 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DNN-based Policies for Stochastic AC OPF
Dec 04, 2021
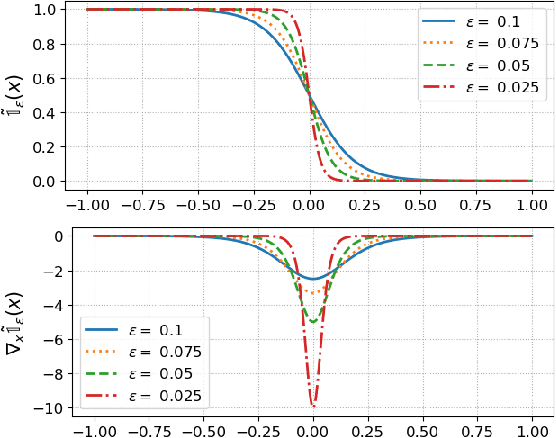
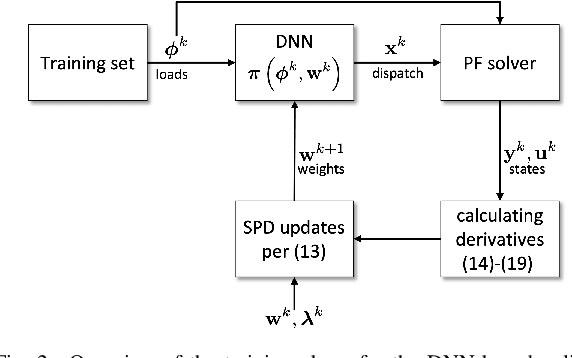
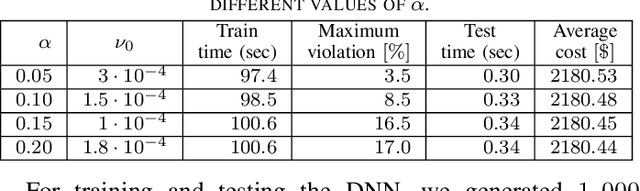

A prominent challenge to the safe and optimal operation of the modern power grid arises due to growing uncertainties in loads and renewables. Stochastic optimal power flow (SOPF) formulations provide a mechanism to handle these uncertainties by computing dispatch decisions and control policies that maintain feasibility under uncertainty. Most SOPF formulations consider simple control policies such as affine policies that are mathematically simple and resemble many policies used in current practice. Motivated by the efficacy of machine learning (ML) algorithms and the potential benefits of general control policies for cost and constraint enforcement, we put forth a deep neural network (DNN)-based policy that predicts the generator dispatch decisions in real time in response to uncertainty. The weights of the DNN are learnt using stochastic primal-dual updates that solve the SOPF without the need for prior generation of training labels and can explicitly account for the feasibility constraints in the SOPF. The advantages of the DNN policy over simpler policies and their efficacy in enforcing safety limits and producing near optimal solutions are demonstrated in the context of a chance constrained formulation on a number of test cases.
Deep Metric Learning with Locality Sensitive Angular Loss for Self-Correcting Source Separation of Neural Spiking Signals
Oct 13, 2021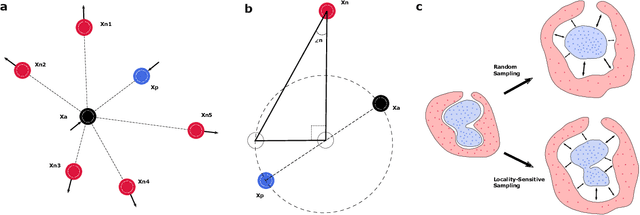
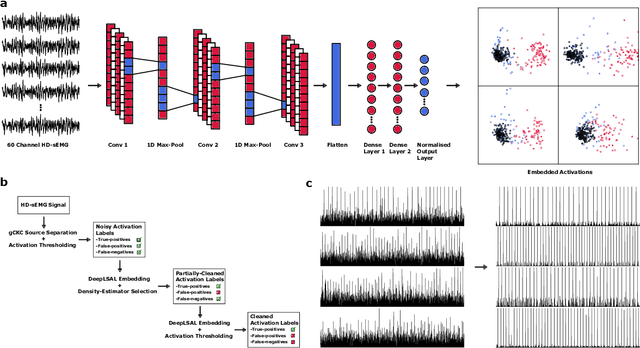
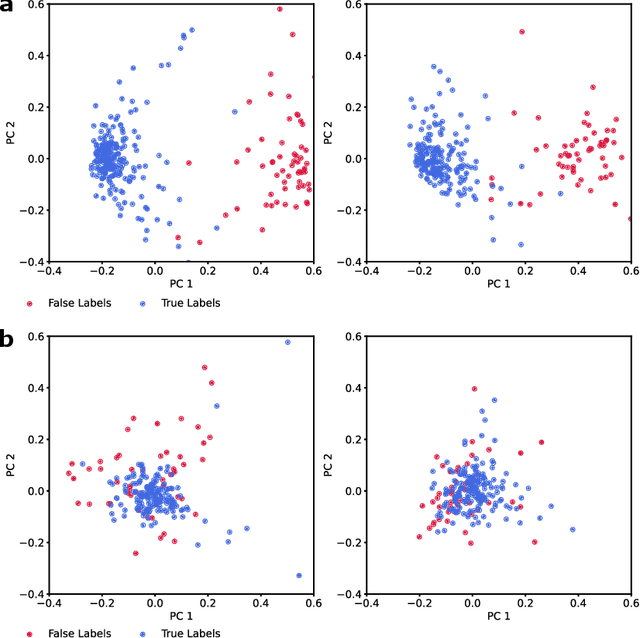
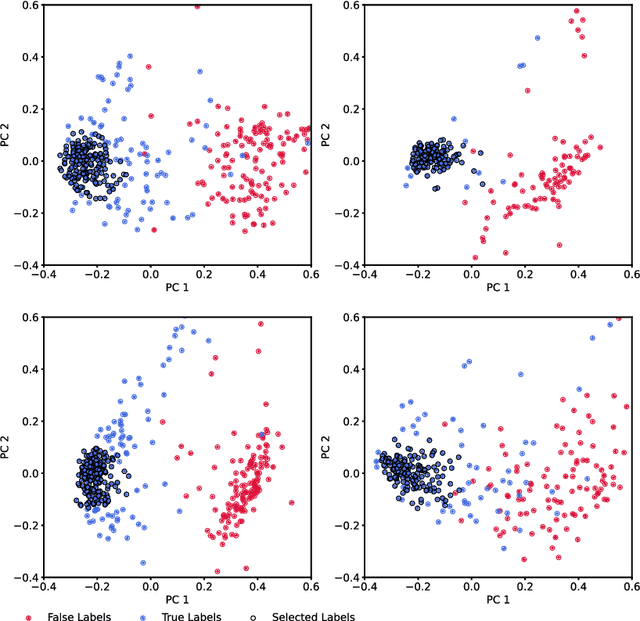
Neurophysiological time series, such as electromyographic signal and intracortical recordings, are typically composed of many individual spiking sources, the recovery of which can give fundamental insights into the biological system of interest or provide neural information for man-machine interfaces. For this reason, source separation algorithms have become an increasingly important tool in neuroscience and neuroengineering. However, in noisy or highly multivariate recordings these decomposition techniques