 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fast Spatio-temporal Compression of Dynamic 3D Meshes
Nov 19, 2021
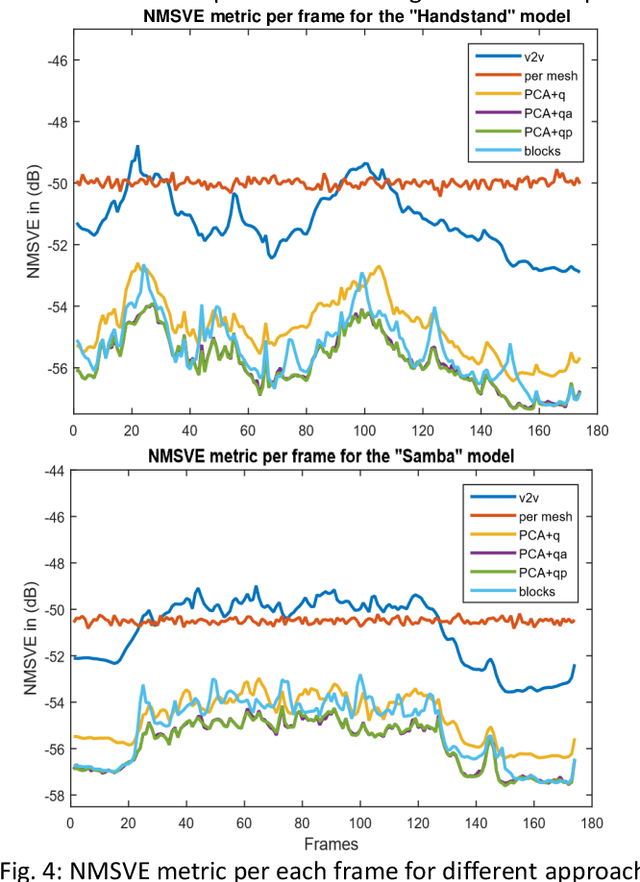
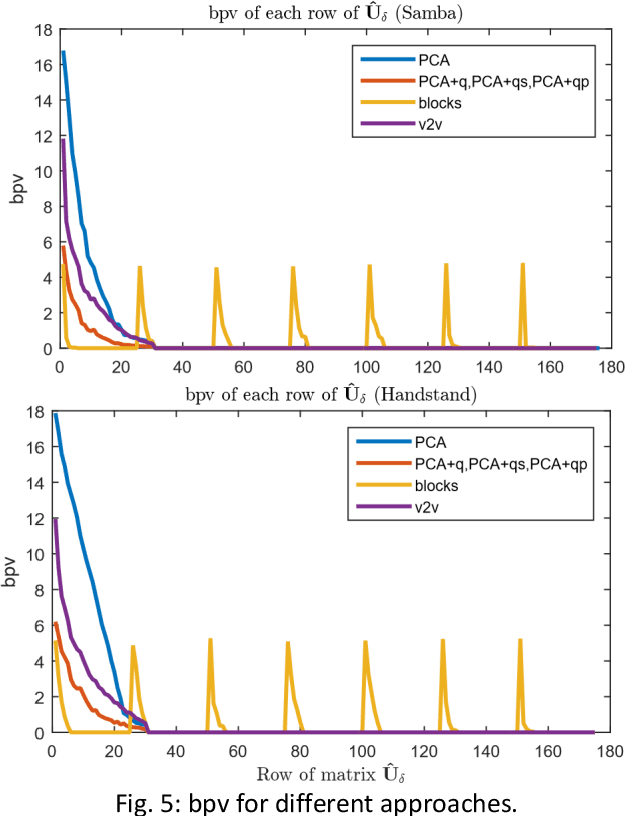

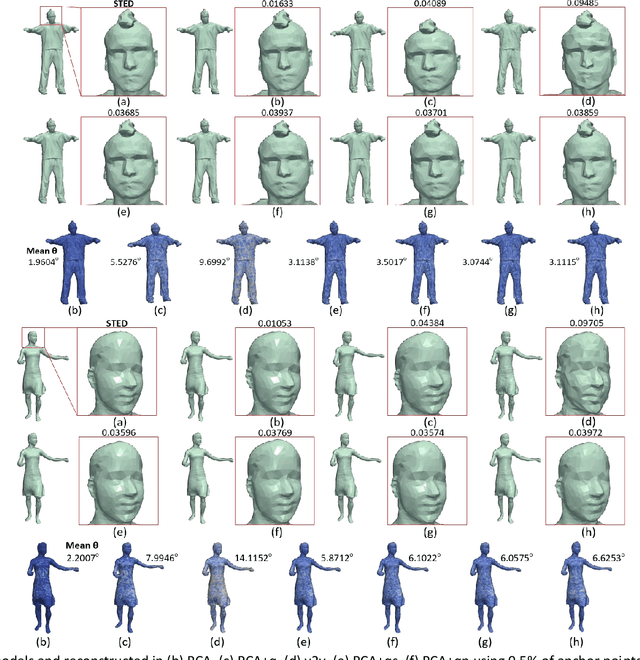
3D representations of highly deformable 3D models, such as dynamic 3D meshes, have recently become very popular due to their wide applicability in various domains. This trend inevitably leads to a demand for storage and transmission of voluminous data sets, making the need for the design of a robust and reliable compression scheme a necessity. In this work, we present an approach for dynamic 3D mesh compression, that effectively exploits the spatio-temporal coherence of animated sequences, achieving low compression ratios without noticeably affecting the visual quality of the animation. We show that, on contrary to mainstream approaches that either exploit spatial (e.g., spectral coding) or temporal redundancies (e.g., PCA-based method), the proposed scheme, achieves increased efficiency, by projecting the differential coordinates sequence to the subspace of the covariance of the point trajectories. An extensive evaluation study, using different dynamic 3D models, highlights the benefits of the proposed approach in terms of both execution time and reconstruction quality, providing extremely low bit-per-vertex per-frame (bpvf) rates.
Monitoring crop phenology with street-level imagery using computer vision
Dec 16, 2021
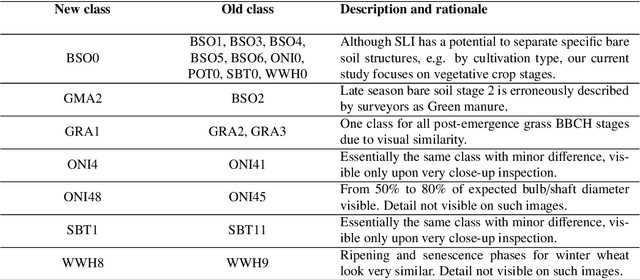


