 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
LiDAR Cluster First and Camera Inference Later: A New Perspective Towards Autonomous Driving
Nov 18, 2021

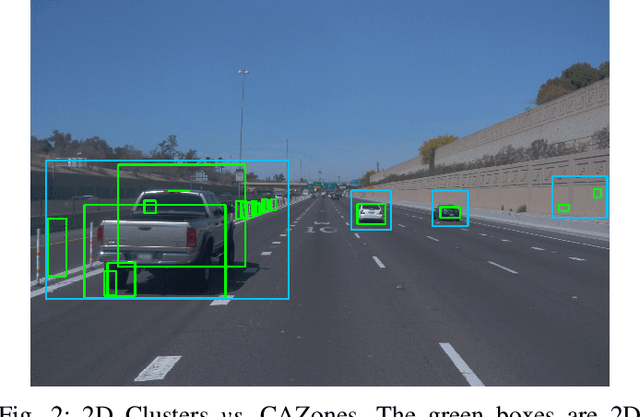


Object detection in state-of-the-art Autonomous Vehicles (AV) framework relies heavily on deep neural networks. Typically, these networks perform object detection uniformly on the entire camera LiDAR frames. However, this uniformity jeopardizes the safety of the AV by giving the same priority to all objects in the scenes regardless of their risk of collision to the AV. In this paper, we present a new end-to-end pipeline for AV that introduces the concept of LiDAR cluster first and camera inference later to detect and classify objects. The benefits of our proposed framework are twofold. First, our pipeline prioritizes detecting objects that pose a higher risk of collision to the AV, giving more time for the AV to react to unsafe conditions. Second, it also provides, on average, faster inference speeds compared to popular deep neural network pipelines. We design our framework using the real-world datasets, the Waymo Open Dataset, solving challenges arising from the limitations of LiDAR sensors and object detection algorithms. We show that our novel object detection pipeline prioritizes the detection of higher risk objects while simultaneously achieving comparable accuracy and a 25% higher average speed compared to camera inference only.
Anomaly Subsequence Detection with Dynamic Local Density for Time Series
Jun 28, 2019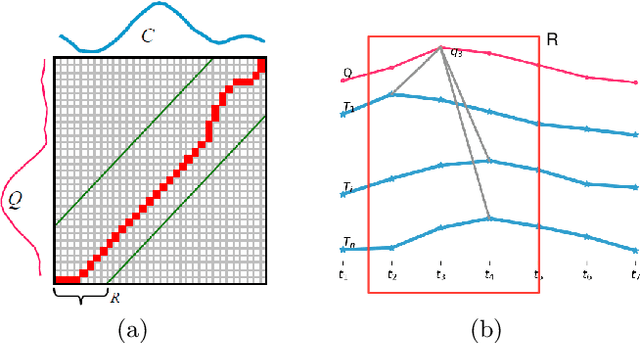
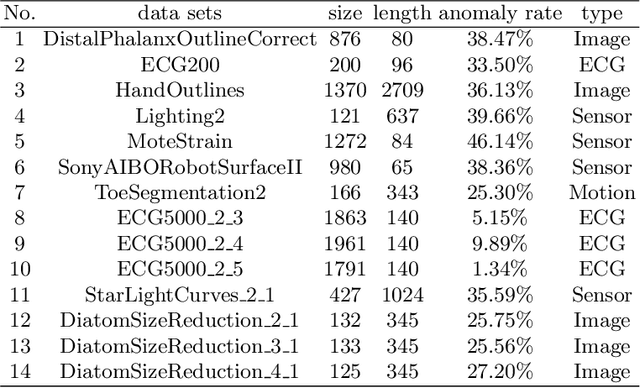
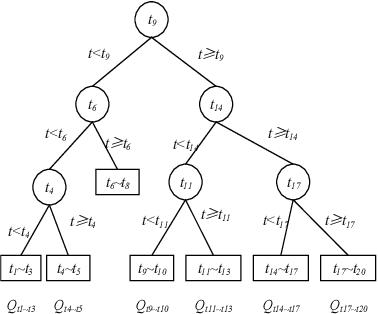
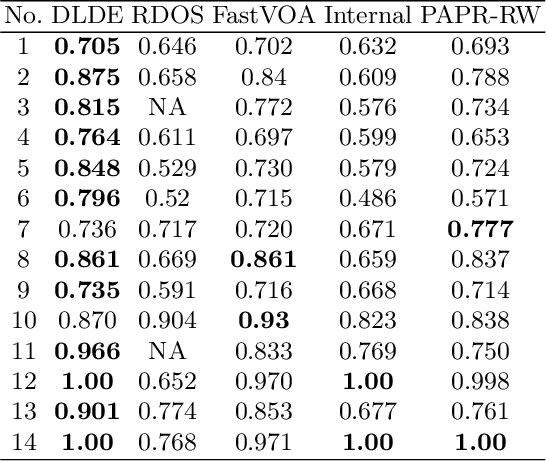
Anomaly subsequence detection is to detect inconsistent data, which always contains important information, among time series. Due to the high dimensionality of the time series, traditional anomaly detection often requires a large time overhead; furthermore, even if the dimensionality reduction techniques can improve the efficiency, they will lose some information and suffer from time drift and parameter tuning. In this paper, we propose a new anomaly subsequence detection with Dynamic Local Density Estimation (DLDE) to improve the detection effect without losing the trend information by dynamically dividing the time series using Time Split Tree. In order to avoid the impact of the hash function and the randomness of dynamic time segments, ensemble learning is used. Experimental results on different types of data sets verify that the proposed model outperforms the state-of-art methods, and the accuracy has big improvement.
