 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Factorial Convolution Neural Networks
Nov 13, 2021

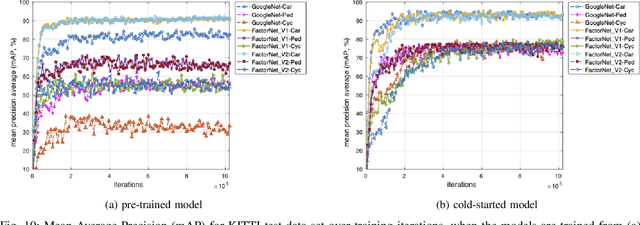


In recent years, GoogleNet has garnered substantial attention as one of the base convolutional neural networks (CNNs) to extract visual features for object detection. However, it experiences challenges of contaminated deep features when concatenating elements with different properties. Also, since GoogleNet is not an entirely lightweight CNN, it still has many execution overheads to apply to a resource-starved application domain. Therefore, a new CNNs, FactorNet, has been proposed to overcome these functional challenges. The FactorNet CNN is composed of multiple independent sub CNNs to encode different aspects of the deep visual features and has far fewer execution overheads in terms of weight parameters and floating-point operations. Incorporating FactorNet into the Faster-RCNN framework proved that FactorNet gives \ignore{a 5\%} better accuracy at a minimum and produces additional speedup over GoolgleNet throughout the KITTI object detection benchmark data set in a real-time object detection system.
Hierarchy Decoder is All You Need To Text Classification
Nov 22, 2021
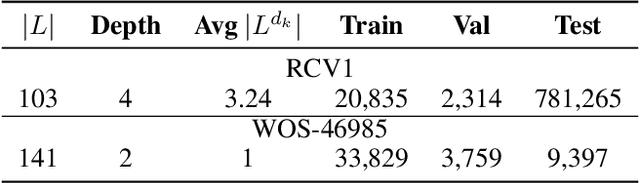
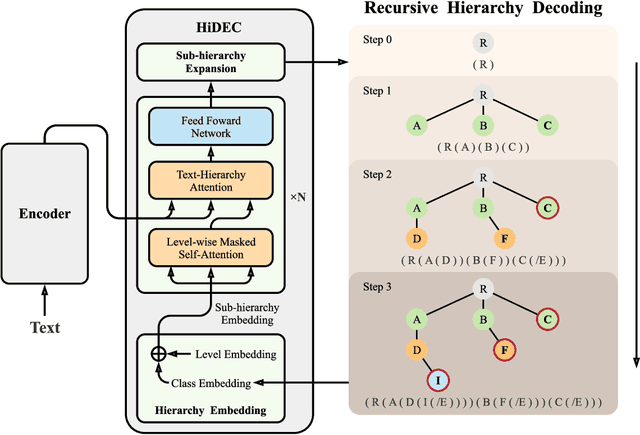
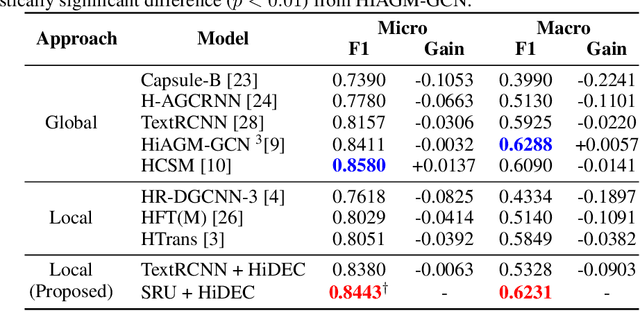
Hierarchical text classification (HTC) to a taxonomy is essential for various real applications butchallenging since HTC models often need to process a large volume of data that are severelyimbalanced and have hierarchy dependencies. Existing local and global approaches use deep learningto improve HTC by reducing the time complexity and incorporating the hierarchy dependencies.However, it is difficult to satisfy both conditions in a single HTC model. This paper proposes ahierarchy decoder (HiDEC) that uses recursive hierarchy decoding based on an encoder-decoderarchitecture. The key idea of the HiDEC involves decoding a context matrix into a sub-hierarchysequence using recursive hierarchy decoding, while staying aware of hierarchical dependenciesand level information. The HiDEC is a unified model that incorporates the benefits of existingapproaches, thereby alleviating the aforementioned difficulties without any trade-off. In addition, itcan be applied to both single- and multi-label classification with a minor modification. The superiorityof the proposed model was verified on two benchmark datasets (WOS-46985 and RCV1) with anexplanation of the reasons for its success
CCO-VOXEL: Chance Constrained Optimization over Uncertain Voxel-Grid Representation for Safe Trajectory Planning
Oct 06, 2021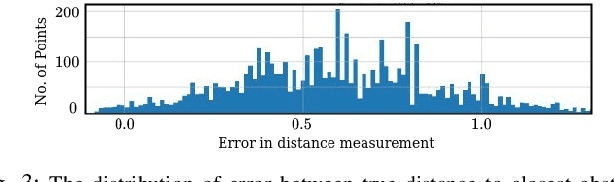
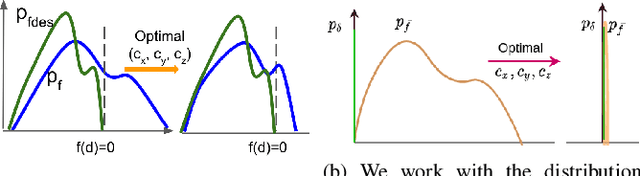
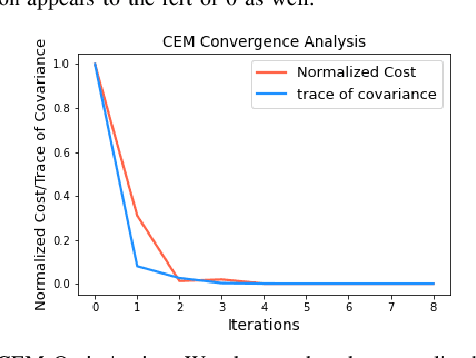

