 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Inferring untrained complex dynamics of delay systems using an adapted echo state network
Nov 05, 2021
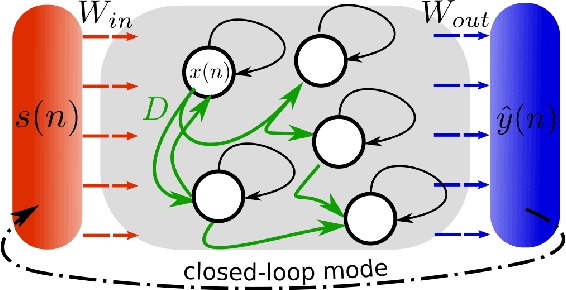
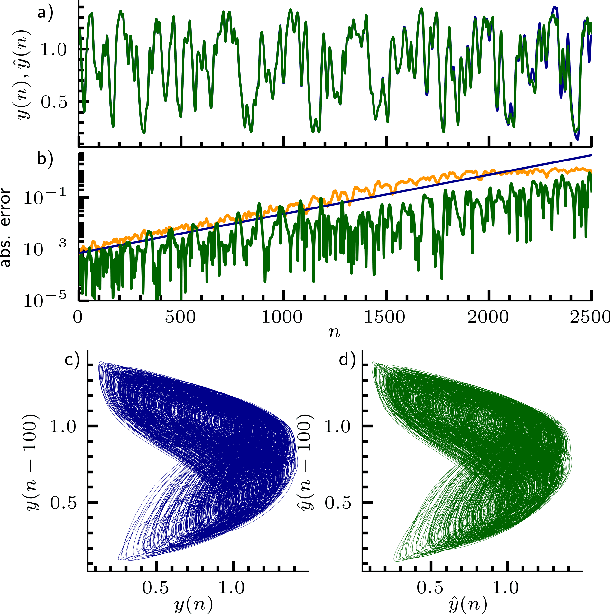
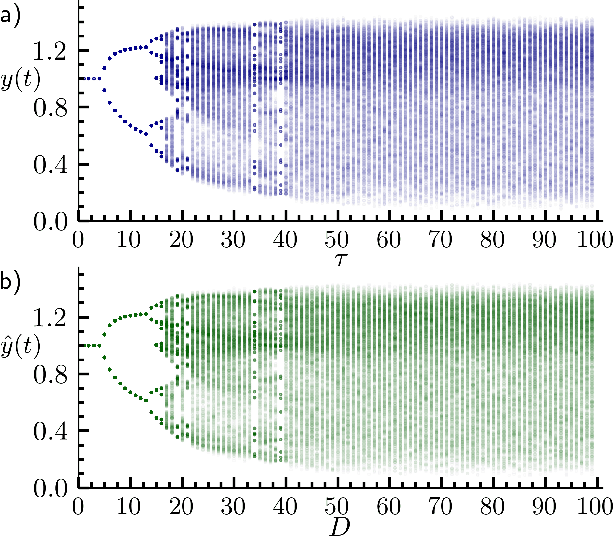

Caused by finite signal propagation velocities, many complex systems feature time delays that may induce high-dimensional chaotic behavior and make forecasting intricate. Here, we propose an echo state network adaptable to the physics of systems with arbitrary delays. After training the network to forecast a system with a unique and sufficiently long delay, it already learned to predict the system dynamics for all other delays. A simple adaptation of the network's topology allows us to infer untrained features such as high-dimensional chaotic attractors, bifurcations, and even multistabilities, that emerge with shorter and longer delays. Thus, the fusion of physical knowledge of the delay system and data-driven machine learning yields a model with high generalization capabilities and unprecedented prediction accuracy.