Prosody-TTS: An end-to-end speech synthesis system with prosody control
Oct 06, 2021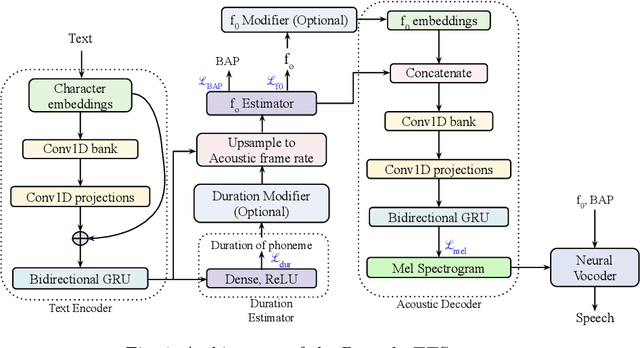
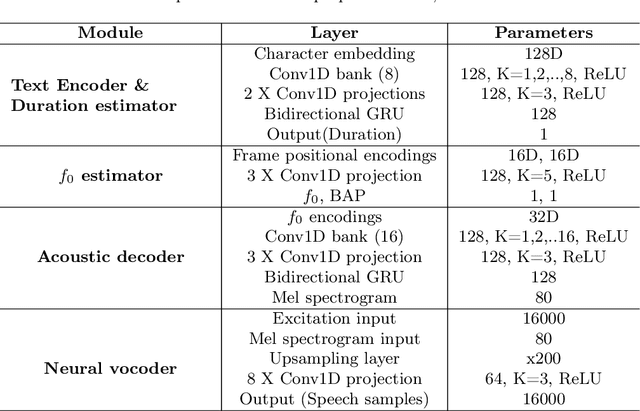
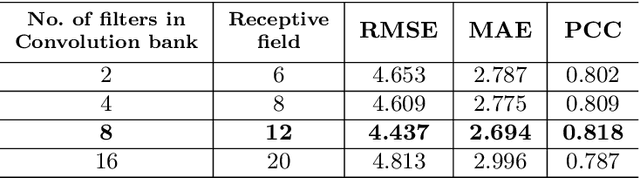
End-to-end text-to-speech synthesis systems achieved immense success in recent times, with improved naturalness and intelligibility. However, the end-to-end models, which primarily depend on the attention-based alignment, do not offer an explicit provision to modify/incorporate the desired prosody while synthesizing the signal. Moreover, the state-of-the-art end-to-end systems use autoregressive models for synthesis, making the prediction sequential. Hence, the inference time and the computational complexity are quite high. This paper proposes Prosody-TTS, an end-to-end speech synthesis model that combines the advantages of statistical parametric models and end-to-end neural network models. It also has a provision to modify or incorporate the desired prosody by controlling the fundamental frequency (f0) and the phone duration. Generating speech samples with appropriate prosody and rhythm helps in improving the naturalness of the synthesized speech. We explicitly model the duration of the phoneme and the f0 to have control over them during the synthesis. The model is trained in an end-to-end fashion to directly generate the speech waveform from the input text, which in turn depends on the auxiliary subtasks of predicting the phoneme duration, f0, and mel spectrogram. Experiments on the Telugu language data of the IndicTTS database show that the proposed Prosody-TTS model achieves state-of-the-art performance with a mean opinion score of 4.08, with a very low inference time.
