 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Glue: Adaptively Merging Single Table Cardinality to Estimate Join Query Size
Dec 07, 2021

Cardinality estimation (CardEst), a central component of the query optimizer, plays a significant role in generating high-quality query plans in DBMS. The CardEst problem has been extensively studied in the last several decades, using both traditional and ML-enhanced methods. Whereas, the hardest problem in CardEst, i.e., how to estimate the join query size on multiple tables, has not been extensively solved. Current methods either reply on independence assumptions or apply techniques with heavy burden, whose performance is still far from satisfactory. Even worse, existing CardEst methods are often designed to optimize one goal, i.e., inference speed or estimation accuracy, which can not adapt to different occasions. In this paper, we propose a very general framework, called Glue, to tackle with these challenges. Its key idea is to elegantly decouple the correlations across different tables and losslessly merge single table CardEst results to estimate the join query size. Glue supports obtaining the single table-wise CardEst results using any existing CardEst method and can process any complex join schema. Therefore, it easily adapts to different scenarios having different performance requirements, i.e., OLTP with fast estimation time or OLAP with high estimation accuracy. Meanwhile, we show that Glue can be seamlessly integrated into the plan search process and is able to support counting distinct number of values. All these properties exhibit the potential advances of deploying Glue in real-world DBMS.
Roadmap on Signal Processing for Next Generation Measurement Systems
Nov 09, 2021
Signal processing is a fundamental component of almost any sensor-enabled system, with a wide range of applications across different scientific disciplines. Time series data, images, and video sequences comprise representative forms of signals that can be enhanced and analysed for information extraction and quantification. The recent advances in artificial intelligence and machine learning are shifting the research attention towards intelligent, data-driven, signal processing. This roadmap presents a critical overview of the state-of-the-art methods and applications aiming to highlight future challenges and research opportunities towards next generation measurement systems. It covers a broad spectrum of topics ranging from basic to industrial research, organized in concise thematic sections that reflect the trends and the impacts of current and future developments per research field. Furthermore, it offers guidance to researchers and funding agencies in identifying new prospects.
