 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Reinforcement Learning for Caching with Space-Time Popularity Dynamics
May 19, 2020
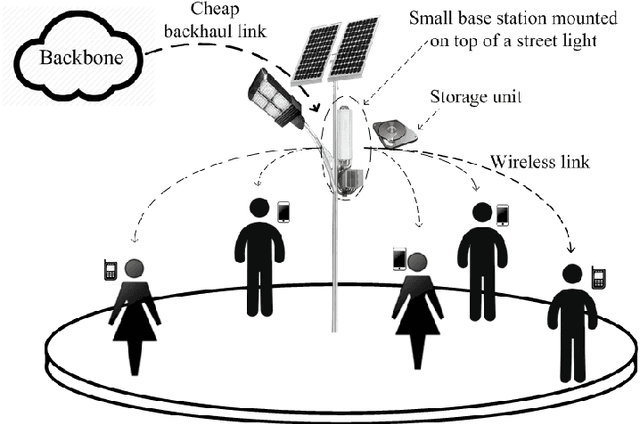
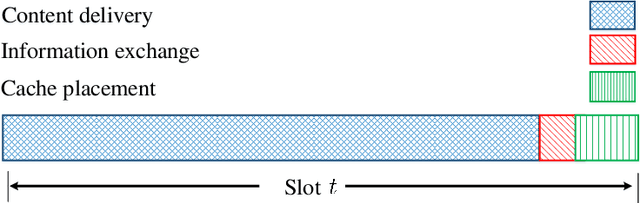
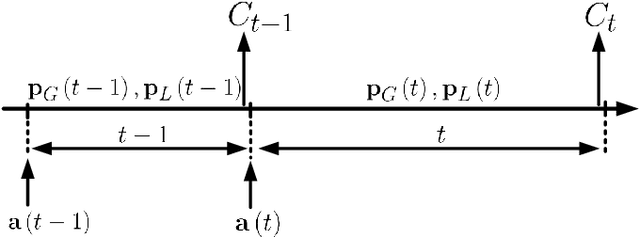
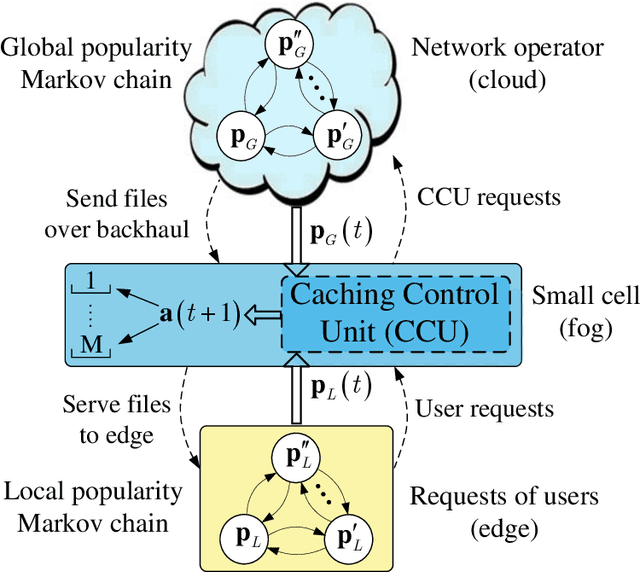
With the tremendous growth of data traffic over wired and wireless networks along with the increasing number of rich-media applications, caching is envisioned to play a critical role in next-generation networks. To intelligently prefetch and store contents, a cache node should be able to learn what and when to cache. Considering the geographical and temporal content popularity dynamics, the limited available storage at cache nodes, as well as the interactive in uence of caching decisions in networked caching settings, developing effective caching policies is practically challenging. In response to these challenges, this chapter presents a versatile reinforcement learning based approach for near-optimal caching policy design, in both single-node and network caching settings under dynamic space-time popularities. The herein presented policies are complemented using a set of numerical tests, which showcase the merits of the presented approach relative to several standard caching policies.
