 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning to Assimilate in Chaotic Dynamical Systems
Nov 01, 2021
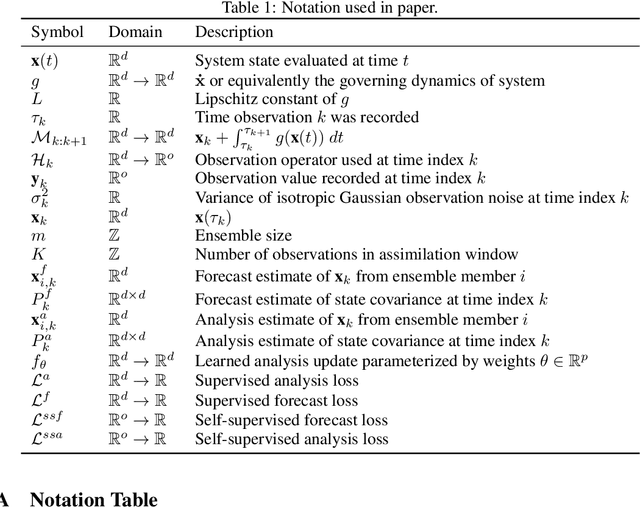
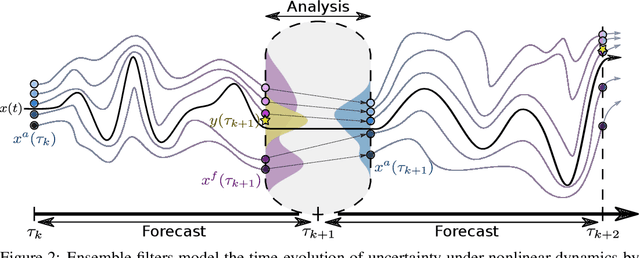
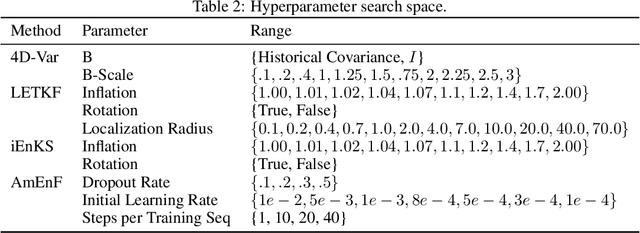
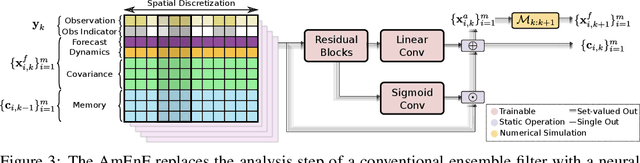
The accuracy of simulation-based forecasting in chaotic systems is heavily dependent on high-quality estimates of the system state at the time the forecast is initialized. Data assimilation methods are used to infer these initial conditions by systematically combining noisy, incomplete observations and numerical models of system dynamics to produce effective estimation schemes. We introduce amortized assimilation, a framework for learning to assimilate in dynamical systems from sequences of noisy observations with no need for ground truth data. We motivate the framework by extending powerful results from self-supervised denoising to the dynamical systems setting through the use of differentiable simulation. Experimental results across several benchmark systems highlight the improved effectiveness of our approach over widely-used data assimilation methods.
Casting graph isomorphism as a point set registration problem using a simplex embedding and sampling
Nov 15, 2021Graph isomorphism is an important problem as its worst-case time complexity is not yet fully understood. In this study, we try to draw parallels between a related optimization problem called point set registration. A graph can be represented as a point set in enough dimensions using a simplex embedding and sampling. Given two graphs, the isomorphism of them corresponds to the existence of a perfect registration between the point set forms of the graphs. In the case of non-isomorphism, the point set form optimization result can be used as a distance measure between two graphs having the same number of vertices and edges. The related idea of equivalence classes suggests that graph canonization may be an important tool in tackling graph isomorphism problem and an orthogonal transformation invariant feature extraction based on this high dimensional point set representation may be fruitful. The concepts presented can also be extended to automorphism, and subgraph isomorphism problems and can also be applied on hypergraphs with certain modifications.