Adaptive Differentially Private Empirical Risk Minimization
Oct 25, 2021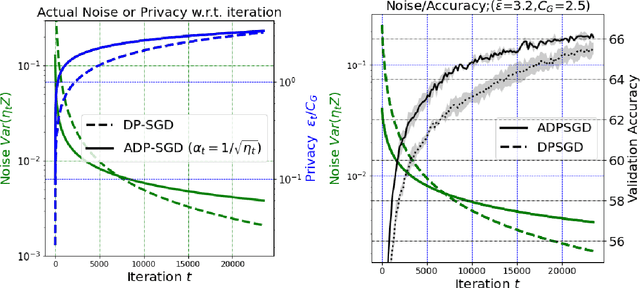
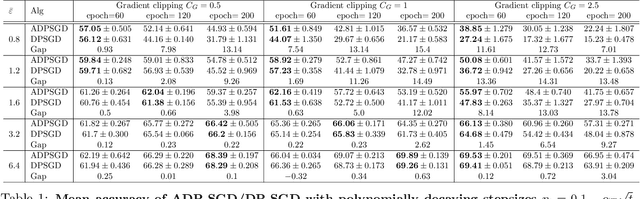
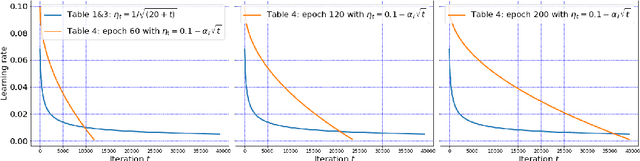
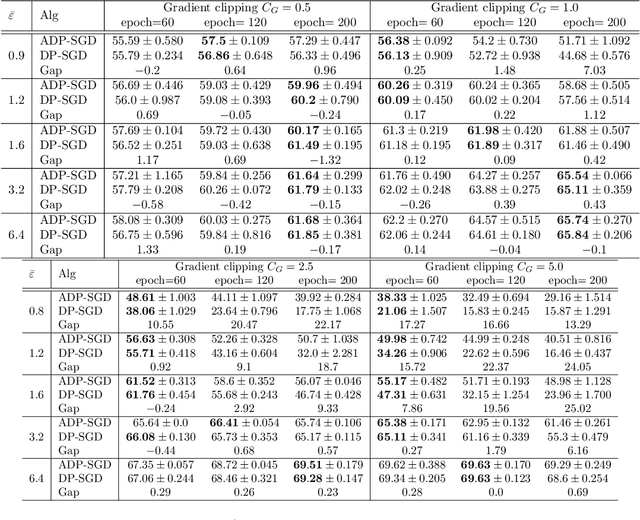
We propose an adaptive (stochastic) gradient perturbation method for differentially private empirical risk minimization. At each iteration, the random noise added to the gradient is optimally adapted to the stepsize; we name this process adaptive differentially private (ADP) learning. Given the same privacy budget, we prove that the ADP method considerably improves the utility guarantee compared to the standard differentially private method in which vanilla random noise is added. Our method is particularly useful for gradient-based algorithms with time-varying learning rates, including variants of AdaGrad (Duchi et al., 2011). We provide extensive numerical experiments to demonstrate the effectiveness of the proposed adaptive differentially private algorithm.
Monte Carlo dropout increases model repeatability
Nov 12, 2021
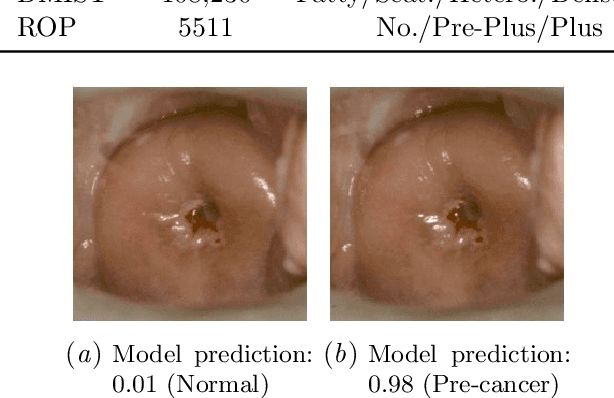
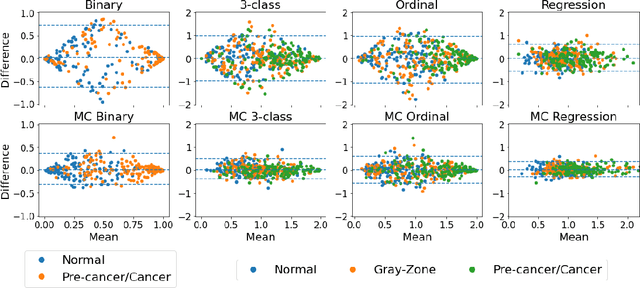
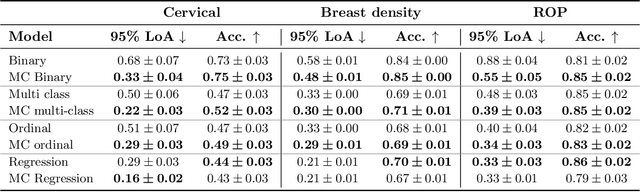
The integration of artificial intelligence into clinical workflows requires reliable and robust models. Among the main features of robustness is repeatability. Much attention is given to classification performance without assessing the model repeatability, leading to the development of models that turn out to be unusable in practice. In this work, we evaluate the repeatability of four model types on images from the same patient that were acquired during the same visit. We study the performance of binary, multi-class, ordinal, and regression models on three medical image analysis tasks: cervical cancer screening, breast density estimation, and retinopathy of prematurity classification. Moreover, we assess the impact of sampling Monte Carlo dropout predictions at test time on classification performance and repeatability. Leveraging Monte Carlo predictions significantly increased repeatability for all tasks on the binary, multi-class, and ordinal models leading to an average reduction of the 95% limits of agreement by 17% points.