Learning to Solve Combinatorial Optimization Problems on Real-World Graphs in Linear Time
Jun 12, 2020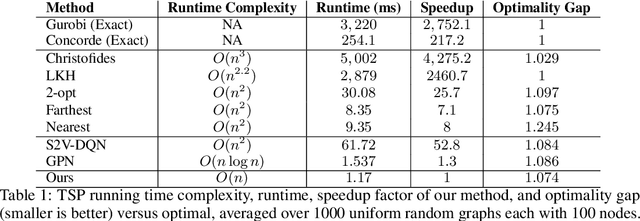
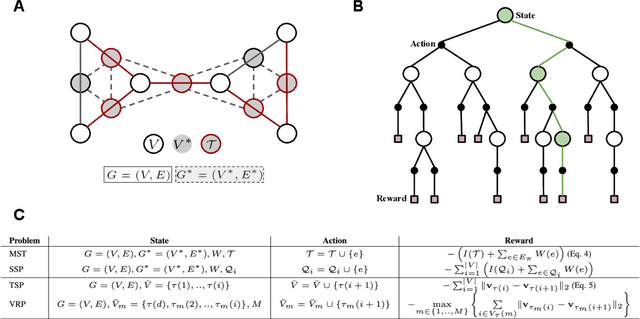
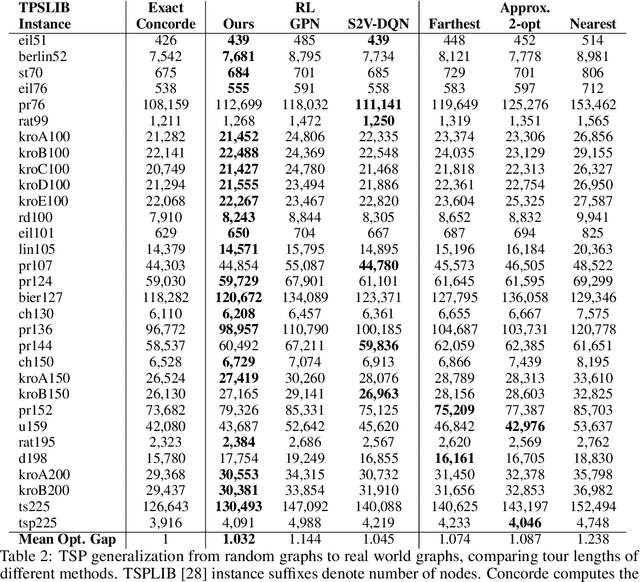
Combinatorial optimization algorithms for graph problems are usually designed afresh for each new problem with careful attention by an expert to the problem structure. In this work, we develop a new framework to solve any combinatorial optimization problem over graphs that can be formulated as a single player game defined by states, actions, and rewards, including minimum spanning tree, shortest paths, traveling salesman problem, and vehicle routing problem, without expert knowledge. Our method trains a graph neural network using reinforcement learning on an unlabeled training set of graphs. The trained network then outputs approximate solutions to new graph instances in linear running time. In contrast, previous approximation algorithms or heuristics tailored to NP-hard problems on graphs generally have at least quadratic running time. We demonstrate the applicability of our approach on both polynomial and NP-hard problems with optimality gaps close to 1, and show that our method is able to generalize well: (i) from training on small graphs to testing on large graphs; (ii) from training on random graphs of one type to testing on random graphs of another type; and (iii) from training on random graphs to running on real world graphs.
The MatrixX Solver For Argumentation Frameworks
Sep 29, 2021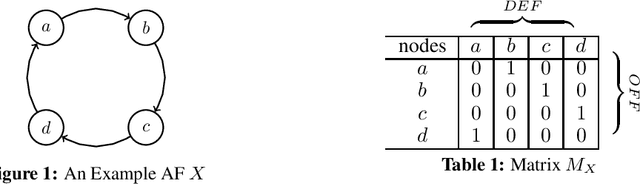


MatrixX is a solver for Abstract Argumentation Frameworks. Offensive and defensive properties of an Argumentation Framework are notated in a matrix style. Rows and columns of this matrix are systematically reduced by the solver. This procedure is implemented through the use of hash maps in order to accelerate calculation time. MatrixX works for stable and complete semantics and was designed for the ICCMA 2021 competition.
