 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A First-Occupancy Representation for Reinforcement Learning
Oct 06, 2021
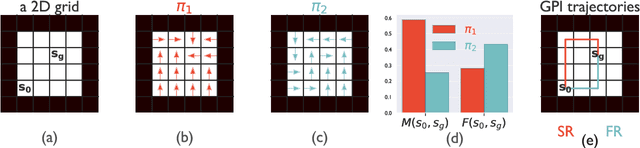
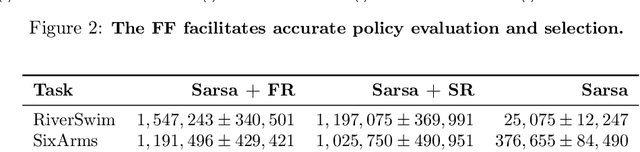
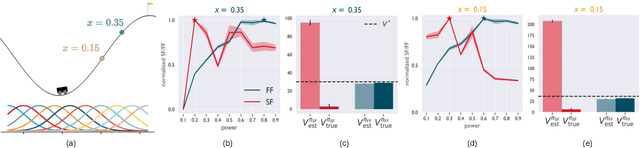
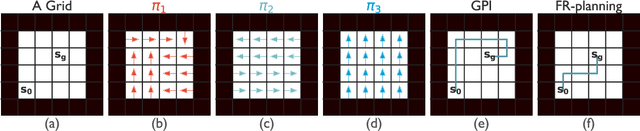
Both animals and artificial agents benefit from state representations that support rapid transfer of learning across tasks and which enable them to efficiently traverse their environments to reach rewarding states. The successor representation (SR), which measures the expected cumulative, discounted state occupancy under a fixed policy, enables efficient transfer to different reward structures in an otherwise constant Markovian environment and has been hypothesized to underlie aspects of biological behavior and neural activity. However, in the real world, rewards may move or only be available for consumption once, may shift location, or agents may simply aim to reach goal states as rapidly as possible without the constraint of artificially imposed task horizons. In such cases, the most behaviorally-relevant representation would carry information about when the agent was likely to first reach states of interest, rather than how often it should expect to visit them over a potentially infinite time span. To reflect such demands, we introduce the first-occupancy representation (FR), which measures the expected temporal discount to the first time a state is accessed. We demonstrate that the FR facilitates exploration, the selection of efficient paths to desired states, allows the agent, under certain conditions, to plan provably optimal trajectories defined by a sequence of subgoals, and induces similar behavior to animals avoiding threatening stimuli.