DisCo: Effective Knowledge Distillation For Contrastive Learning of Sentence Embeddings
Dec 10, 2021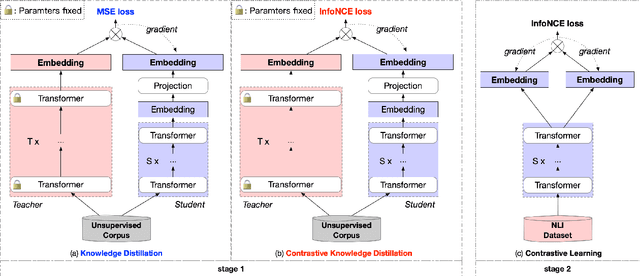
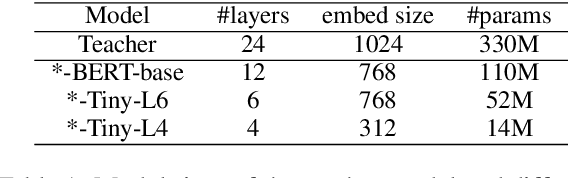
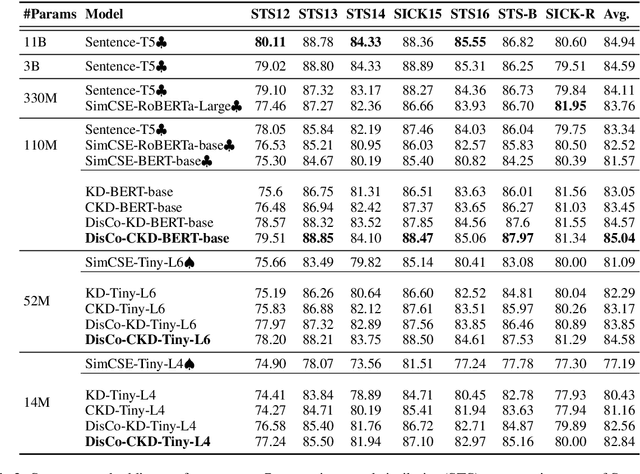
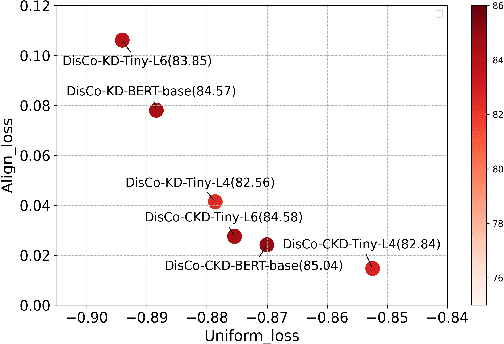
Contrastive learning has been proven suitable for learning sentence embeddings and can significantly improve the semantic textual similarity (STS) tasks. Recently, large contrastive learning models, e.g., Sentence-T5, tend to be proposed to learn more powerful sentence embeddings. Though effective, such large models are hard to serve online due to computational resources or time cost limits. To tackle that, knowledge distillation (KD) is commonly adopted, which can compress a large "teacher" model into a small "student" model but generally suffer from some performance loss. Here we propose an enhanced KD framework termed Distill-Contrast (DisCo). The proposed DisCo framework firstly utilizes KD to transfer the capability of a large sentence embedding model to a small student model on large unlabelled data, and then finetunes the student model with contrastive learning on labelled training data. For the KD process in DisCo, we further propose Contrastive Knowledge Distillation (CKD) to enhance the consistencies among teacher model training, KD, and student model finetuning, which can probably improve performance like prompt learning. Extensive experiments on 7 STS benchmarks show that student models trained with the proposed DisCo and CKD suffer from little or even no performance loss and consistently outperform the corresponding counterparts of the same parameter size. Amazingly, our 110M student model can even outperform the latest state-of-the-art (SOTA) model, i.e., Sentence-T5(11B), with only 1% parameters.
Comparison of inverse problem linear and non-linear methods for localization source: a combined TMS-EEG study
Nov 30, 2021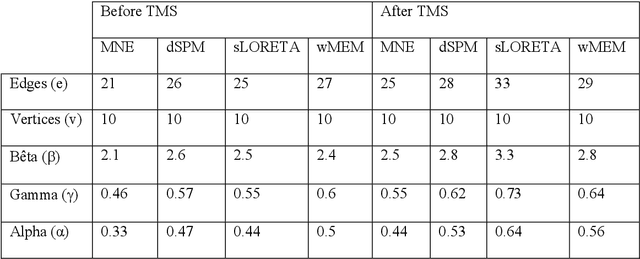
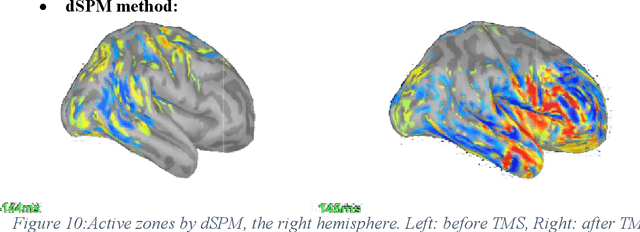
