 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Edge-Enhanced Dual Discriminator Generative Adversarial Network for Fast MRI with Parallel Imaging Using Multi-view Information
Dec 10, 2021
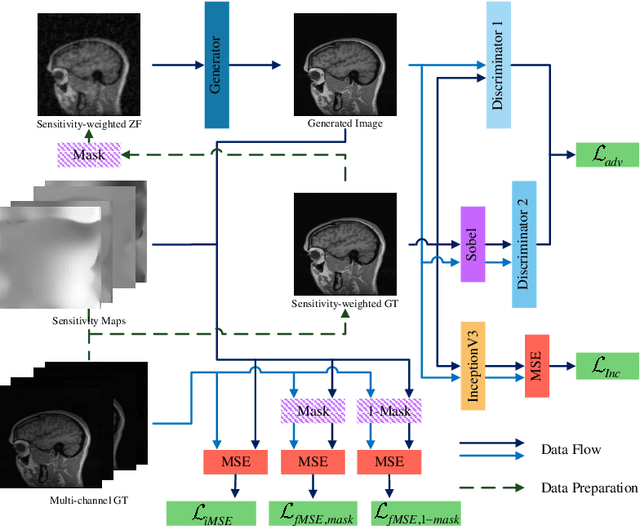
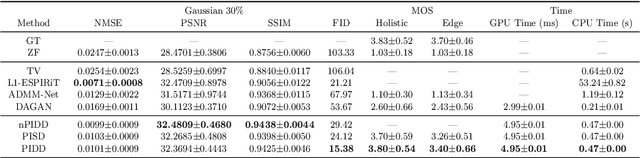
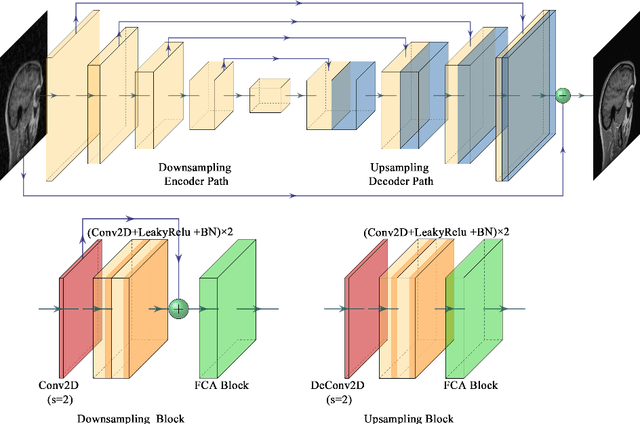
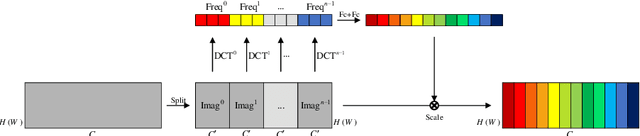
In clinical medicine, magnetic resonance imaging (MRI) is one of the most important tools for diagnosis, triage, prognosis, and treatment planning. However, MRI suffers from an inherent slow data acquisition process because data is collected sequentially in k-space. In recent years, most MRI reconstruction methods proposed in the literature focus on holistic image reconstruction rather than enhancing the edge information. This work steps aside this general trend by elaborating on the enhancement of edge information. Specifically, we introduce a novel parallel imaging coupled dual discriminator generative adversarial network (PIDD-GAN) for fast multi-channel MRI reconstruction by incorporating multi-view information. The dual discriminator design aims to improve the edge information in MRI reconstruction. One discriminator is used for holistic image reconstruction, whereas the other one is responsible for enhancing edge information. An improved U-Net with local and global residual learning is proposed for the generator. Frequency channel attention blocks (FCA Blocks) are embedded in the generator for incorporating attention mechanisms. Content loss is introduced to train the generator for better reconstruction quality. We performed comprehensive experiments on Calgary-Campinas public brain MR dataset and compared our method with state-of-the-art MRI reconstruction methods. Ablation studies of residual learning were conducted on the MICCAI13 dataset to validate the proposed modules. Results show that our PIDD-GAN provides high-quality reconstructed MR images, with well-preserved edge information. The time of single-image reconstruction is below 5ms, which meets the demand of faster processing.