We present CCO-VOXEL: the very first chance-constrained optimization (CCO) algorithm that can compute trajectory plans with probabilistic safety guarantees in real-time directly on the voxel-grid representation of the world. CCO-VOXEL maps the distribution over the distance to the closest obstacle to a distribution over collision-constraint violation and computes an optimal trajectory that minimizes the violation probability. Importantly, unlike existing works, we never assume the nature of the sensor uncertainty or the probability distribution of the resulting collision-constraint violations. We leverage the notion of Hilbert Space embedding of distributions and Maximum Mean Discrepancy (MMD) to compute a tractable surrogate for the original chance-constrained optimization problem and employ a combination of A* based graph-search and Cross-Entropy Method for obtaining its minimum. We show tangible performance gain in terms of collision avoidance and trajectory smoothness as a consequence of our probabilistic formulation vis a vis state-of-the-art planning methods that do not account for such nonparametric noise. Finally, we also show how a combination of low-dimensional feature embedding and pre-caching of Kernel Matrices of MMD allows us to achieve real-time performance in simulations as well as in implementations on on-board commodity hardware that controls the quadrotor flight
Online Feature Selection for Efficient Learning in Networked Systems
Dec 15, 2021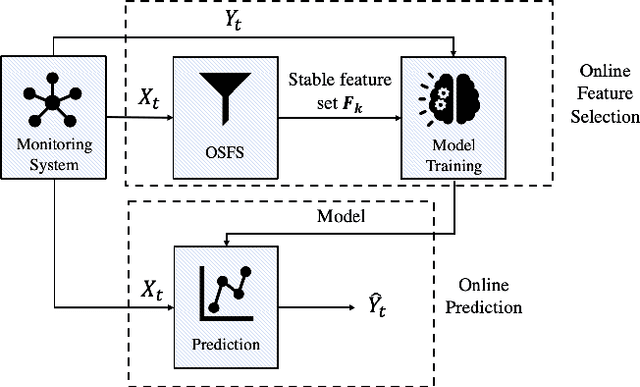

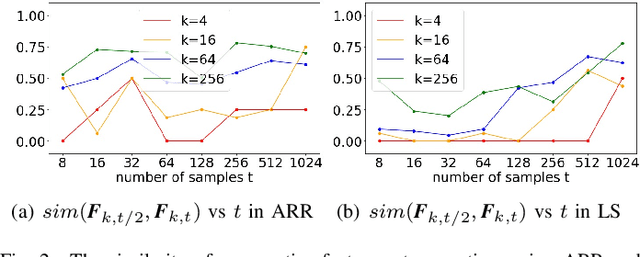

Current AI/ML methods for data-driven engineering use models that are mostly trained offline. Such models can be expensive to build in terms of communication and computing cost, and they rely on data that is collected over extended periods of time. Further, they become out-of-date when changes in the system occur. To address these challenges, we investigate online learning techniques that automatically reduce the number of available data sources for model training. We present an online algorithm called Online Stable Feature Set Algorithm (OSFS), which selects a small feature set from a large number of available data sources after receiving a small number of measurements. The algorithm is initialized with a feature ranking algorithm, a feature set stability metric, and a search policy. We perform an extensive experimental evaluation of this algorithm using traces from an in-house testbed and from a data center in operation. We find that OSFS achieves a massive reduction in the size of the feature set by 1-3 orders of magnitude on all investigated datasets. Most importantly, we find that the accuracy of a predictor trained on a OSFS-produced feature set is somewhat better than when the predictor is trained on a feature set obtained through offline feature selection. OSFS is thus shown to be effective as an online feature selection algorithm and robust regarding the sample interval used for feature selection. We also find that, when concept drift in the data underlying the model occurs, its effect can be mitigated by recomputing the feature set and retraining the prediction model.
