 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-Time High-Performance Semantic Image Segmentation of Urban Street Scenes
Mar 11, 2020
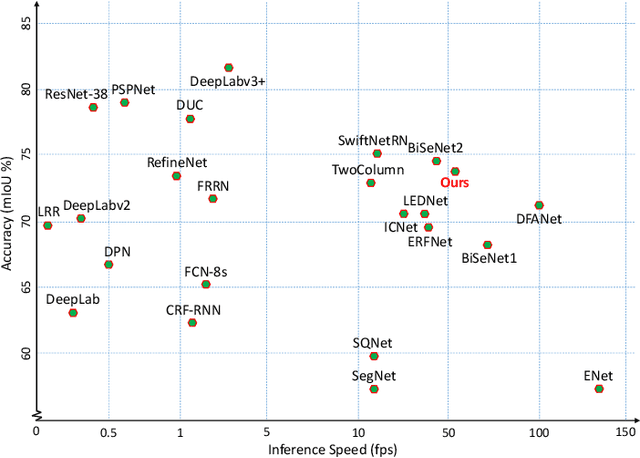


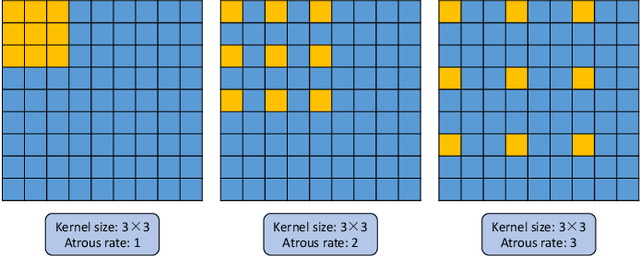
Deep Convolutional Neural Networks (DCNNs) have recently shown outstanding performance in semantic image segmentation. However, state-of-the-art DCNN-based semantic segmentation methods usually suffer from high computational complexity due to the use of complex network architectures. This greatly limits their applications in the real-world scenarios that require real-time processing. In this paper, we propose a real-time high-performance DCNN-based method for robust semantic segmentation of urban street scenes, which achieves a good trade-off between accuracy and speed. Specifically, a Lightweight Baseline Network with Atrous convolution and Attention (LBN-AA) is firstly used as our baseline network to efficiently obtain dense feature maps. Then, the Distinctive Atrous Spatial Pyramid Pooling (DASPP), which exploits the different sizes of pooling operations to encode the rich and distinctive semantic information, is developed to detect objects at multiple scales. Meanwhile, a Spatial detail-Preserving Network (SPN) with shallow convolutional layers is designed to generate high-resolution feature maps preserving the detailed spatial information. Finally, a simple but practical Feature Fusion Network (FFN) is used to effectively combine both shallow and deep features from the semantic branch (DASPP) and the spatial branch (SPN), respectively. Extensive experimental results show that the proposed method respectively achieves the accuracy of 73.6% and 68.0% mean Intersection over Union (mIoU) with the inference speed of 51.0 fps and 39.3 fps on the challenging Cityscapes and CamVid test datasets (by only using a single NVIDIA TITAN X card). This demonstrates that the proposed method offers excellent performance at the real-time speed for semantic segmentation of urban street scenes.