Federated Dynamic Sparse Training: Computing Less, Communicating Less, Yet Learning Better
Dec 18, 2021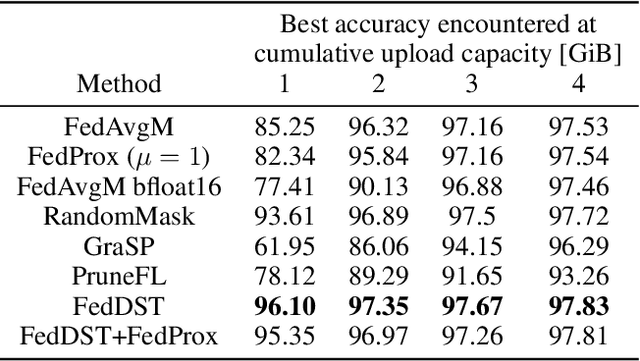
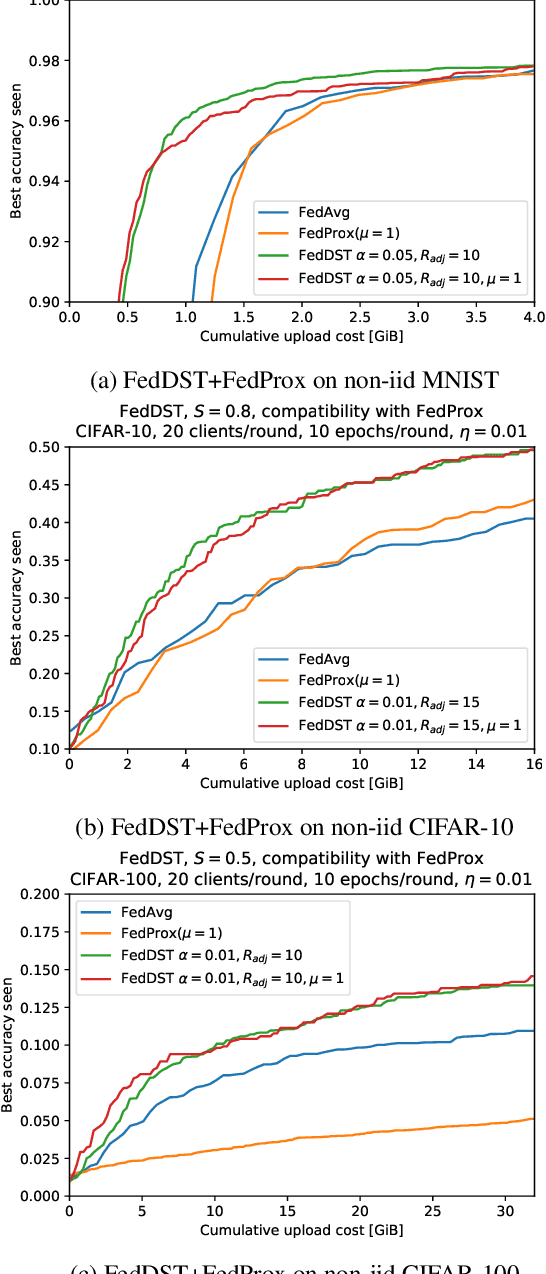
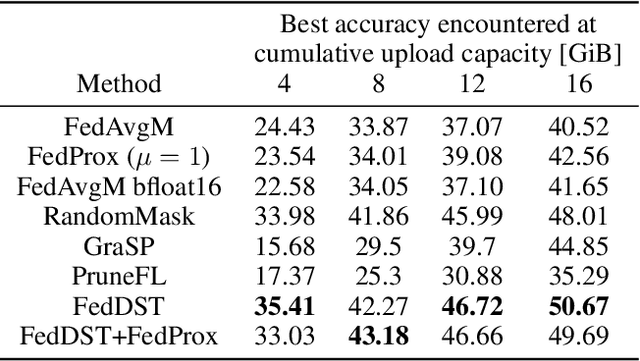
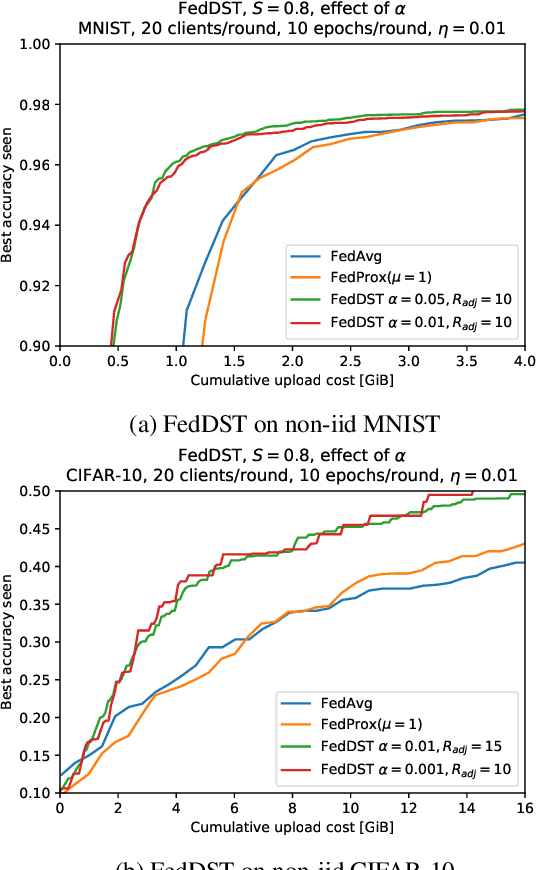
Federated learning (FL) enables distribution of machine learning workloads from the cloud to resource-limited edge devices. Unfortunately, current deep networks remain not only too compute-heavy for inference and training on edge devices, but also too large for communicating updates over bandwidth-constrained networks. In this paper, we develop, implement, and experimentally validate a novel FL framework termed Federated Dynamic Sparse Training (FedDST) by which complex neural networks can be deployed and trained with substantially improved efficiency in both on-device computation and in-network communication. At the core of FedDST is a dynamic process that extracts and trains sparse sub-networks from the target full network. With this scheme, "two birds are killed with one stone:" instead of full models, each client performs efficient training of its own sparse networks, and only sparse networks are transmitted between devices and the cloud. Furthermore, our results reveal that the dynamic sparsity during FL training more flexibly accommodates local heterogeneity in FL agents than the fixed, shared sparse masks. Moreover, dynamic sparsity naturally introduces an "in-time self-ensembling effect" into the training dynamics and improves the FL performance even over dense training. In a realistic and challenging non i.i.d. FL setting, FedDST consistently outperforms competing algorithms in our experiments: for instance, at any fixed upload data cap on non-iid CIFAR-10, it gains an impressive accuracy advantage of 10% over FedAvgM when given the same upload data cap; the accuracy gap remains 3% even when FedAvgM is given 2x the upload data cap, further demonstrating efficacy of FedDST. Code is available at: https://github.com/bibikar/feddst.
