 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Assessment of Data Consistency through Cascades of Independently Recurrent Inference Machines for fast and robust accelerated MRI reconstruction
Nov 30, 2021
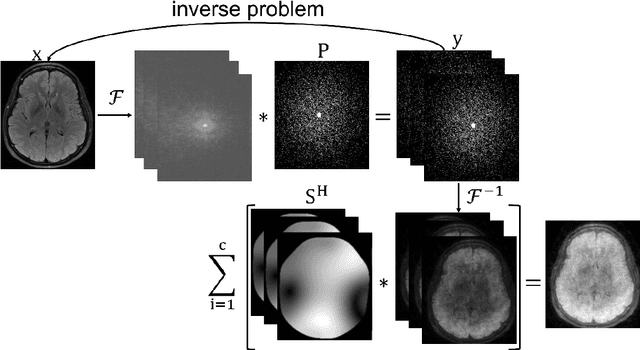
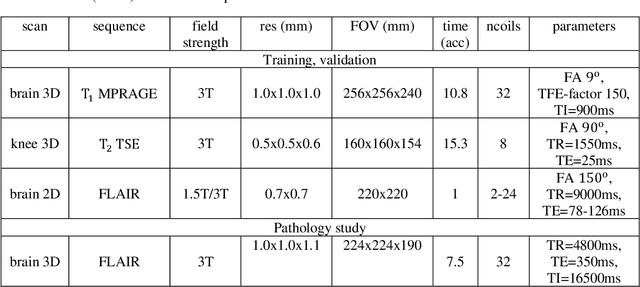
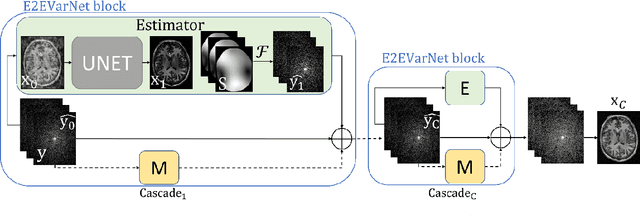
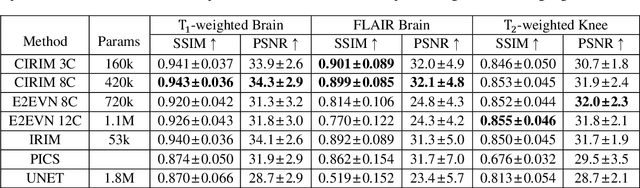
Interpretability and robustness are imperative for integrating Machine Learning methods for accelerated Magnetic Resonance Imaging (MRI) reconstruction in clinical applications. Doing so would allow fast high-quality imaging of anatomy and pathology. Data Consistency (DC) is crucial for generalization in multi-modal data and robustness in detecting pathology. This work proposes the Cascades of Independently Recurrent Inference Machines (CIRIM) to assess DC through unrolled optimization, implicitly by gradient descent and explicitly by a designed term. We perform extensive comparison of the CIRIM to other unrolled optimization methods, being the End-to-End Variational Network (E2EVN) and the RIM, and to the UNet and Compressed Sensing (CS). Evaluation is done in two stages. Firstly, learning on multiple trained MRI modalities is assessed, i.e., brain data with ${T_1}$-weighting and FLAIR contrast, and ${T_2}$-weighted knee data. Secondly, robustness is tested on reconstructing pathology through white matter lesions in 3D FLAIR MRI data of relapsing remitting Multiple Sclerosis (MS) patients. Results show that the CIRIM performs best when implicitly enforcing DC, while the E2EVN requires explicitly formulated DC. The CIRIM shows the highest lesion contrast resolution in reconstructing the clinical MS data. Performance improves by approximately 11% compared to CS, while the reconstruction time is twenty times reduced.
