 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Training Wasserstein GANs without gradient penalties
Oct 27, 2021
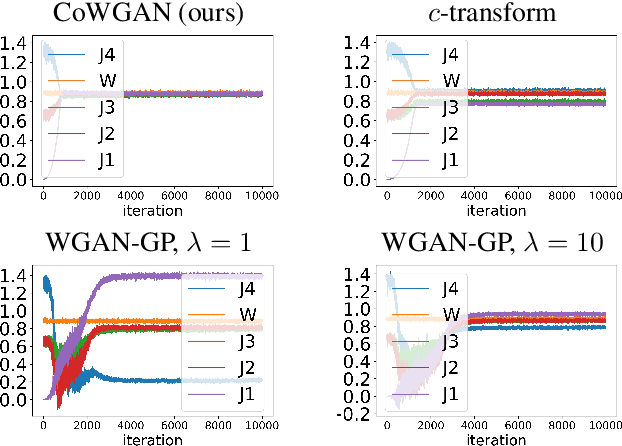

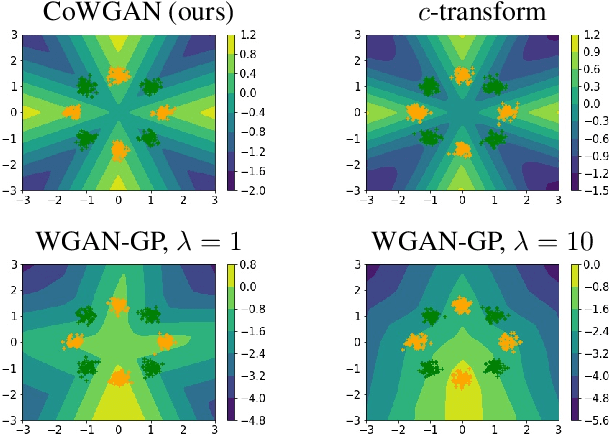
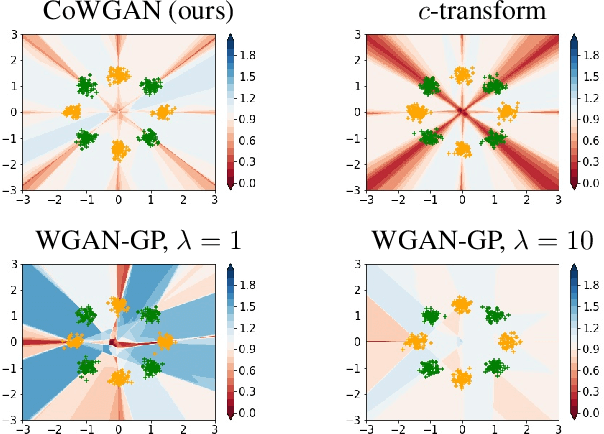
We propose a stable method to train Wasserstein generative adversarial networks. In order to enhance stability, we consider two objective functions using the $c$-transform based on Kantorovich duality which arises in the theory of optimal transport. We experimentally show that this algorithm can effectively enforce the Lipschitz constraint on the discriminator while other standard methods fail to do so. As a consequence, our method yields an accurate estimation for the optimal discriminator and also for the Wasserstein distance between the true distribution and the generated one. Our method requires no gradient penalties nor corresponding hyperparameter tuning and is computationally more efficient than other methods. At the same time, it yields competitive generators of synthetic images based on the MNIST, F-MNIST, and CIFAR-10 datasets.
