 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Distinguishing Natural and Computer-Generated Images using Multi-Colorspace fused EfficientNet
Oct 18, 2021

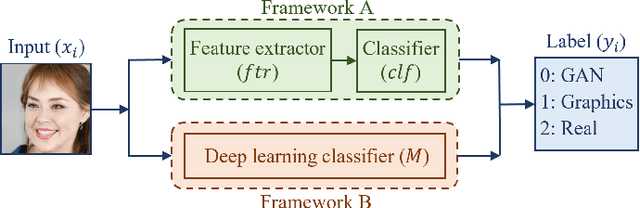
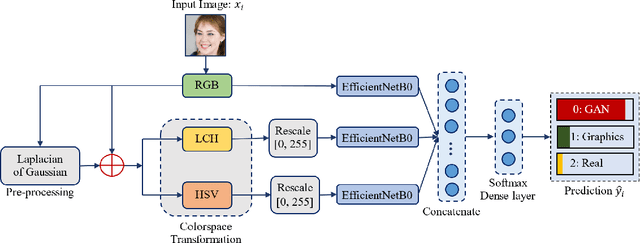
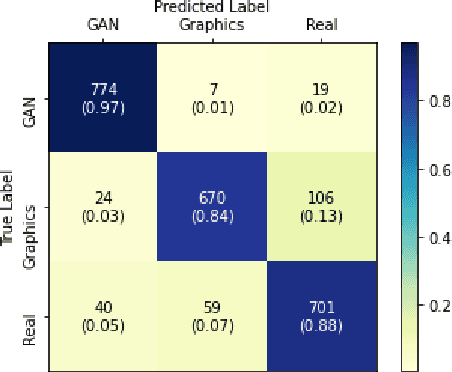
The problem of distinguishing natural images from photo-realistic computer-generated ones either addresses natural images versus computer graphics or natural images versus GAN images, at a time. But in a real-world image forensic scenario, it is highly essential to consider all categories of image generation, since in most cases image generation is unknown. We, for the first time, to our best knowledge, approach the problem of distinguishing natural images from photo-realistic computer-generated images as a three-class classification task classifying natural, computer graphics, and GAN images. For the task, we propose a Multi-Colorspace fused EfficientNet model by parallelly fusing three EfficientNet networks that follow transfer learning methodology where each network operates in different colorspaces, RGB, LCH, and HSV, chosen after analyzing the efficacy of various colorspace transformations in this image forensics problem. Our model outperforms the baselines in terms of accuracy, robustness towards post-processing, and generalizability towards other datasets. We conduct psychophysics experiments to understand how accurately humans can distinguish natural, computer graphics, and GAN images where we could observe that humans find difficulty in classifying these images, particularly the computer-generated images, indicating the necessity of computational algorithms for the task. We also analyze the behavior of our model through visual explanations to understand salient regions that contribute to the model's decision making and compare with manual explanations provided by human participants in the form of region markings, where we could observe similarities in both the explanations indicating the powerful nature of our model to take the decisions meaningfully.