SAT Encodings for Pseudo-Boolean Constraints Together With At-Most-One Constraints
Oct 15, 2021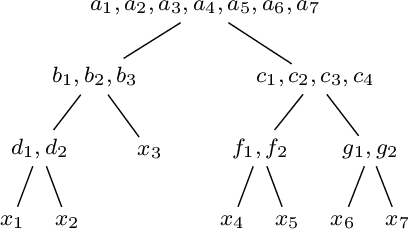

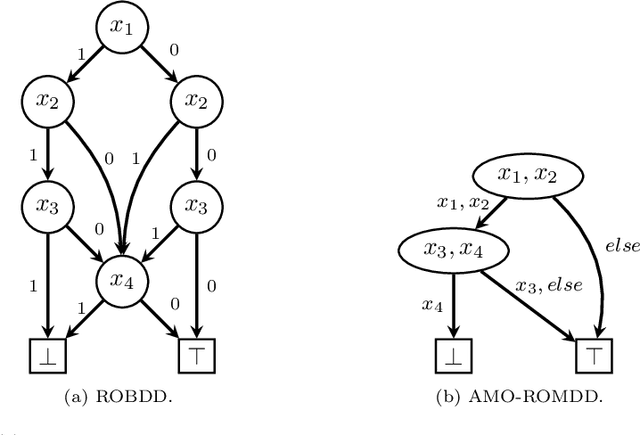
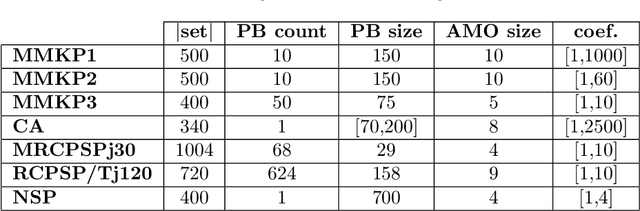
When solving a combinatorial problem using propositional satisfiability (SAT), the encoding of the problem is of vital importance. We study encodings of Pseudo-Boolean (PB) constraints, a common type of arithmetic constraint that appears in a wide variety of combinatorial problems such as timetabling, scheduling, and resource allocation. In some cases PB constraints occur together with at-most-one (AMO) constraints over subsets of their variables (forming PB(AMO) constraints). Recent work has shown that taking account of AMOs when encoding PB constraints using decision diagrams can produce a dramatic improvement in solver efficiency. In this paper we extend the approach to other state-of-the-art encodings of PB constraints, developing several new encodings for PB(AMO) constraints. Also, we present a more compact and efficient version of the popular Generalized Totalizer encoding, named Reduced Generalized Totalizer. This new encoding is also adapted for PB(AMO) constraints for a further gain. Our experiments show that the encodings of PB(AMO) constraints can be substantially smaller than those of PB constraints. PB(AMO) encodings allow many more instances to be solved within a time limit, and solving time is improved by more than one order of magnitude in some cases. We also observed that there is no single overall winner among the considered encodings, but efficiency of each encoding may depend on PB(AMO) characteristics such as the magnitude of coefficient values.
