity optimize performance. To pretrain our proposed framework, we use 3 different datasets with varying sizes, Kinetics-Sound, Kinetics-400, and AudioSet. The learned representations are evaluated on a number of downstream tasks namely action recognition, sound classification, and retrieval. CrissCross shows state-of-the-art performances on action recognition (UCF101 and HMDB51) and sound classification (ESC50). The codes and pretrained models will be made publicly available.
A Virtual Reality Simulation Pipeline for Online Mental Workload Modeling
Nov 24, 2021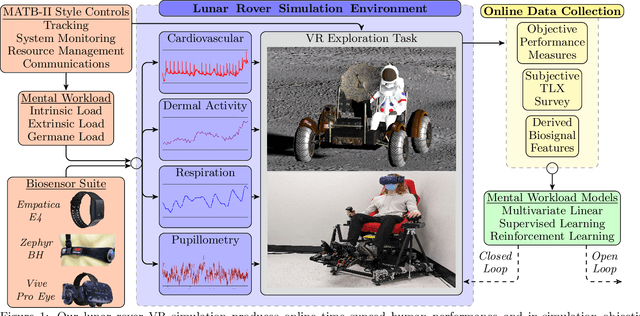
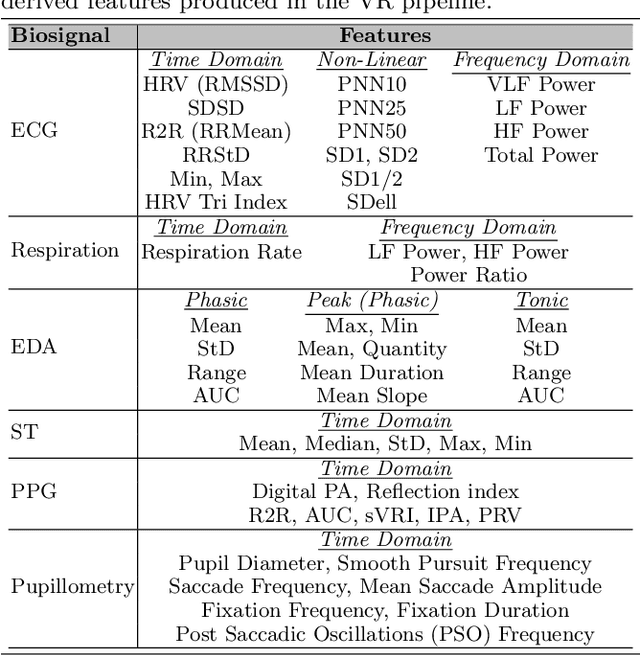

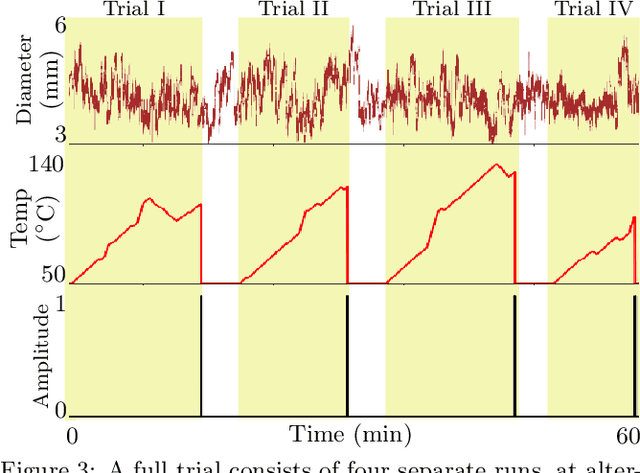
Seamless human robot interaction (HRI) and cooperative human-robot (HR) teaming critically rely upon accurate and timely human mental workload (MW) models. Cognitive Load Theory (CLT) suggests representative physical environments produce representative mental processes; physical environment fidelity corresponds with improved modeling accuracy. Virtual Reality (VR) systems provide immersive environments capable of replicating complicated scenarios, particularly those associated with high-risk, high-stress scenarios. Passive biosignal modeling shows promise as a noninvasive method of MW modeling. However, VR systems rarely include multimodal psychophysiological feedback or capitalize on biosignal data for online MW modeling. Here, we develop a novel VR simulation pipeline, inspired by the NASA Multi-Attribute Task Battery II (MATB-II) task architecture, capable of synchronous collection of objective performance, subjective performance, and passive human biosignals in a simulated hazardous exploration environment. Our system design extracts and publishes biofeatures through the Robot Operating System (ROS), facilitating real time psychophysiology-based MW model integration into complete end-to-end systems. A VR simulation pipeline capable of evaluating MWs online could be foundational for advancing HR systems and VR experiences by enabling these systems to adaptively alter their behaviors in response to operator MW.
