 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Causal Regularization Using Domain Priors
Nov 24, 2021
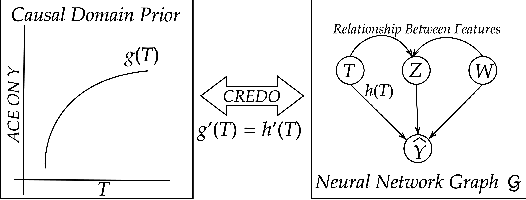
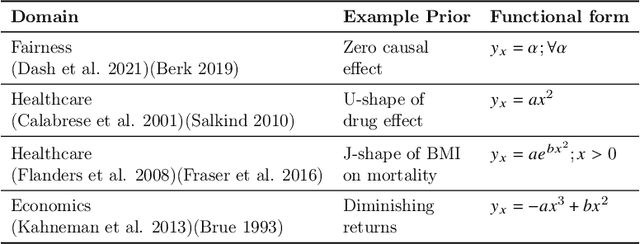
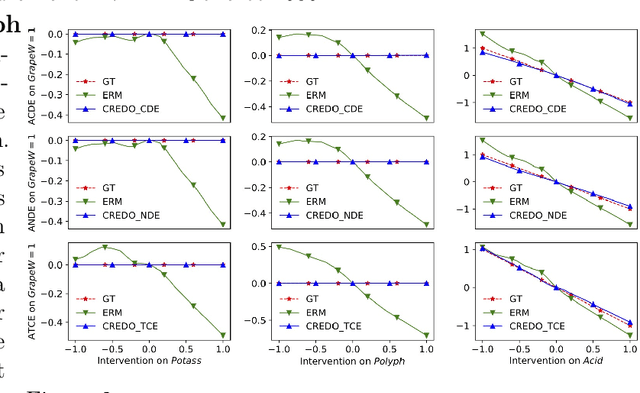
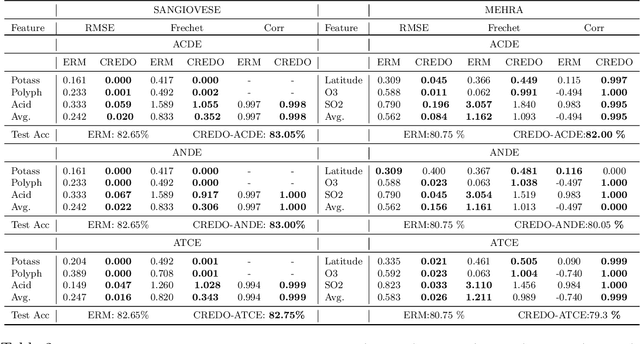
Neural networks leverage both causal and correlation-based relationships in data to learn models that optimize a given performance criterion, such as classification accuracy. This results in learned models that may not necessarily reflect the true causal relationships between input and output. When domain priors of causal relationships are available at the time of training, it is essential that a neural network model maintains these relationships as causal, even as it learns to optimize the performance criterion. We propose a causal regularization method that can incorporate such causal domain priors into the network and which supports both direct and total causal effects. We show that this approach can generalize to various kinds of specifications of causal priors, including monotonicity of causal effect of a given input feature or removing a certain influence for purposes of fairness. Our experiments on eleven benchmark datasets show the usefulness of this approach in regularizing a learned neural network model to maintain desired causal effects. On most datasets, domain-prior consistent models can be obtained without compromising on accuracy.
One More Step Towards Reality: Cooperative Bandits with Imperfect Communication
Nov 24, 2021


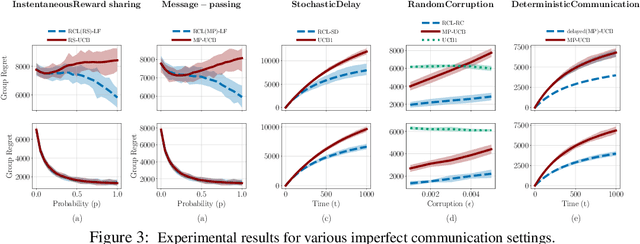
The cooperative bandit problem is increasingly becoming relevant due to its applications in large-scale decision-making. However, most research for this problem focuses exclusively on the setting with perfect communication, whereas in most real-world distributed settings, communication is often over stochastic networks, with arbitrary corruptions and delays. In this paper, we study cooperative bandit learning under three typical real-world communication scenarios, namely, (a) message-passing over stochastic time-varying networks, (b) instantaneous reward-sharing over a network with random delays, and (c) message-passing with adversarially corrupted rewards, including byzantine communication. For each of these environments, we propose decentralized algorithms that achieve competitive performance, along with near-optimal guarantees on the incurred group regret as well. Furthermore, in the setting with perfect communication, we present an improved delayed-update algorithm that outperforms the existing state-of-the-art on various network topologies. Finally, we present tight network-dependent minimax lower bounds on the group regret. Our proposed algorithms are straightforward to implement and obtain competitive empirical performance.
