 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fast Model Editing at Scale
Oct 21, 2021
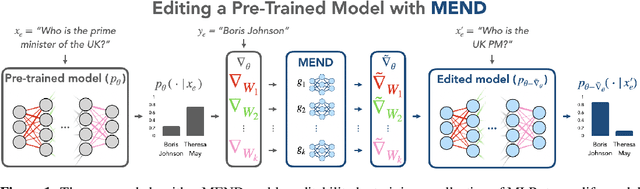

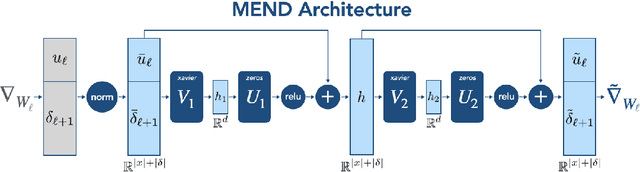

While large pre-trained models have enabled impressive results on a variety of downstream tasks, the largest existing models still make errors, and even accurate predictions may become outdated over time. Because detecting all such failures at training time is impossible, enabling both developers and end users of such models to correct inaccurate outputs while leaving the model otherwise intact is desirable. However, the distributed, black-box nature of the representations learned by large neural networks makes producing such targeted edits difficult. If presented with only a single problematic input and new desired output, fine-tuning approaches tend to overfit; other editing algorithms are either computationally infeasible or simply ineffective when applied to very large models. To enable easy post-hoc editing at scale, we propose Model Editor Networks with Gradient Decomposition (MEND), a collection of small auxiliary editing networks that use a single desired input-output pair to make fast, local edits to a pre-trained model. MEND learns to transform the gradient obtained by standard fine-tuning, using a low-rank decomposition of the gradient to make the parameterization of this transformation tractable. MEND can be trained on a single GPU in less than a day even for 10 billion+ parameter models; once trained MEND enables rapid application of new edits to the pre-trained model. Our experiments with T5, GPT, BERT, and BART models show that MEND is the only approach to model editing that produces effective edits for models with tens of millions to over 10 billion parameters. Implementation available at https://sites.google.com/view/mend-editing.
Local Justice and the Algorithmic Allocation of Societal Resources
Nov 10, 2021AI is increasingly used to aid decision-making about the allocation of scarce societal resources, for example housing for homeless people, organs for transplantation, and food donations. Recently, there have been several proposals for how to design objectives for these systems that attempt to achieve some combination of fairness, efficiency, incentive compatibility, and satisfactory aggregation of stakeholder preferences. This paper lays out possible roles and opportunities for AI in this domain, arguing for a closer engagement with the political philosophy literature on local justice, which provides a framework for thinking about how societies have over time framed objectives for such allocation problems. It also discusses how we may be able to integrate into this framework the opportunities and risks opened up by the ubiquity of data and the availability of algorithms that can use them to make accurate predictions about the future.
