 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Assessing Automated Machine Learning service to detect COVID-19 from X-Ray and CT images: A Real-time Smartphone Application case study
Oct 03, 2020
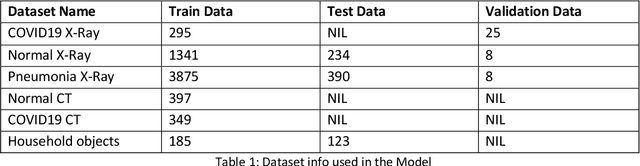
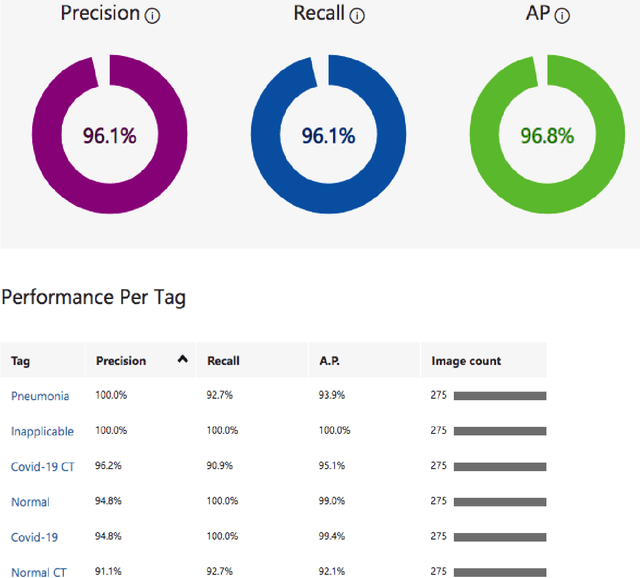
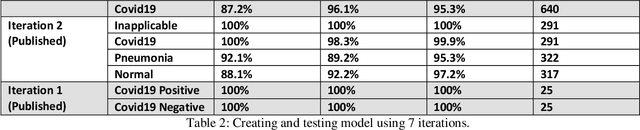
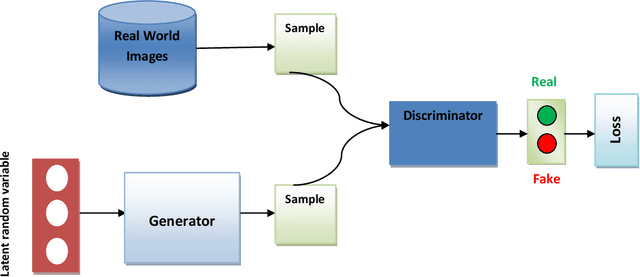
The recent outbreak of SARS COV-2 gave us a unique opportunity to study for a non interventional and sustainable AI solution. Lung disease remains a major healthcare challenge with high morbidity and mortality worldwide. The predominant lung disease was lung cancer. Until recently, the world has witnessed the global pandemic of COVID19, the Novel coronavirus outbreak. We have experienced how viral infection of lung and heart claimed thousands of lives worldwide. With the unprecedented advancement of Artificial Intelligence in recent years, Machine learning can be used to easily detect and classify medical imagery. It is much faster and most of the time more accurate than human radiologists. Once implemented, it is more cost-effective and time-saving. In our study, we evaluated the efficacy of Microsoft Cognitive Service to detect and classify COVID19 induced pneumonia from other Viral/Bacterial pneumonia based on X-Ray and CT images. We wanted to assess the implication and accuracy of the Automated ML-based Rapid Application Development (RAD) environment in the field of Medical Image diagnosis. This study will better equip us to respond with an ML-based diagnostic Decision Support System(DSS) for a Pandemic situation like COVID19. After optimization, the trained network achieved 96.8% Average Precision which was implemented as a Web Application for consumption. However, the same trained network did not perform the same like Web Application when ported to Smartphone for Real-time inference. Which was our main interest of study. The authors believe, there is scope for further study on this issue. One of the main goal of this study was to develop and evaluate the performance of AI-powered Smartphone-based Real-time Application. Facilitating primary diagnostic services in less equipped and understaffed rural healthcare centers of the world with unreliable internet service.