Online Learning for Receding Horizon Control with Provable Regret Guarantees
Nov 30, 2021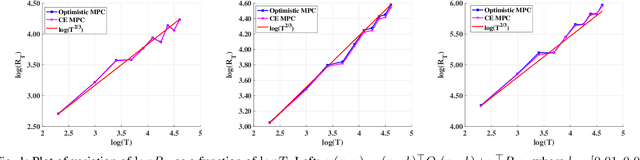
We address the problem of learning to control an unknown linear dynamical system with time varying cost functions through the framework of online Receding Horizon Control (RHC). We consider the setting where the control algorithm does not know the true system model and has only access to a fixed-length (that does not grow with the control horizon) preview of the future cost functions. We characterize the performance of an algorithm using the metric of dynamic regret, which is defined as the difference between the cumulative cost incurred by the algorithm and that of the best sequence of actions in hindsight. We propose two different online RHC algorithms to address this problem, namely Certainty Equivalence RHC (CE-RHC) algorithm and Optimistic RHC (O-RHC) algorithm. We show that under the standard stability assumption for the model estimate, the CE-RHC algorithm achieves $\mathcal{O}(T^{2/3})$ dynamic regret. We then extend this result to the setting where the stability assumption hold only for the true system model by proposing the O-RHC algorithm. We show that O-RHC algorithm achieves $\mathcal{O}(T^{2/3})$ dynamic regret but with some additional computation.
On-device neural speech synthesis
Sep 17, 2021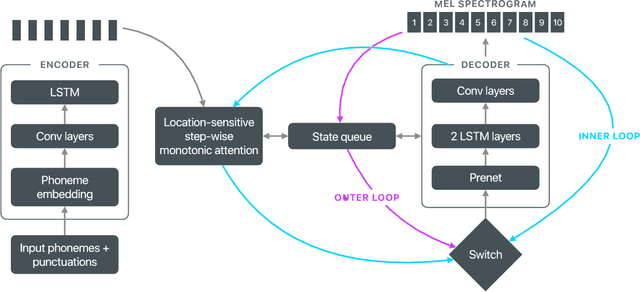

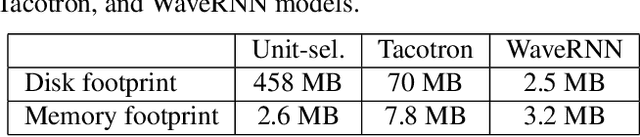
Recent advances in text-to-speech (TTS) synthesis, such as Tacotron and WaveRNN, have made it possible to construct a fully neural network based TTS system, by coupling the two components together. Such a system is conceptually simple as it only takes grapheme or phoneme input, uses Mel-spectrogram as an intermediate feature, and directly generates speech samples. The system achieves quality equal or close to natural speech. However, the high computational cost of the system and issues with robustness have limited their usage in real-world speech synthesis applications and products. In this paper, we present key modeling improvements and optimization strategies that enable deploying these models, not only on GPU servers, but also on mobile devices. The proposed system can generate high-quality 24 kHz speech at 5x faster than real time on server and 3x faster than real time on mobile devices.