often make a large number of errors, which degrades human-machine interfacing applications and often requires costly post-hoc manual cleaning of the output label set of spike timestamps. To address both the need for automated post-hoc cleaning and robust separation filters we propose a methodology based on deep metric learning, using a novel loss function which maintains intra-class variance, creating a rich embedding space suitable for both label cleaning and the discovery of new activations. We then validate this method with an artificially corrupted label set based on source-separated high-density surface electromyography recordings, recovering the original timestamps even in extreme degrees of feature and class-dependent label noise. This approach enables a neural network to learn to accurately decode neurophysiological time series using any imperfect method of labelling the signal.
Learning Dynamic Preference Structure Embedding From Temporal Networks
Nov 23, 2021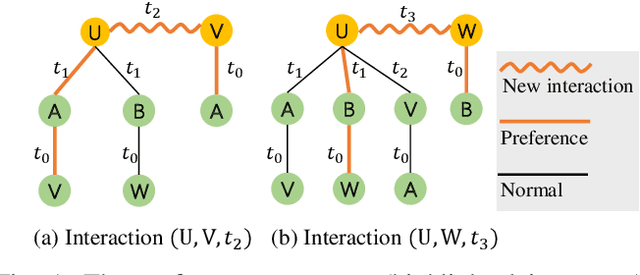
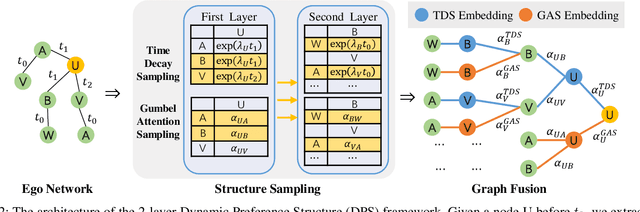
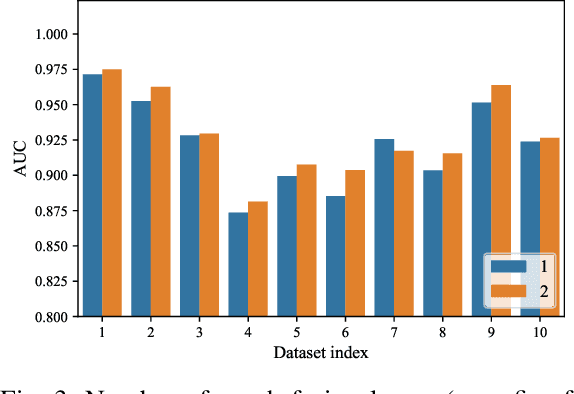
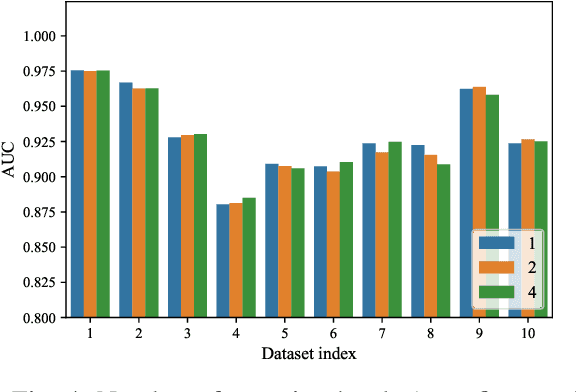
The dynamics of temporal networks lie in the continuous interactions between nodes, which exhibit the dynamic node preferences with time elapsing. The challenges of mining temporal networks are thus two-fold: the dynamic structure of networks and the dynamic node preferences. In this paper, we investigate the dynamic graph sampling problem, aiming to capture the preference structure of nodes dynamically in cooperation with GNNs. Our proposed Dynamic Preference Structure (DPS) framework consists of two stages: structure sampling and graph fusion. In the first stage, two parameterized samplers are designed to learn the preference structure adaptively with network reconstruction tasks. In the second stage, an additional attention layer is designed to fuse two sampled temporal subgraphs of a node, generating temporal node embeddings for downstream tasks. Experimental results on many real-life temporal networks show that our DPS outperforms several state-of-the-art methods substantially owing to learning an adaptive preference structure. The code will be released soon at https://github.com/doujiang-zheng/Dynamic-Preference-Structure.
