 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
End-to-end training of time domain audio separation and recognition
Dec 25, 2019
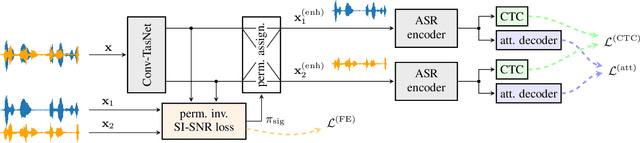


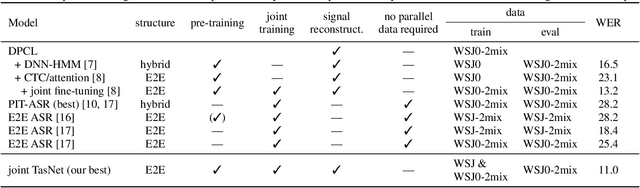
The rising interest in single-channel multi-speaker speech separation sparked development of End-to-End (E2E) approaches to multi-speaker speech recognition. However, up until now, state-of-the-art neural network-based time domain source separation has not yet been combined with E2E speech recognition. We here demonstrate how to combine a separation module based on a Convolutional Time domain Audio Separation Network (Conv-TasNet) with an E2E speech recognizer and how to train such a model jointly by distributing it over multiple GPUs or by approximating truncated back-propagation for the convolutional front-end. To put this work into perspective and illustrate the complexity of the design space, we provide a compact overview of single-channel multi-speaker recognition systems. Our experiments show a word error rate of 11.0% on WSJ0-2mix and indicate that our joint time domain model can yield substantial improvements over cascade DNN-HMM and monolithic E2E frequency domain systems proposed so far.
Learning Low-Dimensional Quadratic-Embeddings of High-Fidelity Nonlinear Dynamics using Deep Learning
Nov 25, 2021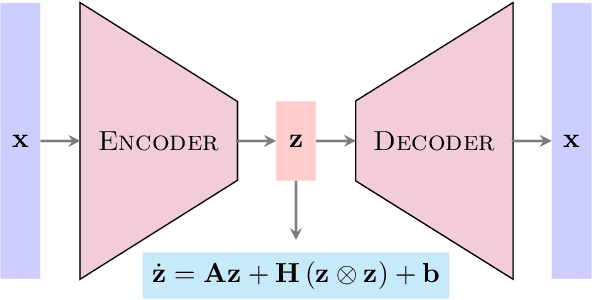
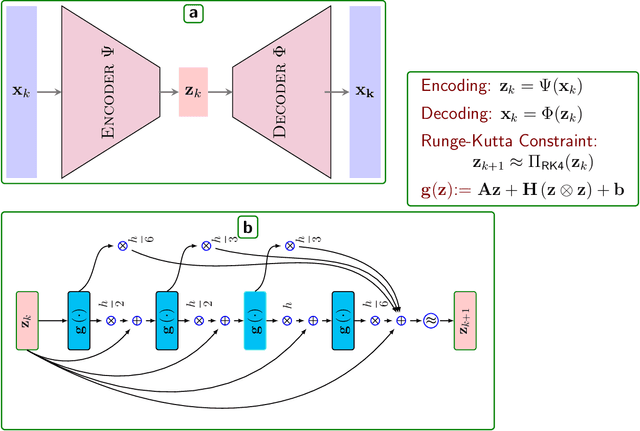
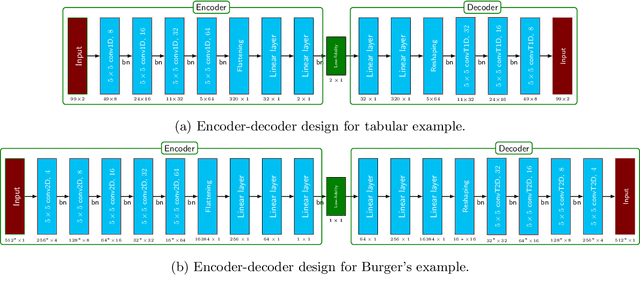
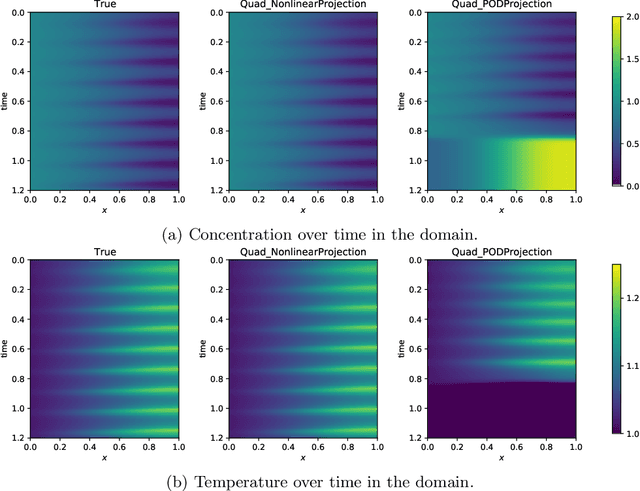
Learning dynamical models from data plays a vital role in engineering design, optimization, and predictions. Building models describing dynamics of complex processes (e.g., weather dynamics, or reactive flows) using empirical knowledge or first principles are onerous or infeasible. Moreover, these models are high-dimensional but spatially correlated. It is, however, observed that the dynamics of high-fidelity models often evolve in low-dimensional manifolds. Furthermore, it is also known that for sufficiently smooth vector fields defining the nonlinear dynamics, a quadratic model can describe it accurately in an appropriate coordinate system, conferring