A deep reinforcement learning model for predictive maintenance planning of road assets: Integrating LCA and LCCA
Dec 24, 2021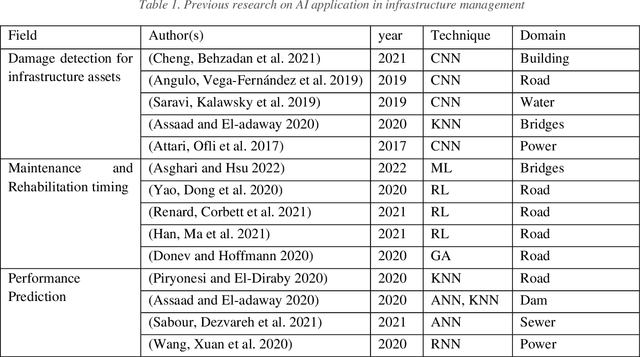
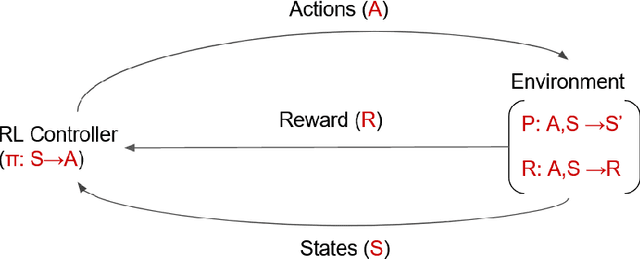
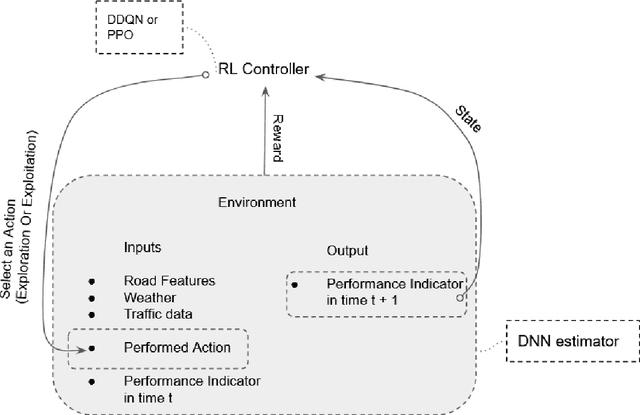
Road maintenance planning is an integral part of road asset management. One of the main challenges in Maintenance and Rehabilitation (M&R) practices is to determine maintenance type and timing. This research proposes a framework using Reinforcement Learning (RL) based on the Long Term Pavement Performance (LTPP) database to determine the type and timing of M&R practices. A predictive DNN model is first developed in the proposed algorithm, which serves as the Environment for the RL algorithm. For the Policy estimation of the RL model, both DQN and PPO models are developed. However, PPO has been selected in the end due to better convergence and higher sample efficiency. Indicators used in this study are International Roughness Index (IRI) and Rutting Depth (RD). Initially, we considered Cracking Metric (CM) as the third indicator, but it was then excluded due to the much fewer data compared to other indicators, which resulted in lower accuracy of the results. Furthermore, in cost-effectiveness calculation (reward), we considered both the economic and environmental impacts of M&R treatments. Costs and environmental impacts have been evaluated with paLATE 2.0 software. Our method is tested on a hypothetical case study of a six-lane highway with 23 kilometers length located in Texas, which has a warm and wet climate. The results propose a 20-year M&R plan in which road condition remains in an excellent condition range. Because the early state of the road is at a good level of service, there