Robustness-aware 2-bit quantization with real-time performance for neural network
Oct 19, 2020
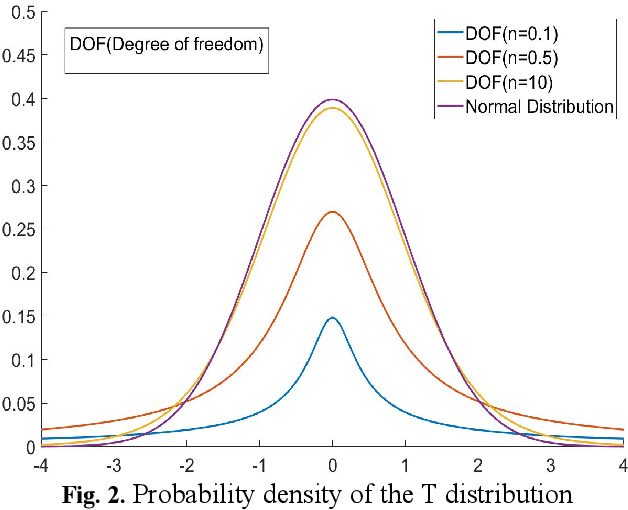
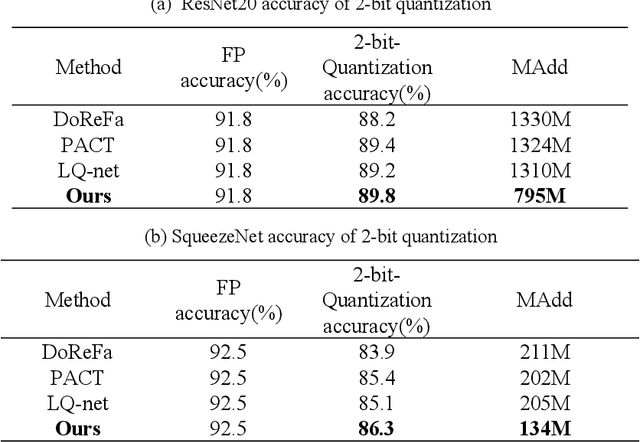
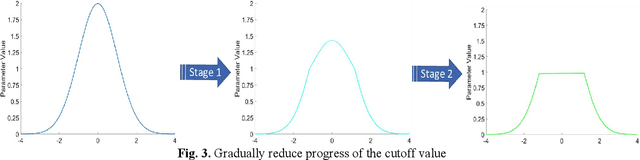
Quantized neural network (NN) with a reduced bit precision is an effective solution to reduces the computational and memory resource requirements and plays a vital role in machine learning. However, it is still challenging to avoid the significant accuracy degradation due to its numerical approximation and lower redundancy. In this paper, a novel robustness-aware 2-bit quantization scheme is proposed for NN base on binary NN and generative adversarial network(GAN), witch improves the performance by enriching the information of binary NN, efficiently extract the structural information and considering the robustness of the quantized NN. Specifically, using shift addition operation to replace the multiply-accumulate in the quantization process witch can effectively speed the NN. Meanwhile, a structural loss between the original NN and quantized NN is proposed to such that the structural information of data is preserved after quantization. The structural information learned from NN not only plays an important role in improving the performance but also allows for further fine tuning of the quantization network by applying the Lipschitz constraint to the structural loss. In addition, we also for the first time take the robustness of the quantized NN into consideration and propose a non-sensitive perturbation loss function by introducing an extraneous term of spectral norm. The experiments are conducted on CIFAR-10 and ImageNet datasets with popular NN( such as MoblieNetV2, SqueezeNet, ResNet20, etc). The experimental results show that the proposed algorithm is more competitive under 2-bit-precision than the state-of-the-art quantization methods. Meanwhile, the experimental results also demonstrate that the proposed method is robust under the FGSM adversarial samples attack.
Adaptive Subsampling for ROI-based Visual Tracking: Algorithms and FPGA Implementation
Dec 17, 2021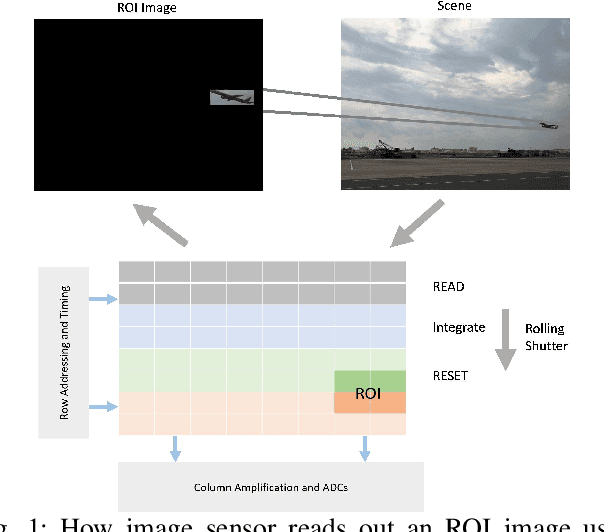

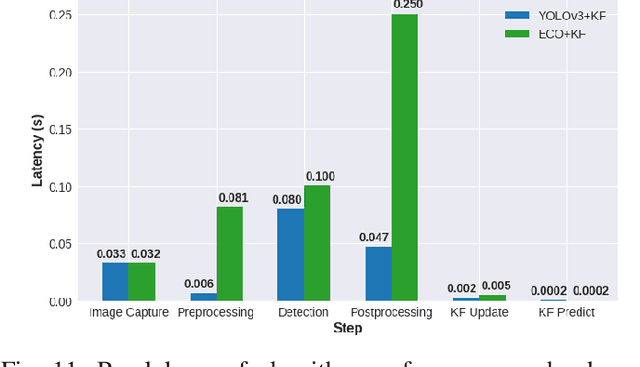