New Evolutionary Computation Models and their Applications to Machine Learning
Oct 01, 2021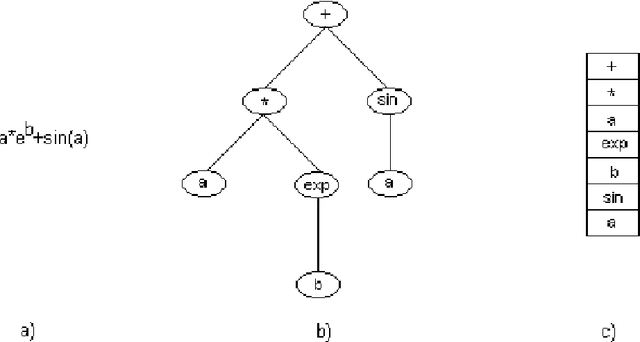
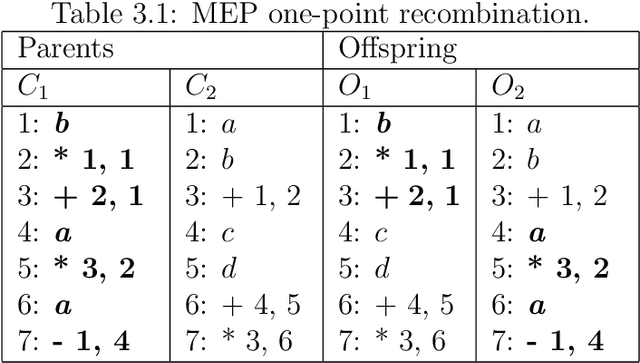
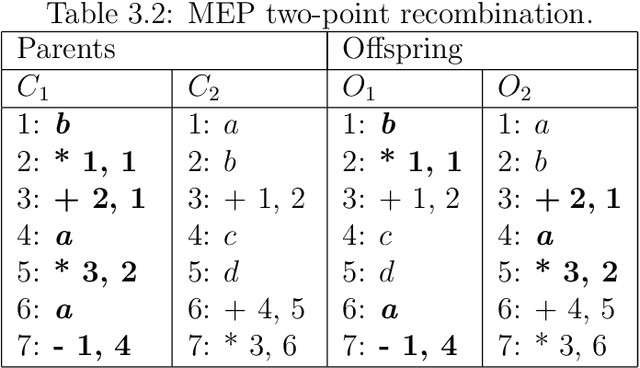
Automatic Programming is one of the most important areas of computer science research today. Hardware speed and capability have increased exponentially, but the software is years behind. The demand for software has also increased significantly, but it is still written in old fashion: by using humans. There are multiple problems when the work is done by humans: cost, time, quality. It is costly to pay humans, it is hard to keep them satisfied for a long time, it takes a lot of time to teach and train them and the quality of their output is in most cases low (in software, mostly due to bugs). The real advances in human civilization appeared during the industrial revolutions. Before the first revolution, most people worked in agriculture. Today, very few percent of people work in this field. A similar revolution must appear in the computer programming field. Otherwise, we will have so many people working in this field as we had in the past working in agriculture. How do people know how to write computer programs? Very simple: by learning. Can we do the same for software? Can we put the software to learn how to write software? It seems that is possible (to some degree) and the term is called Machine Learning. It was first coined in 1959 by the first person who made a computer perform a serious learning task, namely, Arthur Samuel. However, things are not so easy as in humans (well, truth to be said - for some humans it is impossible to learn how to write software). So