Street-level imagery holds a significant potential to scale-up in-situ data collection. This is enabled by combining the use of cheap high quality cameras with recent advances in deep learning compute solutions to derive relevant thematic information. We present a framework to collect and extract crop type and phenological information from street level imagery using computer vision. During the 2018 growing season, high definition pictures were captured with side-looking action cameras in the Flevoland province of the Netherlands. Each month from March to October, a fixed 200-km route was surveyed collecting one picture per second resulting in a total of 400,000 geo-tagged pictures. At 220 specific parcel locations detailed on the spot crop phenology observations were recorded for 17 crop types. Furthermore, the time span included specific pre-emergence parcel stages, such as differently cultivated bare soil for spring and summer crops as well as post-harvest cultivation practices, e.g. green manuring and catch crops. Classification was done using TensorFlow with a well-known image recognition model, based on transfer learning with convolutional neural networks (MobileNet). A hypertuning methodology was developed to obtain the best performing model among 160 models. This best model was applied on an independent inference set discriminating crop type with a Macro F1 score of 88.1% and main phenological stage at 86.9% at the parcel level. Potential and caveats of the approach along with practical considerations for implementation and improvement are discussed. The proposed framework speeds up high quality in-situ data collection and suggests avenues for massive data collection via automated classification using computer vision.