Open-Domain, Content-based, Multi-modal Fact-checking of Out-of-Context Images via Online Resources
Nov 30, 2021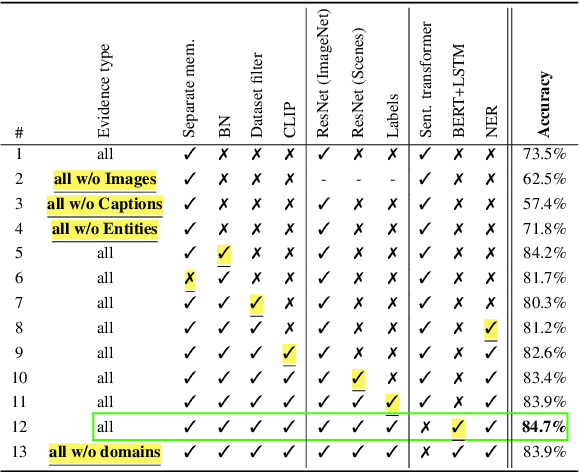
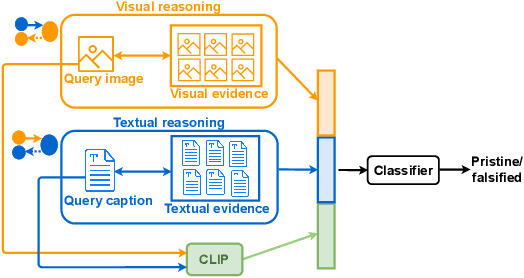
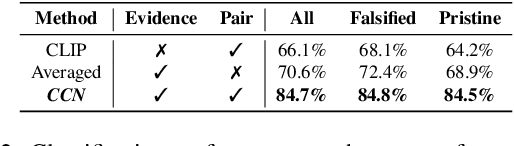
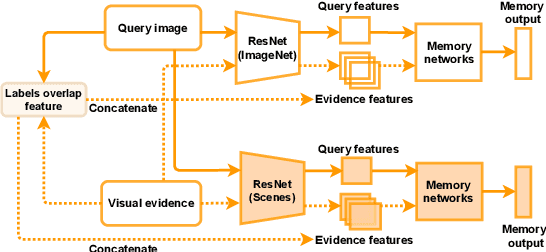
Misinformation is now a major problem due to its potential high risks to our core democratic and societal values and orders. Out-of-context misinformation is one of the easiest and effective ways used by adversaries to spread viral false stories. In this threat, a real image is re-purposed to support other narratives by misrepresenting its context and/or elements. The internet is being used as the go-to way to verify information using different sources and modalities. Our goal is an inspectable method that automates this time-consuming and reasoning-intensive process by fact-checking the image-caption pairing using Web evidence. To integrate evidence and cues from both modalities, we introduce the concept of 'multi-modal cycle-consistency check'; starting from the image/caption, we gather textual/visual evidence, which will be compared against the other paired caption/image, respectively. Moreover, we propose a novel architecture, Consistency-Checking Network (CCN), that mimics the layered human reasoning across the same and different modalities: the caption vs. textual evidence, the image vs. visual evidence, and the image vs. caption. Our work offers the first step and benchmark for open-domain, content-based, multi-modal fact-checking, and significantly outperforms previous baselines that did not leverage external evidence.