A convolutional neural-network model of human cochlear mechanics and filter tuning for real-time applications
Apr 30, 2020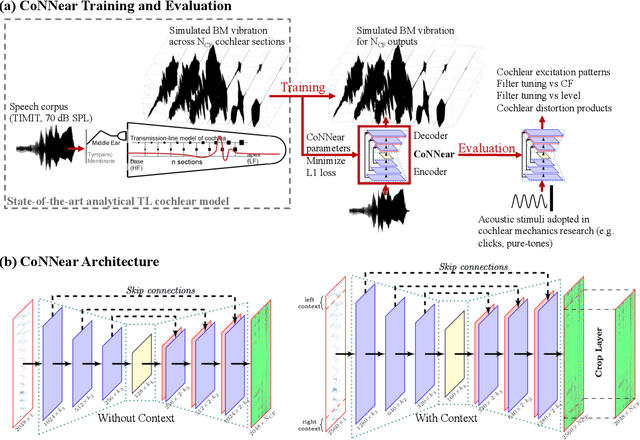
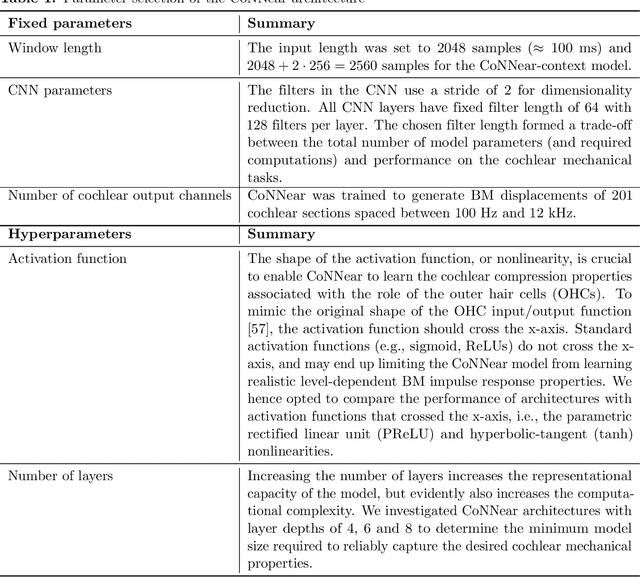
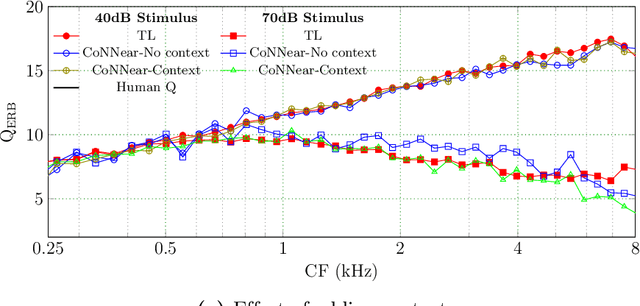

Auditory models are commonly used as feature extractors for automatic speech recognition systems or as front-ends for robotics, machine-hearing and hearing-aid applications. While over the years, auditory models have progressed to capture the biophysical and nonlinear properties of human hearing in great detail, these biophysical models are slow to compute and consequently not used in real-time applications. To enable an uptake, we present a hybrid approach where convolutional neural networks are combined with computational neuroscience to yield a real-time end-to-end model for human cochlear mechanics and level-dependent cochlear filter tuning (CoNNear). The CoNNear model was trained on acoustic speech material, but its performance and applicability evaluated using (unseen) sound stimuli common in cochlear mechanics research. The CoNNear model accurately simulates human frequency selectivity and its dependence on sound intensity, which is essential for our hallmark robust speech intelligibility performance, even at negative speech-to-background noise ratios. Because its architecture is based on real-time, parallel and differentiatable computations, the CoNNear model has the power to leverage real-time auditory applications towards human performance and can inspire the next generation of speech recognition, robotics and hearing-aid systems.