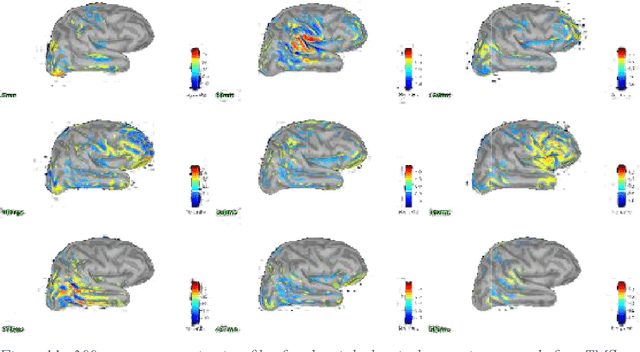
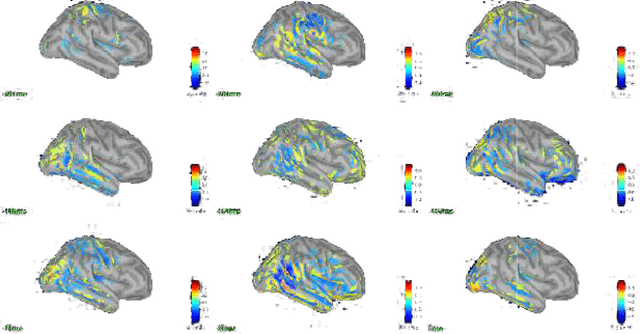
The Electro-Encephalo-Graphy (EEG) technique consists of estimating the cortical distribution of signals over time of electrical activity and also of locating the zones of primary sensory projection. Moreover, it is able to record respectively the variations of potential and field magnetic waves generated by electrical activity in the brain every millisecond. Concerning, the study of the localization source, the brain localizationactivity requires the solution of a inverse problem. Many different imaging methods are used to solve the inverse problem.The aim of the presentstudy is to provide comparison criteria for choosing the least bad method. Hence, the transcranial magnetic stimulation (TMS) and electroencephalography (EEG) technique are combined for the sake of studying the dynamics of the brain at rest following a disturbance. The study focuses in the comparison of the following methods for EEG following stimulation by TMS: sLORETA (standardized Low Resolution Electromagnetic Tomography), MNE (Minimum Estimate of the standard), dSPM (dynamic Statistical Parametric Mapping) and wMEM (wavelet based on the Maximum Entropy on the Mean)in order to study the impact of TMS towards rest and to study inter and intra zone connectivity.The contribution of the comparison is demonstrated via the stages of the simulations.
Deep Reinforcement Learning with Adjustments
Sep 28, 2021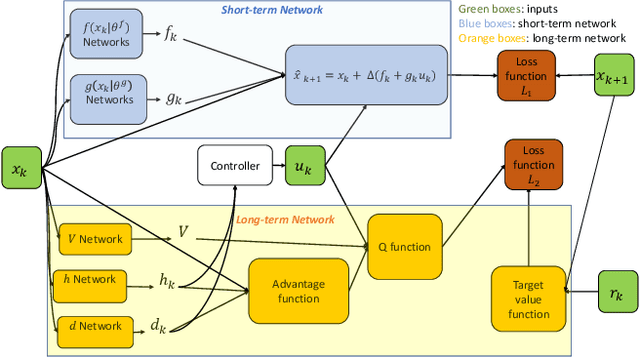
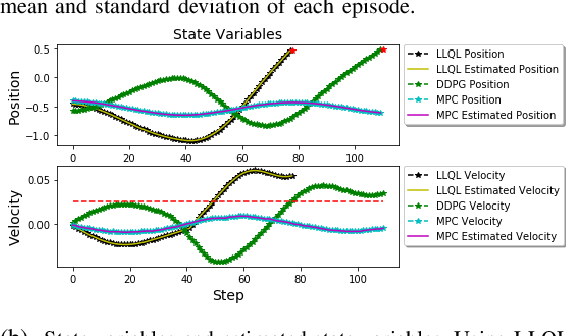
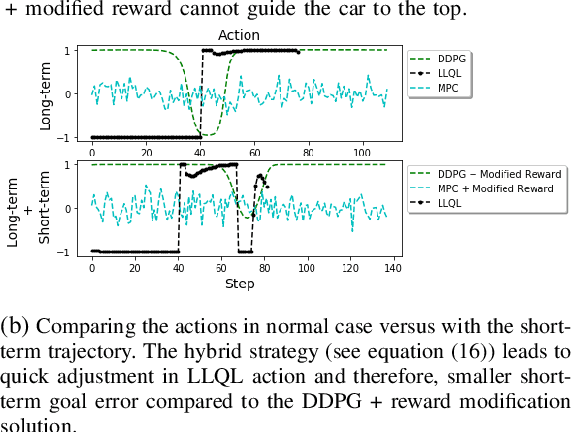
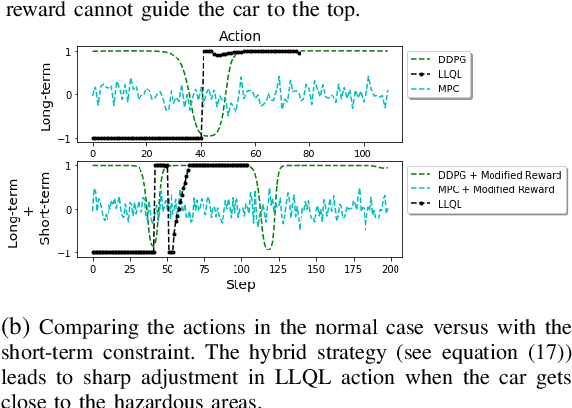
Deep reinforcement learning (RL) algorithms can learn complex policies to optimize agent operation over time. RL algorithms have shown promising results in solving complicated problems in recent years. However, their application on real-world physical systems remains limited. Despite the advancements in RL algorithms, the industries often prefer traditional control