US-Rule: Discovering Utility-driven Sequential Rules
Nov 29, 2021
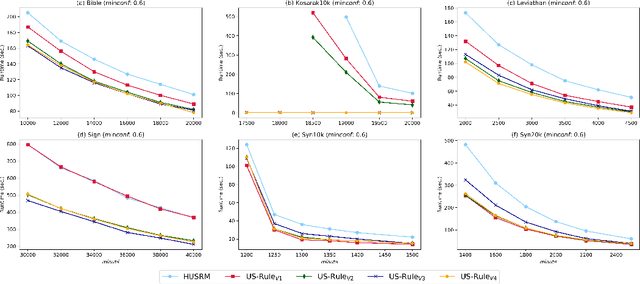

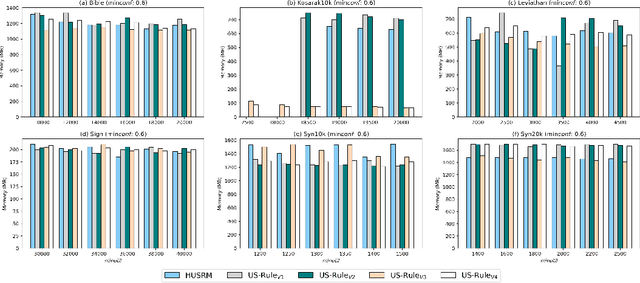
Utility-driven mining is an important task in data science and has many applications in real life. High utility sequential pattern mining (HUSPM) is one kind of utility-driven mining. HUSPM aims to discover all sequential patterns with high utility. However, the existing algorithms of HUSPM can not provide an accurate probability to deal with some scenarios for prediction or recommendation. High-utility sequential rule mining (HUSRM) was proposed to discover all sequential rules with high utility and high confidence. There is only one algorithm proposed for HUSRM, which is not enough efficient. In this paper, we propose a faster algorithm, called US-Rule, to efficiently mine high-utility sequential rules. It utilizes rule estimated utility co-occurrence pruning strategy (REUCP) to avoid meaningless computation. To improve the efficiency on dense and long sequence datasets, four tighter upper bounds (LEEU, REEU, LERSU, RERSU) and their corresponding pruning strategies (LEEUP, REEUP, LERSUP, RERSUP) are proposed. Besides, US-Rule proposes rule estimated utility recomputing pruning strategy (REURP) to deal with sparse datasets. At last, a large number of experiments on different datasets compared to the state-of-the-art algorithm demonstrate that US-Rule can achieve better performance in terms of execution time, memory consumption and scalability.
Neural Attention for Image Captioning: Review of Outstanding Methods