is no need for heavy maintenance practices in the first years. Later, after heavy M&R actions, there are several 1-2 years of no need for treatments. All of these show that the proposed plan has a logical result. Decision-makers and transportation agencies can use this scheme to conduct better maintenance practices that can prevent budget waste and, at the same time, minimize the environmental impacts.
Learning to Align Sequential Actions in the Wild
Nov 17, 2021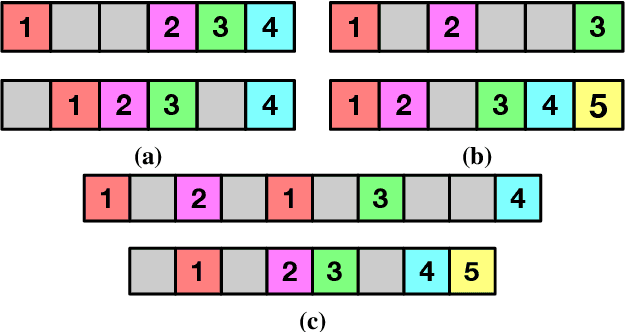
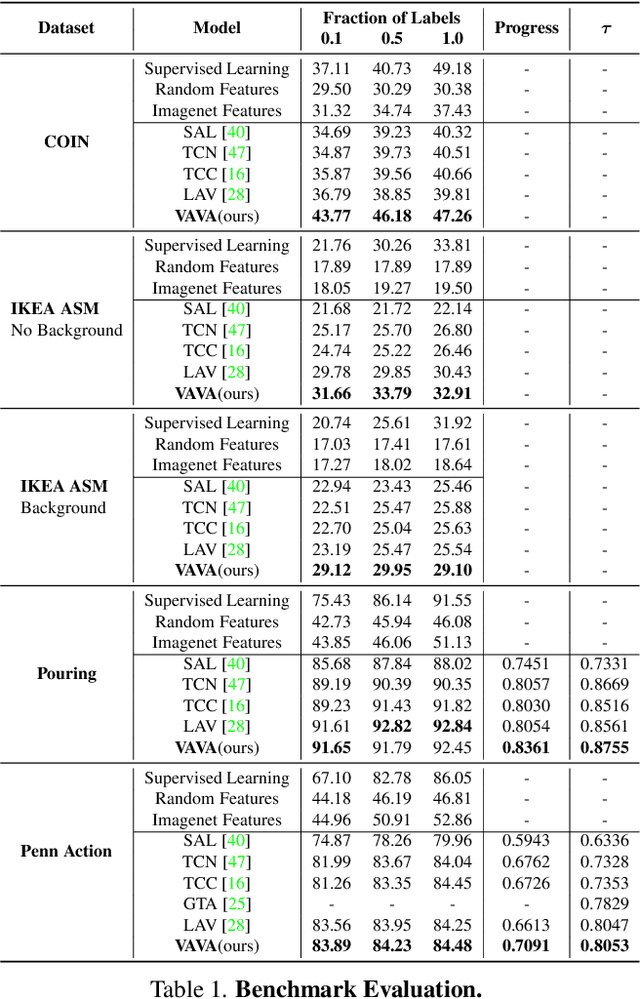
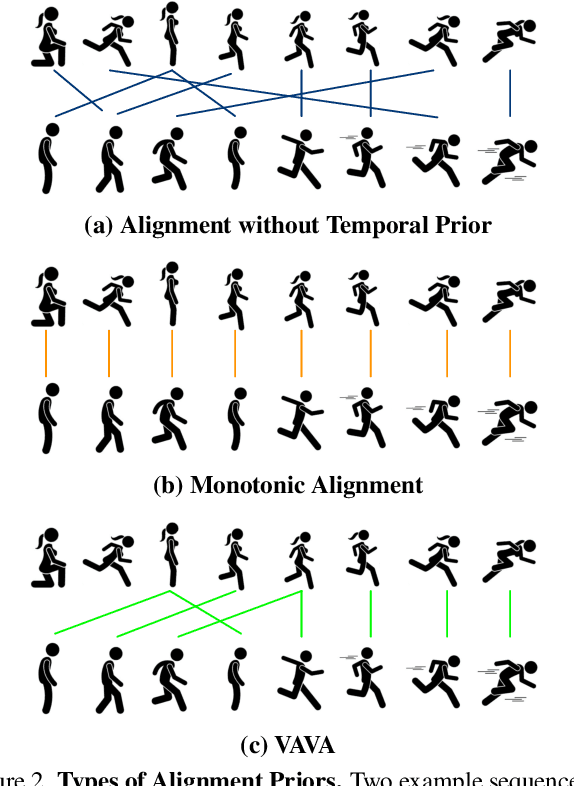
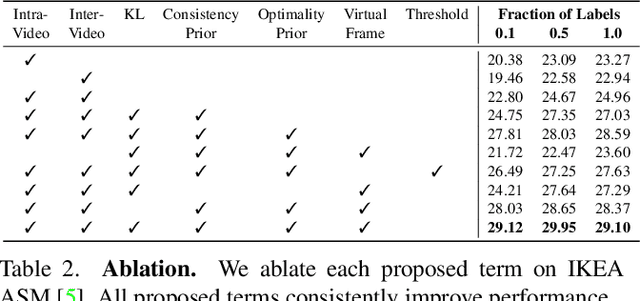
State-of-the-art methods for self-supervised sequential action alignment rely on deep networks that find correspondences across videos in time. They either learn frame-to-frame mapping across sequences, which does not leverage temporal information, or assume monotonic alignment between each video pair, which ignores variations in the order of actions. As such, these methods are not able to deal with common real-world scenarios that involve background frames or videos that contain non-monotonic sequence of actions. In this paper, we propose an approach to align sequential actions in the wild that involve diverse temporal variations. To this end, we propose an approach to enforce temporal priors on the optimal transport matrix, which leverages temporal consistency, while allowing for variations in the order of actions. Our model accounts for both monotonic and non-monotonic sequences and handles background frames that should not be aligned. We demonstrate that our approach consistently outperforms the state-of-the-art in self-supervised sequential action representation learning on four different benchmark datasets.