There is tremendous scope for improving the energy efficiency of embedded vision systems by incorporating programmable region-of-interest (ROI) readout in the image sensor design. In this work, we study how ROI programmability can be leveraged for tracking applications by anticipating where the ROI will be located in future frames and switching pixels off outside of this region. We refer to this process of ROI prediction and corresponding sensor configuration as adaptive subsampling. Our adaptive subsampling algorithms comprise an object detector and an ROI predictor (Kalman filter) which operate in conjunction to optimize the energy efficiency of the vision pipeline with the end task being object tracking. To further facilitate the implementation of our adaptive algorithms in real life, we select a candidate algorithm and map it onto an FPGA. Leveraging Xilinx Vitis AI tools, we designed and accelerated a YOLO object detector-based adaptive subsampling algorithm. In order to further improve the algorithm post-deployment, we evaluated several competing baselines on the OTB100 and LaSOT datasets. We found that coupling the ECO tracker with the Kalman filter has a competitive AUC score of 0.4568 and 0.3471 on the OTB100 and LaSOT datasets respectively. Further, the power efficiency of this algorithm is on par with, and in a couple of instances superior to, the other baselines. The ECO-based algorithm incurs a power consumption of approximately 4 W averaged across both datasets while the YOLO-based approach requires power consumption of approximately 6 W (as per our power consumption model). In terms of accuracy-latency tradeoff, the ECO-based algorithm provides near-real-time performance (19.23 FPS) while managing to attain competitive tracking precision.
Recognition of Tactile-related EEG Signals Generated by Self-touch
Dec 14, 2021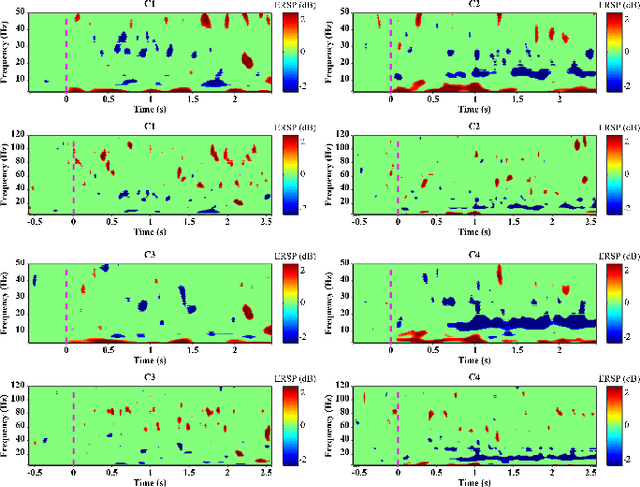
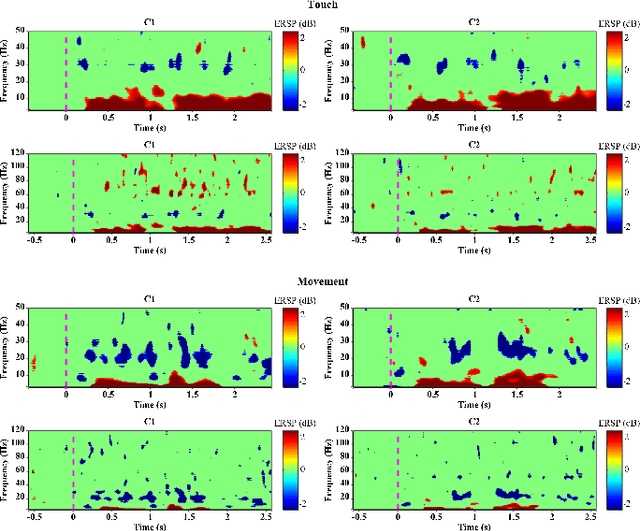
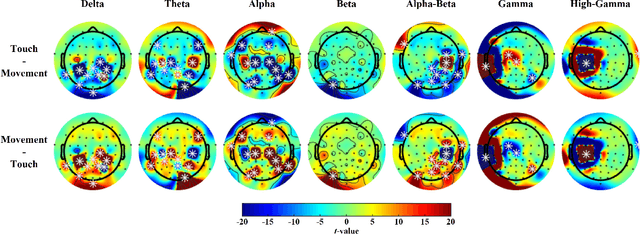
Touch is the first sense among human senses. Not only that, but it is also one of the most important senses that are indispensable. However, compared to sight and hearing, it is often neglected. In particular, since humans use the tactile sense of the skin to recognize and manipulate objects, without tactile sensation, it is very difficult to recognize or skillfully manipulate objects. In addition, the importance and interest