 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Accelerating Edge Intelligence via Integrated Sensing and Communication
Jul 20, 2021
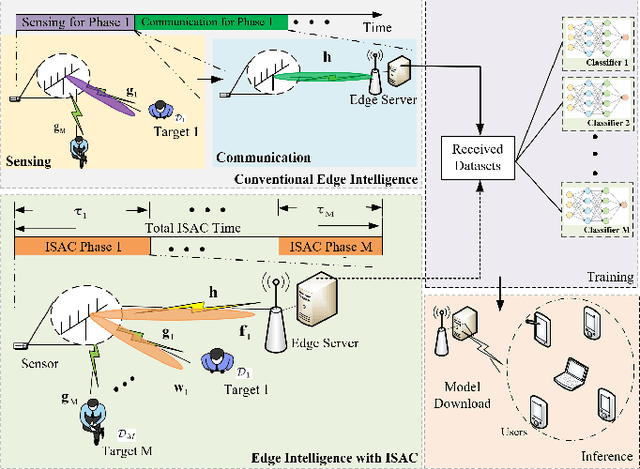
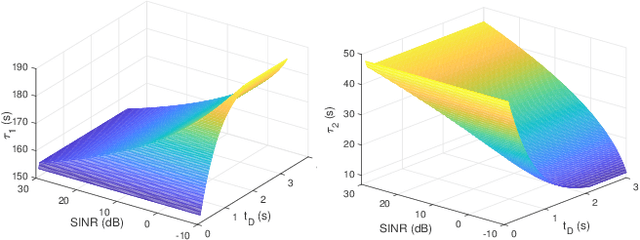
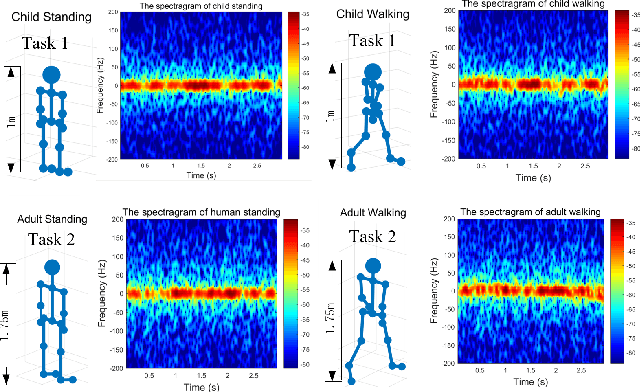
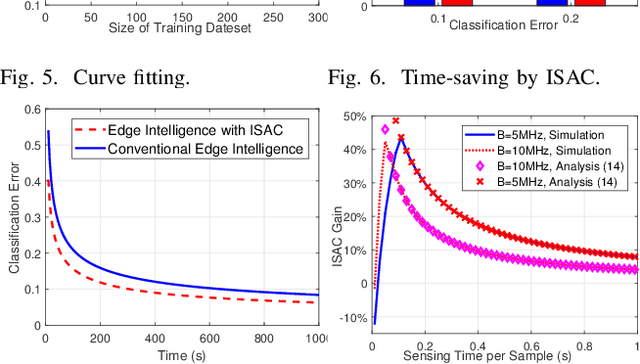
Realizing edge intelligence consists of sensing, communication, training, and inference stages. Conventionally, the sensing and communication stages are executed sequentially, which results in excessive amount of dataset generation and uploading time. This paper proposes to accelerate edge intelligence via integrated sensing and communication (ISAC). As such, the sensing and communication stages are merged so as to make the best use of the wireless signals for the dual purpose of dataset generation and uploading. However, ISAC also introduces additional interference between sensing and communication functionalities. To address this challenge, this paper proposes a classification error minimization formulation to design the ISAC beamforming and time allocation. Globally optimal solution is derived via the rank-1 guaranteed semidefinite relaxation, and performance analysis is performed to quantify the ISAC gain. Simulation results are provided to verify the effectiveness of the proposed ISAC scheme. Interestingly, it is found that when the sensing time dominates the communication time, ISAC is always beneficial. However, when the communication time dominates, the edge intelligence with ISAC scheme may not be better than that with the conventional scheme, since ISAC introduces harmful interference between the sensing and communication signals.