Improving Multi-Domain Generalization through Domain Re-labeling
Dec 17, 2021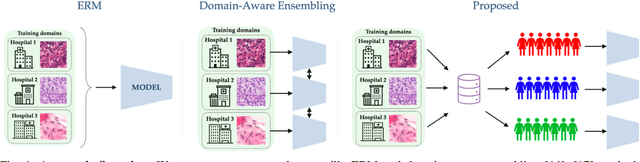
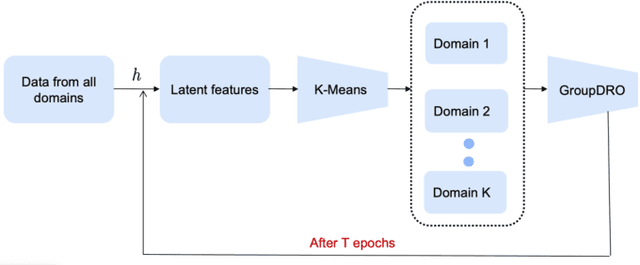
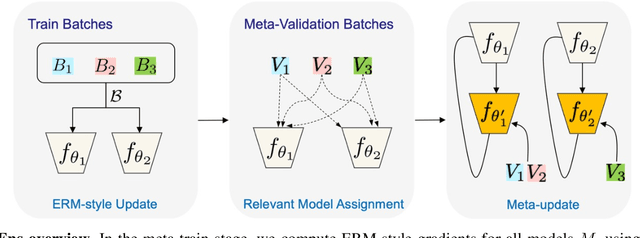
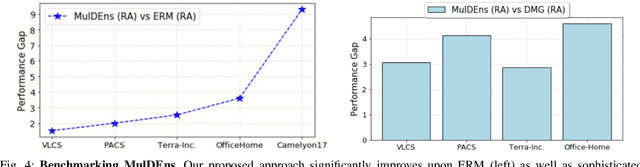
Domain generalization (DG) methods aim to develop models that generalize to settings where the test distribution is different from the training data. In this paper, we focus on the challenging problem of multi-source zero-shot DG, where labeled training data from multiple source domains is available but with no access to data from the target domain. Though this problem has become an important topic of research, surprisingly, the simple solution of pooling all source data together and training a single classifier is highly competitive on standard benchmarks. More importantly, even sophisticated approaches that explicitly optimize for invariance across different domains do not necessarily provide non-trivial gains over ERM. In this paper, for the first time, we study the important link between pre-specified domain labels and the generalization performance. Using a motivating case-study and a new variant of a distributional robust optimization algorithm, GroupDRO++, we first demonstrate how inferring custom domain groups can lead to consistent improvements over the original domain labels that come with the dataset. Subsequently, we introduce a general approach for multi-domain generalization, MulDEns, that uses an ERM-based deep ensembling backbone and performs implicit domain re-labeling through a meta-optimization algorithm. Using empirical studies on multiple standard benchmarks, we show that MulDEns does not require tailoring the augmentation strategy or the training process specific to a dataset, consistently outperforms ERM by significant margins, and produces state-of-the-art generalization performance, even when compared to existing methods that exploit the domain labels.
Statistical learning method for predicting density-matrix based electron dynamics
Jul 31, 2021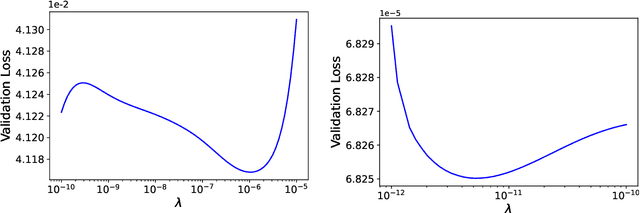

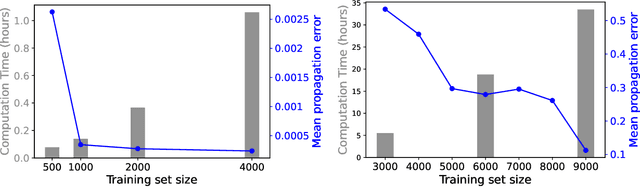
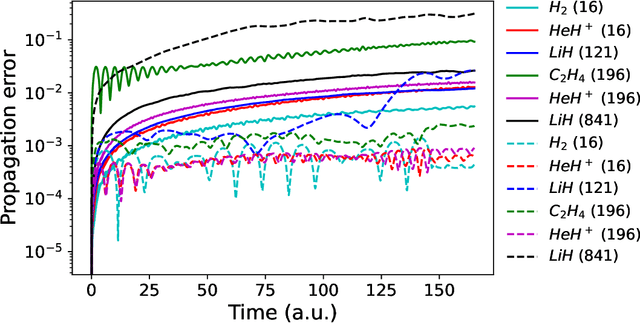
We develop a statistical method to learn a molecular Hamiltonian matrix from a time-series of electron density matrices. We extend our previous method to larger molecular systems by incorporating physical properties to reduce dimensionality, while also exploiting regularization techniques like ridge regression for addressing multicollinearity. With the learned Hamiltonian we can solve the Time-Dependent Hartree-Fock (TDHF) equation to propagate the electron density in time, and predict its dynamics for field-free and field-on scenarios. We observe close quantitative agreement between the predicted dynamics and ground truth for both field-off trajectories similar to the training data, and field-on trajectories outside of the training data.