Antenna De-Embedding in FDTD Using Spherical Wave Functions by Exploiting Orthogonality
Nov 03, 2021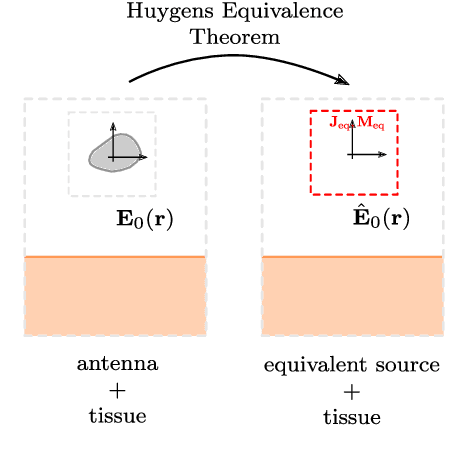
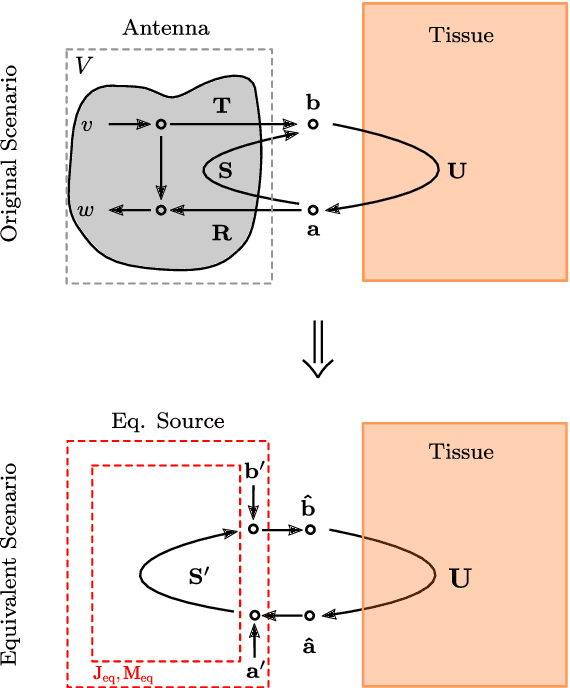
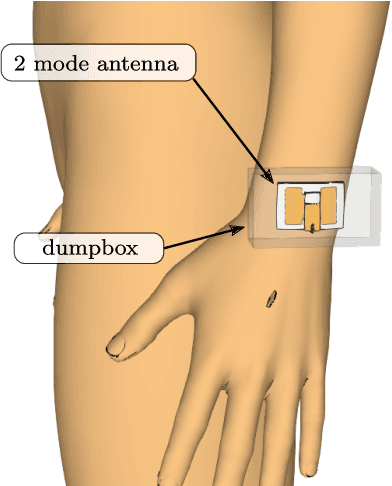
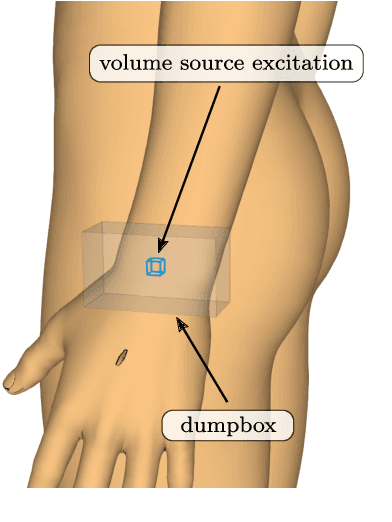
De-embedding antennas from the channel using Spherical Wave Functions (SWF) is a useful method to reduce the numerical effort in the simulation of wearable antennas. In this paper an analytical solution to the De-embedding problem is presented in form of surface integrals. This new integral solution is helpful on a theoretical level to derive insights and is also well suited for implementation in Finite Difference Time Domain (FDTD) numerical software. The spherical wave function coefficients are calculated directly from near-field values. Furthermore, the presence of a near-field scatterer in the de-embedding problem is discussed on a theoretical level based on the Huygens Equivalence Theorem. This makes it possible to exploit the degrees of freedom in such a way that it is sufficient to only use out-going spherical wave functions and still obtain correct results.