Nov 29, 2021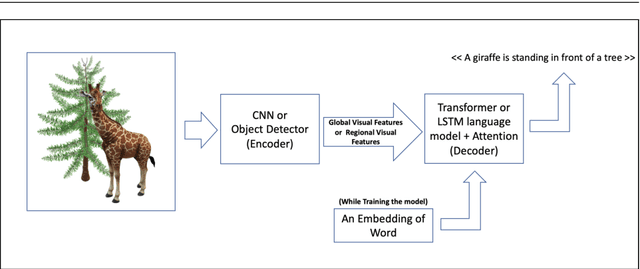
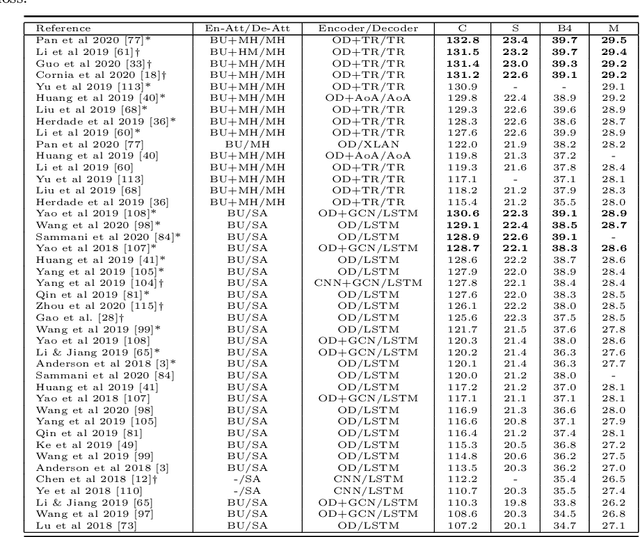
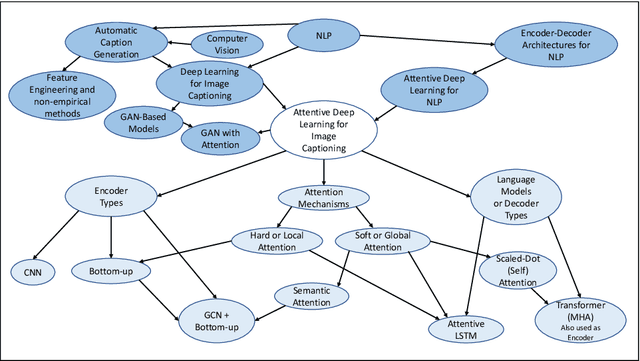
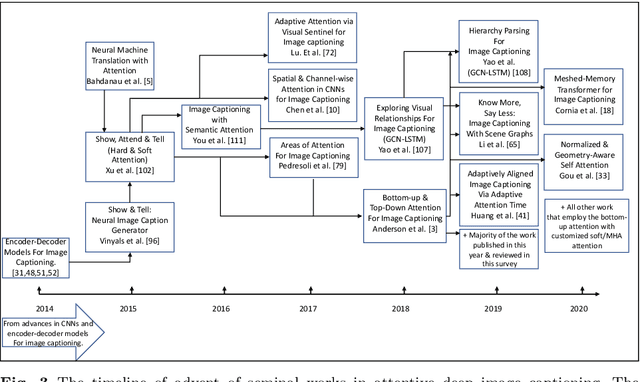
Image captioning is the task of automatically generating sentences that describe an input image in the best way possible. The most successful techniques for automatically generating image captions have recently used attentive deep learning models. There are variations in the way deep learning models with attention are designed. In this survey, we provide a review of literature related to attentive deep learning models for image captioning. Instead of offering a comprehensive review of all prior work on deep image captioning models, we explain various types of attention mechanisms used for the task of image captioning in deep learning models. The most successful deep learning models used for image captioning follow the encoder-decoder architecture, although there are differences in the way these models employ attention mechanisms. Via analysis on performance results from different attentive deep models for image captioning, we aim at finding the most successful types of attention mechanisms in deep models for image captioning. Soft attention, bottom-up attention, and multi-head attention are the types of attention mechanism widely used in state-of-the-art attentive deep learning models for image captioning. At the current time, the best results are achieved from variants of multi-head attention with bottom-up attention.
