 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Time-Stream Framework for Click-Through Rate Prediction by Tracking Interest Evolution
Jan 08, 2020
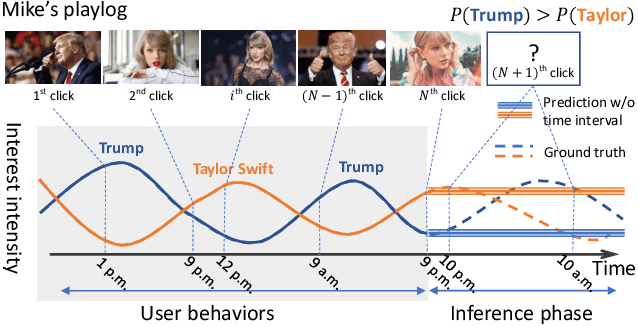
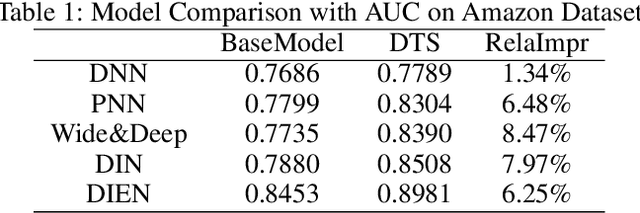
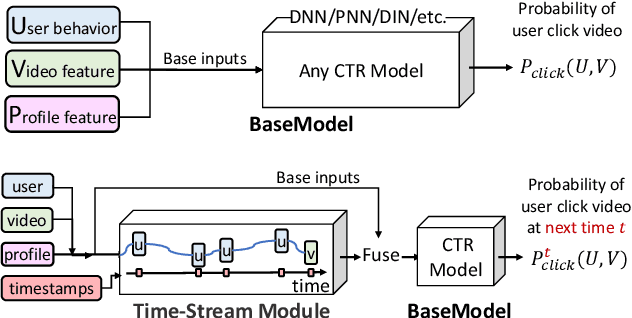
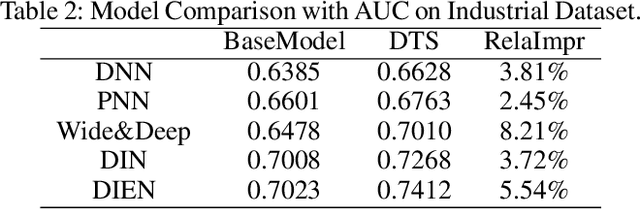
Click-through rate (CTR) prediction is an essential task in industrial applications such as video recommendation. Recently, deep learning models have been proposed to learn the representation of users' overall interests, while ignoring the fact that interests may dynamically change over time. We argue that it is necessary to consider the continuous-time information in CTR models to track user interest trend from rich historical behaviors. In this paper, we propose a novel Deep Time-Stream framework (DTS) which introduces the time information by an ordinary differential equations (ODE). DTS continuously models the evolution of interests using a neural network, and thus is able to tackle the challenge of dynamically representing users' interests based on their historical behaviors. In addition, our framework can be seamlessly applied to any existing deep CTR models by leveraging the additional Time-Stream Module, while no changes are made to the original CTR models. Experiments on public dataset as well as real industry dataset with billions of samples demonstrate the effectiveness of proposed approaches, which achieve superior performance compared with existing methods.