Whistleblower protection in the digital age -- why 'anonymous' is not enough. Towards an interdisciplinary view of ethical dilemmas
Nov 11, 2021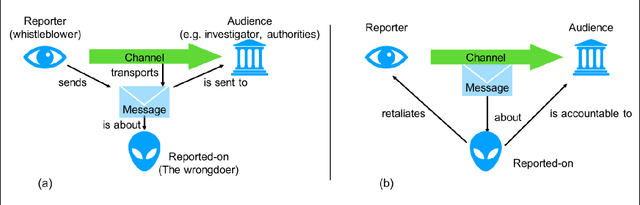
When technology enters applications and processes with a long tradition of controversial societal debate, multi-faceted new ethical and legal questions arise. This paper focusses on the process of whistleblowing, an activity with large impacts on democracy and business. Computer science can, for the first time in history, provide for truly anonymous communication. We investigate this in relation to the values and rights of accountability, fairness and data protection, focusing on opportunities and limitations of the anonymity that can be provided computationally; possible consequences of outsourcing whistleblowing support; and challenges for the interpretation and use of some relevant laws. We conclude that to address these questions, whistleblowing and anonymous whistleblowing must rest on three pillars, forming a 'triangle of whistleblowing protection and incentivisation' that combines anonymity in a formal and technical sense; whistleblower protection through laws; and organisational and political error culture.
Variability-Aware Training and Self-Tuning of Highly Quantized DNNs for Analog PIM
Nov 11, 2021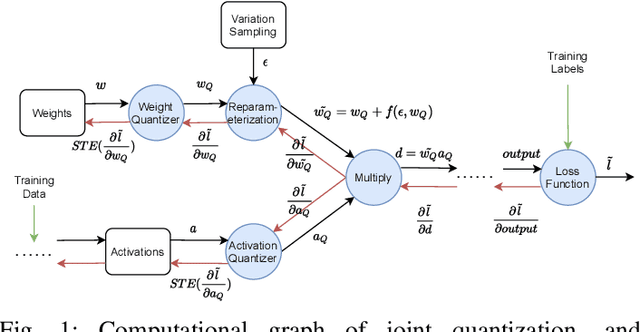
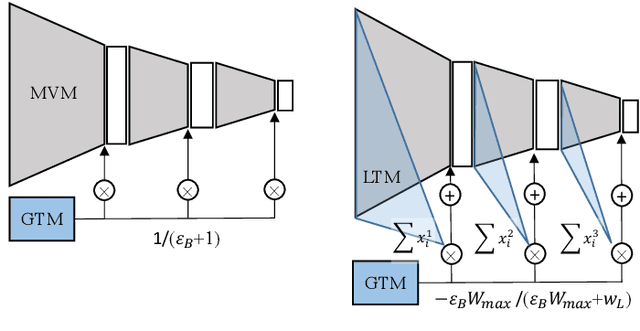
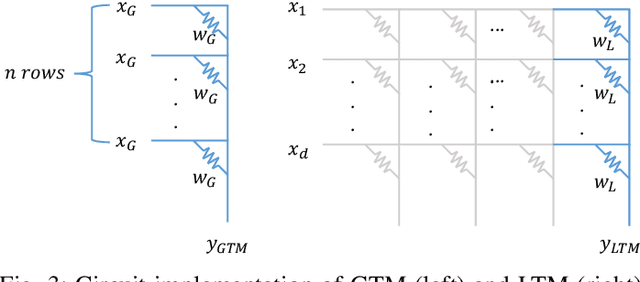
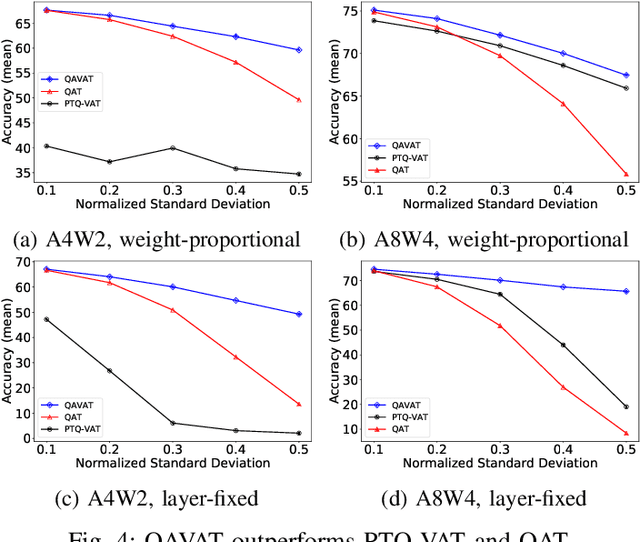
DNNs deployed on analog processing in memory (PIM) architectures are subject to fabrication-time variability. We developed a new joint variability- and quantization-aware DNN training algorithm for highly quantized analog PIM-based models that is significantly more effective than prior work. It outperforms variability-oblivious and post-training quantized models on multiple computer vision datasets/models. For low-bitwidth models and high variation, the gain in accuracy is up to 35.7% for ResNet-18 over the best alternative. We demonstrate that, under a realistic pattern of within- and between-chip components of variability, training alone is unable to prevent large DNN accuracy loss (of up to 54% on CIFAR-100/ResNet-18). We introduce a self-tuning DNN architecture that dynamically adjusts layer-wise activations during inference and is effective in reducing accuracy loss to below 10%.