Multi-Task Prediction of Clinical Outcomes in the Intensive Care Unit using Flexible Multimodal Transformers
Nov 09, 2021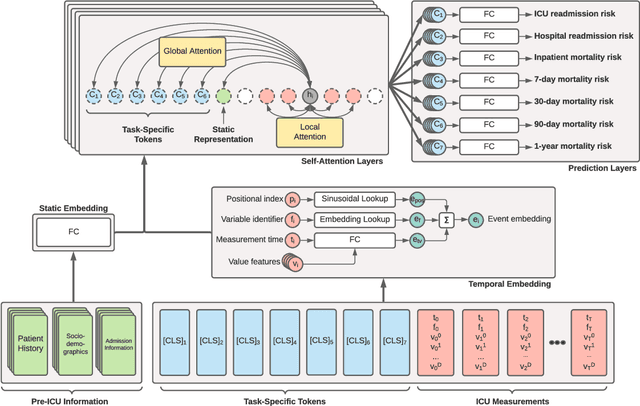
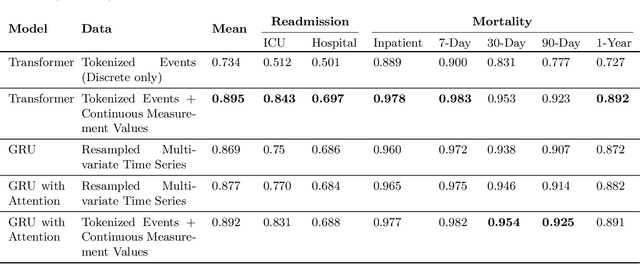
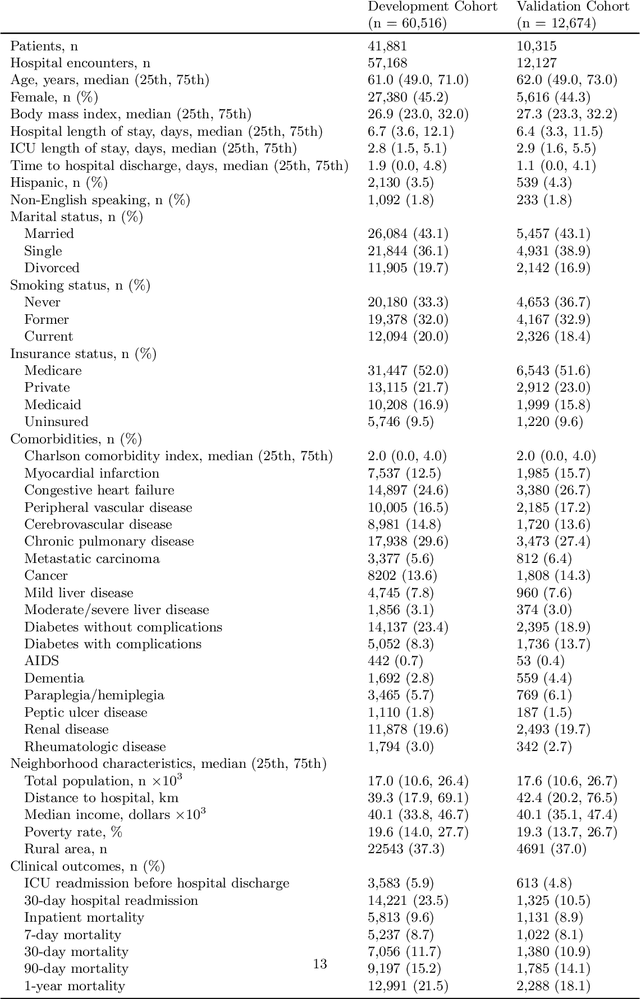
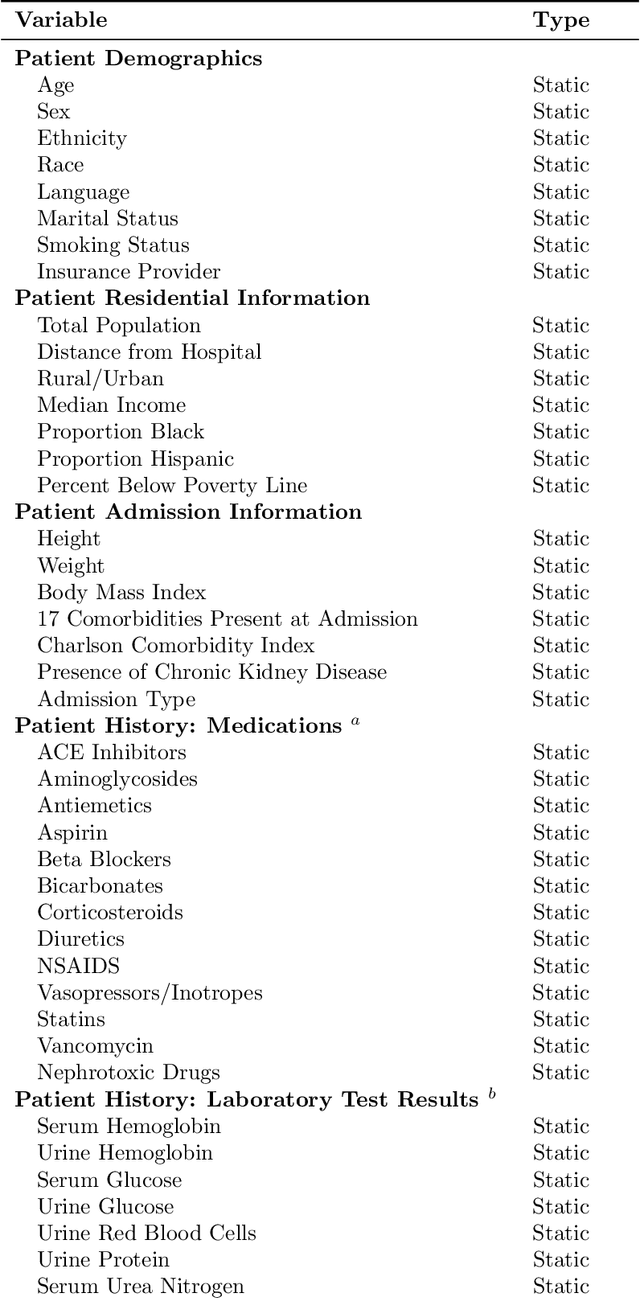
Recent deep learning research based on Transformer model architectures has demonstrated state-of-the-art performance across a variety of domains and tasks, mostly within the computer vision and natural language processing domains. While some recent studies have implemented Transformers for clinical tasks using electronic health records data, they are limited in scope, flexibility, and comprehensiveness. In this study, we propose a flexible Transformer-based EHR embedding pipeline and predictive model framework that introduces several novel modifications of existing workflows that capitalize on data attributes unique to the healthcare domain. We showcase the feasibility of our flexible design in a case study in the intensive care unit, where our models accurately predict seven clinical outcomes pertaining to readmission and patient mortality over multiple future time horizons.
ST-GREED: Space-Time Generalized Entropic Differences for Frame Rate Dependent Video Quality Prediction
Oct 26, 2020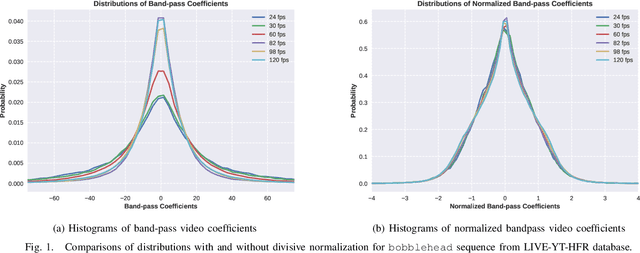
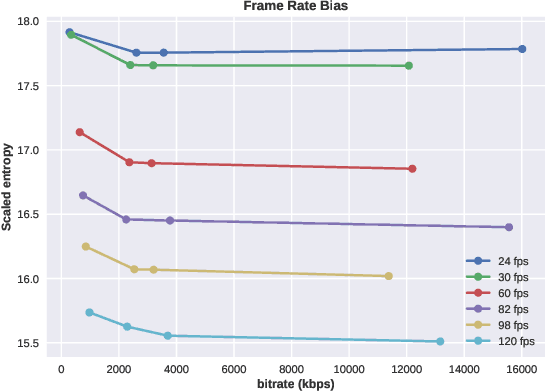
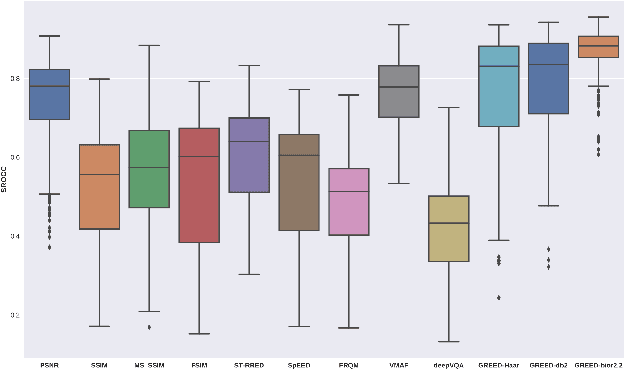
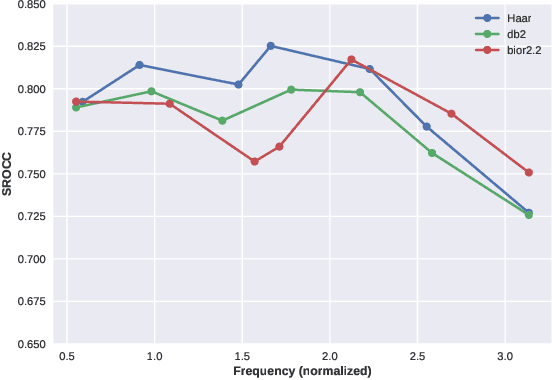