A General Optimization Framework for Dynamic Time Warping
May 31, 2019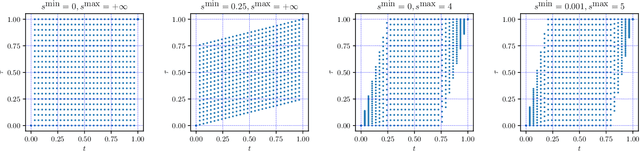
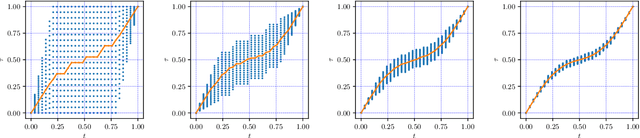
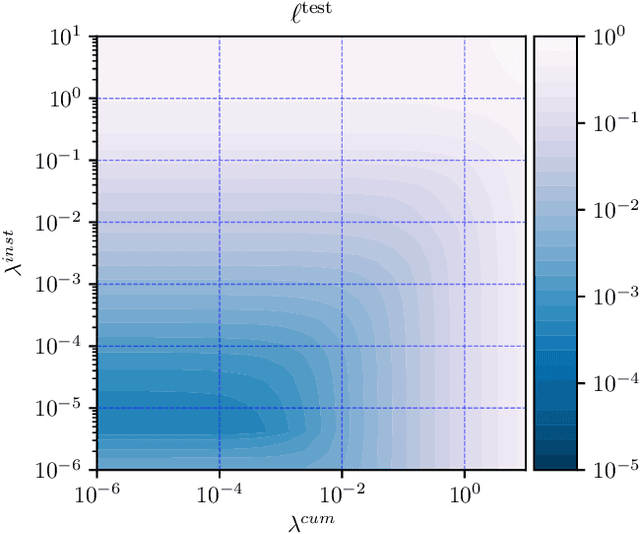
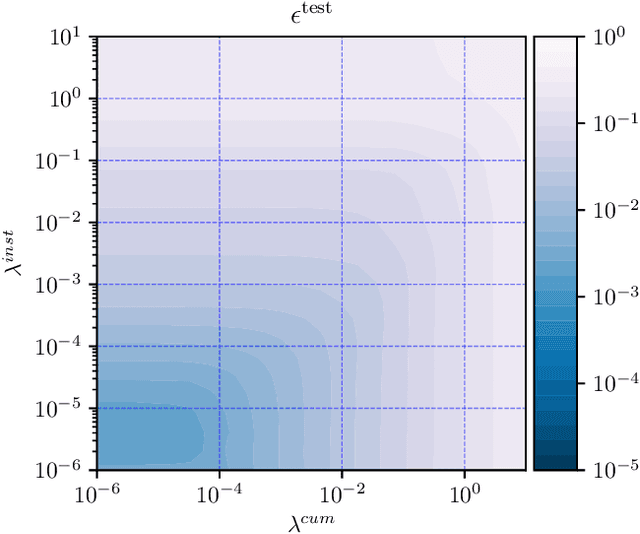
The goal of dynamic time warping is to transform or warp time in order to approximately align two signals together. We pose the choice of warping function as an optimization problem with several terms in the objective. The first term measures the misalignment of the time-warped signals. Two additional regularization terms penalize the cumulative warping and the instantaneous rate of time warping; constraints on the warping can be imposed by assigning the value +inf to the regularization terms. Different choices of the three objective terms yield different time warping functions that trade off signal fit or alignment and properties of the warping function. The optimization problem we formulate is a classical optimal control problem, with initial and terminal constraints, and a state dimension of one. We describe an effective general method that minimizes the objective by discretizing the values of the original and warped time, and using standard dynamic programming to compute the (globally) optimal warping function with the discretized values. Iterated refinement of this scheme yields a high accuracy warping function in just a few iterations. Our method is implemented as an open source Python package GDTW.