Fault-Tolerant Perception for Automated Driving A Lightweight Monitoring Approach
Nov 24, 2021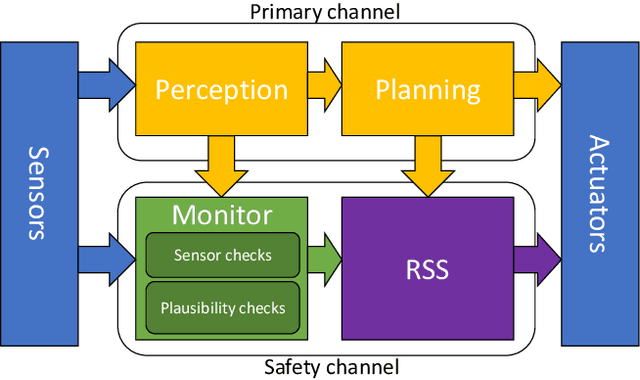
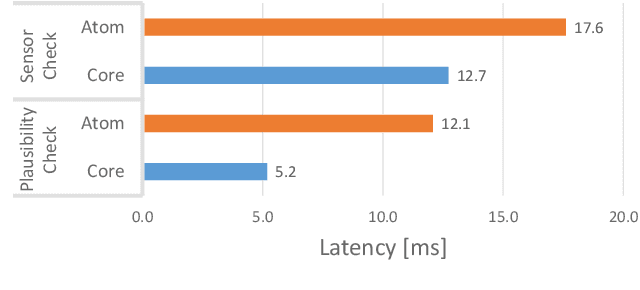
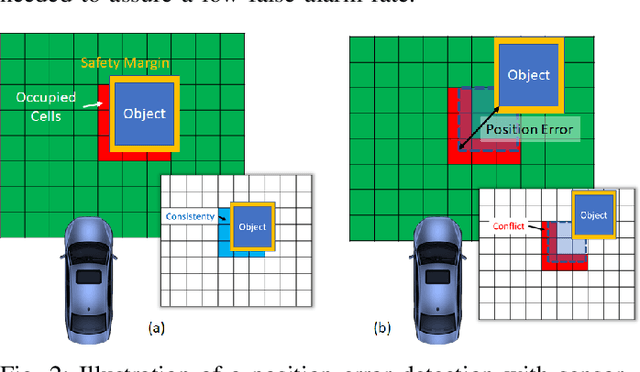
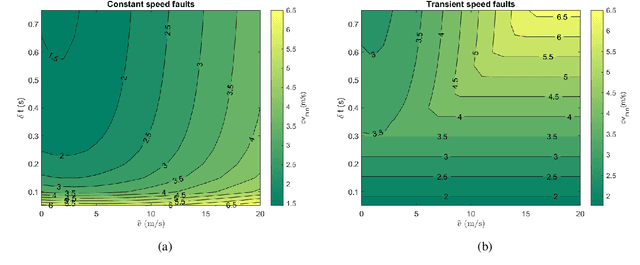
While the most visible part of the safety verification process of automated vehicles concerns the planning and control system, it is often overlooked that safety of the latter crucially depends on the fault-tolerance of the preceding environment perception. Modern perception systems feature complex and often machine-learning-based components with various failure modes that can jeopardize the overall safety. At the same time, a verification by for example redundant execution is not always feasible due to resource constraints. In this paper, we address the need for feasible and efficient perception monitors and propose a lightweight approach that helps to protect the integrity of the perception system while keeping the additional compute overhead minimal. In contrast to existing solutions, the monitor is realized by a well-balanced combination of sensor checks -- here using LiDAR information -- and plausibility checks on the object motion history. It is designed to detect relevant errors in the distance and velocity of objects in the environment of the automated vehicle. In conjunction with an appropriate planning system, such a monitor can help to make safe automated driving feasible.