* 21 Pages, 6 Tables
A Reinforcement Learning-based Adaptive Control Model for Future Street Planning, An Algorithm and A Case Study
Dec 10, 2021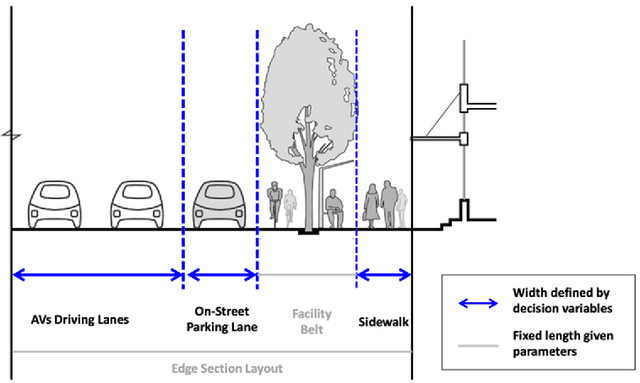
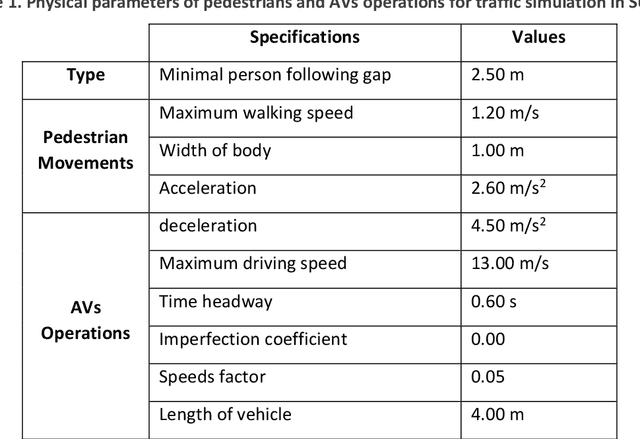
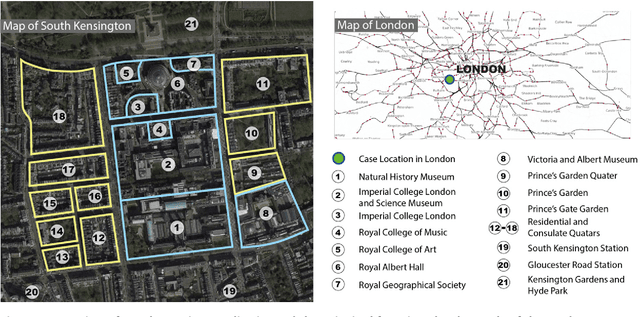
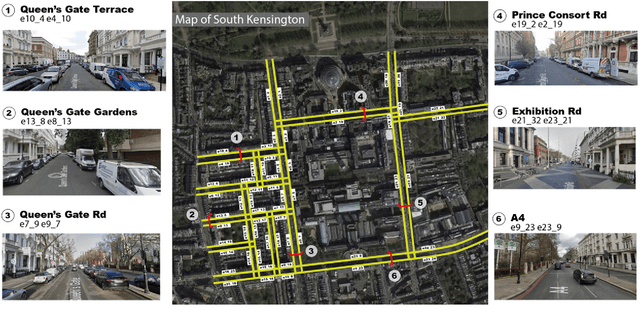
With the emerging technologies in Intelligent Transportation System (ITS), the adaptive operation of road space is likely to be realised within decades. An intelligent street can learn and improve its decision-making on the right-of-way (ROW) for road users, liberating more active pedestrian space while maintaining traffic safety and efficiency. However, there is a lack of effective controlling techniques for these adaptive street infrastructures. To fill this gap in existing studies, we formulate this control problem as a Markov Game and develop a solution based on the multi-agent Deep Deterministic Policy Gradient (MADDPG) algorithm. The proposed model can dynamically assign ROW for sidewalks, autonomous vehicles (AVs) driving lanes and on-street parking areas in real-time. Integrated with the SUMO traffic simulator, this model was evaluated using the road network of the South Kensington District against three cases of divergent traffic conditions: pedestrian flow rates, AVs traffic flow rates and parking demands. Results reveal that our model can achieve an average reduction of 3.87% and 6.26% in street space assigned for on-street parking and vehicular operations. Combined with space gained by limiting the number of driving lanes, the average proportion of sidewalks to total widths of streets can significantly increase by 10.13%.
