 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Frequency Effects on Syntactic Rule Learning in Transformers
Sep 14, 2021

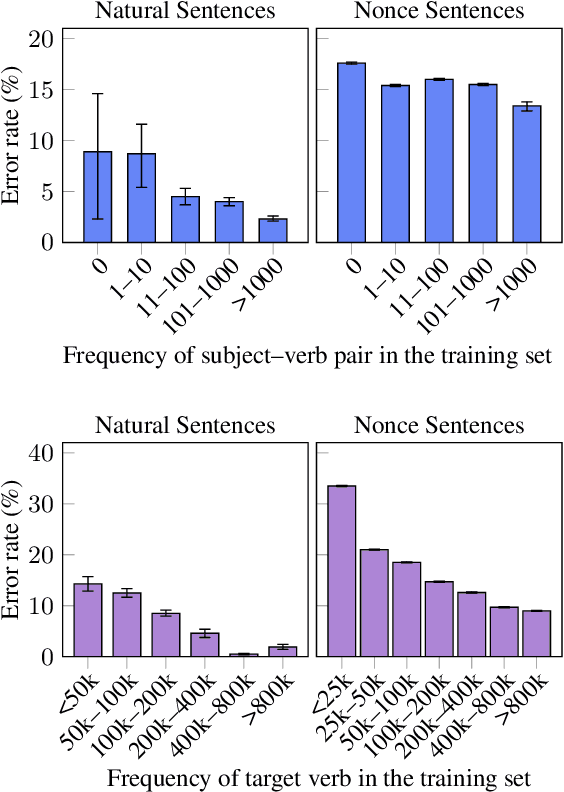
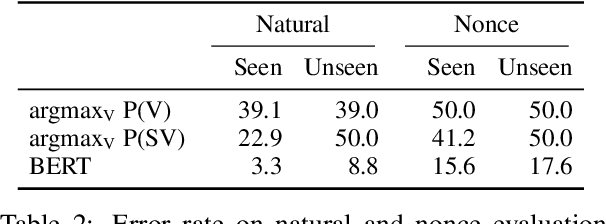
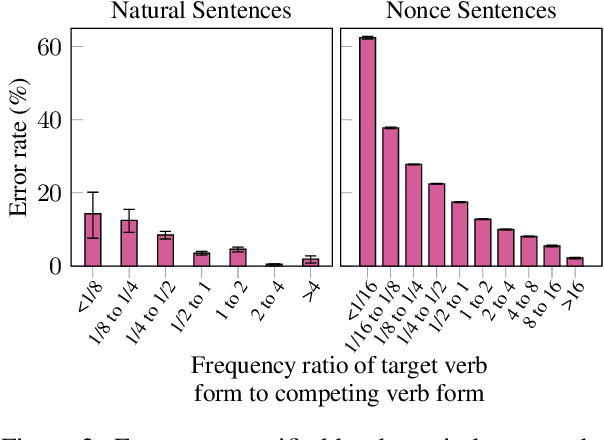
Pre-trained language models perform well on a variety of linguistic tasks that require symbolic reasoning, raising the question of whether such models implicitly represent abstract symbols and rules. We investigate this question using the case study of BERT's performance on English subject-verb agreement. Unlike prior work, we train multiple instances of BERT from scratch, allowing us to perform a series of controlled interventions at pre-training time. We show that BERT often generalizes well to subject-verb pairs that never occurred in training, suggesting a degree of rule-governed behavior. We also find, however, that performance is heavily influenced by word frequency, with experiments showing that both the absolute frequency of a verb form, as well as the frequency relative to the alternate inflection, are causally implicated in the predictions BERT makes at inference time. Closer analysis of these frequency effects reveals that BERT's behavior is consistent with a system that correctly applies the SVA rule in general but struggles to overcome strong training priors and to estimate agreement features (singular vs. plural) on infrequent lexical items.