Learning to Solve Combinatorial Optimization Problems on Real-World Graphs in Linear Time
Jun 06, 2020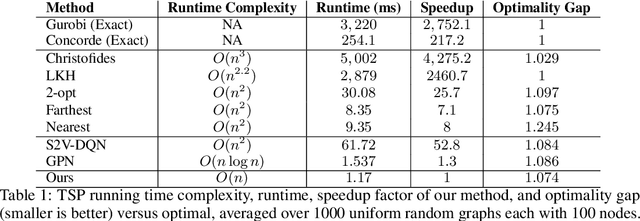
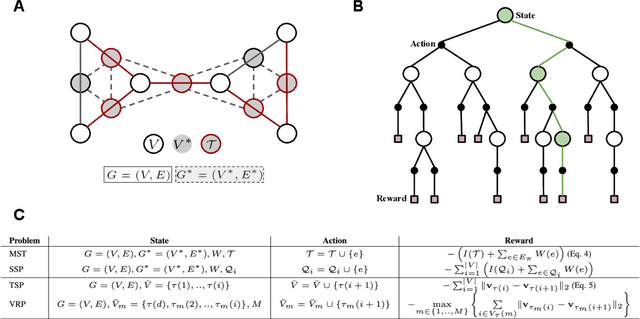
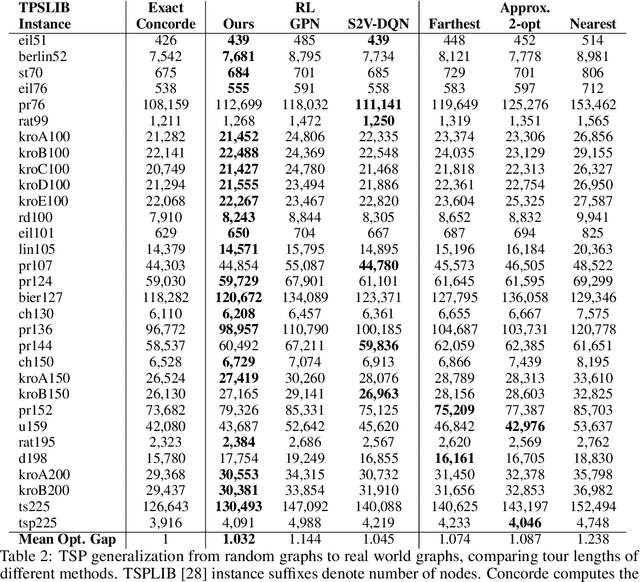
Combinatorial optimization algorithms for graph problems are usually designed afresh for each new problem with careful attention by an expert to the problem structure. In this work, we develop a new framework to solve any combinatorial optimization problem over graphs that can be formulated as a single player game defined by states, actions, and rewards, including minimum spanning tree, shortest paths, traveling salesman problem, and vehicle routing problem, without expert knowledge. Our method trains a graph neural network using reinforcement learning on an unlabeled training set of graphs. The trained network then outputs approximate solutions to new graph instances in linear running time. In contrast, previous approximation algorithms or heuristics tailored to NP-hard problems on graphs generally have at least quadratic running time. We demonstrate the applicability of our approach on both polynomial and NP-hard problems with optimality gaps close to 1, and show that our method is able to generalize well: (i) from training on small graphs to testing on large graphs; (ii) from training on random graphs of one type to testing on random graphs of another type; and (iii) from training on random graphs to running on real world graphs.