ARCH: Efficient Adversarial Regularized Training with Caching
Sep 15, 2021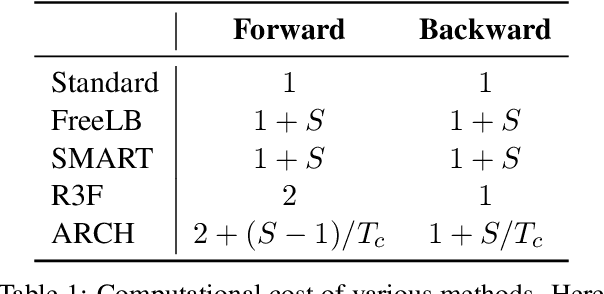
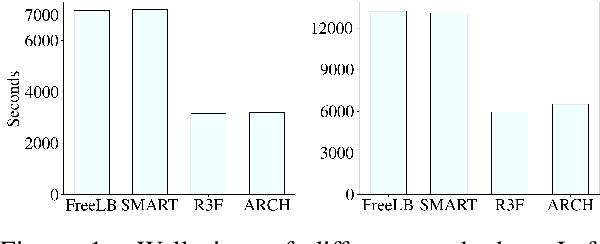
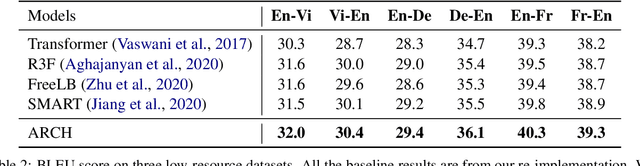
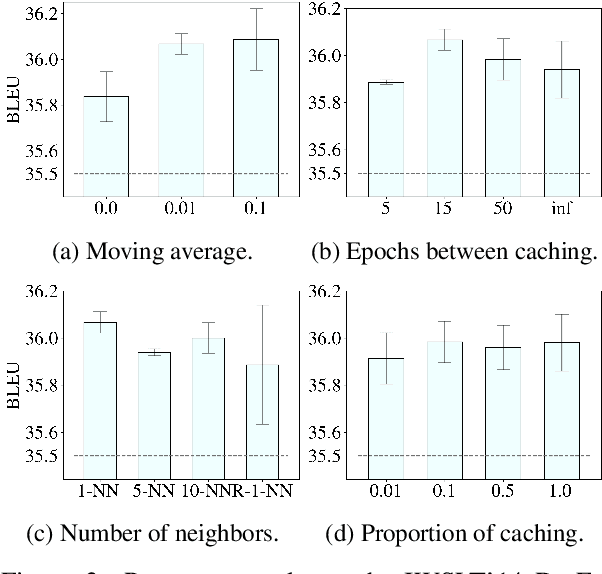
Adversarial regularization can improve model generalization in many natural language processing tasks. However, conventional approaches are computationally expensive since they need to generate a perturbation for each sample in each epoch. We propose a new adversarial regularization method ARCH (adversarial regularization with caching), where perturbations are generated and cached once every several epochs. As caching all the perturbations imposes memory usage concerns, we adopt a K-nearest neighbors-based strategy to tackle this issue. The strategy only requires caching a small amount of perturbations, without introducing additional training time. We evaluate our proposed method on a set of neural machine translation and natural language understanding tasks. We observe that ARCH significantly eases the computational burden (saves up to 70\% of computational time in comparison with conventional approaches). More surprisingly, by reducing the variance of stochastic gradients, ARCH produces a notably better (in most of the tasks) or comparable model generalization. Our code is publicly available.