Black-Box Testing of Deep Neural Networks through Test Case Diversity
Dec 20, 2021

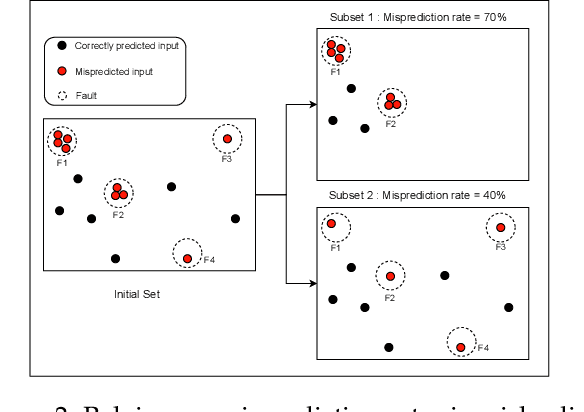

Deep Neural Networks (DNNs) have been extensively used in many areas including image processing, medical diagnostics, and autonomous driving. However, DNNs can exhibit erroneous behaviours that may lead to critical errors, especially when used in safety-critical systems. Inspired by testing techniques for traditional software systems, researchers have proposed neuron coverage criteria, as an analogy to source code coverage, to guide the testing of DNN models. Despite very active research on DNN coverage, several recent studies have questioned the usefulness of such criteria in guiding DNN testing. Further, from a practical standpoint, these criteria are white-box as they require access to the internals or training data of DNN models, which is in many contexts not feasible or convenient. In this paper, we investigate black-box input diversity metrics as an alternative to white-box coverage criteria. To this end, we first select and adapt three diversity metrics and study, in a controlled manner, their capacity to measure actual diversity in input sets. We then analyse their statistical association with fault detection using two datasets and three DNN models. We further compare diversity with state-of-the-art white-box coverage criteria. Our experiments show that relying on the diversity of image features embedded in test input sets is a more reliable indicator than coverage criteria to effectively guide the testing of DNNs. Indeed, we found that one of our selected black-box diversity metrics far outperforms existing coverage criteria in terms of fault-revealing capability and computational time. Results also confirm the suspicions that state-of-the-art coverage metrics are not adequate to guide the construction of test input sets to detect as many faults as possible with natural inputs.
HyperStyle: StyleGAN Inversion with HyperNetworks for Real Image Editing
Nov 30, 2021
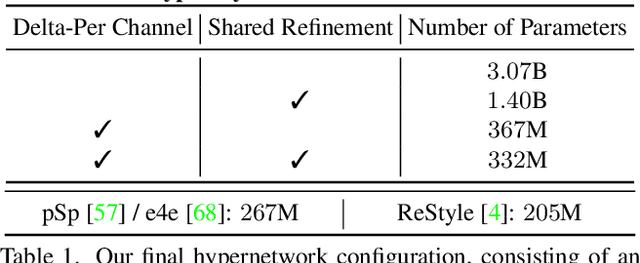
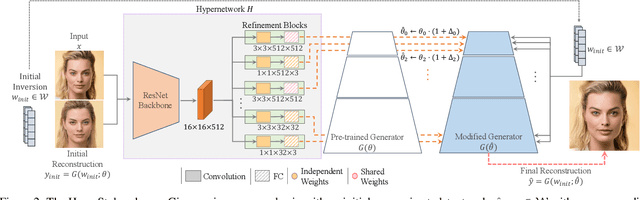
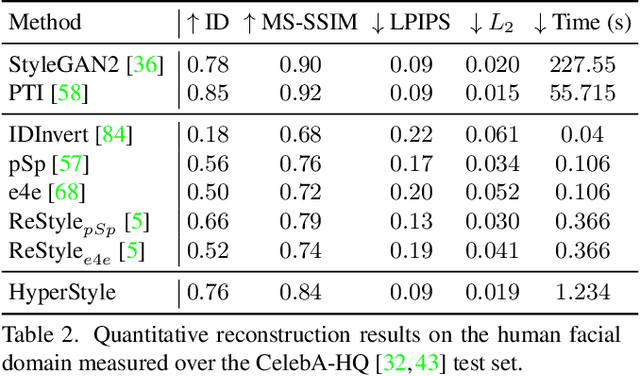
The inversion of real images into StyleGAN's latent space is a well-studied problem. Nevertheless, applying existing approaches to real-world scenarios remains an open challenge, due to an inherent trade-off between reconstruction and editability: latent space regions which can accurately represent real images typically suffer from degraded semantic control. Recent work proposes to mitigate this trade-off by fine-tuning the generator to add the target image to well-behaved, editable regions of the latent space. While promising, this fine-tuning scheme is impractical for prevalent use as it requires a lengthy training phase for each new image. In this work, we introduce this approach into the realm of encoder-based inversion. We propose HyperStyle, a hypernetwork that learns to modulate StyleGAN's weights to faithfully express a given image in editable regions of the latent space. A naive modulation approach would require training a hypernetwork with over three billion parameters. Through careful network design, we reduce this to be in line with existing encoders. HyperStyle yields reconstructions comparable to those of optimization techniques with the near real-time inference capabilities of encoders. Lastly, we demonstrate HyperStyle's effectiveness on several applications beyond the inversion task, including the editing of out-of-domain images which were never seen during training.
