 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
T6D-Direct: Transformers for Multi-Object 6D Pose Direct Regression
Sep 22, 2021

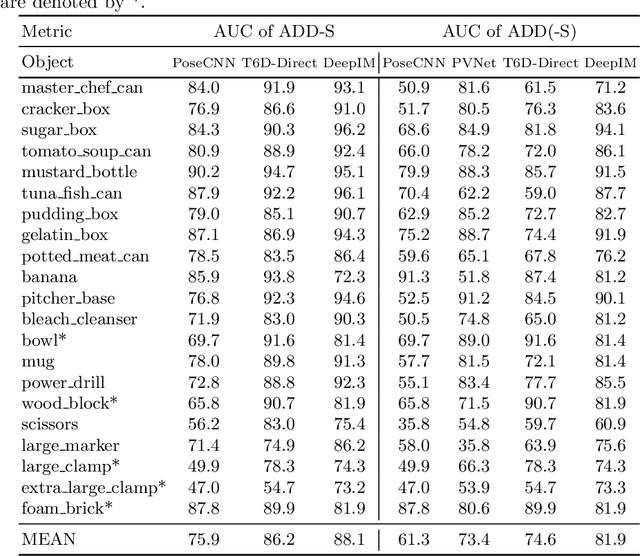
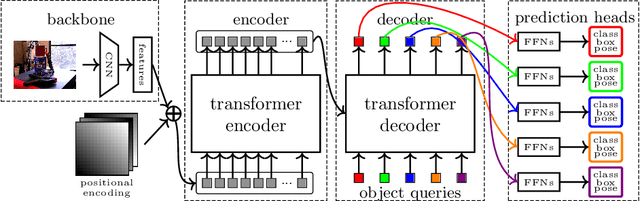
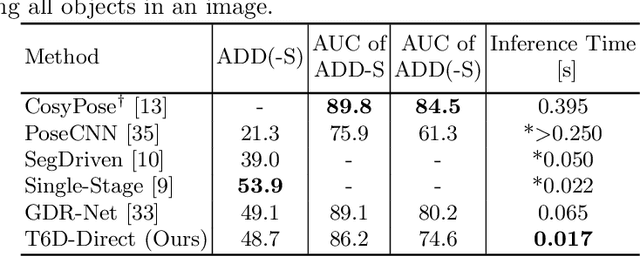
6D pose estimation is the task of predicting the translation and orientation of objects in a given input image, which is a crucial prerequisite for many robotics and augmented reality applications. Lately, the Transformer Network architecture, equipped with a multi-head self-attention mechanism, is emerging to achieve state-of-the-art results in many computer vision tasks. DETR, a Transformer-based model, formulated object detection as a set prediction problem and achieved impressive results without standard components like region of interest pooling, non-maximal suppression, and bounding box proposals. In this work, we propose T6D-Direct, a real-time single-stage direct method with a transformer-based architecture built on DETR to perform 6D multi-object pose direct estimation. We evaluate the performance of our method on the YCB-Video dataset. Our method achieves the fastest inference time, and the pose estimation accuracy is comparable to state-of-the-art methods.