Indoor Path Planning for an Unmanned Aerial Vehicle via Curriculum Learning
Aug 23, 2021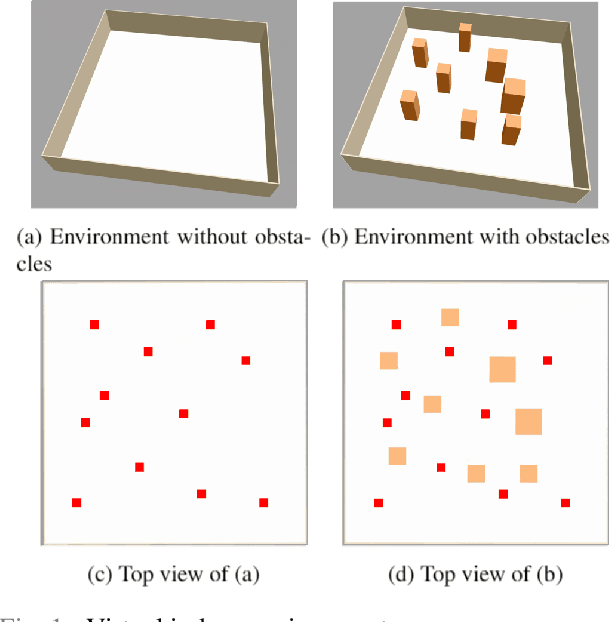
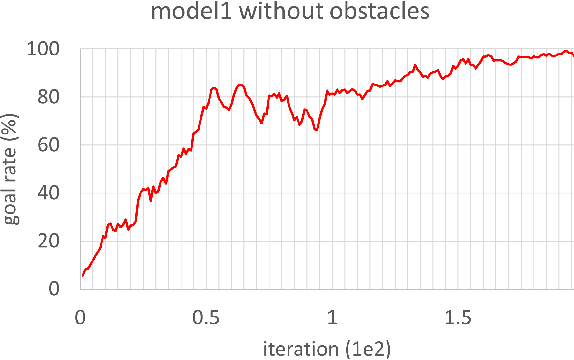
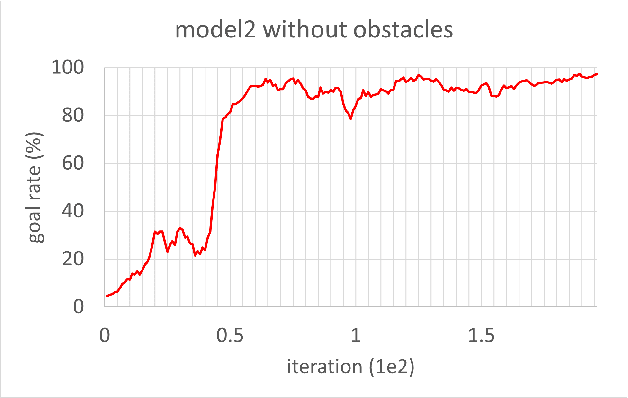
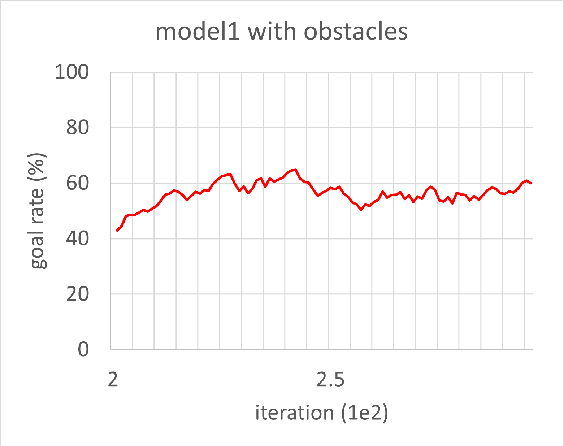
In this study, reinforcement learning was applied to learning two-dimensional path planning including obstacle avoidance by unmanned aerial vehicle (UAV) in an indoor environment. The task assigned to the UAV was to reach the goal position in the shortest amount of time without colliding with any obstacles. Reinforcement learning was performed in a virtual environment created using Gazebo, a virtual environment simulator, to reduce the learning time and cost. Curriculum learning, which consists of two stages was performed for more efficient learning. As a result of learning with two reward models, the maximum goal rates achieved were 71.2% and 88.0%.