Adaptive Newton Sketch: Linear-time Optimization with Quadratic Convergence and Effective Hessian Dimensionality
May 15, 2021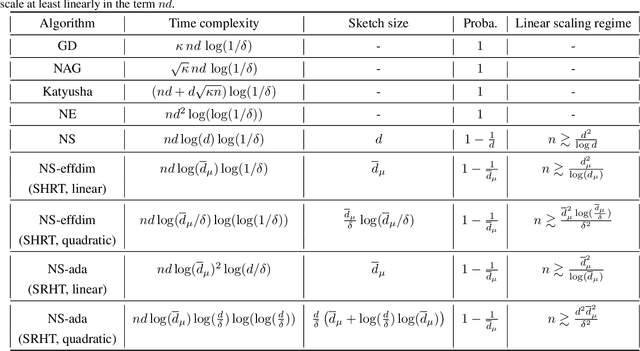
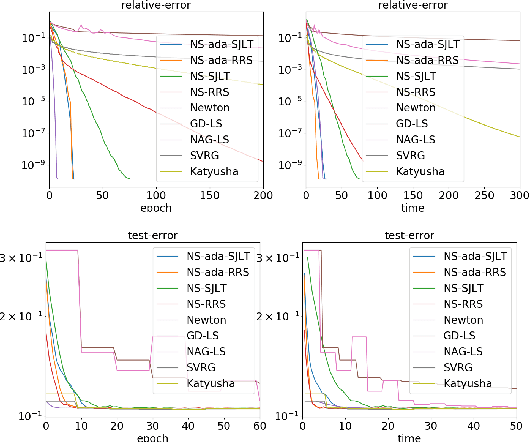
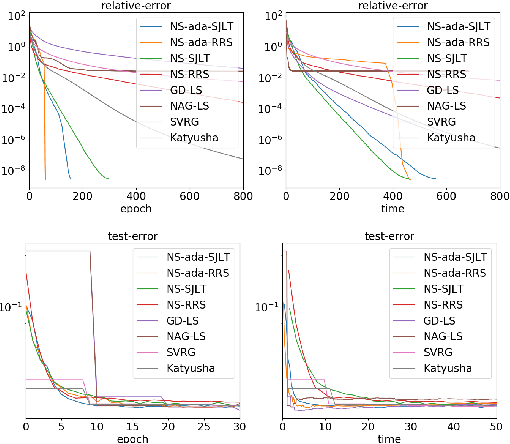
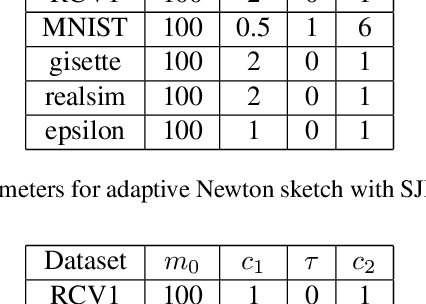
We propose a randomized algorithm with quadratic convergence rate for convex optimization problems with a self-concordant, composite, strongly convex objective function. Our method is based on performing an approximate Newton step using a random projection of the Hessian. Our first contribution is to show that, at each iteration, the embedding dimension (or sketch size) can be as small as the effective dimension of the Hessian matrix. Leveraging this novel fundamental result, we design an algorithm with a sketch size proportional to the effective dimension and which exhibits a quadratic rate of convergence. This result dramatically improves on the classical linear-quadratic convergence rates of state-of-the-art sub-sampled Newton methods. However, in most practical cases, the effective dimension is not known beforehand, and this raises the question of how to pick a sketch size as small as the effective dimension while preserving a quadratic convergence rate. Our second and main contribution is thus to propose an adaptive sketch size algorithm with quadratic convergence rate and which does not require prior knowledge or estimation of the effective dimension: at each iteration, it starts with a small sketch size, and increases it until quadratic progress is achieved. Importantly, we show that the embedding dimension remains proportional to the effective dimension throughout the entire path and that our method achieves state-of-the-art computational complexity for solving convex optimization programs with a strongly convex component.
