 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
In-Bed Human Pose Estimation from Unseen and Privacy-Preserving Image Domains
Nov 30, 2021
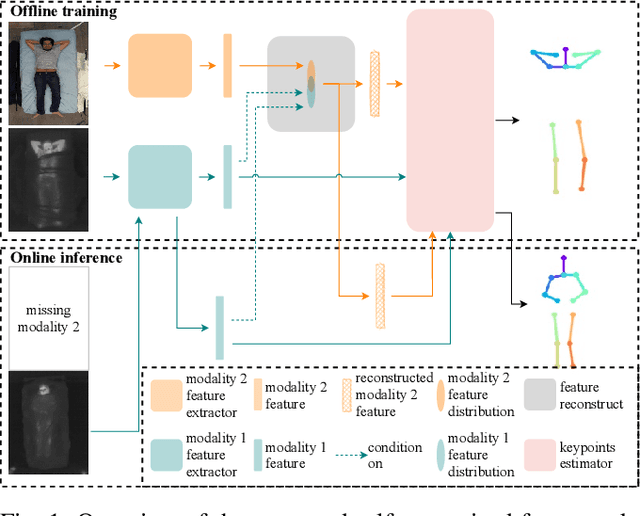
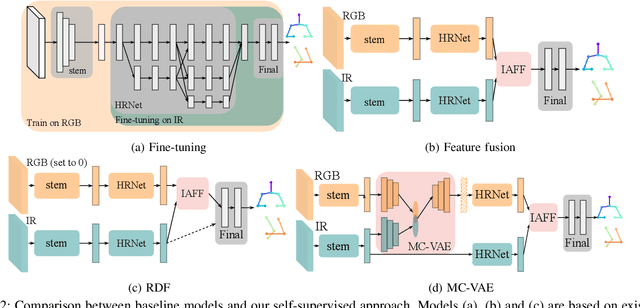
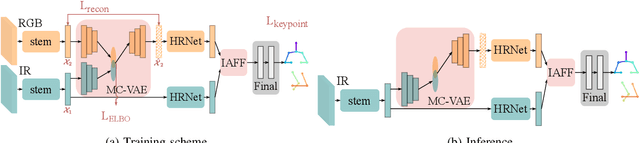
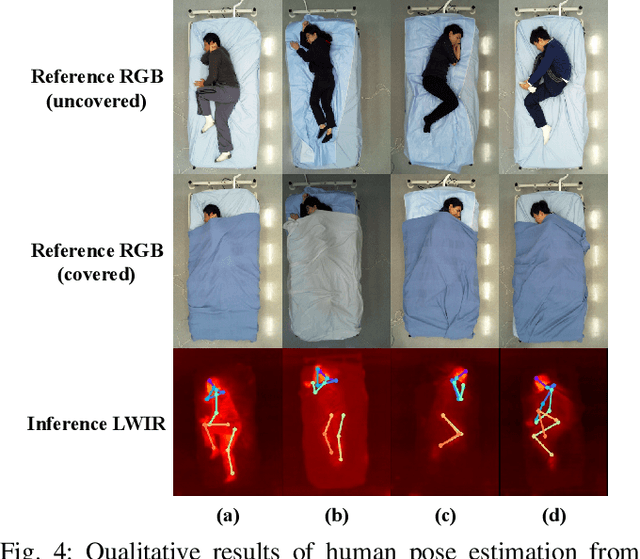
Medical applications have benefited from the rapid advancement in computer vision. For patient monitoring in particular, in-bed human posture estimation provides important health-related metrics with potential value in medical condition assessments. Despite great progress in this domain, it remains a challenging task due to substantial ambiguity during occlusions, and the lack of large corpora of manually labeled data for model training, particularly with domains such as thermal infrared imaging which are privacy-preserving, and thus of great interest. Motivated by the effectiveness of self-supervised methods in learning features directly from data, we propose a multi-modal conditional variational autoencoder (MC-VAE) capable of reconstructing features from missing modalities seen during training. This approach is used with HRNet to enable single modality inference for in-bed pose estimation. Through extensive evaluations, we demonstrate that body positions can be effectively recognized from the available modality, achieving on par results with baseline models that are highly dependent on having access to multiple modes at inference time. The proposed framework supports future research towards self-supervised learning that generates a robust model from a single source, and expects it to generalize over many unknown distributions in clinical environments.