FlexMatch: Boosting Semi-Supervised Learning with Curriculum Pseudo Labeling
Oct 15, 2021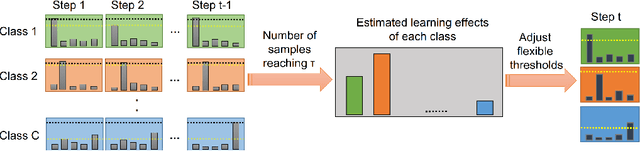
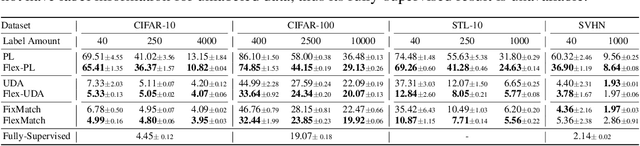
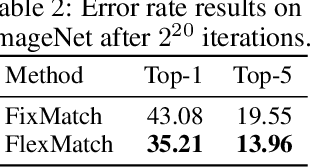
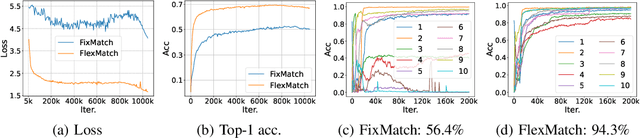
The recently proposed FixMatch achieved state-of-the-art results on most semi-supervised learning (SSL) benchmarks. However, like other modern SSL algorithms, FixMatch uses a pre-defined constant threshold for all classes to select unlabeled data that contribute to the training, thus failing to consider different learning status and learning difficulties of different classes. To address this issue, we propose Curriculum Pseudo Labeling (CPL), a curriculum learning approach to leverage unlabeled data according to the model's learning status. The core of CPL is to flexibly adjust thresholds for different classes at each time step to let pass informative unlabeled data and their pseudo labels. CPL does not introduce additional parameters or computations (forward or backward propagation). We apply CPL to FixMatch and call our improved algorithm FlexMatch. FlexMatch achieves state-of-the-art performance on a variety of SSL benchmarks, with especially strong performances when the labeled data are extremely limited or when the task is challenging. For example, FlexMatch outperforms FixMatch by 14.32% and 24.55% on CIFAR-100 and STL-10 datasets respectively, when there are only 4 labels per class. CPL also significantly boosts the convergence speed, e.g., FlexMatch can use only 1/5 training time of FixMatch to achieve even better performance. Furthermore, we show that CPL can be easily adapted to other SSL algorithms and remarkably improve their performances. We open source our code at https://github.com/TorchSSL/TorchSSL.
Modification-Fair Cluster Editing
Dec 06, 2021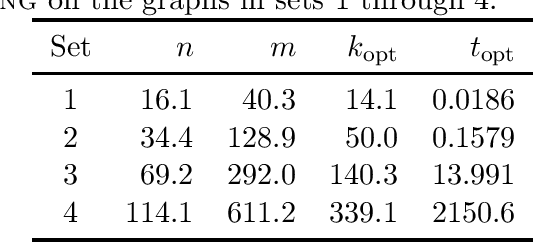
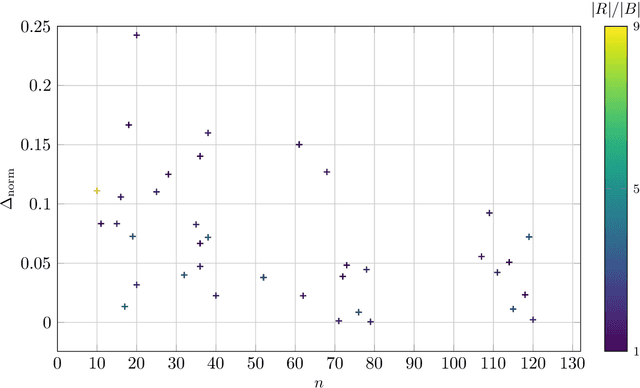
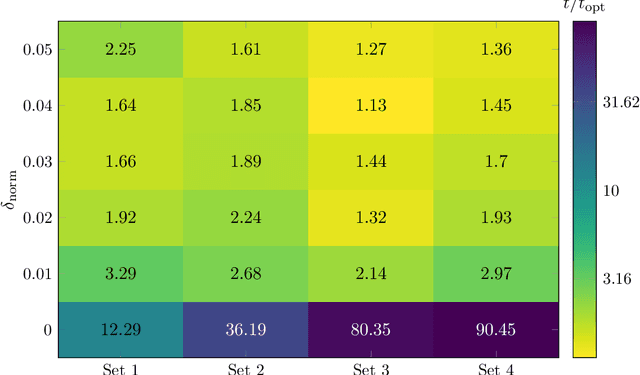
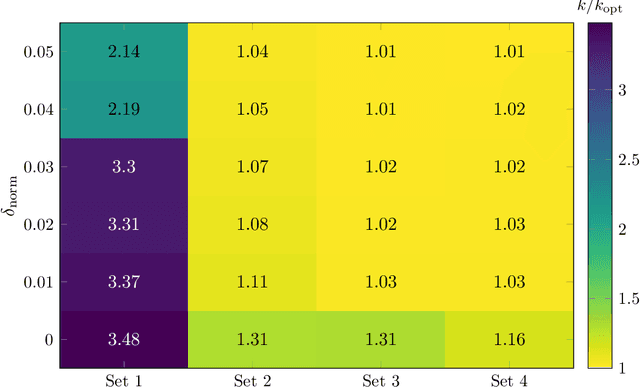