We consider the problem of conducting frame rate dependent video quality assessment (VQA) on videos of diverse frame rates, including high frame rate (HFR) videos. More generally, we study how perceptual quality is affected by frame rate, and how frame rate and compression combine to affect perceived quality. We devise an objective VQA model called Space-Time GeneRalized Entropic Difference (GREED) which analyzes the statistics of spatial and temporal band-pass video coefficients. A generalized Gaussian distribution (GGD) is used to model band-pass responses, while entropy variations between reference and distorted videos under the GGD model are used to capture video quality variations arising from frame rate changes. The entropic differences are calculated across multiple temporal and spatial subbands, and merged using a learned regressor. We show through extensive experiments that GREED achieves state-of-the-art performance on the LIVE-YT-HFR Database when compared with existing VQA models. The features used in GREED are highly generalizable and obtain competitive performance even on standard, non-HFR VQA databases. The implementation of GREED has been made available online: https://github.com/pavancm/GREED
DeepAoANet: Learning Angle of Arrival from Software Defined Radios with Deep Neural Networks
Dec 09, 2021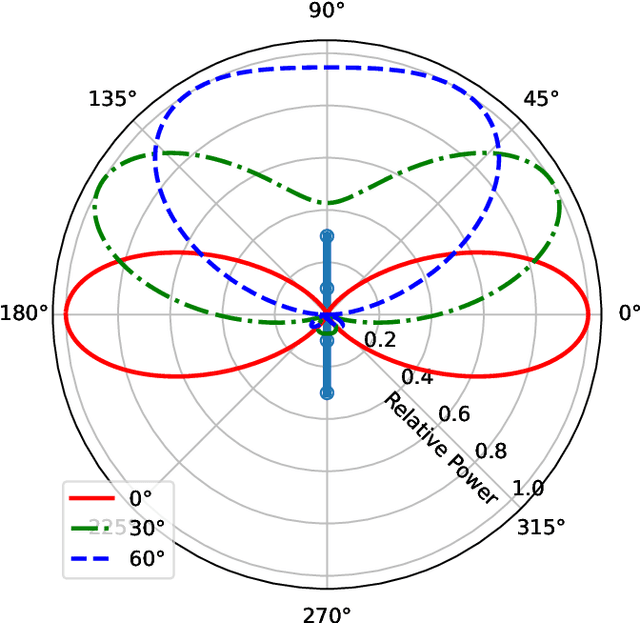
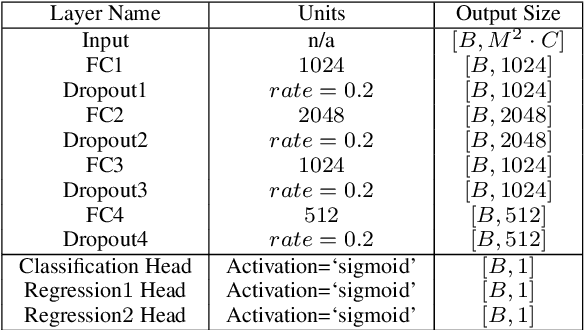
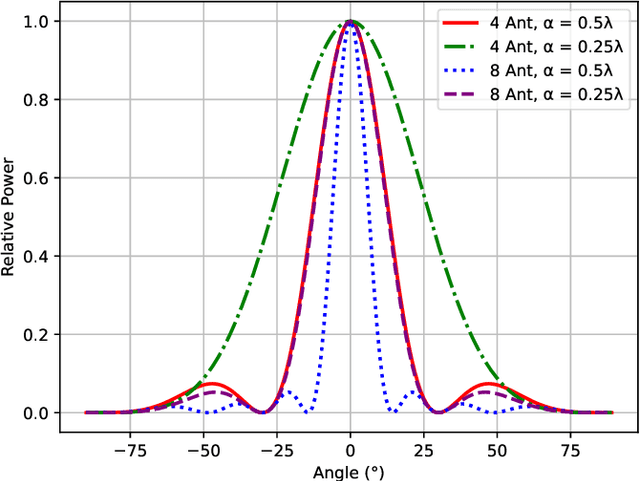