Semi-Supervised Contrastive Learning for Remote Sensing: Identifying Ancient Urbanization in the South Central Andes
Dec 13, 2021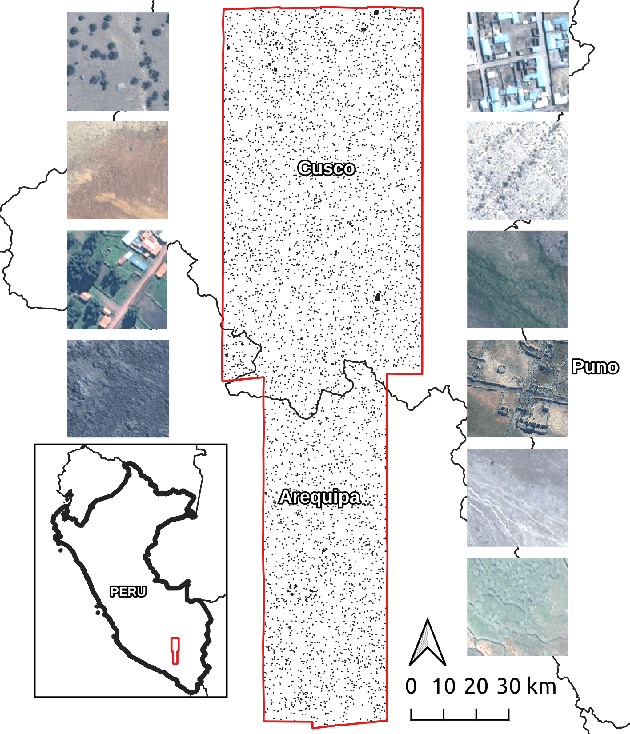

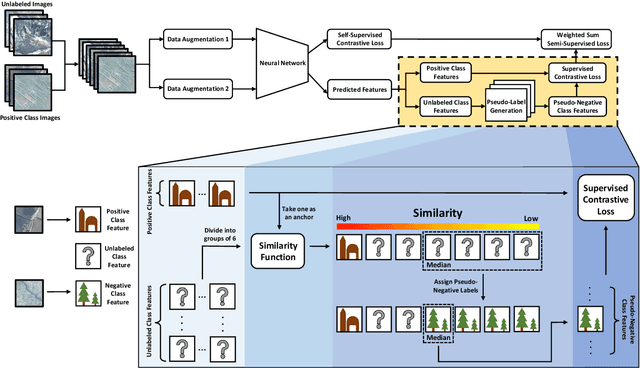

The detection of ancient settlements is a key focus in landscape archaeology. Traditionally, settlements were identified through pedestrian survey, as researchers physically traversed the landscape and recorded settlement locations. Recently the manual identification and labeling of ancient remains in satellite imagery have increased the scale of archaeological data collection, but the process remains tremendously time-consuming and arduous. The development of self-supervised learning (e.g., contrastive learning) offers a scalable learning scheme in locating archaeological sites using unlabeled satellite and historical aerial images. However, archaeology sites are only present in a very small proportion of the whole landscape, while the modern contrastive-supervised learning approach typically yield inferior performance on the highly balanced dataset, such as identifying sparsely localized ancient urbanization on a large area using satellite images. In this work, we propose a framework to solve this long-tail problem. As opposed to the existing contrastive learning approaches that typically treat the labeled and unlabeled data separately, the proposed method reforms the learning paradigm under a semi-supervised setting to fully utilize the precious annotated data (<7% in our setting). Specifically, the highly unbalanced nature of the data is employed as the prior knowledge to form pseudo negative pairs by ranking the similarities between unannotated image patches and annotated anchor images. In this study, we used 95,358 unlabeled images and 5,830 labeled images to solve the problem of detecting ancient buildings from a long-tailed satellite image dataset. From the results, our semi-supervised contrastive learning model achieved a promising testing balanced accuracy of 79.0%, which is 3.8% improvement over state-of-the-art approaches.