The classic Cluster Editing problem (also known as Correlation Clustering) asks to transform a given graph into a disjoint union of cliques (clusters) by a small number of edge modifications. When applied to vertex-colored graphs (the colors representing subgroups), standard algorithms for the NP-hard Cluster Editing problem may yield solutions that are biased towards subgroups of data (e.g., demographic groups), measured in the number of modifications incident to the members of the subgroups. We propose a modification fairness constraint which ensures that the number of edits incident to each subgroup is proportional to its size. To start with, we study Modification-Fair Cluster Editing for graphs with two vertex colors. We show that the problem is NP-hard even if one may only insert edges within a subgroup; note that in the classic "non-fair" setting, this case is trivially polynomial-time solvable. However, in the more general editing form, the modification-fair variant remains fixed-parameter tractable with respect to the number of edge edits. We complement these and further theoretical results with an empirical analysis of our model on real-world social networks where we find that the price of modification-fairness is surprisingly low, that is, the cost of optimal modification-fair differs from the cost of optimal "non-fair" solutions only by a small percentage.
AI in Games: Techniques, Challenges and Opportunities
Nov 15, 2021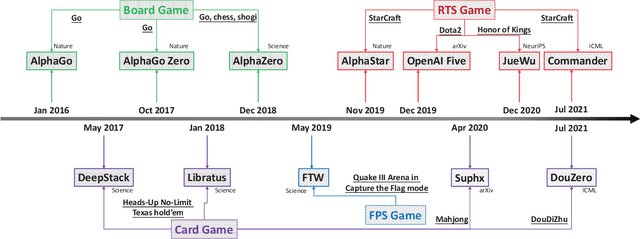

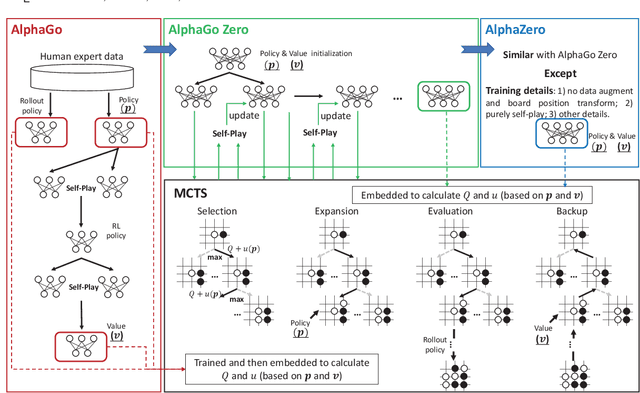
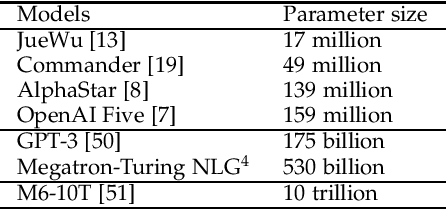
With breakthrough of AlphaGo, AI in human-computer game has become a very hot topic attracting researchers all around the world, which usually serves as an effective standard for testing artificial intelligence. Various game AI systems (AIs) have been developed such as Libratus, OpenAI Five and AlphaStar, beating professional human players. In this paper, we survey recent successful game AIs, covering board game AIs, card game AIs, first-person shooting game AIs and real time strategy game AIs. Through this survey, we 1) compare the main difficulties among different kinds of games for the intelligent decision making field ; 2) illustrate the mainstream frameworks and techniques for developing professional level AIs; 3) raise the challenges or drawbacks in the current AIs for intelligent decision making; and 4) try to propose future trends in the games and intelligent decision making techniques. Finally, we hope this brief review can provide an introduction for beginners, inspire insights for researchers in the filed of AI in games.