Predicting Defects in Laser Powder Bed Fusion using in-situ Thermal Imaging Data and Machine Learning
Dec 16, 2021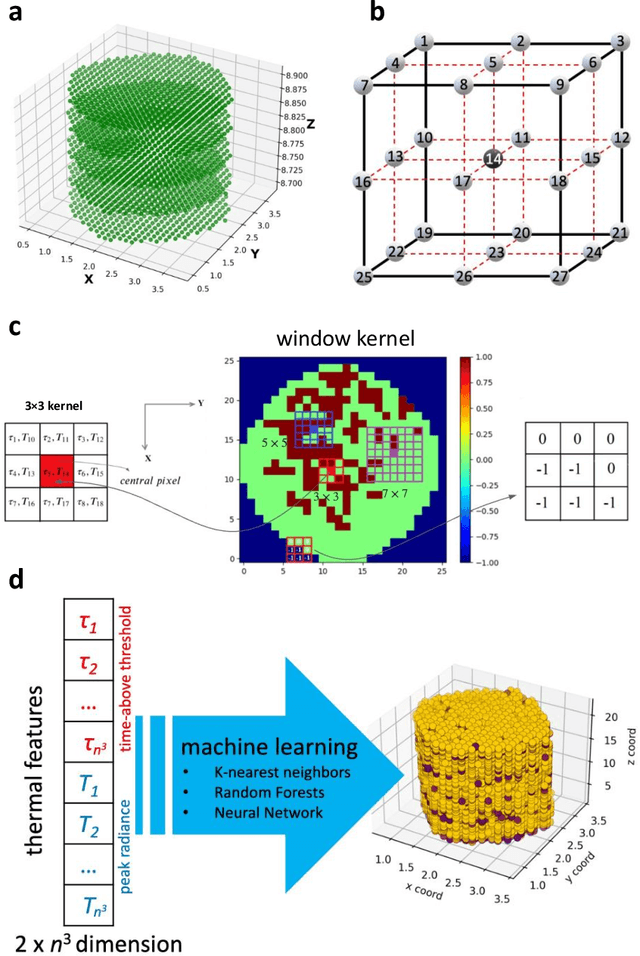

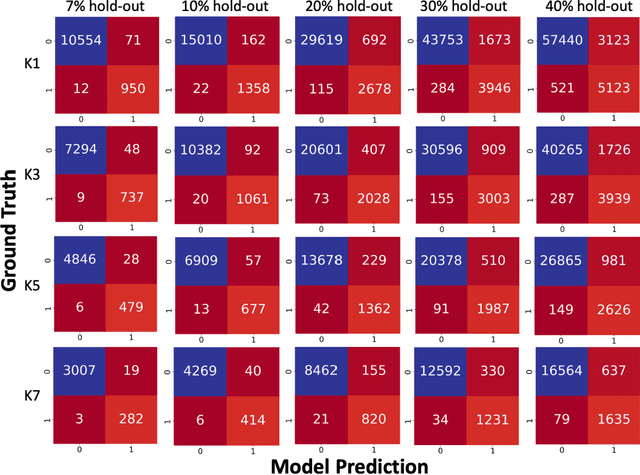

Variation in the local thermal history during the laser powder bed fusion (LPBF) process in additive manufacturing (AM) can cause microporosity defects. in-situ sensing has been proposed to monitor the AM process to minimize defects, but the success requires establishing a quantitative relationship between the sensing data and the porosity, which is especially challenging for a large number of variables and computationally costly. In this work, we develop machine learning (ML) models that can use in-situ thermographic data to predict the microporosity of LPBF stainless steel materials. This work considers two identified key features from the thermal histories: the time above the apparent melting threshold (/tau) and the maximum radiance (T_{max}). These features are computed, stored for each voxel in the built material, are used as inputs. The binary state of each voxel, either defective or normal, is the output. Different ML models are trained and tested for the binary classification task. In addition to using the thermal features of each voxel to predict its own state, the thermal features of neighboring voxels are also included as inputs. This is shown to improve the prediction accuracy, which is consistent with thermal transport physics around each voxel contributing to its final state. Among the models trained, the F1 scores on test sets reach above 0.96 for random forests. Feature importance analysis based on the ML models shows that T_{max}is more important to the voxel state than /tau. The analysis also finds that the thermal history of the voxels above the present voxel is more influential than those beneath it.