Mean-Square Analysis with An Application to Optimal Dimension Dependence of Langevin Monte Carlo
Sep 08, 2021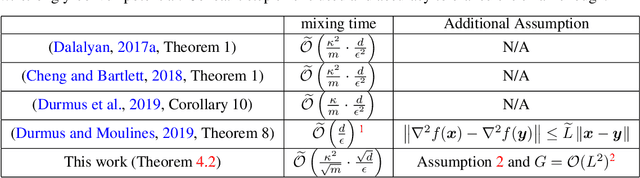
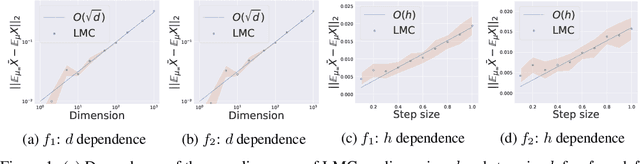
Sampling algorithms based on discretizations of Stochastic Differential Equations (SDEs) compose a rich and popular subset of MCMC methods. This work provides a general framework for the non-asymptotic analysis of sampling error in 2-Wasserstein distance, which also leads to a bound of mixing time. The method applies to any consistent discretization of contractive SDEs. When applied to Langevin Monte Carlo algorithm, it establishes $\tilde{\mathcal{O}}\left( \frac{\sqrt{d}}{\epsilon} \right)$ mixing time, without warm start, under the common log-smooth and log-strongly-convex conditions, plus a growth condition on the 3rd-order derivative of the potential of target measures at infinity. This bound improves the best previously known $\tilde{\mathcal{O}}\left( \frac{d}{\epsilon} \right)$ result and is optimal (in terms of order) in both dimension $d$ and accuracy tolerance $\epsilon$ for target measures satisfying the aforementioned assumptions. Our theoretical analysis is further validated by numerical experiments.
RayNet: Real-time Scene Arbitrary-shape Text Detection with Multiple Rays
Apr 11, 2021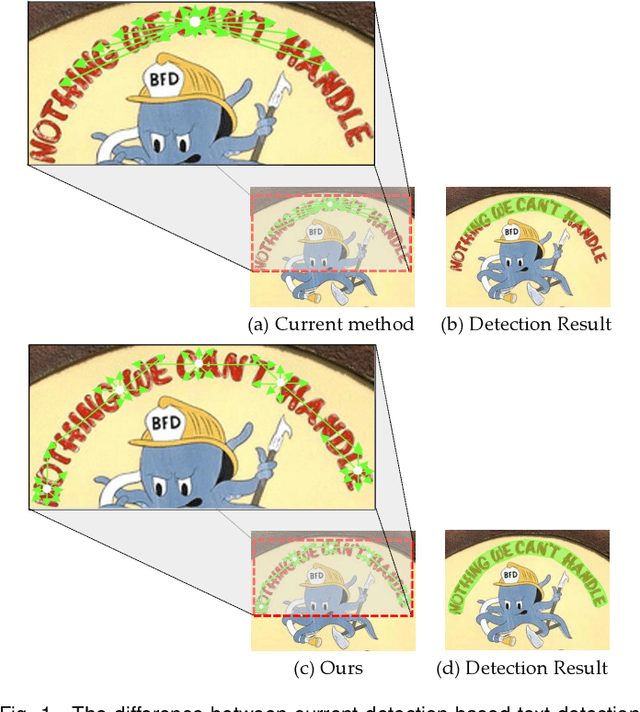
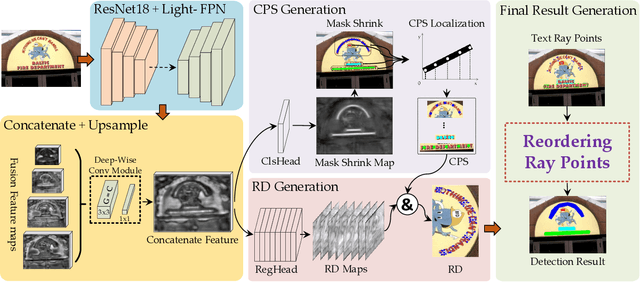
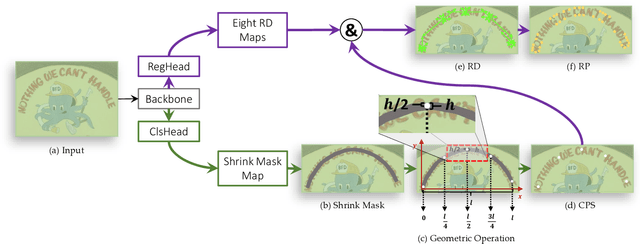
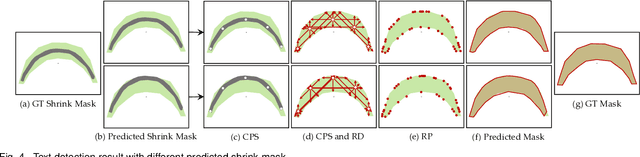
Existing object detection-based text detectors mainly concentrate on detecting horizontal and multioriented text. However, they do not pay enough attention to complex-shape text (curved or other irregularly shaped text). Recently, segmentation-based text detection methods have been introduced to deal with the complex-shape text; however, the pixel level processing increases the computational cost significantly. To further improve the accuracy and efficiency, we propose a novel detection framework for arbitrary-shape text detection, termed as RayNet. RayNet uses Center Point Set (CPS) and Ray Distance (RD) to fit text, where CPS is used to determine the text general position and the RD is combined with CPS to compute Ray Points (RP) to localize the text accurate shape. Since RP are