Intelli-Paint: Towards Developing Human-like Painting Agents
Dec 16, 2021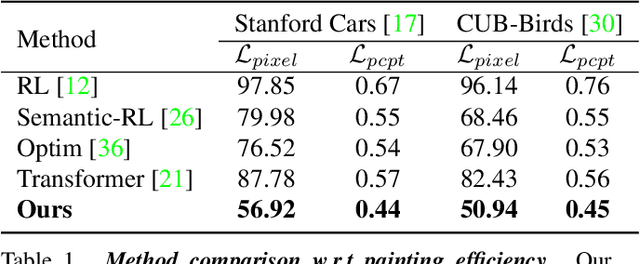
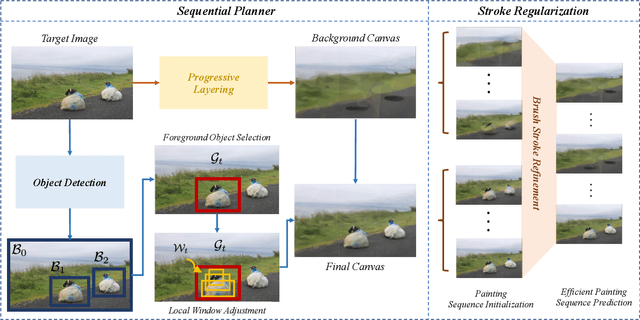


The generation of well-designed artwork is often quite time-consuming and assumes a high degree of proficiency on part of the human painter. In order to facilitate the human painting process, substantial research efforts have been made on teaching machines how to "paint like a human", and then using the trained agent as a painting assistant tool for human users. However, current research in this direction is often reliant on a progressive grid-based division strategy wherein the agent divides the overall image into successively finer grids, and then proceeds to paint each of them in parallel. This inevitably leads to artificial painting sequences which are not easily intelligible to human users. To address this, we propose a novel painting approach which learns to generate output canvases while exhibiting a more human-like painting style. The proposed painting pipeline Intelli-Paint consists of 1) a progressive layering strategy which allows the agent to first paint a natural background scene representation before adding in each of the foreground objects in a progressive fashion. 2) We also introduce a novel sequential brushstroke guidance strategy which helps the painting agent to shift its attention between different image regions in a semantic-aware manner. 3) Finally, we propose a brushstroke regularization strategy which allows for ~60-80% reduction in the total number of required brushstrokes without any perceivable differences in the quality of the generated canvases. Through both quantitative and qualitative results, we show that the resulting agents not only show enhanced efficiency in output canvas generation but also exhibit a more natural-looking painting style which would better assist human users express their ideas through digital artwork.
Searching for More Efficient Dynamic Programs
Sep 14, 2021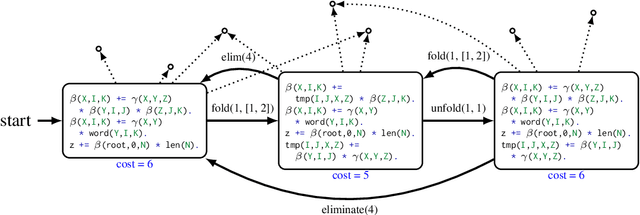
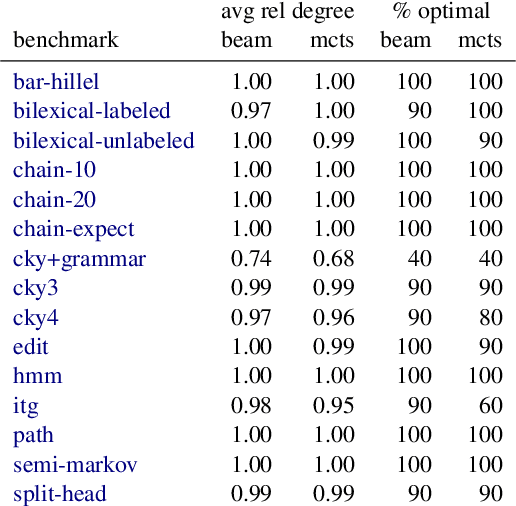

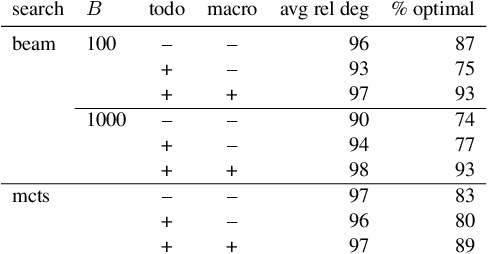
Computational models of human language often involve combinatorial problems. For instance, a probabilistic parser may marginalize over exponentially many trees to make predictions. Algorithms for such problems often employ dynamic programming and are not always unique. Finding one with optimal asymptotic runtime can be unintuitive, time-consuming, and error-prone. Our work aims to automate this laborious process. Given an initial correct declarative program, we search for a sequence of semantics-preserving transformations to improve its running time as much as possible. To this end, we describe a set of program transformations, a simple metric for assessing the efficiency of a transformed program, and a heuristic search procedure to improve this metric. We show that in practice, automated search -- like the mental search performed by human programmers -- can find substantial improvements to the initial program. Empirically, we show that many common speed-ups described in the NLP literature could have been discovered automatically by our system.