Large-Scale Video Analytics through Object-Level Consolidation
Nov 30, 2021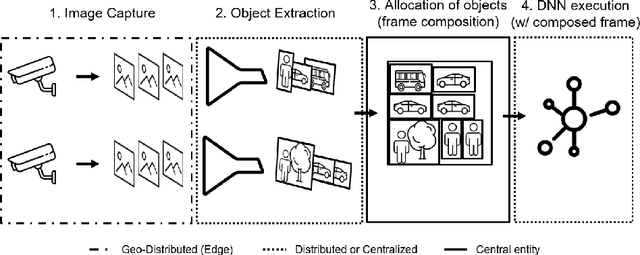
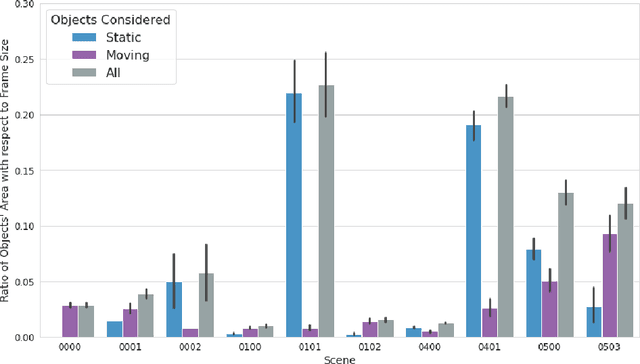
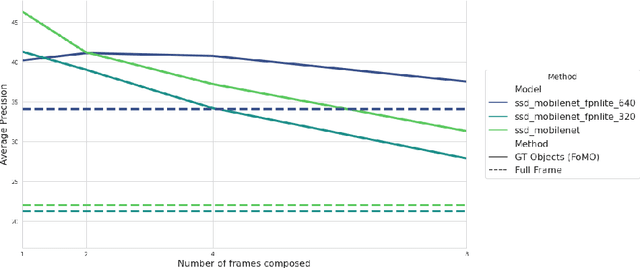
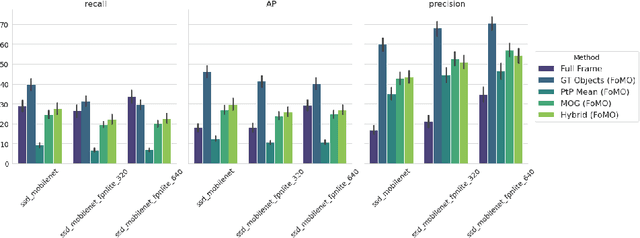
As the number of installed cameras grows, so do the compute resources required to process and analyze all the images captured by these cameras. Video analytics enables new use cases, such as smart cities or autonomous driving. At the same time, it urges service providers to install additional compute resources to cope with the demand while the strict latency requirements push compute towards the end of the network, forming a geographically distributed and heterogeneous set of compute locations, shared and resource-constrained. Such landscape (shared and distributed locations) forces us to design new techniques that can optimize and distribute work among all available locations and, ideally, make compute requirements grow sublinearly with respect to the number of cameras installed. In this paper, we present FoMO (Focus on Moving Objects). This method effectively optimizes multi-camera deployments by preprocessing images for scenes, filtering the empty regions out, and composing regions of interest from multiple cameras into a single image that serves as input for a pre-trained object detection model. Results show that overall system performance can be increased by 8x while accuracy improves 40% as a by-product of the methodology, all using an off-the-shelf pre-trained model with no additional training or fine-tuning.