disordered, we develop the Ray Points Connection (RPC) algorithm to reorder RP, which significantly improves the detection performance of complex-shape text. RayNet achieves impressive performance on existing curved text dataset (CTW1500) and quadrangle text dataset (ICDAR2015), which demonstrate its superiority against several state-of-the-art methods.
Neural Tangent Kernel of Matrix Product States: Convergence and Applications
Nov 28, 2021
In this work, we study the Neural Tangent Kernel (NTK) of Matrix Product States (MPS) and the convergence of its NTK in the infinite bond dimensional limit. We prove that the NTK of MPS asymptotically converges to a constant matrix during the gradient descent (training) process (and also the initialization phase) as the bond dimensions of MPS go to infinity by the observation that the variation of the tensors in MPS asymptotically goes to zero during training in the infinite limit. By showing the positive-definiteness of the NTK of MPS, the convergence of MPS during the training in the function space (space of functions represented by MPS) is guaranteed without any extra assumptions of the data set. We then consider the settings of (supervised) Regression with Mean Square Error (RMSE) and (unsupervised) Born Machines (BM) and analyze their dynamics in the infinite bond dimensional limit. The ordinary differential equations (ODEs) which describe the dynamics of the responses of MPS in the RMSE and BM are derived and solved in the closed-form. For the Regression, we consider Mercer Kernels (Gaussian Kernels) and find that the evolution of the mean of the responses of MPS follows the largest eigenvalue of the NTK. Due to the orthogonality of the kernel functions in BM, the evolution of different modes (samples) decouples and the "characteristic time" of convergence in training is obtained.
End-to-End Optimized Arrhythmia Detection Pipeline using Machine Learning for Ultra-Edge Devices
Nov 23, 2021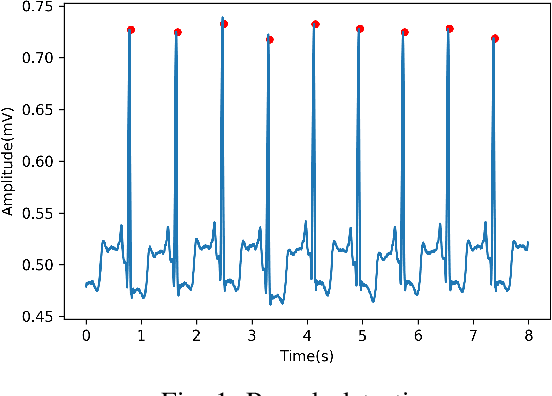
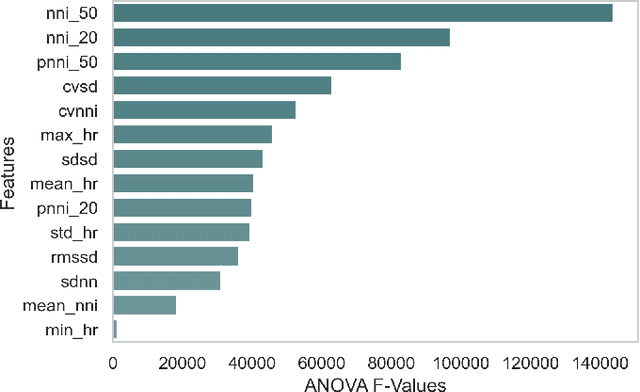
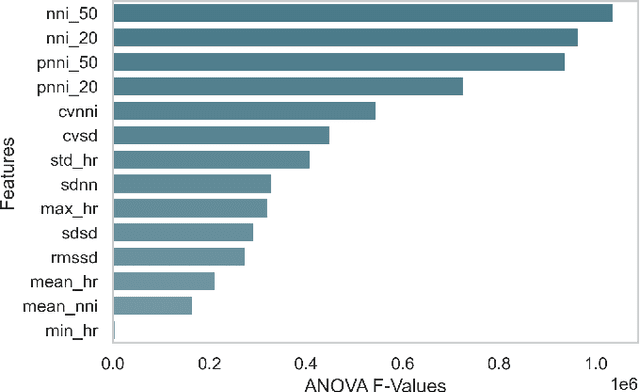
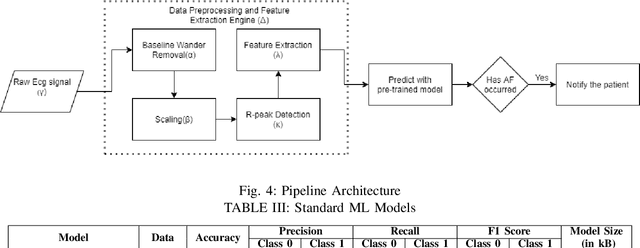