Hierarchically Regularized Deep Forecasting
Jun 14, 2021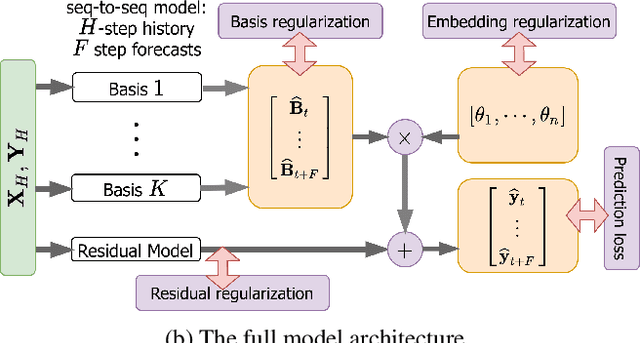
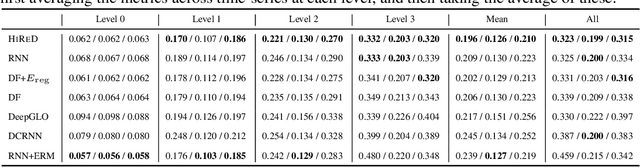
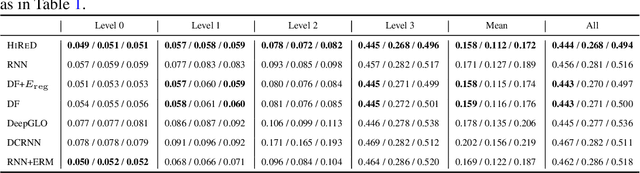

Hierarchical forecasting is a key problem in many practical multivariate forecasting applications - the goal is to simultaneously predict a large number of correlated time series that are arranged in a pre-specified aggregation hierarchy. The challenge is to exploit the hierarchical correlations to simultaneously obtain good prediction accuracy for time series at different levels of the hierarchy. In this paper, we propose a new approach for hierarchical forecasting based on decomposing the time series along a global set of basis time series and modeling hierarchical constraints using the coefficients of the basis decomposition for each time series. Unlike past methods, our approach is scalable at inference-time (forecasting for a specific time series only needs access to its own data) while (approximately) preserving coherence among the time series forecasts. We experiment on several publicly available datasets and demonstrate significantly improved overall performance on forecasts at different levels of the hierarchy, compared to existing state-of-the-art hierarchical reconciliation methods.
Binary Change Guided Hyperspectral Multiclass Change Detection
Dec 11, 2021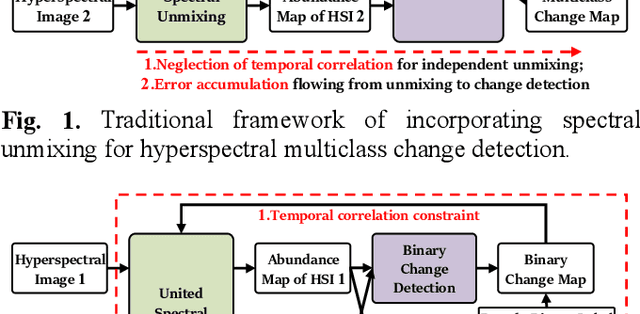

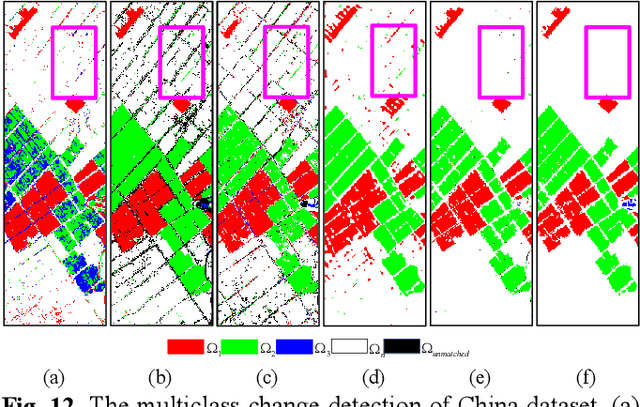
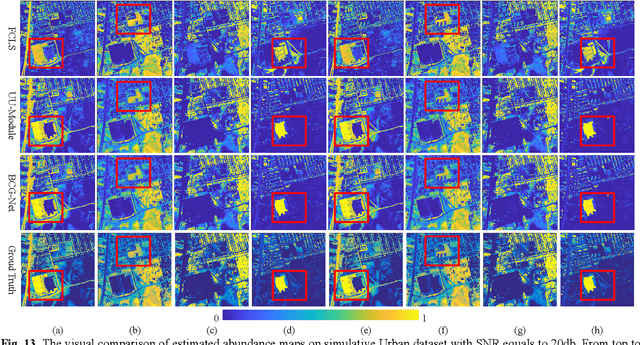
Characterized by tremendous spectral information, hyperspectral image is able to detect subtle changes and discriminate various change classes for change detection. The recent research works dominated by hyperspectral binary change detection, however, cannot provide fine change classes information. And most methods incorporating spectral unmixing for hyperspectral multiclass change detection (HMCD), yet suffer from the neglection of temporal correlation and error accumulation. In this study, we proposed an unsupervised Binary Change Guided hyperspectral multiclass change detection Network (BCG-Net) for HMCD, which aims at boosting the multiclass change detection result and