of haptic technology related to touch are increasing with the development of technologies such as VR and AR in recent years. So far, the focus is only on haptic technology based on mechanical devices. Especially, there are not many studies on tactile sensation in the field of brain-computer interface based on EEG. There have been some studies that measured the surface roughness of artificial structures in relation to EEG-based tactile sensation. However, most studies have used passive contact methods in which the object moves, while the human subject remains still. Additionally, there have been no EEG-based tactile studies of active skin touch. In reality, we directly move our hands to feel the sense of touch. Therefore, as a preliminary study for our future research, we collected EEG signals for tactile sensation upon skin touch based on active touch and compared and analyzed differences in brain changes during touch and movement tasks. Through time-frequency analysis and statistical analysis, significant differences in power changes in alpha, beta, gamma, and high-gamma regions were observed. In addition, major spatial differences were observed in the sensory-motor region of the brain.
Beyond Pointwise Submodularity: Non-Monotone Adaptive Submodular Maximization in Linear Time
Aug 11, 2020In this paper, we study the non-monotone adaptive submodular maximization problem subject to a cardinality constraint. We first revisit the adaptive random greedy algorithm proposed in \citep{gotovos2015non}, where they show that this algorithm achieves a $1/e$ approximation ratio if the objective function is adaptive submodular and pointwise submodular. It is not clear whether the same guarantee holds under adaptive submodularity (without resorting to pointwise submodularity) or not. Our first contribution is to show that the adaptive random greedy algorithm achieves a $1/e$ approximation ratio under adaptive submodularity. One limitation of the adaptive random greedy algorithm is that it requires $O(n\times k)$ value oracle queries, where $n$ is the size of the ground set and $k$ is the cardinality constraint. Our second contribution is to develop the first linear-time algorithm for the non-monotone adaptive submodular maximization problem. Our algorithm achieves a $1/e-\epsilon$ approximation ratio (this bound is improved to $1-1/e-\epsilon$ for monotone case), using only $O(n\epsilon^{-2}\log \epsilon^{-1})$ value oracle queries. Notably, $O(n\epsilon^{-2}\log \epsilon^{-1})$ is independent of the cardinality constraint.