Atrial fibrillation (AF) is the most prevalent cardiac arrhythmia worldwide, with 2% of the population affected. It is associated with an increased risk of strokes, heart failure and other heart-related complications. Monitoring at-risk individuals and detecting asymptomatic AF could result in considerable public health benefits, as individuals with asymptomatic AF could take preventive measures with lifestyle changes. With increasing affordability to wearables, personalized health care is becoming more accessible. These personalized healthcare solutions require accurate classification of bio-signals while being computationally inexpensive. By making inferences on-device, we avoid issues inherent to cloud-based systems such as latency and network connection dependency. We propose an efficient pipeline for real-time Atrial Fibrillation Detection with high accuracy that can be deployed in ultra-edge devices. The feature engineering employed in this research catered to optimizing the resource-efficient classifier used in the proposed pipeline, which was able to outperform the best performing standard ML model by $10^5\times$ in terms of memory footprint with a mere trade-off of 2% classification accuracy. We also obtain higher accuracy of approximately 6% while consuming 403$\times$ lesser memory and being 5.2$\times$ faster compared to the previous state-of-the-art (SoA) embedded implementation.
Continuous Homeostatic Reinforcement Learning for Self-Regulated Autonomous Agents
Sep 14, 2021
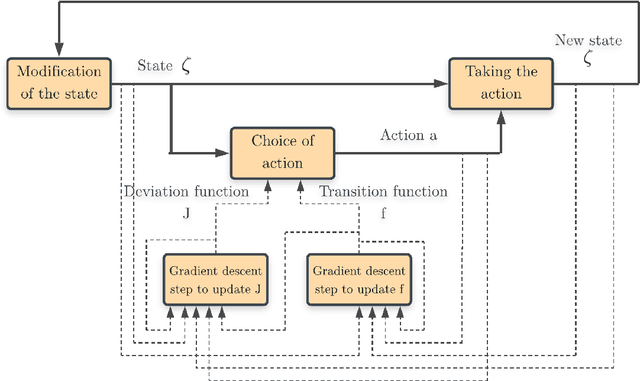
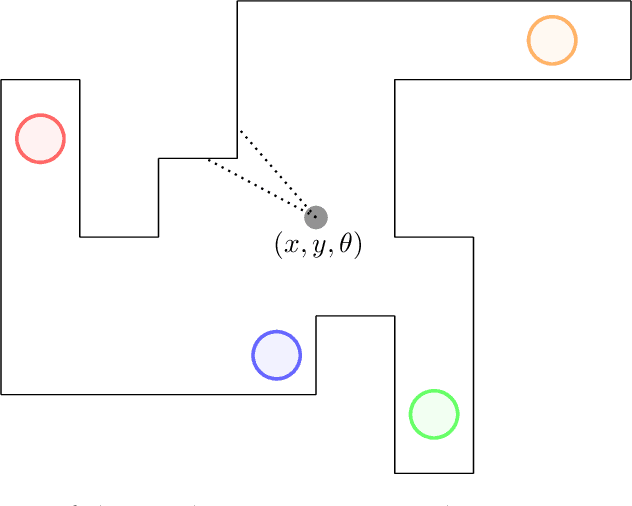

Homeostasis is a prevalent process by which living beings maintain their internal milieu around optimal levels. Multiple lines of evidence suggest that living beings learn to act to predicatively ensure homeostasis (allostasis). A classical theory for such regulation is drive reduction, where a function of the difference between the current and the optimal internal state. The recently introduced homeostatic regulated reinforcement learning theory (HRRL), by defining within the framework of reinforcement learning a reward function based on the internal state of the agent, makes the link between the theories of drive reduction and reinforcement learning. The HRRL makes it possible to explain multiple eating disorders. However, the lack of continuous change in the internal state of the agent