Distilled Domain Randomization
Dec 06, 2021
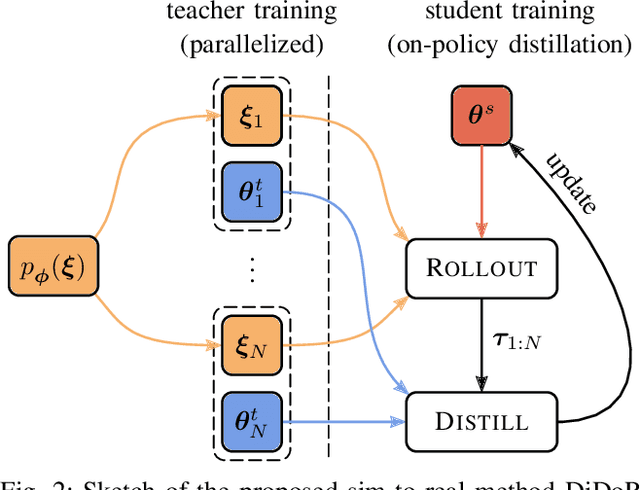
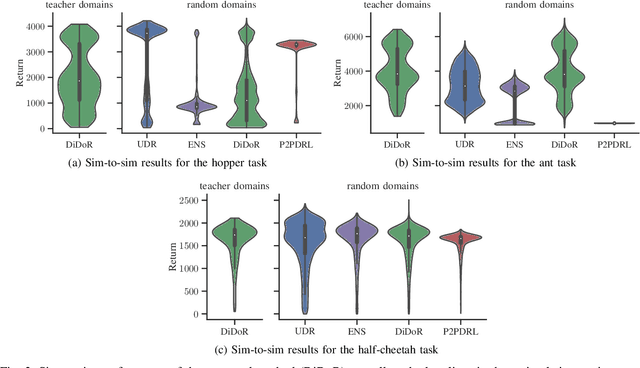
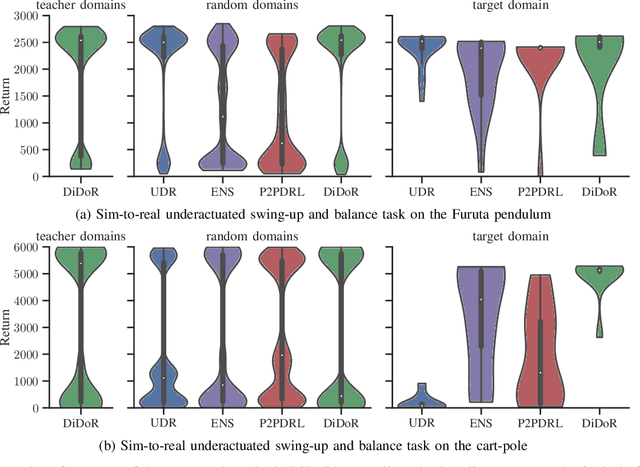
Deep reinforcement learning is an effective tool to learn robot control policies from scratch. However, these methods are notorious for the enormous amount of required training data which is prohibitively expensive to collect on real robots. A highly popular alternative is to learn from simulations, allowing to generate the data much faster, safer, and cheaper. Since all simulators are mere models of reality, there are inevitable differences between the simulated and the real data, often referenced as the 'reality gap'. To bridge this gap, many approaches learn one policy from a distribution over simulators. In this paper, we propose to combine reinforcement learning from randomized physics simulations with policy distillation. Our algorithm, called Distilled Domain Randomization (DiDoR), distills so-called teacher policies, which are experts on domains that have been sampled initially, into a student policy that is later deployed. This way, DiDoR learns controllers which transfer directly from simulation to reality, i.e., without requiring data from the target domain. We compare DiDoR against three baselines in three sim-to-sim as well as two sim-to-real experiments. Our results show that the target domain performance of policies trained with DiDoR is en par or better than the baselines'. Moreover, our approach neither increases the required memory capacity nor the time to compute an action, which may well be a point of failure for successfully deploying the learned controller.