Adaptive exponential power distribution with moving estimator for nonstationary time series
Mar 04, 2020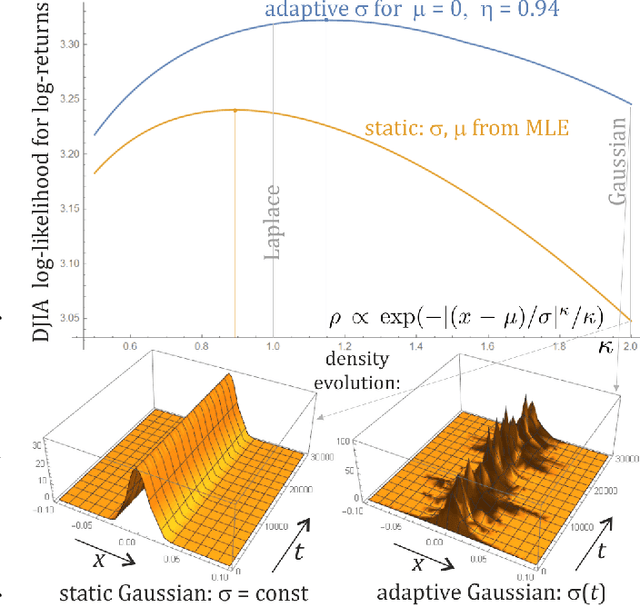
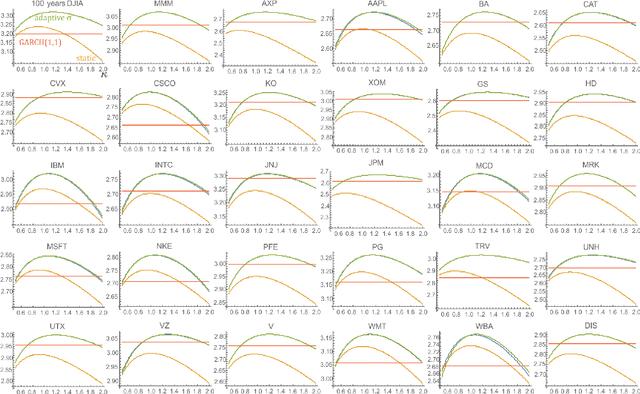
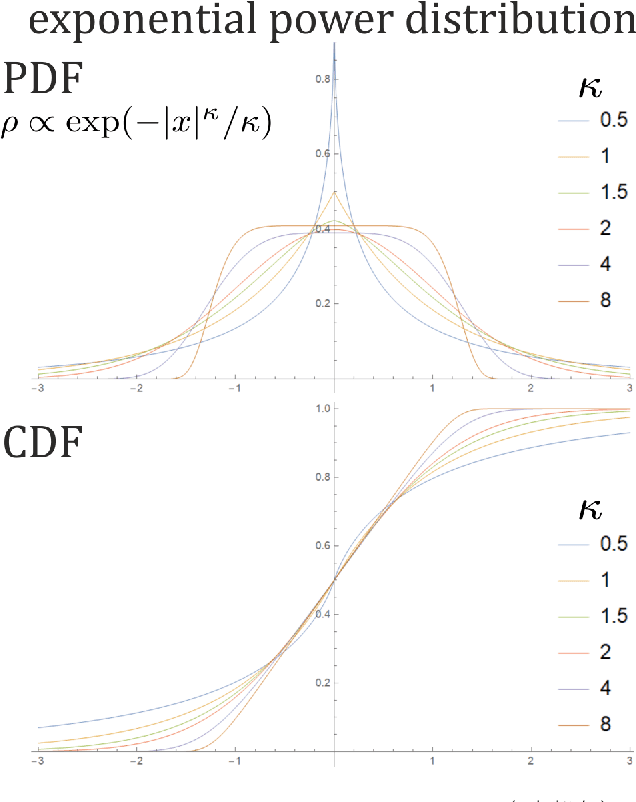
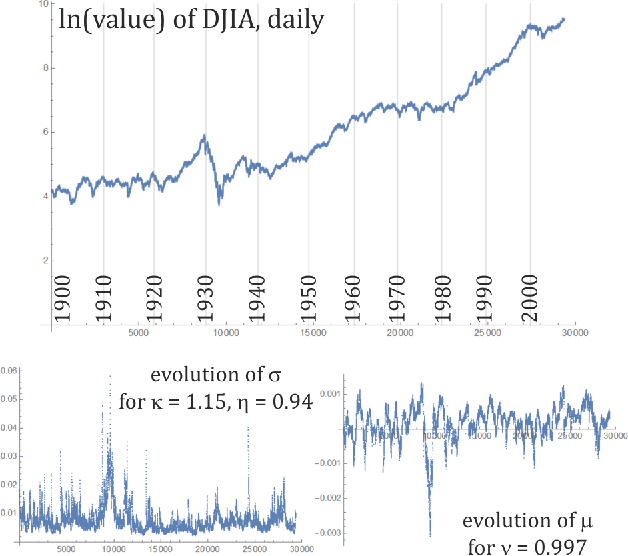
While standard estimation assumes that all datapoints are from probability distribution of the same fixed parameters $\theta$, we will focus on maximum likelihood (ML) adaptive estimation for nonstationary time series: separately estimating parameters $\theta_T$ for each time $T$ based on the earlier values $(x_t)_{t<T}$ using (exponential) moving ML estimator $\theta_T=\arg\max_\theta l_T$ for $l_T=\sum_{t<T} \eta^{T-t} \ln(\rho_\theta (x_t))$ and some $\eta\in(0,1]$. Computational cost of such moving estimator is generally much higher as we need to optimize log-likelihood multiple times, however, in many cases it can be made inexpensive thanks to dependencies. We focus on such example: exponential power distribution (EPD) $\rho(x)\propto \exp(-|(x-\mu)/\sigma|^\kappa/\kappa)$ family, which covers wide range of tail behavior like Gaussian ($\kappa=2$) or Laplace ($\kappa=1$) distribution. It is also convenient for such adaptive estimation of scale parameter $\sigma$ as its standard ML estimation is $\sigma^\kappa$ being average $\|x-\mu\|^\kappa$. By just replacing average with exponential moving average: $(\sigma_{T+1})^\kappa=\eta(\sigma_T)^\kappa +(1-\eta)|x_T-\mu|^\kappa$ we can inexpensively make it adaptive. It is tested on daily log-return series for DJIA companies, leading to essentially better log-likelihoods than standard (static) estimation, surprisingly with optimal $\kappa$ tails types varying between companies. Presented general alternative estimation philosophy provides tools which might be useful for building better models for analysis of nonstationary time-series.
Distributed Control for a Robotic Swarm to Pass through a Curve Virtual Tube
Dec 02, 2021
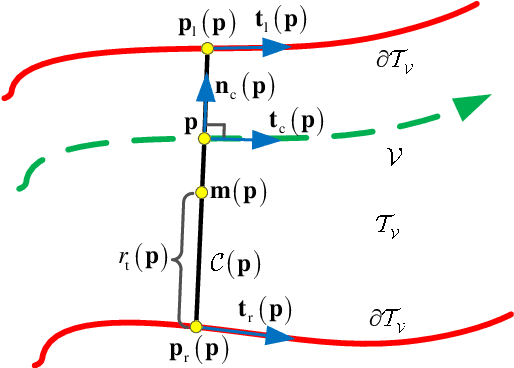
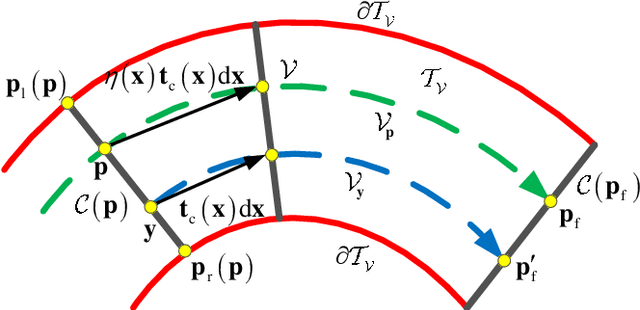
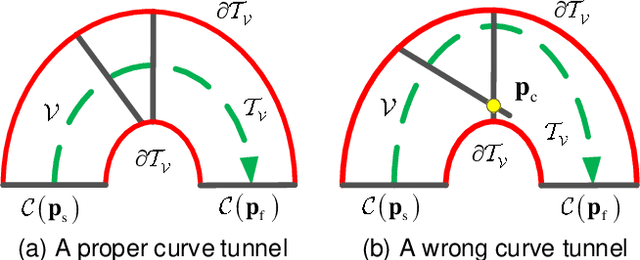
Robotic swarm systems are now becoming increasingly attractive for many challenging applications. The main task for any robot is to reach the destination while keeping a safe separation from other robots and obstacles. In many scenarios, robots need to move within a narrow corridor, through a window or a doorframe. In order to guide all robots to move in a cluttered environment, a curve virtual tube with no obstacle inside is carefully designed in this paper. There is no obstacle inside the tube, namely the area inside the tube can be seen as a safety zone. Then, a distributed swarm controller is proposed with three elaborate control terms: a line approaching term, a robot avoidance term and a tube keeping term. Formal analysis and proofs are made to show that the curve