Asynchronous Real-Time Optimization of Footstep Placement and Timing in Bipedal Walking Robots
Jul 02, 2020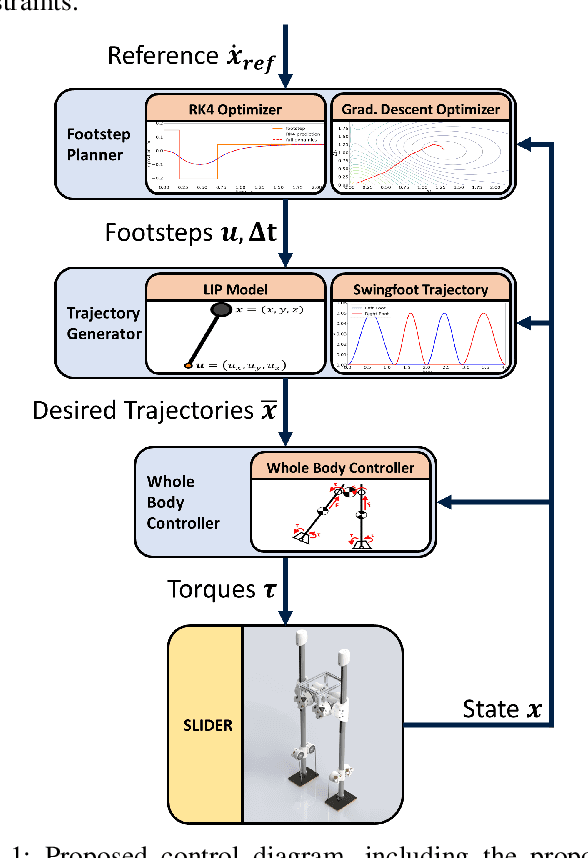
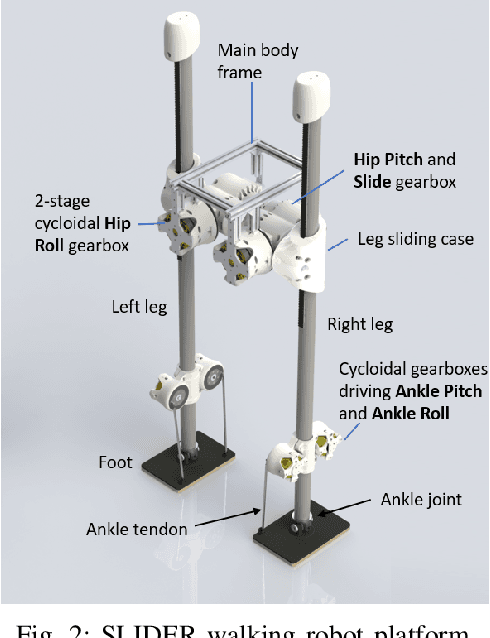
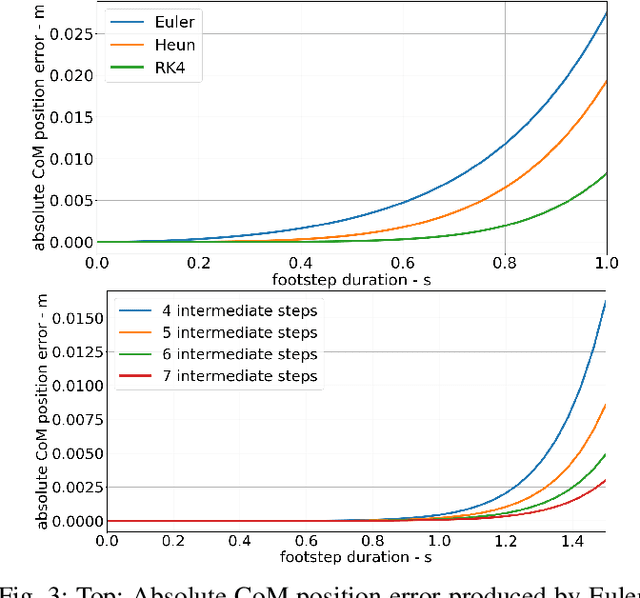
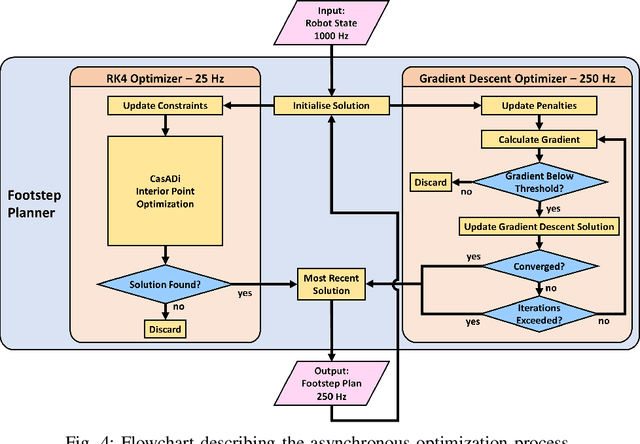
Online footstep planning is essential for bipedal walking robots to be able to walk in the presence of disturbances. Until recently this has been achieved by only optimizing the placement of the footstep, keeping the duration of the step constant. In this paper we introduce a footstep planner capable of optimizing footstep placement and timing in real-time by asynchronously combining two optimizers, which we refer to as asynchronous real-time optimization (ARTO). The first optimizer which runs at approximately 25 Hz, utilizes a fourth-order Runge-Kutta (RK4) method to accurately approximate the dynamics of the linear inverted pendulum (LIP) model for bipedal walking, then uses non-linear optimization to find optimal footsteps and duration at a lower frequency. The second optimizer that runs at approximately 250 Hz, uses analytical gradients derived from the full dynamics of the LIP model and constraint penalty terms to perform gradient descent, which finds approximately optimal footstep placement and timing at a higher frequency. By combining the two optimizers asynchronously, ARTO has the benefits of fast reactions to disturbances from the gradient descent optimizer, accurate solutions that avoid local optima from the RK4 optimizer, and increases the probability that a feasible