EEG-based Classification of Drivers Attention using Convolutional Neural Network
Aug 23, 2021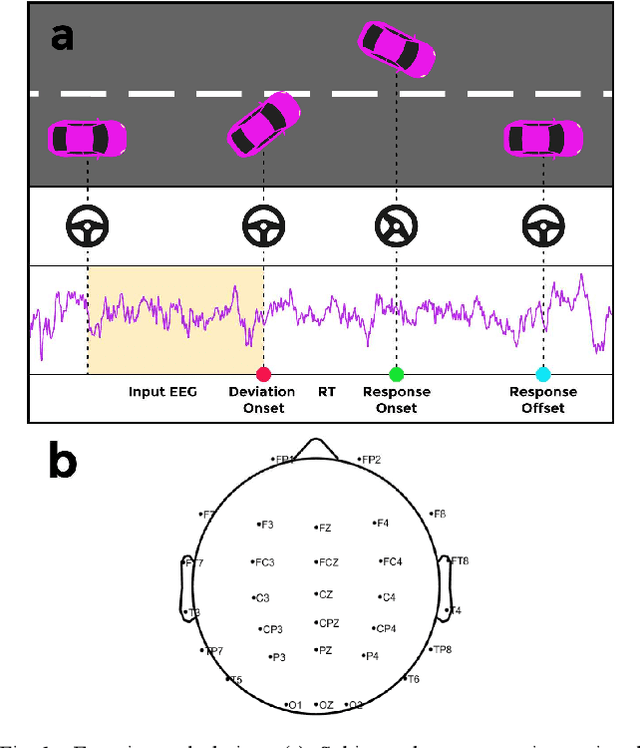
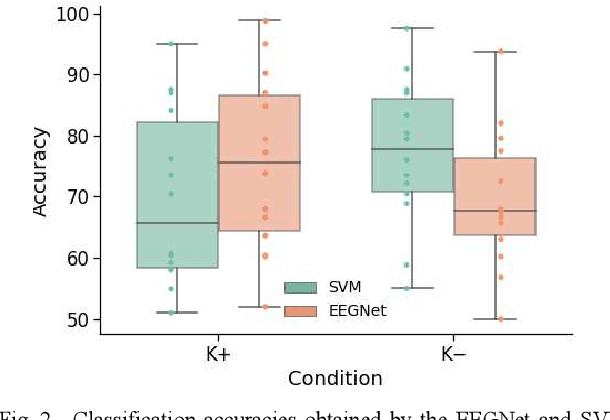
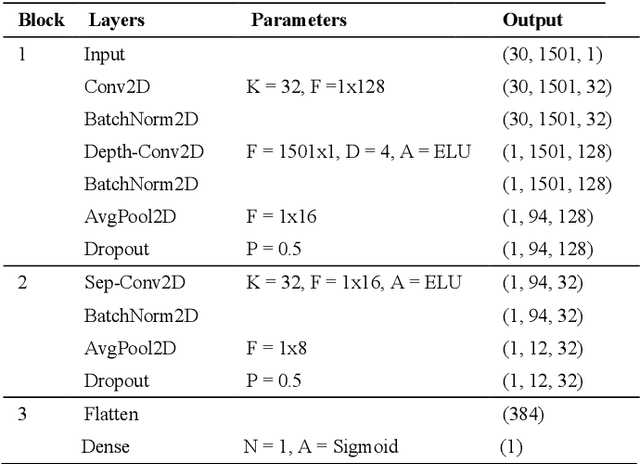
Accurate detection of a drivers attention state can help develop assistive technologies that respond to unexpected hazards in real time and therefore improve road safety. This study compares the performance of several attention classifiers trained on participants brain activity. Participants performed a driving task in an immersive simulator where the car randomly deviated from the cruising lane. They had to correct the deviation and their response time was considered as an indicator of attention level. Participants repeated the task in two sessions; in one session they received kinesthetic feedback and in another session no feedback. Using their EEG signals, we trained three attention classifiers; a support vector machine (SVM) using EEG spectral band powers, and a Convolutional Neural Network (CNN) using either spectral features or the raw EEG data. Our results indicated that the CNN model trained on raw EEG data obtained under kinesthetic feedback achieved the highest accuracy (89%). While using a participants own brain activity to train the model resulted in the best performances, inter-subject transfer learning still performed high (75%), showing promise for calibration-free Brain-Computer Interface (BCI) systems. Our findings show that CNN and raw EEG signals can be employed for effective training of a passive BCI for real-time attention classification.