The Wind in Our Sails: Developing a Reusable and Maintainable Dutch Maritime History Knowledge Graph
Nov 10, 2021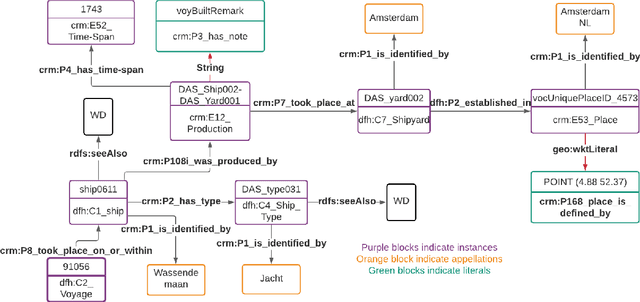
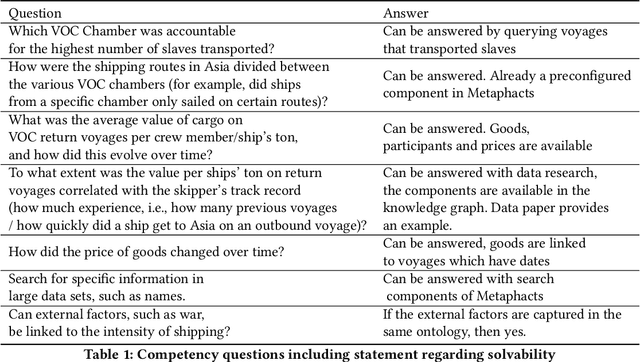
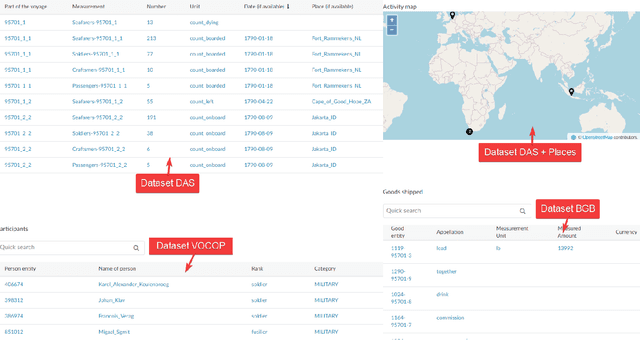
Digital sources are more prevalent than ever but effectively using them can be challenging. One core challenge is that digitized sources are often distributed, thus forcing researchers to spend time collecting, interpreting, and aligning different sources. A knowledge graph can accelerate research by providing a single connected source of truth that humans and machines can query. During two design-test cycles, we convert four data sets from the historical maritime domain into a knowledge graph. The focus during these cycles is on creating a sustainable and usable approach that can be adopted in other linked data conversion efforts. Furthermore, our knowledge graph is available for maritime historians and other interested users to investigate the daily business of the Dutch East India Company through a unified portal.