Dense Uncertainty Estimation via an Ensemble-based Conditional Latent Variable Model
Nov 22, 2021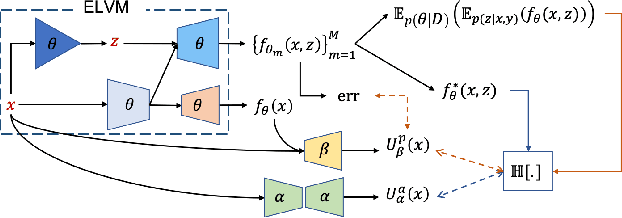



Uncertainty estimation has been extensively studied in recent literature, which can usually be classified as aleatoric uncertainty and epistemic uncertainty. In current aleatoric uncertainty estimation frameworks, it is often neglected that the aleatoric uncertainty is an inherent attribute of the data and can only be correctly estimated with an unbiased oracle model. Since the oracle model is inaccessible in most cases, we propose a new sampling and selection strategy at train time to approximate the oracle model for aleatoric uncertainty estimation. Further, we show a trivial solution in the dual-head based heteroscedastic aleatoric uncertainty estimation framework and introduce a new uncertainty consistency loss to avoid it. For epistemic uncertainty estimation, we argue that the internal variable in a conditional latent variable model is another source of epistemic uncertainty to model the predictive distribution and explore the limited knowledge about the hidden true model. We validate our observation on a dense prediction task, i.e., camouflaged object detection. Our results show that our solution achieves both accurate deterministic results and reliable uncertainty estimation.
Self-Attention for Raw Optical Satellite Time Series Classification
Oct 23, 2019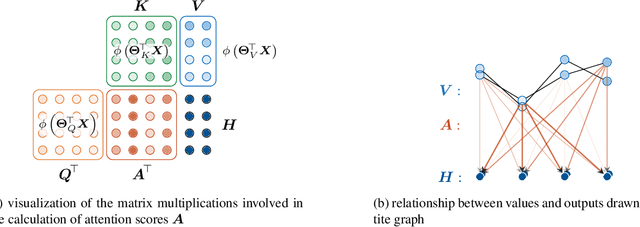
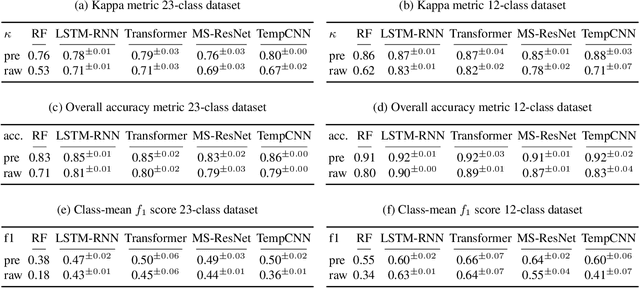
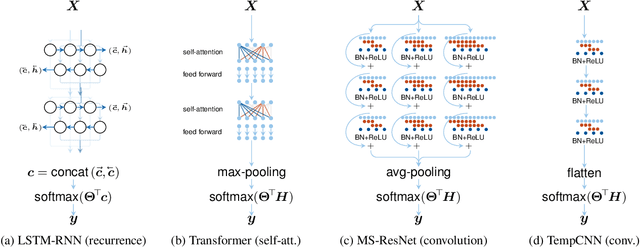
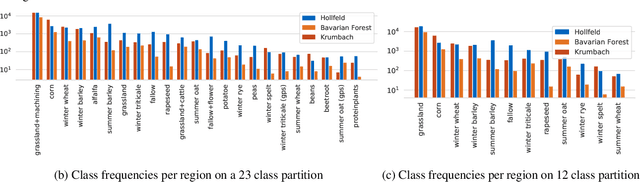
Deep learning methods have received increasing interest by the remote sensing community for multi-temporal land cover classification in recent years. Convolutional Neural networks that elementwise compare a time series with learned kernels, and recurrent neural networks that sequentially process temporal data have dominated the state-of-the-art in the classification of vegetation from satellite time series. Self-attention allows a neural network to selectively extract features from specific times in the input sequence thus