virtual tube passing problem can be solved in a finite time. For the convenience in practical use, a modified controller with an approximate control performance is put forward. Finally, the effectiveness of the proposed method is validated by numerical simulations and real experiments. To show the advantages of the proposed method, the comparison between our method and the control barrier function method is also presented in terms of calculation speed.
Network Clustering for Latent State and Changepoint Detection
Nov 01, 2021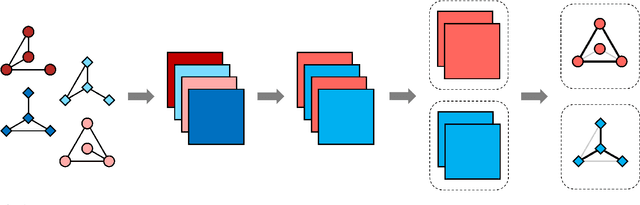
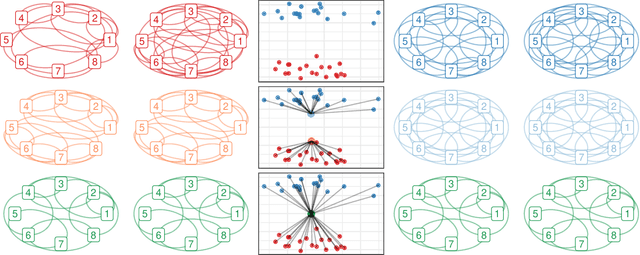
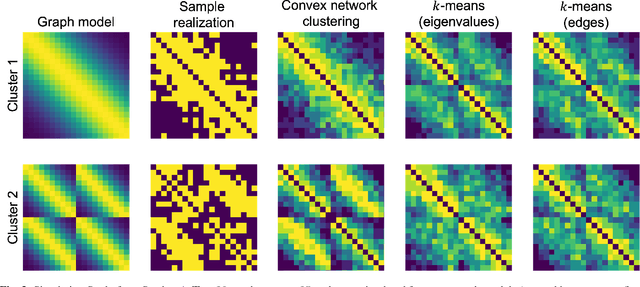
Network models provide a powerful and flexible framework for analyzing a wide range of structured data sources. In many situations of interest, however, multiple networks can be constructed to capture different aspects of an underlying phenomenon or to capture changing behavior over time. In such settings, it is often useful to cluster together related networks in attempt to identify patterns of common structure. In this paper, we propose a convex approach for the task of network clustering. Our approach uses a convex fusion penalty to induce a smoothly-varying tree-like cluster structure, eliminating the need to select the number of clusters a priori. We provide an efficient algorithm for convex network clustering and demonstrate its effectiveness on synthetic examples.