* 8 pages. arXiv admin note: text overlap with arXiv:1809.03672 by other authors
HiRID-ICU-Benchmark -- A Comprehensive Machine Learning Benchmark on High-resolution ICU Data
Nov 18, 2021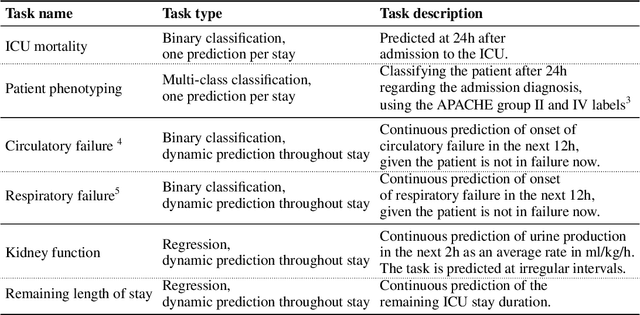
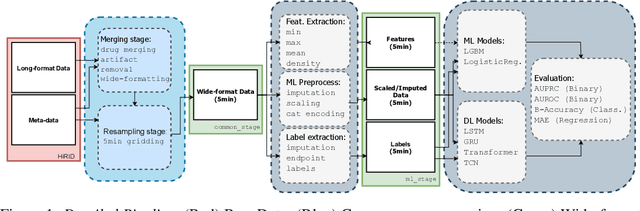
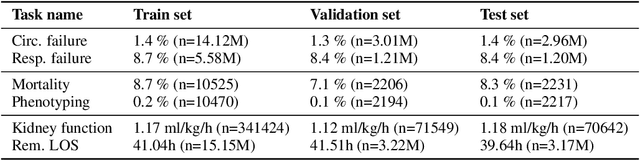
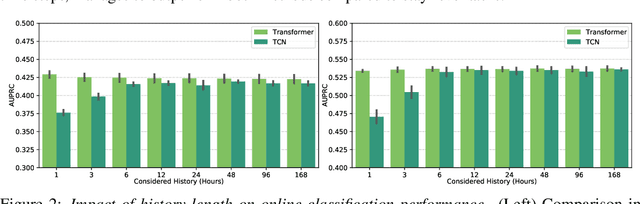
The recent success of machine learning methods applied to time series collected from Intensive Care Units (ICU) exposes the lack of standardized machine learning benchmarks for developing and comparing such methods. While raw datasets, such as MIMIC-IV or eICU, can be freely accessed on Physionet, the choice of tasks and pre-processing is often chosen ad-hoc for each publication, limiting comparability across publications. In this work, we aim to improve this situation by providing a benchmark covering a large spectrum of ICU-related tasks. Using the HiRID dataset, we define multiple clinically relevant tasks developed in collaboration with clinicians. In addition, we provide a reproducible end-to-end pipeline to construct both data and labels. Finally, we provide an in-depth analysis of current state-of-the-art sequence modeling methods, highlighting some limitations of deep learning approaches for this type of data. With this benchmark, we hope to give the research community the possibility of a fair comparison of their work.
A General Optimization Framework for Dynamic Time Warping
May 31, 2019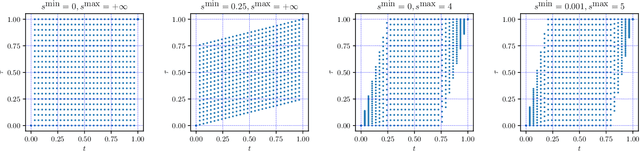
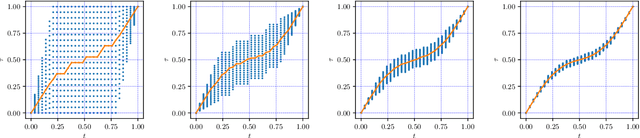
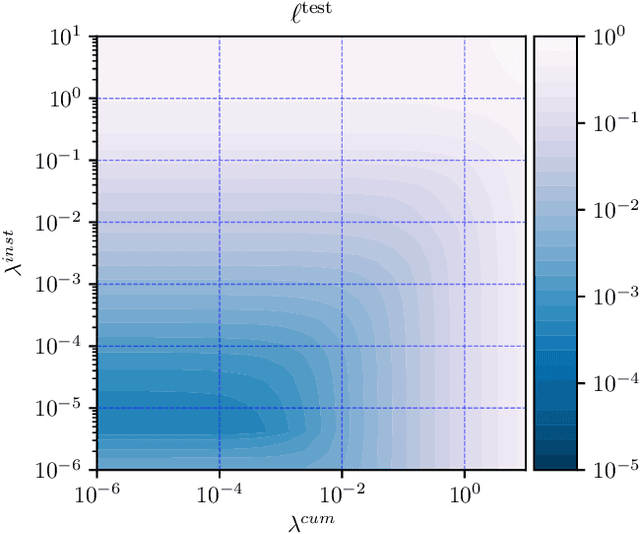
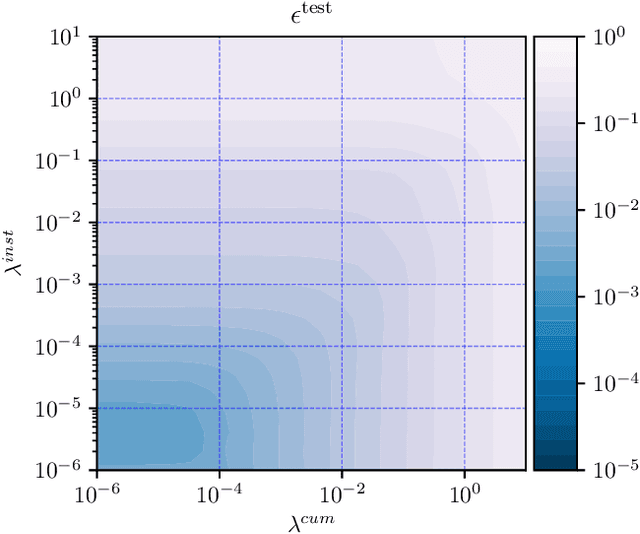
The goal of dynamic time warping is to transform or warp time in order to approximately align two signals together. We pose the choice of warping function as an optimization problem with several terms in the objective. The first term measures the misalignment of the time-warped signals. Two additional regularization terms penalize the cumulative warping and the instantaneous rate of time warping; constraints on the warping can be imposed by assigning the value +inf to the regularization terms. Different choices of the three objective terms yield different time warping functions that trade off signal fit or alignment and properties of the warping function. The optimization problem we formulate is a classical optimal control problem, with initial and terminal constraints, and a state dimension of one. We describe an effective general method that minimizes the objective by discretizing the values of the original and warped time, and using standard dynamic programming to compute the (globally) optimal warping function with the discretized values. Iterated refinement of this scheme yields a high accuracy warping function in just a few iterations. Our method is implemented as an open source Python package GDTW.