strategies. Traditional methods are simple, computationally efficient and easy to adjust. In this paper, we first propose a new Q-learning algorithm for continuous action space, which can bridge the control and RL algorithms and bring us the best of both worlds. Our method can learn complex policies to achieve long-term goals and at the same time it can be easily adjusted to address short-term requirements without retraining. Next, we present an approximation of our algorithm which can be applied to address short-term requirements of any pre-trained RL algorithm. The case studies demonstrate that both our proposed method as well as its practical approximation can achieve short-term and long-term goals without complex reward functions.
Learning in High-Dimensional Feature Spaces Using ANOVA-Based Fast Matrix-Vector Multiplication
Nov 19, 2021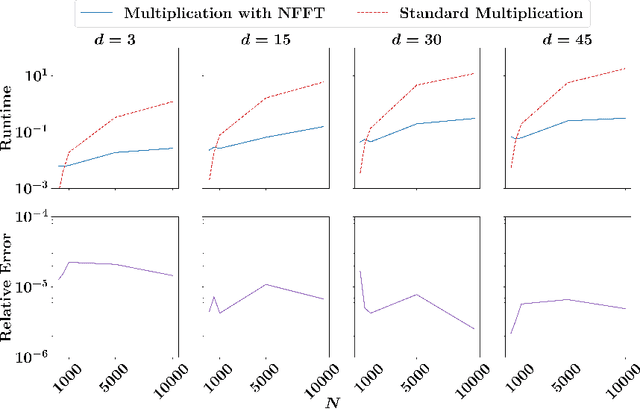
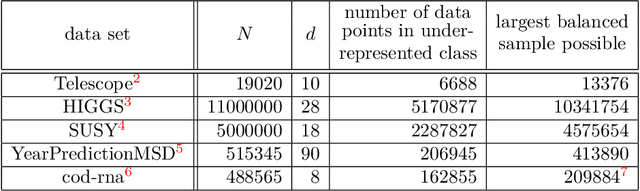
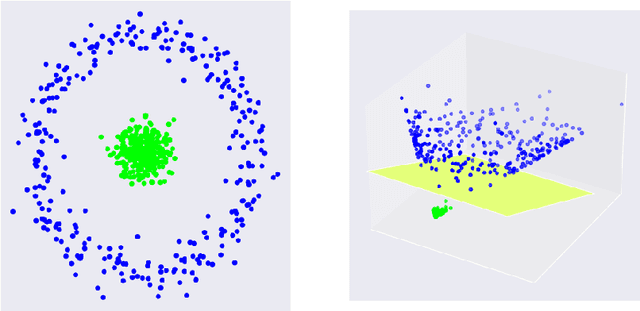

Kernel matrices are crucial in many learning tasks such as support vector machines or kernel ridge regression. The kernel matrix is typically dense and large-scale. Depending on the dimension of the feature space even the computation of all of its entries in reasonable time becomes a challenging task. For such dense matrices the cost of a matrix-vector product scales quadratically in the number of entries, if no customized methods are applied. We propose the use of an ANOVA kernel, where we construct several kernels based on lower-dimensional feature spaces for which we provide fast algorithms realizing the matrix-vector products. We employ the non-equispaced fast Fourier transform (NFFT), which is of linear complexity for fixed accuracy. Based on a feature grouping approach, we then show how the fast matrix-vector products can be embedded into a learning method choosing kernel ridge regression and the preconditioned conjugate gradient solver. We illustrate the performance of our approach on several data sets.