Globally Consistent 3D LiDAR Mapping with GPU-accelerated GICP Matching Cost Factors
Sep 15, 2021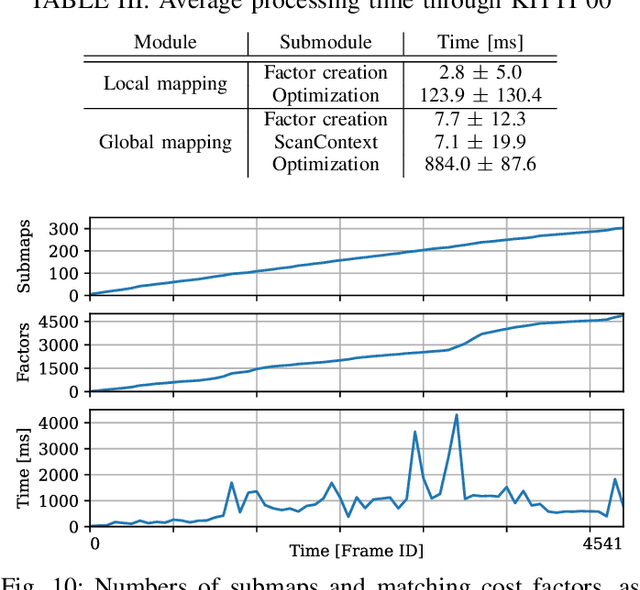
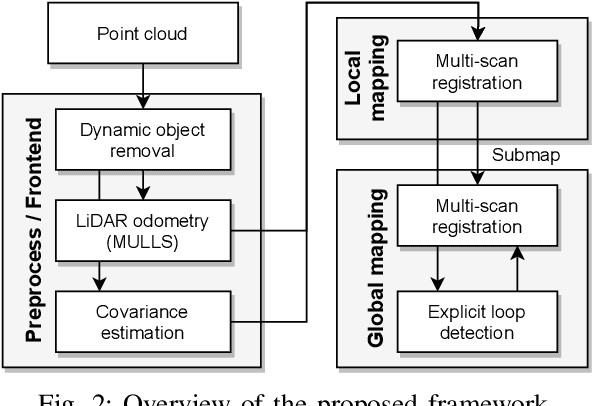
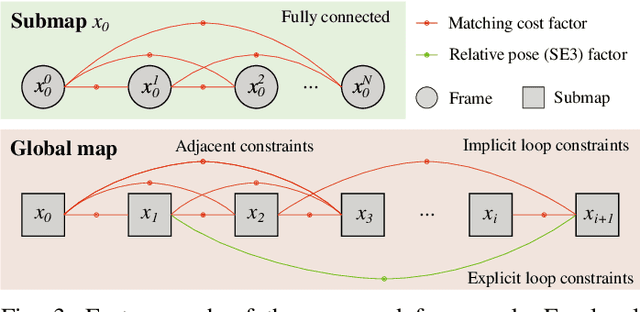
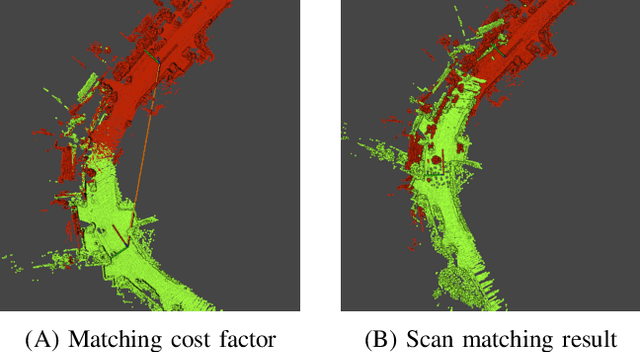
This paper presents a real-time 3D LiDAR mapping framework based on global matching cost minimization. The proposed method constructs a factor graph that directly minimizes matching costs between frames over the entire map, unlike pose graph-based approaches that minimize errors in the pose space. For real-time global matching cost minimization, we use a voxel data association-based GICP matching cost factor that is able to fully leverage GPU parallel processing. The combination of the matching cost factor and GPU computation enables constraint of the relative pose between frames with a small overlap and creation of a densely connected factor graph. The mapping process is managed based on a voxel-based overlap metric that can quickly be evaluated on a GPU. We incorporate the proposed method with an external loop detection method in order to help the voxel-based matching cost factors to avoid convergence in a local solution. The experimental result on the KITTI dataset shows that the proposed approach improves the estimation accuracy of long trajectories.