SACBP: Belief Space Planning for Continuous-Time Dynamical Systems via Stochastic Sequential Action Control
Feb 26, 2020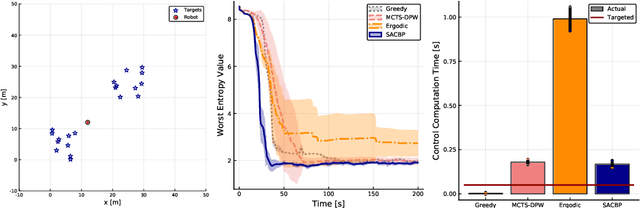
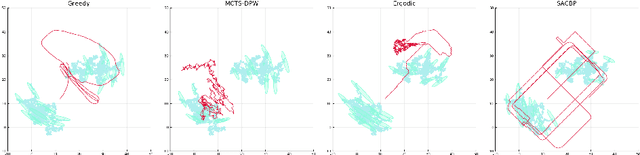
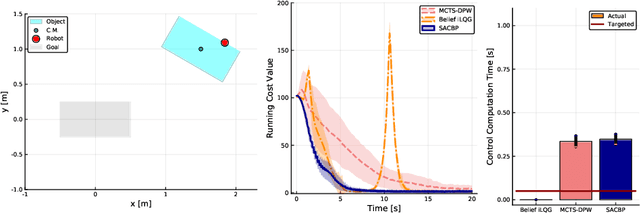
We propose a novel belief space planning technique for continuous dynamics by viewing the belief system as a hybrid dynamical system with time-driven switching. Our approach is based on the perturbation theory of differential equations and extends Sequential Action Control to stochastic belief dynamics. The resulting algorithm, which we name SACBP, does not require discretization of spaces or time and synthesizes control signals in near real-time. SACBP is an anytime algorithm that can handle general parametric Bayesian filters under certain assumptions. We demonstrate the effectiveness of our approach in an active sensing scenario and a model-based Bayesian reinforcement learning problem. In these challenging problems, we show that the algorithm significantly outperforms other existing solution techniques including approximate dynamic programming and local trajectory optimization.
A Survey of Self-Supervised and Few-Shot Object Detection
Oct 27, 2021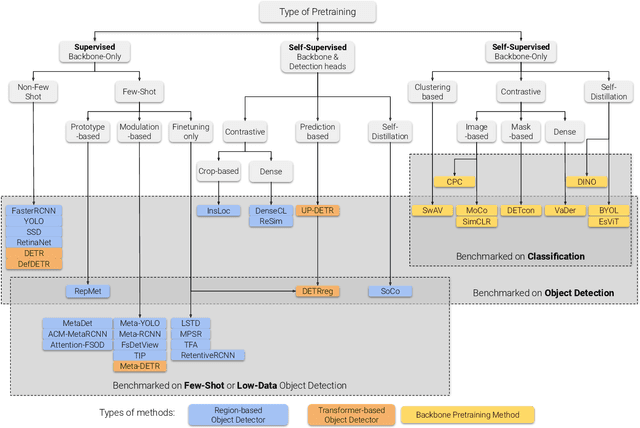

Labeling data is often expensive and time-consuming, especially for tasks such as object detection and instance segmentation, which require dense labeling of the image. While few-shot object detection is about training a model on novel (unseen) object classes with little data, it still requires prior training on many labeled examples of base (seen) classes. On the other hand, self-supervised methods aim at learning representations from unlabeled data which transfer well to downstream tasks such as object detection. Combining few-shot and self-supervised object detection is a promising research direction. In this survey, we review and characterize the most recent approaches on few-shot and self-supervised object detection. Then, we give our main takeaways and discuss future research directions.
Deep Kernel Survival Analysis and Subject-Specific Survival Time Prediction Intervals
Jul 25, 2020Kernel survival analysis methods predict subject-specific survival curves and times using information about which training subjects are most similar to a test subject. These most similar training subjects could serve as forecast evidence. How similar any two subjects are is given by the kernel function. In this paper, we present the first neural network framework that learns which kernel functions to use in kernel survival analysis. We also show how to use kernel functions to construct prediction intervals of survival time estimates that are statistically valid for individuals similar to a test subject. These prediction intervals can use any kernel function, such as ones learned using our neural kernel learning framework or using random survival forests. Our experiments show that our neural kernel survival estimators are competitive with a variety of existing survival analysis methods, and that our prediction intervals can help compare different methods' uncertainties, even for estimators that do not use kernels. In particular, these prediction interval widths can be used as a new performance metric for survival analysis methods.