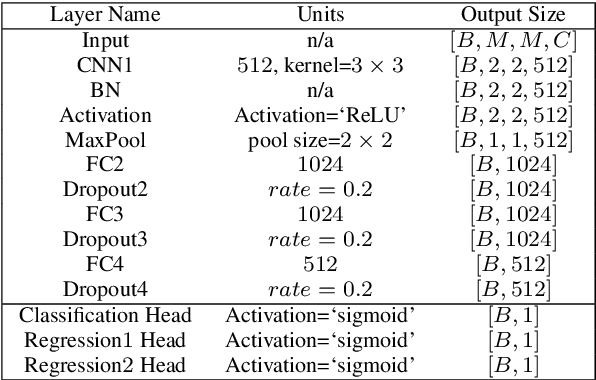
Direction finding and positioning systems based on RF signals are significantly impacted by multipath propagation, particularly in indoor environments. Existing algorithms (e.g MUSIC) perform poorly in resolving Angle of Arrival (AoA) in the presence of multipath or when operating in a weak signal regime. We note that digitally sampled RF frontends allow for the easy analysis of signals, and their delayed components. Low-cost Software-Defined Radio (SDR) modules enable Channel State Information (CSI) extraction across a wide spectrum, motivating the design of an enhanced Angle-of-Arrival (AoA) solution. We propose a Deep Learning approach to deriving AoA from a single snapshot of the SDR multichannel data. We compare and contrast deep-learning based angle classification and regression models, to estimate up to two AoAs accurately. We have implemented the inference engines on different platforms to extract AoAs in real-time, demonstrating the computational tractability of our approach. To demonstrate the utility of our approach we have collected IQ (In-phase and Quadrature components) samples from a four-element Universal Linear Array (ULA) in various Light-of-Sight (LOS) and Non-Line-of-Sight (NLOS) environments, and published the dataset. Our proposed method demonstrates excellent reliability in determining number of impinging signals and realized mean absolute AoA errors less than $2^{\circ}$.