Text Gestalt: Stroke-Aware Scene Text Image Super-Resolution
Dec 13, 2021
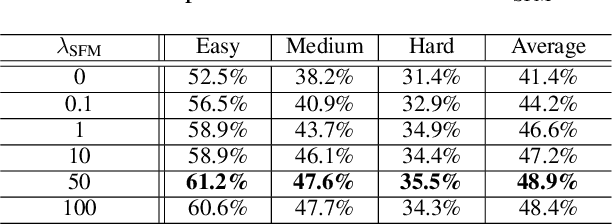
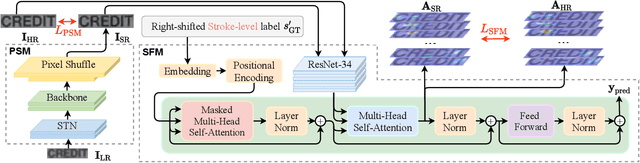
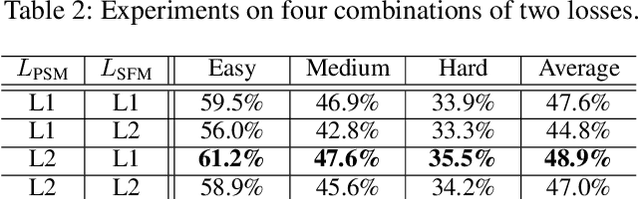
In the last decade, the blossom of deep learning has witnessed the rapid development of scene text recognition. However, the recognition of low-resolution scene text images remains a challenge. Even though some super-resolution methods have been proposed to tackle this problem, they usually treat text images as general images while ignoring the fact that the visual quality of strokes (the atomic unit of text) plays an essential role for text recognition. According to Gestalt Psychology, humans are capable of composing parts of details into the most similar objects guided by prior knowledge. Likewise, when humans observe a low-resolution text image, they will inherently use partial stroke-level details to recover the appearance of holistic characters. Inspired by Gestalt Psychology, we put forward a Stroke-Aware Scene Text Image Super-Resolution method containing a Stroke-Focused Module (SFM) to concentrate on stroke-level internal structures of characters in text images. Specifically, we attempt to design rules for decomposing English characters and digits at stroke-level, then pre-train a text recognizer to provide stroke-level attention maps as positional clues with the purpose of controlling the consistency between the generated super-resolution image and high-resolution ground truth. The extensive experimental results validate that the proposed method can indeed generate more distinguishable images on TextZoom and manually constructed Chinese character dataset Degraded-IC13. Furthermore, since the proposed SFM is only used to provide stroke-level guidance when training, it will not bring any time overhead during the test phase. Code is available at https://github.com/FudanVI/FudanOCR/tree/main/text-gestalt.