New Evolutionary Computation Models and their Applications to Machine Learning
Oct 01, 2021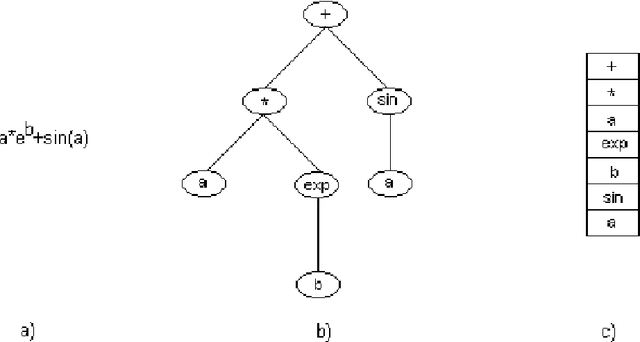
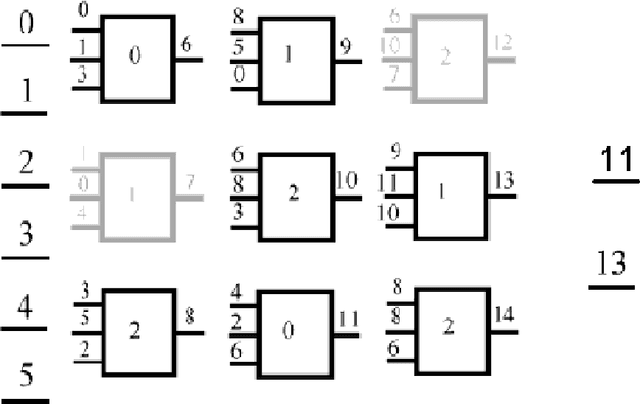
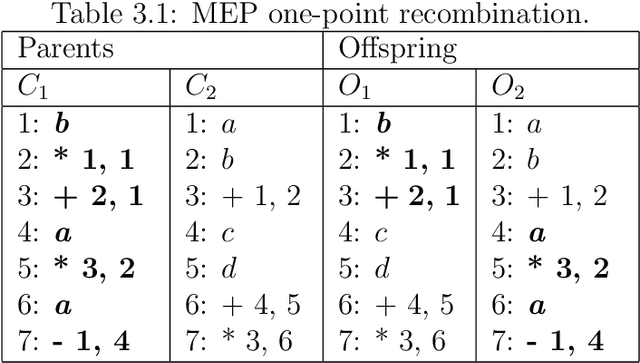
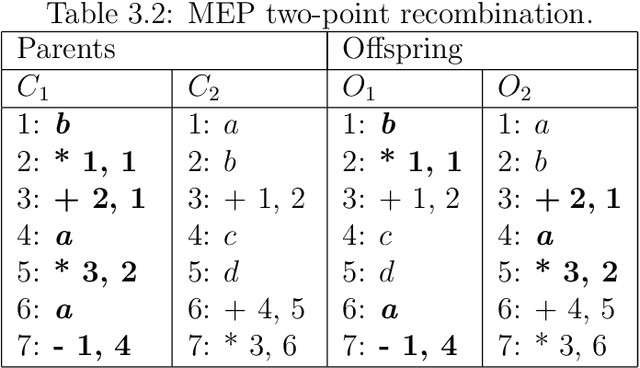
Automatic Programming is one of the most important areas of computer science research today. Hardware speed and capability have increased exponentially, but the software is years behind. The demand for software has also increased significantly, but it is still written in old fashion: by using humans. There are multiple problems when the work is done by humans: cost, time, quality. It is costly to pay humans, it is hard to keep them satisfied for a long time, it takes a lot of time to teach and train them and the quality of their output is in most cases low (in software, mostly due to bugs). The real advances in human civilization appeared during the industrial revolutions. Before the first revolution, most people worked in agriculture. Today, very few percent of people work in this field. A similar revolution must appear in the computer programming field. Otherwise, we will have so many people working in this field as we had in the past working in agriculture. How do people know how to write computer programs? Very simple: by learning. Can we do the same for software? Can we put the software to learn how to write software? It seems that is possible (to some degree) and the term is called Machine Learning. It was first coined in 1959 by the first person who made a computer perform a serious learning task, namely, Arthur Samuel. However, things are not so easy as in humans (well, truth to be said - for some humans it is impossible to learn how to write software). So far we do not have software that can learn perfectly to write software. We have some particular cases where some programs do better than humans, but the examples are sporadic at best. Learning from experience is difficult for computer programs. Instead of trying to simulate how humans teach humans how to write computer programs, we can simulate nature.