Machine Learning-Assisted E-jet Printing of Organic Flexible Biosensors
Nov 07, 2021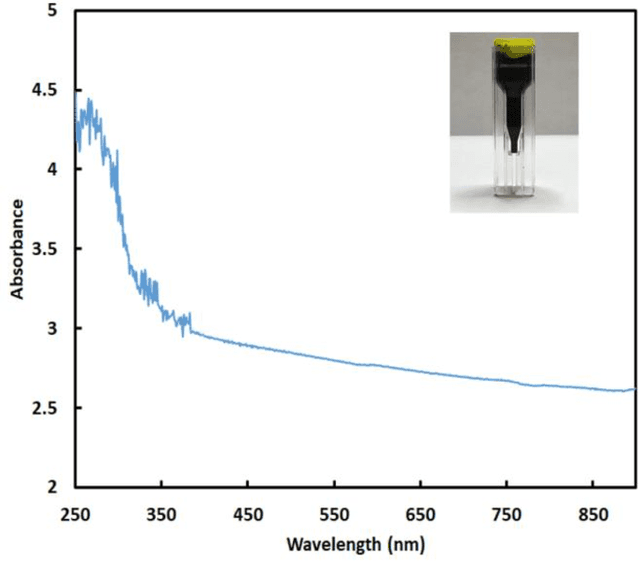
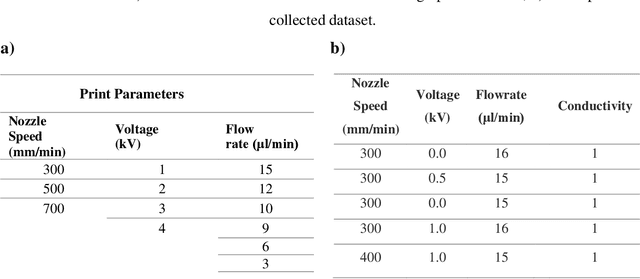

Electrohydrodynamic-jet (e-jet) printing technique enables the high-resolution printing of complex soft electronic devices. As such, it has an unmatched potential for becoming the conventional technique for printing soft electronic devices. In this study, the electrical conductivity of the e-jet printed circuits was studied as a function of key printing parameters (nozzle speed, ink flow rate, and voltage). The collected experimental dataset was then used to train a machine learning algorithm to establish models capable of predicting the characteristics of the printed circuits in real-time. Precision parameters were compared to evaluate the supervised classification models. Since decision tree methods could not increase the accuracy higher than 71%, more advanced algorithms are performed on our dataset to improve the precision of model. According to F-measure values, the K-NN model (k=10) and random forest are the best methods to classify the conductivity of electrodes. The highest accuracy of AdaBoost ensemble learning has resulted in the range of 10-15 trees (87%).
Romanian Speech Recognition Experiments from the ROBIN Project
Nov 23, 2021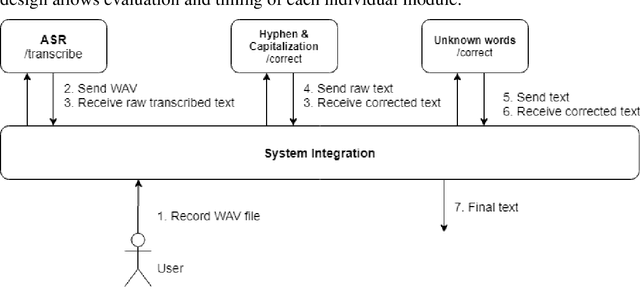
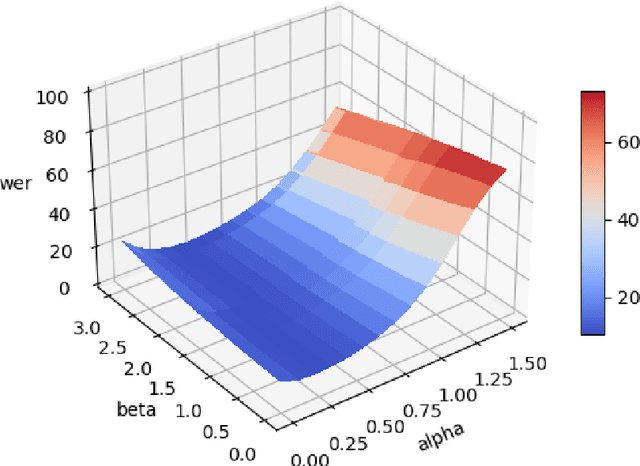
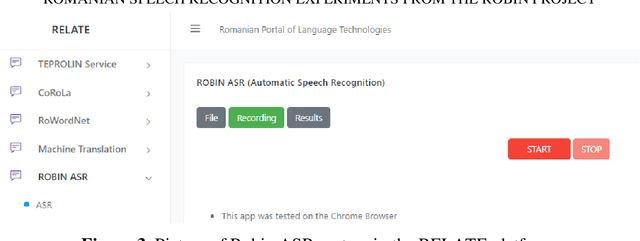
One of the fundamental functionalities for accepting a socially assistive robot is its communication capabilities with other agents in the environment. In the context of the ROBIN project, situational dialogue through voice interaction with a robot was investigated. This paper presents different speech recognition experiments with deep neural