Simulating the Effects of Eco-Friendly Transportation Selections for Air Pollution Reduction
Sep 14, 2021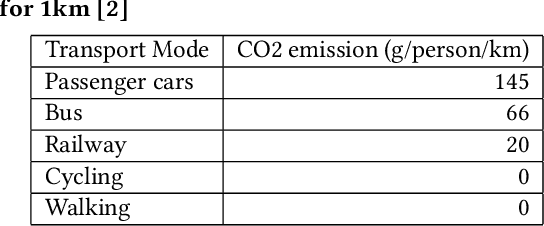
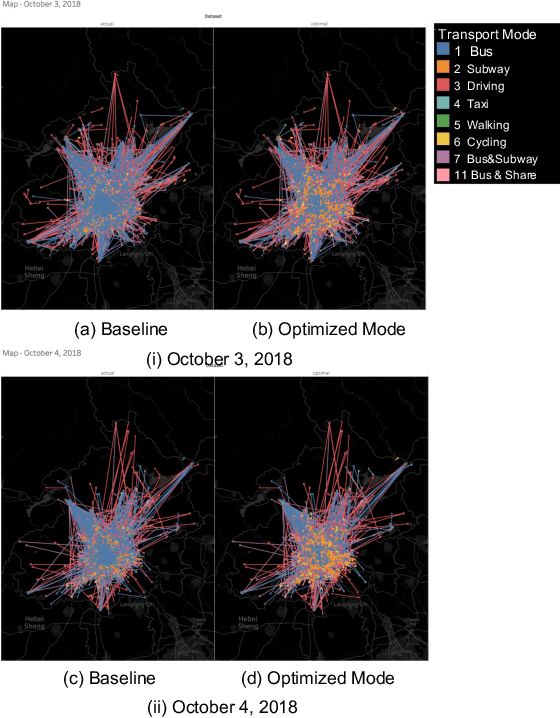
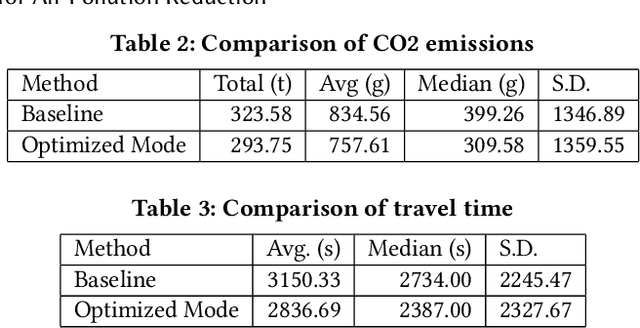

Reducing air pollution, such as CO2 and PM2.5 emissions, is one of the most important issues for many countries worldwide. Selecting an environmentally friendly transport mode can be an effective approach of individuals to reduce air pollution in daily life. In this study, we propose a method to simulate the effectiveness of an eco-friendly transport mode selection for reducing air pollution by using map search logs. We formulate the transport mode selection as a combinatorial optimization problem with the constraints regarding the total amount of CO2 emissions as an example of air pollution and the average travel time. The optimization results show that the total amount of CO2 emissions can be reduced by 9.23%, whereas the average travel time can in fact be reduced by 9.96%. Our research proposal won first prize in Regular Machine Learning Competition Track Task 2 at KDD Cup 2019.