to the McCormick relaxation idea in nonconvex optimization. Here, we aim at finding a low-dimensional embedding of high-fidelity dynamical data, ensuring a simple quadratic model to explain its dynamics. To that aim, this work leverages deep learning to identify low-dimensional quadratic embeddings for high-fidelity dynamical systems. Precisely, we identify the embedding of data using an autoencoder to have the desired property of the embedding. We also embed a Runge-Kutta method to avoid the time-derivative computations, which is often a challenge. We illustrate the ability of the approach by a couple of examples, arising in describing flow dynamics and the oscillatory tubular reactor model.
RODEO: Robust DE-aliasing autoencOder for Real-time Medical Image Reconstruction
Dec 11, 2019
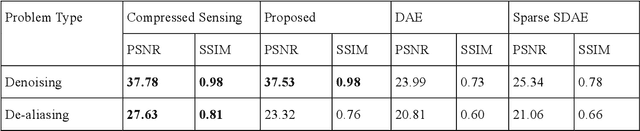
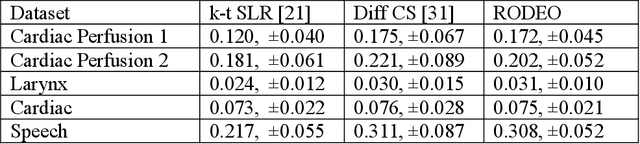
In this work we address the problem of real-time dynamic medical MRI and X Ray CT image reconstruction from parsimonious samples Fourier frequency space for MRI and sinogram tomographic projections for CT. Today the de facto standard for such reconstruction is compressed sensing. CS produces high quality images (with minimal perceptual loss, but such reconstructions are time consuming, requiring solving a complex optimization problem. In this work we propose to learn the reconstruction from training samples using an autoencoder. Our work is based on the universal function approximation capacity of neural networks. The training time for the autoencoder is large, but is offline and hence does not affect performance during operation. During testing or operation, our method requires only a few matrix vector products and hence is significantly faster than CS based methods. In fact, it is fast enough for real-time reconstruction the images are reconstructed as fast as they are acquired with only slight degradation of image quality. However, in order to make the autoencoder suitable for our problem, we depart from the standard Euclidean norm cost function of autoencoders and use a robust l1-norm instead. The ensuing problem is solved using the Split Bregman method.