Data-Driven Market Segmentation in Hospitality Using Unsupervised Machine Learning
Nov 04, 2021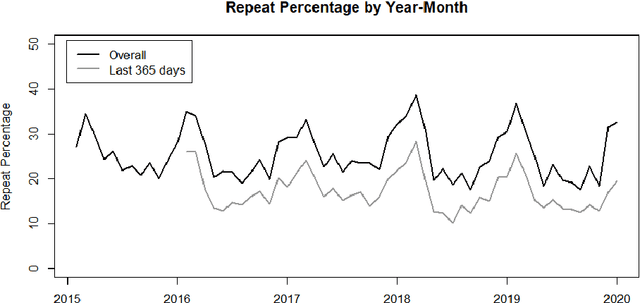
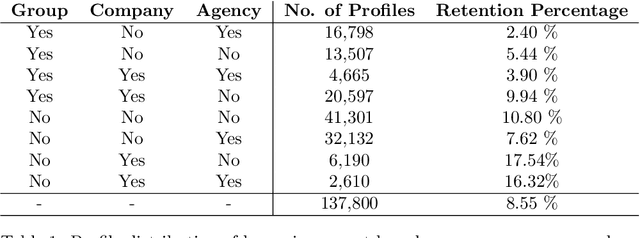
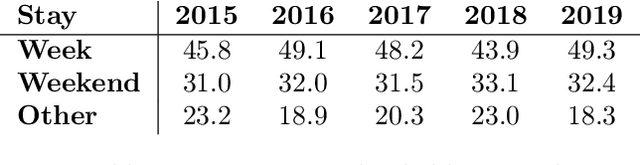
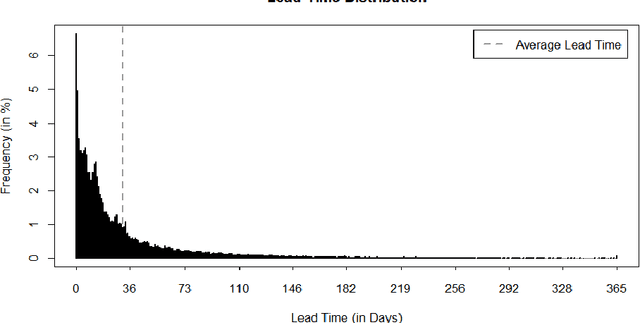
Within hospitality, marketing departments use segmentation to create tailored strategies to ensure personalized marketing. This study provides a data-driven approach by segmenting guest profiles via hierarchical clustering, based on an extensive set of features. The industry requires understandable outcomes that contribute to adaptability for marketing departments to make data-driven decisions and ultimately driving profit. A marketing department specified a business question that guides the unsupervised machine learning algorithm. Features of guests change over time; therefore, there is a probability that guests transition from one segment to another. The purpose of the study is to provide steps in the process from raw data to actionable insights, which serve as a guideline for how hospitality companies can adopt an algorithmic approach.