Self-Attention for Raw Optical Satellite Time Series Classification
Oct 23, 2019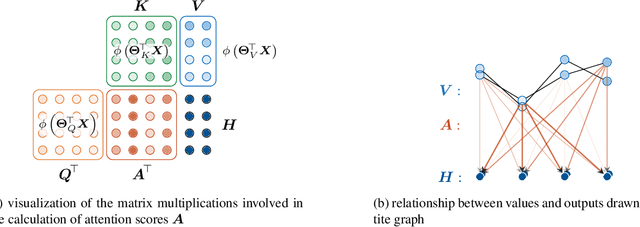
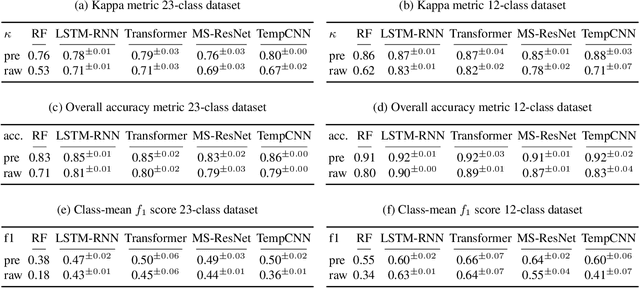
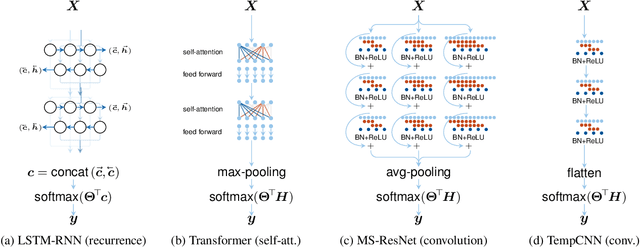
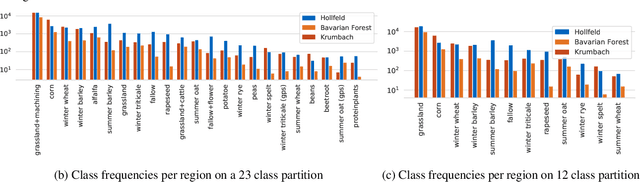
Deep learning methods have received increasing interest by the remote sensing community for multi-temporal land cover classification in recent years. Convolutional Neural networks that elementwise compare a time series with learned kernels, and recurrent neural networks that sequentially process temporal data have dominated the state-of-the-art in the classification of vegetation from satellite time series. Self-attention allows a neural network to selectively extract features from specific times in the input sequence thus suppressing non-classification relevant information. Today, self-attention based neural networks dominate the state-of-the-art in natural language processing but are hardly explored and tested in the remote sensing context. In this work, we embed self-attention in the canon of deep learning mechanisms for satellite time series classification for vegetation modeling and crop type identification. We compare it quantitatively to convolution, and recurrence and test four models that each exclusively relies on one of these mechanisms. The models are trained to identify the type of vegetation on crop parcels using raw and preprocessed Sentinel 2 time series over one entire year. To obtain an objective measure we find the best possible performance for each of the models by a large-scale hyperparameter search with more than 2400 validation runs. Beyond the quantitative comparison, we qualitatively analyze the models by an easy-to-implement, but yet effective feature importance analysis based on gradient back-propagation that exploits the differentiable nature of deep learning models. Finally, we look into the self-attention transformer model and visualize attention scores as bipartite graphs in the context of the input time series and a low-dimensional representation of internal hidden states using t-distributed stochastic neighborhood embedding (t-SNE).