Online Aggregation of Probability Forecasts with Confidence
Sep 29, 2021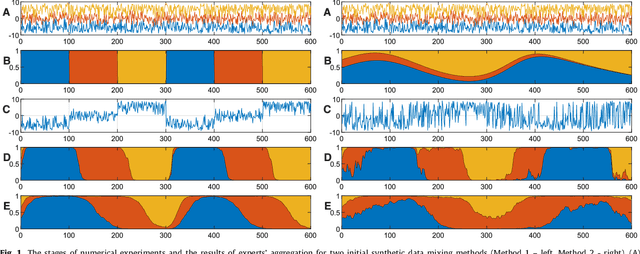

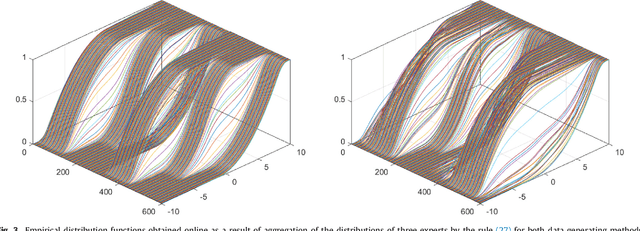
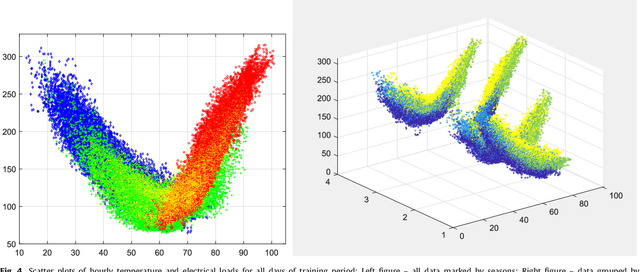
The paper presents numerical experiments and some theoretical developments in prediction with expert advice (PEA). One experiment deals with predicting electricity consumption depending on temperature and uses real data. As the pattern of dependence can change with season and time of the day, the domain naturally admits PEA formulation with experts having different ``areas of expertise''. We consider the case where several competing methods produce online predictions in the form of probability distribution functions. The dissimilarity between a probability forecast and an outcome is measured by a loss function (scoring rule). A popular example of scoring rule for continuous outcomes is Continuous Ranked Probability Score (CRPS). In this paper the problem of combining probabilistic forecasts is considered in the PEA framework. We show that CRPS is a mixable loss function and then the time-independent upper bound for the regret of the Vovk aggregating algorithm using CRPS as a loss function can be obtained. Also, we incorporate a ``smooth'' version of the method of specialized experts in this scheme which allows us to combine the probabilistic predictions of the specialized experts with overlapping domains of their competence.
* 32 pages, 10 figures
Hamilton-Jacobi-Bellman Equations for Q-Learning in Continuous Time
Dec 23, 2019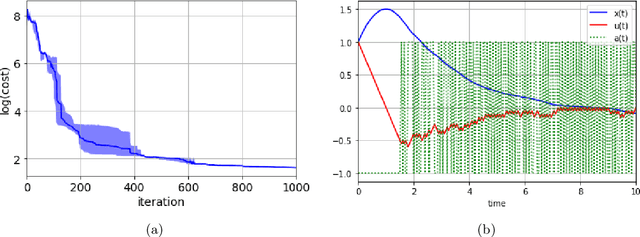
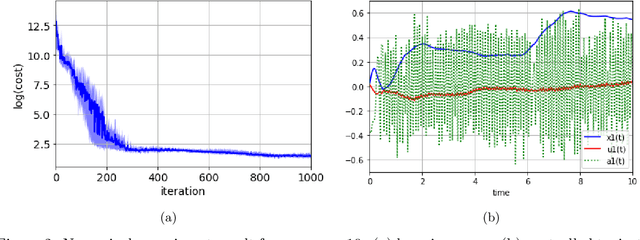
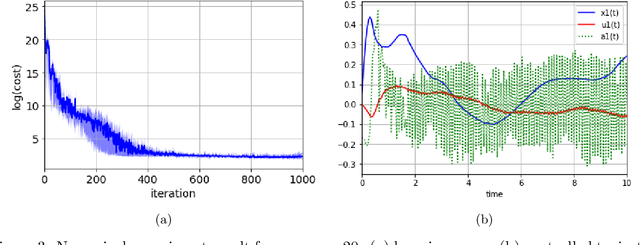
In this paper, we introduce Hamilton-Jacobi-Bellman (HJB) equations for Q-functions in continuous time optimal control problems with Lipschitz continuous controls. The standard Q-function used in reinforcement learning is shown to be the unique viscosity solution of the HJB equation. A necessary and sufficient condition for optimality is provided using the viscosity solution framework. By using the HJB equation, we develop a Q-learning method for continuous-time dynamical systems. A DQN-like algorithm is also proposed for high-dimensional state and control spaces. The performance of the proposed Q-learning algorithm is demonstrated using 1-, 10- and 20-dimensional dynamical systems.