Nonuniform-to-Uniform Quantization: Towards Accurate Quantization via Generalized Straight-Through Estimation
Nov 29, 2021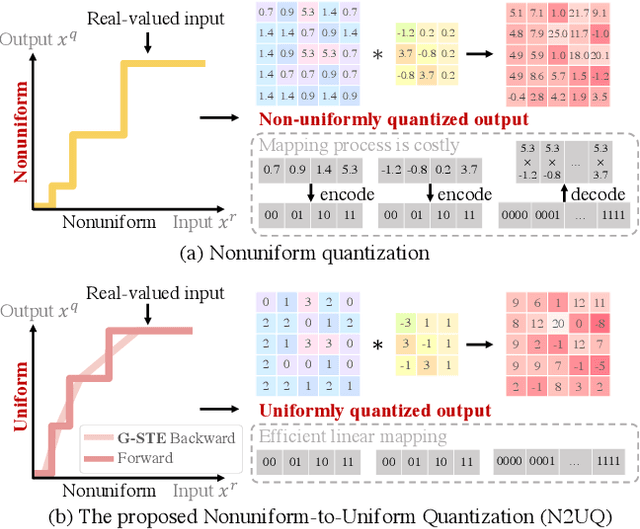
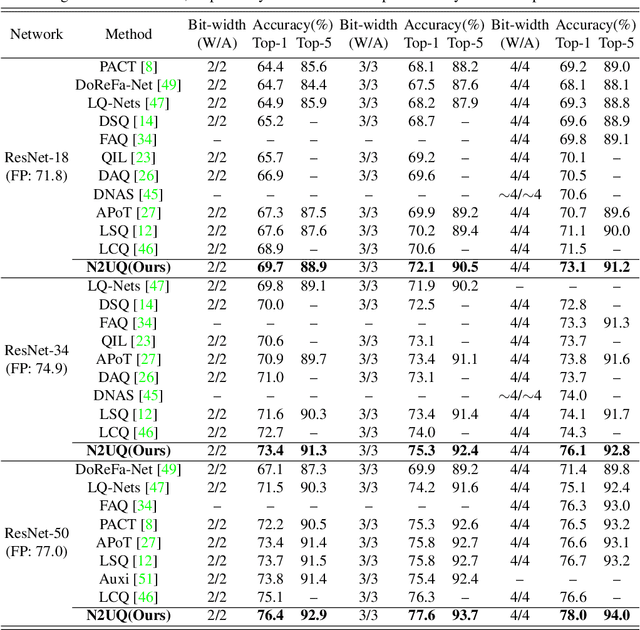
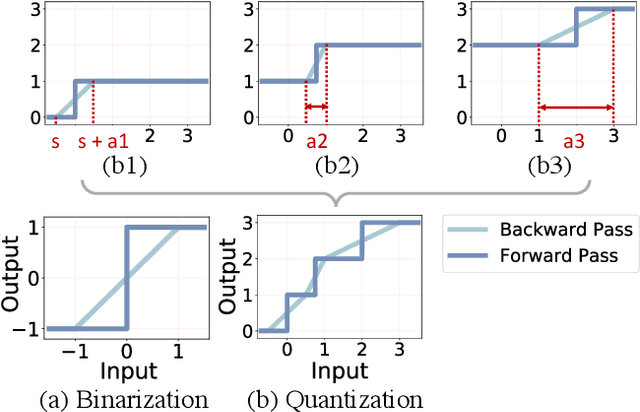

The nonuniform quantization strategy for compressing neural networks usually achieves better performance than its counterpart, i.e., uniform strategy, due to its superior representational capacity. However, many nonuniform quantization methods overlook the complicated projection process in implementing the nonuniformly quantized weights/activations, which incurs non-negligible time and space overhead in hardware deployment. In this study, we propose Nonuniform-to-Uniform Quantization (N2UQ), a method that can maintain the strong representation ability of nonuniform methods while being hardware-friendly and efficient as the uniform quantization for model inference. We achieve this through learning the flexible in-equidistant input thresholds to better fit the underlying distribution while quantizing these real-valued inputs into equidistant output levels. To train the quantized network with learnable input thresholds, we introduce a generalized straight-through estimator (G-STE) for intractable backward derivative calculation w.r.t. threshold parameters. Additionally, we consider entropy preserving regularization to further reduce information loss in weight quantization. Even under this adverse constraint of imposing uniformly quantized weights and activations, our N2UQ outperforms state-of-the-art nonuniform quantization methods by 0.7~1.8% on ImageNet, demonstrating the contribution of N2UQ design. Code will be made publicly available.