SROM: Simple Real-time Odometry and Mapping using LiDAR data for Autonomous Vehicles
May 07, 2020
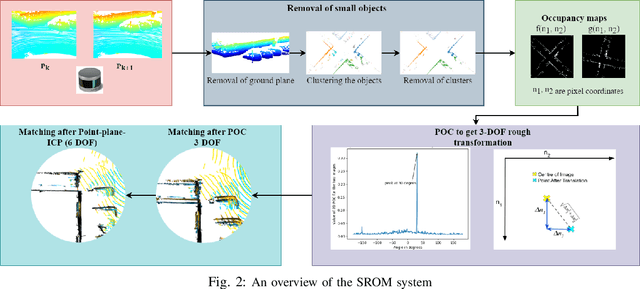
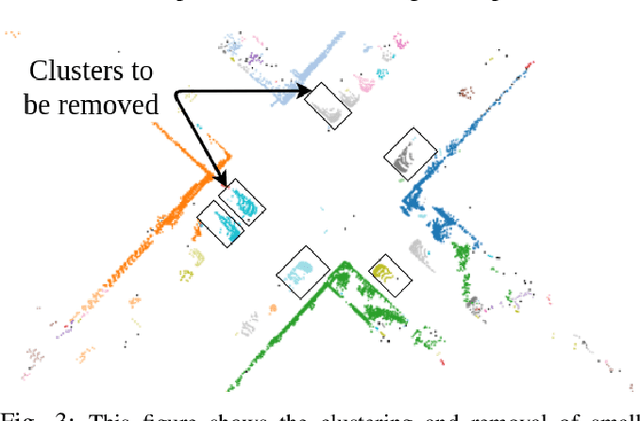

In this paper, we present SROM, a novel real-time Simultaneous Localization and Mapping (SLAM) system for autonomous vehicles. The keynote of the paper showcases SROM's ability to maintain localization at low sampling rates or at high linear or angular velocities where most popular LiDAR based localization approaches get degraded fast. We also demonstrate SROM to be computationally efficient and capable of handling high-speed maneuvers. It also achieves low drifts without the need for any other sensors like IMU and/or GPS. Our method has a two-layer structure wherein first, an approximate estimate of the rotation angle and translation parameters are calculated using a Phase Only Correlation (POC) method. Next, we use this estimate as an initialization for a point-to-plane ICP algorithm to obtain fine matching and registration. Another key feature of the proposed algorithm is the removal of dynamic objects before matching the scans. This improves the performance of our system as the dynamic objects can corrupt the matching scheme and derail localization. Our SLAM system can build reliable maps at the same time generating high-quality odometry. We exhaustively evaluated the proposed method in many challenging highways/country/urban sequences from the KITTI dataset and the results demonstrate better accuracy in comparisons to other state-of-the-art methods with reduced computational expense aiding in real-time realizations. We have also integrated our SROM system with our in-house autonomous vehicle and compared it with the state-of-the-art methods like LOAM and LeGO-LOAM.