suppressing non-classification relevant information. Today, self-attention based neural networks dominate the state-of-the-art in natural language processing but are hardly explored and tested in the remote sensing context. In this work, we embed self-attention in the canon of deep learning mechanisms for satellite time series classification for vegetation modeling and crop type identification. We compare it quantitatively to convolution, and recurrence and test four models that each exclusively relies on one of these mechanisms. The models are trained to identify the type of vegetation on crop parcels using raw and preprocessed Sentinel 2 time series over one entire year. To obtain an objective measure we find the best possible performance for each of the models by a large-scale hyperparameter search with more than 2400 validation runs. Beyond the quantitative comparison, we qualitatively analyze the models by an easy-to-implement, but yet effective feature importance analysis based on gradient back-propagation that exploits the differentiable nature of deep learning models. Finally, we look into the self-attention transformer model and visualize attention scores as bipartite graphs in the context of the input time series and a low-dimensional representation of internal hidden states using t-distributed stochastic neighborhood embedding (t-SNE).
Resource allocation method using tug-of-war-based synchronization
Aug 19, 2021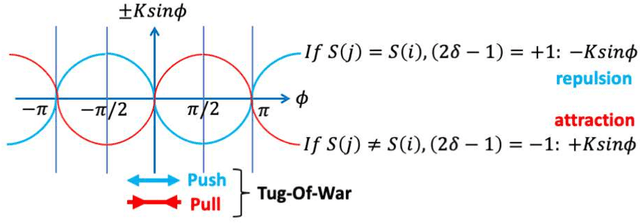
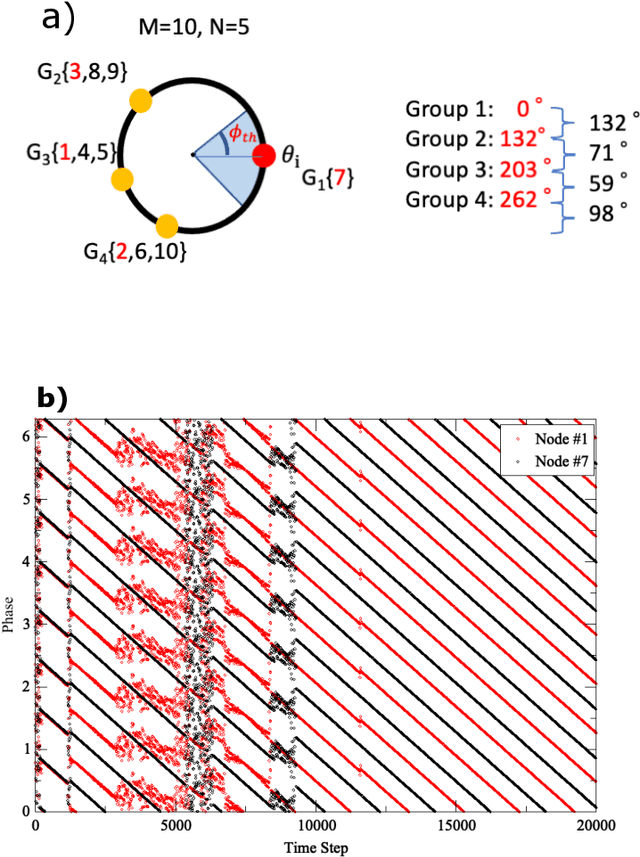
We propose a simple channel-allocation method based on tug-of-war (TOW) dynamics, combined with the time scheduling based on nonlinear oscillator synchronization to efficiently use of the space (channel) and time resources in wireless communications. This study demonstrates that synchronization groups, where each node selects a different channel, are non-uniformly distributed in phase space such that every distance between groups is larger than the area of influence. New type of self-organized spatiotemporal patterns can be formed for resource allocation according to channel rewards.