Attentive Gaussian processes for probabilistic time-series generation
Feb 10, 2021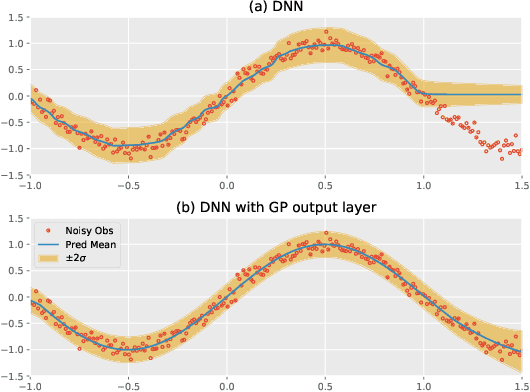
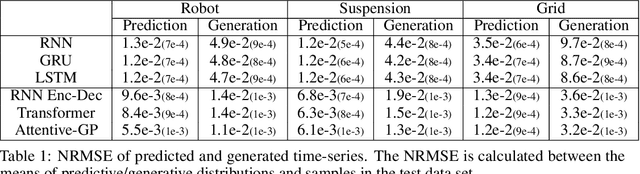
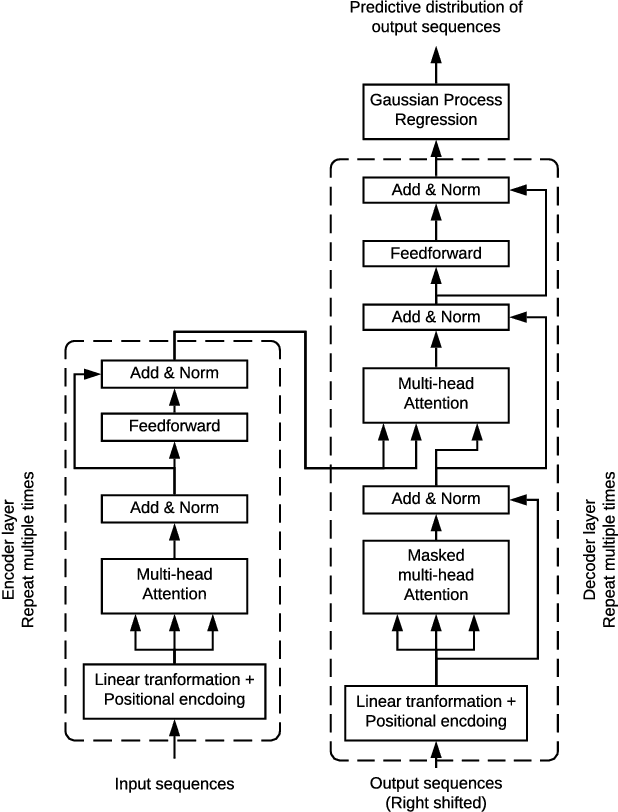
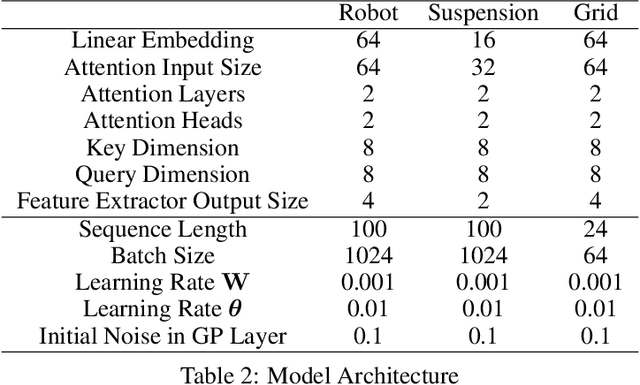
The transduction of sequence has been mostly done by recurrent networks, which are computationally demanding and often underestimate uncertainty severely. We propose a computationally efficient attention-based network combined with the Gaussian process regression to generate real-valued sequence, which we call the Attentive-GP. The proposed model not only improves the training efficiency by dispensing recurrence and convolutions but also learns the factorized generative distribution with Bayesian representation. However, the presence of the GP precludes the commonly used mini-batch approach to the training of the attention network. Therefore, we develop a block-wise training algorithm to allow mini-batch training of the network while the GP is trained using full-batch, resulting in a scalable training method. The algorithm has been proved to converge and shows comparable, if not better, quality of the found solution. As the algorithm does not assume any specific network architecture, it can be used with a wide range of hybrid models such as neural networks with kernel machine layers in the scarcity of resources for computation and memory.