A convolutional neural-network model of human cochlear mechanics and filter tuning for real-time applications
Apr 30, 2020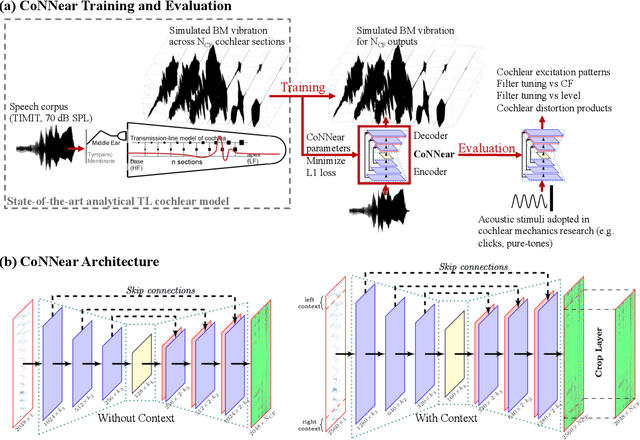
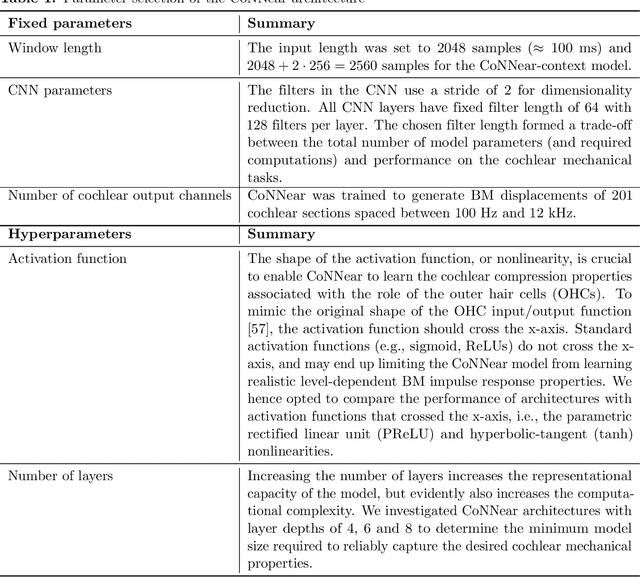
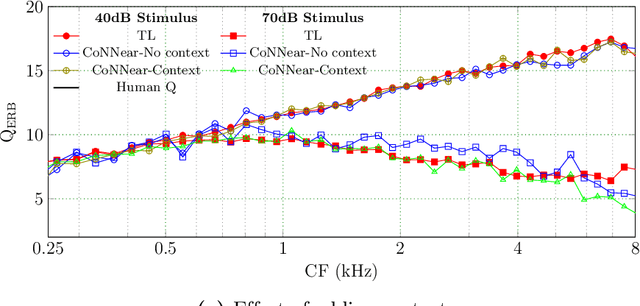

Auditory models are commonly used as feature extractors for automatic speech recognition systems or as front-ends for robotics, machine-hearing and hearing-aid applications. While over the years, auditory models have progressed to capture the biophysical and nonlinear properties of human hearing in great detail, these biophysical models are slow to compute and consequently not used in real-time applications. To enable an uptake, we present a hybrid approach where convolutional neural networks are combined with computational neuroscience to yield a real-time end-to-end model for human cochlear mechanics and level-dependent cochlear filter tuning (CoNNear). The CoNNear model was trained on acoustic speech material, but its performance and applicability evaluated using (unseen) sound stimuli common in cochlear mechanics research. The CoNNear model accurately simulates human frequency selectivity and its dependence on sound intensity, which is essential for our hallmark robust speech intelligibility performance, even at negative speech-to-background noise ratios. Because its architecture is based on real-time, parallel and differentiatable computations, the CoNNear model has the power to leverage real-time auditory applications towards human performance and can inspire the next generation of speech recognition, robotics and hearing-aid systems.