Distinguishing Natural and Computer-Generated Images using Multi-Colorspace fused EfficientNet
Oct 18, 2021
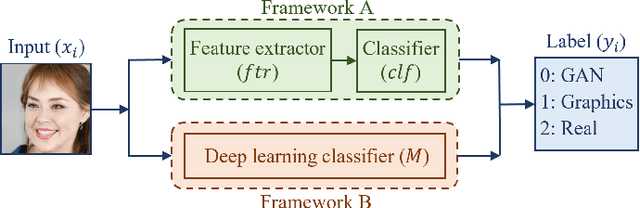
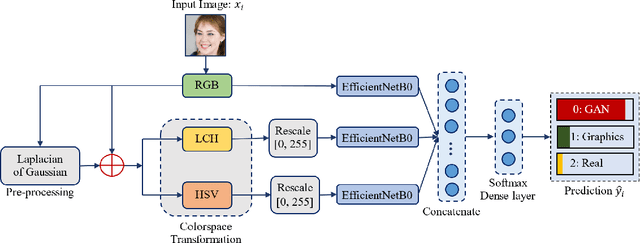
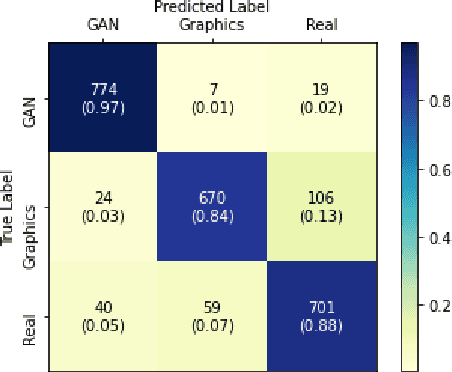
The problem of distinguishing natural images from photo-realistic computer-generated ones either addresses natural images versus computer graphics or natural images versus GAN images, at a time. But in a real-world image forensic scenario, it is highly essential to consider all categories of image generation, since in most cases image generation is unknown. We, for the first time, to our best knowledge, approach the problem of distinguishing natural images from photo-realistic computer-generated images as a three-class classification task classifying natural, computer graphics, and GAN images. For the task, we propose a Multi-Colorspace fused EfficientNet model by parallelly fusing three EfficientNet networks that follow transfer learning methodology where each network operates in different colorspaces, RGB, LCH, and HSV, chosen after analyzing the efficacy of various colorspace transformations in this image forensics problem. Our model outperforms the baselines in terms of accuracy, robustness towards post-processing, and generalizability towards other datasets. We conduct psychophysics experiments to understand how accurately humans can distinguish natural, computer graphics, and GAN images where we could observe that humans find difficulty in classifying these images, particularly the computer-generated images, indicating the necessity of computational algorithms for the task. We also analyze the behavior of our model through visual explanations to understand salient regions that contribute to the model's decision making and compare with manual explanations provided by human participants in the form of region markings, where we could observe similarities in both the explanations indicating the powerful nature of our model to take the decisions meaningfully.
Deep Learning of Transferable MIMO Channel Modes for 6G V2X Communications
Aug 31, 2021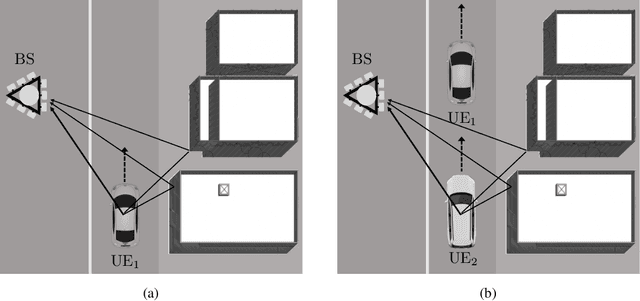
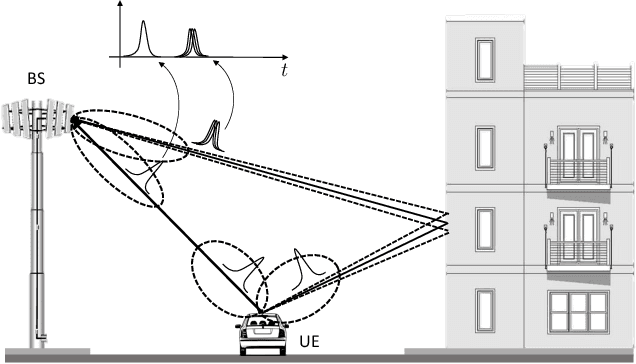
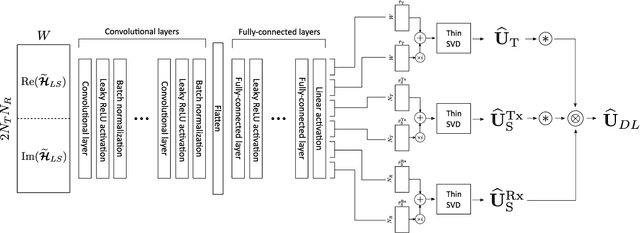