Online Continual Learning with Natural Distribution Shifts: An Empirical Study with Visual Data
Aug 20, 2021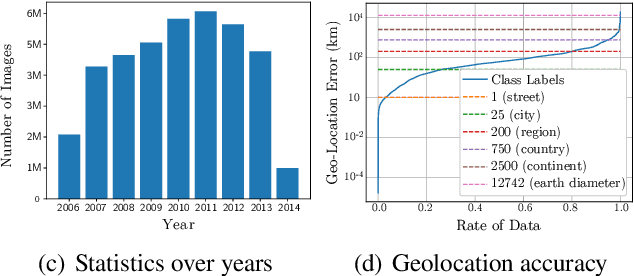
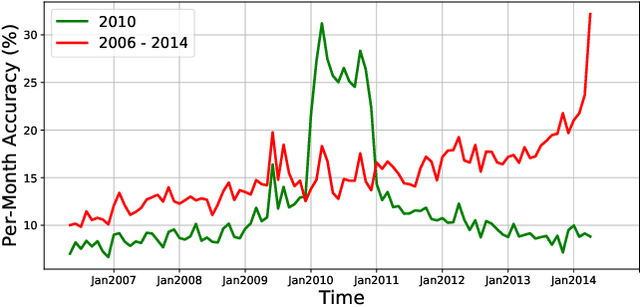
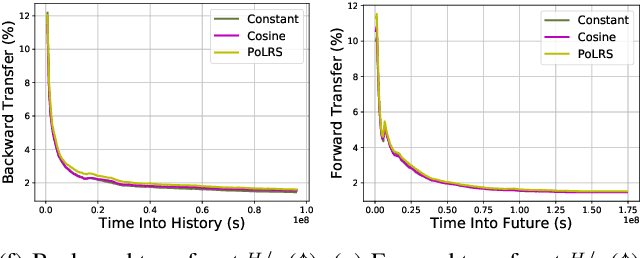
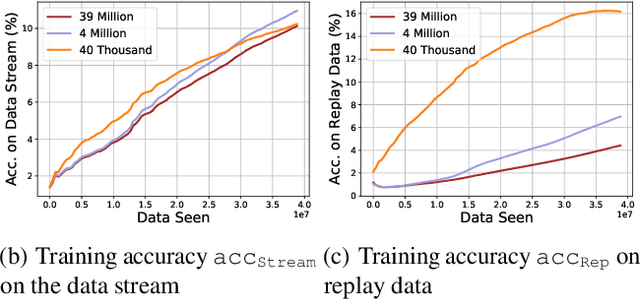
Continual learning is the problem of learning and retaining knowledge through time over multiple tasks and environments. Research has primarily focused on the incremental classification setting, where new tasks/classes are added at discrete time intervals. Such an "offline" setting does not evaluate the ability of agents to learn effectively and efficiently, since an agent can perform multiple learning epochs without any time limitation when a task is added. We argue that "online" continual learning, where data is a single continuous stream without task boundaries, enables evaluating both information retention and online learning efficacy. In online continual learning, each incoming small batch of data is first used for testing and then added to the training set, making the problem truly online. Trained models are later evaluated on historical data to assess information retention. We introduce a new benchmark for online continual visual learning that exhibits large scale and natural distribution shifts. Through a large-scale analysis, we identify critical and previously unobserved phenomena of gradient-based optimization in continual learning, and propose effective strategies for improving gradient-based online continual learning with real data. The source code and dataset are available in: https://github.com/IntelLabs/continuallearning.
CovXR: Automated Detection of COVID-19 Pneumonia in Chest X-Rays through Machine Learning
Oct 12, 2021
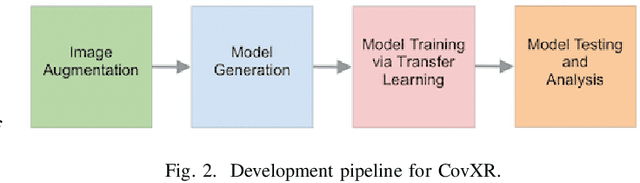
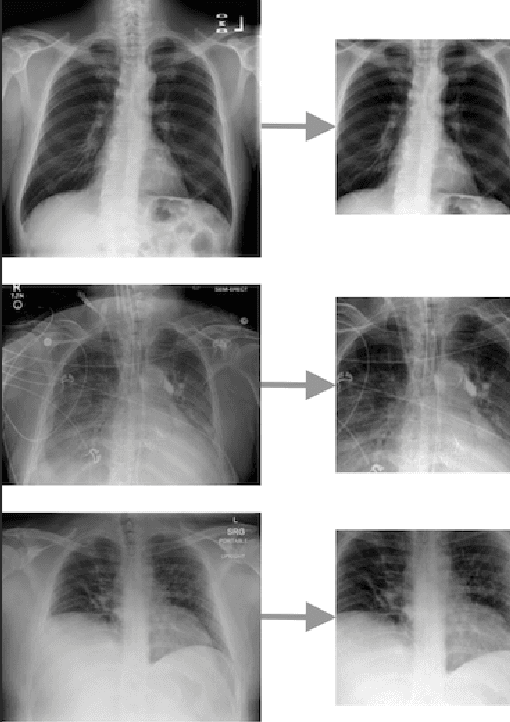
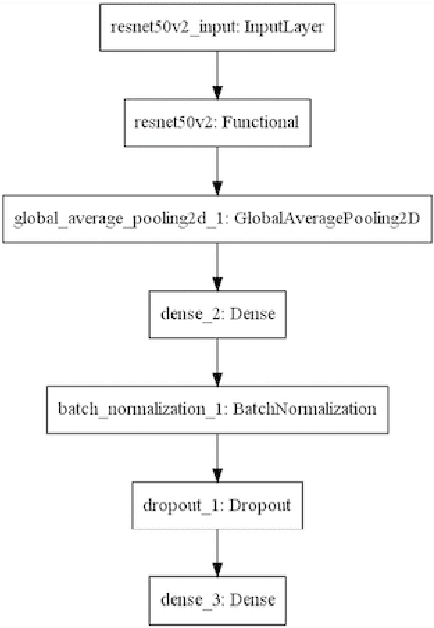
Coronavirus disease 2019 (COVID-19) is the highly contagious illness caused by severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). The standard diagnostic testing procedure for COVID-19 is testing a nasopharyngeal swab for SARS-CoV-2 nucleic acid using a real-time polymerase chain reaction (PCR), which can take multiple days to provide a diagnosis. Another widespread form of testing is rapid antigen testing, which has a low sensitivity compared to PCR, but is favored for its quick diagnosis time of usually 15-30 minutes. Patients who test positive for COVID-19 demonstrate diffuse alveolar damage in 87% of cases. Machine learning has proven to have advantages in image classification problems with radiology. In this work, we introduce CovXR as a machine learning model designed to detect COVID-19 pneumonia in