Self-supervised Monocular Depth Estimation for All Day Images using Domain Separation
Aug 17, 2021
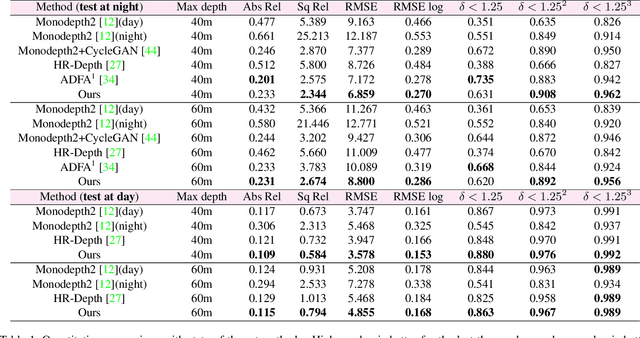
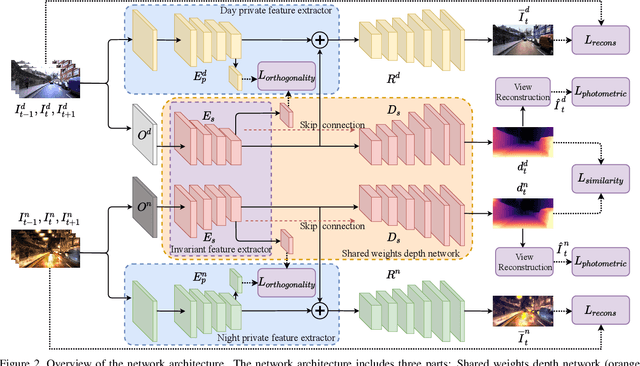
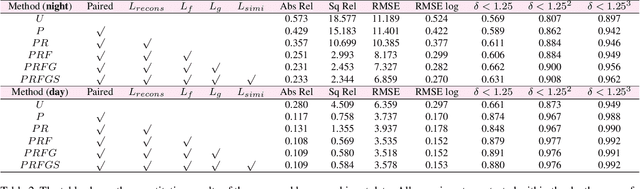
Remarkable results have been achieved by DCNN based self-supervised depth estimation approaches. However, most of these approaches can only handle either day-time or night-time images, while their performance degrades for all-day images due to large domain shift and the variation of illumination between day and night images. To relieve these limitations, we propose a domain-separated network for self-supervised depth estimation of all-day images. Specifically, to relieve the negative influence of disturbing terms (illumination, etc.), we partition the information of day and night image pairs into two complementary sub-spaces: private and invariant domains, where the former contains the unique information (illumination, etc.) of day and night images and the latter contains essential shared information (texture, etc.). Meanwhile, to guarantee that the day and night images contain the same information, the domain-separated network takes the day-time images and corresponding night-time images (generated by GAN) as input, and the private and invariant feature extractors are learned by orthogonality and similarity loss, where the domain gap can be alleviated, thus better depth maps can be expected. Meanwhile, the reconstruction and photometric losses are utilized to estimate complementary information and depth maps effectively. Experimental results demonstrate that our approach achieves state-of-the-art depth estimation results for all-day images on the challenging Oxford RobotCar dataset, proving the superiority of our proposed approach.
Pixel-wise Energy-biased Abstention Learning for Anomaly Segmentation on Complex Urban Driving Scenes
Nov 24, 2021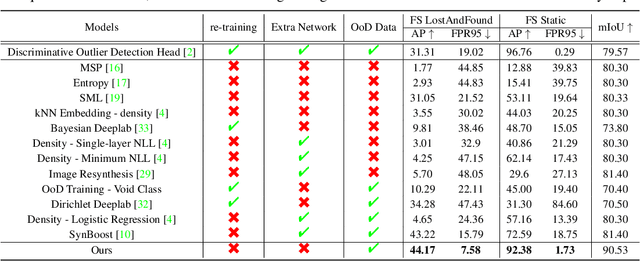
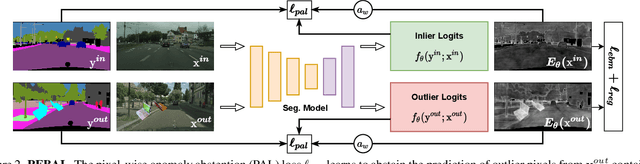
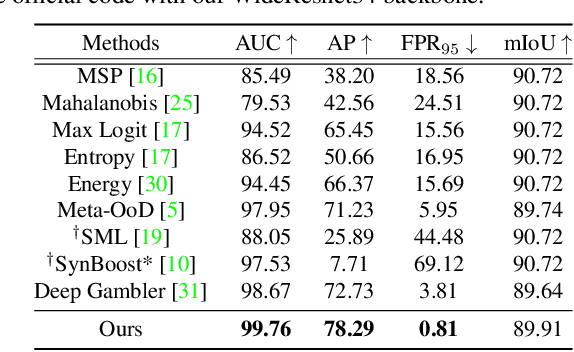
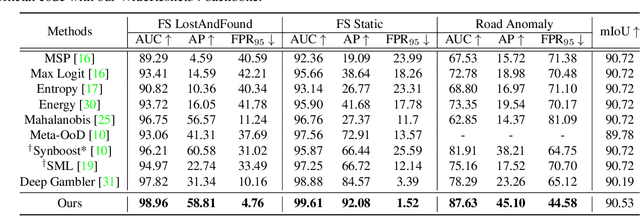
State-of-the-art (SOTA) anomaly segmentation approaches on complex urban driving scenes explore pixel-wise classification uncertainty learned from outlier exposure, or external reconstruction models. However, previous uncertainty approaches that directly associate high uncertainty to anomaly may sometimes lead to incorrect anomaly predictions, and external reconstruction models tend to be too inefficient for real-time self-driving embedded systems. In this paper, we propose a new anomaly segmentation method, named pixel-wise energy-biased abstention learning (PEBAL), that explores pixel-wise abstention learning (AL) with a model that learns an adaptive pixel-level anomaly class, and an energy-based model (EBM) that learns inlier pixel distribution. More specifically, PEBAL is based on a non-trivial joint training of EBM and AL, where EBM is trained to output high-energy for anomaly pixels (from outlier exposure) and AL is trained such that these high-energy pixels receive adaptive low penalty for being included to the anomaly class. We extensively evaluate PEBAL against the SOTA and show that it achieves the best performance across four benchmarks. Code is available at https://github.com/tianyu0207/PEBAL.