Enhancing Keyphrase Extraction from Academic Articles with their Reference Information
Nov 30, 2021
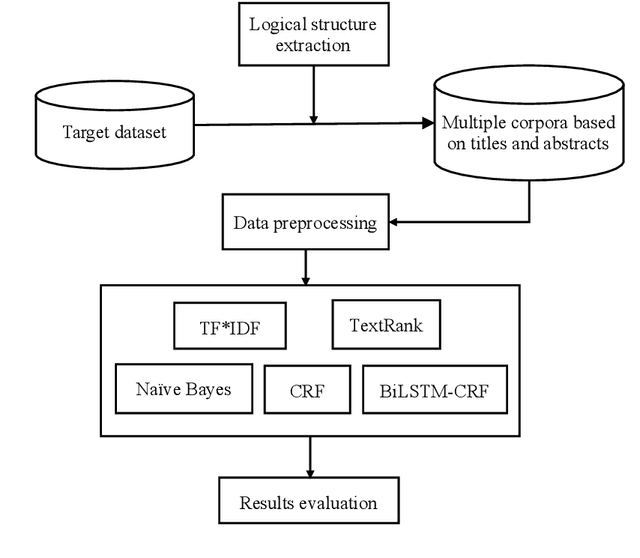
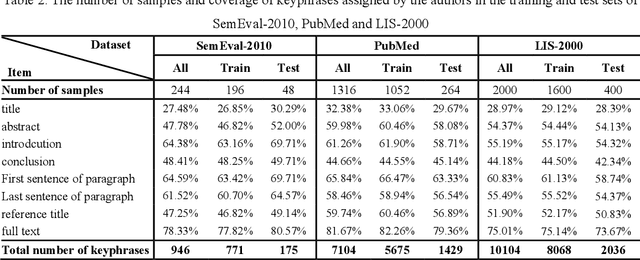
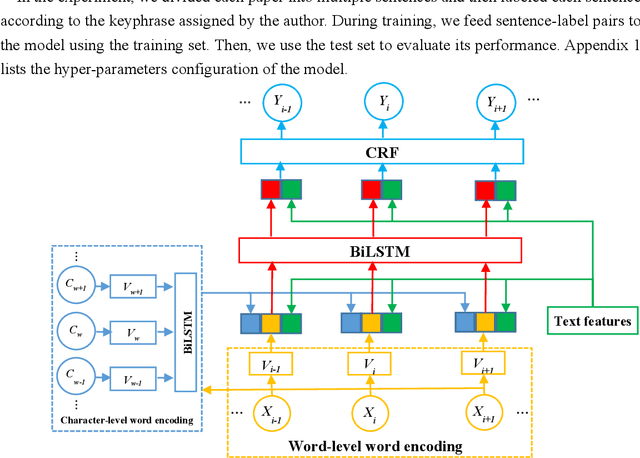
With the development of Internet technology, the phenomenon of information overload is becoming more and more obvious. It takes a lot of time for users to obtain the information they need. However, keyphrases that summarize document information highly are helpful for users to quickly obtain and understand documents. For academic resources, most existing studies extract keyphrases through the title and abstract of papers. We find that title information in references also contains author-assigned keyphrases. Therefore, this article uses reference information and applies two typical methods of unsupervised extraction methods (TF*IDF and TextRank), two representative traditional supervised learning algorithms (Na\"ive Bayes and Conditional Random Field) and a supervised deep learning model (BiLSTM-CRF), to analyze the specific performance of reference information on keyphrase extraction. It is expected to improve the quality of keyphrase recognition from the perspective of expanding the source text. The experimental results show that reference information can increase precision, recall, and F1 of automatic keyphrase extraction to a certain extent. This indicates the usefulness of reference information on keyphrase extraction of academic papers and provides a new idea for the following research on automatic keyphrase extraction.