Dynamic Ranking with the BTL Model: A Nearest Neighbor based Rank Centrality Method
Sep 28, 2021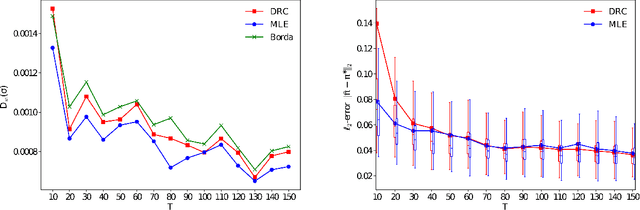
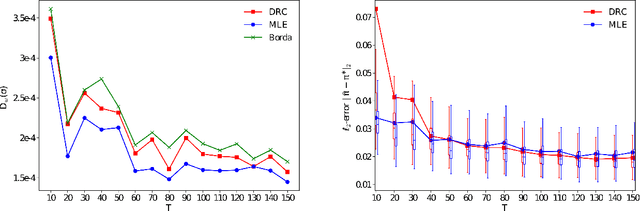
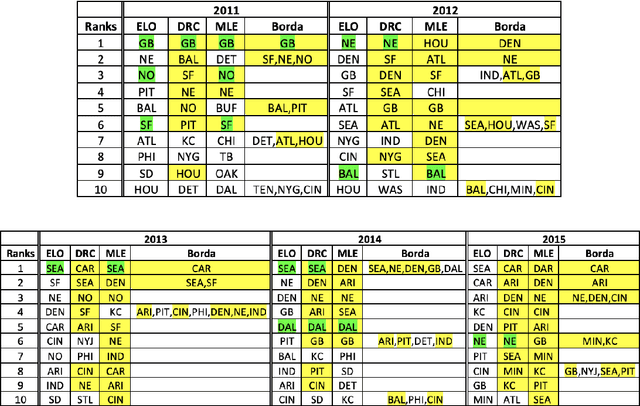
Many applications such as recommendation systems or sports tournaments involve pairwise comparisons within a collection of $n$ items, the goal being to aggregate the binary outcomes of the comparisons in order to recover the latent strength and/or global ranking of the items. In recent years, this problem has received significant interest from a theoretical perspective with a number of methods being proposed, along with associated statistical guarantees under the assumption of a suitable generative model. While these results typically collect the pairwise comparisons as one comparison graph $G$, however in many applications - such as the outcomes of soccer matches during a tournament - the nature of pairwise outcomes can evolve with time. Theoretical results for such a dynamic setting are relatively limited compared to the aforementioned static setting. We study in this paper an extension of the classic BTL (Bradley-Terry-Luce) model for the static setting to our dynamic setup under the assumption that the probabilities of the pairwise outcomes evolve smoothly over the time domain $[0,1]$. Given a sequence of comparison graphs $(G_{t'})_{t' \in \mathcal{T}}$ on a regular grid $\mathcal{T} \subset [0,1]$, we aim at recovering the latent strengths of the items $w_t \in \mathbb{R}^n$ at any time $t \in [0,1]$. To this end, we adapt the Rank Centrality method - a popular spectral approach for ranking in the static case - by locally averaging the available data on a suitable neighborhood of $t$. When $(G_{t'})_{t' \in \mathcal{T}}$ is a sequence of Erd\"os-Renyi graphs, we provide non-asymptotic $\ell_2$ and $\ell_{\infty}$ error bounds for estimating $w_t^*$ which in particular establishes the consistency of this method in terms of $n$, and the grid size $\lvert\mathcal{T}\rvert$. We also complement our theoretical analysis with experiments on real and synthetic data.