MCS-HMS: A Multi-Cluster Selection Strategy for the Human Mental Search Algorithm
Nov 20, 2021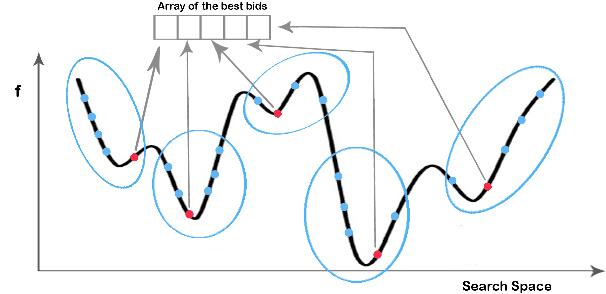
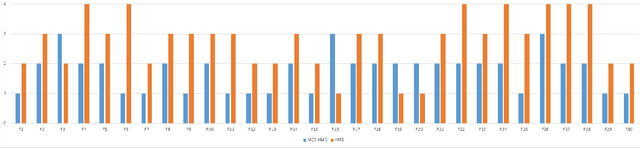
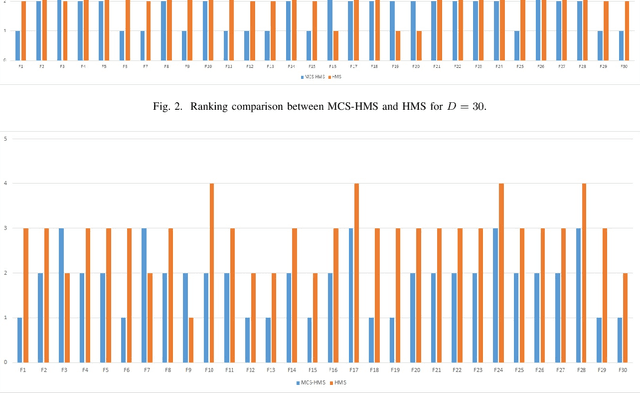
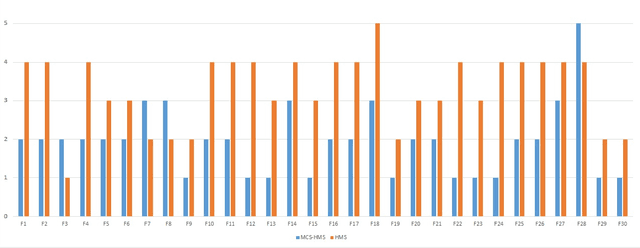
Population-based metaheuristic algorithms have received significant attention in global optimisation. Human Mental Search (HMS) is a relatively recent population-based metaheuristic that has been shown to work well in comparison to other algorithms. However, HMS is time-consuming and suffers from relatively poor exploration. Having clustered the candidate solutions, HMS selects a winner cluster with the best mean objective function. This is not necessarily the best criterion to choose the winner group and limits the exploration ability of the algorithm. In this paper, we propose an improvement to the HMS algorithm in which the best bids from multiple clusters are used to benefit from enhanced exploration. We also use a one-step k-means algorithm in the clustering phase to improve the speed of the algorithm. Our experimental results show that MCS-HMS outperforms HMS as well as other population-based metaheuristic algorithms
Layer-Parallel Training of Residual Networks with Auxiliary-Variable Networks
Dec 10, 2021
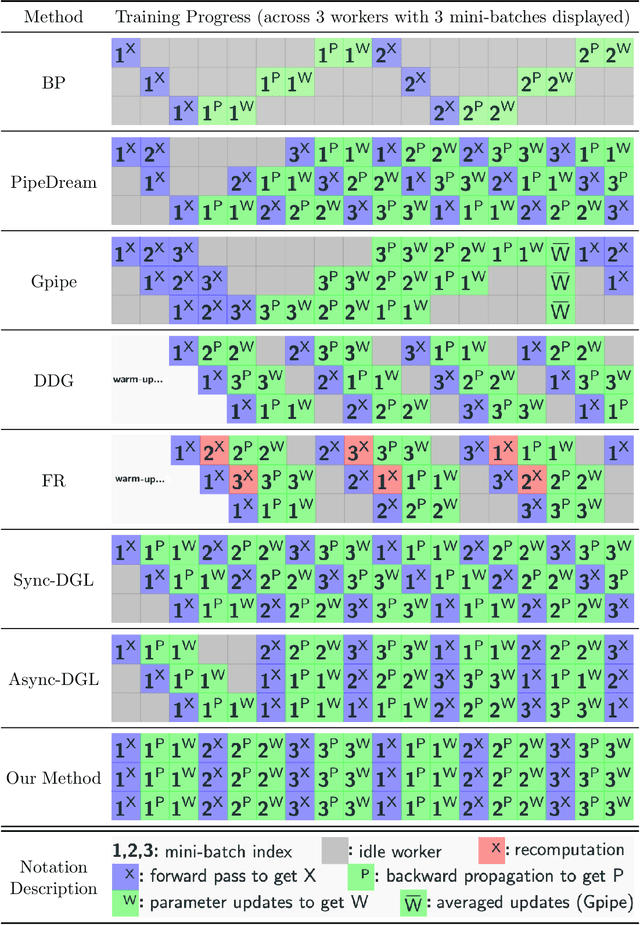

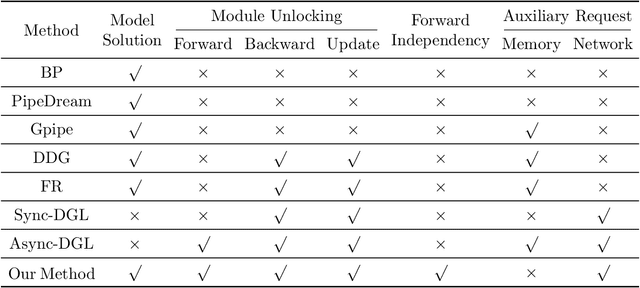
Gradient-based methods for the distributed training of residual networks (ResNets) typically require a forward pass of the input data, followed by back-propagating the error gradient to update model parameters, which becomes time-consuming as the network goes deeper. To break the algorithmic locking and exploit synchronous module parallelism in both the forward and backward modes, auxiliary-variable methods have attracted much interest lately but suffer from significant communication overhead and lack of data augmentation. In this work, a novel joint learning framework for training realistic ResNets across multiple compute devices is established by trading off the storage and recomputation of external auxiliary variables. More specifically, the input data of each independent processor is generated from its low-capacity auxiliary network (AuxNet), which permits the use of data