unmixing result with the mature binary change detection approaches. In BCG-Net, a novel partial-siamese united-unmixing module is designed for multi-temporal spectral unmixing, and a groundbreaking temporal correlation constraint directed by the pseudo-labels of binary change detection result is developed to guide the unmixing process from the perspective of change detection, encouraging the abundance of the unchanged pixels more coherent and that of the changed pixels more accurate. Moreover, an innovative binary change detection rule is put forward to deal with the problem that traditional rule is susceptible to numerical values. The iterative optimization of the spectral unmixing process and the change detection process is proposed to eliminate the accumulated errors and bias from unmixing result to change detection result. The experimental results demonstrate that our proposed BCG-Net could achieve comparative or even outstanding performance of multiclass change detection among the state-of-the-art approaches and gain better spectral unmixing results at the same time.
SROM: Simple Real-time Odometry and Mapping using LiDAR data for Autonomous Vehicles
May 07, 2020
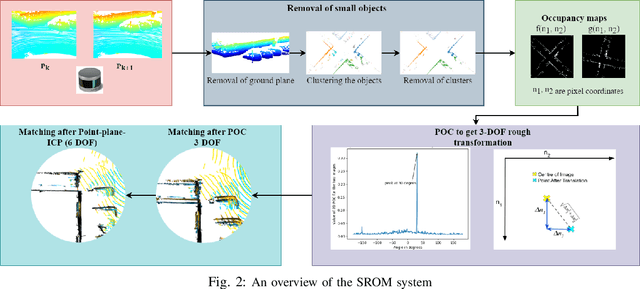
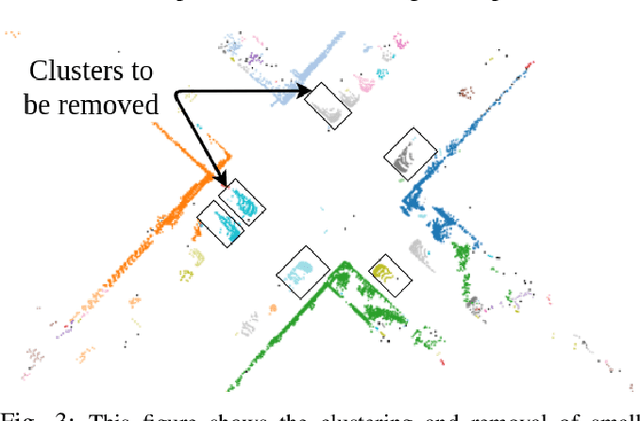

In this paper, we present SROM, a novel real-time Simultaneous Localization and Mapping (SLAM) system for autonomous vehicles. The keynote of the paper showcases SROM's ability to maintain localization at low sampling rates or at high linear or angular velocities where most popular LiDAR based localization approaches get degraded fast. We also demonstrate SROM to be computationally efficient and capable of handling high-speed maneuvers. It also achieves low drifts without the need for any other sensors like IMU and/or GPS. Our method has a two-layer structure wherein first, an approximate estimate of the rotation angle and translation parameters are calculated using a Phase Only Correlation (POC) method. Next, we use this estimate as an initialization for a point-to-plane ICP algorithm to obtain fine matching and registration. Another key feature of the proposed algorithm is the removal of