Sayer: Using Implicit Feedback to Optimize System Policies
Oct 28, 2021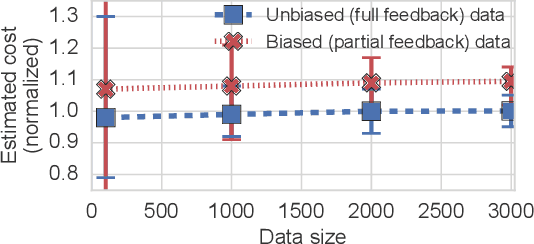
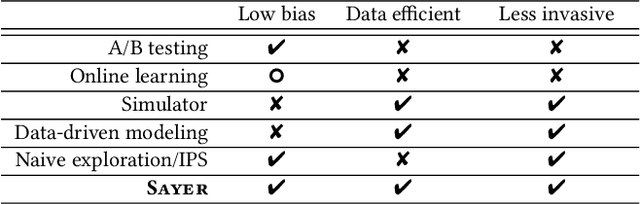
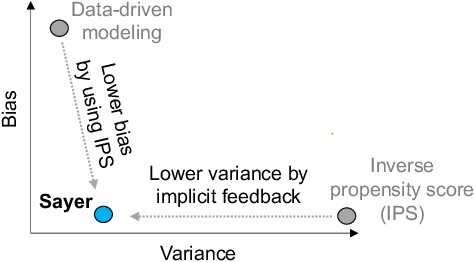
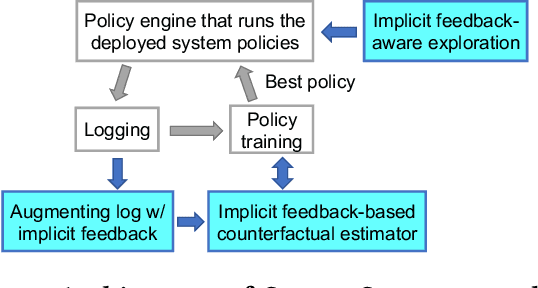
We observe that many system policies that make threshold decisions involving a resource (e.g., time, memory, cores) naturally reveal additional, or implicit feedback. For example, if a system waits X min for an event to occur, then it automatically learns what would have happened if it waited <X min, because time has a cumulative property. This feedback tells us about alternative decisions, and can be used to improve the system policy. However, leveraging implicit feedback is difficult because it tends to be one-sided or incomplete, and may depend on the outcome of the event. As a result, existing practices for using feedback, such as simply incorporating it into a data-driven model, suffer from bias. We develop a methodology, called Sayer, that leverages implicit feedback to evaluate and train new system policies. Sayer builds on two ideas from reinforcement learning -- randomized exploration and unbiased counterfactual estimators -- to leverage data collected by an existing policy to estimate the performance of new candidate policies, without actually deploying those policies. Sayer uses implicit exploration and implicit data augmentation to generate implicit feedback in an unbiased form, which is then used by an implicit counterfactual estimator to evaluate and train new policies. The key idea underlying these techniques is to assign implicit probabilities to decisions that are not actually taken but whose feedback can be inferred; these probabilities are carefully calculated to ensure statistical unbiasedness. We apply Sayer to two production scenarios in Azure, and show that it can evaluate arbitrary policies accurately, and train new policies that outperform the production policies.