RIS-aided D2D Communication Design for URLLC Packet Delivery
Nov 26, 2021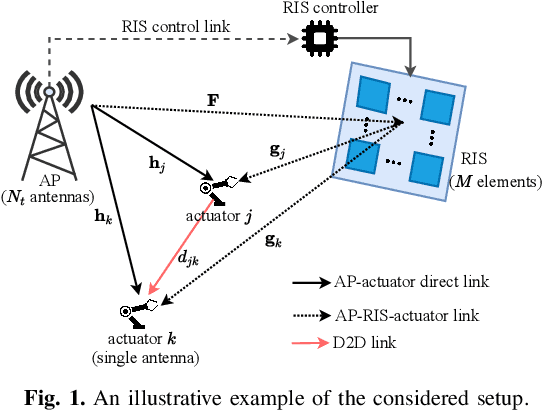
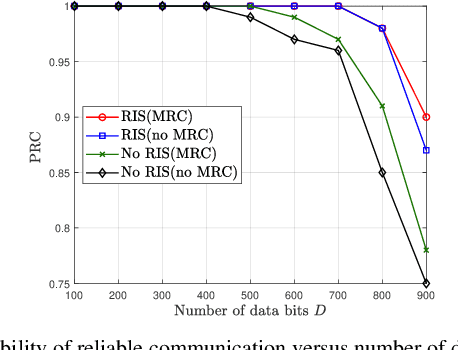
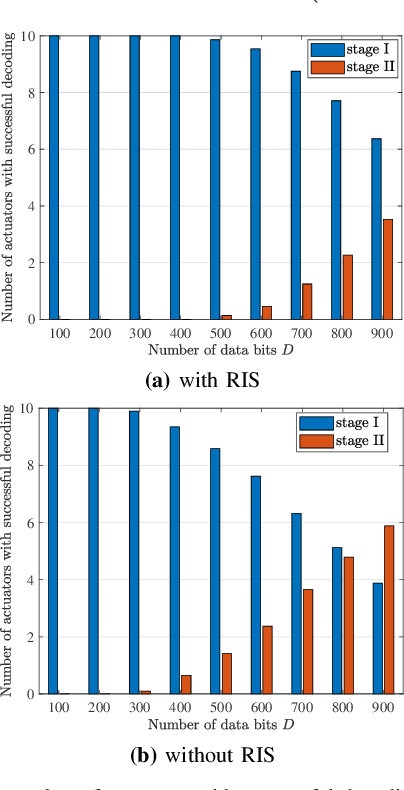
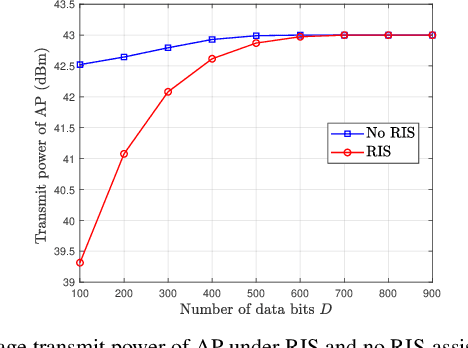
In this paper, we consider a smart factory scenario where a set of actuators receive critical control signals from an access point (AP) with reliability and low latency requirements. We investigate jointly active beamforming at the AP and passive phase shifting at the reconfigurable intelligent surface (RIS) for successfully delivering the control signals from the AP to the actuators within a required time duration. The transmission follows a two-stage design. In the first stage, each actuator can both receive the direct signal from AP and the reflected signal from the RIS. In the second stage, the actuators with successful reception in the first stage, relay the message through the D2D network to the actuators with failed receptions. We formulate a non-convex optimization problem where we first obtain an equivalent but more tractable form by addressing the problem with discrete indicator functions. Then, Frobenius inner product based equality is applied for decoupling the optimization variables. Further, we adopt a penalty-based approach to resolve the rank-one constraints. Finally, we deal with the $\ell_0$-norm by $\ell_1$-norm approximation and add an extra term $\ell_1-\ell_2$ for sparsity. Numerical results reveal that the proposed two-stage RIS-aided D2D communication protocol is effective for enabling reliable communication with latency requirements.
Confounder Identification-free Causal Visual Feature Learning
Nov 26, 2021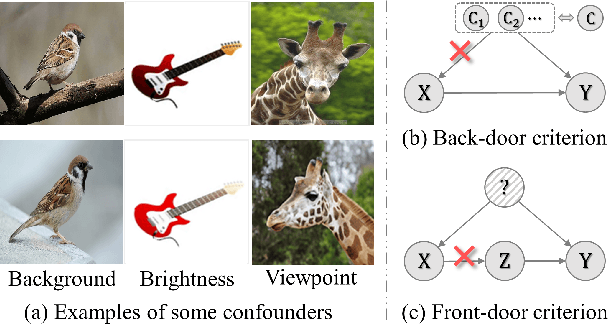
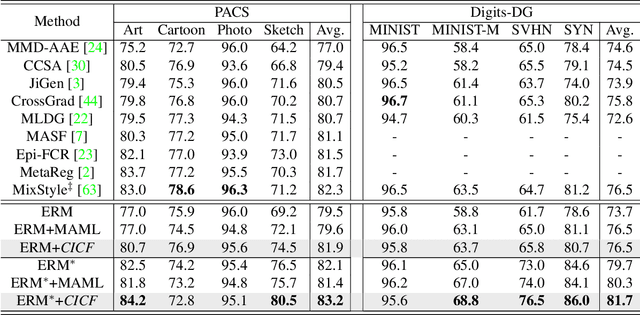
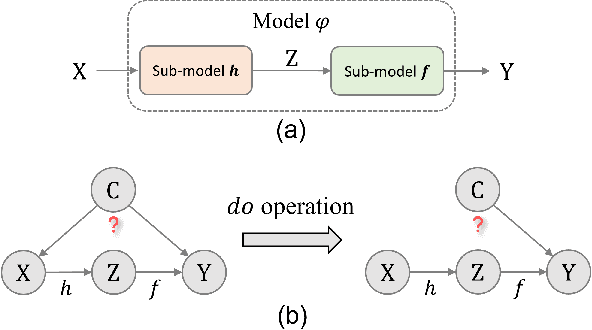
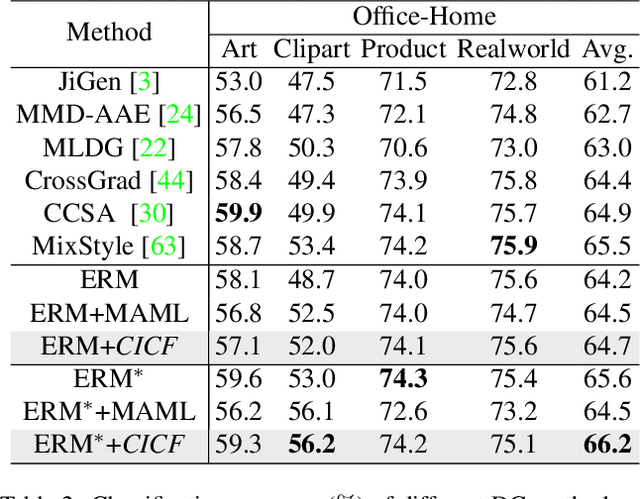
Confounders in deep learning are in general detrimental to model's generalization where they infiltrate feature representations. Therefore, learning causal features that are free of interference from confounders is important. Most previous causal learning based approaches employ back-door criterion to mitigate the adverse effect of certain specific confounder, which require the explicit identification of confounder. However, in real scenarios, confounders are typically diverse and difficult