augmentation and realizes forward unlocking. The backward passes are then executed in parallel, each with a local loss function that originates from the penalty or augmented Lagrangian (AL) methods. Finally, the proposed AuxNet is employed to reproduce the updated auxiliary variables through an end-to-end training process. We demonstrate the effectiveness of our methods on ResNets and WideResNets across CIFAR-10, CIFAR-100, and ImageNet datasets, achieving speedup over the traditional layer-serial training method while maintaining comparable testing accuracy.
Assessing Human Interaction in Virtual Reality With Continually Learning Prediction Agents Based on Reinforcement Learning Algorithms: A Pilot Study
Dec 14, 2021
Artificial intelligence systems increasingly involve continual learning to enable flexibility in general situations that are not encountered during system training. Human interaction with autonomous systems is broadly studied, but research has hitherto under-explored interactions that occur while the system is actively learning, and can noticeably change its behaviour in minutes. In this pilot study, we investigate how the interaction between a human and a continually learning prediction agent develops as the agent develops competency. Additionally, we compare two different agent architectures to assess how representational choices in agent design affect the human-agent interaction. We develop a virtual reality environment and a time-based prediction task wherein learned predictions from a reinforcement learning (RL) algorithm augment human predictions. We assess how a participant's performance and behaviour in this task differs across agent types, using both quantitative and qualitative analyses. Our findings suggest that human trust of the system may be influenced by early interactions with the agent, and that trust in turn affects strategic behaviour, but limitations of the pilot study rule out any conclusive statement. We identify trust as a key feature of interaction to focus on when considering RL-based technologies, and make several recommendations for modification to this study in preparation for a larger-scale investigation. A video summary of this paper can be found at https://youtu.be/oVYJdnBqTwQ .