solution will be found from the two optimizers. Experimentally, we show that ARTO is able to recover from considerably larger pushes and produces feasible solutions to larger reference velocity changes than a standard footstep location optimizer, and outperforms using just the RK4 optimizer alone.
Simple online and real-time tracking with occlusion handling
Mar 06, 2021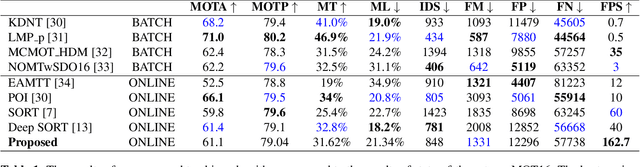

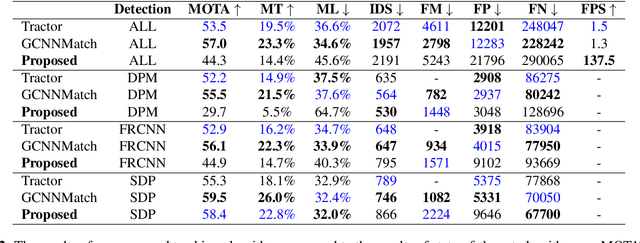

Multiple object tracking is a challenging problem in computer vision due to difficulty in dealing with motion prediction, occlusion handling, and object re-identification. Many recent algorithms use motion and appearance cues to overcome these challenges. But using appearance cues increases the computation cost notably and therefore the speed of the algorithm decreases significantly which makes them inappropriate for online applications. In contrast, there are algorithms that only use motion cues to increase speed, especially for online applications. But these algorithms cannot handle occlusions and re-identify lost objects. In this paper, a novel online multiple object tracking algorithm is presented that only uses geometric cues of objects to tackle the occlusion and reidentification challenges simultaneously. As a result, it decreases the identity switch and fragmentation metrics. Experimental results show that the proposed algorithm could decrease identity switch by 40% and fragmentation by 28% compared to the state of the art online tracking algorithms. The code is also publicly available.