Dynamic Neural Network Architectural and Topological Adaptation and Related Methods -- A Survey
Jul 28, 2021
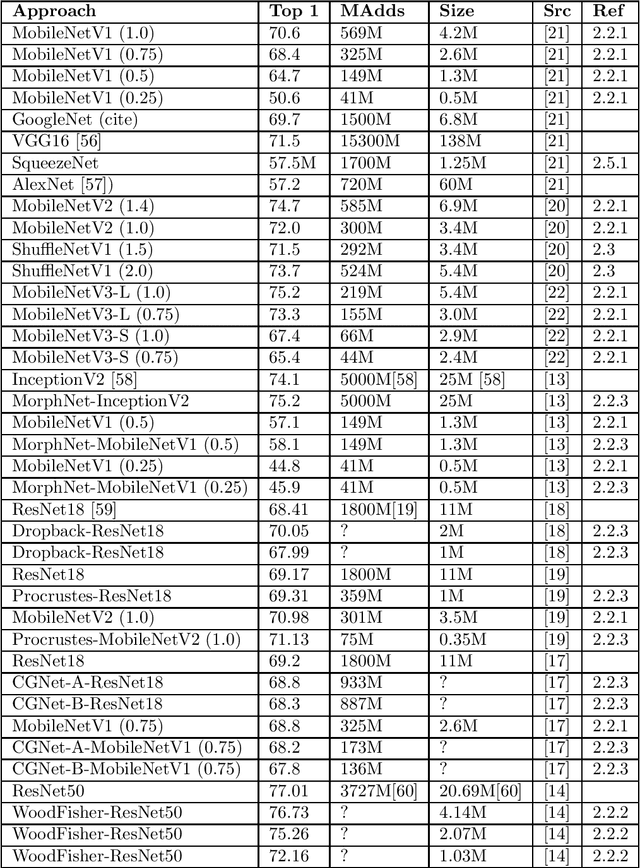
Training and inference in deep neural networks (DNNs) has, due to a steady increase in architectural complexity and data set size, lead to the development of strategies for reducing time and space requirements of DNN training and inference, which is of particular importance in scenarios where training takes place in resource constrained computation environments or inference is part of a time critical application. In this survey, we aim to provide a general overview and categorization of state-of-the-art (SOTA) of techniques to reduced DNN training and inference time and space complexities with a particular focus on architectural adaptions.
Audio-Visual Scene-Aware Dialog and Reasoning using Audio-Visual Transformers with Joint Student-Teacher Learning
Oct 13, 2021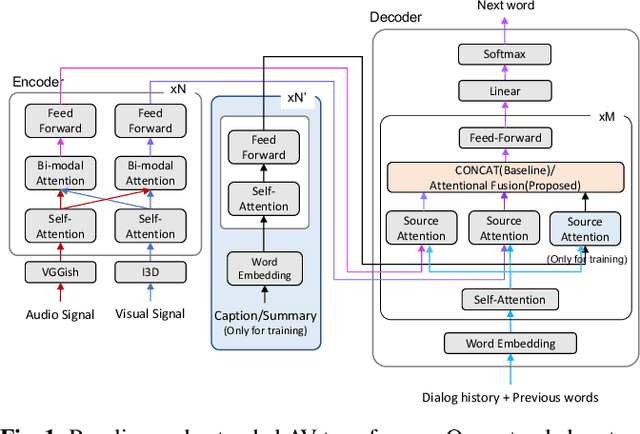
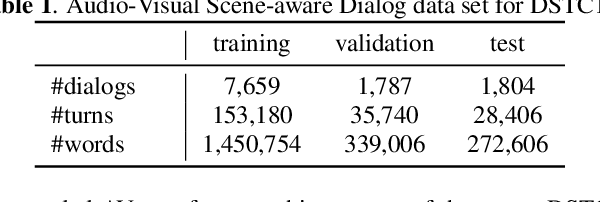
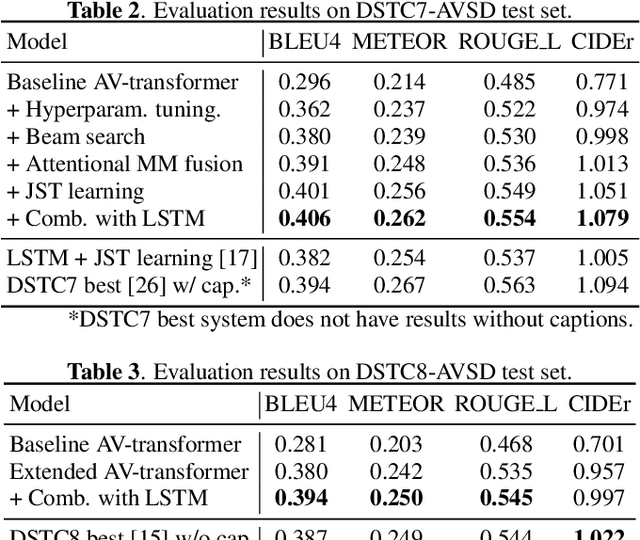
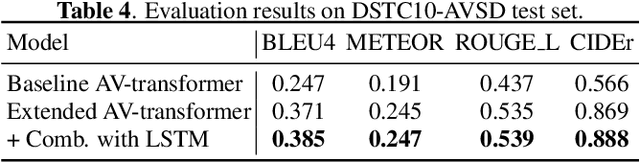
In previous work, we have proposed the Audio-Visual Scene-Aware Dialog (AVSD) task, collected an AVSD dataset, developed AVSD technologies, and hosted an AVSD challenge track at both the 7th and 8th Dialog System Technology Challenges (DSTC7, DSTC8). In these challenges, the best-performing systems relied heavily on human-generated descriptions of the video content, which were available in the datasets but would be unavailable in real-world applications. To promote further advancements for real-world applications, we proposed a third AVSD challenge, at DSTC10, with two modifications: 1) the human-created description is unavailable at inference time, and 2) systems must demonstrate temporal reasoning by finding evidence from the video to support each answer. This paper introduces the new task that includes temporal reasoning and our new extension of the AVSD dataset for DSTC10, for which we collected human-generated temporal reasoning data. We also introduce a baseline system built using an AV-transformer, which we released along with the new dataset. Finally, this paper introduces a new system that extends our baseline system with attentional multimodal fusion, joint student-teacher learning (JSTL), and model combination techniques, achieving state-of-the-art performances on the AVSD datasets for DSTC7, DSTC8, and DSTC10. We also propose two temporal reasoning methods for AVSD: one attention-based, and one based on a time-domain region proposal network.