Hierarchical Object-to-Zone Graph for Object Navigation
Sep 09, 2021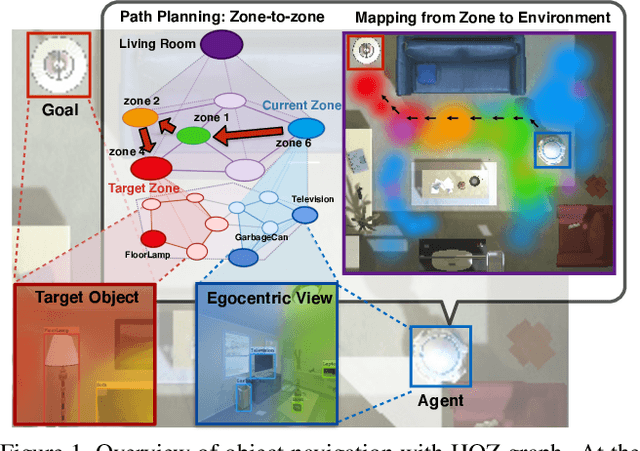
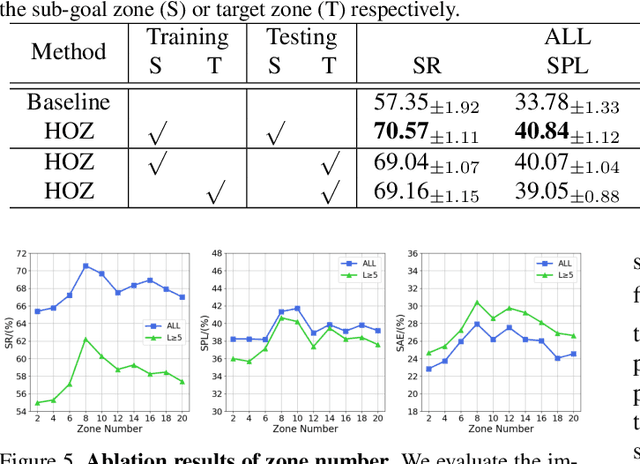
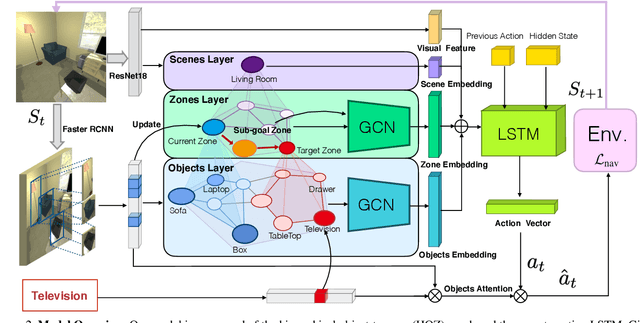
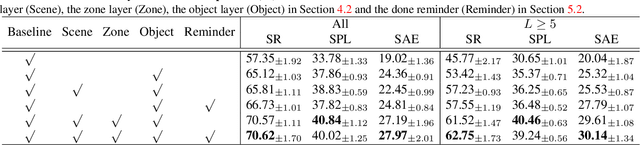
The goal of object navigation is to reach the expected objects according to visual information in the unseen environments. Previous works usually implement deep models to train an agent to predict actions in real-time. However, in the unseen environment, when the target object is not in egocentric view, the agent may not be able to make wise decisions due to the lack of guidance. In this paper, we propose a hierarchical object-to-zone (HOZ) graph to guide the agent in a coarse-to-fine manner, and an online-learning mechanism is also proposed to update HOZ according to the real-time observation in new environments. In particular, the HOZ graph is composed of scene nodes, zone nodes and object nodes. With the pre-learned HOZ graph, the real-time observation and the target goal, the agent can constantly plan an optimal path from zone to zone. In the estimated path, the next potential zone is regarded as sub-goal, which is also fed into the deep reinforcement learning model for action prediction. Our methods are evaluated on the AI2-Thor simulator. In addition to widely used evaluation metrics SR and SPL, we also propose a new evaluation metric of SAE that focuses on the effective action rate. Experimental results demonstrate the effectiveness and efficiency of our proposed method.