Locally-symplectic neural networks for learning volume-preserving dynamics
Sep 19, 2021
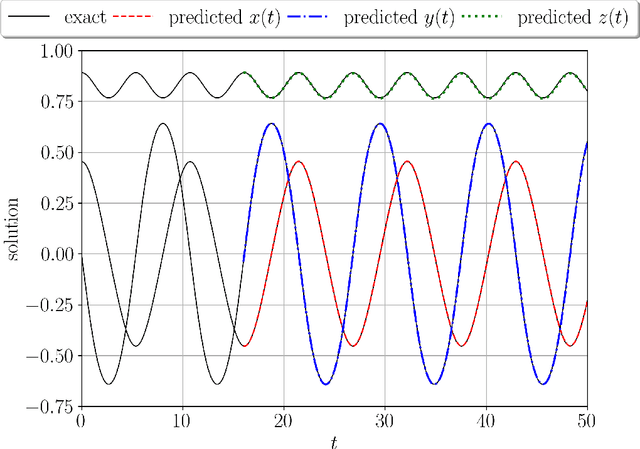
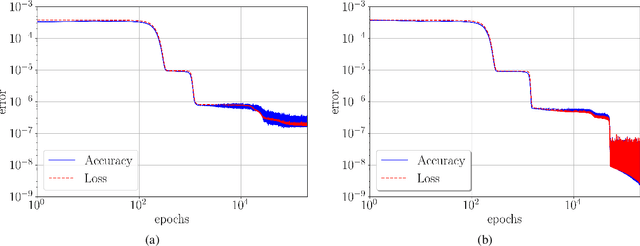
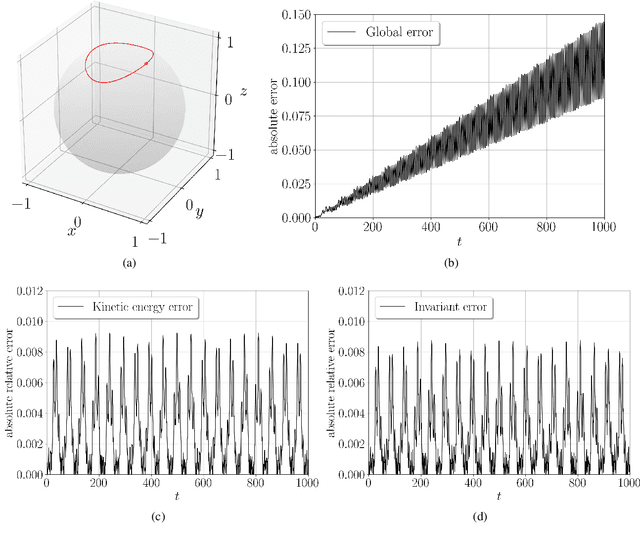
We propose locally-symplectic neural networks LocSympNets for learning volume-preserving dynamics. The construction of LocSympNets stems from the theorem of local Hamiltonian description of the vector field of a volume-preserving dynamical system and the splitting methods based on symplectic integrators. Modified gradient modules of recently proposed symplecticity-preserving neural networks SympNets are used to construct locally-symplectic modules, which composition results in volume-preserving neural networks. LocSympNets are studied numerically considering linear and nonlinear dynamics, i.e., semi-discretized advection equation and Euler equations of the motion of a free rigid body, respectively. LocSympNets are able to learn linear and nonlinear dynamics to high degree of accuracy. When learning a single trajectory of the rigid body dynamics LocSympNets are able to learn both invariants of the system with absolute relative errors below 1% in long-time predictions and produce qualitatively good short-time predictions, when the learning of the whole system from randomly sampled data is considered.