LiveView: Dynamic Target-Centered MPI for View Synthesis
Jul 11, 2021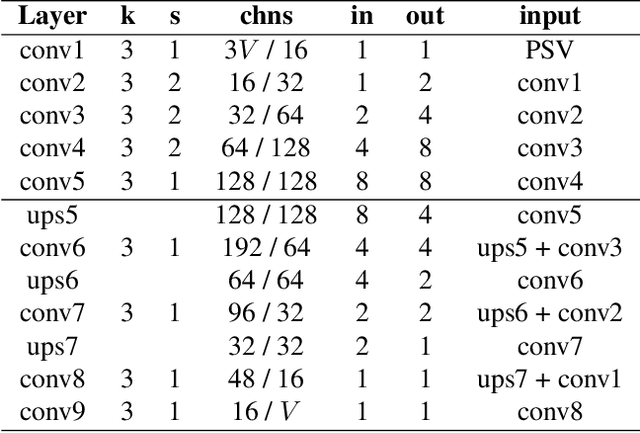
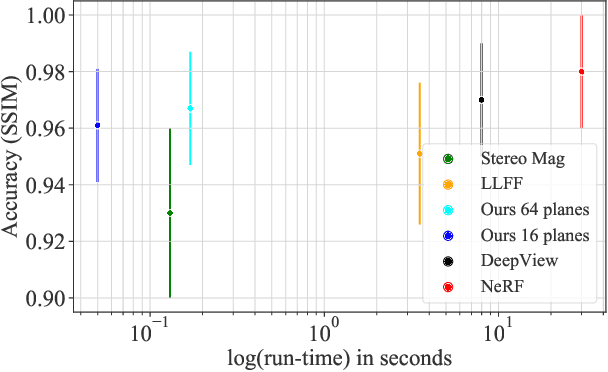
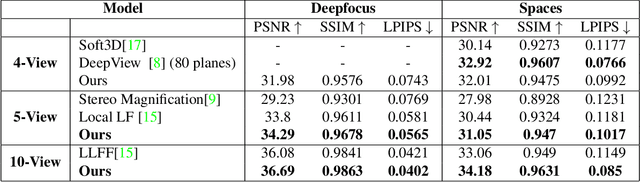
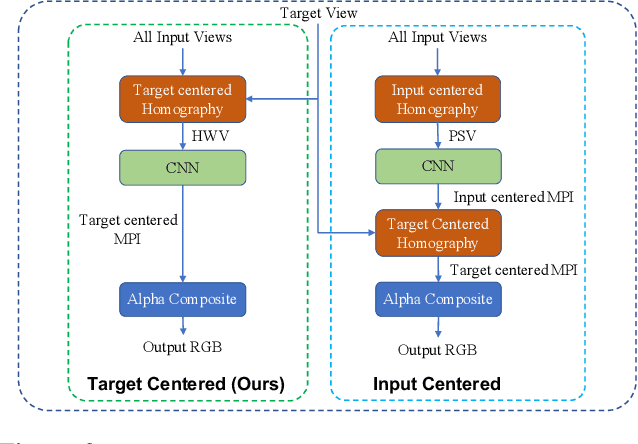
Existing Multi-Plane Image (MPI) based view-synthesis methods generate an MPI aligned with the input view using a fixed number of planes in one forward pass. These methods produce fast, high-quality rendering of novel views, but rely on slow and computationally expensive MPI generation methods unsuitable for real-time applications. In addition, most MPI techniques use fixed depth/disparity planes which cannot be modified once the training is complete, hence offering very little flexibility at run-time. We propose LiveView - a novel MPI generation and rendering technique that produces high-quality view synthesis in real-time. Our method can also offer the flexibility to select scene-dependent MPI planes (number of planes and spacing between them) at run-time. LiveView first warps input images to target view (target-centered) and then learns to generate a target view centered MPI, one depth plane at a time (dynamically). The method generates high-quality renderings, while also enabling fast MPI generation and novel view synthesis. As a result, LiveView enables real-time view synthesis applications where an MPI needs to be updated frequently based on a video stream of input views. We demonstrate that LiveView improves the quality of view synthesis while being 70 times faster at run-time compared to state-of-the-art MPI-based methods.