Intra-Domain Task-Adaptive Transfer Learning to Determine Acute Ischemic Stroke Onset Time
Nov 05, 2020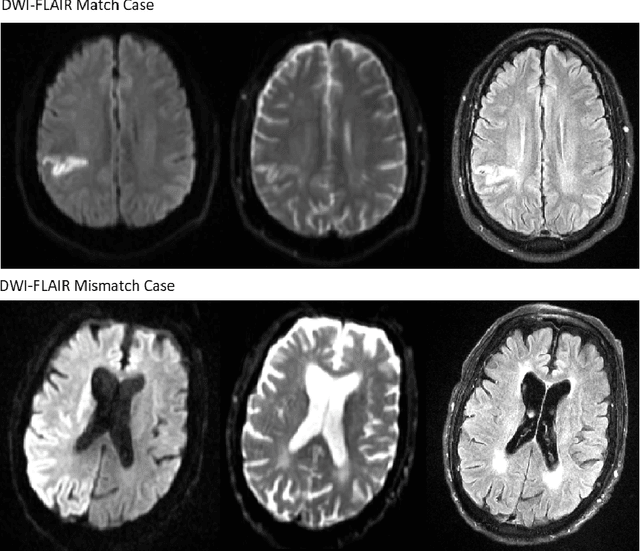
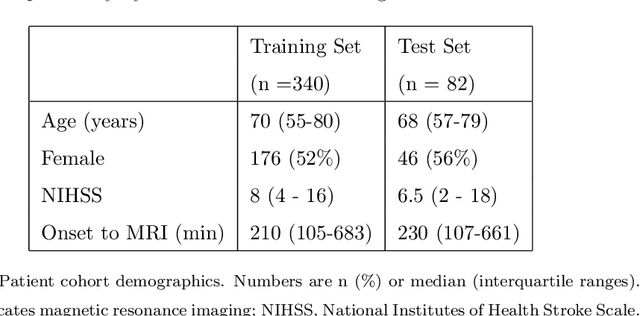
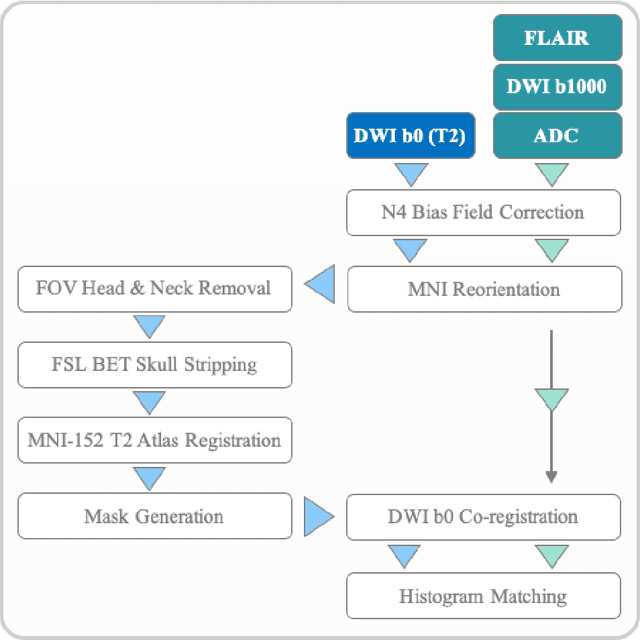
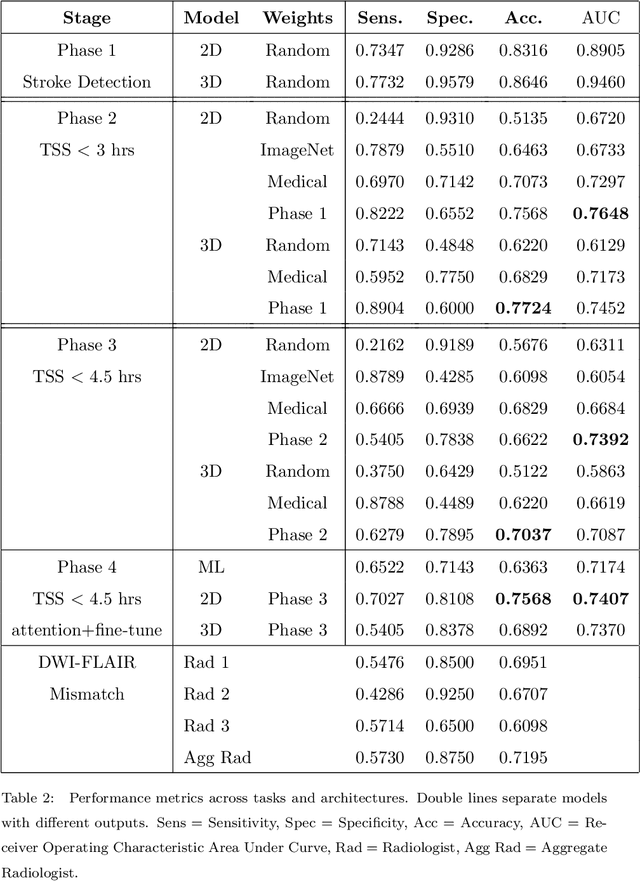
Treatment of acute ischemic strokes (AIS) is largely contingent upon the time since stroke onset (TSS). However, TSS may not be readily available in up to 25% of patients with unwitnessed AIS. Current clinical guidelines for patients with unknown TSS recommend the use of MRI to determine eligibility for thrombolysis, but radiology assessments have high inter-reader variability. In this work, we present deep learning models that leverage MRI diffusion series to classify TSS based on clinically validated thresholds. We propose an intra-domain task-adaptive transfer learning method, which involves training a model on an easier clinical task (stroke detection) and then refining the model with different binary thresholds of TSS. We apply this approach to both 2D and 3D CNN architectures with our top model achieving an ROC-AUC value of 0.74, with a sensitivity of 0.70 and a specificity of 0.81 for classifying TSS < 4.5 hours. Our pretrained models achieve better classification metrics than the models trained from scratch, and these metrics exceed those of previously published models applied to our dataset. Furthermore, our pipeline accommodates a more inclusive patient cohort than previous work, as we did not exclude imaging studies based on clinical, demographic, or image processing criteria. When applied to this broad spectrum of patients, our deep learning model achieves an overall accuracy of 75.78% when classifying TSS < 4.5 hours, carrying potential therapeutic implications for patients with unknown TSS.