to be identified. In this paper, we propose a novel Confounder Identification-free Causal Visual Feature Learning (CICF) method, which obviates the need for identifying confounders. CICF models the interventions among different samples based on front-door criterion, and then approximates the global-scope intervening effect upon the instance-level interventions from the perspective of optimization. In this way, we aim to find a reliable optimization direction, which avoids the intervening effects of confounders, to learn causal features. Furthermore, we uncover the relation between CICF and the popular meta-learning strategy MAML, and provide an interpretation of why MAML works from the theoretical perspective of causal learning for the first time. Thanks to the effective learning of causal features, our CICF enables models to have superior generalization capability. Extensive experiments on domain generalization benchmark datasets demonstrate the effectiveness of our CICF, which achieves the state-of-the-art performance.
Stacked Generative Machine Learning Models for Fast Approximations of Steady-State Navier-Stokes Equations
Dec 13, 2021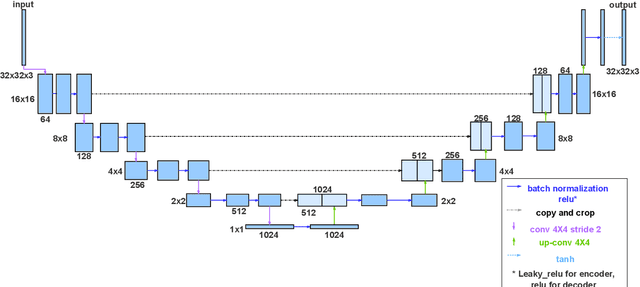
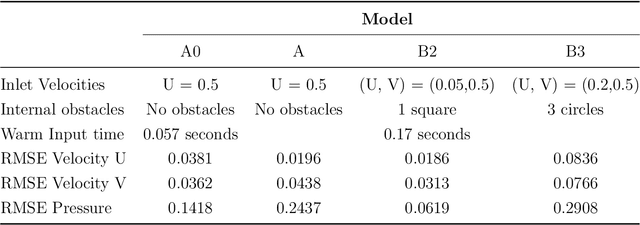
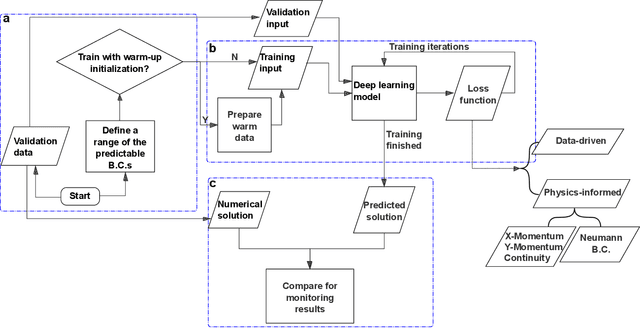
Computational fluid dynamics (CFD) simulations are broadly applied in engineering and physics. A standard description of fluid dynamics requires solving the Navier-Stokes (N-S) equations in different flow regimes. However, applications of CFD simulations are computationally-limited by the availability, speed, and parallelism of high-performance computing. To improve computational efficiency, machine learning techniques have been used to create accelerated data-driven approximations for CFD. A majority of such approaches rely on large labeled CFD datasets that are expensive to obtain at the scale necessary to build robust data-driven models. We develop a weakly-supervised approach to solve the steady-state N-S equations under various boundary conditions, using a multi-channel input with boundary and geometric conditions. We achieve state-of-the-art results without any labeled simulation data, but using a custom data-driven and physics-informed loss function by using and small-scale solutions to prime the model to solve the N-S equations. To improve