YOLObile: Real-Time Object Detection on Mobile Devices via Compression-Compilation Co-Design
Sep 12, 2020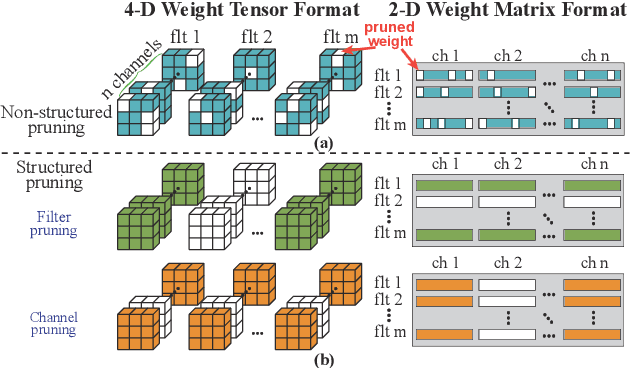
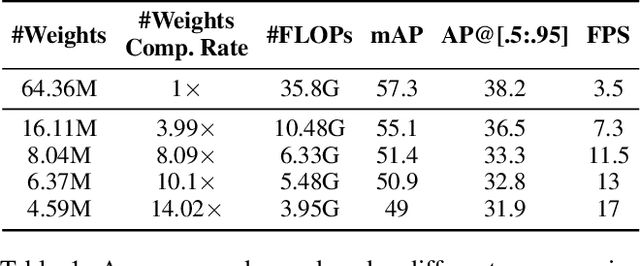
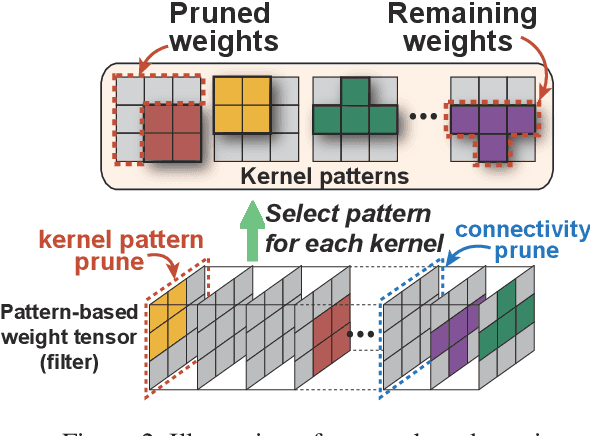
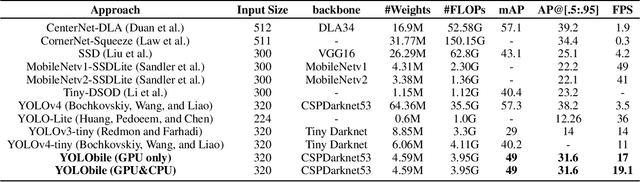
The rapid development and wide utilization of object detection techniques have aroused attention on both accuracy and speed of object detectors. However, the current state-of-the-art object detection works are either accuracy-oriented using a large model but leading to high latency or speed-oriented using a lightweight model but sacrificing accuracy. In this work, we propose YOLObile framework, a real-time object detection on mobile devices via compression-compilation co-design. A novel block-punched pruning scheme is proposed for any kernel size. To improve computational efficiency on mobile devices, a GPU-CPU collaborative scheme is adopted along with advanced compiler-assisted optimizations. Experimental results indicate that our pruning scheme achieves 14$\times$ compression rate of YOLOv4 with 49.0 mAP. Under our YOLObile framework, we achieve 17 FPS inference speed using GPU on Samsung Galaxy S20. By incorporating our proposed GPU-CPU collaborative scheme, the inference speed is increased to 19.1 FPS, and outperforms the original YOLOv4 by 5$\times$ speedup.
Improving Adversarial Robustness for Free with Snapshot Ensemble
Oct 07, 2021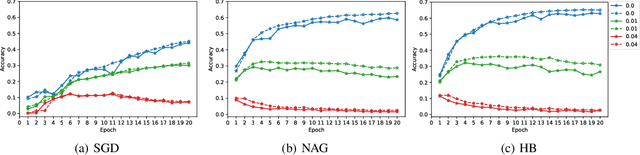
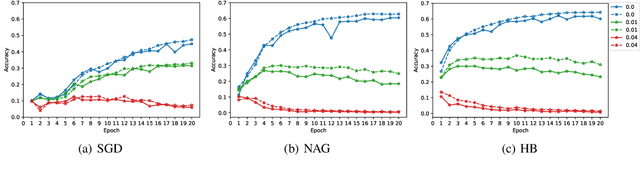


Adversarial training, as one of the few certified defenses against adversarial attacks, can be quite complicated and time-consuming, while the results might not be robust enough. To address the issue of lack of robustness, ensemble methods were proposed, aiming to get the final output by weighting the selected results from repeatedly trained processes. It is proved to be very useful in achieving robust and accurate results, but the computational and memory costs are even higher. Snapshot ensemble, a new ensemble method that combines several local minima in a single training process to make the final prediction, was proposed recently, which reduces the time spent on training multiple networks and the memory to store the results. Based on the snapshot ensemble, we present a new method that is easier to implement: unlike original snapshot ensemble that seeks for local minima, our snapshot ensemble focuses on the last few iterations of a training and stores the sets of parameters from them. Our algorithm is much simpler but the results are no less accurate than the original ones: based on different hyperparameters and datasets, our snapshot ensemble has shown a 5% to 30% increase in accuracy when compared to the traditional adversarial training.