Drug Similarity and Link Prediction Using Graph Embeddings on Medical Knowledge Graphs
Oct 29, 2021
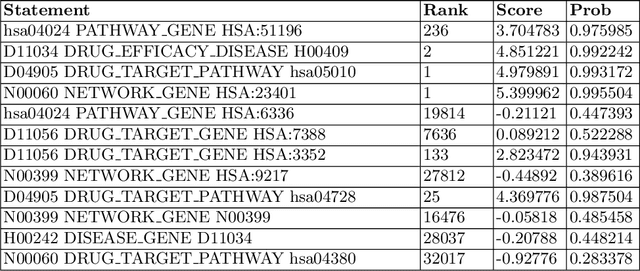
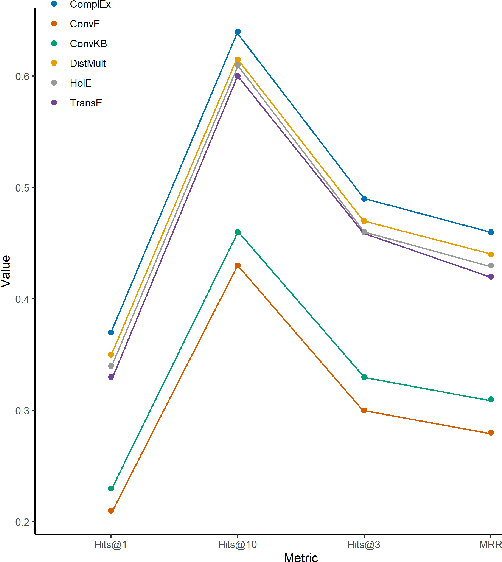
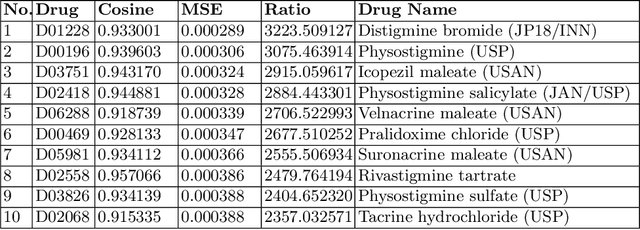
The paper utilizes the graph embeddings generated for entities of a large biomedical database to perform link prediction to capture various new relationships among different entities. A novel node similarity measure is proposed that utilizes the graph embeddings and link prediction scores to find similarity scores among various drugs which can be used by the medical experts to recommend alternative drugs to avoid side effects from original one. Utilizing machine learning on knowledge graph for drug similarity and recommendation will be less costly and less time consuming with higher scalability as compared to traditional biomedical methods due to the dependency on costly medical equipment and experts of the latter ones.
$\ell_\infty$-Robustness and Beyond: Unleashing Efficient Adversarial Training
Dec 01, 2021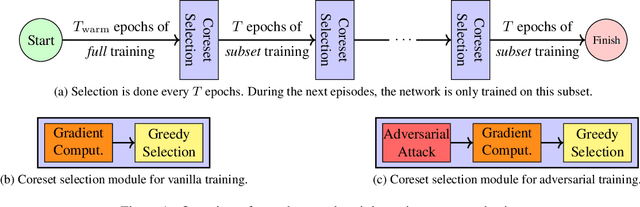

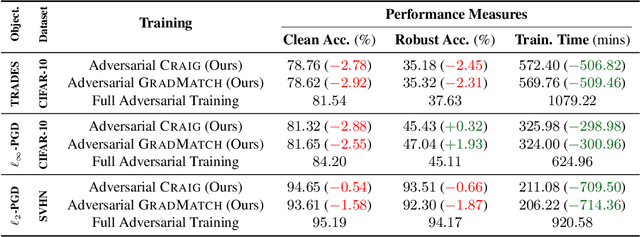
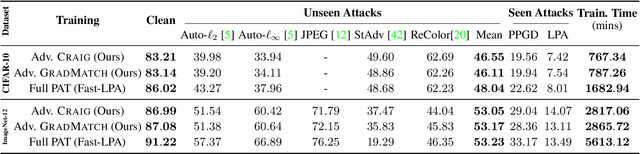
Neural networks are vulnerable to adversarial attacks: adding well-crafted, imperceptible perturbations to their input can modify their output. Adversarial training is one of the most effective approaches in training robust models against such attacks. However, it is much slower than vanilla training of neural networks since it needs to construct adversarial examples for the entire training data at every iteration, which has hampered its effectiveness. Recently, Fast Adversarial Training was proposed that can obtain robust models efficiently. However, the reasons behind its success are not fully understood, and more importantly, it can only train robust models for $\ell_\infty$-bounded attacks as it uses FGSM during training. In this paper, by leveraging the theory of coreset selection we show how selecting a small subset of training data provides a more principled approach towards reducing the time complexity of robust training. Unlike existing methods, our approach can be adapted to a wide variety of training objectives, including TRADES, $\ell_p$-PGD, and Perceptual Adversarial Training. Our experimental results indicate that our approach speeds up adversarial training by 2-3 times, while experiencing a small reduction in the clean and robust accuracy.