Securing your Airspace: Detection of Drones Trespassing Protected Areas
Nov 05, 2021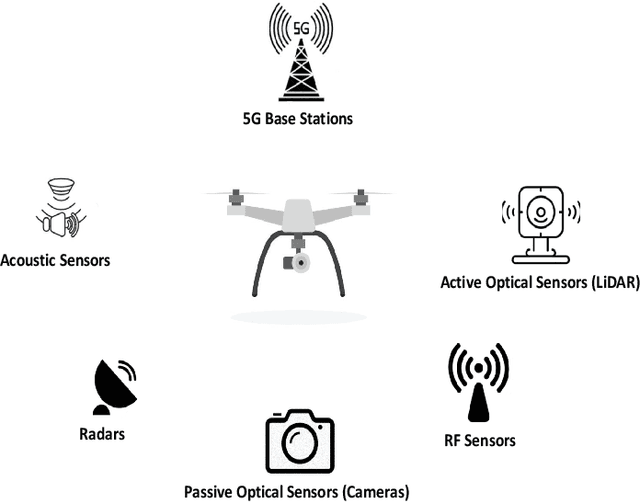
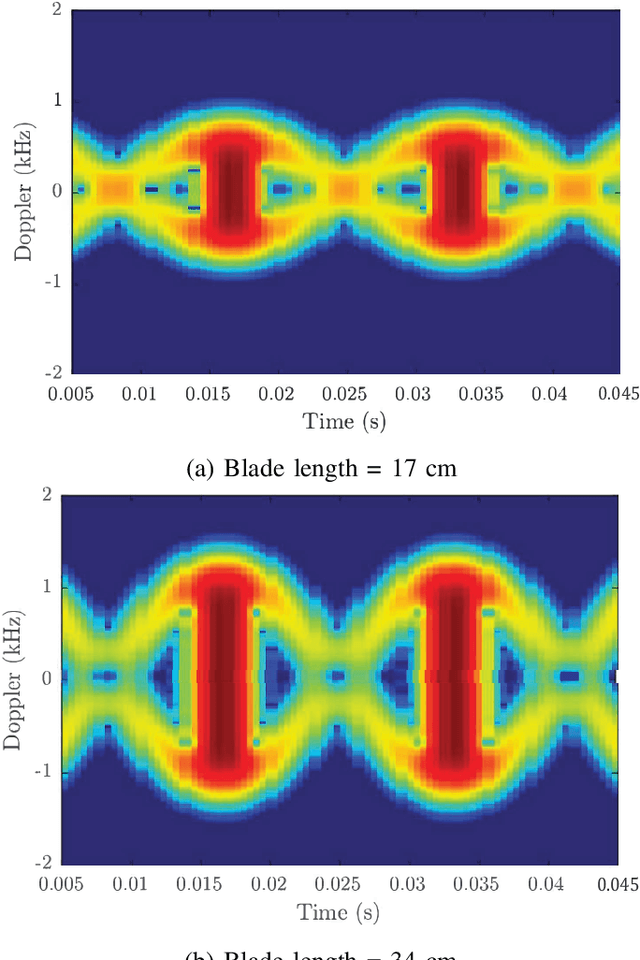
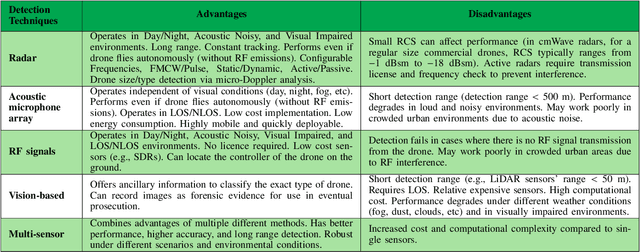
There has been a rapid growth in the deployment of Unmanned Aerial Vehicles (UAVs) in various applications ranging from vital safety-of-life such as surveillance and reconnaissance at nuclear power plants to entertainment and hobby applications. While popular, drones can pose serious security threats that can be unintentional or intentional. Thus, there is an urgent need for real-time accurate detection and classification of drones. In this article, we perform a survey of drone detection approaches presenting their advantages and limitations. We analyze detection techniques that employ radars, acoustic and optical sensors, and emitted radio frequency (RF) signals. We compare their performance, accuracy, and cost, concluding that combining multiple sensing modalities might be the path forward.
Spatio-temporal Relation Modeling for Few-shot Action Recognition
Dec 09, 2021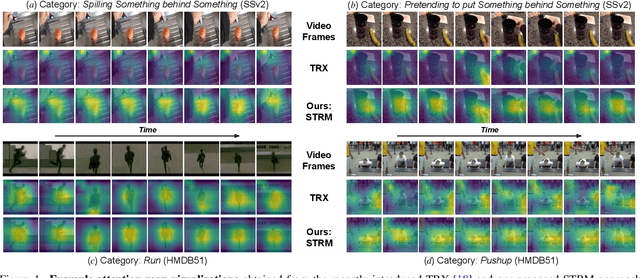
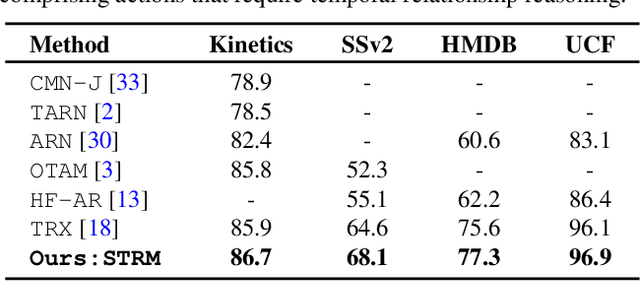
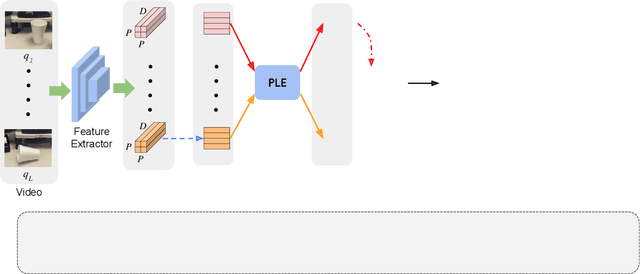
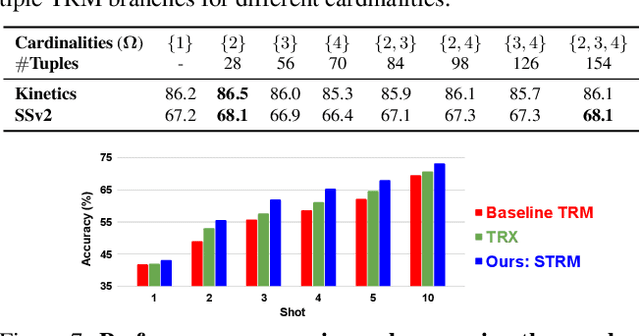
We propose a novel few-shot action recognition framework, STRM, which enhances class-specific feature discriminability while simultaneously learning higher-order temporal representations. The focus of our approach is a novel spatio-temporal enrichment module that aggregates spatial and temporal contexts with dedicated local patch-level and global frame-level feature enrichment sub-modules. Local patch-level enrichment captures the appearance-based characteristics of actions. On the other hand, global frame-level enrichment explicitly encodes the broad temporal context, thereby capturing the relevant object features over time. The resulting spatio-temporally enriched representations are then utilized to learn the relational matching between query and support action sub-sequences. We further introduce a query-class similarity classifier on the patch-level enriched features to enhance class-specific