Context-aware Health Event Prediction via Transition Functions on Dynamic Disease Graphs
Dec 09, 2021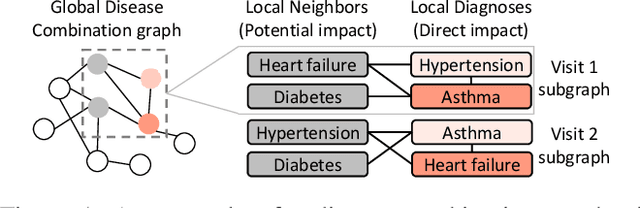

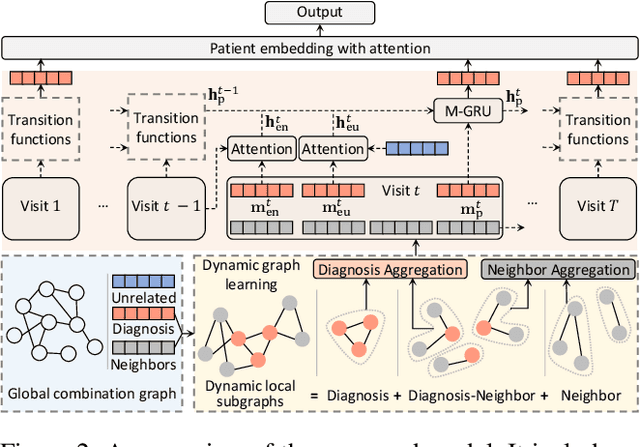
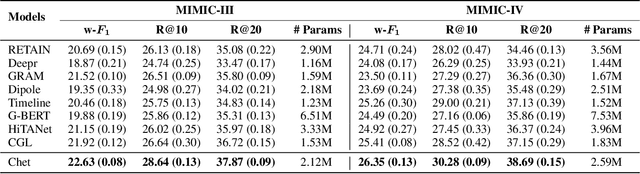
With the wide application of electronic health records (EHR) in healthcare facilities, health event prediction with deep learning has gained more and more attention. A common feature of EHR data used for deep-learning-based predictions is historical diagnoses. Existing work mainly regards a diagnosis as an independent disease and does not consider clinical relations among diseases in a visit. Many machine learning approaches assume disease representations are static in different visits of a patient. However, in real practice, multiple diseases that are frequently diagnosed at the same time reflect hidden patterns that are conducive to prognosis. Moreover, the development of a disease is not static since some diseases can emerge or disappear and show various symptoms in different visits of a patient. To effectively utilize this combinational disease information and explore the dynamics of diseases, we propose a novel context-aware learning framework using transition functions on dynamic disease graphs. Specifically, we construct a global disease co-occurrence graph with multiple node properties for disease combinations. We design dynamic subgraphs for each patient's visit to leverage global and local contexts. We further define three diagnosis roles in each visit based on the variation of node properties to model disease transition processes. Experimental results on two real-world EHR datasets show that the proposed model outperforms state of the art in predicting health events.