the resolution and predictability, we train stacked models of increasing complexity generating the numerical solutions for N-S equations. Without expensive computations, our model achieves high predictability with a variety of obstacles and boundary conditions. Given its high flexibility, the model can generate a solution on a 64 x 64 domain within 5 ms on a regular desktop computer which is 1000 times faster than a regular CFD solver. Translation of interactive CFD simulation on local consumer computing hardware enables new applications in real-time predictions on the internet of things devices where data transfer is prohibitive and can increase the scale, speed, and computational cost of boundary-value fluid problems.
A Single Stream Network for Robust and Real-time RGB-D Salient Object Detection
Jul 15, 2020
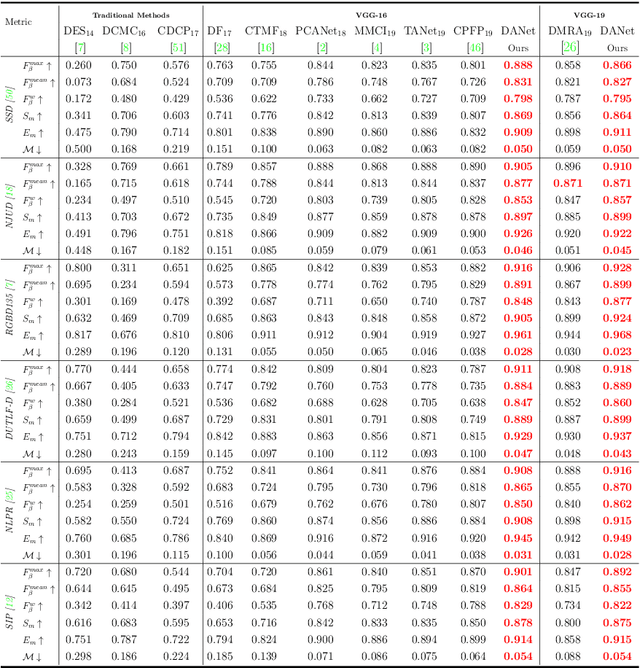
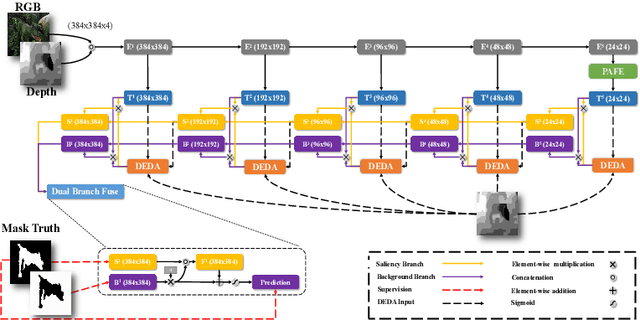

Existing RGB-D salient object detection (SOD) approaches concentrate on the cross-modal fusion between the RGB stream and the depth stream. They do not deeply explore the effect of the depth map itself. In this work, we design a single stream network to directly use the depth map to guide early fusion and middle fusion between RGB and depth, which saves the feature encoder of the depth stream and achieves a lightweight and real-time model. We tactfully utilize depth information from two perspectives: (1) Overcoming the incompatibility problem caused by the great difference between modalities, we build a single stream encoder to achieve the early fusion, which can take full advantage of ImageNet pre-trained backbone model to extract rich and discriminative features. (2) We design a novel depth-enhanced dual attention module (DEDA) to efficiently provide the fore-/back-ground branches with the spatially filtered features, which enables the decoder to optimally perform the middle fusion. Besides, we put forward a pyramidally attended feature extraction module (PAFE) to accurately localize the objects of different scales. Extensive experiments demonstrate that the proposed model performs favorably against most state-of-the-art methods under different evaluation metrics. Furthermore, this model is 55.5\% lighter than the current lightest model and runs at a real-time speed of 32 FPS when processing a $384 \times 384$ image.