Self-Supervised Audio-Visual Representation Learning with Relaxed Cross-Modal Temporal Synchronicity
Nov 14, 2021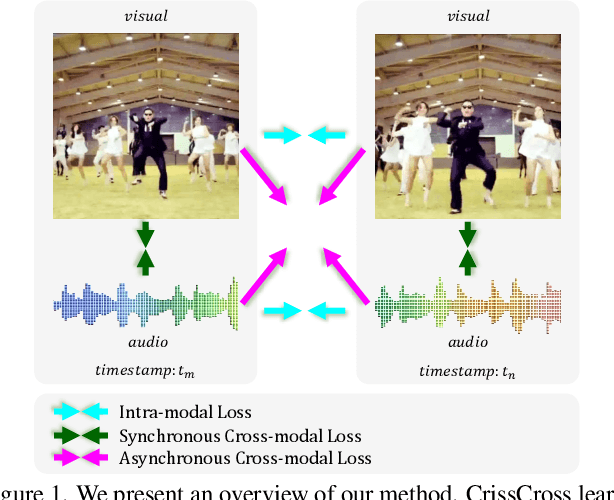
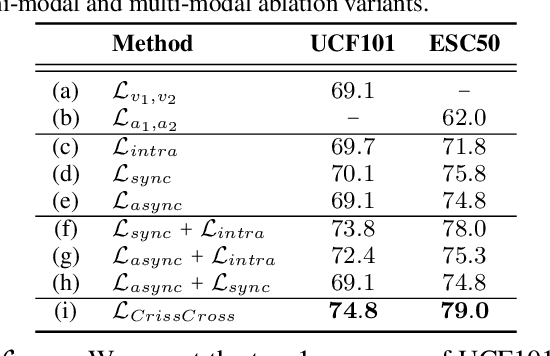
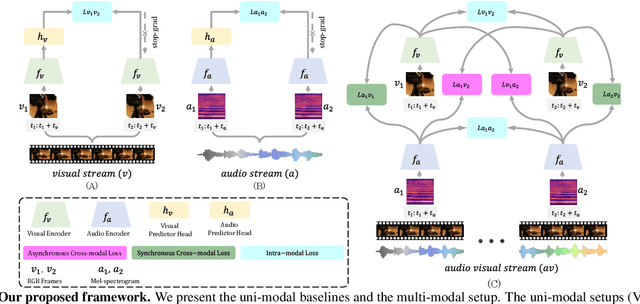
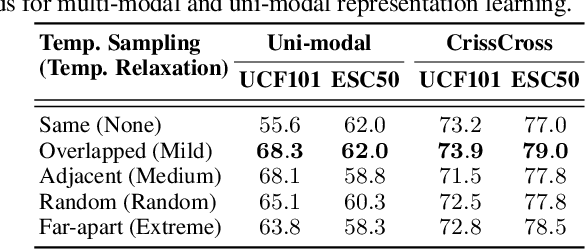
We present CrissCross, a self-supervised framework for learning audio-visual representations. A novel notion is introduced in our framework whereby in addition to learning the intra-modal and standard 'synchronous' cross-modal relations, CrissCross also learns 'asynchronous' cross-modal relationships. We show that by relaxing the temporal synchronicity between the audio and visual modalities, the network learns strong time-invariant representations. Our experiments show that strong augmentations for both audio and visual modalities with relaxation of cross-modal temporal synchronicity optimize performance. To pretrain our proposed framework, we use 3 different datasets with varying sizes, Kinetics-Sound, Kinetics-400, and AudioSet. The learned representations are evaluated on a number of downstream tasks namely action recognition, sound classification, and retrieval. CrissCross shows state-of-the-art performances on action recognition (UCF101 and HMDB51) and sound classification (ESC50). The codes and pretrained models will be made publicly available.