far we do not have software that can learn perfectly to write software. We have some particular cases where some programs do better than humans, but the examples are sporadic at best. Learning from experience is difficult for computer programs. Instead of trying to simulate how humans teach humans how to write computer programs, we can simulate nature.
* 169 pages. This thesis describes several evolutionary models developed by the author during his PhD program
Time accelerated image super-resolution using shallow residual feature representative network
Apr 08, 2020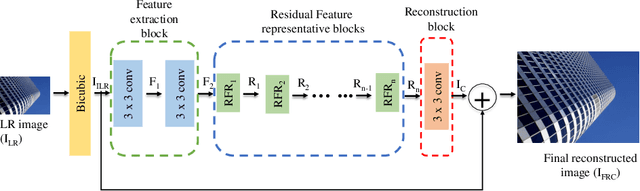
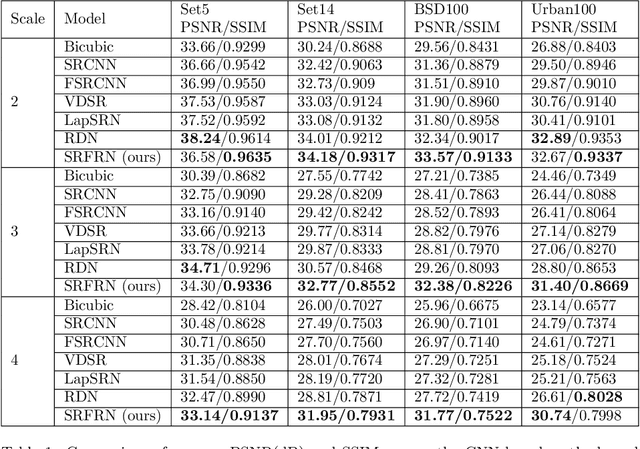

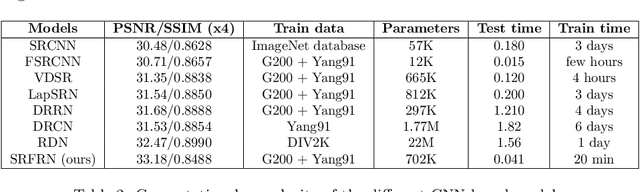
The recent advances in deep learning indicate significant progress in the field of single image super-resolution. With the advent of these techniques, high-resolution image with high peak signal to noise ratio (PSNR) and excellent perceptual quality can be reconstructed. The major challenges associated with existing deep convolutional neural networks are their computational complexity and time; the increasing depth of the networks, often result in high space complexity. To alleviate these issues, we developed an innovative shallow residual feature representative network (SRFRN) that uses a bicubic interpolated low-resolution image as input and residual representative units (RFR) which include serially stacked residual non-linear convolutions. Furthermore, the reconstruction of the high-resolution image is done by combining the output of the RFR units and the residual output from the bicubic interpolated LR image. Finally, multiple experiments have been performed on the benchmark datasets and the proposed model illustrates superior performance for higher scales. Besides, this model also exhibits faster execution time compared to all the existing approaches.