Towards Live Video Analytics with On-Drone Deeper-yet-Compatible Compression
Nov 10, 2021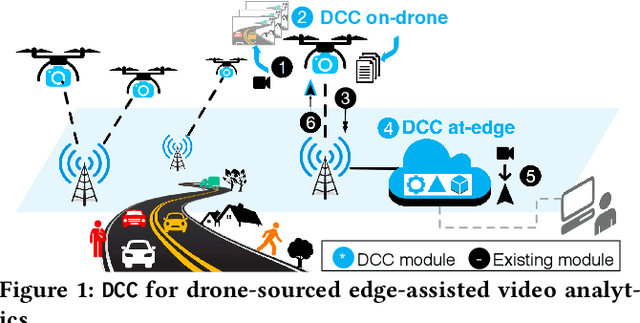

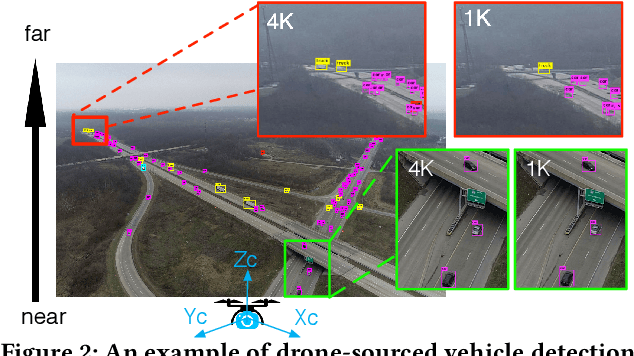
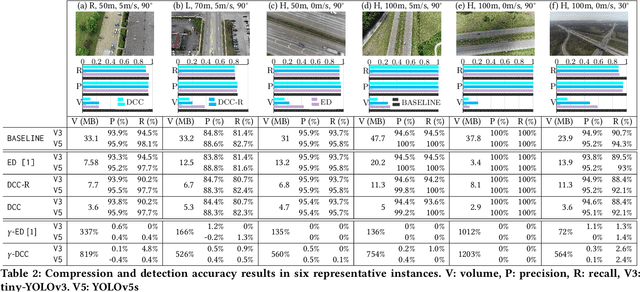
In this work, we present DCC(Deeper-yet-Compatible Compression), one enabling technique for real-time drone-sourced edge-assisted video analytics built on top of the existing codec. DCC tackles an important technical problem to compress streamed video from the drone to the edge without scarifying accuracy and timeliness of video analytical tasks performed at the edge. DCC is inspired by the fact that not every bit in streamed video is equally valuable to video analytics, which opens new compression room over the conventional analytics-oblivious video codec technology. We exploit drone-specific context and intermediate hints from object detection to pursue adaptive fidelity needed to retain analytical quality. We have prototyped DCC in one showcase application of vehicle detection and validated its efficiency in representative scenarios. DCC has reduced transmission volume by 9.5-fold over the baseline approach and 19-683% over the state-of-the-art with comparable detection accuracy.
Pre-training Methods in Information Retrieval
Nov 27, 2021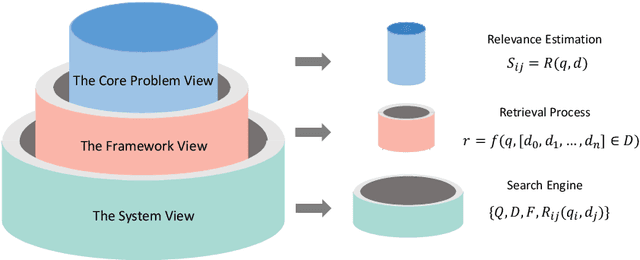
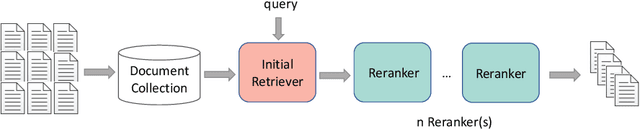
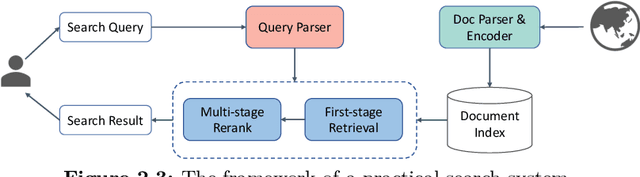

The core of information retrieval (IR) is to identify relevant information from large-scale resources and return it as a ranked list to respond to user's information need. Recently, the resurgence of deep learning has greatly advanced this field and leads to a hot topic named NeuIR (i.e., neural information retrieval), especially the paradigm of pre-training methods (PTMs). Owing to sophisticated pre-training objectives and huge model size, pre-trained models can learn universal language representations from massive textual data, which are beneficial to the ranking task of IR. Since there have been a large number of works dedicating to the application of PTMs in IR, we believe it is the right time to summarize the current status, learn from existing methods, and gain some insights for future development. In this survey, we present an overview of PTMs applied in different components of IR system, including the retrieval component, the re-ranking component, and other components. In addition, we also introduce PTMs specifically designed for IR, and summarize available datasets as well as benchmark leaderboards. Moreover, we discuss some open challenges and envision some promising directions, with the hope of inspiring more works on these topics for future research.