* 169 pages. This thesis describes several evolutionary models developed by the author during his PhD program
Conformer-based Hybrid ASR System for Switchboard Dataset
Nov 05, 2021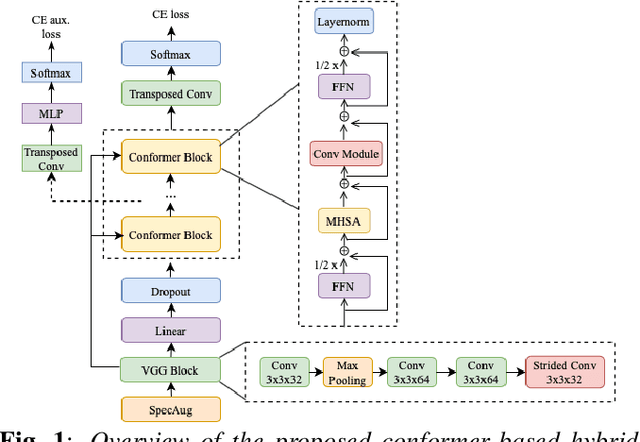
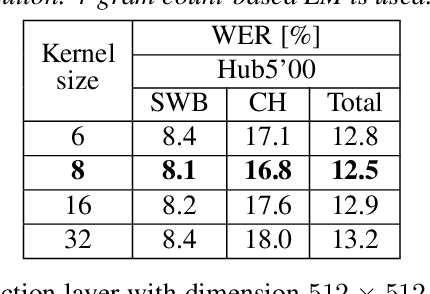
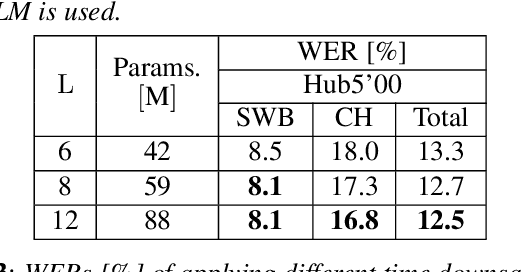
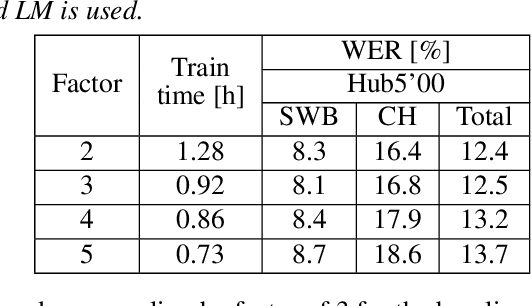
The recently proposed conformer architecture has been successfully used for end-to-end automatic speech recognition (ASR) architectures achieving state-of-the-art performance on different datasets. To our best knowledge, the impact of using conformer acoustic model for hybrid ASR is not investigated. In this paper, we present and evaluate a competitive conformer-based hybrid model training recipe. We study different training aspects and methods to improve word-error-rate as well as to increase training speed. We apply time downsampling methods for efficient training and use transposed convolutions to upsample the output sequence again. We conduct experiments on Switchboard 300h dataset and our conformer-based hybrid model achieves competitive results compared to other architectures. It generalizes very well on Hub5'01 test set and outperforms the BLSTM-based hybrid model significantly.