Indoor Path Planning for an Unmanned Aerial Vehicle via Curriculum Learning
Aug 23, 2021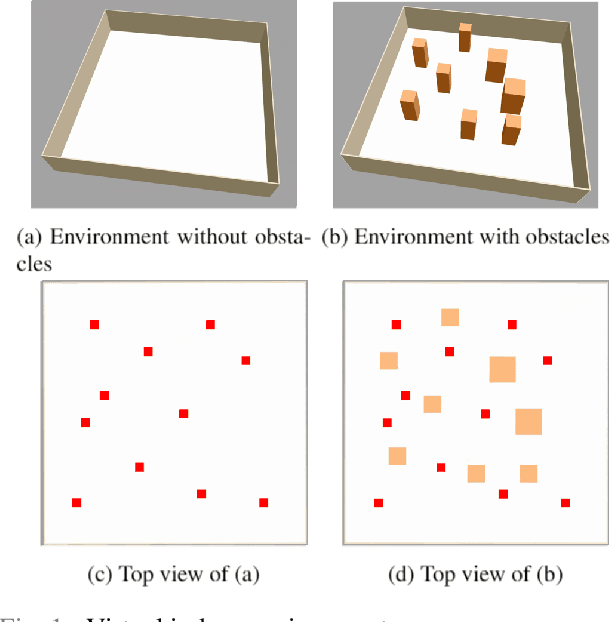
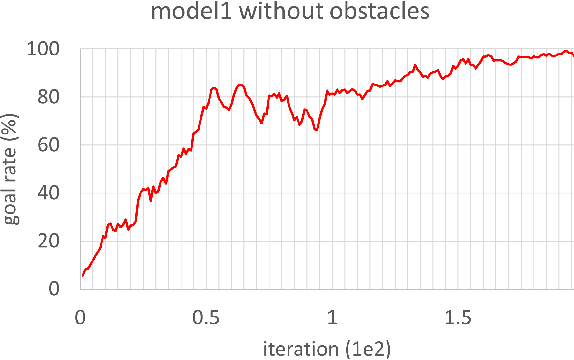
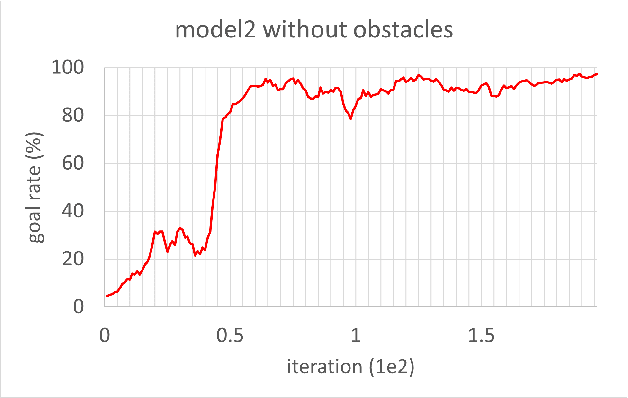
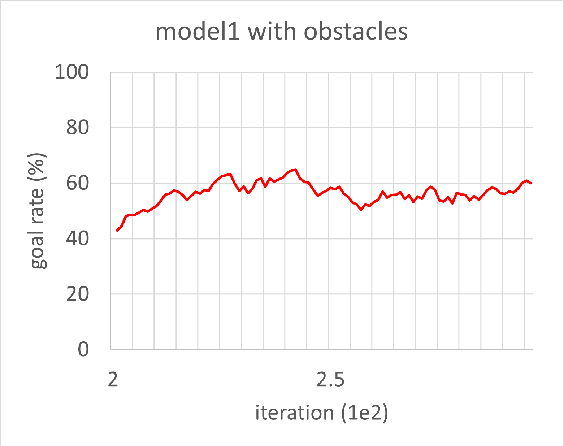
In this study, reinforcement learning was applied to learning two-dimensional path planning including obstacle avoidance by unmanned aerial vehicle (UAV) in an indoor environment. The task assigned to the UAV was to reach the goal position in the shortest amount of time without colliding with any obstacles. Reinforcement learning was performed in a virtual environment created using Gazebo, a virtual environment simulator, to reduce the learning time and cost. Curriculum learning, which consists of two stages was performed for more efficient learning. As a result of learning with two reward models, the maximum goal rates achieved were 71.2% and 88.0%.