Machine Learning-Assisted Analysis of Small Angle X-ray Scattering
Nov 16, 2021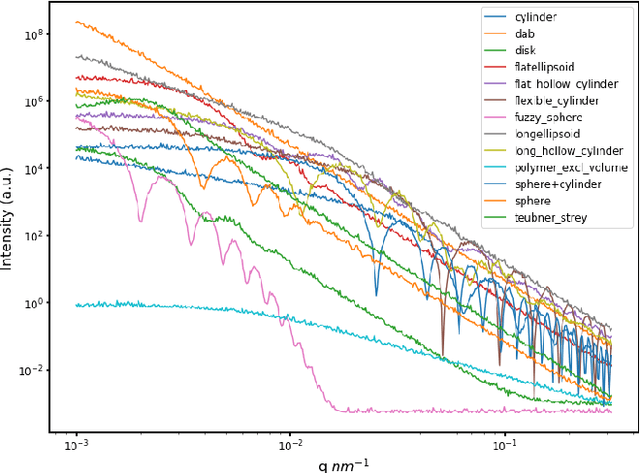
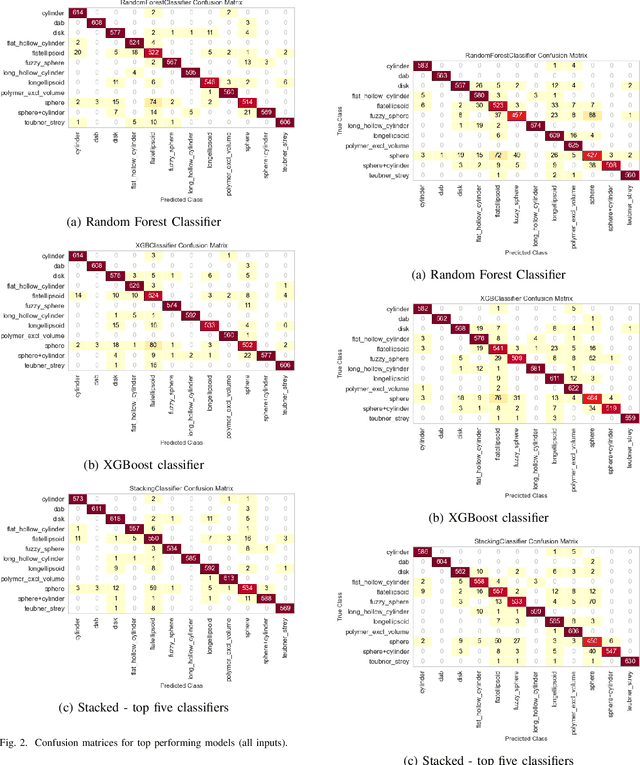
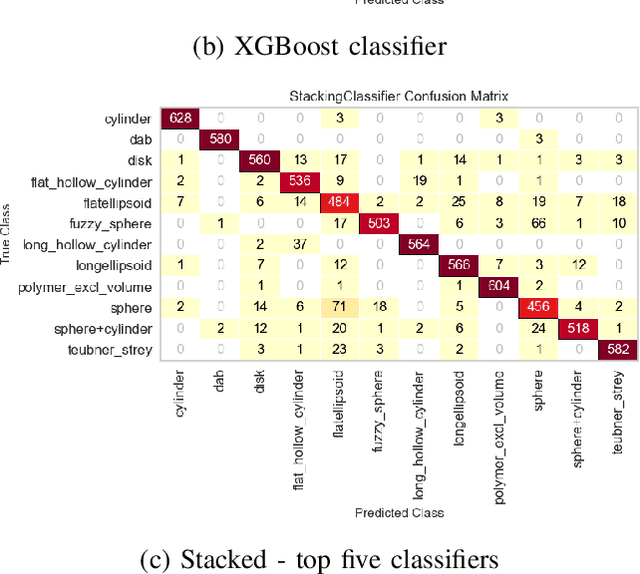
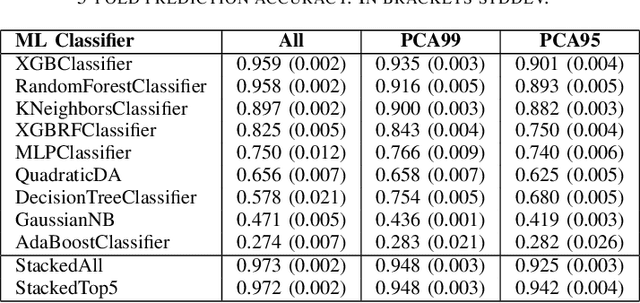
Small angle X-ray scattering (SAXS) is extensively used in materials science as a way of examining nanostructures. The analysis of experimental SAXS data involves mapping a rather simple data format to a vast amount of structural models. Despite various scientific computing tools to assist the model selection, the activity heavily relies on the SAXS analysts' experience, which is recognized as an efficiency bottleneck by the community. To cope with this decision-making problem, we develop and evaluate the open-source, Machine Learning-based tool SCAN (SCattering Ai aNalysis) to provide recommendations on model selection. SCAN exploits multiple machine learning algorithms and uses models and a simulation tool implemented in the SasView package for generating a well defined set of datasets. Our evaluation shows that SCAN delivers an overall accuracy of 95%-97%. The XGBoost Classifier has been identified as the most accurate method with a good balance between accuracy and training time. With eleven predefined structural models for common nanostructures and an easy draw-drop function to expand the number and types training models, SCAN can accelerate the SAXS data analysis workflow.