SARS-CoV-2 Dissemination using a Network of the United States Counties
Nov 26, 2021
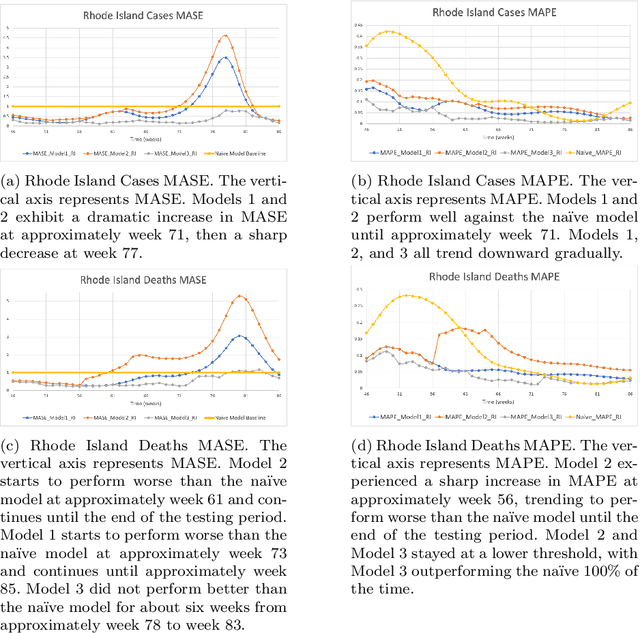
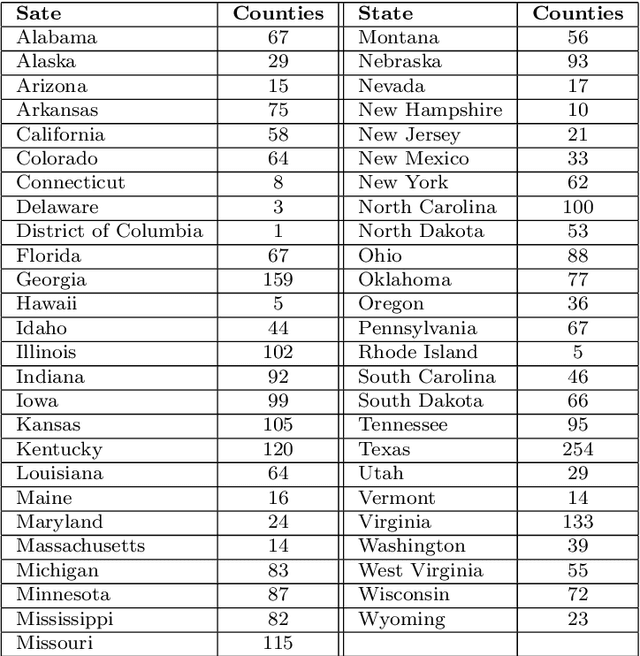
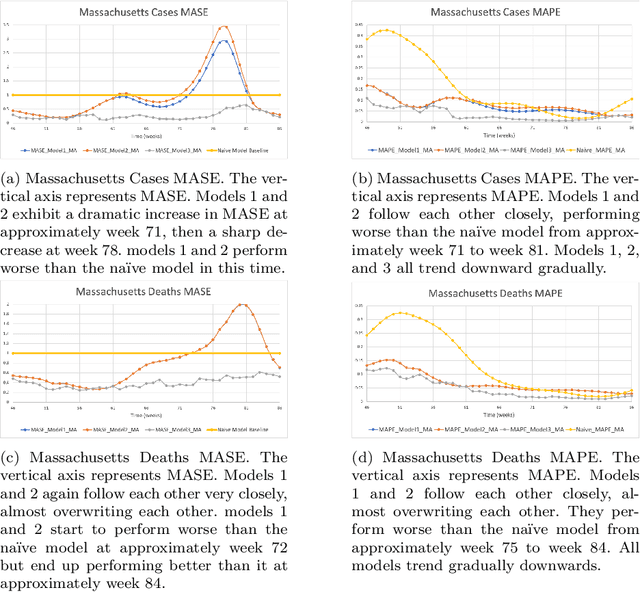
During 2020 and 2021, severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) transmission has been increasing amongst the world's population at an alarming rate. Reducing the spread of SARS-CoV-2 and other diseases that are spread in similar manners is paramount for public health officials as they seek to effectively manage resources and potential population control measures such as social distancing and quarantines. By analyzing the United States' county network structure, one can model and interdict potential higher infection areas. County officials can provide targeted information, preparedness training, as well as increase testing in these areas. While these approaches may provide adequate countermeasures for localized areas, they are inadequate for the holistic United States. We solve this problem by collecting coronavirus disease 2019 (COVID-19) infections and deaths from the Center for Disease Control and Prevention and a network adjacency structure from the United States Census Bureau. Generalized network autoregressive (GNAR) time series models have been proposed as an efficient learning algorithm for networked datasets. This work fuses network science and operations research techniques to univariately model COVID-19 cases, deaths, and current survivors across the United States' county network structure.