Channel Characterization of Diffusion-based Molecular Communication with Multiple Fully-absorbing Receivers
Nov 23, 2021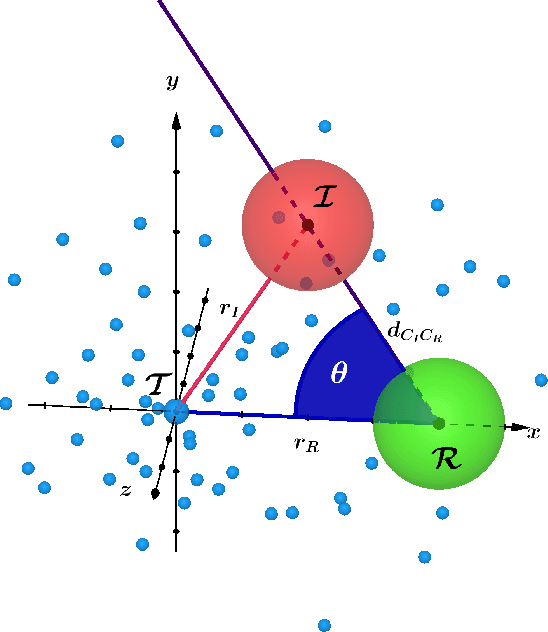
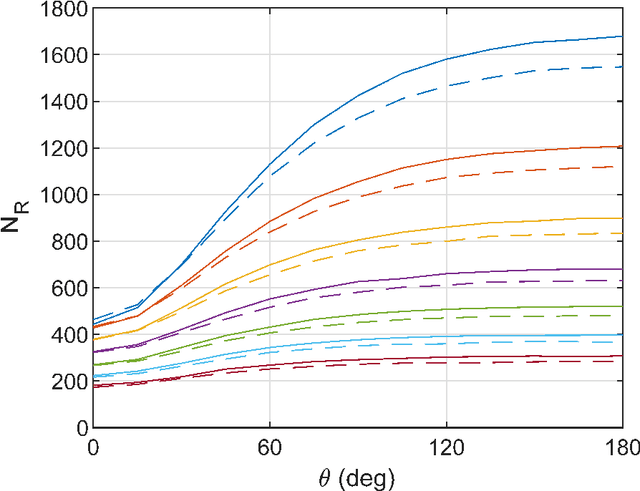
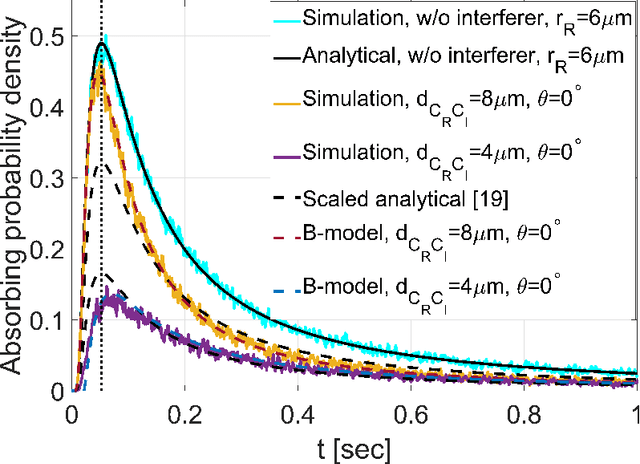
In this paper an analytical model is introduced to describe the impulse response of the diffusive channel between a pointwise transmitter and a given fully-absorbing (FA) receiver in a molecular communication (MC) system. The presence of neighbouring FA nanomachines in the environment is taken into account by describing them as sources of negative molecules. The channel impulse responses of all the receivers are linked in a system of integral equations. The solution of the system with two receivers is obtained analytically. For a higher number of receivers the system of integral equations is solved numerically. It is also shown that the channel impulse response shape is distorted by the presence of the interferers. For instance, there is a time shift of the peak in the number of absorbed molecules compared to the case without interference, as predicted by the proposed model. The analytical derivations are validated by means of particle based simulations.