Contextualized Spatio-Temporal Contrastive Learning with Self-Supervision
Dec 09, 2021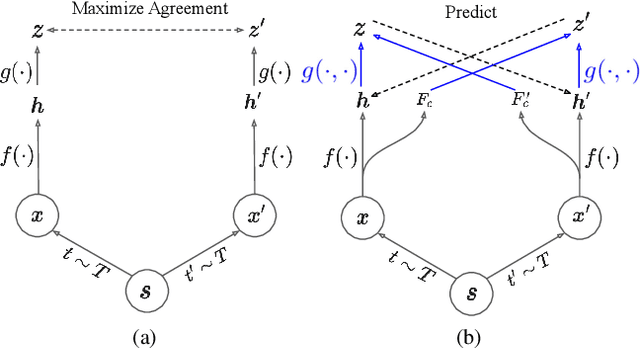
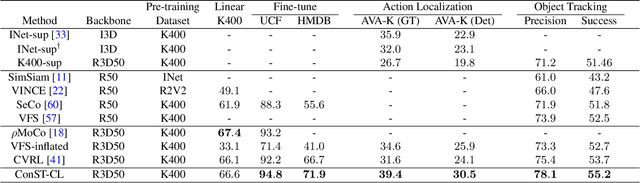
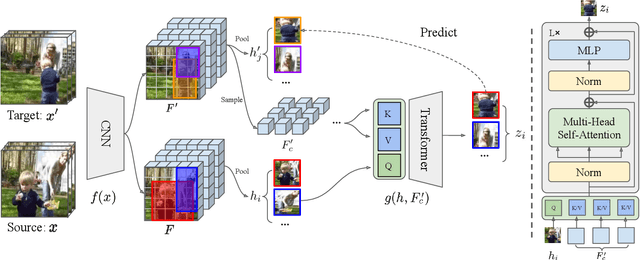
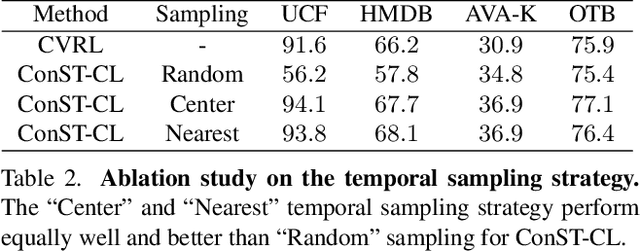
A modern self-supervised learning algorithm typically enforces persistency of the representations of an instance across views. While being very effective on learning holistic image and video representations, such an approach becomes sub-optimal for learning spatio-temporally fine-grained features in videos, where scenes and instances evolve through space and time. In this paper, we present the Contextualized Spatio-Temporal Contrastive Learning (ConST-CL) framework to effectively learn spatio-temporally fine-grained representations using self-supervision. We first design a region-based self-supervised pretext task which requires the model to learn to transform instance representations from one view to another guided by context features. Further, we introduce a simple network design that effectively reconciles the simultaneous learning process of both holistic and local representations. We evaluate our learned representations on a variety of downstream tasks and ConST-CL achieves state-of-the-art results on four datasets. For spatio-temporal action localization, ConST-CL achieves 39.4% mAP with ground-truth boxes and 30.5% mAP with detected boxes on the AVA-Kinetics validation set. For object tracking, ConST-CL achieves 78.1% precision and 55.2% success scores on OTB2015. Furthermore, ConST-CL achieves 94.8% and 71.9% top-1 fine-tuning accuracy on video action recognition datasets, UCF101 and HMDB51 respectively. We plan to release our code and models to the public.
Incremental Ensemble Gaussian Processes
Oct 13, 2021
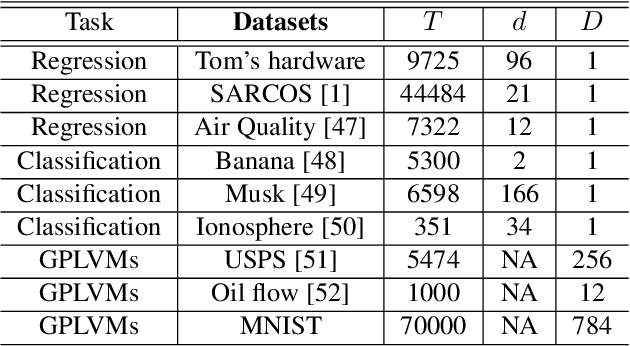
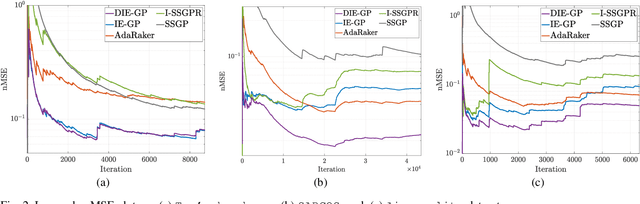
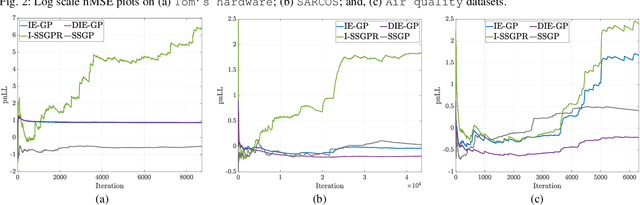
Belonging to the family of Bayesian nonparametrics, Gaussian process (GP) based approaches have well-documented merits not only in learning over a rich class of nonlinear functions, but also in quantifying the associated uncertainty. However, most GP methods rely on a single preselected kernel function, which may fall short in characterizing data samples that arrive sequentially in time-critical applications. To enable {\it online} kernel adaptation, the present work advocates an incremental ensemble (IE-) GP framework, where an EGP meta-learner employs an {\it ensemble} of GP learners, each having a unique kernel belonging to a prescribed kernel dictionary. With