Deep Learning Approach for Hyperspectral Image Demosaicking, Spectral Correction and High-resolution RGB Reconstruction
Sep 03, 2021

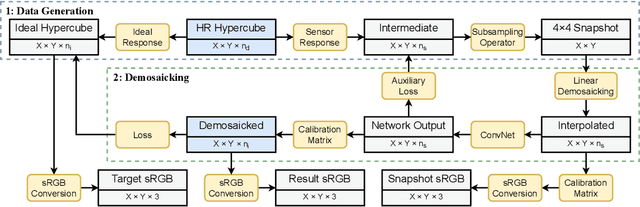
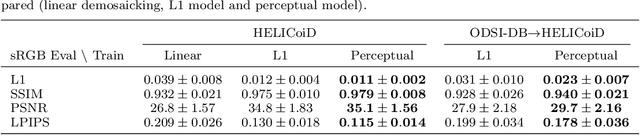
Hyperspectral imaging is one of the most promising techniques for intraoperative tissue characterisation. Snapshot mosaic cameras, which can capture hyperspectral data in a single exposure, have the potential to make a real-time hyperspectral imaging system for surgical decision-making possible. However, optimal exploitation of the captured data requires solving an ill-posed demosaicking problem and applying additional spectral corrections to recover spatial and spectral information of the image. In this work, we propose a deep learning-based image demosaicking algorithm for snapshot hyperspectral images using supervised learning methods. Due to the lack of publicly available medical images acquired with snapshot mosaic cameras, a synthetic image generation approach is proposed to simulate snapshot images from existing medical image datasets captured by high-resolution, but slow, hyperspectral imaging devices. Image reconstruction is achieved using convolutional neural networks for hyperspectral image super-resolution, followed by cross-talk and leakage correction using a sensor-specific calibration matrix. The resulting demosaicked images are evaluated both quantitatively and qualitatively, showing clear improvements in image quality compared to a baseline demosaicking method using linear interpolation. Moreover, the fast processing time of~45\,ms of our algorithm to obtain super-resolved RGB or oxygenation saturation maps per image frame for a state-of-the-art snapshot mosaic camera demonstrates the potential for its seamless integration into real-time surgical hyperspectral imaging applications.
Reinforcement Learning in Reward-Mixing MDPs
Oct 07, 2021Learning a near optimal policy in a partially observable system remains an elusive challenge in contemporary reinforcement learning. In this work, we consider episodic reinforcement learning in a reward-mixing Markov decision process (MDP). There, a reward function is drawn from one of multiple possible reward models at the beginning of every episode, but the identity of the chosen reward model is not revealed to the agent. Hence, the latent state space, for which the dynamics are Markovian, is not given to the agent. We study the problem of learning a near optimal policy for two reward-mixing MDPs. Unlike existing approaches that rely on strong assumptions on the dynamics, we make no assumptions and study the problem in full generality. Indeed, with no further assumptions, even for two switching reward-models, the problem requires several new ideas beyond existing algorithmic and analysis techniques for efficient exploration. We provide the first polynomial-time algorithm that finds an $\epsilon$-optimal policy after exploring $\tilde{O}(poly(H,\epsilon^{-1}) \cdot S^2 A^2)$ episodes, where $H$ is time-horizon and $S, A$ are the number of states and actions respectively. This is the first efficient algorithm that does not require any assumptions in partially observed environments where the observation space is smaller than the latent state space.
A scale invariant ranking function for learning-to-rank: a real-world use case
Oct 21, 2021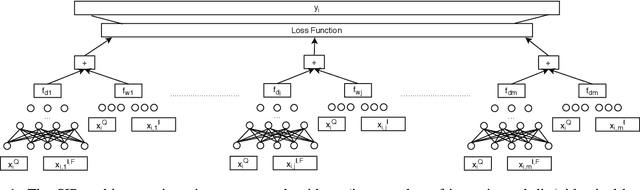
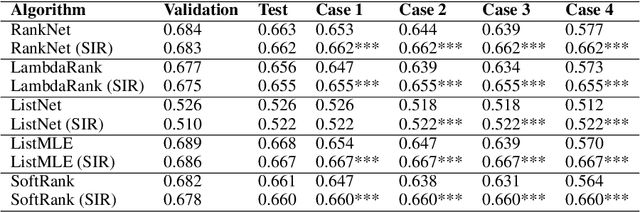
Nowadays, Online Travel Agencies provide the main service for booking holidays, business trips, accommodations, etc. As in many e-commerce services where users, items, and preferences are involved, the use of a Recommender System facilitates the navigation of the marketplaces. One of the main challenges when productizing machine learning models (and in this case, Learning-to-Rank models) is the need of, not only consistent pre-processing transformations, but also input features maintaining a similar scale both at training and prediction time. However, the features' scale does not necessarily stay the same in the real-world production environment, which could lead to unexpected ranking order. Normalization techniques such as feature standardization, batch normalization and layer normalization are commonly used to tackle the scaling issue. However, these techniques. To address this issue, in this paper we propose a novel scale-invariant ranking function (dubbed as SIR) which is accomplished by combining a deep and a wide neural network. We incorporate SIR with five state-of-the-art Learning-to-Rank models and compare the performance of the combined models with the classic algorithms on a large data set containing 56 million booked searches from the Hotels.com website. Besides, we simulate four real-world scenarios where the features' scale at the test set is inconsistent with that at the training set. The results reveal that when the features' scale is inconsistent at prediction time, Learning-To-Rank methods incorporating SIR outperform their original counterpart in all scenarios (with performance difference up to 14.7%), while when the features' scale at the training and test set are consistent our proposal achieves comparable accuracy to the classic algorithms.