Physics-Informed Neural Networks for AC Optimal Power Flow
Oct 06, 2021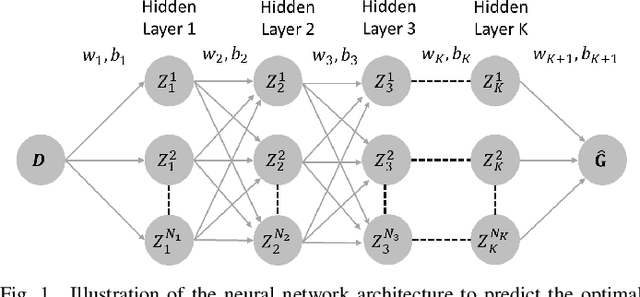
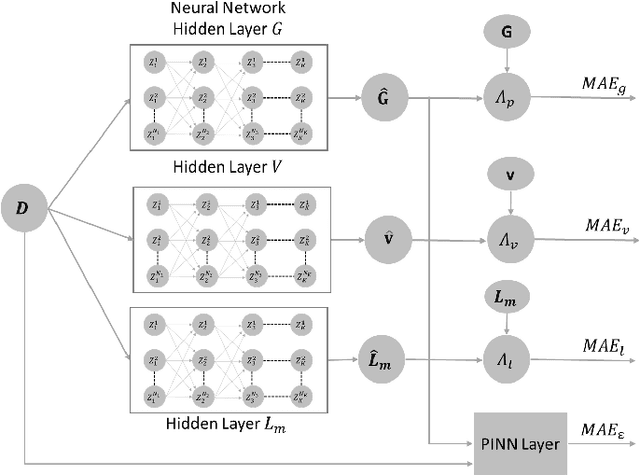
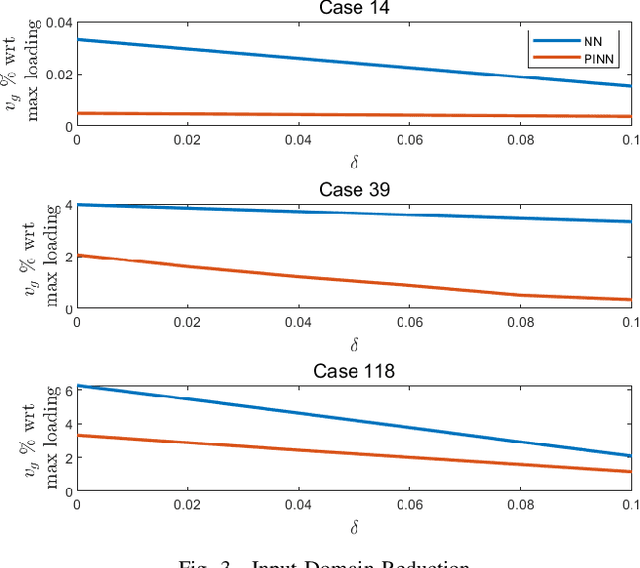
This paper introduces, for the first time to our knowledge, physics-informed neural networks to accurately estimate the AC-OPF result and delivers rigorous guarantees about their performance. Power system operators, along with several other actors, are increasingly using Optimal Power Flow (OPF) algorithms for a wide number of applications, including planning and real-time operations. However, in its original form, the AC Optimal Power Flow problem is often challenging to solve as it is non-linear and non-convex. Besides the large number of approximations and relaxations, recent efforts have also been focusing on Machine Learning approaches, especially neural networks. So far, however, these approaches have only partially considered the wide number of physical models available during training. And, more importantly, they have offered no guarantees about potential constraint violations of their output. Our approach (i) introduces the AC power flow equations inside neural network training and (ii) integrates methods that rigorously determine and reduce the worst-case constraint violations across the entire input domain, while maintaining the optimality of the prediction. We demonstrate how physics-informed neural networks achieve higher accuracy and lower constraint violations than standard neural networks, and show how we can further reduce the worst-case violations for all neural networks.