Reproducible and Portable Big Data Analytics in the Cloud
Dec 17, 2021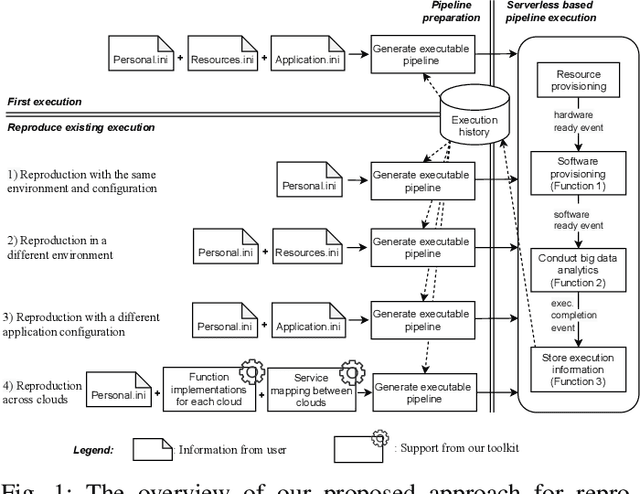
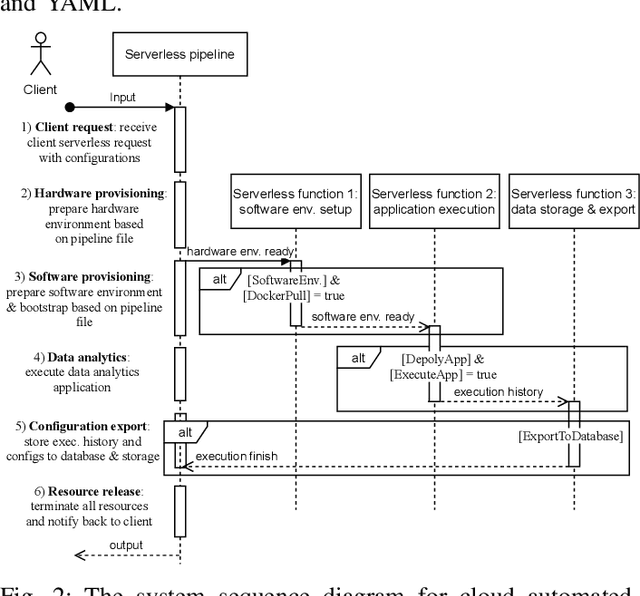
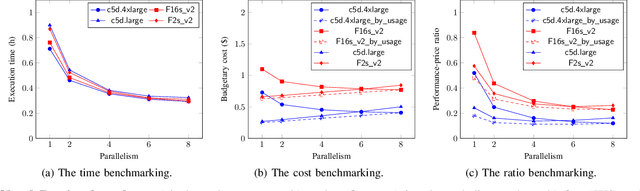
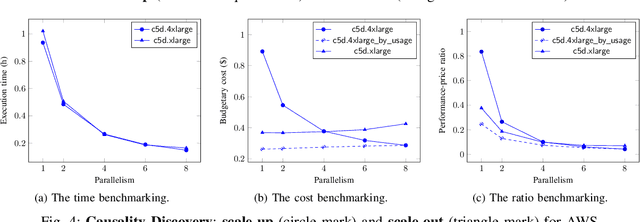
Cloud computing has become a major approach to enable reproducible computational experiments because of its support of on-demand hardware and software resource provisioning. Yet there are still two main difficulties in reproducing big data applications in the cloud. The first is how to automate end-to-end execution of big data analytics in the cloud including virtual distributed environment provisioning, network and security group setup, and big data analytics pipeline description and execution. The second is an application developed for one cloud, such as AWS or Azure, is difficult to reproduce in another cloud, a.k.a. vendor lock-in problem. To tackle these problems, we leverage serverless computing and containerization techniques for automatic scalable big data application execution and reproducibility, and utilize the adapter design pattern to enable application portability and reproducibility across different clouds. Based on the approach, we propose and develop an open-source toolkit that supports 1) on-demand distributed hardware and software environment provisioning, 2) automatic data and configuration storage for each execution, 3) flexible client modes based on user preferences, 4) execution history query, and 5) simple reproducibility of existing executions in the same environment or a different environment. We did extensive experiments on both AWS and Azure using three big data analytics applications that run on a virtual CPU/GPU cluster. Three main behaviors of our toolkit were benchmarked: i) execution overhead ratio for reproducibility support, ii) differences of reproducing the same application on AWS and Azure in terms of execution time, budgetary cost and cost-performance ratio, iii) differences between scale-out and scale-up approach for the same application on AWS and Azure.