Real-Time Anomaly Detection in Data Centers for Log-based Predictive Maintenance using an Evolving Fuzzy-Rule-Based Approach
Apr 25, 2020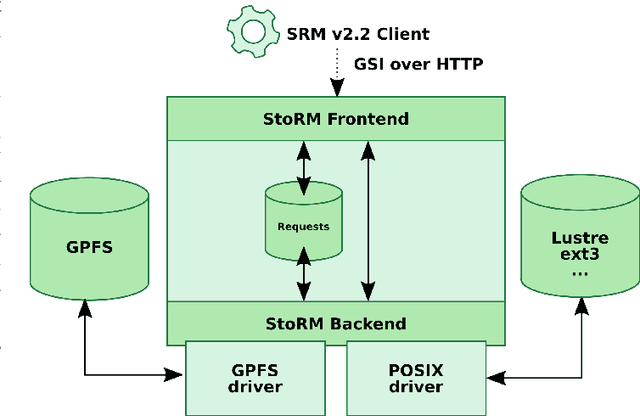
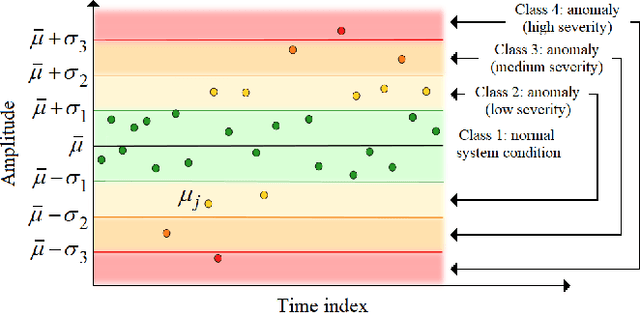
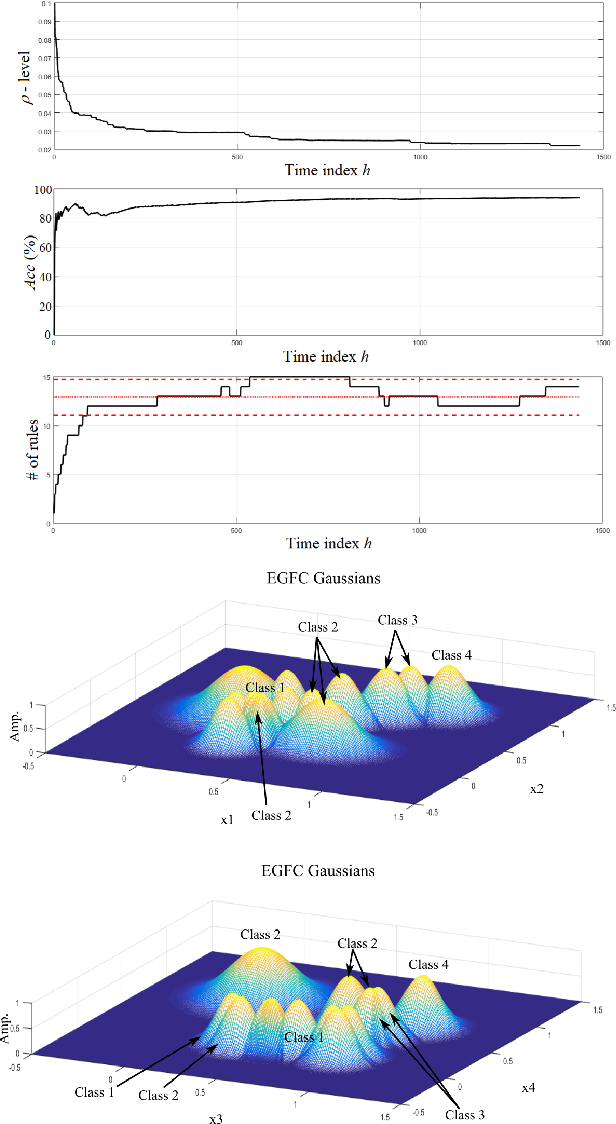
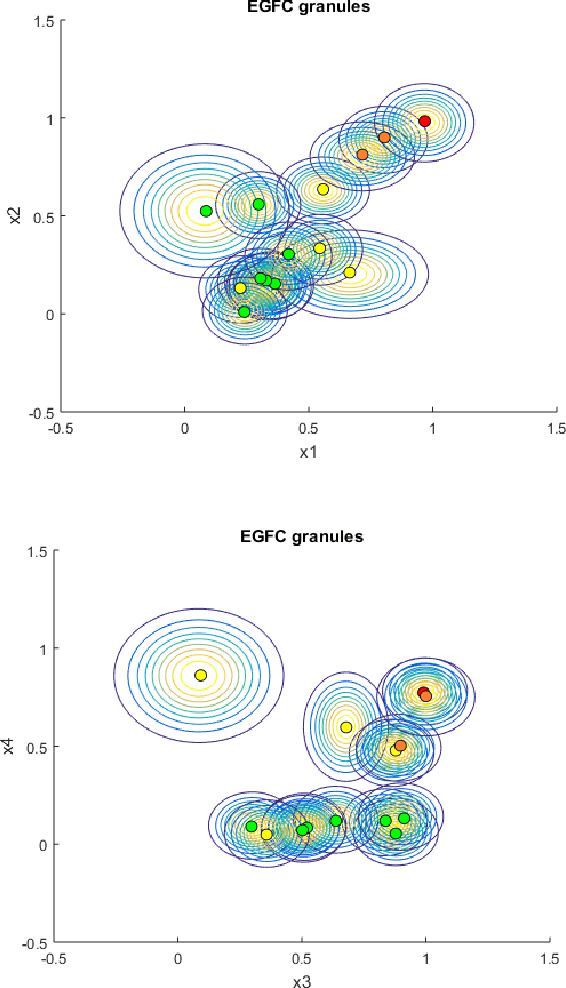
Detection of anomalous behaviors in data centers is crucial to predictive maintenance and data safety. With data centers, we mean any computer network that allows users to transmit and exchange data and information. In particular, we focus on the Tier-1 data center of the Italian Institute for Nuclear Physics (INFN), which supports the high-energy physics experiments at the Large Hadron Collider (LHC) in Geneva. The center provides resources and services needed for data processing, storage, analysis, and distribution. Log records in the data center is a stochastic and non-stationary phenomenon in nature. We propose a real-time approach to monitor and classify log records based on sliding time windows, and a time-varying evolving fuzzy-rule-based classification model. The most frequent log pattern according to a control chart is taken as the normal system status. We extract attributes from time windows to gradually develop and update an evolving Gaussian Fuzzy Classifier (eGFC) on the fly. The real-time anomaly monitoring system has to provide encouraging results in terms of accuracy, compactness, and real-time operation.