with the discrete-time modeling has been so far a key shortcoming of the HRRL theory. Here, we propose an extension of the homeostatic reinforcement learning theory to a continuous environment in space and time, while maintaining the validity of the theoretical results and the behaviors explained by the model in discrete time. Inspired by the self-regulating mechanisms abundantly present in biology, we also introduce a model for the dynamics of the agent internal state, requiring the agent to continuously take actions to maintain homeostasis. Based on the Hamilton-Jacobi-Bellman equation and function approximation with neural networks, we derive a numerical scheme allowing the agent to learn directly how its internal mechanism works, and to choose appropriate action policies via reinforcement learning and an appropriate exploration of the environment. Our numerical experiments show that the agent does indeed learn to behave in a way that is beneficial to its survival in the environment, making our framework promising for modeling animal dynamics and decision-making.
Federated Expectation Maximization with heterogeneity mitigation and variance reduction
Nov 03, 2021
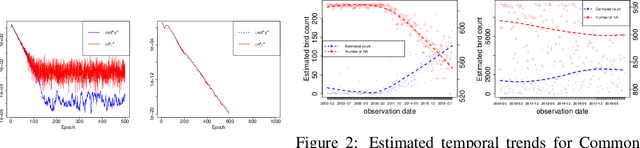
The Expectation Maximization (EM) algorithm is the default algorithm for inference in latent variable models. As in any other field of machine learning, applications of latent variable models to very large datasets make the use of advanced parallel and distributed architectures mandatory. This paper introduces FedEM, which is the first extension of the EM algorithm to the federated learning context. FedEM is a new communication efficient method, which handles partial participation of local devices, and is robust to heterogeneous distributions of the datasets. To alleviate the communication bottleneck, FedEM compresses appropriately defined complete data sufficient statistics. We also develop and analyze an extension of FedEM to further incorporate a variance reduction scheme. In all cases, we derive finite-time complexity bounds for smooth non-convex problems. Numerical results are presented to support our theoretical findings, as well as an application to federated missing values imputation for biodiversity monitoring.