Comparison of computing efficiency among FFT, CZT and Zoom FFT in THz-TDS
Aug 09, 2021

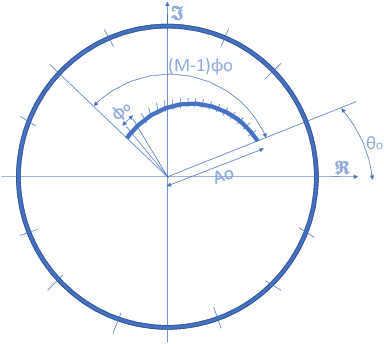
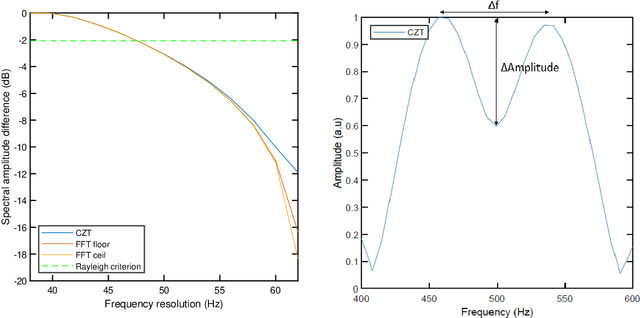
A study of alternative transforms to FFT in order to compare their potential to enhance resolution and computation time in the framework of THz time domain spectroscopy (THz-TDS) instruments is carried out. Both from simulated and experimental data it is shown that, as expected, resolution cannot be enhanced using CZT or Zoom FFT and, in terms of computing efficiency, FFT is in practical cases, the most efficient one.
Multilingual training for Software Engineering
Dec 06, 2021
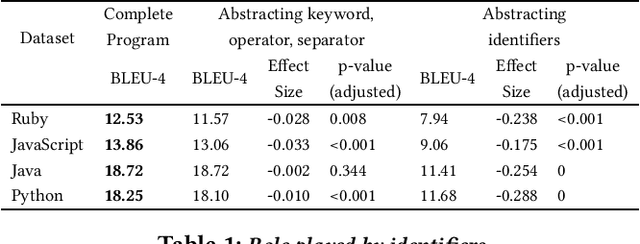
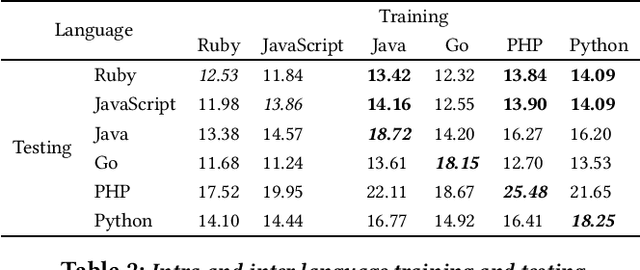

Well-trained machine-learning models, which leverage large amounts of open-source software data, have now become an interesting approach to automating many software engineering tasks. Several SE tasks have all been subject to this approach, with performance gradually improving over the past several years with better models and training methods. More, and more diverse, clean, labeled data is better for training; but constructing good-quality datasets is time-consuming and challenging. Ways of augmenting the volume and diversity of clean, labeled data generally have wide applicability. For some languages (e.g., Ruby) labeled data is less abundant; in others (e.g., JavaScript) the available data maybe more focused on some application domains, and thus less diverse. As a way around such data bottlenecks, we present evidence suggesting that human-written code in different languages (which performs the same function), is rather similar, and particularly preserving of identifier naming patterns; we further present evidence suggesting that identifiers are a very important element of training data for software engineering tasks. We leverage this rather fortuitous phenomenon to find evidence that available multilingual training data (across different languages) can be used to amplify performance. We study this for 3 different tasks: code summarization, code retrieval, and function naming. We note that this data-augmenting approach is broadly compatible with different tasks, languages, and machine-learning models.