Look at the Variance! Efficient Black-box Explanations with Sobol-based Sensitivity Analysis
Nov 07, 2021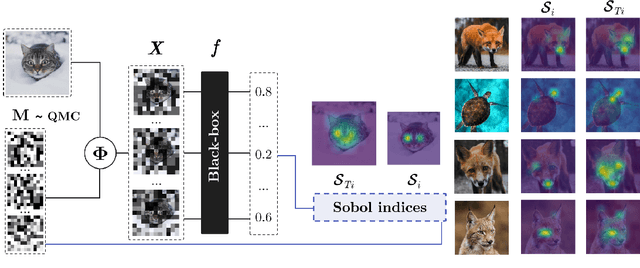
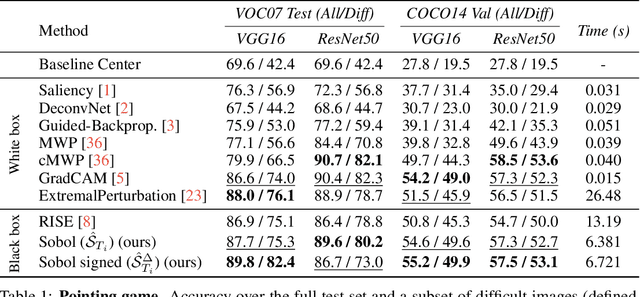
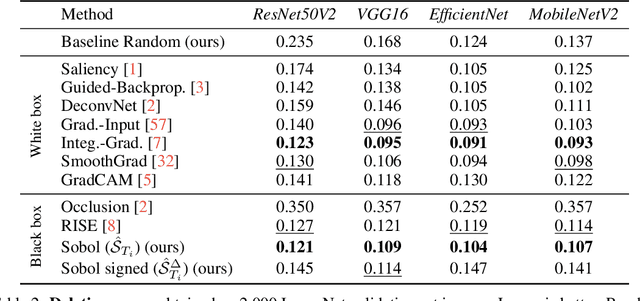
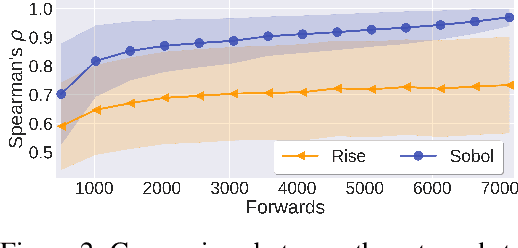
We describe a novel attribution method which is grounded in Sensitivity Analysis and uses Sobol indices. Beyond modeling the individual contributions of image regions, Sobol indices provide an efficient way to capture higher-order interactions between image regions and their contributions to a neural network's prediction through the lens of variance. We describe an approach that makes the computation of these indices efficient for high-dimensional problems by using perturbation masks coupled with efficient estimators to handle the high dimensionality of images. Importantly, we show that the proposed method leads to favorable scores on standard benchmarks for vision (and language models) while drastically reducing the computing time compared to other black-box methods -- even surpassing the accuracy of state-of-the-art white-box methods which require access to internal representations. Our code is freely available: https://github.com/fel-thomas/Sobol-Attribution-Method
A Novel Solution of an Elastic Net Regularization for Dementia Knowledge Discovery using Deep Learning
Aug 21, 2021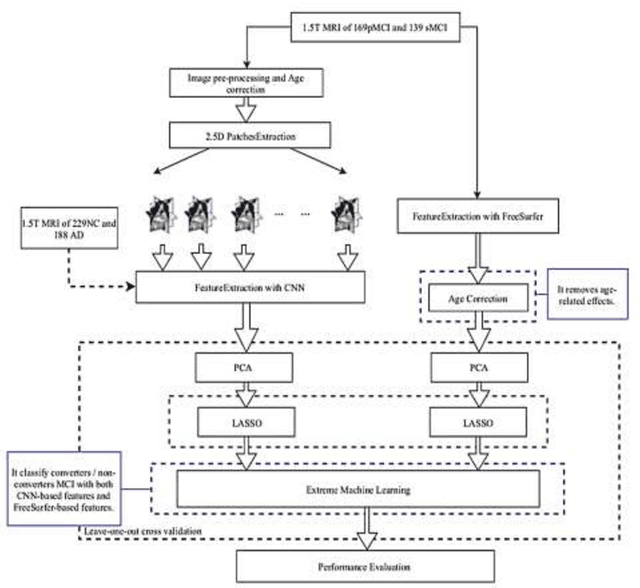

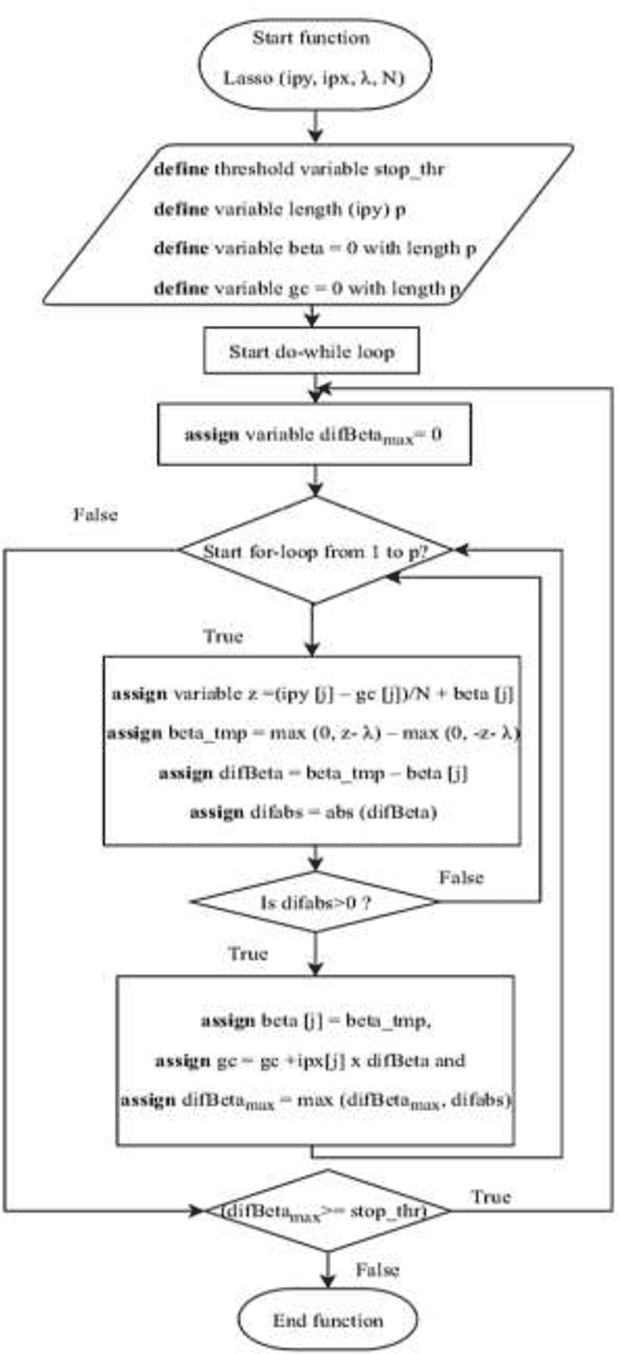