Bifocal Neural ASR: Exploiting Keyword Spotting for Inference Optimization
Aug 03, 2021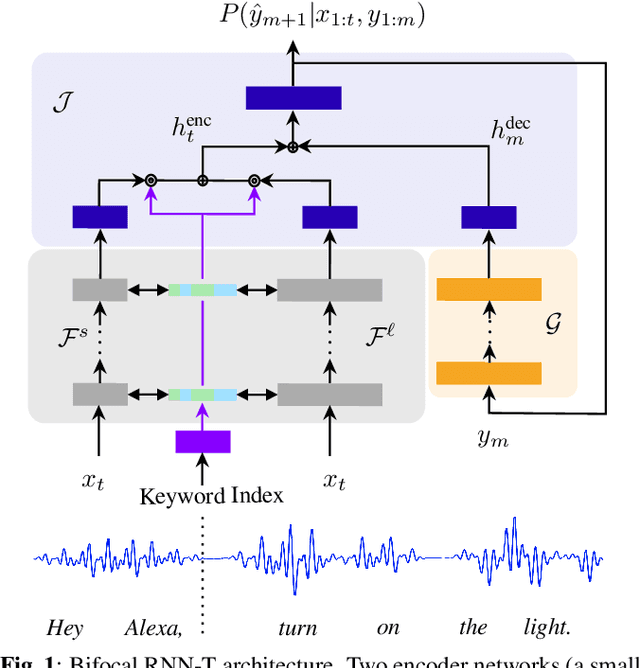
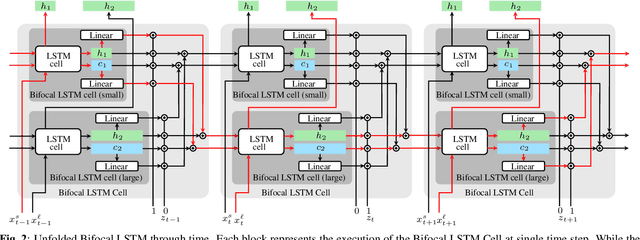
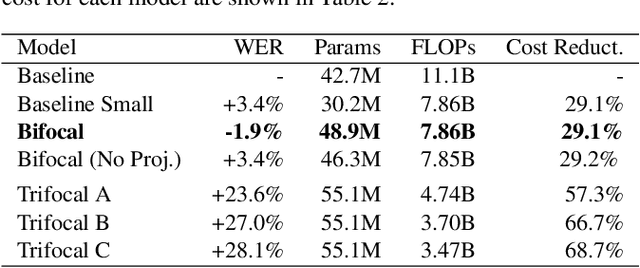
We present Bifocal RNN-T, a new variant of the Recurrent Neural Network Transducer (RNN-T) architecture designed for improved inference time latency on speech recognition tasks. The architecture enables a dynamic pivot for its runtime compute pathway, namely taking advantage of keyword spotting to select which component of the network to execute for a given audio frame. To accomplish this, we leverage a recurrent cell we call the Bifocal LSTM (BFLSTM), which we detail in the paper. The architecture is compatible with other optimization strategies such as quantization, sparsification, and applying time-reduction layers, making it especially applicable for deployed, real-time speech recognition settings. We present the architecture and report comparative experimental results on voice-assistant speech recognition tasks. Specifically, we show our proposed Bifocal RNN-T can improve inference cost by 29.1% with matching word error rates and only a minor increase in memory size.
Features or Shape? Tackling the False Dichotomy of Time Series Classification
Dec 20, 2019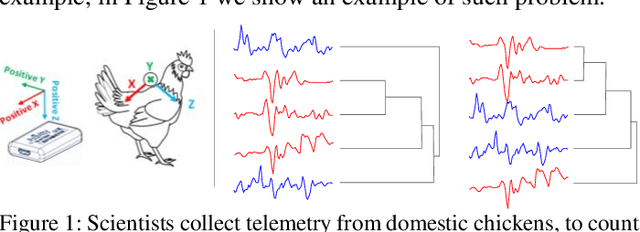
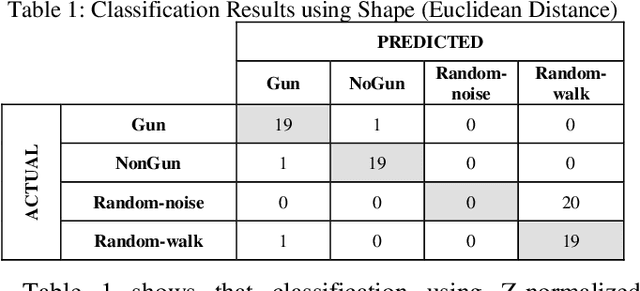
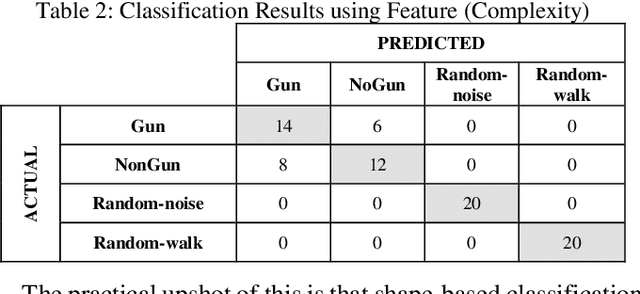
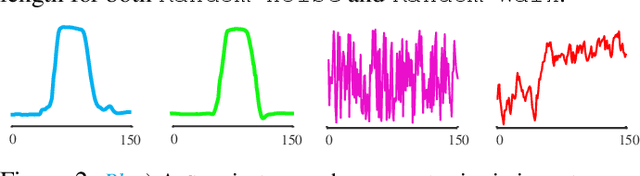
Time series classification is an important task in its own right, and it is often a precursor to further downstream analytics. To date, virtually all works in the literature have used either shape-based classification using a distance measure or feature-based classification after finding some suitable features for the domain. It seems to be underappreciated that in many datasets it is the case that some classes are best discriminated with features, while others are best discriminated with shape. Thus, making the shape vs. feature choice will condemn us to poor results, at least for some classes. In this work, we propose a new model for classifying time series that allows the use of both shape and feature-based measures, when warranted. Our algorithm automatically decides which approach is best for which class, and at query time chooses which classifier to trust the most. We evaluate our idea on real world datasets and demonstrate that our ideas produce statistically significant improvement in classification accuracy.