DeepEdge: A Deep Reinforcement Learning based Task Orchestrator for Edge Computing
Oct 05, 2021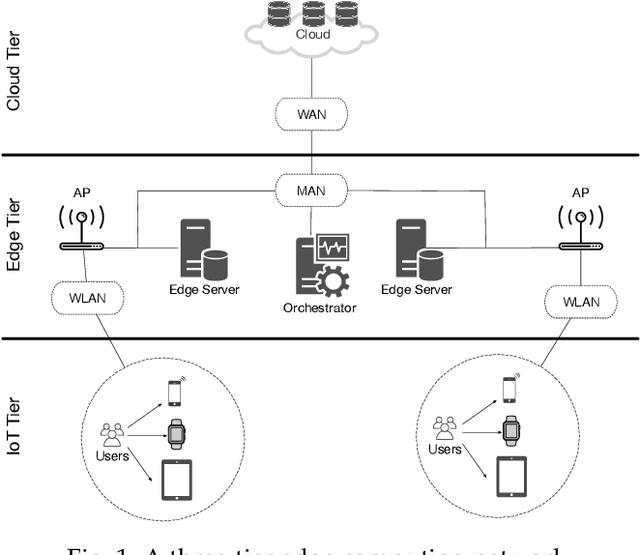

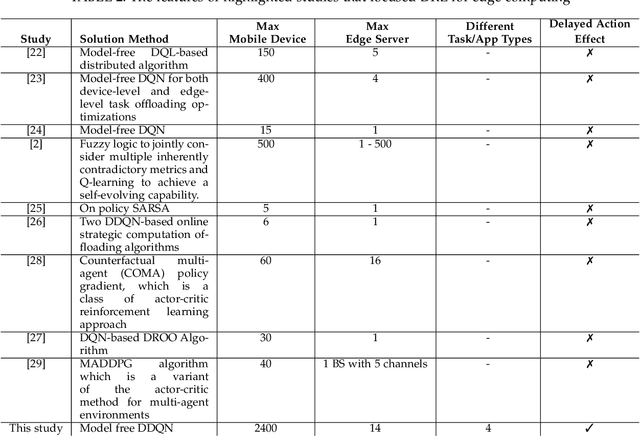

The improvements in the edge computing technology pave the road for diversified applications that demand real-time interaction. However, due to the mobility of the end-users and the dynamic edge environment, it becomes challenging to handle the task offloading with high performance. Moreover, since each application in mobile devices has different characteristics, a task orchestrator must be adaptive and have the ability to learn the dynamics of the environment. For this purpose, we develop a deep reinforcement learning based task orchestrator, DeepEdge, which learns to meet different task requirements without needing human interaction even under the heavily-loaded stochastic network conditions in terms of mobile users and applications. Given the dynamic offloading requests and time-varying communication conditions, we successfully model the problem as a Markov process and then apply the Double Deep Q-Network (DDQN) algorithm to implement DeepEdge. To evaluate the robustness of DeepEdge, we experiment with four different applications including image rendering, infotainment, pervasive health, and augmented reality in the network under various loads. Furthermore, we compare the performance of our agent with the four different task offloading approaches in the literature. Our results show that DeepEdge outperforms its competitors in terms of the percentage of satisfactorily completed tasks.