networks focusing on producing fast (under 100ms latency from the network itself), while still reliable models. Even though one of the key desired characteristics is low latency, the final deep neural network model achieves state of the art results for recognizing Romanian language, obtaining a 9.91% word error rate (WER), when combined with a language model, thus improving over the previous results while offering at the same time an improved runtime performance. Additionally, we explore two modules for correcting the ASR output (hyphen and capitalization restoration and unknown words correction), targeting the ROBIN project's goals (dialogue in closed micro-worlds). We design a modular architecture based on APIs allowing an integration engine (either in the robot or external) to chain together the available modules as needed. Finally, we test the proposed design by integrating it in the RELATE platform and making the ASR service available to web users by either uploading a file or recording new speech.
Adding more data does not always help: A study in medical conversation summarization with PEGASUS
Nov 28, 2021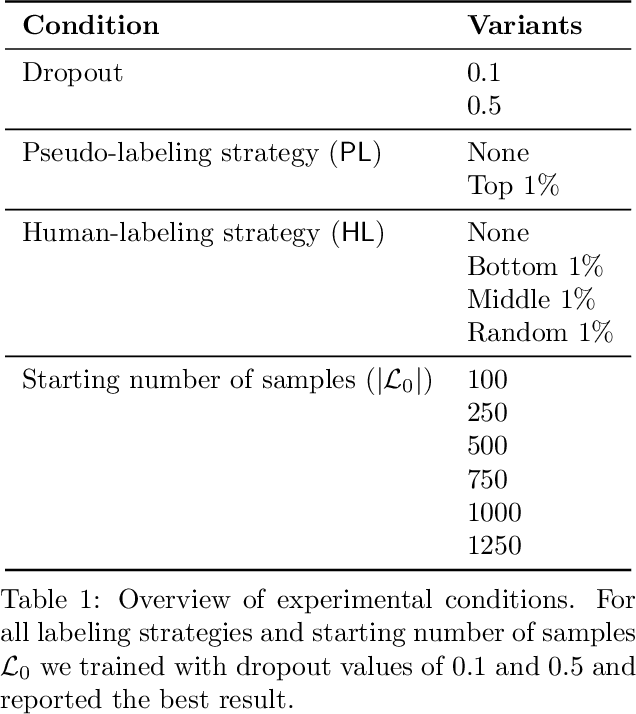
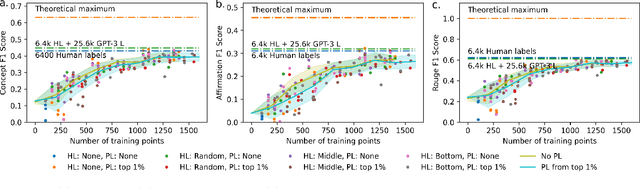
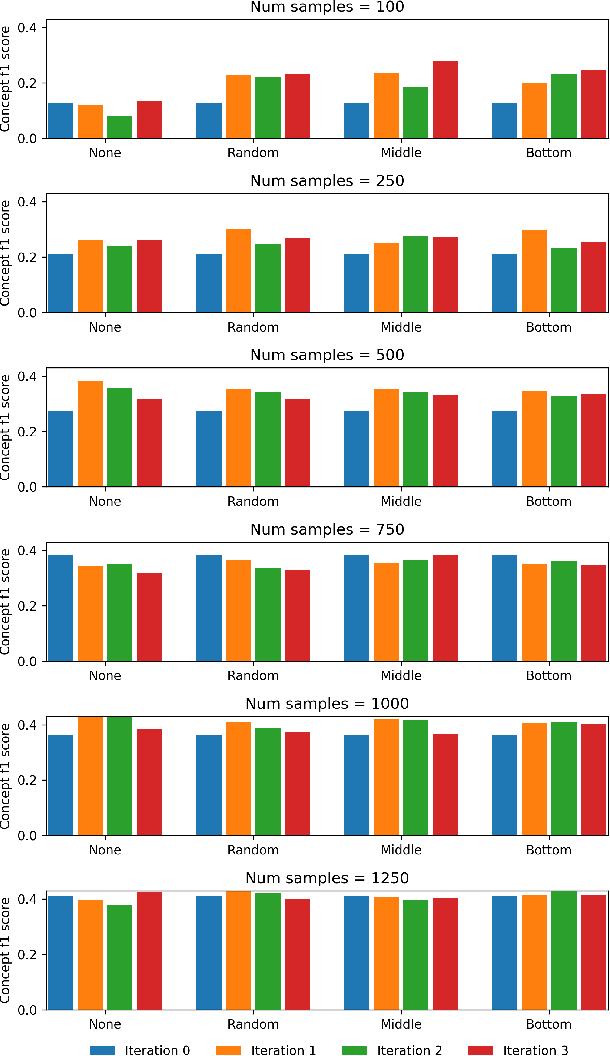
Medical conversation summarization is integral in capturing information gathered during interactions between patients and physicians. Summarized conversations are used to facilitate patient hand-offs between physicians, and as part of providing care in the future. Summaries, however, can be time-consuming to produce and require domain expertise. Modern pre-trained NLP models such as PEGASUS have emerged as capable alternatives to human summarization, reaching state-of-the-art performance on many summarization benchmarks. However, many