Simulating the Effects of Eco-Friendly Transportation Selections for Air Pollution Reduction
Sep 14, 2021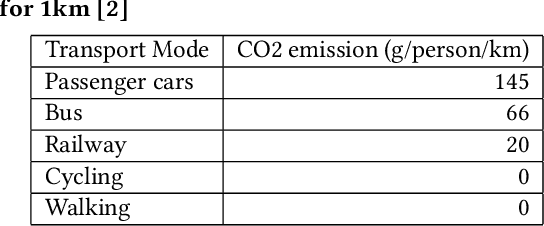
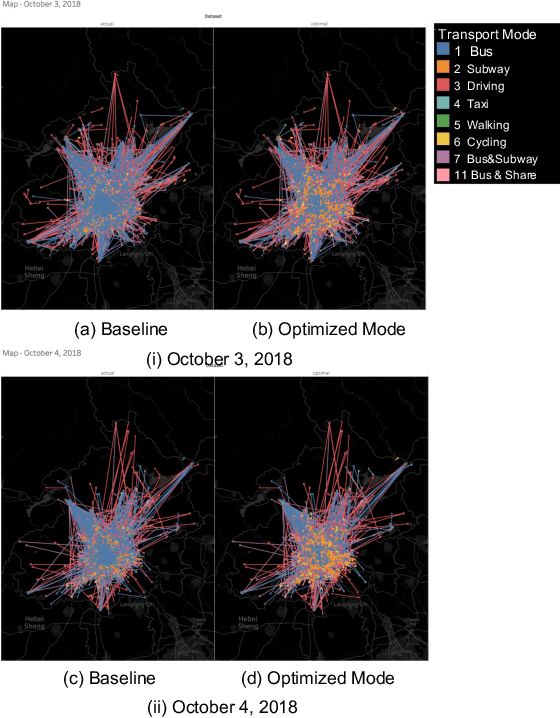
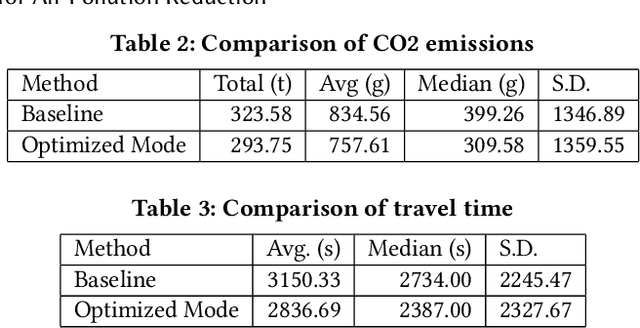

Reducing air pollution, such as CO2 and PM2.5 emissions, is one of the most important issues for many countries worldwide. Selecting an environmentally friendly transport mode can be an effective approach of individuals to reduce air pollution in daily life. In this study, we propose a method to simulate the effectiveness of an eco-friendly transport mode selection for reducing air pollution by using map search logs. We formulate the transport mode selection as a combinatorial optimization problem with the constraints regarding the total amount of CO2 emissions as an example of air pollution and the average travel time. The optimization results show that the total amount of CO2 emissions can be reduced by 9.23%, whereas the average travel time can in fact be reduced by 9.96%. Our research proposal won first prize in Regular Machine Learning Competition Track Task 2 at KDD Cup 2019.