Antenna De-Embedding in FDTD Using Spherical Wave Functions by Exploiting Orthogonality
Nov 08, 2021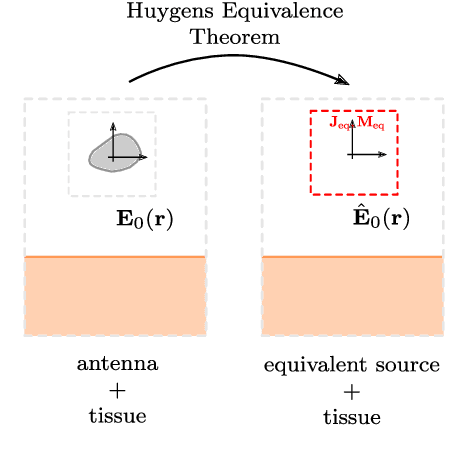
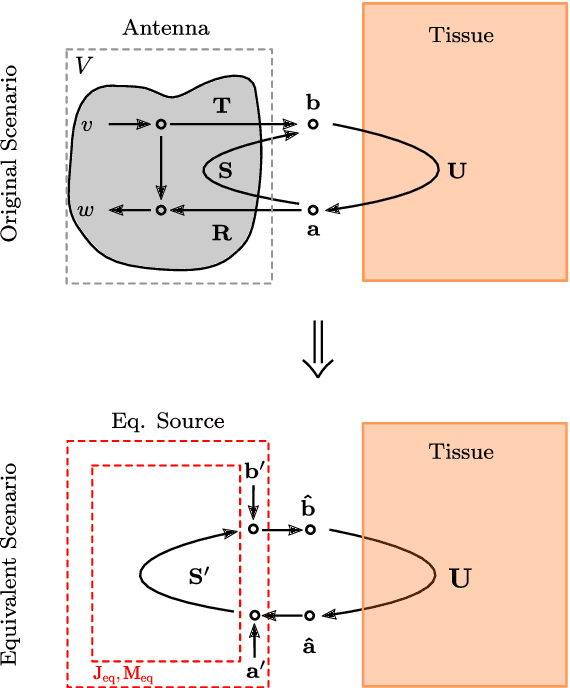
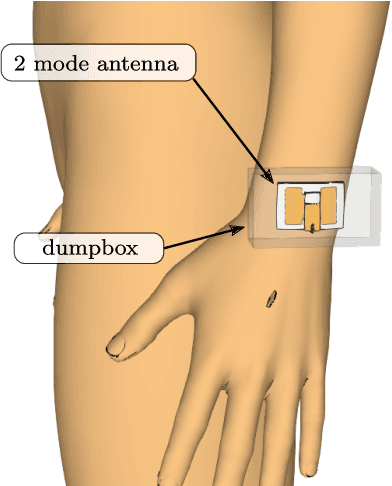
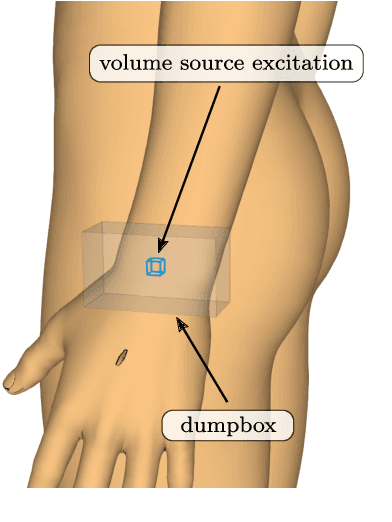
De-embedding antennas from the channel using Spherical Wave Functions (SWF) is a useful method to reduce the numerical effort in the simulation of wearable antennas. In this paper an analytical solution to the De-embedding problem is presented in form of surface integrals. This new integral solution is helpful on a theoretical level to derive insights and is also well suited for implementation in Finite Difference Time Domain (FDTD) numerical software. The spherical wave function coefficients are calculated directly from near-field values. Furthermore, the presence of a near-field scatterer in the de-embedding problem is discussed on a theoretical level based on the Huygens Equivalence Theorem. This makes it possible to exploit the degrees of freedom in such a way that it is sufficient to only use out-going spherical wave functions and still obtain correct results.