BP-Net: Efficient Deep Learning for Continuous Arterial Blood Pressure Estimation using Photoplethysmogram
Nov 29, 2021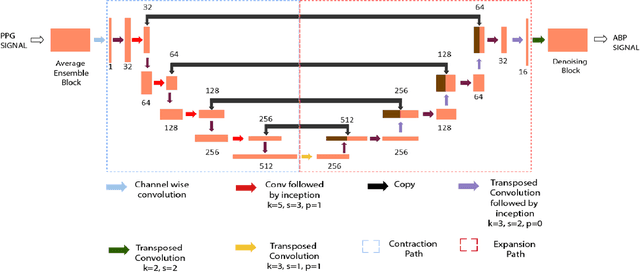
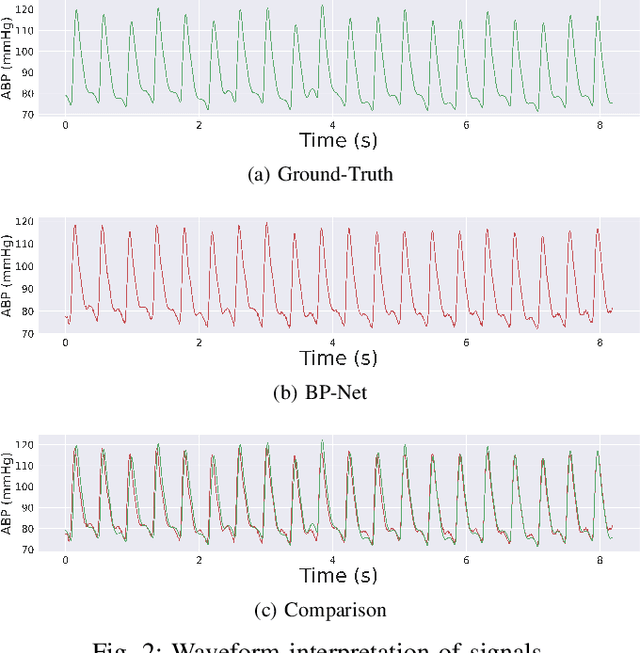
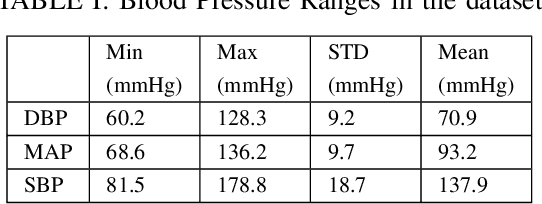
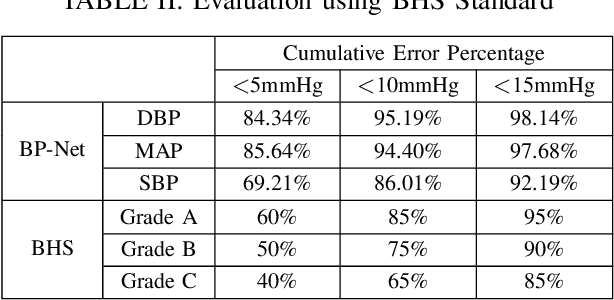
Blood pressure (BP) is one of the most influential bio-markers for cardiovascular diseases and stroke; therefore, it needs to be regularly monitored to diagnose and prevent any advent of medical complications. Current cuffless approaches to continuous BP monitoring, though non-invasive and unobtrusive, involve explicit feature engineering surrounding fingertip Photoplethysmogram (PPG) signals. To circumvent this, we present an end-to-end deep learning solution, BP-Net, that uses PPG waveform to estimate Systolic BP (SBP), Mean Average Pressure (MAP), and Diastolic BP (DBP) through intermediate continuous Arterial BP (ABP) waveform. Under the terms of the British Hypertension Society (BHS) standard, BP-Net achieves Grade A for DBP and MAP estimation and Grade B for SBP estimation. BP-Net also satisfies Advancement of Medical Instrumentation (AAMI) criteria for DBP and MAP estimation and achieves Mean Absolute Error (MAE) of 5.16 mmHg and 2.89 mmHg for SBP and DBP, respectively. Further, we establish the ubiquitous potential of our approach by deploying BP-Net on a Raspberry Pi 4 device and achieve 4.25 ms inference time for our model to translate the PPG waveform to ABP waveform.