Inductive Conformal Recommender System
Sep 18, 2021
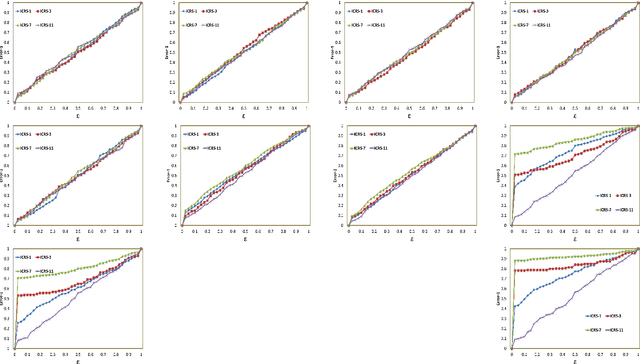
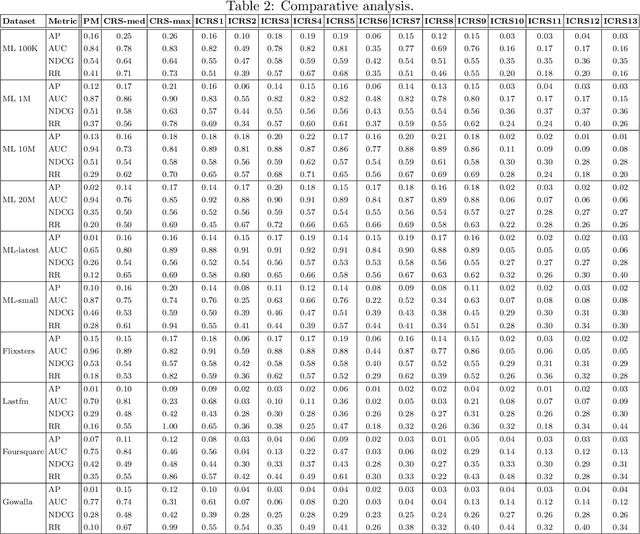
Traditional recommendation algorithms develop techniques that can help people to choose desirable items. However, in many real-world applications, along with a set of recommendations, it is also essential to quantify each recommendation's (un)certainty. The conformal recommender system uses the experience of a user to output a set of recommendations, each associated with a precise confidence value. Given a significance level $\varepsilon$, it provides a bound $\varepsilon$ on the probability of making a wrong recommendation. The conformal framework uses a key concept called nonconformity measure that measure the strangeness of an item concerning other items. One of the significant design challenges of any conformal recommendation framework is integrating nonconformity measure with the recommendation algorithm. In this paper, we introduce an inductive variant of a conformal recommender system. We propose and analyze different nonconformity measures in the inductive setting. We also provide theoretical proofs on the error-bound and the time complexity. Extensive empirical analysis on ten benchmark datasets demonstrates that the inductive variant substantially improves the performance in computation time while preserving the accuracy.