Antenna De-Embedding in FDTD Using Spherical Wave Functions by Exploiting Orthogonality
Nov 08, 2021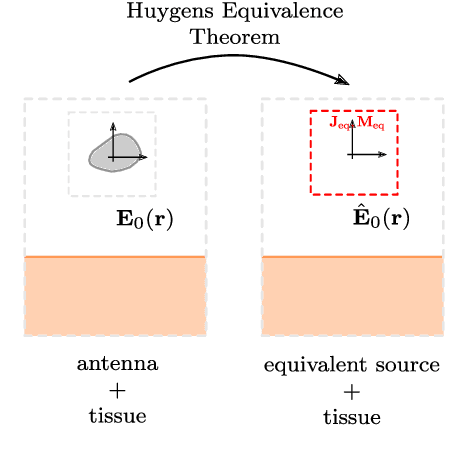
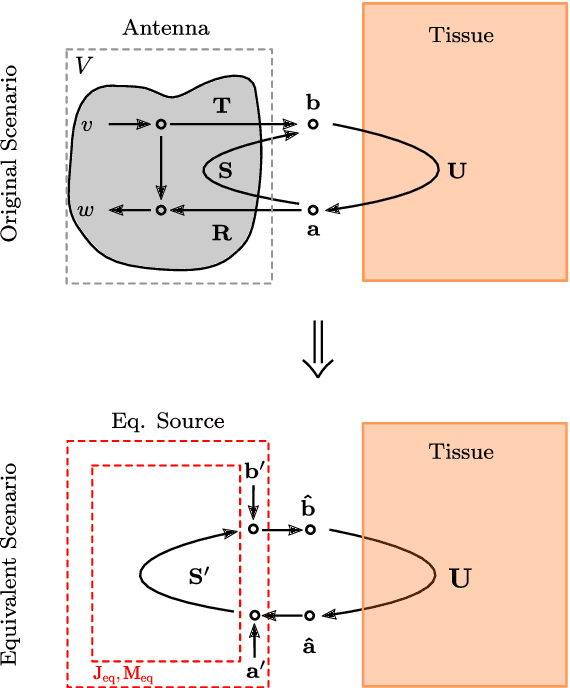
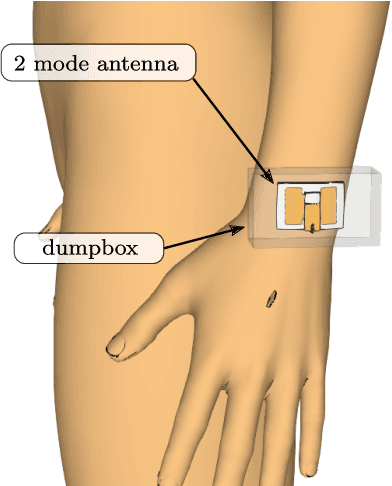
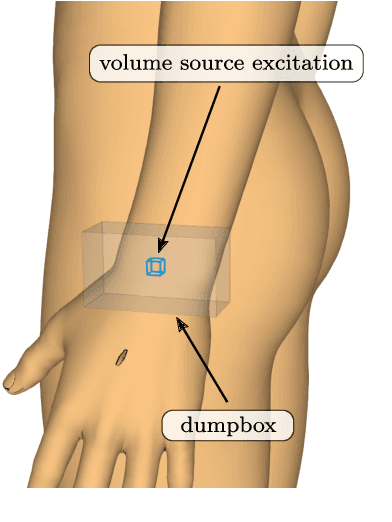
De-embedding antennas from the channel using Spherical Wave Functions (SWF) is a useful method to reduce the numerical effort in the simulation of wearable antennas. In this paper an analytical solution to the De-embedding problem is presented in form of surface integrals. This new integral solution is helpful on a theoretical level to derive insights and is also well suited for implementation in Finite Difference Time Domain (FDTD) numerical software. The spherical wave function coefficients are calculated directly from near-field values. Furthermore, the presence of a near-field scatterer in the de-embedding problem is discussed on a theoretical level based on the Huygens Equivalence Theorem. This makes it possible to exploit the degrees of freedom in such a way that it is sufficient to only use out-going spherical wave functions and still obtain correct results.