Robust Weakly Supervised Learning for COVID-19 Recognition Using Multi-Center CT Images
Dec 09, 2021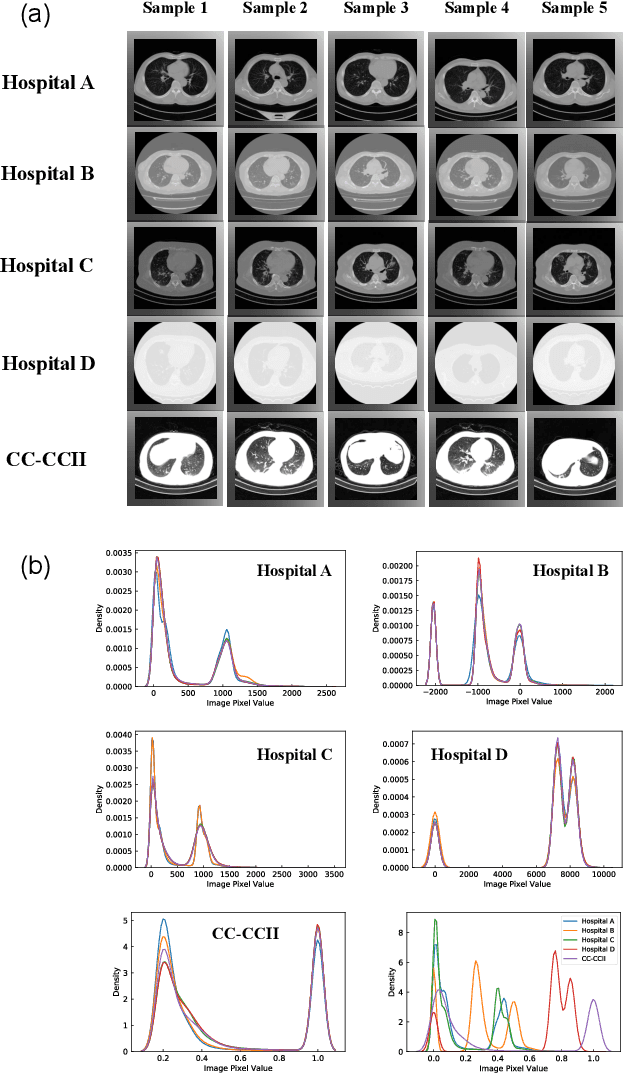
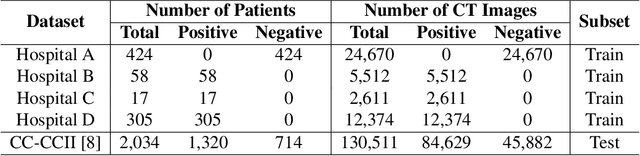
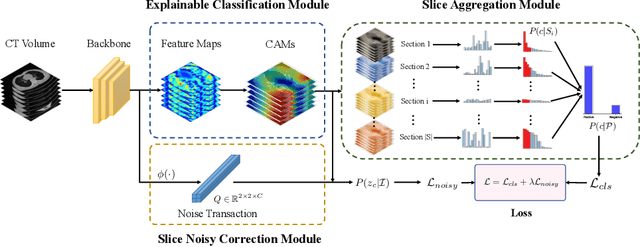
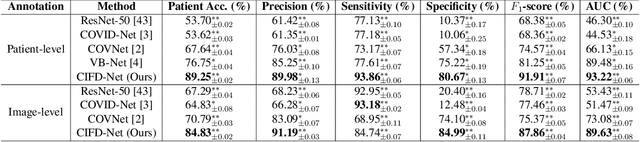
The world is currently experiencing an ongoing pandemic of an infectious disease named coronavirus disease 2019 (i.e., COVID-19), which is caused by the severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). Computed Tomography (CT) plays an important role in assessing the severity of the infection and can also be used to identify those symptomatic and asymptomatic COVID-19 carriers. With a surge of the cumulative number of COVID-19 patients, radiologists are increasingly stressed to examine the CT scans manually. Therefore, an automated 3D CT scan recognition tool is highly in demand since the manual analysis is time-consuming for radiologists and their fatigue can cause possible misjudgment. However, due to various technical specifications of CT scanners located in different hospitals, the appearance of CT images can be significantly different leading to the failure of many automated image recognition approaches. The multi-domain shift problem for the multi-center and multi-scanner studies is therefore nontrivial that is also crucial for a dependable recognition and critical for reproducible and objective diagnosis and prognosis. In this paper, we proposed a COVID-19 CT scan recognition model namely coronavirus information fusion and diagnosis network (CIFD-Net) that can efficiently handle the multi-domain shift problem via a new robust weakly supervised learning paradigm. Our model can resolve the problem of different appearance in CT scan images reliably and efficiently while attaining higher accuracy compared to other state-of-the-art methods.