In the emerging high mobility Vehicle-to-Everything (V2X) communications using millimeter Wave (mmWave) and sub-THz, Multiple-Input Multiple-Output (MIMO) channel estimation is an extremely challenging task. At mmWaves/sub-THz frequencies, MIMO channels exhibit few leading paths in the space-time domain (i.e., directions or arrival/departure and delays). Algebraic Low-rank (LR) channel estimation exploits space-time channel sparsity through the computation of position-dependent MIMO channel eigenmodes leveraging recurrent training vehicle passages in the coverage cell. LR requires vehicles' geographical positions and tens to hundreds of training vehicles' passages for each position, leading to significant complexity and control signalling overhead. Here we design a DL-based LR channel estimation method to infer MIMO channel eigenmodes in V2X urban settings, starting from a single LS channel estimate and without needing vehicle's position information. Numerical results show that the proposed method attains comparable Mean Squared Error (MSE) performance as the position-based LR. Moreover, we show that the proposed model can be trained on a reference scenario and be effectively transferred to urban contexts with different space-time channel features, providing comparable MSE performance without an explicit transfer learning procedure. This result eases the deployment in arbitrary dense urban scenarios.
Robust Object Detection with Multi-input Multi-output Faster R-CNN
Nov 25, 2021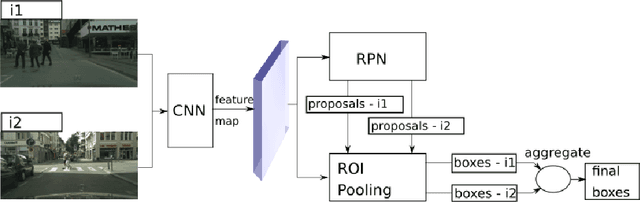
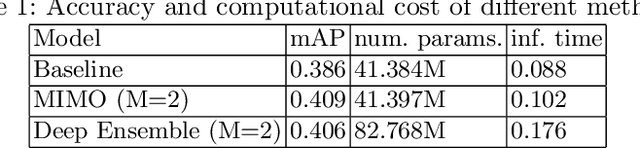
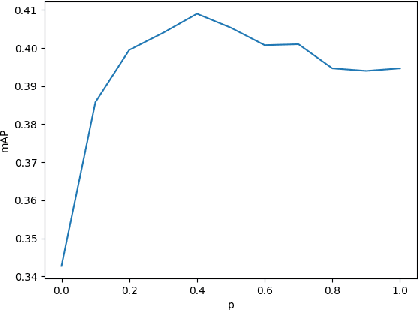
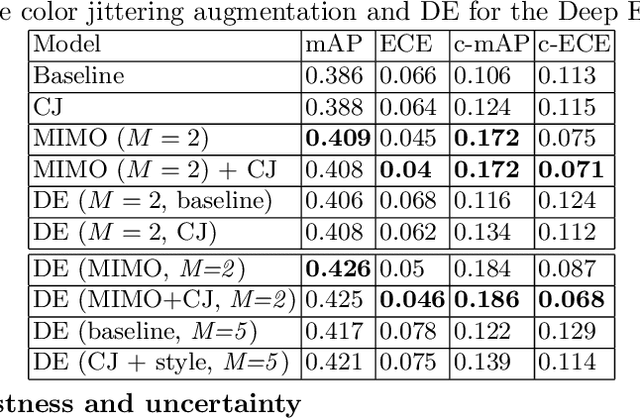
Recent years have seen impressive progress in visual recognition on many benchmarks, however, generalization to the real-world in out-of-distribution setting remains a significant challenge. A state-of-the-art method for robust visual recognition is model ensembling. however, recently it was shown that similarly competitive results could be achieved with a much smaller cost, by using multi-input multi-output architecture (MIMO). In this work, a generalization of the MIMO approach is applied to the task of object detection using the general-purpose Faster R-CNN model. It was shown that using the MIMO framework allows building strong feature representation and obtains very competitive accuracy when using just two input/output pairs. Furthermore, it adds just 0.5\% additional model parameters and increases the inference time by 15.9\% when compared to the standard Faster R-CNN. It also works comparably to, or outperforms the Deep Ensemble approach in terms of model accuracy, robustness to out-of-distribution setting, and uncertainty calibration when the same number of predictions is used. This work opens up avenues for applying the MIMO approach in other high-level tasks such as semantic segmentation and depth estimation.