Integrating Physiological Time Series and Clinical Notes with Deep Learning for Improved ICU Mortality Prediction
Mar 24, 2020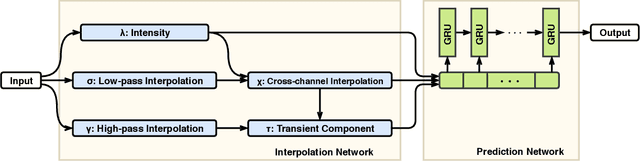
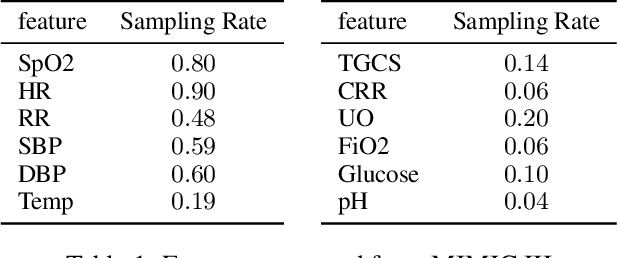
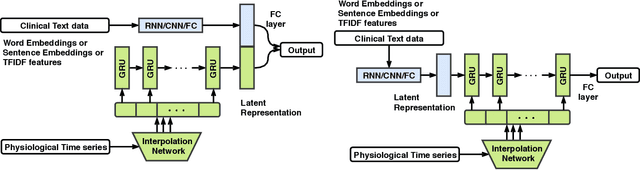
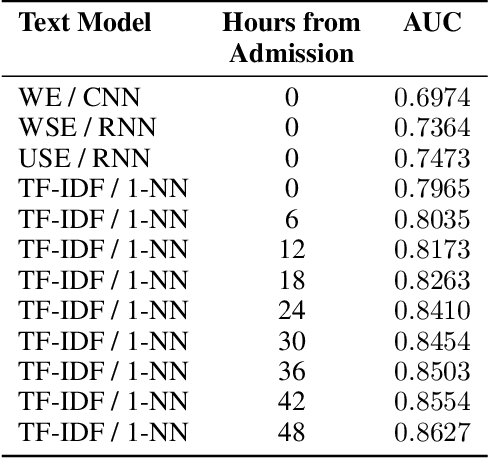
Intensive Care Unit Electronic Health Records (ICU EHRs) store multimodal data about patients including clinical notes, sparse and irregularly sampled physiological time series, lab results, and more. To date, most methods designed to learn predictive models from ICU EHR data have focused on a single modality. In this paper, we leverage the recently proposed interpolation-prediction deep learning architecture(Shukla and Marlin 2019) as a basis for exploring how physiological time series data and clinical notes can be integrated into a unified mortality prediction model. We study both early and late fusion approaches and demonstrate how the relative predictive value of clinical text and physiological data change over time. Our results show that a late fusion approach can provide a statistically significant improvement in mortality prediction performance over using individual modalities in isolation.