feature discriminability by reinforcing the feature learning at different stages in the proposed framework. Experiments are performed on four few-shot action recognition benchmarks: Kinetics, SSv2, HMDB51 and UCF101. Our extensive ablation study reveals the benefits of the proposed contributions. Furthermore, our approach sets a new state-of-the-art on all four benchmarks. On the challenging SSv2 benchmark, our approach achieves an absolute gain of 3.5% in classification accuracy, as compared to the best existing method in the literature. Our code and models will be publicly released.
Extracting Dynamical Models from Data
Oct 13, 2021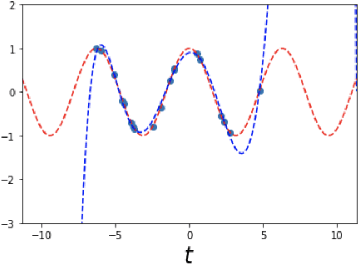
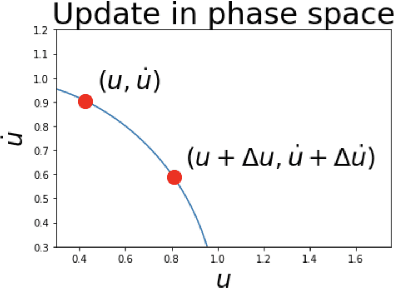
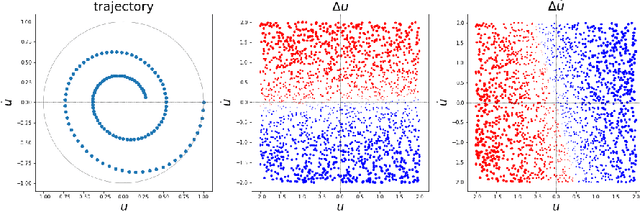
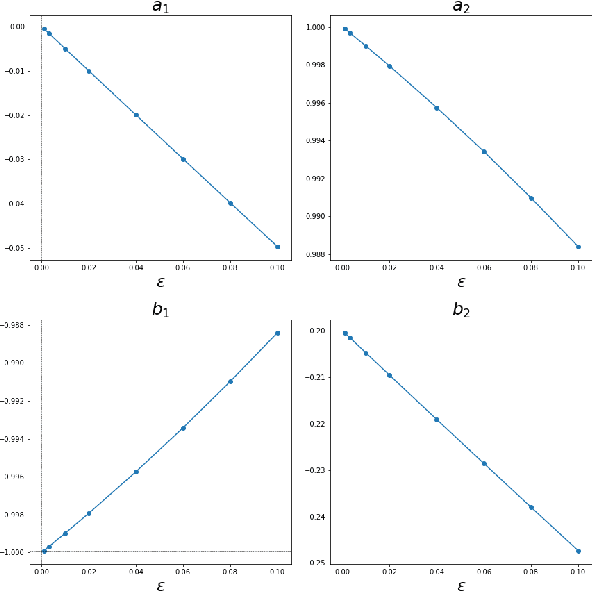
The FJet approach is introduced for determining the underlying model of a dynamical system. It borrows ideas from the fields of Lie symmetries as applied to differential equations (DEs), and numerical integration (such as Runge-Kutta). The technique can be considered as a way to use machine learning (ML) to derive a numerical integration scheme. The technique naturally overcomes the "extrapolation problem", which is when ML is used to extrapolate a model beyond the time range of the original training data. It does this by doing the modeling in the phase space of the system, rather than over the time domain. When modeled with a type of regression scheme, it's possible to accurately determine the underlying DE, along with parameter dependencies. Ideas from the field of Lie symmetries applied to ordinary DEs are used to determine constants of motion, even for damped and driven systems. These statements are demonstrated on three examples: a damped harmonic oscillator, a damped pendulum, and a damped, driven nonlinear oscillator (Duffing oscillator). In the model for the Duffing oscillator, it's possible to treat the external force in a manner reminiscent of a Green's function approach. Also, in the case of the undamped harmonic oscillator, the FJet approach remains stable approximately $10^9$ times longer than $4$th-order Runge-Kutta.