DeepGamble: Towards unlocking real-time player intelligence using multi-layer instance segmentation and attribute detection
Dec 14, 2020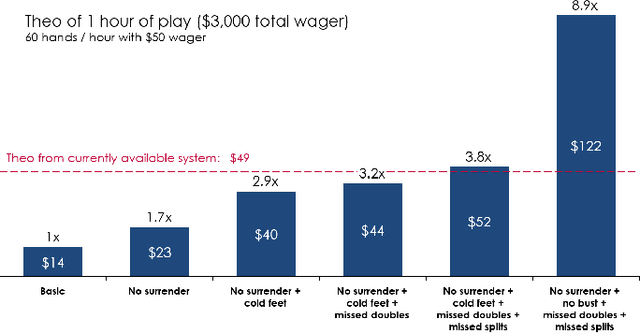
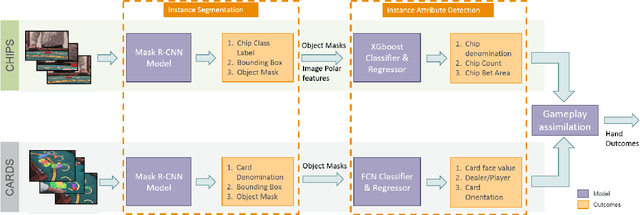
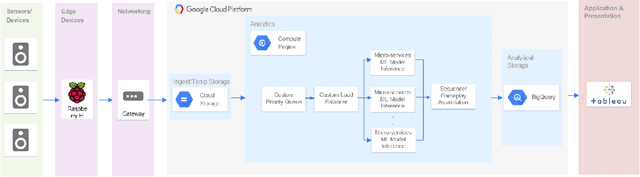

Annually the gaming industry spends approximately $15 billion in marketing reinvestment. However, this amount is spent without any consideration for the skill and luck of the player. For a casino, an unskilled player could fetch ~4 times more revenue than a skilled player. This paper describes a video recognition system that is based on an extension of the Mask R-CNN model. Our system digitizes the game of blackjack by detecting cards and player bets in real-time and processes decisions they took in order to create accurate player personas. Our proposed supervised learning approach consists of a specialized three-stage pipeline that takes images from two viewpoints of the casino table and does instance segmentation to generate masks on proposed regions of interest. These predicted masks along with derivative features are used to classify image attributes that are passed onto the next stage to assimilate the gameplay understanding. Our end-to-end model yields an accuracy of ~95% for the main bet detection and ~97% for card detection in a controlled environment trained using transfer learning approach with 900 training examples. Our approach is generalizable and scalable and shows promising results in varied gaming scenarios and test data. Such granular level gathered data, helped in understanding player's deviation from optimum strategy and thereby separate the skill of the player from the luck of the game. Our system also assesses the likelihood of card counting by correlating the player's betting pattern to the deck's scaled count. Such a system lets casinos flag fraudulent activity and calculate expected personalized profitability for each player and tailor their marketing reinvestment decisions.