Tunable Image Quality Control of 3-D Ultrasound using Switchable CycleGAN
Dec 06, 2021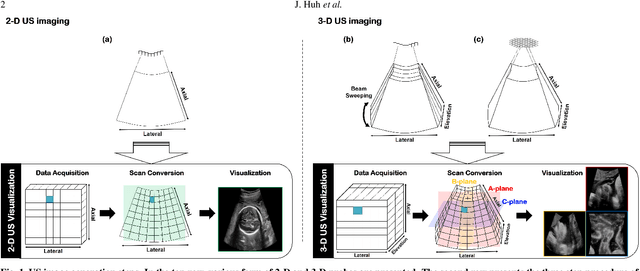
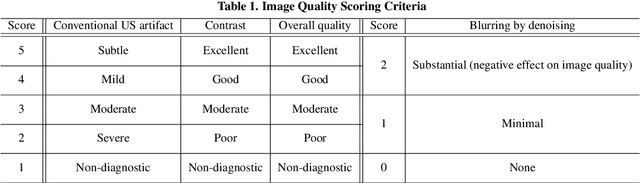
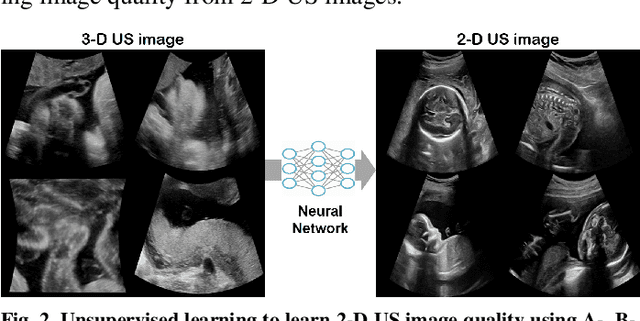
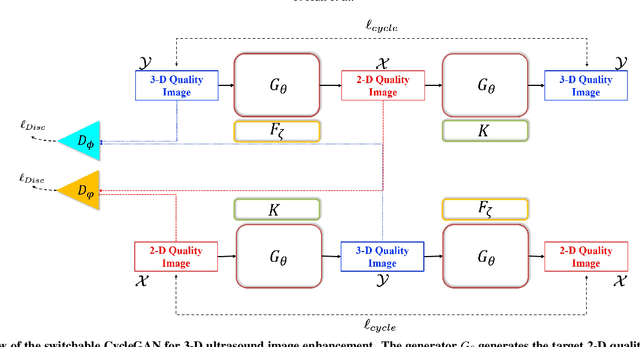
In contrast to 2-D ultrasound (US) for uniaxial plane imaging, a 3-D US imaging system can visualize a volume along three axial planes. This allows for a full view of the anatomy, which is useful for gynecological (GYN) and obstetrical (OB) applications. Unfortunately, the 3-D US has an inherent limitation in resolution compared to the 2-D US. In the case of 3-D US with a 3-D mechanical probe, for example, the image quality is comparable along the beam direction, but significant deterioration in image quality is often observed in the other two axial image planes. To address this, here we propose a novel unsupervised deep learning approach to improve 3-D US image quality. In particular, using {\em unmatched} high-quality 2-D US images as a reference, we trained a recently proposed switchable CycleGAN architecture so that every mapping plane in 3-D US can learn the image quality of 2-D US images. Thanks to the switchable architecture, our network can also provide real-time control of image enhancement level based on user preference, which is ideal for a user-centric scanner setup. Extensive experiments with clinical evaluation confirm that our method offers significantly improved image quality as well user-friendly flexibility.