A Kernel to Exploit Informative Missingness in Multivariate Time Series from EHRs
Feb 27, 2020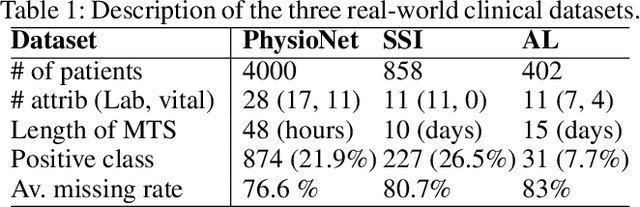
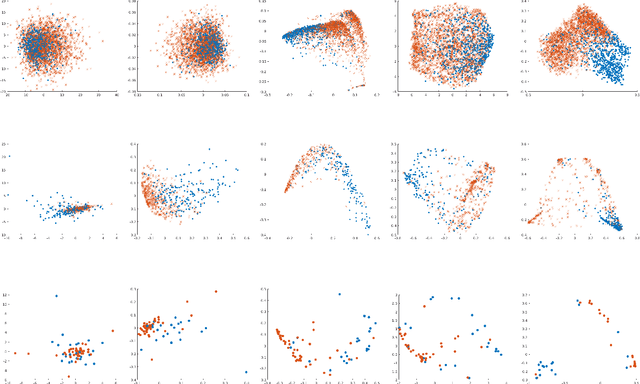
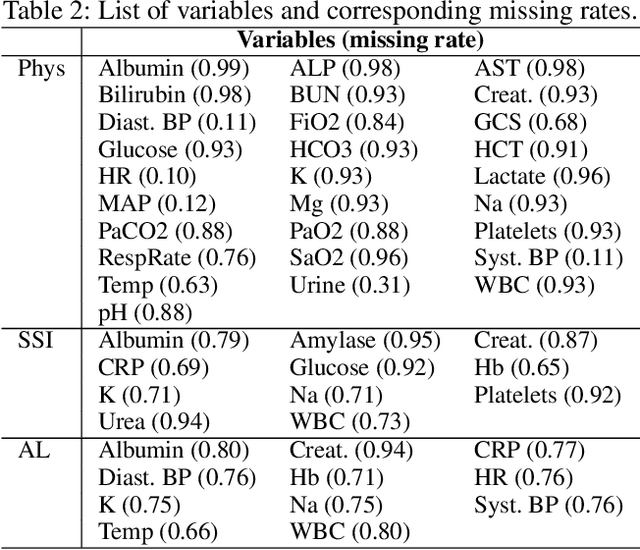
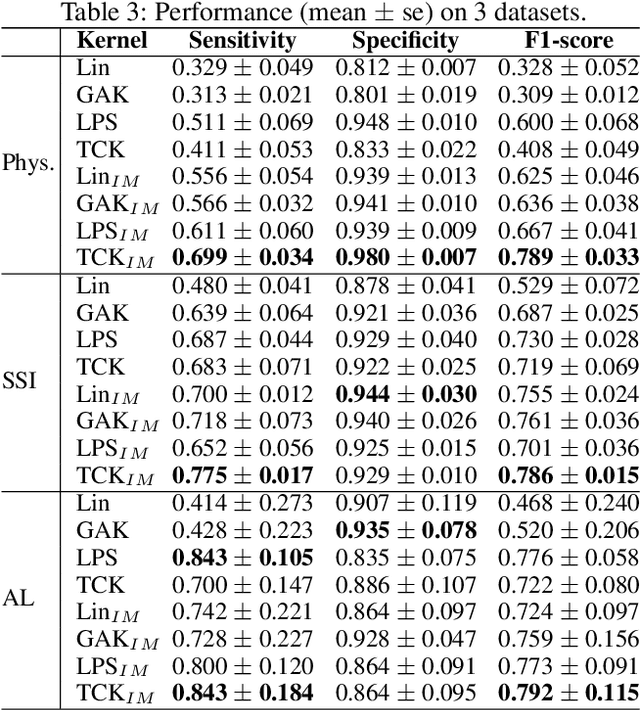
A large fraction of the electronic health records (EHRs) consists of clinical measurements collected over time, such as lab tests and vital signs, which provide important information about a patient's health status. These sequences of clinical measurements are naturally represented as time series, characterized by multiple variables and large amounts of missing data, which complicate the analysis. In this work, we propose a novel kernel which is capable of exploiting both the information from the observed values as well the information hidden in the missing patterns in multivariate time series (MTS) originating e.g. from EHRs. The kernel, called TCK$_{IM}$, is designed using an ensemble learning strategy in which the base models are novel mixed mode Bayesian mixture models which can effectively exploit informative missingness without having to resort to imputation methods. Moreover, the ensemble approach ensures robustness to hyperparameters and therefore TCK$_{IM}$ is particularly well suited if there is a lack of labels - a known challenge in medical applications. Experiments on three real-world clinical datasets demonstrate the effectiveness of the proposed kernel.