ST-GREED: Space-Time Generalized Entropic Differences for Frame Rate Dependent Video Quality Prediction
Oct 26, 2020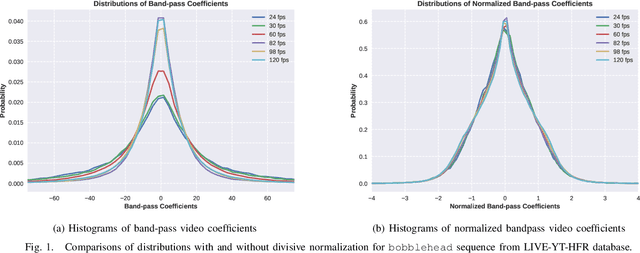
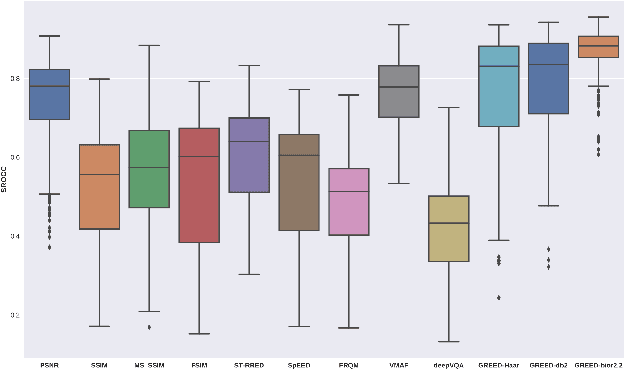
We consider the problem of conducting frame rate dependent video quality assessment (VQA) on videos of diverse frame rates, including high frame rate (HFR) videos. More generally, we study how perceptual quality is affected by frame rate, and how frame rate and compression combine to affect perceived quality. We devise an objective VQA model called Space-Time GeneRalized Entropic Difference (GREED) which analyzes the statistics of spatial and temporal band-pass video coefficients. A generalized Gaussian distribution (GGD) is used to model band-pass responses, while entropy variations between reference and distorted videos under the GGD model are used to capture video quality variations arising from frame rate changes. The entropic differences are calculated across multiple temporal and spatial subbands, and merged using a learned regressor. We show through extensive experiments that GREED achieves state-of-the-art performance on the LIVE-YT-HFR Database when compared with existing VQA models. The features used in GREED are highly generalizable and obtain competitive performance even on standard, non-HFR VQA databases. The implementation of GREED has been made available online: https://github.com/pavancm/GREED
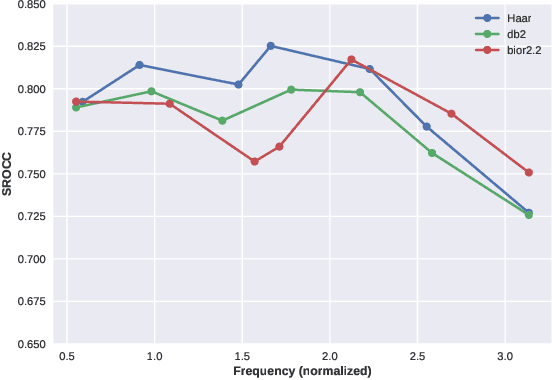
BN-NAS: Neural Architecture Search with Batch Normalization
Aug 16, 2021
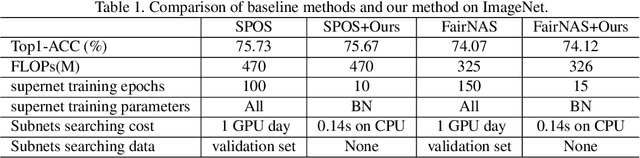
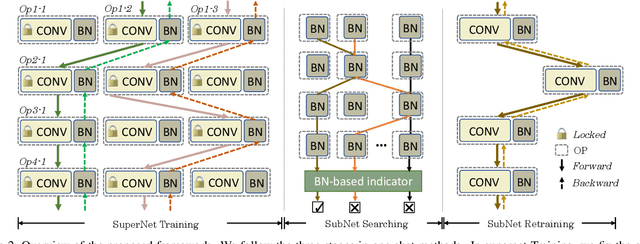
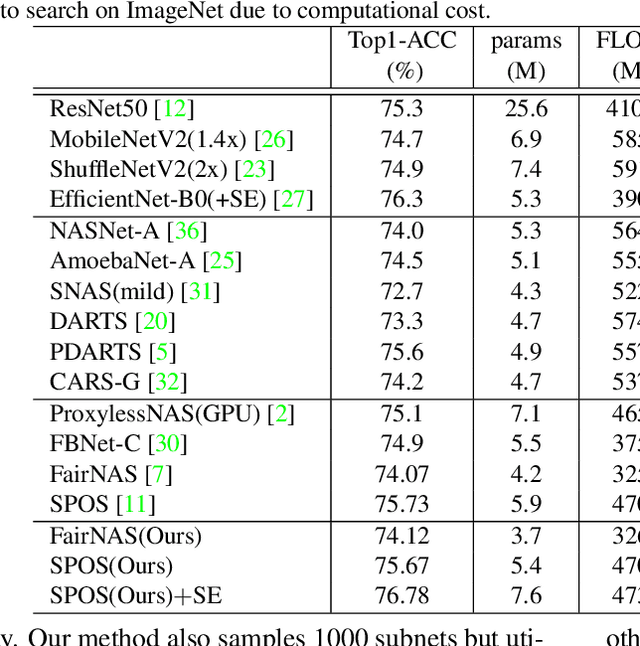