A Sensitivity Matrix Approach Using Two-Stage Optimization for Voltage Regulation of LV Networks with High PV Penetration
Aug 23, 2021
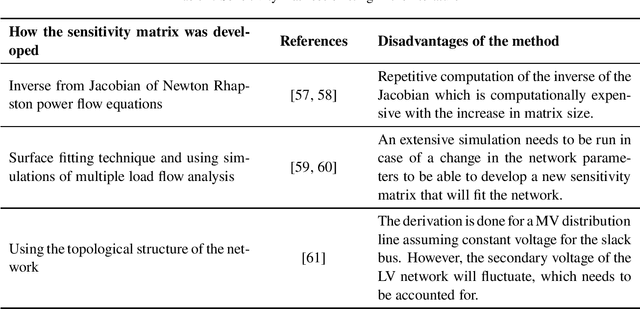
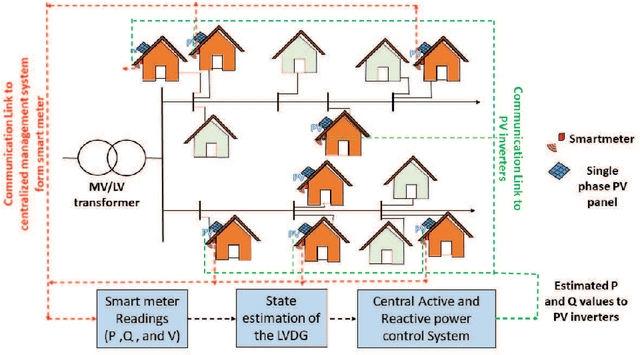

The occurrence of voltage violations are a major deterrent for absorbing more roof-top solar power to smart Low Voltage Distribution Grids (LVDG). Recent studies have focused on decentralized control methods to solve this problem due to the high computational time in performing load flows in centralized control techniques. To address this issue a novel sensitivity matrix is developed to estimate voltages of the network by replacing load flow simulations. In this paper, a Centralized Active, Reactive Power Management System (CARPMS) is proposed to optimally utilize the reactive power capability of smart photo-voltaic inverters with minimal active power curtailment to mitigate the voltage violation problem. The developed sensitivity matrix is able to reduce the time consumed by 48% compared to load flow simulations, enabling near real-time control optimization. Given the large solution space of power systems, a novel two-stage optimization is proposed, where the solution space is narrowed down by a Feasible Region Search (FRS) step, followed by Particle Swarm Optimization (PSO). The performance of the proposed methodology is analyzed in comparison to the load flow method to demonstrate the accuracy and the capability of the optimization algorithm to mitigate voltage violations in near real-time. The deviation of mean voltages of the proposed methodology from load flow method was; 6.5*10^-3 p.u for reactive power control using Q-injection, 1.02*10^-2 p.u for reactive power control using Q-absorption, and 0 p.u for active power curtailment case.