Does MAML Only Work via Feature Re-use? A Data Centric Perspective
Dec 24, 2021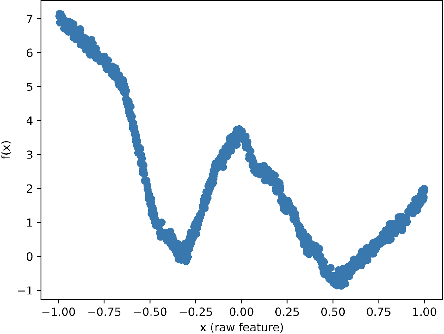
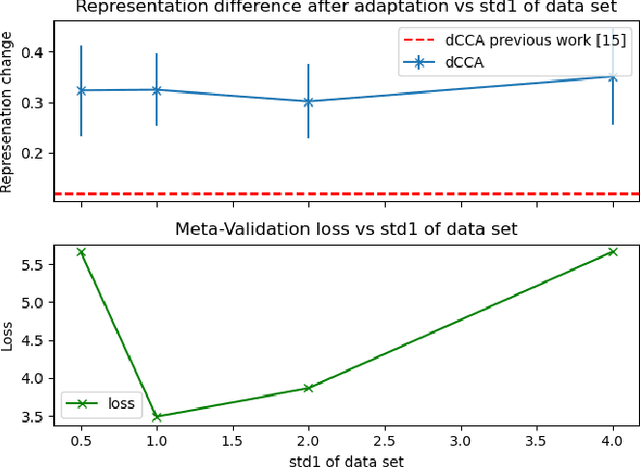
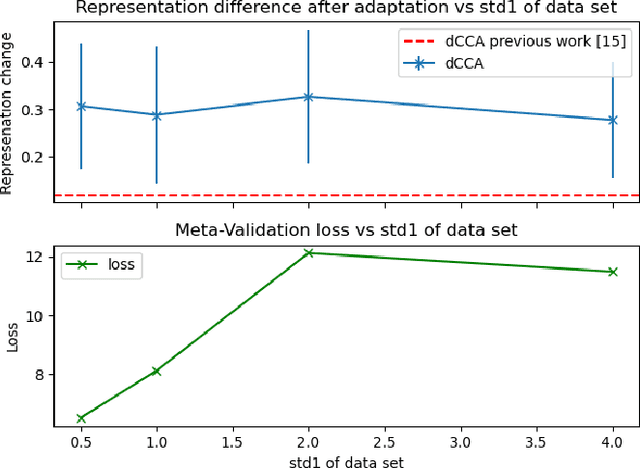
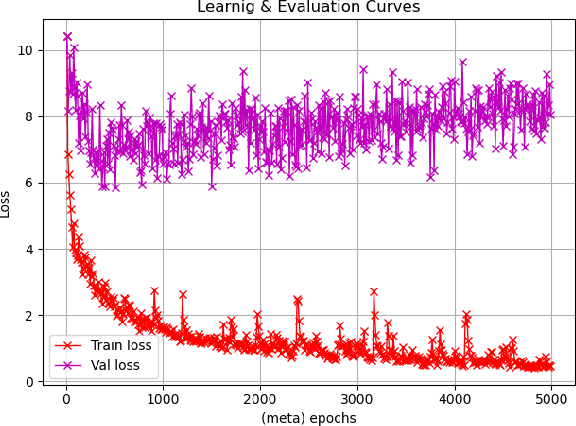
Recent work has suggested that a good embedding is all we need to solve many few-shot learning benchmarks. Furthermore, other work has strongly suggested that Model Agnostic Meta-Learning (MAML) also works via this same method - by learning a good embedding. These observations highlight our lack of understanding of what meta-learning algorithms are doing and when they work. In this work, we provide empirical results that shed some light on how meta-learned MAML representations function. In particular, we identify three interesting properties: 1) In contrast to previous work, we show that it is possible to define a family of synthetic benchmarks that result in a low degree of feature re-use - suggesting that current few-shot learning benchmarks might not have the properties needed for the success of meta-learning algorithms; 2) meta-overfitting occurs when the number of classes (or concepts) are finite, and this issue disappears once the task has an unbounded number of concepts (e.g., online learning); 3) more adaptation at meta-test time with MAML does not necessarily result in a significant representation change or even an improvement in meta-test performance - even when training on our proposed synthetic benchmarks. Finally, we suggest that to understand meta-learning algorithms better, we must go beyond tracking only absolute performance and, in addition, formally quantify the degree of meta-learning and track both metrics together. Reporting results in future work this way will help us identify the sources of meta-overfitting more accurately and help us design more flexible meta-learning algorithms that learn beyond fixed feature re-use. Finally, we conjecture the core challenge of re-thinking meta-learning is in the design of few-shot learning data sets and benchmarks - rather than in the algorithms, as suggested by previous work.