Continuous Latent Process Flows
Jun 29, 2021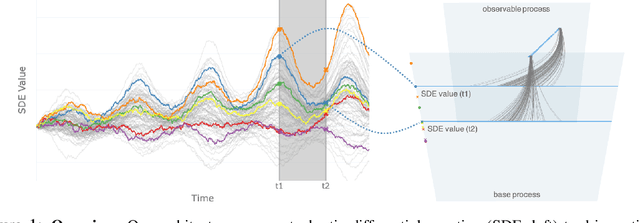
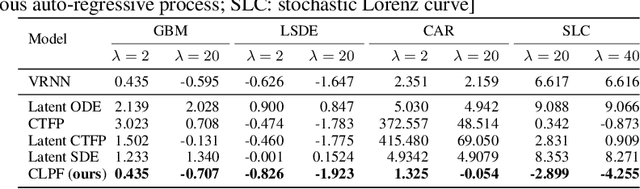
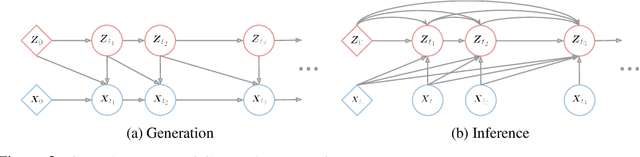
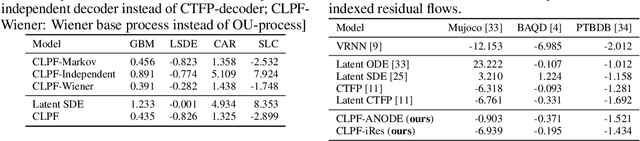
Partial observations of continuous time-series dynamics at arbitrary time stamps exist in many disciplines. Fitting this type of data using statistical models with continuous dynamics is not only promising at an intuitive level but also has practical benefits, including the ability to generate continuous trajectories and to perform inference on previously unseen time stamps. Despite exciting progress in this area, the existing models still face challenges in terms of their representational power and the quality of their variational approximations. We tackle these challenges with continuous latent process flows (CLPF), a principled architecture decoding continuous latent processes into continuous observable processes using a time-dependent normalizing flow driven by a stochastic differential equation. To optimize our model using maximum likelihood, we propose a novel piecewise construction of a variational posterior process and derive the corresponding variational lower bound using trajectory re-weighting. Our ablation studies demonstrate the effectiveness of our contributions in various inference tasks on irregular time grids. Comparisons to state-of-the-art baselines show our model's favourable performance on both synthetic and real-world time-series data.
A Meta-Learned Neuron model for Continual Learning
Nov 03, 2021
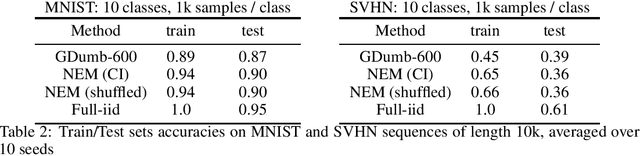
Continual learning is the ability to acquire new knowledge without forgetting the previously learned one, assuming no further access to past training data. Neural network approximators trained with gradient descent are known to fail in this setting as they must learn from a stream of data-points sampled from a stationary distribution to converge. In this work, we replace the standard neuron by a meta-learned neuron model whom inference and update rules are optimized to minimize catastrophic interference. Our approach can memorize dataset-length sequences of training samples, and its learning capabilities generalize to any domain. Unlike previous continual learning methods, our method does not make any assumption about how tasks are constructed, delivered and how they relate to each other: it simply absorbs and retains training samples one by one, whether the stream of input data is time-correlated or not.