chest X-rays (CXR). CovXR is a convolutional neural network (CNN) trained on over 4,300 chest X-rays. The performance of the model is measured through accuracy, F1 score, sensitivity, and specificity. The model achieves an accuracy of 95.5% and an F1 score of 0.954. The sensitivity is 93.5% and specificity is 97.5%. With accuracy above 95% and F1 score above 0.95, CovXR is highly accurate in predicting COVID-19 pneumonia on CXRs. The model achieves better accuracy than prior work and uses a unique approach to identify COVID-19 pneumonia. CovXR is highly accurate in identifying COVID-19 on CXRs of patients with a PCR confirmed positive diagnosis and provides much faster results than PCR tests.
Semi-supervised teacher-student deep neural network for materials discovery
Dec 12, 2021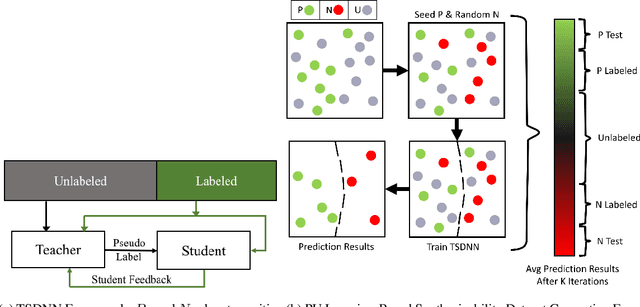


Data driven generative machine learning models have recently emerged as one of the most promising approaches for new materials discovery. While the generator models can generate millions of candidates, it is critical to train fast and accurate machine learning models to filter out stable, synthesizable materials with desired properties. However, such efforts to build supervised regression or classification screening models have been severely hindered by the lack of unstable or unsynthesizable samples, which usually are not collected and deposited in materials databases such as ICSD and Materials Project (MP). At the same time, there are a significant amount of unlabelled data available in these databases. Here we propose a semi-supervised deep neural network (TSDNN) model for high-performance formation energy and synthesizability prediction, which is achieved via its unique teacher-student dual network architecture and its effective exploitation of the large amount of unlabeled data. For formation energy based stability screening, our semi-supervised classifier achieves an absolute 10.3\% accuracy improvement compared to the baseline CGCNN regression model. For synthesizability prediction, our model significantly increases the baseline PU learning's true positive rate from 87.9\% to 97.9\% using 1/49 model parameters. To further prove the effectiveness of our models, we combined our TSDNN-energy and TSDNN-synthesizability models with our CubicGAN generator to discover novel stable cubic structures. Out of 1000 recommended candidate samples by our models, 512 of them have negative formation energies as validated by our DFT formation energy calculations. Our experimental results show that our semi-supervised deep neural networks can significantly improve the screening accuracy in large-scale generative materials design.