Estimating the time-lapse between medical insurance reimbursement with non-parametric regression models
Aug 19, 2020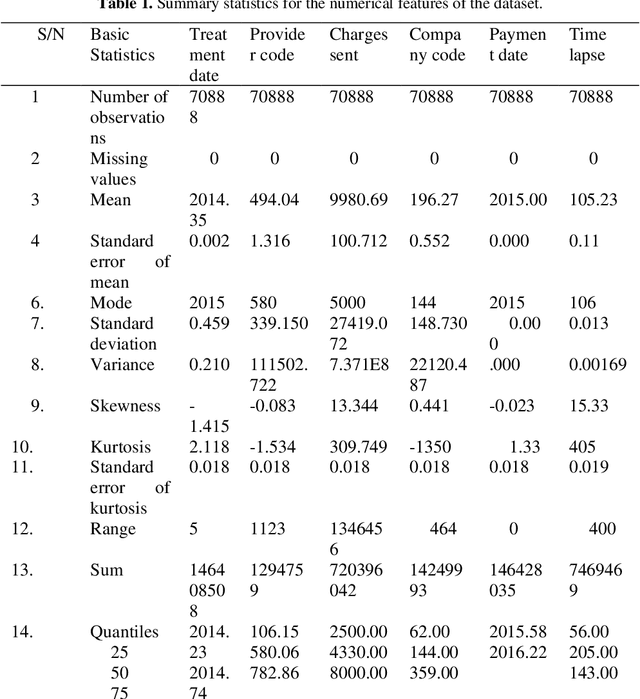
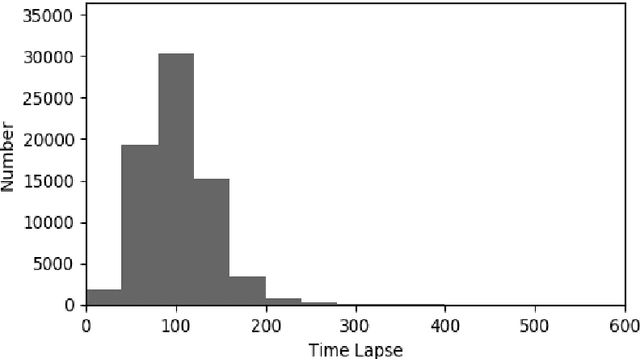
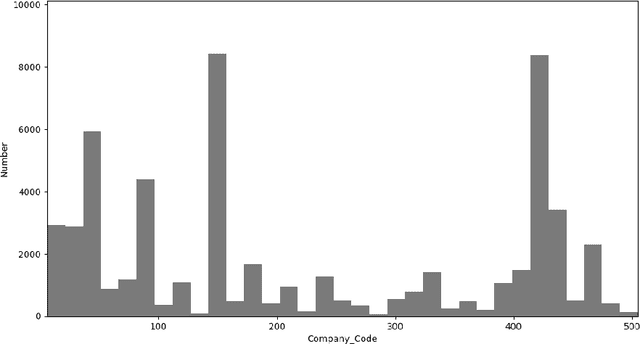
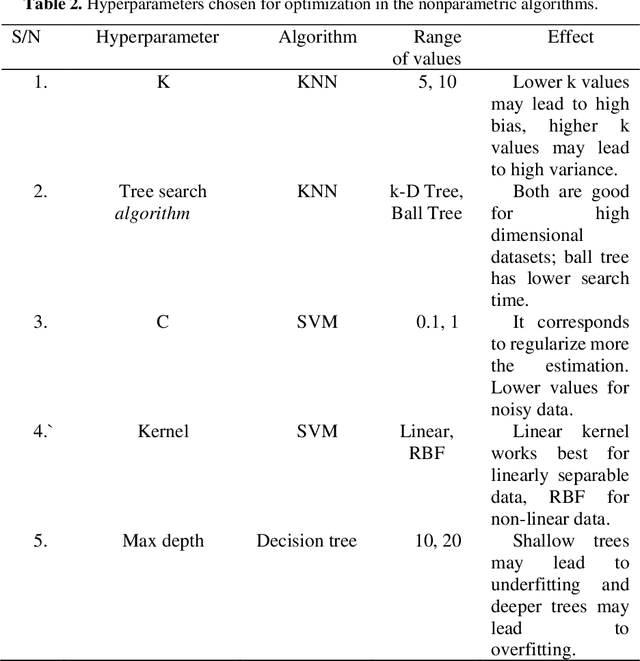
Non-parametric supervised learning algorithms represent a succinct class of supervised learning algorithms where the learning parameters are highly flexible and whose values are directly dependent on the size of the training data. In this paper, we comparatively study the properties of four nonparametric algorithms, K-Nearest Neighbours (KNNs), Support Vector Machines (SVMs), Decision trees and Random forests. The supervised learning task is a regression estimate of the time-lapse in medical insurance reimbursement. Our study is concerned precisely with how well each of the nonparametric regression models fits the training data. We quantify the goodness of fit using the R-squared metric. The results are presented with a focus on the effect of the size of the training data, the feature space dimension and hyperparameter optimization.