Independent SE(3)-Equivariant Models for End-to-End Rigid Protein Docking
Nov 15, 2021



Protein complex formation is a central problem in biology, being involved in most of the cell's processes, and essential for applications, e.g. drug design or protein engineering. We tackle rigid body protein-protein docking, i.e., computationally predicting the 3D structure of a protein-protein complex from the individual unbound structures, assuming no conformational change within the proteins happens during binding. We design a novel pairwise-independent SE(3)-equivariant graph matching network to predict the rotation and translation to place one of the proteins at the right docked position relative to the second protein. We mathematically guarantee a basic principle: the predicted complex is always identical regardless of the initial locations and orientations of the two structures. Our model, named EquiDock, approximates the binding pockets and predicts the docking poses using keypoint matching and alignment, achieved through optimal transport and a differentiable Kabsch algorithm. Empirically, we achieve significant running time improvements and often outperform existing docking software despite not relying on heavy candidate sampling, structure refinement, or templates.
Multi-Agent Path Planning Using Deep Reinforcement Learning
Oct 04, 2021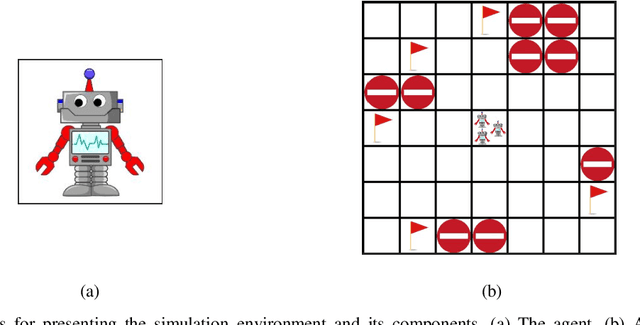
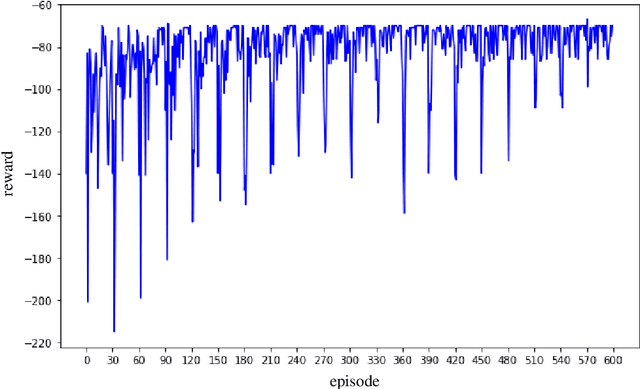
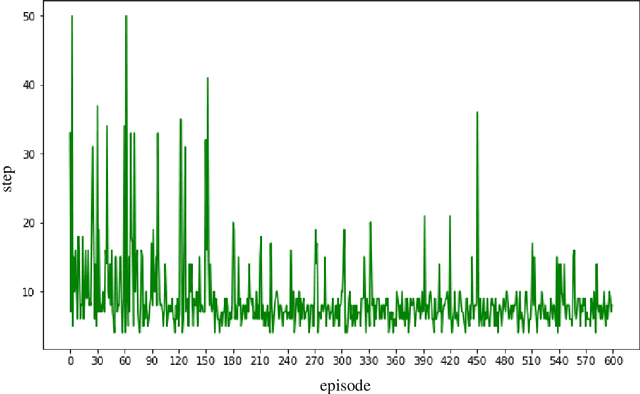
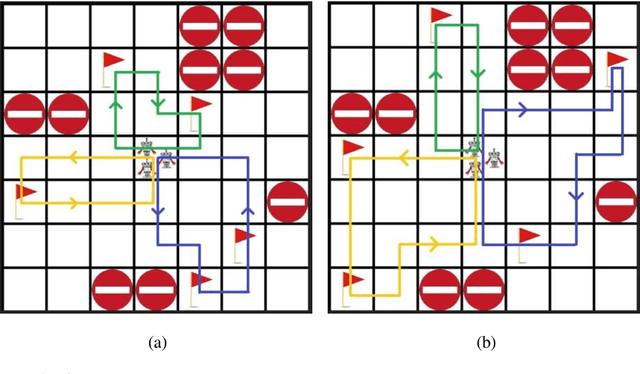
In this paper a deep reinforcement based multi-agent path planning approach is introduced. The experiments are realized in a simulation environment and in this environment different multi-agent path planning problems are produced. The produced problems are actually similar to a vehicle routing problem and they are solved using multi-agent deep reinforcement learning. In the simulation environment, the model is trained on different consecutive problems in this way and, as the time passes, it is observed that the model's performance to solve a problem increases. Always the same simulation environment is used and only the location of target points for the agents to visit is changed. This contributes the model to learn its environment and