A Framework for Automatic Monitoring of Norms that regulate Time Constrained Actions
May 01, 2021This paper addresses the problem of proposing a model of norms and a framework for automatically computing their violation or fulfilment. The proposed T-NORM model can be used to express abstract norms able to regulate classes of actions that should or should not be performed in a temporal interval. We show how the model can be used to formalize obligations and prohibitions and for inhibiting them by introducing permissions and exemptions. The basic building blocks for norm specification consists of rules with suitably nested components. The activation condition, the regulated actions, and the temporal constrains of norms are specified using the W3C Web Ontology Language (OWL 2). Thanks to this choice, it is possible to use OWL reasoning for computing the effects that the logical implication between actions has on norms fulfilment or violation. The operational semantics of the T-NORM model is specified by providing an unambiguous procedure for translating every norm and every exception into production rules.
Real-Time High-Performance Semantic Image Segmentation of Urban Street Scenes
Mar 11, 2020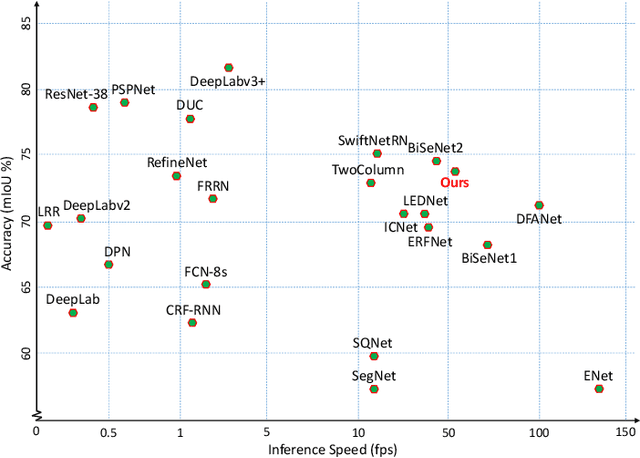


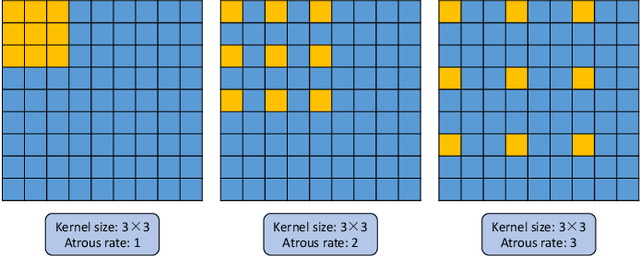
Deep Convolutional Neural Networks (DCNNs) have recently shown outstanding performance in semantic image segmentation. However, state-of-the-art DCNN-based semantic segmentation methods usually suffer from high computational complexity due to the use of complex network architectures. This greatly limits their applications in the real-world scenarios that require real-time processing. In this paper, we propose a real-time high-performance DCNN-based method for robust semantic segmentation of urban street scenes, which achieves a good trade-off between accuracy and speed. Specifically, a Lightweight Baseline Network with Atrous convolution and Attention (LBN-AA) is firstly used as our baseline network to efficiently obtain dense feature maps. Then, the Distinctive Atrous Spatial Pyramid Pooling (DASPP), which exploits the different sizes of pooling operations to encode the rich and distinctive semantic information, is developed to detect objects at multiple scales. Meanwhile, a Spatial detail-Preserving Network (SPN) with shallow convolutional layers is designed to generate high-resolution feature maps preserving the detailed spatial information. Finally, a simple but practical Feature Fusion Network (FFN) is used to effectively combine both shallow and deep features from the semantic branch (DASPP) and the spatial branch (SPN), respectively. Extensive experimental results show that the proposed method respectively achieves the accuracy of 73.6% and 68.0% mean Intersection over Union (mIoU) with the inference speed of 51.0 fps and 39.3 fps on the challenging Cityscapes and CamVid test datasets (by only using a single NVIDIA TITAN X card). This demonstrates that the proposed method offers excellent performance at the real-time speed for semantic segmentation of urban street scenes.