Reinforcement Explanation Learning
Nov 26, 2021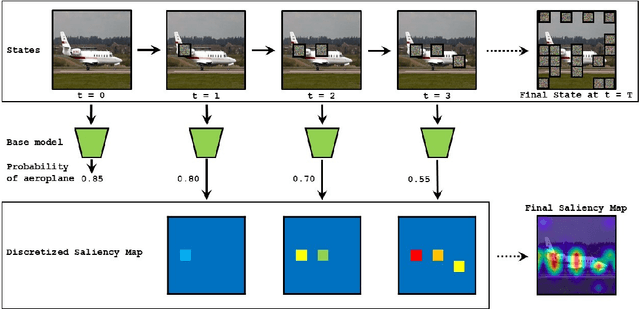
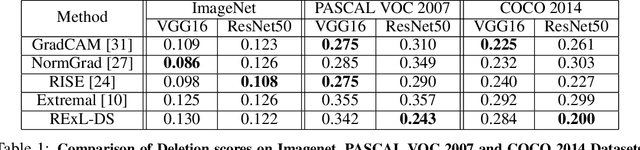
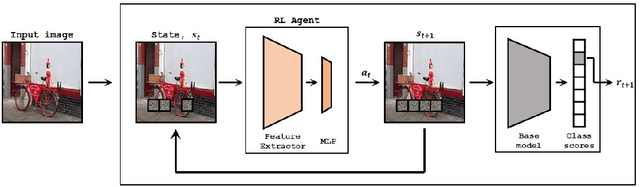
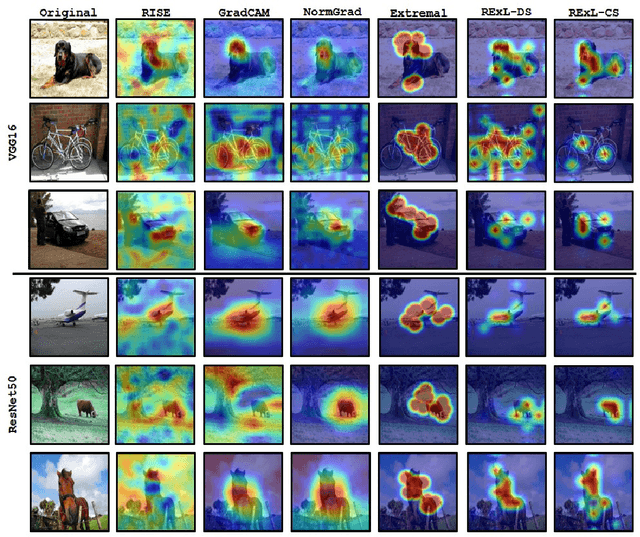
Deep Learning has become overly complicated and has enjoyed stellar success in solving several classical problems like image classification, object detection, etc. Several methods for explaining these decisions have been proposed. Black-box methods to generate saliency maps are particularly interesting due to the fact that they do not utilize the internals of the model to explain the decision. Most black-box methods perturb the input and observe the changes in the output. We formulate saliency map generation as a sequential search problem and leverage upon Reinforcement Learning (RL) to accumulate evidence from input images that most strongly support decisions made by a classifier. Such a strategy encourages to search intelligently for the perturbations that will lead to high-quality explanations. While successful black box explanation approaches need to rely on heavy computations and suffer from small sample approximation, the deterministic policy learned by our method makes it a lot more efficient during the inference. Experiments on three benchmark datasets demonstrate the superiority of the proposed approach in inference time over state-of-the-arts without hurting the performance. Project Page: https://cvir.github.io/projects/rexl.html
A New Approach to Image Compression in Industrial Internet of Things
Dec 10, 2021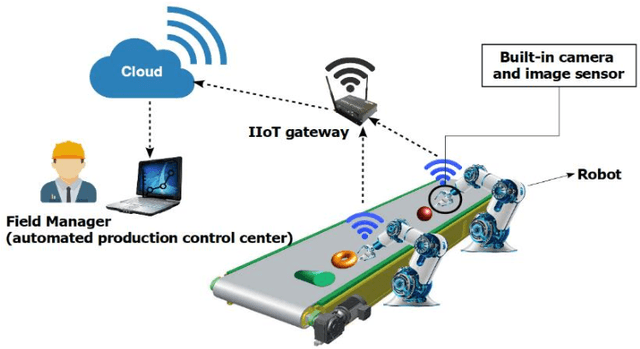



Applying image sensors in automation of Industrial Internet of Things (IIoT) technology is on the rise, day by day. In such companies, a large number of high volume images are transmitted at any moment; therefore, a significant challenge is reducing the amount of transmitted information and consequently bandwidth without reducing the quality of images. Image compression in sensors, in this regard, will save bandwidth and speed up data transmitting. There are several pieces of research in image compression for sensor networks, but, according to the nature of image transfer in IIoT, there is no study in this particular field. In this paper, it is for the first time that a new reusable technique to improve productivity in image compression is introduced and applied. To do this, a new adaptive lossy compression technique to compact sensor-generated images in IIoT by using K- Means++ and Intelligent Embedded Coding (IEC) as our novel approach, is presented. The new method is based on the colour of pixels so that pixels with the same or nearly the same colours are clustered around a centroid and finally, the colour of the pixels will be encoded. The experiments are based on a reputable image dataset from a real smart greenhouse; i.e. KOMATSUNA. The evaluation results reveal that, with the same compression rate, our approach compresses images with higher quality in comparison with other methods such as K-means, fuzzy C-means and fuzzy C-means++ clustering.