dynamic objects before matching the scans. This improves the performance of our system as the dynamic objects can corrupt the matching scheme and derail localization. Our SLAM system can build reliable maps at the same time generating high-quality odometry. We exhaustively evaluated the proposed method in many challenging highways/country/urban sequences from the KITTI dataset and the results demonstrate better accuracy in comparisons to other state-of-the-art methods with reduced computational expense aiding in real-time realizations. We have also integrated our SROM system with our in-house autonomous vehicle and compared it with the state-of-the-art methods like LOAM and LeGO-LOAM.
Learning to Solve Combinatorial Optimization Problems on Real-World Graphs in Linear Time
Jun 06, 2020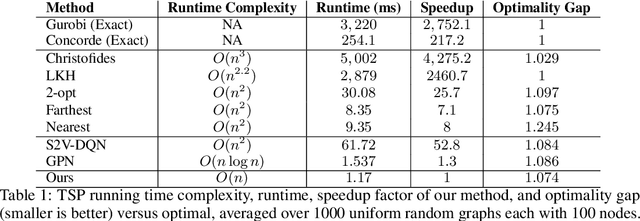
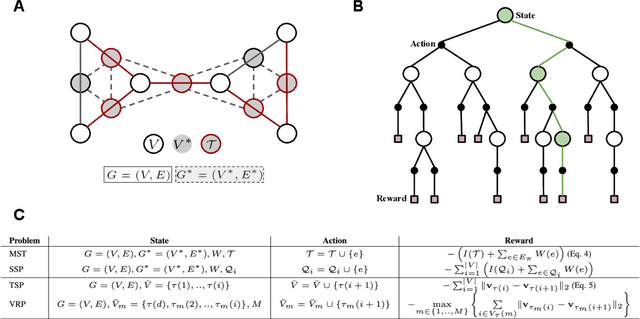
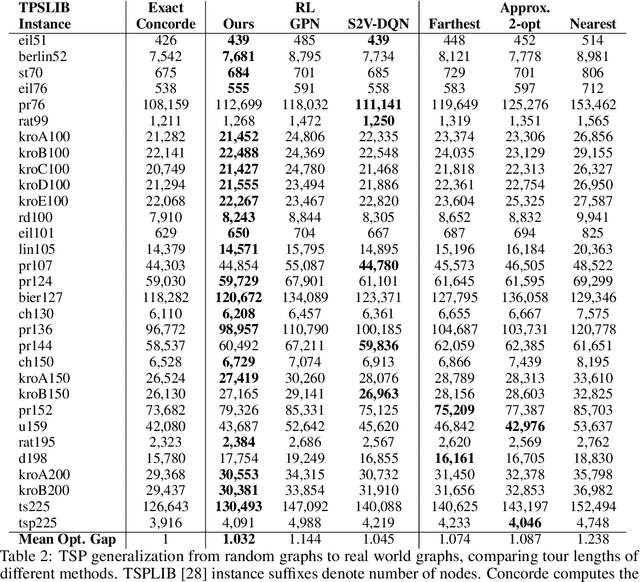
Combinatorial optimization algorithms for graph problems are usually designed afresh for each new problem with careful attention by an expert to the problem structure. In this work, we develop a new framework to solve any combinatorial optimization problem over graphs that can be formulated as a single player game defined by states, actions, and rewards, including minimum spanning tree, shortest paths, traveling salesman problem, and vehicle routing problem, without expert knowledge. Our method trains a graph neural network using reinforcement learning on an unlabeled training set of graphs. The trained network then outputs approximate solutions to new graph instances in linear running time. In contrast, previous approximation algorithms or heuristics tailored to NP-hard problems on graphs generally have at least quadratic running time. We demonstrate the applicability of our approach on both polynomial and NP-hard problems with optimality gaps close to 1, and show that our method is able to generalize well: (i) from training on small graphs to testing on large graphs; (ii) from training on random graphs of one type to testing on random graphs of another type; and (iii) from training on random graphs to running on real world graphs.