downstream tasks still require at least moderately sized datasets to achieve satisfactory performance. In this work we (1) explore the effect of dataset size on transfer learning medical conversation summarization using PEGASUS and (2) evaluate various iterative labeling strategies in the low-data regime, following their success in the classification setting. We find that model performance saturates with increase in dataset size and that the various active-learning strategies evaluated all show equivalent performance consistent with simple dataset size increase. We also find that naive iterative pseudo-labeling is on-par or slightly worse than no pseudo-labeling. Our work sheds light on the successes and challenges of translating low-data regime techniques in classification to medical conversation summarization and helps guides future work in this space. Relevant code available at \url{https://github.com/curai/curai-research/tree/main/medical-summarization-ML4H-2021}.
Differentially Private Approximate Quantiles
Oct 11, 2021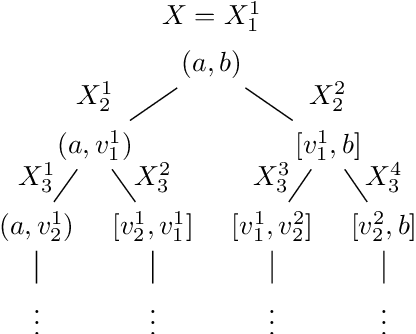
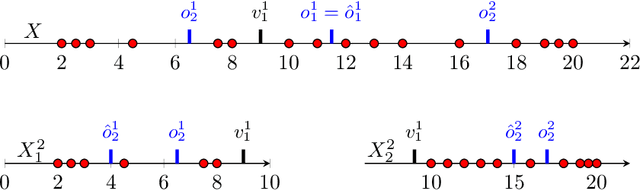
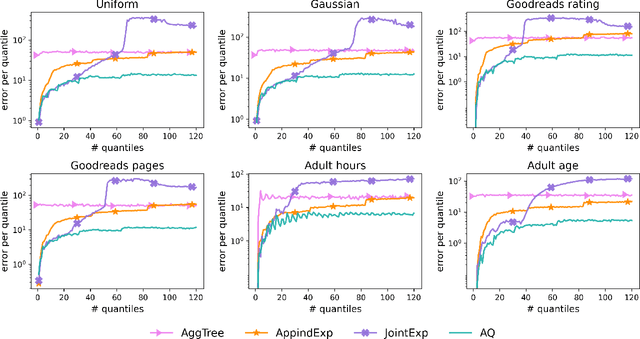
In this work we study the problem of differentially private (DP) quantiles, in which given dataset $X$ and quantiles $q_1, ..., q_m \in [0,1]$, we want to output $m$ quantile estimations which are as close as possible to the true quantiles and preserve DP. We describe a simple recursive DP algorithm, which we call ApproximateQuantiles (AQ), for this task. We give a worst case upper bound on its error, and show that its error is much lower than of previous implementations on several different datasets. Furthermore, it gets this low error while running time two orders of magnitude faster that the best previous implementation.