Feature Selective Likelihood Ratio Estimator for Low- and Zero-frequency N-grams
Nov 05, 2021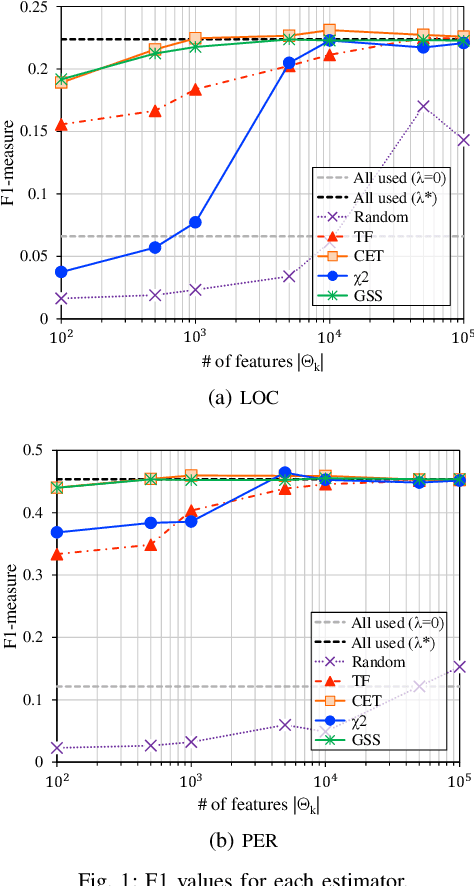
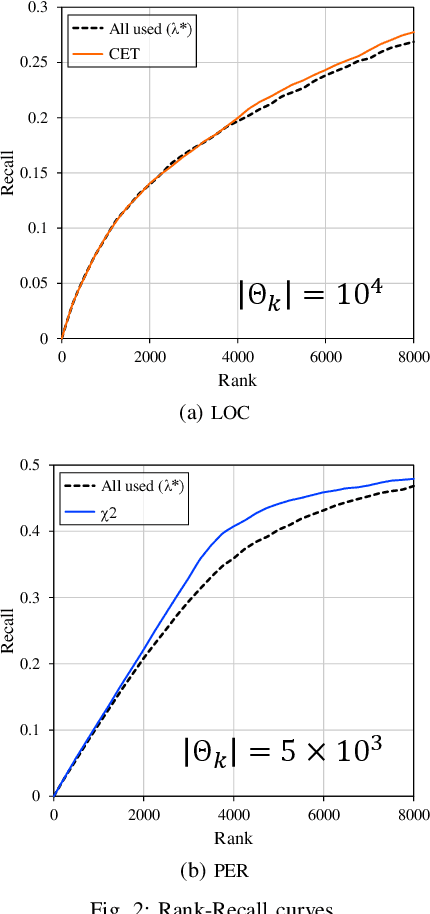
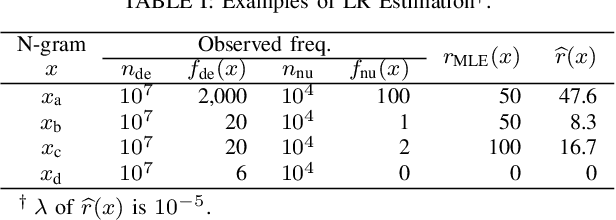
In natural language processing (NLP), the likelihood ratios (LRs) of N-grams are often estimated from the frequency information. However, a corpus contains only a fraction of the possible N-grams, and most of them occur infrequently. Hence, we desire an LR estimator for low- and zero-frequency N-grams. One way to achieve this is to decompose the N-grams into discrete values, such as letters and words, and take the product of the LRs for the values. However, because this method deals with a large number of discrete values, the running time and memory usage for estimation are problematic. Moreover, use of unnecessary discrete values causes deterioration of the estimation accuracy. Therefore, this paper proposes combining the aforementioned method with the feature selection method used in document classification, and shows that our estimator provides effective and efficient estimation results for low- and zero-frequency N-grams.