Traversing the Local Polytopes of ReLU Neural Networks: A Unified Approach for Network Verification
Nov 17, 2021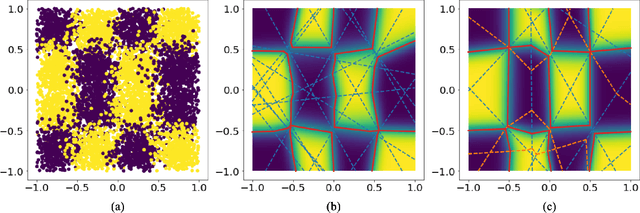
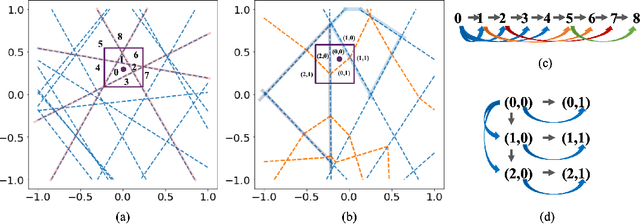
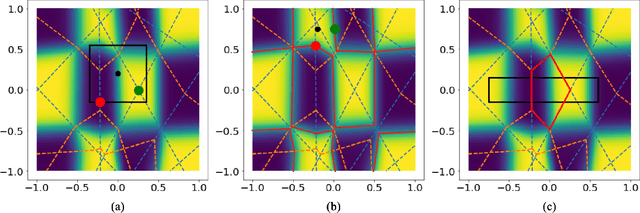
Although neural networks (NNs) with ReLU activation functions have found success in a wide range of applications, their adoption in risk-sensitive settings has been limited by the concerns on robustness and interpretability. Previous works to examine robustness and to improve interpretability partially exploited the piecewise linear function form of ReLU NNs. In this paper, we explore the unique topological structure that ReLU NNs create in the input space, identifying the adjacency among the partitioned local polytopes and developing a traversing algorithm based on this adjacency. Our polytope traversing algorithm can be adapted to verify a wide range of network properties related to robustness and interpretability, providing an unified approach to examine the network behavior. As the traversing algorithm explicitly visits all local polytopes, it returns a clear and full picture of the network behavior within the traversed region. The time and space complexity of the traversing algorithm is determined by the number of a ReLU NN's partitioning hyperplanes passing through the traversing region.