We present BN-NAS, neural architecture search with Batch Normalization (BN-NAS), to accelerate neural architecture search (NAS). BN-NAS can significantly reduce the time required by model training and evaluation in NAS. Specifically, for fast evaluation, we propose a BN-based indicator for predicting subnet performance at a very early training stage. The BN-based indicator further facilitates us to improve the training efficiency by only training the BN parameters during the supernet training. This is based on our observation that training the whole supernet is not necessary while training only BN parameters accelerates network convergence for network architecture search. Extensive experiments show that our method can significantly shorten the time of training supernet by more than 10 times and shorten the time of evaluating subnets by more than 600,000 times without losing accuracy.
Jointly Learning from Decentralized (Federated) and Centralized Data to Mitigate Distribution Shift
Nov 23, 2021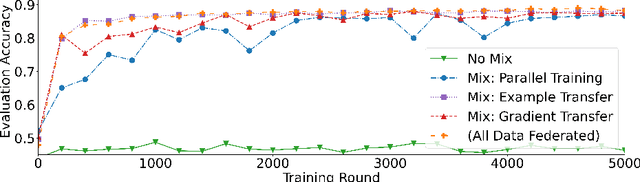
With privacy as a motivation, Federated Learning (FL) is an increasingly used paradigm where learning takes place collectively on edge devices, each with a cache of user-generated training examples that remain resident on the local device. These on-device training examples are gathered in situ during the course of users' interactions with their devices, and thus are highly reflective of at least part of the inference data distribution. Yet a distribution shift may still exist; the on-device training examples may lack for some data inputs expected to be encountered at inference time. This paper proposes a way to mitigate this shift: selective usage of datacenter data, mixed in with FL. By mixing decentralized (federated) and centralized (datacenter) data, we can form an effective training data distribution that better matches the inference data distribution, resulting in more useful models while still meeting the private training data access constraints imposed by FL.