Probabilistic 3D Multilabel Real-time Mapping for Multi-object Manipulation
Jan 16, 2020
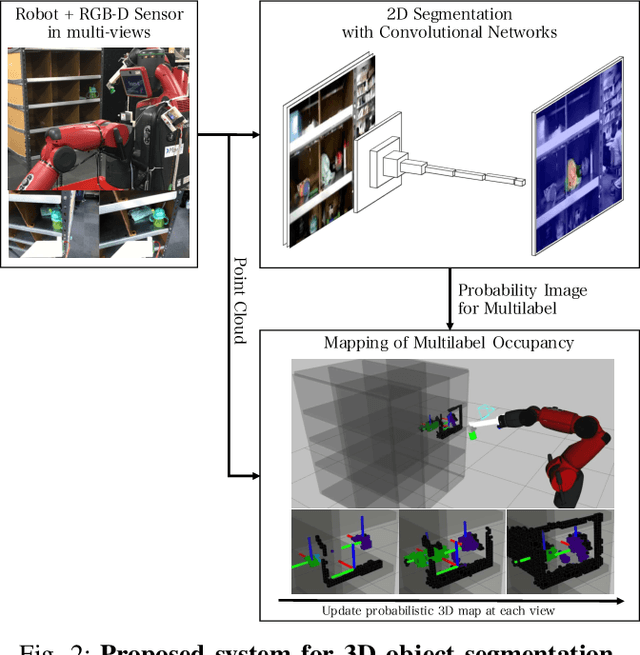


Probabilistic 3D map has been applied to object segmentation with multiple camera viewpoints, however, conventional methods lack of real-time efficiency and functionality of multilabel object mapping. In this paper, we propose a method to generate three-dimensional map with multilabel occupancy in real-time. Extending our previous work in which only target label occupancy is mapped, we achieve multilabel object segmentation in a single looking around action. We evaluate our method by testing segmentation accuracy with 39 different objects, and applying it to a manipulation task of multiple objects in the experiments. Our mapping-based method outperforms the conventional projection-based method by 40 - 96\% relative (12.6 mean $IU_{3d}$), and robot successfully recognizes (86.9\%) and manipulates multiple objects (60.7\%) in an environment with heavy occlusions.