Classification-Then-Grounding: Reformulating Video Scene Graphs as Temporal Bipartite Graphs
Dec 08, 2021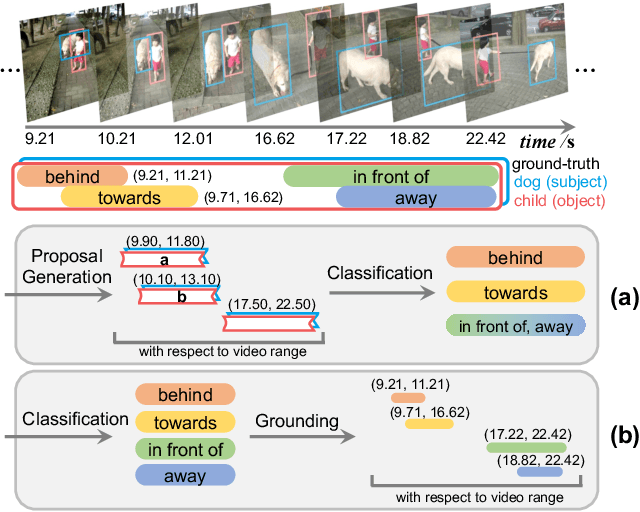
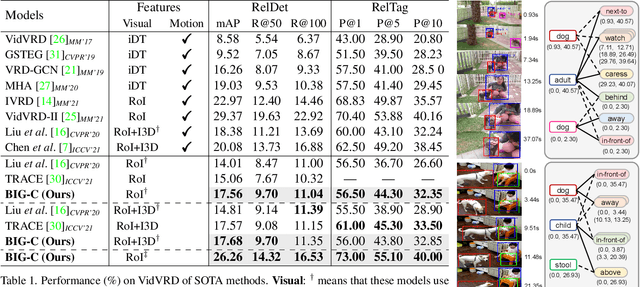
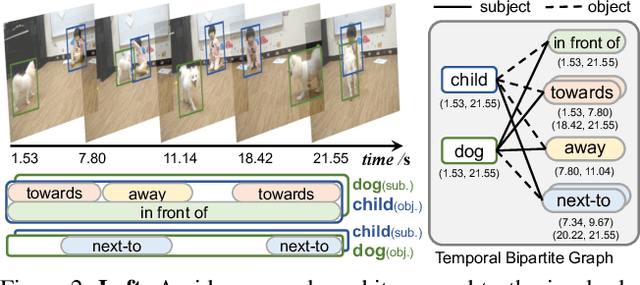
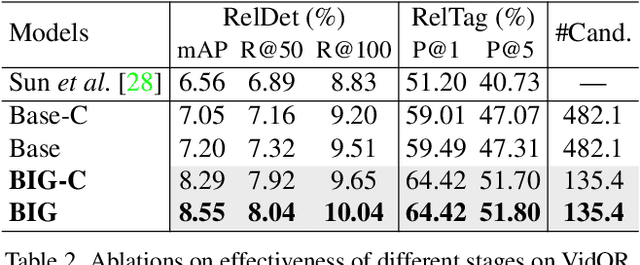
Today's VidSGG models are all proposal-based methods, i.e., they first generate numerous paired subject-object snippets as proposals, and then conduct predicate classification for each proposal. In this paper, we argue that this prevalent proposal-based framework has three inherent drawbacks: 1) The ground-truth predicate labels for proposals are partially correct. 2) They break the high-order relations among different predicate instances of a same subject-object pair. 3) VidSGG performance is upper-bounded by the quality of the proposals. To this end, we propose a new classification-then-grounding framework for VidSGG, which can avoid all the three overlooked drawbacks. Meanwhile, under this framework, we reformulate the video scene graphs as temporal bipartite graphs, where the entities and predicates are two types of nodes with time slots, and the edges denote different semantic roles between these nodes. This formulation takes full advantage of our new framework. Accordingly, we further propose a novel BIpartite Graph based SGG model: BIG. Specifically, BIG consists of two parts: a classification stage and a grounding stage, where the former aims to classify the categories of all the nodes and the edges, and the latter tries to localize the temporal location of each relation instance. Extensive ablations on two VidSGG datasets have attested to the effectiveness of our framework and BIG.