each GP expert leveraging the random feature-based approximation to perform online prediction and model update with {\it scalability}, the EGP meta-learner capitalizes on data-adaptive weights to synthesize the per-expert predictions. Further, the novel IE-GP is generalized to accommodate time-varying functions by modeling structured dynamics at the EGP meta-learner and within each GP learner. To benchmark the performance of IE-GP and its dynamic variant in the adversarial setting where the modeling assumptions are violated, rigorous performance analysis has been conducted via the notion of regret, as the norm in online convex optimization. Last but not the least, online unsupervised learning for dimensionality reduction is explored under the novel IE-GP framework. Synthetic and real data tests demonstrate the effectiveness of the proposed schemes.
CELLS: Cost-Effective Evolution in Latent Space for Goal-Directed Molecular Generation
Dec 05, 2021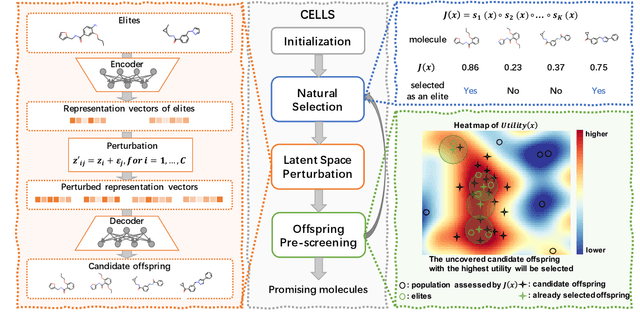
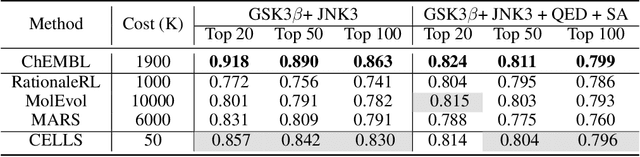
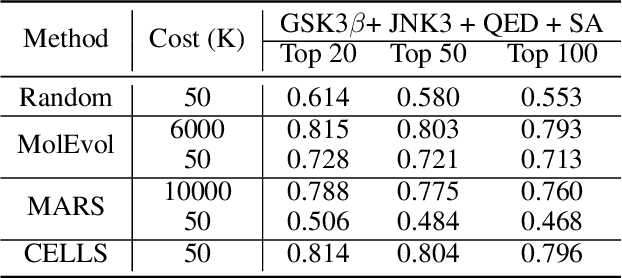
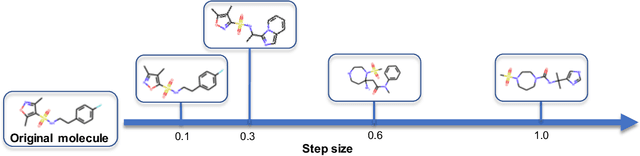
Efficiently discovering molecules that meet various property requirements can significantly benefit the drug discovery industry. Since it is infeasible to search over the entire chemical space, recent works adopt generative models for goal-directed molecular generation. They tend to utilize the iterative processes, optimizing the parameters of the molecular generative models at each iteration to produce promising molecules for further validation. Assessments are exploited to evaluate the generated molecules at each iteration, providing direction for model optimization. However, most previous works require a massive number of expensive and time-consuming assessments, e.g., wet experiments and molecular dynamic simulations, leading to the lack of practicability. To reduce the assessments in the iterative process, we propose a cost-effective evolution strategy in latent space, which optimizes the molecular latent representation vectors instead. We adopt a pre-trained molecular generative model to map the latent and observation spaces, taking advantage of the large-scale unlabeled molecules to learn chemical knowledge. To further reduce the number of expensive assessments, we introduce a pre-screener as the proxy to the assessments. We conduct extensive experiments on multiple optimization tasks comparing the proposed framework to several advanced techniques, showing that the proposed framework achieves better performance with fewer assessments.