IV-GNN : Interval Valued Data Handling Using Graph Neural Network
Nov 17, 2021
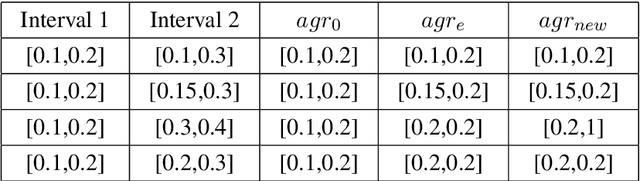

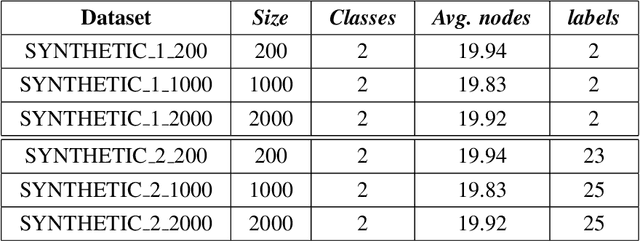
Graph Neural Network (GNN) is a powerful tool to perform standard machine learning on graphs. To have a Euclidean representation of every node in the Non-Euclidean graph-like data, GNN follows neighbourhood aggregation and combination of information recursively along the edges of the graph. Despite having many GNN variants in the literature, no model can deal with graphs having nodes with interval-valued features. This article proposes an Interval-ValuedGraph Neural Network, a novel GNN model where, for the first time, we relax the restriction of the feature space being countable. Our model is much more general than existing models as any countable set is always a subset of the universal set $R^{n}$, which is uncountable. Here, to deal with interval-valued feature vectors, we propose a new aggregation scheme of intervals and show its expressive power to capture different interval structures. We validate our theoretical findings about our model for graph classification tasks by comparing its performance with those of the state-of-the-art models on several benchmark network and synthetic datasets.
A Generalized Zero-Shot Quantization of Deep Convolutional Neural Networks via Learned Weights Statistics
Dec 11, 2021
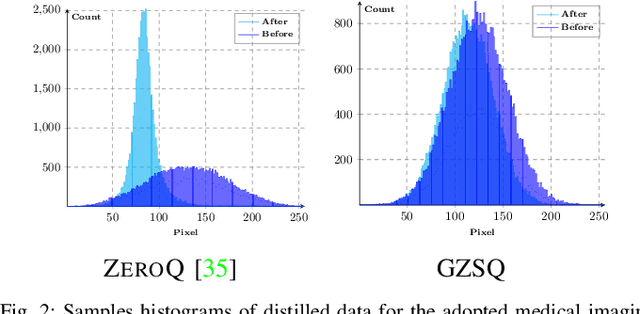
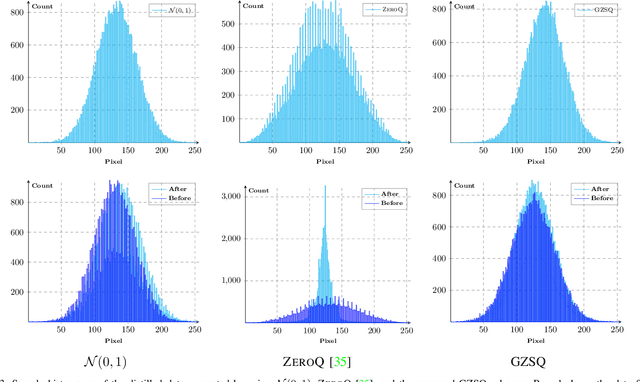
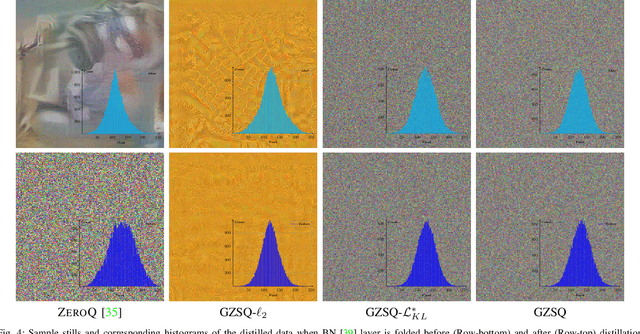
Quantizing the floating-point weights and activations of deep convolutional neural networks to fixed-point representation yields reduced memory footprints and inference time. Recently, efforts have been afoot towards zero-shot quantization that does not require original unlabelled training samples of a given task. These best-published works heavily rely on the learned batch normalization (BN) parameters to infer the range of the activations for quantization. In particular, these methods are built upon either empirical estimation framework or the data distillation approach, for computing the range of the activations. However, the performance of such schemes severely degrades when presented with a network that does not accommodate BN layers. In this line of thought, we propose a generalized zero-shot quantization (GZSQ) framework that neither requires original data nor relies on BN layer statistics. We