Cube Sampled K-Prototype Clustering for Featured Data
Aug 23, 2021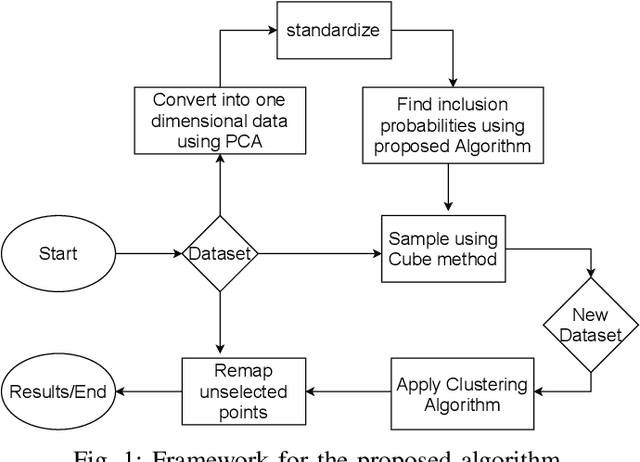
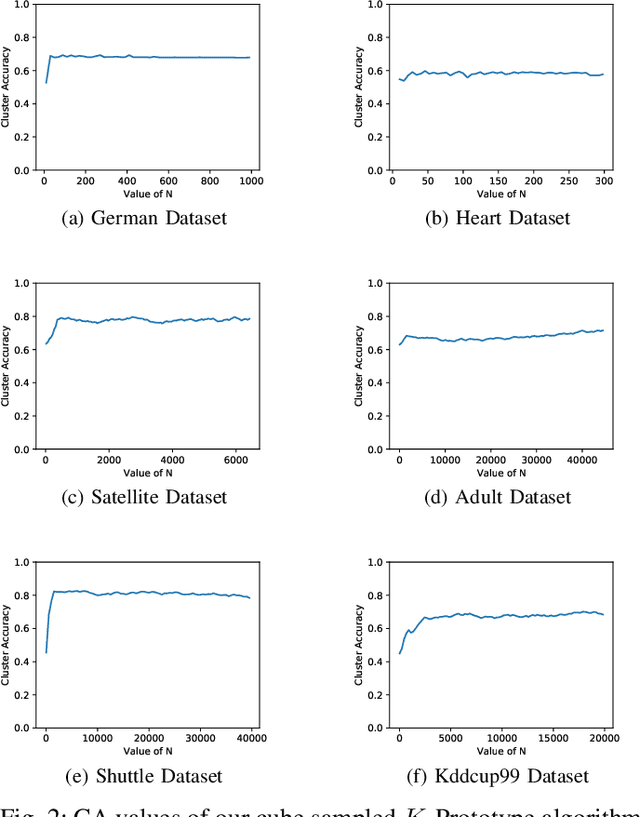
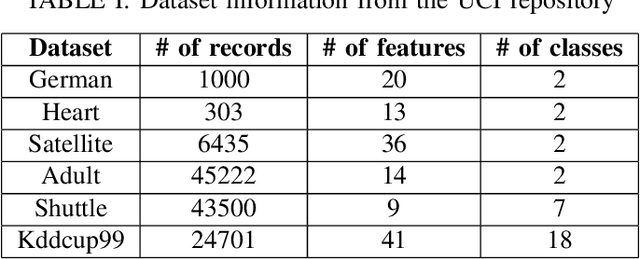
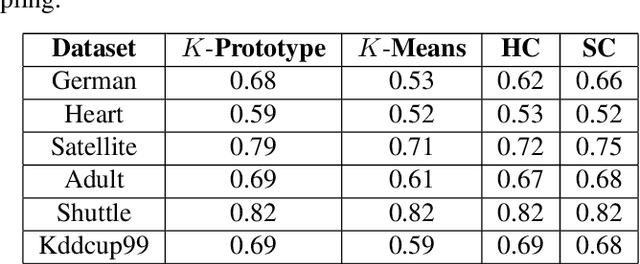
Clustering large amount of data is becoming increasingly important in the current times. Due to the large sizes of data, clustering algorithm often take too much time. Sampling this data before clustering is commonly used to reduce this time. In this work, we propose a probabilistic sampling technique called cube sampling along with K-Prototype clustering. Cube sampling is used because of its accurate sample selection. K-Prototype is most frequently used clustering algorithm when the data is numerical as well as categorical (very common in today's time). The novelty of this work is in obtaining the crucial inclusion probabilities for cube sampling using Principal Component Analysis (PCA). Experiments on multiple datasets from the UCI repository demonstrate that cube sampled K-Prototype algorithm gives the best clustering accuracy among similarly sampled other popular clustering algorithms (K-Means, Hierarchical Clustering (HC), Spectral Clustering (SC)). When compared with unsampled K-Prototype, K-Means, HC and SC, it still has the best accuracy with the added advantage of reduced computational complexity (due to reduced data size).