Background and Aim: Accurate classification of Magnetic Resonance Images (MRI) is essential to accurately predict Mild Cognitive Impairment (MCI) to Alzheimer's Disease (AD) conversion. Meanwhile, deep learning has been successfully implemented to classify and predict dementia disease. However, the accuracy of MRI image classification is low. This paper aims to increase the accuracy and reduce the processing time of classification through Deep Learning Architecture by using Elastic Net Regularization in Feature Selection. Methodology: The proposed system consists of Convolutional Neural Network (CNN) to enhance the accuracy of classification and prediction by using Elastic Net Regularization. Initially, the MRI images are fed into CNN for features extraction through convolutional layers alternate with pooling layers, and then through a fully connected layer. After that, the features extracted are subjected to Principle Component Analysis (PCA) and Elastic Net Regularization for feature selection. Finally, the selected features are used as an input to Extreme Machine Learning (EML) for the classification of MRI images. Results: The result shows that the accuracy of the proposed solution is better than the current system. In addition to that, the proposed method has improved the classification accuracy by 5% on average and reduced the processing time by 30 ~ 40 seconds on average. Conclusion: The proposed system is focused on improving the accuracy and processing time of MCI converters/non-converters classification. It consists of features extraction, feature selection, and classification using CNN, FreeSurfer, PCA, Elastic Net, Extreme Machine Learning. Finally, this study enhances the accuracy and the processing time by using Elastic Net Regularization, which provides important selected features for classification.