have utilized the data distillation approach and leveraged only the pre-trained weights of the model to estimate enriched data for range calibration of the activations. To the best of our knowledge, this is the first work that utilizes the distribution of the pretrained weights to assist the process of zero-shot quantization. The proposed scheme has significantly outperformed the existing zero-shot works, e.g., an improvement of ~ 33% in classification accuracy for MobileNetV2 and several other models that are w & w/o BN layers, for a variety of tasks. We have also demonstrated the efficacy of the proposed work across multiple open-source quantization frameworks. Importantly, our work is the first attempt towards the post-training zero-shot quantization of futuristic unnormalized deep neural networks.
Location Leakage in Federated Signal Maps
Dec 07, 2021

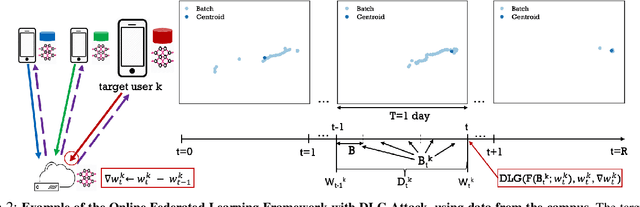

We consider the problem of predicting cellular network performance (signal maps) from measurements collected by several mobile devices. We formulate the problem within the online federated learning framework: (i) federated learning (FL) enables users to collaboratively train a model, while keeping their training data on their devices; (ii) measurements are collected as users move around over time and are used for local training in an online fashion. We consider an honest-but-curious server, who observes the updates from target users participating in FL and infers their location using a deep leakage from gradients (DLG) type of attack, originally developed to reconstruct training data of DNN image classifiers. We make the key observation that a DLG attack, applied to our setting, infers the average location of a batch of local data, and can thus be used to reconstruct the target users' trajectory at a coarse granularity. We show that a moderate level of privacy protection is already offered by the averaging of gradients, which is inherent to Federated Averaging. Furthermore, we propose an algorithm that devices can apply locally to curate the batches used for local updates, so as to effectively protect their location privacy without hurting utility. Finally, we show that the effect of multiple users participating in FL depends on the similarity of their trajectories. To the best of our knowledge, this is the first study of DLG attacks in the setting of FL from crowdsourced spatio-temporal data.