A Daily Tourism Demand Prediction Framework Based on Multi-head Attention CNN: The Case of The Foreign Entrant in South Korea
Dec 01, 2021
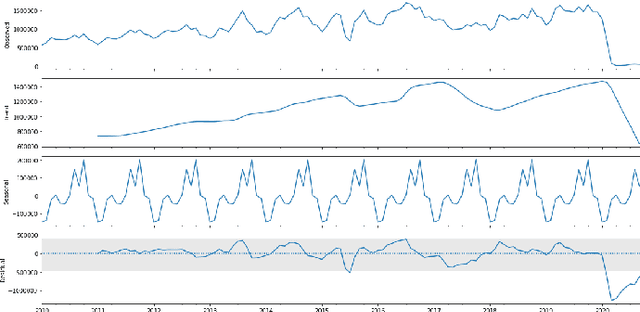
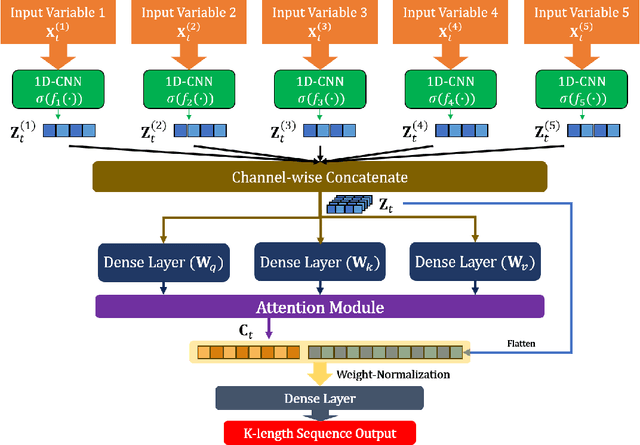
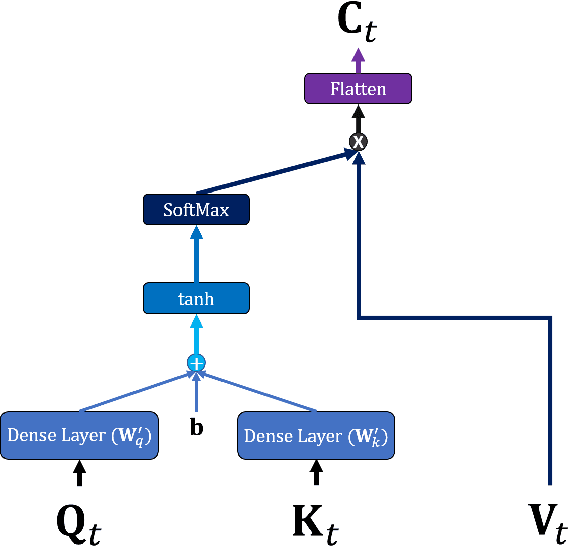
Developing an accurate tourism forecasting model is essential for making desirable policy decisions for tourism management. Early studies on tourism management focus on discovering external factors related to tourism demand. Recent studies utilize deep learning in demand forecasting along with these external factors. They mainly use recursive neural network models such as LSTM and RNN for their frameworks. However, these models are not suitable for use in forecasting tourism demand. This is because tourism demand is strongly affected by changes in various external factors, and recursive neural network models have limitations in handling these multivariate inputs. We propose a multi-head attention CNN model (MHAC) for addressing these limitations. The MHAC uses 1D-convolutional neural network to analyze temporal patterns and the attention mechanism to reflect correlations between input variables. This model makes it possible to extract spatiotemporal characteristics from time-series data of various variables. We apply our forecasting framework to predict inbound tourist changes in South Korea by considering external factors such as politics, disease, season, and attraction of Korean culture. The performance results of extensive experiments show that our method outperforms other deep-learning-based prediction frameworks in South Korea tourism forecasting.
Light-weight Deformable Registration using Adversarial Learning with Distilling Knowledge
Oct 04, 2021



Deformable registration is a crucial step in many medical procedures such as image-guided surgery and radiation therapy. Most recent learning-based methods focus on improving the accuracy by optimizing the non-linear spatial correspondence between the input images. Therefore, these methods are computationally expensive and require modern graphic cards for real-time deployment. In this paper, we introduce a new Light-weight Deformable Registration network that significantly reduces the computational cost while achieving competitive accuracy. In particular, we propose a new adversarial learning with distilling knowledge algorithm that successfully leverages meaningful information from the effective but expensive teacher network to the student network. We design the student network such as it is light-weight and well suitable for deployment on a typical CPU. The extensively experimental results on different public datasets show that our proposed method achieves state-of-the-art accuracy while significantly faster than recent methods. We further show that the use of our adversarial learning algorithm is essential for a time-efficiency deformable registration method. Finally, our source code and trained models are available at: https://github.com/aioz-ai/LDR_ALDK.