MVLidarNet: Real-Time Multi-Class Scene Understanding for Autonomous Driving Using Multiple Views
Jun 09, 2020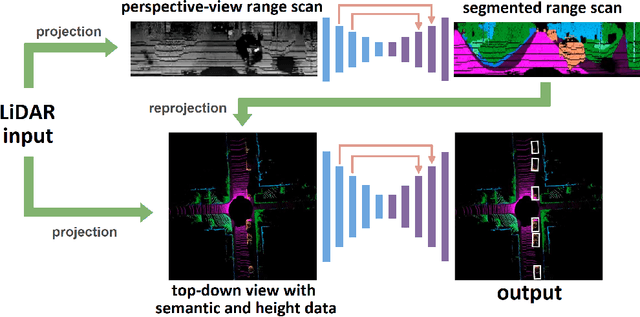
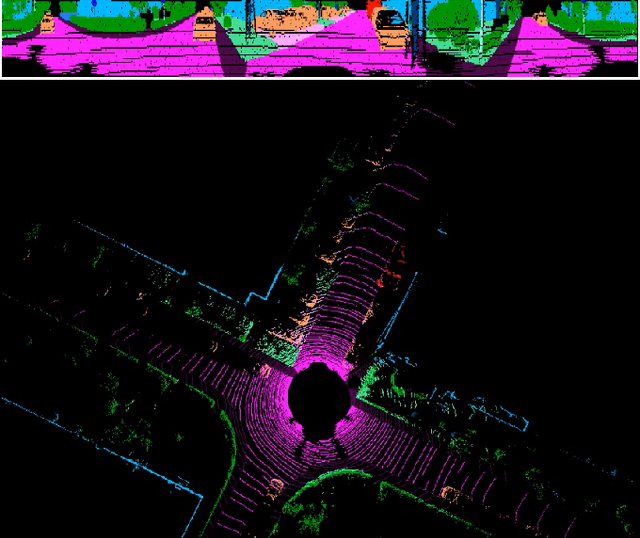


Autonomous driving requires the inference of actionable information such as detecting and classifying objects, and determining the drivable space. To this end, we present a two-stage deep neural network (MVLidarNet) for multi-class object detection and drivable segmentation using multiple views of a single LiDAR point cloud. The first stage processes the point cloud projected onto a perspective view in order to semantically segment the scene. The second stage then processes the point cloud (along with semantic labels from the first stage) projected onto a bird's eye view, to detect and classify objects. Both stages are simple encoder-decoders. We show that our multi-view, multi-stage, multi-class approach is able to detect and classify objects while simultaneously determining the drivable space using a single LiDAR scan as input, in challenging scenes with more than one hundred vehicles and pedestrians at a time. The system operates efficiently at 150 fps on an embedded GPU designed for a self-driving car, including a postprocessing step to maintain identities over time. We show results on both KITTI and a much larger internal dataset, thus demonstrating the method's ability to scale by an order of magnitude.
A study on Channel Popularity in Twitch
Nov 10, 2021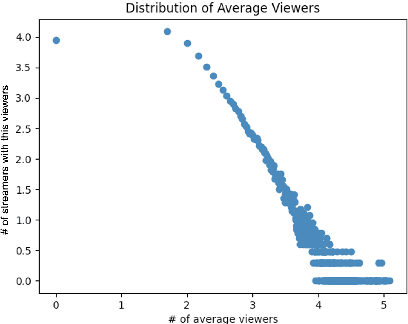

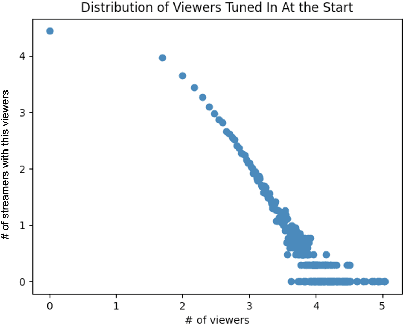

In the past few decades, there has been an increasing need for Internet users to host real time events online and to share their experiences with live, interactive audiences. Online streaming services like Twitch have attracted millions of users to stream and to spectate. There have been few studies about the prediction of streamers' popularity on Twitch. In this paper, we look at potential factors that can contribute to the popularity of streamers. Streamer data was collected through consistent tracking using Twitch's API during a 4 weeks period. Each user's streaming information such as the number of current viewers and followers, the genre of the stream etc., were collected. From the results, we found that the frequency of streaming sessions, the types of content and the length of the streams are major factors in determining how much viewers and subscribers streamers can gain during sessions.