Learning and Crafting for the Wide Multiple Baseline Stereo
Dec 22, 2021
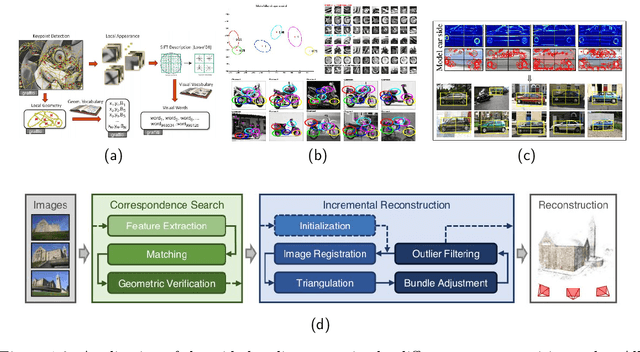
This thesis introduces the wide multiple baseline stereo (WxBS) problem. WxBS, a generalization of the standard wide baseline stereo problem, considers the matching of images that simultaneously differ in more than one image acquisition factor such as viewpoint, illumination, sensor type, or where object appearance changes significantly, e.g., over time. A new dataset with the ground truth, evaluation metric and baselines has been introduced. The thesis presents the following improvements of the WxBS pipeline. (i) A loss function, called HardNeg, for learning a local image descriptor that relies on hard negative mining within a mini-batch and on the maximization of the distance between the closest positive and the closest negative patches. (ii) The descriptor trained with the HardNeg loss, called HardNet, is compact and shows state-of-the-art performance in standard matching, patch verification and retrieval benchmarks. (iii) A method for learning the affine shape, orientation, and potentially other parameters related to geometric and appearance properties of local features. (iv) A tentative correspondences generation strategy which generalizes the standard first to second closest distance ratio is presented. The selection strategy, which shows performance superior to the standard method, is applicable to either hard-engineered descriptors like SIFT, LIOP, and MROGH or deeply learned like HardNet. (v) A feedback loop is introduced for the two-view matching problem, resulting in MODS -- matching with on-demand view synthesis -- algorithm. MODS is an algorithm that handles a viewing angle difference even larger than the previous state-of-the-art ASIFT algorithm, without a significant increase of computational cost over "standard" wide and narrow baseline approaches. Last, but not least, a comprehensive benchmark for local features and robust estimation algorithms is introduced.
Time accelerated image super-resolution using shallow residual feature representative network
Apr 08, 2020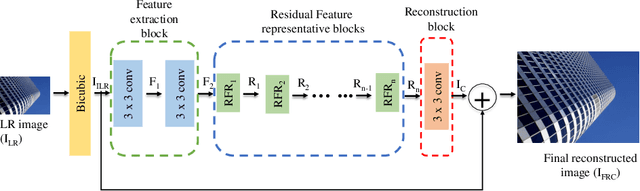
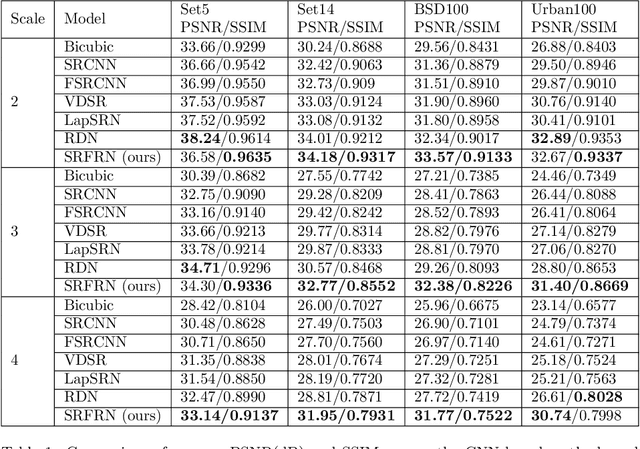

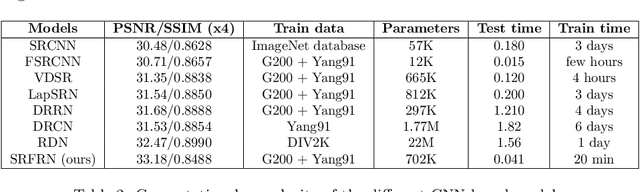
The recent advances in deep learning indicate significant progress in the field of single image super-resolution. With the advent of these techniques, high-resolution image with high peak signal to noise ratio (PSNR) and excellent perceptual quality can be reconstructed. The major challenges associated with existing deep convolutional neural networks are their computational complexity and time; the increasing depth of the networks, often result in high space complexity. To alleviate these issues, we developed an innovative shallow residual feature representative network (SRFRN) that uses a bicubic interpolated low-resolution image as input and residual representative units (RFR) which include serially stacked residual non-linear convolutions. Furthermore, the reconstruction of the high-resolution image is done by combining the output of the RFR units and the residual output from the bicubic interpolated LR image. Finally, multiple experiments have been performed on the benchmark datasets and the proposed model illustrates superior performance for higher scales. Besides, this model also exhibits faster execution time compared to all the existing approaches.