Synthetic ECG Signal Generation Using Generative Neural Networks
Dec 05, 2021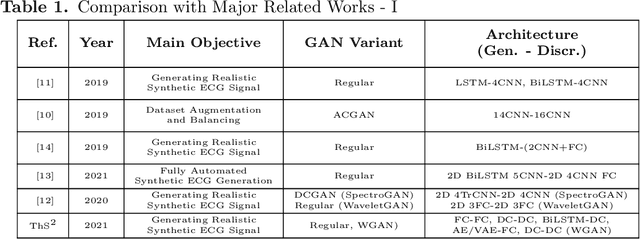
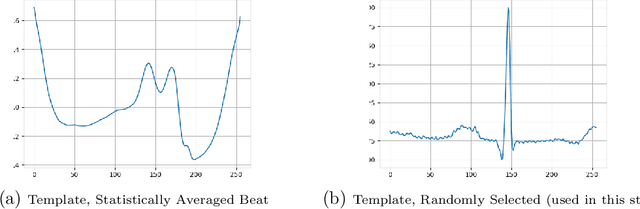
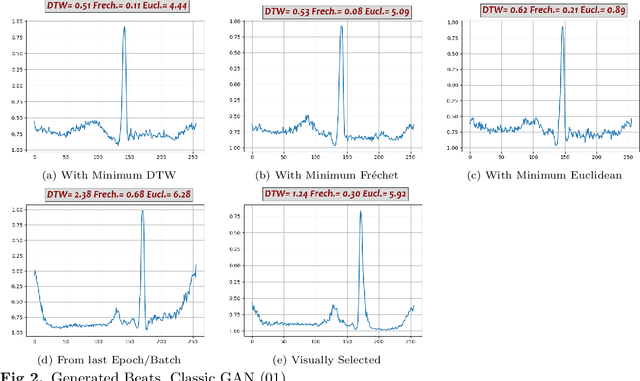
Electrocardiogram (ECG) datasets tend to be highly imbalanced due to the scarcity of abnormal cases. Additionally, the use of real patients' ECG is highly regulated due to privacy issues. Therefore, there is always a need for more ECG data, especially for the training of automatic diagnosis machine learning models, which perform better when trained on a balanced dataset. We studied the synthetic ECG generation capability of 5 different models from the generative adversarial network (GAN) family and compared their performances, the focus being only on Normal cardiac cycles. Dynamic Time Warping (DTW), Fr\'echet, and Euclidean distance functions were employed to quantitatively measure performance. Five different methods for evaluating generated beats were proposed and applied. We also proposed 3 new concepts (threshold, accepted beat and productivity rate) and employed them along with the aforementioned methods as a systematic way for comparison between models. The results show that all the tested models can to an extent successfully mass-generate acceptable heartbeats with high similarity in morphological features, and potentially all of them can be used to augment imbalanced datasets. However, visual inspections of generated beats favor BiLSTM-DC GAN and WGAN, as they produce statistically more acceptable beats. Also, with regards to productivity rate, the Classic GAN is superior with a 72% productivity rate.