the right attitude against a problem as the episodes pass. At the end, a model who has already learned a lot to solve a path planning or routing problem in this environment is obtained and this model can already find a nice and instant solution to a given unseen problem even without any training. In routing problems, standard mathematical modeling or heuristics seem to suffer from high computational time to find the solution and it is also difficult and critical to find an instant solution. In this paper a new solution method against these points is proposed and its efficiency is proven experimentally.
3d sequential image mosaicing for underwater navigation and mapping
Oct 04, 2021
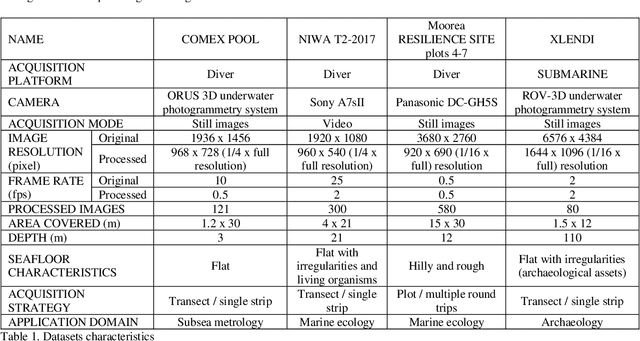
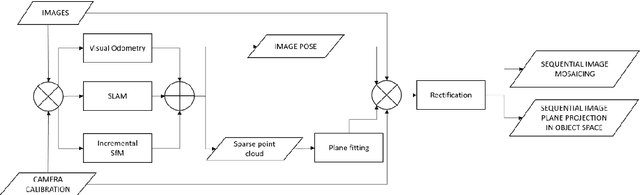

Although fully autonomous mapping methods are becoming more and more common and reliable, still the human operator is regularly employed in many 3D surveying missions. In a number of underwater applications, divers or pilots of remotely operated vehicles (ROVs) are still considered irreplaceable, and tools for real-time visualization of the mapped scene are essential to support and maximize the navigation and surveying efforts. For underwater exploration, image mosaicing has proved to be a valid and effective approach to visualize large mapped areas, often employed in conjunction with autonomous underwater vehicles (AUVs) and ROVs. In this work, we propose the use of a modified image mosaicing algorithm that coupled with image-based real-time navigation and mapping algorithms provides two visual navigation aids. The first is a classic image mosaic, where the recorded and processed images are incrementally added, named 2D sequential image mosaicing (2DSIM). The second one geometrically transform the images so that they are projected as planar point clouds in the 3D space providing an incremental point cloud mosaicing, named 3D sequential image plane projection (3DSIP). In the paper, the implemented procedure is detailed, and experiments in different underwater scenarios presented and discussed. Technical considerations about computational efforts, frame rate capabilities and scalability to different and more compact architectures (i.e. embedded systems) is also provided.