* 20 pages
Recurrent Neural Networks for Stochastic Control in Real-Time Bidding
Jun 12, 2020
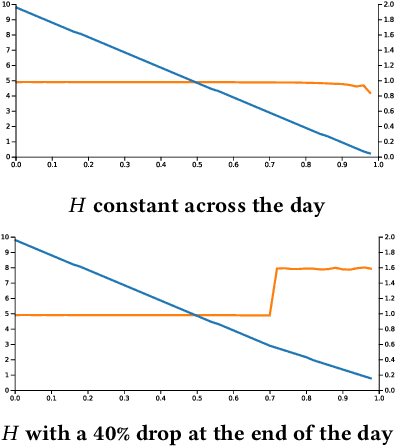
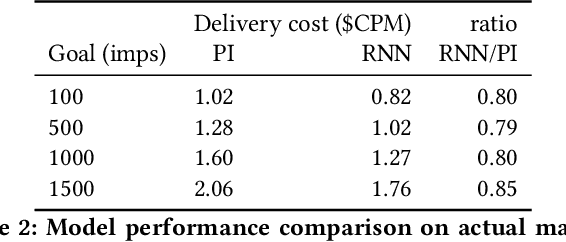
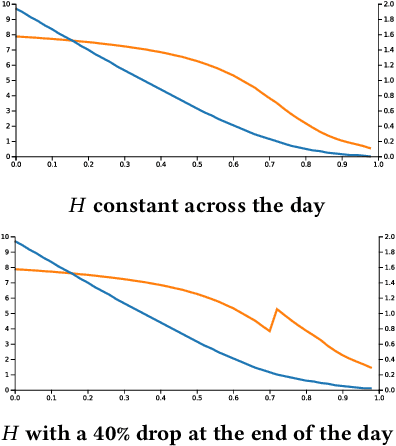
Bidding in real-time auctions can be a difficult stochastic control task; especially if underdelivery incurs strong penalties and the market is very uncertain. Most current works and implementations focus on optimally delivering a campaign given a reasonable forecast of the market. Practical implementations have a feedback loop to adjust and be robust to forecasting errors, but no implementation, to the best of our knowledge, uses a model of market risk and actively anticipates market shifts. Solving such stochastic control problems in practice is actually very challenging. This paper proposes an approximate solution based on a Recurrent Neural Network (RNN) architecture that is both effective and practical for implementation in a production environment. The RNN bidder provisions everything it needs to avoid missing its goal. It also deliberately falls short of its goal when buying the missing impressions would cost more than the penalty for not reaching it.
Wind Turbine Gearbox Condition Based Monitoring
Aug 30, 2021

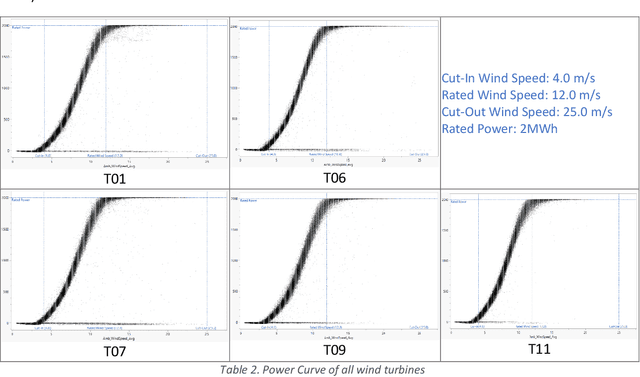
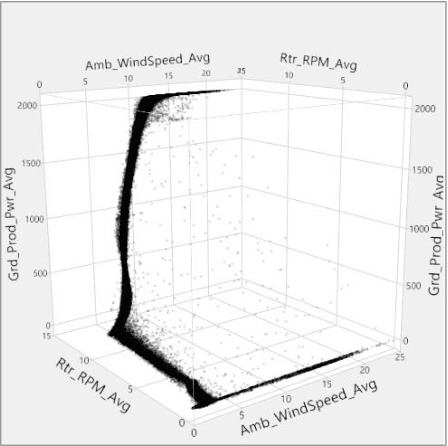
The main objective of this paper is finding effective gearbox condition monitoring methods by using continuously recorded monitoring SCADA (Supervisory Control and Data Accusation) data points. Typically for wind turbine gearbox condition monitoring; temperature readings, high frequency sounds and vibrations in addition to lubricant condition monitoring have been used. However, collection of such data, require shutting down equipment for installation of costly sensors and measuring lubricant quality. Meanwhile, operational data usually collected every 10 minutes, comprised of wind speed, power generated, pitch angle and similar performance parameters can be used for monitoring health of wind turbine components such as blades, gearbox and generator. This paper uses gear rotational speed for monitoring health of gearbox teeth; since gearbox teeth deterioration can be measured by monitoring rotor to generator rotation ratios over extended period of time. As nature of wind is turbulent with rapid fluctuations, a wind turbine may operate in variety of modes within relatively short period of time. Monitoring rotational speed ratio over time, requires consistent operational conditions such as wind speed and torques within the gearbox. This paper also introduces the concept of clustering such as Normal Mixture algorithm for dividing operating datasets into consistent subgroups, which are used for long term monitoring.