Representation Learning on Variable Length and Incomplete Wearable-Sensory Time Series
Feb 10, 2020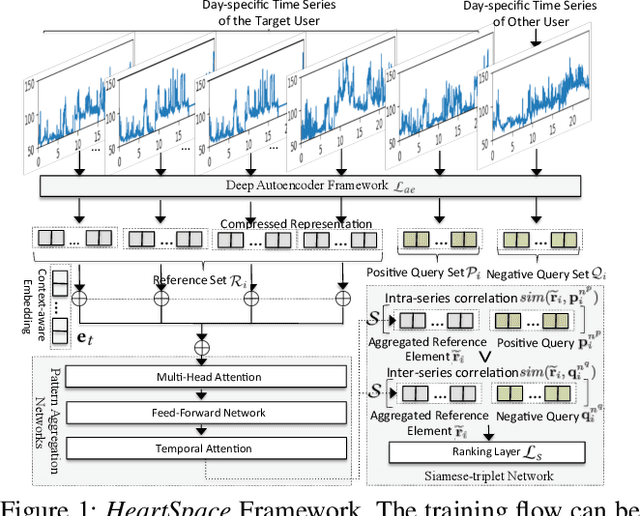
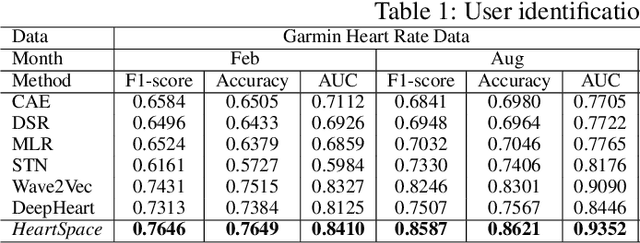
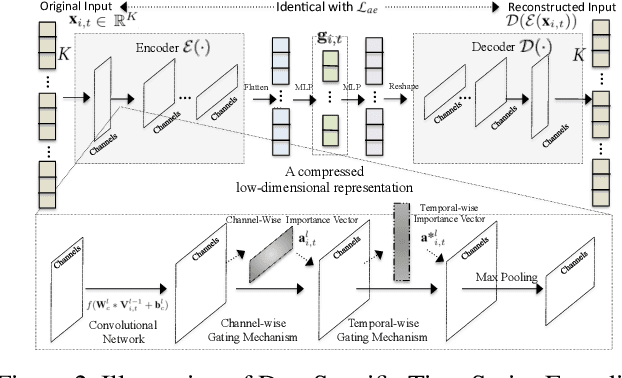
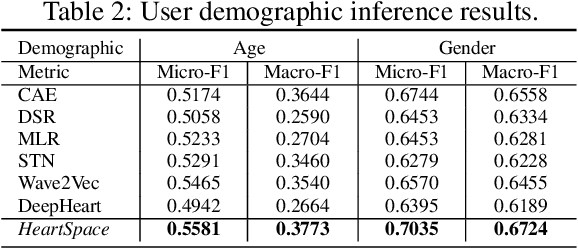
The prevalence of wearable sensors (e.g., smart wristband) is enabling an unprecedented opportunity to not only inform health and wellness states of individuals, but also assess and infer demographic information and personality. This can allow us a deeper personalized insight beyond how many steps we took or what is our heart rate. However, before we can achieve this goal of personalized insight about an individual, we have to resolve a number of shortcomings: 1) wearable-sensory time series is often of variable-length and incomplete due to different data collection periods (e.g., wearing behavior varies by person); 2) inter-individual variability to external factors like stress and environment. This paper addresses these challenges and brings us closer to the potential of personalized insights whether about health or personality or job performance about an individual by developing a novel representation learning algorithm, HeartSpace. Specifically, HeartSpace is capable of encoding time series data with variable-length and missing values via the integration of a time series encoding module and a pattern aggregation network. Additionally, HeartSpace implements a Siamese-triplet network to optimize representations by jointly capturing intra- and inter-series correlations during the embedding learning process. Our empirical evaluation over two different data presents significant performance gains over state-of-the-art baselines in a variety of applications, including personality prediction, demographics inference, user identification.