Monitoring geometrical properties of word embeddings for detecting the emergence of new topics
Nov 05, 2021
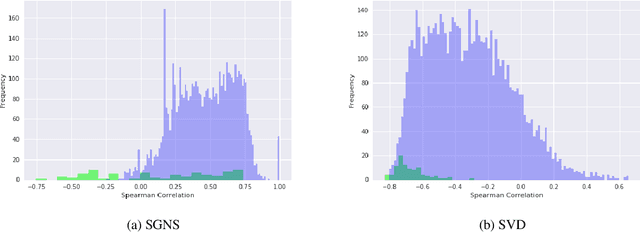

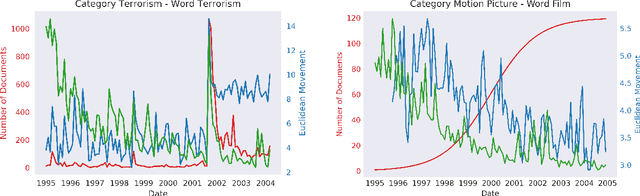
Slow emerging topic detection is a task between event detection, where we aggregate behaviors of different words on short period of time, and language evolution, where we monitor their long term evolution. In this work, we tackle the problem of early detection of slowly emerging new topics. To this end, we gather evidence of weak signals at the word level. We propose to monitor the behavior of words representation in an embedding space and use one of its geometrical properties to characterize the emergence of topics. As evaluation is typically hard for this kind of task, we present a framework for quantitative evaluation. We show positive results that outperform state-of-the-art methods on two public datasets of press and scientific articles.
ES-dRNN: A Hybrid Exponential Smoothing and Dilated Recurrent Neural Network Model for Short-Term Load Forecasting
Dec 05, 2021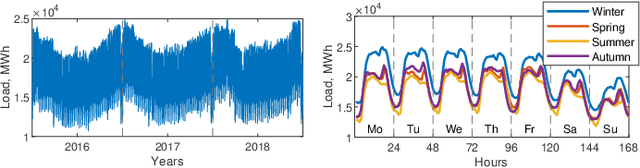
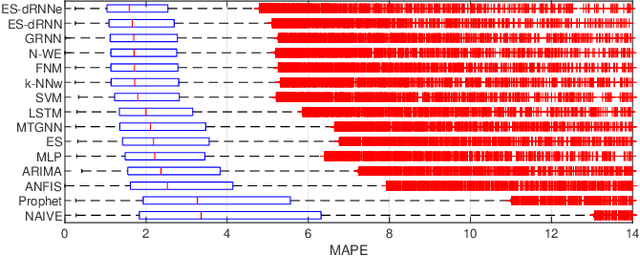
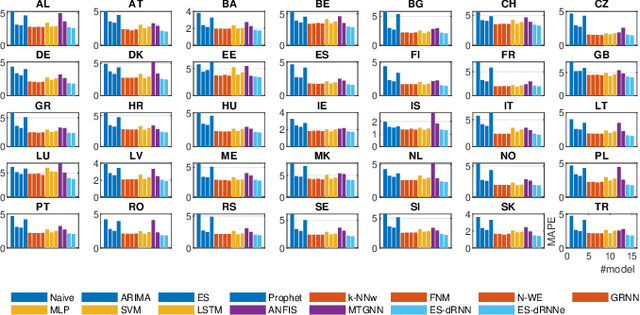
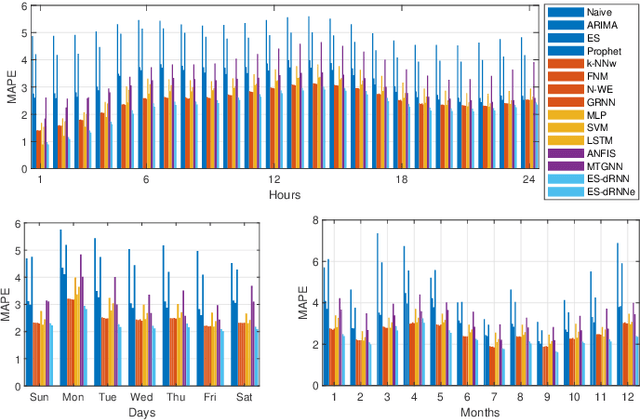
Short-term load forecasting (STLF) is challenging due to complex time series (TS) which express three seasonal patterns and a nonlinear trend. This paper proposes a novel hybrid hierarchical deep learning model that deals with multiple seasonality and produces both point forecasts and predictive intervals (PIs). It combines exponential smoothing (ES) and a recurrent neural network (RNN). ES extracts dynamically the main components of each individual TS and enables on-the-fly deseasonalization, which is particularly useful when operating on a relatively small data set. A multi-layer RNN is equipped with a new type of dilated recurrent cell designed to efficiently model both short and long-term dependencies in TS. To improve the internal TS representation and thus the model's performance, RNN learns simultaneously both the ES parameters and the main mapping function transforming inputs into forecasts. We compare our approach against several baseline methods, including classical statistical methods and machine learning (ML) approaches, on STLF problems for 35 European countries. The empirical study clearly shows that the proposed model has high expressive power to solve nonlinear stochastic forecasting problems with TS including multiple seasonality and significant random fluctuations. In fact, it outperforms both statistical and state-of-the-art ML models in terms of accuracy.