Where the Earth is flat and 9/11 is an inside job: A comparative algorithm audit of conspiratorial information in web search results
Dec 06, 2021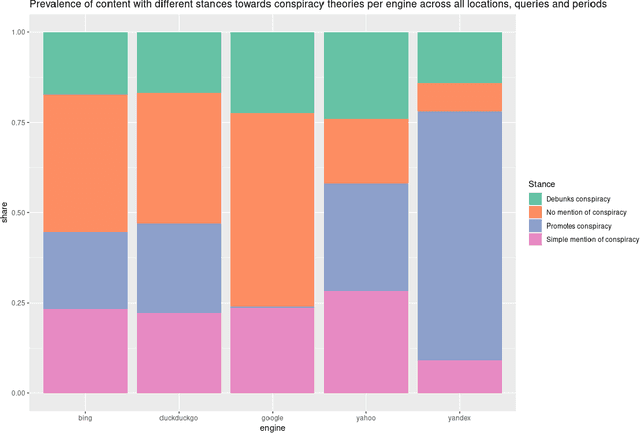
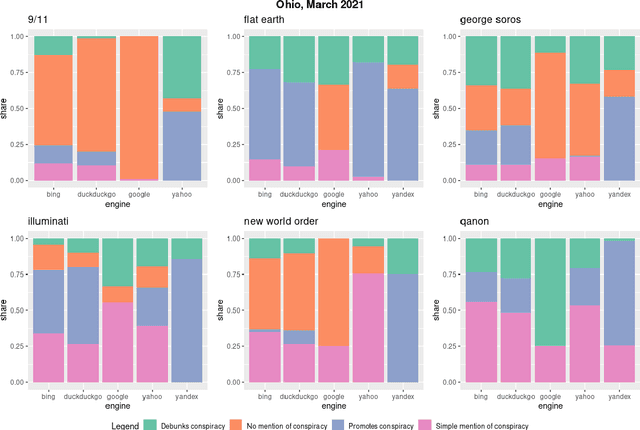
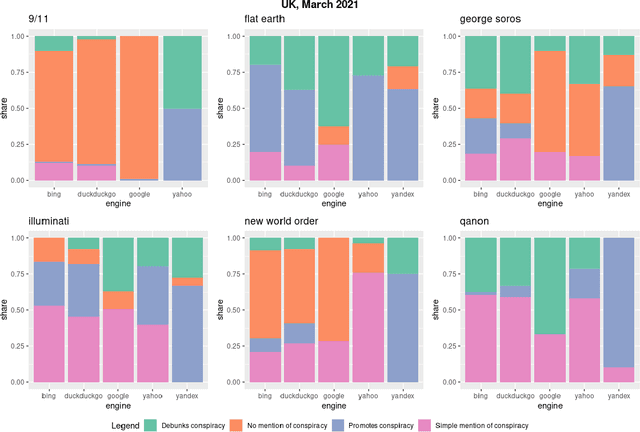
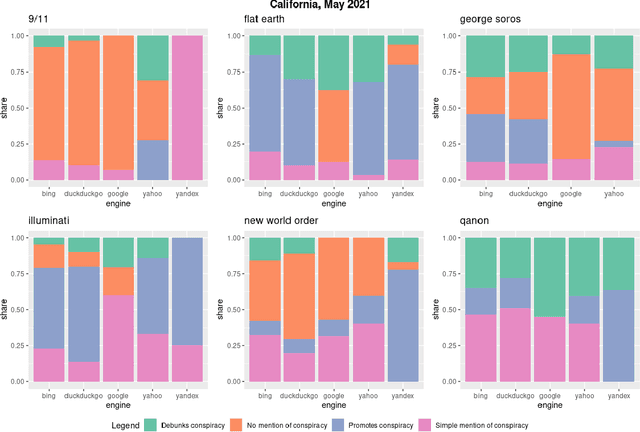
Web search engines are important online information intermediaries that are frequently used and highly trusted by the public despite multiple evidence of their outputs being subjected to inaccuracies and biases. One form of such inaccuracy, which so far received little scholarly attention, is the presence of conspiratorial information, namely pages promoting conspiracy theories. We address this gap by conducting a comparative algorithm audit to examine the distribution of conspiratorial information in search results across five search engines: Google, Bing, DuckDuckGo, Yahoo and Yandex. Using a virtual agent-based infrastructure, we systematically collect search outputs for six conspiracy theory-related queries (flat earth, new world order, qanon, 9/11, illuminati, george soros) across three locations (two in the US and one in the UK) and two observation periods (March and May 2021). We find that all search engines except Google consistently displayed conspiracy-promoting results and returned links to conspiracy-dedicated websites in their top results, although the share of such content varied across queries. Most conspiracy-promoting results came from social media and conspiracy-dedicated websites while conspiracy-debunking information was shared by scientific websites and, to a lesser extent, legacy media. The fact that these observations are consistent across different locations and time periods highlight the possibility of some search engines systematically prioritizing conspiracy-promoting content and, thus, amplifying their distribution in the online environments.