Accelerating Edge Intelligence via Integrated Sensing and Communication
Jul 20, 2021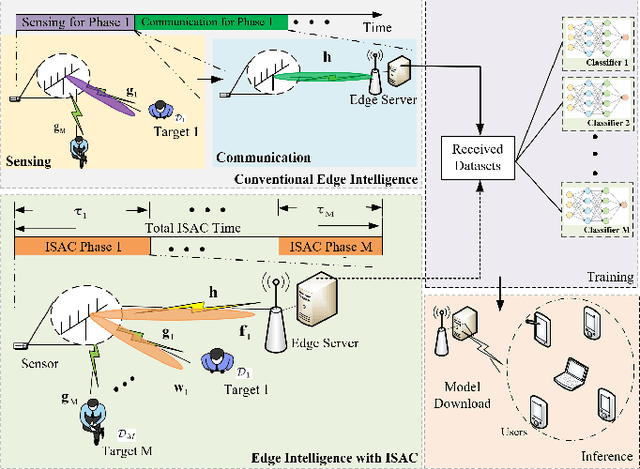
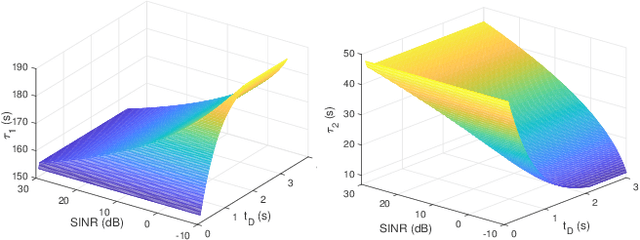
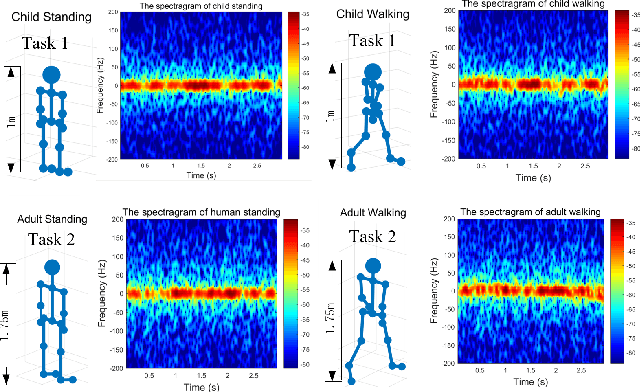
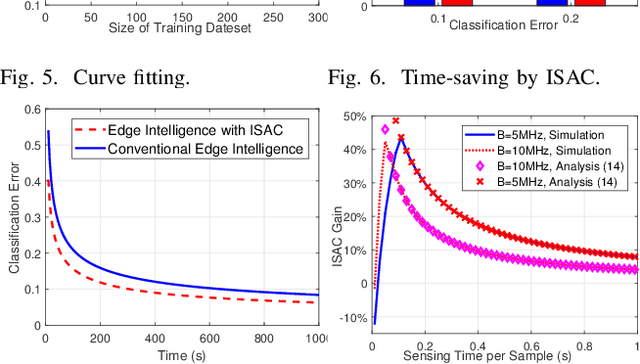
Realizing edge intelligence consists of sensing, communication, training, and inference stages. Conventionally, the sensing and communication stages are executed sequentially, which results in excessive amount of dataset generation and uploading time. This paper proposes to accelerate edge intelligence via integrated sensing and communication (ISAC). As such, the sensing and communication stages are merged so as to make the best use of the wireless signals for the dual purpose of dataset generation and uploading. However, ISAC also introduces additional interference between sensing and communication functionalities. To address this challenge, this paper proposes a classification error minimization formulation to design the ISAC beamforming and time allocation. Globally optimal solution is derived via the rank-1 guaranteed semidefinite relaxation, and performance analysis is performed to quantify the ISAC gain. Simulation results are provided to verify the effectiveness of the proposed ISAC scheme. Interestingly, it is found that when the sensing time dominates the communication time, ISAC is always beneficial. However, when the communication time dominates, the edge intelligence with ISAC scheme may not be better than that with the conventional scheme, since ISAC introduces harmful interference between the sensing and communication signals.