Towards a Science of Human-AI Decision Making: A Survey of Empirical Studies
Dec 21, 2021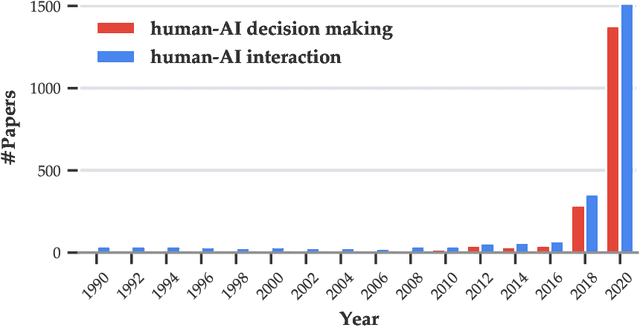
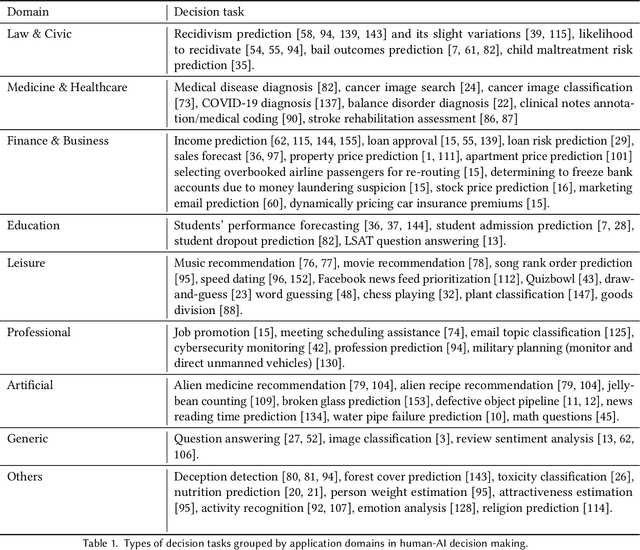
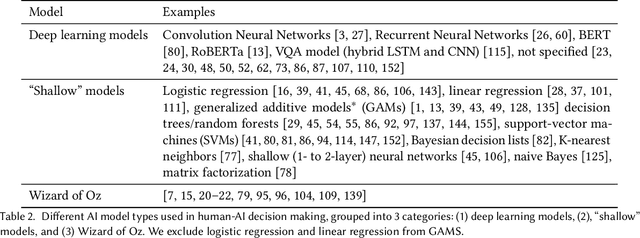
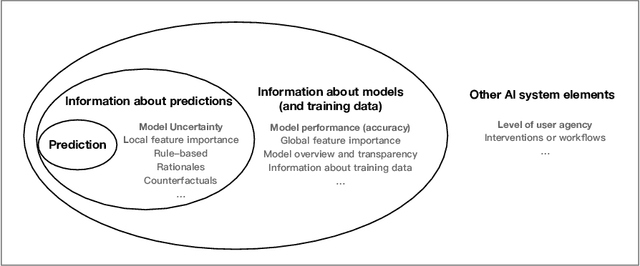
As AI systems demonstrate increasingly strong predictive performance, their adoption has grown in numerous domains. However, in high-stakes domains such as criminal justice and healthcare, full automation is often not desirable due to safety, ethical, and legal concerns, yet fully manual approaches can be inaccurate and time consuming. As a result, there is growing interest in the research community to augment human decision making with AI assistance. Besides developing AI technologies for this purpose, the emerging field of human-AI decision making must embrace empirical approaches to form a foundational understanding of how humans interact and work with AI to make decisions. To invite and help structure research efforts towards a science of understanding and improving human-AI decision making, we survey recent literature of empirical human-subject studies on this topic. We summarize the study design choices made in over 100 papers in three important aspects: (1) decision tasks, (2) AI models and AI assistance elements, and (3) evaluation metrics. For each aspect, we summarize current trends, discuss gaps in current practices of the field, and make a list of recommendations for future research. Our survey highlights the need to develop common frameworks to account for the design and research spaces of human-AI decision making, so that researchers can make rigorous choices in study design, and the research community can build on each other's work and produce generalizable scientific knowledge. We also hope this survey will serve as a bridge for HCI and AI communities to work together to mutually shape the empirical science and computational technologies for human-AI decision making.