Generating High-fidelity, Synthetic Time Series Datasets with DoppelGANger
Sep 30, 2019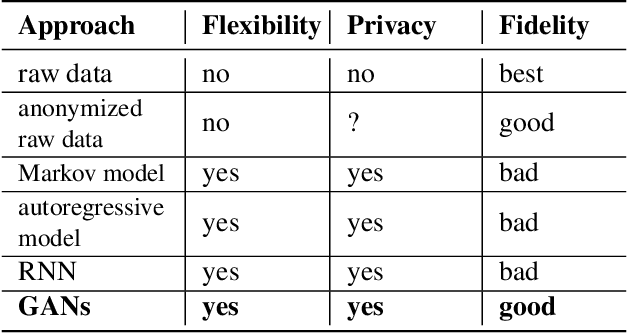
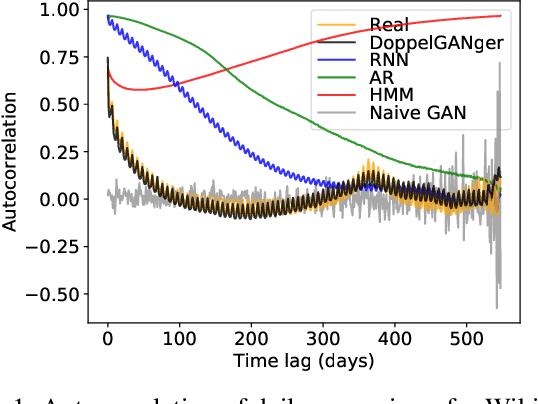
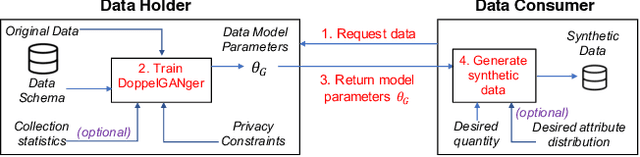
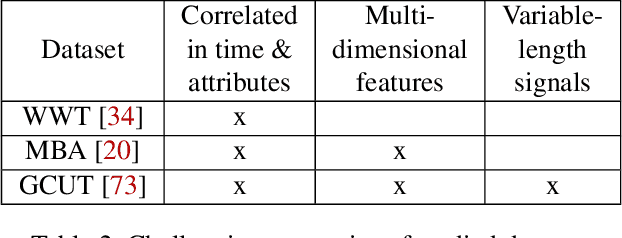
Limited data access is a substantial barrier to data-driven networking research and development. Although many organizations are motivated to share data, privacy concerns often prevent the sharing of proprietary data, including between teams in the same organization and with outside stakeholders (e.g., researchers, vendors). Many researchers have therefore proposed synthetic data models, most of which have not gained traction because of their narrow scope. In this work, we present DoppelGANger, a synthetic data generation framework based on generative adversarial networks (GANs). DoppelGANger is designed to work on time series datasets with both continuous features (e.g. traffic measurements) and discrete ones (e.g., protocol name). Modeling time series and mixed-type data is known to be difficult; DoppelGANger circumvents these problems through a new conditional architecture that isolates the generation of metadata from time series, but uses metadata to strongly influence time series generation. We demonstrate the efficacy of DoppelGANger on three real-world datasets. We show that DoppelGANger achieves up to 43% better fidelity than baseline models, and captures structural properties of data that baseline methods are unable to learn. Additionally, it gives data holders an easy mechanism for protecting attributes of their data without substantial loss of data utility.
The MatrixX Solver For Argumentation Frameworks
Sep 29, 2021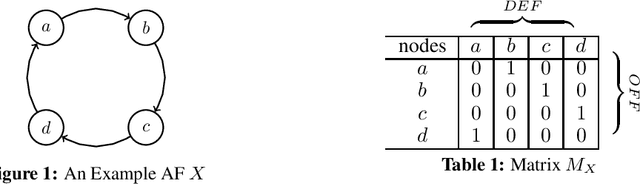


MatrixX is a solver for Abstract Argumentation Frameworks. Offensive and defensive properties of an Argumentation Framework are notated in a matrix style. Rows and columns of this matrix are systematically reduced by the solver. This procedure is implemented through the use of hash maps in order to accelerate calculation time. MatrixX works for stable and complete semantics and was designed for the ICCMA 2021 competition.